CAPITOLO V
NUOVA ARCHITETTURA
PER RETI DI SENSORI
Sebbene le applicazioni per le Reti di Sensori sono molto diverse per na-tura e requisiti, in tutte c’e’ la necessità di una strutna-tura di rete che sia in grado di risolvere problemi comuni.
È mia opinione infatti che la possibilità del proliferarsi di questa nuova tec-nologia sia fortemente dipendente dalla realizzazione di una architettura di rete dedicata.
La soluzione adottata nel TinyDB presenta alcuni punti deboli tra cui il fatto che non è presente una vera e propria architettura di rete . Nel TinyDB la gestione della rete e quella dei dati risulta ammassata. Infatti tutto appare come un blocco monolitico andando contro al paradigma mo-dulare che permette indipendenza ed riusabilità dei protocolli.
Un altro aspetto su cui è fondamentale far leva è quello della necessità di sfruttare maggiormente le capacità elaborative dei singoli nodi e quindi sgravare il nodo Sink da questo compito. Una soluzione decentralizzata risponde meglio alle esigenze di una Rete di Sensori ed in particolare in-dirizza in modo ottimo il problema della scalabilità e della gestione della rete.
In questo capitolo è introdotta una nuova architettura network per gestire una Rete di Sensori.
A differenza del TinyDB, in questa nuova architettura si cerca di spostare una parte d’intelligenza dal nodo Sink sui singoli nodi come ad esempio la
decisione del piano di esecuzione dell’interrogazione oppure la gestione della reliability.
La disseminazione dell’ interrogazione e la raccolta dei risultati vengono effettuate facendo uso di un albero di routing che spesso viene riorganiz-zato per permettere un consumo omogeneo di energia dei nodi della rete. Naturalmente anche in questa nuova architettura l’obbiettivo primario ri-mane quello del risparmio energetico ed è per questo che i protocolli ap-partenenti a layer diversi possono condividere informazioni tramite l’uso del cross-layer.
5.1
Cross-Layer
Uno dei maggiori vincoli che caratterizza una Rete di Sensori è la limita-tezza dal punto di vista energetico. Perciò in questa nuova architettura fa-remo ricorso ad una tecnica che permette la cooperazione tra protocolli appartenenti a layer diversi: ricorreremo al cross-layer [Conti 03].
Una delle maggiori motivazioni del successo e del proliferarsi di Internet è stato senza dubbio l’uso del layering (strict layering). Infatti sono molti i vantaggi che si traggono nell’usare questa tecnica come ad esempio il fatto che protocolli appartenenti a livelli diversi risultano indipendenti tra loro e che le interazioni tra i livelli sono controllate. Da tutto ciò consegue che lo sviluppo ed la manutenzione dei protocolli di un layer può essere fatto in modo indipendente rispetto al resto del protocolstack.
Allo stesso tempo molti sono i benefici che è possibile trarre usando un approccio cross-layered : sono infatti possibili ottimizzazioni per tutte le funzioni di rete, una riduzione degli overhead evitando la duplicazione di dati su layer diversi. Inoltre è possibile rendere ogni livello contex-aware : ogni protocollo può essere progettato per essere consapevole dello stato della rete.
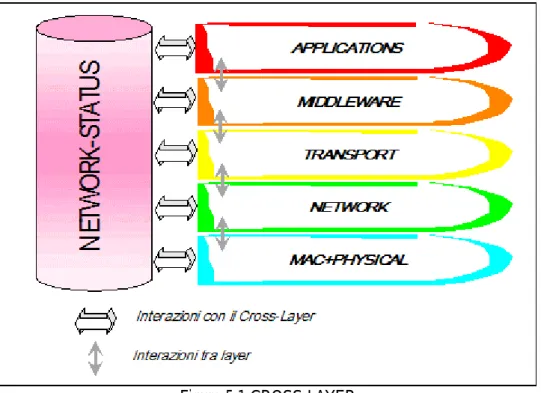
Risulta evidente il fatto che l’uso di entrambi gli approcci sia la soluzione migliore (come mostrato in Figura 5.1). Mantenendo l’architettura a layer
diamo la possibilità a protocolli appartenenti a layer diversi di cooperare tramite la condivisione di informazioni riguardanti lo stato della rete.
Come si nota in Figura 5.1 il core dell’architettura è il network-status che contiene tutte le informazioni collezionate dai protocolli di rete presenti nello stack. Ogni protocollo può accedere al network-status per condivi-dere i propri dati con gli altri protocolli; la separazione dei layer è ottenuta standardizzando gli accessi al network-status.
Figura 5.1 CROSS-LAYER
5.2
Descrizione della Nuova
Architettura per Reti di Sensori
Come introdotto in precedenza la nuova architettura per Reti di Sensori utilizza l’approccio cross-layered. La pila di protocolli e la loro collocazione è mostrata nella Tabella 5.1.
