Introduzione
11.
MPLS
3
1.1. Introduzione a MPLS 3 1.2. Elementi di un dominio MPLS 7
1.3. Forwarding Equivalence Class 10
1.4. Label Switching 11
1.4.1. Label Binding 15
1.4.2. Operazioni sulle label 15
1.5. Metodi per la distribuzione delle label 18
1.6. RSVP-TE 19
1.6.1. Funzionamento di RSVP 20
1.6.2. Estensioni presenti in RSVP-TE 23
1.7.1. Constraint Based Routing 26 1.7.2. Load Balancing 29 1.7.3. Priorità degli LSP 30 1.7.4. Fast Rerouting 31
2.
DiffServ
35 2.1. Introduzione a DiffServ 35 2.1.1. Funzionamento di DiffServ 36 2.1.2. PHB standard 38 2.2. DiffServ over MPLS 41 2.2.1. E-LSP 43 2.2.2. L-LSP 432.2.3. Estensioni di RSVP-TE per DiffServ over MPLS 44 2.2.4. Label Switching DiffServ 47
2.3. DiffServ-Aware MPLS Traffic Engineering 48
2.3.1. Scenari applicativi di DS-TE 49
2.3.2. Class-Type e TE-Class 52
2.3.3. Bandwidth Constraints Model 55
2.3.4. Unreserved Bandwidth 68
2.3.5. Estensioni da apportare ai protocolli 69
3.
Network Simulator 2
753.2. Simulazione ad eventi discreti 76
3.3. Network Simulator 2 77
3.3.1. Struttura di uno script NS2 80
3.4. MPLS Network Simulator 85
3.4.1. Script di esempio per il modulo MNS 90
4.
Moduli aggiuntivi per NS2
994.1. Modulo RSVP-TE\ns 100 4.1.1. LSP establishment 100 4.1.2. LSP release 101 4.1.3. Failure Handing 101 4.1.4. LSP recovery 102 4.2. Modulo OSPF-TE\ns 103 4.2.1. LSP establishment 105
4.2.2. LSP release e failure handling 106
4.2.3. LSP recovery 107 4.3. Modulo DBCTE\ns 107 4.3.1. LSP establishment 107 4.3.2. LSP recovery 109 4.4. Modulo EBMP e MPBF\ns 109 4.4.1. LSP establishment 110 4.4.2. LSP binding 111
4.5. Modulo algoritmi off-line\ns 112
4.6. Modulo P2MP\ns 113
4.7. Modulo DS-TE\ns 115
4.7.1. Definizione link DS-TE 116
4.7.2. LSP establishment 117
4.7.3. LSP release 118
4.7.4. LSP recovery 118
5.
Modulo RDM-GRDM\ns
1215.1. Comandi del simulatore 121
5.1.1. Configurazione dei parametri DS-TE 122
5.1.2. Creazione dei link 122
5.1.3. instaurazione degli LSP 124
5.2. Modifiche apportate al simulatore 125
5.2.1. Configurazione di BCM e TE-Class 125
5.2.2. Aggiunta della preemption all’agent RSVP 127
5.2.3. Comandi per la creazione dei link 129
5.2.4. Creazione degli LSP e procedure di routing 130
6.
Simulazioni
1376.1. Test di validazione MAM con preemption 137
6.2. Test di validazione RDM 145
6.3. Test di validazione G-RDM 153
6.4.2. Simulazioni 165
Conclusioni
183La nascita di nuovi tipi di applicazioni, che richiedono lo scambio di dati attraverso Internet in tempo reale, congiuntamente alla sempre maggiore richiesta di capacità trasmissiva hanno creato la necessità di sviluppare nuovi metodi per gestire in maniera più efficiente le risorse di rete e differenziare il traffico in modo da garantire ad ogni tipologia le prestazioni richieste. Di seguito vengono analizzate in dettaglio le architetture MPLS e DiffServ. MPLS fornisce un’infrastruttura di rete sulla quale è possibile utilizzare algoritmi avanzati di routing che tengano conto dello stato della rete durante le decisioni di instradamento, inoltre tramite l’uso dei circuiti virtuali il traffico può essere classificato e trattato differentemente a seconda della tipologia a cui appartiene. DiffServ è un’architettura in grado di fornire strumenti di gestione della qualità del servizio all’interno delle code dei singoli router.
