Capitolo 1
La Visione per veicoli autonomi
1.1 La Computer Vision: caratteristiche principali
La Computer Vision (mal traducibile in italiano come “Visione mediante computer”, pertanto nel seguito si preferirà utilizzare la dicitura in Inglese) è quella materia che si occupa di studiare le varie tecniche che riguardano la rielaborazione delle immagini provenienti da uno o più dispositivi atti a raccoglierle (come videocamere), al fine di poterne estrarre le informazioni di interesse in diversi settori applicativi.
Anche se esistono lavori precedenti, è a partire dalla fine degli anni ‘70 che è iniziato uno studio più accurato in questo campo, nel tempo la crescente velocità di calcolo dei computer ha agevolato l’analisi e il processo di grossi volumi di insieme di dati, come le immagini.
La maggiorparte di questi studi hanno origine spesso in campi applicativi molto diversi tra loro, percui non esiste né uno standard della formulazione del “problema della Computer Vision”, né esiste uno standard
su come risolvere i problemi di “Computer Vision”. Tuttavia, esiste una vasta gamma di metodi per risolvere problemi specifici ben definiti, implementabili attraverso task di Computer Vision molto specifici, raramente generalizzabili su range di applicazioni più ampi. Molte di queste tecniche e applicazioni sono ancora nello stato base di ricerca, invece altre sono già largamente utilizzate in molti prodotti commerciali, dove spesso costituiscono una parte di un sistema più vasto che risolve task più complessi (per esempio nell’area delle immagini mediche o nel controllo della qualità o nelle misure di processi industriali).
La Computer Vision può essere vista come un sottocampo dell’ Artificial Intelligence (Intelligenza Artificiale) dove i dati immagine vengono forniti a sistemi, in alternativa a input basati su testo, per controllare il comportamento di un sistema.
Dato che una videocamera può essere vista come un sensore di luce, esistono molti metodi nella Computer Vision, basati sulla corrispondenza tra fenomeni fisici legati alla luce e immagini di quel fenomeno. Pertanto la Computer Vision è strettamente legata alla Fisica, dato che assume un ruolo fondamentale lo studio del processo fisico che da uno scenario di oggetti, sorgenti di luce, attraverso lenti delle videocamere forma l’immagine nella videocamera.
Un altro settore che assume un ruolo importante per la Computer Vision è lo studio del sistemi di Visione Biologica. Grazie agli studi estensivi di occhi, neuroni, e le strutture del cervello devolute al processo degli stimoli visuali sia per gli uomini che per gli animali, si è giunti a una descrizione grossolana, ma piuttosto complicata, di come opera un sistema di visione reale per risolvere certi compiti legati alla visione. Questi studi guidano un sottocampo della Computer Vision dove sistemi artificiali vengono progettati per imitare i processi e il comportamento dei sistemi biologici, a diversi livelli si complessità. Inoltre molti metodi sviluppati nella Computer Vision hanno il loro background nella Biologia.
Anche l’Analisi dei Segnali è strettamente legata alla Computer Vision, perché molti metodi per l’analisi di segnali a 1variabile possono essere estesi a quelli a 2 variabili o multivariabili, come le immagini.
La Computer Vision e l’Analisi delle immagini (digitali) sono campi strettamente legati. La distinzione tra le due non è molto chiara, anche perché la prima fa largo uso dei metodi tradizionalmente appartenenti alla seconda. Una distinzione formale tra le due potrebbe essere basata sulla constatazione che l’Analisi delle Immagini si occupa di trasformare le immagini, producendo un immagine da un’altra o producendo informazioni a basso-livello sull’immagine, come contorni e linee. Nessuno di questi task provvede o richiede un interpretazione su ciò che compare nell’immagine in termini di oggetti o eventi. La Computer Vision, invece, usa modelli e supposizioni sul mondo reale raffigurato nelle immagini per estrarre informazioni che possono essere usate per il controllo di azioni rispetto a (o sugli) oggetti nella scena.