MIDDLEWARE
Linguaggio di Interrogazione
Piano di Esecuzione della Interrogazione Calcolo del Periodo di Campionamento Gestione dei Metadati
Disseminazione della Interrogazione
Raccolta dei risultati: affidabilità della Interrogazione Raccolta dei risultati:aggregazione
Protocollo di Scheduling
TRANSPORT LAYER
Controllo Congestione
NETWORK LAYER Routing
Creazione e gestione Albero di Routing
MAC+PHYSICAL LAYER Topologia della rete Sincronizzazione Nodi MAC-Protocol
Controllo dell’errore e Recupero dell’errore
Tabella 5.1 Protocolli Nuova Architettura per Reti di Sensori
Nel livello Middleware sono collocati tutti i protocolli che hanno una dipen-denza dalla semantica dell’applicazione. Infine gli altri protocolli, indipen-denti dalla semantica dei dati, sono stati collocati nei loro naturali strati (Seguendo il modello TCP/IP e il modello OSI).
Il resto del capitolo fornisce una descrizione a grandi linee di tutte le fun-zionalità elencate in precedenza.
5.3
Linguaggio di Interrogazione
Il linguaggio di interrogazione che usiamo è pressoché identico a quello usato dal TinyDB (cioè SQL-like) e descritto in precedenza (vd. Capitolo 4) con l’unica eccezione che per ogni interrogazione può essere riportata an-che il grado di affidabilità (reliability) richiesto nel recupero dei risultati. Quindi un’interrogazione sarà del tipo:
Select light From sensors Where temp>20 Epoch Duration 5s Reliability 0.6
Specificare una reliability pari a 0.6 significa che, ogni epoch, devono arri-vare al nodo Sink almeno il 60% dei rilevamenti effettuati dai nodi. Natu-ralmente la reliability può variare da un minimo di 0 ad un massimo di 1. La reliability impone un lower bound al numero minimo di risultati che de-vono pervenire al nodo Sink mentre invece, per quanto riguarda il mecca-nismo di disseminazione delle interrogazioni, si assume implicitamente che debba avvenire sempre con reliability pari ad 1.
I rilevamenti effettuati dai nodi sensori sono correlati tra loro (Correlazione Spaziale) come descritto in [Akyildiz 03]. Tipicamente le applicazioni con Reti Sensoriali richiedono una disposizione con alta densità dei sensori in modo da provvedere ad una copertura soddisfacente dell’area di sensing. Da ciò consegue che più sensori effettuano rilevamenti sulla medesima area. Limitare il numero di risultati che sono inviati verso il nodo Sink non porta quindi ad una perdita di informazioni ma, al contrario apporta solo benefici alla rete in quanto, diminuendo il numero messaggi in viaggio, di-minuisce il consumo energetico della rete.
5.4
Albero di Routing
Per la disseminazione delle interrogazioni dal Sink verso la rete e per la raccolta dei risultati è utilizzato un albero di routing simile a quello utiliz-zato dal TinyDB. Ogni nodo ha cioè come riferimento:
• Nodo Padre: da cui riceve le comunicazioni inviate dal Sink e a cui inoltra le comunicazioni e i risultati delle interrogazioni per il nodo Sink. • Nodi figlio: verso i quali svolge le funzionalità di nodo Sink e cioè
recu-pera i risultati delle interrogazioni e inoltra i messaggi inviati dal Sink.
L’albero di routing viene costruito allo startup della rete e l’inizio di tale procedura viene dato dal nodo Sink. Il protocollo di costruzione può es-sere diviso in due fasi:
• La prima parte prevede che ogni nodo decida il padre, si registri presso questo e attenda i messaggi di registrazione di eventuali nodi figlio • La seconda (Dynasty Discover) serve a rendere consapevole ogni
nodo delle caratteristiche del sottoalbero di cui è radice. In particolare ciascun nodo è interessato al numero di nodi e di livelli dell’albero sot-tostante.
La scelta del padre dipende da vari fattori ed in particolare viene effettuata una valutazione in base all’energia disponibile sul padre e al livello dell’albero occupato dal padre.
Alla fine della costruzione dell’albero ogni nodo tiene nota del padre, di una eventuale lista di nodi figlio e delle caratteristiche del sottoalbero. Un albero di routing di esempio è riportato in Figura 5.2.
L’albero di routing non è un albero di tipo statico ma al contrario la sua struttura cambia nel tempo. Infatti sono quattro le cause che possono portare ad una variazione della configurazione dell’albero:
• Aggiunta di un nuovo nodo alla rete: nel caso in cui, per motivi dipendenti dall’applicazione, vengano inseriti nella rete ulteriori nodi, questi, per poter comunicare con il Sink, devono entrare a far parte dell’albero.