Tramite l’unione di queste due tecnologie si può realizzare un’architettura in grado di gestire tutte le problematiche relative alla QoS.
Per valutare le prestazioni dell’architettura MPLS sono molto utili i sumulatori, in quanto, ad oggi, non esistono implementazioni di tale tecnologia su larga scala sulle quali sia possibile effettuare misure in condizioni di traffico reale. Proseguendo il lavoro del dipartimento di Ingegneria dell’ Informazione dell’università di Pisa, durante questo lavoro di tesi, sono state aggiunte nuove funzionalità al simulatore di reti NS2. Qiesto scritto è così organizzato:
• Nel primo capitolo viene presentata l’architettura MPLS ed alcuni dei principali protocolli che la compongono.
• Nel secondo capitolo viene desscritta l’architettura DiffServ e le modalità di integrazione con MPLS.
• Il terzo capitolo consiste in una breve introduzione al siulatore NS2
• Nel capitolo quattro sono brevemente descritti tutti i moduli, sviluppati dal dipartimento di Ingegneria dell’Informazione dell’università di Pisa, che sono stati aggionati, durante questo lavoro di tesi, per poter funzionare con la nuova versione di NS.
• Nel quinto capitolo sono descritte le nuove funzionalità inserite nel simulatore e come sono state realizzate.
• Infine, nel sesto capitolo vengono presentate le simulazioni effettuate con il nuovo simulatore e vengono analizzati i loro risultati.
1.1
Introduzione a MPLS
MPLS (Multiprotocol Label Switching) è una tecnologia, standardizzata da IETF, la cui definizione ha avuto origine dall’intensa attività condotta a partire dalla metà degli anni ’90 da diverse aziende manifatturiere nel settore del networking IP. L’obiettivo era quello di migliorare le prestazioni della tecnologia IP, con particolare riguardo al throughput dei router e al ritardo di commutazione dei pacchetti, utilizzando le soluzioni tipiche dell’ATM. L’approccio seguito consisteva nei seguenti principi:
• individuare, mediante un protocollo standard di routing (es. OSPF), i cammini tra due punti terminali all’interno della rete;
• identificare questo cammino mediante un’etichetta;
• effettuare la commutazione dei pacchetti esclusivamente mediante l’elaborazione della sola etichetta (label switching) e di tutto l’header del pacchetto IP.
La ragione di questo approccio risiedeva nel fatto che, all’epoca, la commutazione ATM, che adotta la tecnica label switching in modo nativo, era nettamente più veloce di quella IP che è invece basata sull’elaborazione degli indirizzi. A seguito di queste iniziative, a partire dal 1997, l’IETF ha proposto la creazione di un gruppo di lavoro avente come obiettivo lo sviluppo di uno standard comune denominato Multi Protocol Label Switching. La prima edizione di questo standard risale al gennaio 2001. Il termine Multi Protocol indica che la soluzione proposta in questo standard può essere applicata a qualsiasi protocollo di rete (IP, SNA, IPX, ecc.). In questo elaborato ci si riferirà esclusivamente al caso di supporto del protocollo IP che rappresenta l’applicazione di maggiore interesse della tecnica MPLS.
Nel corso degli stessi anni, mentre si sviluppavano i lavori di definizione dell’architettura MPLS, lo scenario tecnologico ha subito un’importante evoluzione con la diffusione di una nuova generazione di router IP che di fatto cancellavano il divario di prestazioni tra la tecnica ATM e quella IP dal punto di vista dei tempi di commutazione e del throughput. Tuttavia, nonostante questo mutamento tecnologico, la tecnica MPLS ha continuato a mantenere un ruolo chiave perché è in grado di fornire ad una rete IP, oltre ad un miglioramento delle prestazioni, una serie di funzionalità addizionali, quali:
• Supporto della qualità di servizio: una rete connectionless, come
ad esempio una rete IP, non è in grado di soddisfare in modo pienamente affidabile le richieste di trasferimento dati, garantendo determinati parametri di QoS. Una rete connection-oriented ha invece la possibilità di gestire in modo molto efficiente gli aspetti di QoS; la tecnica MPLS, consentendo di utilizzare una modalità di trasferimento connection-oriented in una rete IP, rende possibile la fornitura flessibile di servizi con prefissati livelli di qualità.