Uno dei sottocampi fondamentali della Computer Vision è dedicato all’aspetto dell’implementazione: come i metodi esistenti possono essere realizzati in varie combinazioni di software e hardware o come questi metodi possono essere modificati in modo da migliorarne la velocità senza perdere troppo in performance.
1.2 La Computer Vision nel Campo dell’Automazione
I scopi di questo lavoro di tesi portano a focalizzare l’attenzione sulla Computer Vision nel settore dell’Automazione per veicoli autonomi (Autonomous Vehicle, AV).
Gli AV vengono oramai largamente utilizzati sia per eseguire dei processi di routine per l’industria, sia per svolgere compiti particolarmente azzardati per l’uomo e non solo. La Machine Vision (Visione attraverso le macchine) tenta di “donar la vista” ai veicoli, al fine di capire il loro ambiente circostante, consentendo un uso più flessibile degli stessi. [3]
Nel 2003 AIA (Automated Immagine Assotiation) [4] ha stimato il volume d’affari dell’intera industria della Computer Vision aggirarsi intorno ai 6.6 bilioni di dollari (con un aumento del 14% rispetto al 2002). Una grossa porzione di questa somma si riferisce poi agli investimenti specifici nel campo dell’Automazione, come è possibile rilevare, ad esempio dai dati forniti da David Lowe nel suo sito [6].
Tuttavia, anche se la velocità e la potenza dei calcolatori è in continua crescita, la Ricerca è ancora molto lontana da riuscire a processare le immagini come è in grado di fare il genere umano. Il cervello umano è in grado di analizzare gli elementi 10 volte più lentamente che i chip digitali, eppure in tempo reale, grazie a una qualche elaborazione parallela e grazie ad un largo uso di astrazioni gerarchiche (anche se tale fenomeni ancora non sono chiari).
Cercando di schematizzare la visione umana, questa consiste di due sensori di visione (gli occhi), i quali lavorano in stretto legame con un interprete, il cervello. Entrambi devono essere replicati per dotare le macchine di una capacità visiva. Fortunatamente la maggiorparte delle applicazioni industriali non richiedono di coprire il vasto panorama della sensitività della visione umana, ad esempio, spesso è sufficiente riconoscere solo la sagoma di un oggetto.
I sensori maggiormente utilizzati sono le videocamere, in un numero variabile a seconda degli scopi. In alcuni casi queste vengono affiancate da sensori come scanner laser, ma in questo ambito ci limitiamo all’uso esclusivo di videocamere.
I tre casi applicativi su cui si riversa la maggiorparte della Ricerca in campo Visuale-Automatico trattano [5]:
1. Rilevamento degli ostacoli (Obstacle Avoidance): La Visione stereo (tramite cioè 2 videocamere) consente agli AV di capire il loro ambiente di lavoro in 3 dimensioni. In questo modo è possibile ricostruire una mappa dell’ambiente libero da ostruzioni (Free Space Mapping) o, in maniera complementare, una mappa degli ostacoli rilevati (3D Depth Map), in modo che il veicolo autonomo
sia in grado di individuare una chiara traiettoria tra questi. I contorni dello scenario 3D, derivati attraverso la stereovisione, possono essere usati per la navigazione del veicolo e per la localizzazione e tracciamento degli oggetti conosciuti.
2. Esplorazione dell’ambiente sconosciuto circostante (Exploring New Surroundings): Se un veicolo guidato autonomo (AGV) si muove in un ambiente sconosciuto, deve essere in grado di riconoscerne le caratteristiche, intanto che procede. Un approccio prevede l’analisi delle immagini provenienti da una videocamera posizionate sulla parte anteriore del veicolo. Innanzitutto vengono estratte le feature come gli angoli (giunzioni a T e giunzioni a Y), che sono localizzate come l’AGV si muove sulla scena. Tali feature vengono scelte, perché il punto di intersezione delle linee che formano l’angolo viene fissato rispetto all’angolo da cui viene visto. Le feature vengono poi tracciate nella serie di immagini. Come l’AGV si muove, il moto apparente delle feature in questo campo di vista dipenderà dalla distanza. Infatti dalla traiettoria delle feature dell’immagine, la loro posizione 3D e il moto 3D dell’AGV possono venir stimati. Sovrapponendo una griglia sull’immagine può essere definita una regione in cui guidare il veicolo.