1 3 2 4 5 6 7 8 9 10 Livello 0 Livello 1 Livello 2 Livello 3 Livello 4
Figura 5.2 Albero di Routing
• Caduta di un nodo : un nodo può smettere di funzionare o per un fallimento interno oppure perché esaurisce la propria carica ener-getica. In questi casi l’albero deve essere aggiornato il più veloce-mente possibile in quanto si corre il rischio che una parte della rete rimanga scollegata dal Sink. La caduta di un nodo è rilevata dal nodo figlio nel caso in cui quest’ultimo non riceva notizie dal padre per alcune epoch. In questo caso se il figlio risulta essere una fo-glia dell’albero allora nessuno rileva la caduta, altrimenti una parte dell’albero viene ricostruita per far fronte a questa perdita.
• Nodo a basso livello energetico : quando l’energia di un nodo scende al di sotto di una certa soglia è consigliabile riorganizzare l’albero in modo che il nodo con un basso livello energetico diventi
un nodo foglia e possa ridurre in questo modo il proprio consumo energetico. Da questo momento in poi dovrà occuparsi solo di in-viare i propri risultati verso il Sink e non di effettuare l’inoltro dei ri-sultati di altri nodi figlio. Tutto questo viene fatto per uniformare il consumo della rete e per cercare di non ritrovarsi nella situazione in cui ci sono nodi scarichi mentre contemporaneamente altri nodi si ritrovino con grandi capacità energetiche.
• Refresh Periodico : anche nel caso in cui non si verifichi una delle tre condizioni appena elencate è necessario provvedere ad un ag-giornamento periodico (di periodo ampio) dell’albero di routing per prevenire eventuali malfunzionamenti e per bilanciare il consumo energetico dei nodi.
Nei primi tre casi, per limitare il numero di messaggi scambiati e quindi per minimizzare il consumo energetico, si cerca di effettuare un aggiorna-mento parziale dell’albero, coinvolgendo solo i nodi strettamente neces-sari.
Durante i meccanismi di manutenzione sopra citati è necessario rilevare eventuali cicli che possono venire a crearsi tra i nodi della rete.
La descrizione completa del protocollo è presente nel Capitolo 7.
5.5
Metadati
Periodicamente i nodi inviano, verso il nodo Sink tramite l’albero di
routing, delle informazioni riguardanti il proprio stato energetico ed i valori assunti dai propri attributi. Ogni nodo padre riceve queste informazioni dai nodi figli, le memorizza ,le aggrega aggiungendo anche i propri dati ed infine le inoltra verso l’alto.
In questo modo ogni nodo ha informazioni riguardanti gli attributi ed il li-vello energetico di ogni ramo appartenente al proprio sottoalbero.
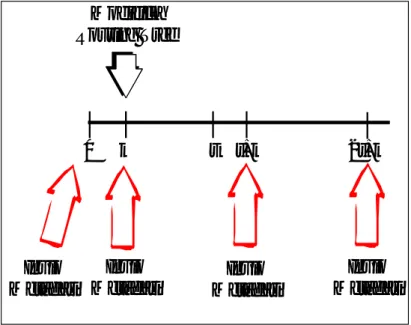
Queste informazioni, che da ora in poi chiameremo metadati, vengono usate da ciascun nodo nel processo di disseminazione dell’interrogazione. I metadati vengono inviati ogni intervallo temporale t, oppure ogni volta che si ha un cambiamento nell’albero di routing e questo provoca però uno slittamento del periodo t successivo. Se ad esempio all’istante k<t av-viene un cambiamento della topologia dell’albero con conseguente invio dei metadati allora il successivo invio dei metadati avverrà all’istante t+k e non all’istante t (Figura 5.3).
0 k t t+k 2t+k Modifica Routing Tree Invio Metadati Invio Metadati Invio Metadati Invio Metadati
Figura 5.3 Invio Metadati
5.6
Disseminazione delle Interrogazioni
Dato un attributo A ciascun nodo, tramite il meccanismo di gestione dei metadati precedentemente descritto, ha memorizzato un intervallo rappre-sentante il range dei valori assunti da A su ciascun ramo del proprio sot-toalbero.
Quando una interrogazione q con un predicato riguardante A (es A>100) arriva al nodo n, il nodo guarda se qualche ramo appartenente al proprio sottoalbero ha un range di A che si sovrappone al predicato dell’interrogazione. In questo caso il nodo n effettua l’inoltro
dell’interrogazione sul figlio (o sui figli) e si prepara a ricevere il risultato; altrimenti l’interrogazione o è applicata solo localmente (se il predicato è soddisfatto) oppure viene cancellata.