• Ingegneria del traffico: la tecnica MPLS consente l’instaurazione
di cammini in rete in modo da ottimizzare l’utilizzazione delle sue risorse. Questa funzione, normalmente indicata con il termine Ingegneria del traffico (Traffic Engineering – TE), non può essere realizzata, almeno in modo semplice, mediante le tecniche tradizionali di instradamento utilizzate nelle reti IP. La ragione di questo risiede nel fatto che nelle reti IP il traffico tra due punti segue sempre un’unica via, mentre con MPLS tra due punti può essere utilizzata una pluralità di cammini; i flussi di traffico possono essere quindi instradati utilizzando tutti i camini disponibili in modo da ottenere una distribuzione uniforme del traffico sulle risorse di rete e di conseguenza un miglioramento complessivo delle prestazioni di rete.
• Definizione di servizi evoluti: la tecnica MPLS consente di
definire reti private virtuali (Virtual Private Network – VPN) all’interno di una rete IP. Mediante questo servizio il traffico tra
punti d’accesso remoti può transitare in modo trasparente e completamente separato dagli altri flussi di traffico all’interno della rete IP con conseguenti vantaggi sia per la gestione della qualità del servizio che per i requisiti di sicurezza.
• Realizzazione di tecniche efficienti di riconfigurazione dei cammini in caso di guasto: la tecnica MPLS consente, al
momento dell’instaurazione di un cammino in rete, la predisposizione di cammini alternativi, detti di protezione o di back-up, da utilizzarsi in caso di guasto di uno o più tratte del cammino principale per re-instradare il flusso di traffico supportato da quest'ultimo; questa soluzione consente di raggiungere dei tempi di riconfigurazione dei cammini molto inferiori a quelli ottenibili utilizzando i normali protocolli di routing IP e praticamente comparabili con quelli tipici di tecniche a circuito come l’SDH.
Nello stack protocollare ISO/OSI, MPLS, è situato tra il livello data-link ed il livello network, tale classificazione è giustificata dal fatto che il suo meccanismo di instradamento dei pacchetti può essere considerato come una soluzione intermedia tra lo switching tipico del livello 2 e il routing di livello 3
Figura 1-1 Posizione di MPLS nello stack ISO/OSI
1.2
Elementi di un dominio MPLSUn dominio MPLS è un insieme contiguo di nodi detti LSR (Label Switching Router) che sono in grado di inoltrare i pacchetti in base alla label. Dalla figura nota che esistono due differenti tipologie di LSR:
• LER (Label Edge Router): questi LSR si trovano ai confini del
dominio (zona edge) e si occupano di processare il traffico IP in ingresso ed in uscita, assegnando le label ai pacchetti ed inserendoli nella struttura dati MPLS; per questo motivo i LER devono necessariamente supportare sia il label switching MPLS sia il routing IP; i LER vengono anche chiamati Ingress LSR e Egress
APPLICATION PRESENTATION SESSION TRANSPORT NETWORK DATA LINK PHYSICAL
MPLS
Stack ISO/OSI 7 5 4 3 2 1 6LSR rispettivamente se ricevono o trasmettono pacchetti esterni al dominio;
• Transit LSR: di questo gruppo fanno parte tutti gli LSR che non
hanno contatti diretti con l’esterno del dominio (zona core); non è necessario che i transit LSR supportino il routing IP;
Figura 1-2 Dominio MPLS
La struttura interna di un LSR è mostrata nella seguente figura
Transit LSR LER LER LER CORE EDGE
Figura 1-3 Struttura interna di un LSR
Essa è costituita da due parti principali:
• piano di controllo: contiene le procedure utilizzate per scambiare
informazioni di routing tra gli LSR e per convertire tali informazioni in una tabella di forwarding
• piano di forwarding: contiene le procedure utilizzate per estrarre
da un pacchetto le informazioni necessarie per identificare l’opportuno next hop nella tabella di forwarding
I nodi di un dominio MPLS che sono in grado di effettuare anche il forwarding dei tradizionali pacchetti IP, devono poter supportare i due tipi di routing. Per tale ragione, sia il piano di controllo che il piano di
Protocolli di routing IP Forwarding IP Forwarding MPLS Piano di controllo Protocolli di distribuzione delle label Piano di forwarding Scambio informazioni di routing Scambio informazioni di Label Binding Pacchetti IP in ingresso Pacchetti MPLS in uscita Pacchetti IP in uscita Pacchetti MPLS in ingresso
forwarding sono composti da due parti distinte, una per la gestione delle tradizionali funzioni di routing e forwarding IP e una per le nuove funzioni di routing e forwarding MPLS, come è mostrato in figura.