3. Sorveglianza di ambienti conosciuti (Surveillance): I veicoli utilizzati sono dotati di un meccanismo per localizzare la loro posizione relativa all’ambiente circostante. Il calcolo esatto della posizione dell’AV è essenziale per la performance sicura e efficace dei task. E’ importante monitorare i movimenti dell’ AV e mettere in relazione queste informazioni con la stima che l’AV possiede della sua posizione. Alcuni sistemi usano 4 videocamere per rilevare l’ambiente di lavoro. L’immagine di ciascuna videocamera viene usata per identificare gli oggetti/ostacoli sottraendo l’immagine ricevuta rispetto ad una immagine di riferimento che
raffigura l’ambiente di lavoro “vuoto”. I dati dalle quattro videocamere vengono fuse per ottenere una locazione precisa. Gli oggetti, ad esempio le persone, possono essere riconosciute da un AV, facendo uso di modelli che descrivano le feature caratteristiche.
In questo a lavoro di tesi ci limitiamo a prendere in considerazione il solo primo caso (Obstacle avoidance) trattandosi appunto dello scopo principale dello studio svolto.
1.3 Sensori di Visione: la videocamera
1.3.1 Vantaggi
La scelta di un sensore di tipo videocamera per la realizzazione di un Sistema di Visione è motivata dai parecchi vantaggi che ne derivano; i principali risultano:
● Sensore passivo (passive sensor): Non è possibile rilevare la presenza del sensore dal momento che misurano l’ambiente senza nessun tipo di contatto ed è necessaria poca potenza per l’uso; diversamente da ciò che accade qualora si scelgano sensori attivi, ad esempio come il laser o radar.
● Dimensioni: Esistono videocamere in commercio anche molto piccole, il ché non dà problemi anche in caso di miniAV o microAV (veicoli autonomi di ridotte dimensioni).
● Costo: Il costo di una videocamera è divenuto oramai molto contenuto, neanche lontanamente paragonabile rispetto alla maggiorparte degli altri sensori, come laser o radar. Per tante applicazioni di visione non è necessaria neanche un’alta risoluzione e risulta possibile far uso addirittura di webcam.
● Ricchezza di informazioni e facilità di interpretazione per un utente: In molte applicazioni, anche una sola videocamera fornisce
informazioni sufficienti e persino intuitive, nel caso sia necessario un interfaccia con un utente umano.
Nel seguito si entrerà nel dettaglio del funzionamento di tale dispositivo, in particolare dal punto di vista geometrico.
1.3.2
Il modello di proiezione della videocamera
Una videocamera contiene al suo interno una lente che forma una proiezione 2D della scena sul piano immagine, dove è posto il sensore (in genere CCD).
Nel seguito con il termine videocamera (camera), piuttosto che il dispositivo fisico in sé, intenderemo la trasformazione di proiezione che vi è legata: i punti del mondo 3D (object space) diventano punti 2D sul piano immagine. Questo comporta la perdita di informazione della profondità della scena, perché un punto sul piano immagine corrisponde ad una retta intera della scena 3D. La conoscenza della geometria del processo di acquisizione delle immagini diventa essenziale, in modo che le informazioni provenienti dalle telecamere possano essere “fuse” con le misure provenienti da altri sensori al fine del controllo del veicolo o del robot.