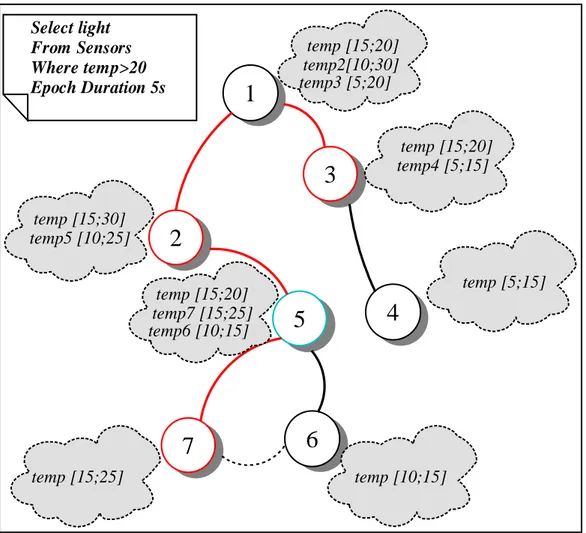
Nella Figura 5.4 è mostrato un esempio di disseminazione di una interrogazione: in nero sono evidenziati i nodi che non partecipano all’interrogazione, in rosso i nodi che partecipano mentre in blu i nodi che, pur non interessati devono inoltrare i risultati dei propri figli.
1
3
2
4
5
6
7
Select light From Sensors Where temp>20 Epoch Duration 5s temp [15;25] temp [10;15] temp [15;20] temp7 [15;25] temp6 [10;15] temp [15;30] temp5 [10;25] temp [5;15] temp [15;20] temp4 [5;15] temp [15;20] temp2[10;30] temp3 [5;20]5.7
Esecuzione delle Interrogazioni
A differenza del TinyDB il nodo Sink non ha una visione completa della rete ma solo una visione parziale in quanto i metadati che periodicamente sono trasmessi arrivano al Sink in modo aggregato. È quindi logico che il piano di esecuzione delle interrogazioni non sia stabilito dal nodo Sink ma da ogni singolo nodo risultando quindi personalizzato e perciò ottimizzato rispetto al metodo adottato in TinyDB . Il nodo Sink si limita soltanto ad effettuare un parsing ed una validazione dell’interrogazione e a indicare un
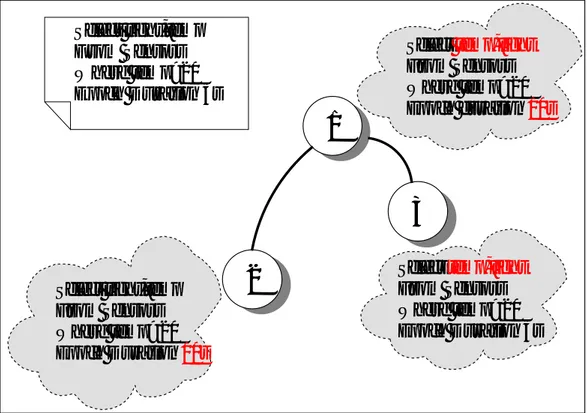
sample period di riferimento. Quando una interrogazione arriva su un nodo questo, in base ai propri metadati, decide il proprio piano di esecuzione in base alla selettività dei propri attributi, all’energia che spende per il cam-pionamento e all’energia attuale del nodo stesso. L’interrogazione speci-fica anche un sample period che il nodo, dopo aver fatto opportune valu-tazioni di tipo energetico può accettare oppure può scegliere un periodo di campionamento maggiore di quello indicato dalla Basestation (ma non mi-nore in quanto produrrei dei risultati che risulterebbero inutili per la Base-station). La Figura 5.5 mostra come ogni singolo nodo possa costruirsi un piano di esecuzione della interrogazione personalizzato ed inoltre come il periodo di campionamento venga ristabilito in base alle esigenze del nodo stesso.
1
3
2
Select light,temp From Sensors Where temp>20 Epoch Duration 5s Select light,temp From Sensors Where temp>20 Epoch Duration 10s Select temp,light From Sensors Where temp>20 Epoch duration10s Selecttemp,light From Sensors Where temp>20 Epoch Duration 5sFigura 5.5 Scelta del Piano di Esecuzione di una interrogazione
5.8
Protocollo MAC
L’accesso al mezzo in una Rete di Sensori non deve solo essere efficiente dal punto di vista energetico ma deve anche garantire un’allocazione equa della banda per tutti i nodi che appartengono alla rete multihop.
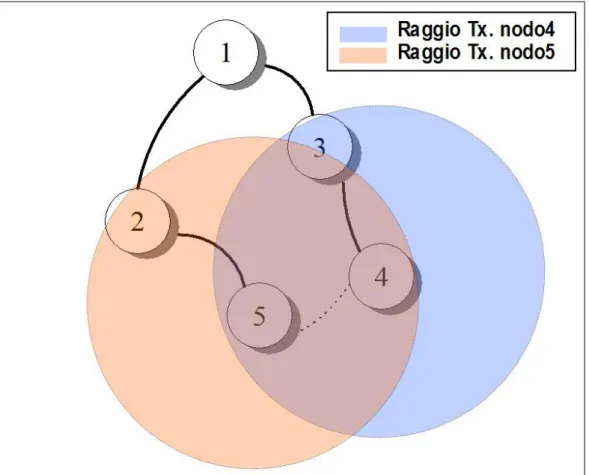
Il MAC protocol utilizzato è quindi un CSMA-CA ma con un backoff time
scelto in modo random da una distribuzione dipendente dal numero di nodi vicini appartenenti allo stesso livello del nodo preso in questione (maggiore è il numero di vicini appartenenti allo stesso livello dell’albero di
routing maggiore è anche l’intervallo da cui viene scelto il backoff time). Infatti, come è rappresentato nella Figura 5.6, i nodi 4 e 5, sebbene ap-partenenti a padri diversi hanno il talk interval parzialmente sovrapposto: ciò potrebbe essere causa di interferenza durante la trasmissione di mes-saggi.