1.3
Forwarding Equivalence Class
In un dominio MPLS tutti i pacchetti in ingresso vengono classificati ed assegnati ad una determinata Forwarding Equivalence Class (FEC) cioè viene definito il modo in cui un gruppo di pacchetti verrà trattato durante l’instradamento. In altre parole, tutti i pacchetti IP che sono inoltrati sullo stesso percorso e ricevono lo stesso trattamento da parte dei router (ad esempio vengono inseriti nella stessa coda di uno scheduler) appartengono alla stessa FEC. Allo stesso modo potrebbero appartenere ad una stessa FEC tutti i pacchetti il cui indirizzo di destinazione presenta lo stesso prefisso di rete. Il traffico può essere aggregato in una FEC a diversi livelli di granularità: ad esempio è possibile avere una granularità grossa (coarse granularity) aggregando nella stessa FEC tutti i pacchetti IP aventi in comune l’indirizzo di rete di destinazione, oppure avere una granularità più fine (fine granularity) come, ad esempio, nel caso in cui si considerano i numeri di porta o alcune caratteristiche del traffico per effettuare la classificazione. Più è grossa la granularità più aumenta la scalabilità del sistema, poiché c’è un minore numero di aggregati da gestire. Viceversa con una granularità più fine è possibile offrire servizi migliori intermini di QoS. E’ dunque necessario, per ottenere un buon compromesso tra scalabilità e flessibilità in termini di QoS, avere a disposizione un ampio ventaglio di
FEC avviene solo all’ingresso del dominio MPLS, semplificando di molto la procedura di inoltro nei router intermedi. In questo modo il sistema non solo risulta più veloce, ma anche più flessibile, in quanto l’assegnazione iniziale ad una FEC potrebbe risultare anche molto sofisticata, coinvolgendo più campi delle intestazioni protocollari, senza gravare sul carico computazionale dei nodi intermedi.
1.4
Label Switching
MPLS utilizza, per l’inoltro dei pacchetti, un metodo tipico delle reti connection-oriented: il label switching o commutazione di etichetta. Con questo metodo, i transit LSR, prendono decisioni sul next hop al quale inoltrare il pacchetto, basandosi esclusivamente sul valore della label. Il percorso effettuato dai pacchetti instradati tramite label switching all’interno del dominio MPLS prende il nome di LSP (Label Switched Path) ed è una “connessione virtuale” unidirezionale, questo implica che sono necessari due LSP per instaurare una comunicazione bidirezionale tra due nodi della rete. Ogni LSR sceglie il next hop consultando la tabella LFIB (Label Forwarding Information Base) nella quale ogni entry (chiamata NHLFE - Next Hop Label Forwarding Entry) contiene le associazioni tra:
• Label di ingresso
• Label di uscita
• Interfaccia di uscita
Quando un pacchetto IP arriva ad un ingress LSR viene assegnato ad una FEC mediante l’analisi dell' header IP. Dopo la classificazione l’ingress LSR, tramite la tabella FTN (FEC-to-NHLFE) assegna il pacchetto ad una particolare NHLFE e inserisce tra l’header di livello 2 e l’header di livello 3 l’header MPLS (detto anche Shim Header) il cui formato è riportato in figura e i cui campi sono i seguenti:
• label (20 bit): valore della label associata al pacchetto; • exp (3 bit): campo riservato ad utilizzi sperimentali;
• S (1bit): se settato ad uno indica che nel caso di label stacking la
label indicata è l’ultimo elemento della pila (maggiori dettagli sul label stacking verranno forniti nei successivi paragrafi);
• TTL (8 bit) analogo al campo TTL dell’header IP;
Figura 1-4 Header MPLS
Dopo aver inserito l’header MPLS, l’ingress LSR inoltra il pacchetto al next hop indicato dalla NHLFE corrispondente.