Per descrivere la geometria che regola il funzionamento di una videocamera, in particolare ci riferiremo al modello pinhole a proiezione centrale (central projection). [1, 2]
Una volta che vengono fissati il sistema di riferimento della videocamera (con origine nel centro di proiezione, detto anche centro della videocamera), il piano individuato da Z=f, viene chiamato piano immagine (image plane o focal plane), mentre f viene chiamata lunghezza focale (focal lenght). Nel modello pinhole un punto nello spazio P di coordinate
[
]
TZ
Y
X
P
=
, nel sistema di riferimento della videocamera, si proietta sulpiano immagine posto a attraverso una proiezione perspettiva (perspective projection) alla locazione
[
]
Ty x
intersezione sul piano immagine della retta che collega il punto P al centro di proiezione.
Si chiama asse ottico o asse principale, l’asse che attraversa il centro di proiezione, ortogonale al piano immagine. Questo asse interseca il piano immagine sul punto
[
]
TY X
c
c
c
=
0
(nel sistema di riferimentodell’immagine) chiamato punto principale.
La figura 1.1 mostra l’operazione di proiezione. I due sistemi di coordinate sono il sistema di riferimento sulla videocamera di origine OC,
Camera frame, (rispetto al quale si esprimono le coordinate 3D del punto) e il sistema di riferimento sul piano immagine di origine OI, Image frame,
(rispetto al quale si esprimono le coordinate in pixel). Gli assi XC e xI hanno
stessa direzione ma sono scalati l’uno rispetto all’altro a seconda della lunghezza focale f (espressa in pixel). Lo stesso rapporto intercorre anche tra gli assi YC e yI .
Per triangoli simili,come da figura 1.1, se si considera l’origine del sistema di riferimento sul piano immagine coincidente con il centro ottico, anziché sull’angolo in alto a sinistra, il punto
[
]
TZ
Y
X
X
=
risulta mappatosul punto
x
sul piano immagine, le cui coordinate si esprimono come:⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ = Z Y f Z X f
x per cui la funzione proiezione centrale dal mondo alle coordinate
sull’immagine si esprime come:
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ ℜ ℜ Z Y f Z X f Z Y X a a 2 : 3 (1.1)
L’espressione (1.1) non è del tutto corretta, in quanto scegliendo la terna di riferimento sull’immagine come in figura 1.1, bisogna considerare un offset per il punto principale:
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ + + ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ ℜ ℜ Y X c Z Y f c Z X f Z Y X a a 2 : 3 (1.2)
Figura 1.1 L’operazione di proiezione
Quando i pixel non sono quadrati, la lunghezza focale deve essere espressa usando larghezza e altezza di un pixel come unità di lunghezza: fx
e fY . Le coordinate del punto proiettato sono in questo caso:
Camera Frame Image frame XC ZC YC P f x
X
yI OI OC c Asse principale Centro della videocamera OC YC ZC Z Y f f Y/Z c xI⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ + + = Y Y X X c Z Y f c Z X f x{1,2} (1.3)
Questo ultimo vettore dà precisamente la posizione del punto proiettato sull’immagine in pixel, quando si ha una pinhole camera ideale. Le videocamere reali non hanno pinhole ma lenti, che introducono una certa distorsione dell’immagine, percui il punto proiettato risulta in una posizione leggermente diversa x~. Un semplice modello del primo ordine della distorsione introdotta da una lente è il modello di distorsione radiale:
⎪
⎪
⎪
⎪
⎩
⎪
⎪
⎪
⎪
⎨
⎧
⎥
⎦
⎤
⎢
⎣
⎡
+
+
=
⎥
⎦
⎤
⎢
⎣
⎡
=
+
=
⎥
⎥
⎦
⎤
⎢
⎢
⎣
⎡
=
y y x x y xc
b
c
b
b
b
a
k
a
b
Z
Y
Z
X
a
y x 2f
f
x~
)
1
(
distorsione radiale (1.4)dove k è chiamato coefficiente di distorsione radiale.