Il backoff time da noi utilizzato da ora in poi verrà chiamato backoff se-mantico.
Figura 5.6 Interferenza durante la trasmissione tra nodi vicini
Il comportamento di una Rete di Sensori dipende molto dall’applicazione in esecuzione e quindi le caratteristiche del traffico tendono ad essere molto diverse da quelle che troviamo nelle reti convenzionali. La rete tende ad operare come una struttura collettiva, piuttosto che supportare diversi flussi indipendenti di tipo point-to-point. Il traffico tende ad essere molto variabile e molto correlato (Temporal-Correlation [Akyildiz 03]). Per un lungo periodo di tempo ci possono essere un piccolo numero di attività e quindi poco traffico per poi ritrovarsi ad avere un piccolo intervallo di tempo in cui il traffico può rivelarsi molto intenso. Ad esempio, il verificarsi di un evento (come un incendio), scaturisce l’invio contemporaneo di dati da parte di molti sensori. Anche senza considerare gli eventi, nel caso più semplice, i nodi compiono campionamenti periodici creando dei burst di messaggi tra loro correlati, anche quando il duty-cycle risulta molto basso
[Woo]. La soluzione da adottare è quindi quella di introdurre anche un pre-delay random nella trasmissione per cercare di de-sincronizzare i nodi.
CONTROLLO E RECUPERO DELL’ERRORE
Un’altra importante funzione del data link layer è il controllo di eventuali er-rori dei dati trasmessi. In letteratura esistono due principali meccanismi per il controllo dell’errore che sono il forward error correction (FEC) in cui l’errore viene rilevato e corretto direttamente dal destinatario e l’automatic repeat request (ARQ) dove una volta rilevato l’errore si procede alla ritra-smissione del pacchetto corrotto.
Utilizzando il FEC si risparmiano le eventuali ritrasmissioni in caso di errori a discapito di un maggiore numero di bit da trasmettere e di maggiori ela-borazioni da compiere sui nodi.
Nella nuova architettura utilizzeremo la tecnica del FEC con ack per quanto riguarda la disseminazione delle interrogazioni (cioè per i pacchetti inviati dal nodo padre verso i nodi figlio); questo perchè le trasmissioni sono effettuate in broadcast
Al contrario, per le trasmissioni da un nodo figlio verso un nodo padre uti-lizziamo la tecnica ARQ unita alla strategia del nack (come mostrato in Figura 5.7). L’uso della strategia del nack risulta molto utile sia per verifi-care la presenza di un nodo sia per implementare la reliability.
1 2 NODO PADRE NODO FIGLIO
FEC,
ack
ARQ,
nack
Figura 5.7 Error Control
Solitamente il controllo dell’errore viene effettuato su tutti i livelli della pila di protocolli. In una Rete di Sensori comunque, tale ridondanza può risul-tare molto dispendiosa dal punto di vista energetico.
5.9
Protocollo di Scheduling
I nodi della rete si organizzano in modo da coordinarsi tra loro e stabilire dei meeting point in cui scambiarsi messaggi. Negli altri istanti i nodi pos-sono essere messi nello stato di sleep con conseguente risparmio dal punto di vista energetico.
Viene sfruttata l’organizzazione ad albero che esiste tra i nodi ed in parti-colare il fatto che ogni nodo abbia bisogno di comunicare solo con il pro-prio padre e con gli eventuali figli.
Il protocollo di scheduling fa in modo che la comunicazione padre-figlio avvenga periodicamente e concentrata in un intervallo temporale prestabi-lito.
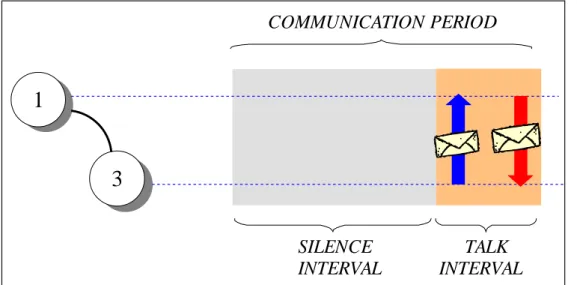
Il periodo di comunicazione tra due nodi è detto communication period e viene suddiviso in due intervalli temporali: silence interval e talk interval. Il
silence interval scandisce le pause di comunicazione padre-figlio mentre al contrario il talk interval è l’intervallo di tempo in cui i nodi possono co-municare (Figura 5.8)
1
3
COMMUNICATION PERIOD SILENCE INTERVAL TALK INTERVALFigura 5.8 Talk Interval e Silente Interval
Il nodo padre stabilisce i valori del silence interval e del talk interval e li comunica ai propri figli.