LABEL EXP S TTL
Ogni LSR ha una tabella chiamata ILM (Incoming Label Mapping) nella quale è indicata l’operazione che il LSR deve eseguire sui pacchetti ricevuti; mediante questa tabella è possibile differenziare il comportamento di un LSR a seconda che sia il nodo di destinazione di un pacchetto, l’egress LSR o semplicemente un transit LSR.
Quando un transit LSR riceve un pacchetto legge la label di ingresso, la sostituisce con la corrispondente label di uscita (label swapping), indicata nella NHLFE, ed inoltra il pacchetto al next hop tramite l’interfaccia di uscita. Se il pacchetto viene ricevuto dall’egress LSR, quest’ultimo si occupa di eliminare l’header MPLS e di inoltrare il pacchetto sulla rete IP.
Un esempio del procedimento di label switching è mostrato nelle seguenti figure
Figura 1-5 Esempio di Label Switching
IP 12 LSR A LSR B LSR C LSR D IP IP 5 IP 8 IP
LSR A
Incoming Prefix Outgoing Label
Outgoing
Interface Next Hop
112.246.0.0 12 0 B
LSR B
Incoming Label Outgoing Label Outgoing
Interface Next Hop
12 5 2 C
LSR C
Incoming Label Outgoing Label Outgoing
Interface Next Hop
5 8 1 D LSR D Incoming Label Outgoing Label Outgoing
Interface Next Hop
5 - 3 112.246.x.x
1.4.1
Label binding
La creazione delle associazioni tra classi di traffico e label può avvenire secondo due modalità:
• associazione remota: gli LSR ricevono istruzioni su come
associare classi e label dagli altri LSR;
• associazione locale: ogni LSR decide localmente come effettuare
le associazioni
Un’ulteriore classificazione può essere fatta in base ai criteri con cui vengono create le associazioni:
• modalità data-driven: gli LSR analizzano il traffico per decidere
come effettuare l’associazione
• modalità control-driven: le associazioni vengono stabilite in base
1.4.2
Operazioni sulle label
Ogni LSR effettua determinate operazioni sulle label a seconda del contenuto delle tabelle ILM, LFIB e FTN. Queste operazioni sono essenzialmente di tre tipi:
• swap: si sostituisce il valore della label in cima alla pila, con un
nuovo valore;
• pop: si elimina l’etichetta alla sommità della pila; • push: si inserisce una nuova etichetta nella pila;
tramite queste operazioni MPLS è in grado di utilizzare alcuni particolari meccanismi per lo switching dei pacchetti: label stacking, penultimate hop popping, label merging.
Label stacking
Un pacchetto può contenere più di una label. All’interno dello shim header, le label vengono organizzate in una pila di tipo LIFO (Last In First Out). Durante l’instradamento dei pacchetti, le decisioni vengono prese esclusivamente basandosi sulla label più esterna della pila, questo permette di non avere impatti significativi sulle prestazioni del sistema, anche in caso
di label stack con molti elementi. Grazie al label stacking è possibile realizzare, in modo trasparente, dei tunnel all’interno del dominio MPLS.
Penultimate hop popping
Normalmente, quando un pacchetto MPLS arriva ad un LSR che è direttamente collegato alla sua destinazione, quest’ultimo deve eseguire l’operazione di pop sulla label stack ed inviare nuovamente il pacchetto a se stesso. A questo punto , se la label eliminata era l’ultima dello stack, il router processerà il pacchetto secondo il meccanismo di routing di livello 3, altrimenti eseguirà le procedure di label switching considerando la nuova etichetta in cima alla lista.
Per evitare la doppia elaborazione del pacchetto da parte del router di destinazione, si utilizza il “penultimate hop popping”, meccanismo secondo il quale il penultimo LSR (quando realizza che il router a cui dovrà inviare il pacchetto è la destinazione del pacchetto stesso) esegue l’operazione di pop prima di inoltrare il pacchetto.
Label merging
Il meccanismo di “label merging” consente di aggregare più flussi mediante l’associazione, all’interno di un LSR, di una sola label di uscita a diverse label di ingresso.