Alcuni di questi parametri costituiscono i coefficienti della cosiddetta matrice di calibrazione della videocamera, la quale contiene appunto i parametri intrinseci della videocamera:
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ = 1 0 0 0 Y Y x X c f c f K
α
(1.5) dove:● fx e fy sono la lunghezza focale espressa in pixel secondo la
dimensione dei pixel lungo XI e YI
● cx e cy sono le coordinate del punto principale sul frame del piano
immagine
● α è lo skew, l’obliquità, l’angolo tra gli assi XI e YI in pixel.
Non compaiono nella matrice di calibrazione ma fanno parte comunque dei parametri intrinseci di una telecamera, i parametri che rappresentano la distorsione (radiale e tangenziale).
1.4 La Stereo-Visione e Geometria Epipolare
Grazie alla vista di una scena mediante l’uso coordinato di più videocamere montate su uno stesso veicolo è possibile ricostruire la profondità 3D. A questo scopo sono sufficienti due videocamere, ciascuna delle quali funge da sensore di vista analogamente alla “vista umana”; è in questo senso il nome di Visione Stereo (Stereo Vision). In questo lavoro di tesi ci si restringe al caso di un Sistema di Visione i cui sensori siano appunto 2 videocamere montate a distanza prestabilita e giacenti alla stessa altezza da terra. In altri termini si supporrà che:
● La distanza tra le due telecamere sia fissa e nota.
● La matrice di rototraslazione tra le due videocamere sia nota. ● La vista dai due sensori di visione sia non eccessivamente diversa
una dall’altra (approccio classico).
● Parametri intrinseci delle telecamere molto simili.
La tipica configurazione stereo utilizzata è quella nominata parallel cameras, (vedi figura 1.2) in cui:
● I due piani immagini sono disposti in verticale e sono coplanari nello spazio
● Le due telecamere hanno identica lunghezza focale e sono separate solo lungo l’asse X da una distanza di Baseline B.
Si chiama coppia di coniugati (conjugate pair) la coppia delle due proiezioni di un medesimo punto sulla scena nei due piani immagini; in figura 1.2 vengono indicati con pL e pR.
In questo caso ideale, le informazioni sulla profondità si ottengono considerando che le proiezioni della coppia di coniugati risultano di coordinate solo leggermente diverse, in particolare la coordinata (verticale) Y della proiezione del punto sui due piani immagini è la stessa, invece la coordinata X varia di poco; la differenza delle due coordinate lungo X si chiama disparità (disparity).
Figura 1.2 Parallel cameras: La proiezione su videocamere Stereo
Il piano che passa per i centri delle due videocamere e il punto sulla scena è chiamato piano epipolare. L’intersezione tra un piano immagine e il piano epipolare si chiama linea epipolare. La Geometria Epipolare è appunto la geometria proiettiva intrinseca tra due differenti viste.
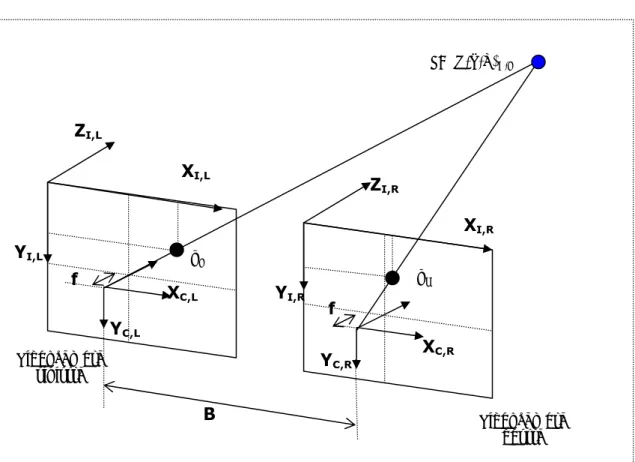
La figura 1.3 mostra nel dettaglio il piano epipolare, in cui giacciono le rette che collegano il punto nello spazio della scena 3D (indicato in blu e con coordinate espresse rispetto al frame della videocamera sinistra) con i rispettivi centri delle due videocamere e la relativa baseline, e le linee epipolari, eviedenziate in rosso.