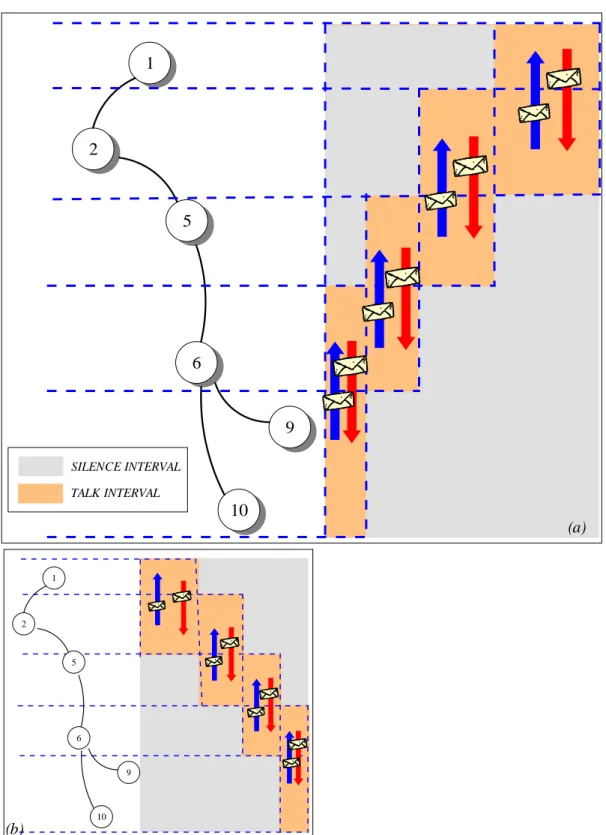
Per permettere un rapido fluire dei risultati delle interrogazioni dai nodi fo-glia al nodo Sink abbiamo scelto lo scheduling mostrato in Figura 3.12-a e non, ad esempio, quello in Figura 3.12-b. In pratica ogni nodo per prima cosa parla con i propri figli ed in seguito con il padre (Figura 3.11) . Il pro-tocollo cerca di far coincidere la fine del Talk Interval con i nodi figlio con l’inizio di quello con il padre in modo da limitare il numero di cambi di stato (sleep-awake, awake-sleep) da far effettuare al nodo.
1
3
4
SILENCE INTERVALTALK INTERVAL
Figura 5.9 Comunicazione padre-figlio
dal tipo di interrogazioni attive sulla rete (numero e tipo di interrogazioni e selettività dei predicati) e dal numero di nodi presenti nel sottoalbero del nodo padre.
Intuitivamente si nota che il communication period deve coincidere con il
sample period imposto dall’interrogazione (o con il minimo tra i sample pe-riod indicato dalle interrogazioni). Idealmente in un Communication Period i risultati dovrebbero fluire dai nodi foglia al nodo Sink (come in Figura 3.12): non sempre questo risulta possibile e a volte è necessario fare ri-corso ad un approccio a pipeline. L’approccio a pipeline viene usato solo quando necessario in quanto introduce un ritardo nella consegna dei ri-sultati al nodo Sink.
La durata del Talk Interval tra un nodo padre e i figli può variare nel tempo in quanto un padre può decidere di aumentare o di diminuire il tempo di comunicazione con i figli. Inoltre il nodo Sink può decidere di cambiare la durata del Communication Period. Come detto in precedenza, uno sche-duling di questo tipo favorisce la comunicazione dal basso verso l’alto dell’albero ma, conseguentemente, rallenta la comunicazione nel verso opposto. La descrizione completa di questo protocollo è riportata nel Ca-pitolo 6.
5.10
Gestione della topologia della Rete
Ogni nodo ha solo una visione parziale della rete di cui fa parte ed in par-ticolare deve essere a conoscenza solo dei vicini distanti un hop. Su cia-scun nodo, periodicamente, va in esecuzione un algoritmo che permette di aggiornare la lista dei vicini. Per fare questo il nodo si mette in ascolto di tutti i messaggi che rileva sul mezzo trasmissivo e preleva l’Identificatore del mittente. In pratica il nodo, per un Communication Period, non viene messo nello stato di sleep ma rimane sempre nello stato awake.
Questa soluzione limita le informazioni che ciascun nodo deve mantenere memorizzate rendendo il tutto scalabile.