1.5
Metodi per la distribuzione delle label
Il compito di distribuire, tra gli LSR, le informazioni riguardanti le associazioni label-FEC può essere svolto da alcuni protocolli:
• LDP (Label Distribution Protocol) • CR-LDP (Constraint Routing – LDP)
• RSVP-TE (Resource reSerVation Protocol – Tunnel Extensions)
LDP e CR-LDP[4] sono stati sviluppati in ambito IETF dagli stessi autori di MPLS; mentre RSVP-TE [7] è stato sviluppato come estensione (inserendo il supporto per il Traffic Engineering) del protocollo RSVP utilizzato per la prenotazione delle risorse della rete in ambito IntServ. Allo stesso modo CR-LDP è una estensione di LDP che aggiunge le funzionalità necessarie per realizzare Traffic Engineering.
Anche se, CR-LDP e RSVP-TE, dal punto di vista delle funzioni che possono svolgere sono equivalenti, esistono alcune differenze tra i due protocolli che hanno portato a privilegiare RSVP-TE come protocollo da utilizzare nella procedura di standardizzazione di MPLS [9].
L’architettura MPLS prevede due modalità di distribuzione delle label ed entrambe sono indipendenti dal protocollo utilizzato:
• downstream on demand: in questa modalità gli LSR devono richiedere esplicitamente, agli altri LSR, quale label è associata ad una specifica FEC;
• unsolicited downstream: le associazioni FEC-label vengono automaticamente comunicate a tutti gli LSR che fanno parte di una sessione;
La prima modalità è utile per non sprecare capacità trasmissiva, mentre la seconda risulta più veloce nell’instaurazione degli LSP.
1.6
RSVP-TE
Mentre nell’architettura IntServ, il protocollo RSVP si occupa della prenotazione risorse relativa a microflussi di traffico, il protocollo RSVP-TE, in MPLS, agisce su TT (Traffic Trunk) cioè insiemi di flussi dati appartenenti alla stessa classe di servizio ed instradati sullo stesso LSP. Per i percorsi che i pacchetti dovranno seguire, RSVP si affida ai tradizionali protocolli di routing. Questa non è sicuramente la scelta migliore, poiché il protocollo di routing IP calcola i percorsi esclusivamente minimizzando il numero di nodi da attraversare e non considerando altri parametri come ad esempio la banda gia occupata. Questo sistema tende a far congestionare il percorso più breve, mentre i percorsi più lunghi rimangono sottoutilizzati. Il problema appena descritto è stato risolto da RSVP-TE, che si basa invece sul Constraint Based Routing, analizzato più dettagliatamente in seguito, per decidere il percorso di un determinato LSP.
1.6.1
Funzionamento di RSVP
RSVP utilizza sette tipi di messaggio:
• PATH • RESV • PATH-TEAR • RESV-TEAR • PATH-ERR • RESV-ERR • RESV-CONF
In figura è mostrata la procedura di segnalazione e prenotazione di banda su una rete IP. La sorgente (nodo A) invia un Path Message alla destinazione (nodo D), il messaggio seguirà il percorso determinato dai protocolli di routing di livello 3.
Figura 1-7 Esempio di funzionamento di RSVP
Ogni router attraversato crea un PSB (Path State Block) nel quale memorizza i dati contenuti nel messaggio di path, tra cui i più importanti sono i seguenti:
• Previous hop: indicazione del nodo precedentemente attraversato; • Sender T-Spec: caratteristiche del traffico per cui si stanno
prenotando le risorse;
• Sender Template: indirizzo e numero di porta della sorgente; • Session Type: indica il tipo di sessione che si intende instaurare;
Il destinatario verifica se le risorse disponibili sono sufficienti a soddisfare le richieste della sorgente ed in caso affermativo risponde al messaggio ricevuto con un Resv Message diretto verso il mittente iniziale. I campi principali del messaggio resv sono i seguenti:
A F B E D C Path Path Path Resv Resv Resv
• Filter Spec: analogamente al Sender Template trasporta indirizzo e
porta del trasmettitore;
• Flow Spec: descrive il tipo di traffico ed il livello di QoS richiesto;
è composto dai seguenti elementi:
- Classe di servizio: identifica il tipo di servizio IntServ
richiesto (Guaranteed Service o Controlled Load);
- Rspec: indica la quantità di banda da prenotare;
- Tspec: descrive il profilo del traffico
Grazie alle informazioni trasportate dal campo “previous hop”, il messaggio resv è in grado di passare dai router attraversati dal messaggio path. In questi router vengono prenotate, se disponibili, le risorse specificate nel messaggio di resv. In ogni router attraversato vengono creati gli RSB (Reservation State Block) nei quali vengono memorizzate le informazioni contenute nel messaggio resv. Essendo RSVP un protocollo di tipo soft-state, il ricevitore dovrà periodicamente (tipicamente ogni 30 secondi) ritrasmettere il messaggio resv per mantenere valide le prenotazioni.