In realtà, a causa della naturale distorsione delle immagini da video e della geometria imperfetta, è necessario considerare anche una leggera disparità verticale delle proiezioni.
ZI,L ZI,R XI,R YI,R XI,L YI,L P=(X,Y,Z)C,L f f YC,L XC,L XC,R YC,R B Videocamera sinistra Videocamera destra pL pR
Figura 1.3 Parallel Cameras:Geometria della Visione Stereo bioculare
Definiremo più appropriatamente la disparità come la distanza tra i punti di una coppia di coniugati se le due immagini venissero sovrapposte.
La configurazione di tipo parallel cameras, fin qui analizzata, risulta di difficile realizzazione pratica, in tutti i casi in cui si abbia a che fare con un veicolo “prototipale” o nei casi in cui le due videocamere siano indipendenti e montate in configurazione stereo . Per queste ragioni si può fare riferimento ad una configurazione stereo generica, che in seguito si indicherà semplicemente come configurazione stereo, in cui:
● I due piani immagini sono disposti in verticale e non sono coplanari nello spazio
● Le due telecamere hanno identica lunghezza focale e sono separate solo lungo l’asse X da una distanza di Baseline B.
ZI,L ZI,R XI,R YI,R XI,L YI,L P=(X,Y,Z)C,L B Videocamera sinistra Videocamera destra pL pR Piano Epipolare Linee Epipolari assi ottici
Dal momento che la geometria proiettiva dipende solamente dai parametri interni alle videocamere e alla posizione relativa l’una rispetto all’altra, le definizioni di piano epipolare e di linea epipolare rimangono invariate; la figura 1.4. mostra un esempio. I centri delle videocamere, il punto nello spazio 3D P e le sue proiezioni pL, pR, giacciono sullo stesso
piano (epipolare). Se un punto dell’immagine pL viene proiettato all’indietro
nello spazio 3D, questo corrisponde ad un raggio definito dal centro della telecamera sinistra e il punto stesso. Tale raggio di punti si proietta come una linea lR nel secondo piano immagine (piano immagine destro nella
figura 1.4): la proiezione di P sulla seconda immagine (immagine destra) è un punto che appartiene a tale linea (epipolare).
Figura 1.4 Stereo Cameras:Geometria epipolare della Visione Stereo bioculare
Si chiama epipolo (epipole) l’intersezione della linea che congiunge i centri delle videocamere (baseline) con il piano immagine. Allo stesso modo, l’epipolo è la vista del centro dell’altra videocamera dell’altra vista. L’epipolo cosituisce anche il punto di fuga della direzione di traslazione della baseline.
Tutte le linee epipolari si intersecano all’epipolo del piano immagine. Ciascun piano epipolare interseca il piano dell’immagine sinistra e il piano
P Piano Epipolare OC,R OC,L pR pL P P’ P’’ eR eL pR pL lR lL
dell’immagine destra lungo le linee epipolare e definisce le corrispondenze tra le linee.
Grazie alla possibilità di poter caratterizzare algebricamente la geometria che regola le proiezioni di un punto nello spazio 3D sui due piani immagini, ovvero la Geometria Epipolare, è possibile calcolare agevolmente la profondità del punto dai piani delle due videocamere, come si vedrà più dettagliatamente in seguito.
Una volta che la posizione e l’orientazione delle due videocamere è nota, resta da risolvere il problema della stereopsi (stereopsis): trovare le due proiezioni sui due piani immagini che corrispondono allo stesso punto 3D. Questo aspetto è noto come il problema delle corrispondenze (correspondence problem) e sarà l’argomento del capitolo successivo.
1.5 Approccio al problema dell’Obstacle Avoidance
In generale la visione e l’azionamento che deriva dai sottosistemi atti a questi scopi si combinano insieme secondo un modello open-loop del tipo looking-then-moving. L’accuratezza del risultato dell’operazione dipende strettamente dalla precisione dei sistemi di visione (nel caso dei robot anche dall’accuratezza dell’end-effector).