Solo il nodo Sink ha una visione completa di tutta la Rete di Sensori. In-fatti, tramite un’apposita interrogazione, può richiedere ai nodi di inviare la lista dei vicini ed in questo modo è possibile ricavare la topologia della rete. 1 2 5 6 9 10 SILENCE INTERVAL TALK INTERVAL 1 2 5 6 9 10 (a) (b)
1 3 2 4 5 6 7 8 9 10
NODE ID PADRE FIGLIO NODE ID PADRE FIGLIO
2 4 7 6 Sì No No No No No Sì Sì 3 5 Sì No No No PACKET Figura 5.11 Lista Nodi Vicini
5.11
Reliability
In questa nuova architettura l’utente associa ad ogni interrogazione un grado di affidabilità che rappresenta l’accuratezza con cui i risultati devono essere recapitati al nodo Sink.
Indichiamo con R il grado di affidabilità (reliability) definito come il rapporto tra i risultati recapitati al Sink e tutti i risultati inviati dai nodi, cioè:
sensore nodi dai inviati risultati sink nodo al pervenuti risultati = R (5.1)
Mentre il processo di disseminazione dell’interrogazione deve essere molto affidabile (R=1 in quanto vogliamo che arrivi a tutti i nodi interessati) non è detto che per la raccolta dei risultati occorra lo stesso grado di affi-dabilità. Abbiamo bisogno di una affidabilità di tipo event-to-Sink [Akyildiz].
Se, ad esempio, abbiamo dei sensori di temperatura disposti in un appar-tamento, molto probabilmente, a causa dell’ alta densità con cui i nodi sono stati distribuiti , le rilevazioni effettuate da due nodi adiacenti non di-scosteranno di molto e quindi non è necessario che entrambe le rileva-zioni arrivino al Sink in quanto risulterebbero solo informazioni duplicate. L’affidabilità degli eventi rilevati dal nodo Sink è basata sull’informazione collettiva fornita dai Nodi Sensore e non su ciascun report individuale: non importa che tutti i rilevamenti effettuati dai nodi arrivino al Sink ma l’importante è che al Sink pervenga il numero minimo di informazioni tali da poter permettere la rilevazione dell’evento.
In questa architettura il controllo della reliability non viene effettuato a li-vello end-to-end ma a livello hop-by-hop richiedendo l’eventuale ritra-smissione dei messaggi corrotti. Questo porta ad un risparmio energetico e una significativa riduzione della congestione nella rete riducendo al mi-nimo necessario il numero di messaggi trasmessi tra i nodi della rete. Ciascun nodo, in base all’affidabilità associata ad unainterrogazione, al tipo di interrogazione (tipo aggregato, selettività dei predicati) ed al nu-mero di nodi appartenenti al proprio sottoalbero è in grado di calcolarsi il numero minimo di risultati che deve ricevere da ogni ramo del sottoalbero per poter ritenere tale evento attendibile. Tale numero da ora in poi verrà chiamato MNRE (minum number for reliable event).
Se supponiamo che in esecuzione ci sia una sola interrogazione del tipo: Select light
From sensors Epoch Duration 5s Reliability 0.65
Poiché con questa interrogazione ogni nodo, ogni 5 secondi deve inviare un risultato, allora risulta semplice, per ogni nodo padre, calcolarsi il pro-prio MNRE. Dato l’albero di routing di Figura 5.2 il valore dell’MNRE di ogni nodo è riportato nella Tabella 5.2.
In base a questi valori ciascun nodo compie alcune operazioni per cercare di trasmettere, ad ogni communication period un numero di risultati coinci-dente con l’MNRE richiesto dal padre.
Le operazioni intraprese da ciascun nodo possono essenzialmente essere riassunte nei seguenti punti:
• Calcola un adeguato talk interval da indicare ai propri figli (tenendo conto anche di eventuali ritrasmissioni)
• Se durante un talk interval ha ricevuto un numero di messaggi suffi-ciente può informare di questo i propri figli ed esortarli a non inviare ( durante quel medesimo talk interval) altri messaggi relativi a quella interrogazione.
• Se il numero di risultati ricevuti durante un talk interval è superiore alla soglia minima allora può decidere di non inoltrare tutti i mes-saggi verso il Sink ma può eliminarne in locale alcuni (di solito scelti in modo random).
• Se il numero di risultati ricevuti in un talk interval è accettabile allora il nodo può decidere di non inviare eventuali nack ai propri figli an-che a fronte di messaggi ricevuti non correttamente
La Figura 5.12 riporta un possibile sviluppo dell’esempio introdotto sopra. Nella Figura 5.12-a è riportato l’invio dei risultati da parte dell’ultimo livello dell’albero: i nodi 8,9,10 inviano i propri rilevamenti ai relativi padri. Man mano che i risultati risalgono i livelli dell’albero (Figura 5.12-b,-c,) è possi-bile vedere come alcuni messaggi possono essere eliminati dai nodi pa-dre. Infine, nella figura -d vediamo che i risultati che arrivano al nodo Sink
sono quelli relativi ai rilevamenti effettuati dai nodi 8,10,6,5,2,3 che rap-presentano un’istantanea ben distribuita dell’ambiente.