Quando una delle due terminazioni vuole rilasciare le risorse prenotate usa i messaggi Path-Tear e Resv-Tear. Questi messaggi eliminano rispettivamente i PSB e RSB; Il primo viene inviato dal mittente mentre il secondo dal destinatario.
I messaggi Path-Err e Resv-Err vengono generati dai router intermedi nei casi in cui si verificano errori durante la prenotazione o guasti e vengono
Il messaggio Resv-Conf viene inviato dal mittente al destinatario per la conferma dell’avvenuta prenotazione.
1.6.2
Estensioni presenti in RSVP-TE
La segnalazione necessaria alla creazione di un LSP utilizza gli stessi messaggi di RSVP, opportunamente estesi, con l’aggiunta del messaggio di HELLO, non presente nella versione originaria del protocollo.
All’ interno di un dominio MPLS (rappresentato in figura) supponiamo che l’ingress LSR A voglia creare un LSP esplicito verso l’egress LSR D. In tal caso A invia un messaggio di Path con session type LSP_TUNNEL al nodo successivo del percorso (LSR B).
Figura 1-8 Esempio di funzionamento di RSVP-TE
Di seguito vengono elencati alcuni dei nuovi oggetti che possono essere inclusi nel messaggio di path:
• LABEL_REQUEST: serve ad informare gli LSR nel percorso di
associare una label al TT in esame;
Path ERO = [B,C,D] Ingress LSR A Resv Label = 89 Path ERO = [C,D] LSR B LSR C Path ERO = [D] Resv Label = 57 Resv Label = 3 Egress LSR D
• ERO (EXPLICIT_ROUTE Object): contiene la lista degli LSR
da attraversare, nel caso in cui il sender abbia già calcolato il miglior percorso tramite il Constraint Based Routing;
• RECORD_ROUTE: che permette di registrare il percorso
effettuato;
• SESSION_ATTRIBUTE: contiene informazioni addizionali quali
preemption, priorità, protezione e diagnostica.
Alla ricezione del messaggio , il nodo B verifica la correttezza del formato e la disponibilità di banda (operazioni di Admission Control) e, se l’esito del controllo è positivo, crea al suo interno il PSB, in cui memorizza tutte le informazioni necessarie già viste nel caso di RSVP. Esso quindi genera a sua volta un nuovo messaggio di Path e lo invia all’LSR successivo nell’ERO (nell’esempio LSR C), dopo aver modificato l’oggetto Explicit_Route eliminando il proprio identificativo.
Il nodo C esegue le stesse operazioni svolte da B e quindi invia al successivo LSR un messaggio di Path contenente un ERO che include il solo identificativo di D. A questo punto D, riconoscendo di essere l’egress LSR dell’LSP, invia all’interfaccia da cui ha ricevuto il messaggio di path un messaggio di Resv contenente un nuovo oggetto, denominato LABEL, dove viene scritta l’etichetta MPLS associata al traffico dell’LSP in esame. La stessa operazione viene svolta dagli altri LSR, al ricevimento del messaggio di resv. Quando infatti C riceve il messaggio, prende la label contenuta nel Label object e la usa come label di uscita per l’LSP; quindi crea una nuova label e la pone nel Label object del resv message che
informazioni estratte dal resv all’interno del RSB. La propagazione del messaggio avviene hop-by-hop ed ogni nodo attraversato sostituisce la label ricevuta con quella determinata localmente, quindi aggiorna le tabelle ILM e NHFLE, necessarie per il label swapping.