La base di tutto il processo di Obstacle Avoidance diventa il processo che porta all’identificazione di un oggetto presente sulla scena del veicolo in movimento può essere schematizzato a passi, come segue:
1. Rielaborazione del contenuto informativo delle immagini (Tracking): Le immagini provenienti dalle due telecamere al medesimo istante vengono rielaborate secondo opportune tecniche in modo da estrarne in entrambe i tratti fondamentali che identificano gli oggetti rappresentati.
2. Ricerca di corrispondenze fra le immagini (Matching): Per ciascun istante i tratti distintivi (rilevati al passo precedente) di un’immagine
(ad esempio la sinistra) devono poter trovare un corrispettivo nell’altra immagine (la destra).
3. Localizzazione delle corrdipondenze sullo spazio 3D (Depth Estimation): Dal momento che ciascun tratto distintivo individua una caratteristica di un oggetto nello scenario, qualora si rilevi una corrispondenza di un tratto distintivo tra immagine sinistra e immagine destra, è anche possibile risalire, tramite la geometria che regola le proiezioni, alla posizione 3D di quella caratteristica dell’oggetto.
4. Raggruppamento di più caratteristiche di un oggetto (Clustering): Più corrispondenze vicine spazialmente possono essere raggruppate in un unico insieme (cluster) in modo che esse identifichino lo stesso oggetto dell’ambiente di lavoro del veicolo. E’ possibile costruire così una mappa di profondità che rappresenti opportunamente gli ostacoli che compongono lo scenario in cui il veicolo si muove.
Gli studi finora compiuti offrono un vasto panorama su cosa definire e su come descrivere i tratti distintivi di un immagine. Ne riportiamo tre:
1. Utilizzo delle feature. Una feature non è altro che un pixel importante dell’immagine perché ingloba in sé caratteristiche rilevanti del punto dell’oggetto 3D di cui è la proiezione.
2. Utilizzo delle sagome. Si estraggono le sagome o i contorni degli oggetti.
3. Utilizzo di texture. Si estraggono dall’immagine piccole finestre di pixel, identificative della zona da cui sono state prelevate.
Gli algoritmi che ne derivano dipendono strettamente da tale scelta di base; si possono indicare sinteticamente con le tre categorie:
1. Algoritmi di tracking feature-based stimano la posizione degli oggetti basate sulla variazione delle feature degli oggetti in una sequenza di immagini. [10,11]
2. Metodi di contorni attivi modellano la sagoma di oggetti rigidi o non rigidi (deformabili) come curve parametriche che si muovono durante
il tracking minimizzando l’energia sotto l’influenza delle forze dell’immagine. [12]
3. Algoritmi basati sul flusso ottico (optical flow) coinvolgono il calcolo del campo di flusso ottico, da cui si possono estrarre le informazioni del moto dell’oggetto. [7-9]
Per quanto la scelta di una delle tre assunzioni non escluda l’altra, ovvero è possibile avvalersi di un uso combinato di feature e tessiture o feature e contorni, ad esempio, nel nostro caso si prenderà in considerazione solamente la prima possibilità. Pertanto si intenderà per feature un qualsiasi punto d’interesse dell’immagine e si analizzeranno tecniche basate sulla prima categoria.
Figura 1.5 Schema dell’approccio seguito per l’Obstacle Avoidance
1.Tracking delle feature
2.Matching
3.Calcolo della profondità
4. Aggiornamento e costruzione della mappa dell’ambiente (Clustering)
La figura 1.5 mostra schematicamente i passi che si considereranno per l’approccio al problema. L’ultimo passo che consiste nel clustering e la relativa costruzione della mappa non verrà presa in considerazione nel dettaglio di questo lavoro, in quanto ancora oggetto di studio da parte del gruppo di Ricerca.