Per quanto riguarda le interrogazioni basate sugli eventi a queste viene associata un’alta affidabilità (R=1) perché in generale gli eventi segnalano un qualcosa di particolarmente importante ai fini dell’applicazione e quindi è necessario che le informazioni siano pervenute nella loro interezza al nodo Sink.
NODO PADRE NODI RAMO1 NODI RAMO 2 TOT. NODI 65% MNRE RAMO1 MNRE RAMO2 7 1 0 1 1 1 0 6 1 1 2 2 1 1 5 2 3 5 4 2 2 2 6 0 6 4 4 0 3 1 0 1 1 1 0 1 7 2 9 6 5 1 Tabella 5.2 MNRE
Un approccio particolare deve essere riservato alle interrogazioni di tipo aggregato in quanto l’importanza dei risultati trasmessi aumenta man mano che i risultati si avvicinano al Sink (in quanto un risultato aggregato è l’unione dei risultati di ogni singolo nodo). è quindi necessario aumentar il livello di affidabilità man mano che i risultati risalgono i livelli dell’albero. Ciascun nodo padre cerca di inviare verso il Sink il numero minimo di ri-sultati richiesto; può anche capitare che in un talk interval un nodo padre raccolga un numero di risultati insufficiente ai fini della reliability; in questi casi il nodo cercherà di adattare il talk interval dei communication period successivi in modo da raggiungere il livello necessario (in questo caso aumentando il talk interval).
5.12
Decisione del Periodo di
Campionamento
Indicando con sample communication period il minimo sample period im-posto dalle interrogazioni attualmente attive sulla rete è necessario, affin-ché il protocollo di scheduling funzioni correttamente, che gli altri sample period siano multipli interi del sample communication period. Questo com-porta una inefficienza dal punto di vista applicativo ma che la maggior parte delle volte risulta trascurabile ai fini dell’applicazione stessa.
Un’ulteriore approssimazione che deve essere effettuata è quella di rag-gruppare tutti i rilevamenti pochi istanti prima dell’inizio del Talk Interval in
modo che i risultati siano pronti per essere inviati durante il talk interval
successivo.
La Basestation indica, per ogni interrogazione che viene iniettata nella rete, un sample period che è multiplo del sample communication period. Ciascun nodo, ricevuta l’interrogazione, effettua delle verifiche per con-trollare che il proprio livello energetico sia compatibile con il sample period indicato nell’interrogazione ed in caso di esito negativo sceglie un sample period multiplo di quello indicato nell’interrogazione stessa ed informa il proprio padre della decisione.
1 3 2 4 5 6 7 8 9 10 1 1 1 1 3 2 4 5 6 7 8 9 10 1 1 1 2 2 2 2 1 3 2 4 5 6 7 8 9 10 4 4 1 1 1 3 2 4 5 6 7 8 9 10 5 1 5 1 (a) (b) (c) (d) Figura 5.12 Reliablity
5.13
Sincronizzazione
Nelle applicazioni di monitoraggio è necessario poter attribuire un ordine cronologico ai risultati che periodicamente sono inviati dai Nodi Sensore verso il nodo Sink. Quindi, per poter affermare che la rilevazione effettuata dal nodo x è precedente a quella effettuata dal nodo y, occorre che gli orologi di tutti i nodi della rete siano sincronizzati tra loro consentendo quindi un ordinamento temporale dei campioni e degli eventi.
Inoltre, la sincronizzazione tra i nodi della rete è indispensabile per far funzionare il protocollo di scheduling descritto in precedenza. I nodi de-vono essere coordinati in modo che la comunicazione tra due nodi adia-centi avvenga quando entrambi sono attivi evitando così l’invio inutile (e il conseguente spreco di energia) di messaggi. Nella Figura 5.13 viene illu-strato come una cattiva sincronizzazione porti ad una comunicazione er-rata tra i nodi (Figura 5.13-a) mentre una accuer-rata sincronizzazione renda la comunicazione efficace (Figura 5.13-b).
1 3 2 NODO1 NODO2 NODO3 NODO1 NODO2 NODO3 (a) (b) Figura 5.13 Sincronizzazione tra Nodi Sensore
Per provvedere una sincronizzazione i nodi della rete devono periodica-mente scambiarsi dei messaggi: la frequenza dei messaggi di
sincroniz-zazione dipende dall’ accuratezza con cui vogliamo coordinare gli orologi dei nodi (è possibile arrivare ad avere un errore dell’ordine di 2 µs).
Ogni messaggio inviato contiene un timestamp che però non può essere inserito dal livello applicativo a causa del fatto che un pacchetto può su-bire ritardi non trascurabili prima della trasmissione vera e propria (il MAC protocol può ritardare la trasmissione di un pacchetto a causa della con-tesa sul canale e dei vari backoff period). È quindi il MACprotocol a inse-rire il timestamp corretto prima dell’invio del pacchetto.
Per una dettagliata e precisa descrizione dei protocolli di sincronizzazione applicabili ad una Rete di Sensori fare riferimento a [Mills] e [Elson].