L’LSR A, al ricevimento del messaggio di Resv, considera l’LSP instaurato. Tutte le tabelle FTN e ILM sono a questo punto pronte e può iniziare l’invio del traffico dati.
Prima di inoltrare il messaggio di Resv, ogni router deve controllare di avere le risorse necessarie per soddisfare la richiesta e verificare che la richiesta provenga da una sorgente abilitata. Se una delle due condizioni viene meno, il router manda verso l’egress node un messaggio di Resv-Err e la creazione dell’LSP viene interrotta.
In sintesi, i nuovi oggetti introdotti in RSVP-TE sono:
• LABEL_REQUEST
• LABEL
• EXPLICIT_ROUTE (ERO)
• SESSION_ATTRIBUTE
• RECORD_ROUTE
Oltre ai nuovi oggetti sono stati definiti anche nuovi tipi di “sotto-oggetti” per gli oggetti SESSION, SENDER_TEMPLATE, FILTER_SPEC e FLOWSPEC.
1.7
Traffic Engineering
Con Traffic Engineering si intende l’insieme delle tecniche atte a ottimizzare l’utilizzo delle risorse di una rete. Nelle tradizionali reti basate sul protocollo IP, l’unico criterio adottato nel calcolo dei percorsi è quello del costo minimo: i router, durante il calcolo del percorso considerano solo una metrica statica associata ai singoli link (nel caso in cui ogni link abbia costo 1 il routing sceglie i percorsi con numero di hop minimo) e non tengono conto di fattori dinamici, come ad esempio, la quantità di banda già occupata. Questo criterio fornisce buoni risultati fino a che il traffico della rete rimane basso, ma si rivela insufficiente quando la quantità di dati da trasportare è elevata. Infatti, se tale situazione si verifica, i percorsi brevi tendono a saturarsi portando velocemente la rete in uno stato di congestione. MPLS introduce una serie di strumenti e criteri con i quali si riesce a utilizzare la rete in modo più uniforme, migliorando la qualità del servizio e gestendo meglio i guasti.
1.7.1
Constraint Based Routing
Il CBR (Constraint Based Routing), a differenza del routing tradizionale, non sceglie i percorsi solo in base al costo dei link, ma considera anche alcuni vincoli, sia statici che dinamici. Alcuni possibili vincoli sono i seguenti:
• la banda disponibile sul percorso deve essere maggiore di una certa quantità;
• i link attraversati non devono introdurre, complessivamente un ritardo maggiore del valore richiesto;
• attraversare (o evitare di attraversare) un determinato link.
In MPLS uno dei possibili protocollo in grado di eseguire CBR è OSPF-TE (Open Shortest Path First – Traffic Engineering)[8], in quanto è in grado di trasportare informazioni necessarie per la TE come la banda non ancora allocata sui link, la quantità di banda riservabile ed alti ancora. OSPF-TE utilizza l’algoritmo CSPF (Constraint Shortest Path First) per calcolare un percorso che rispetti i vincoli imposti.
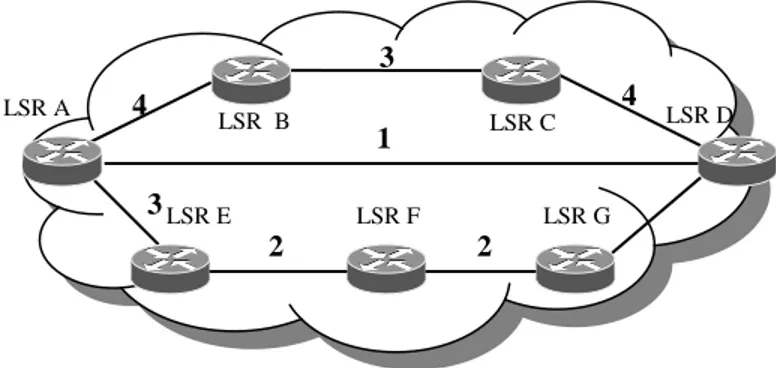
In figura è mostrato un esempio di come CSPF effettua le sue decisioni.
Figura 1-9 Esempio CSPF (situazione iniziale)
LSR B LSR F LSR E LSR C 4 3 4 3 2 LSR A LSR D LSR G 1 2
Su ogni link è indicata la banda non ancora allocata in Mbps. Supponiamo che il nodo A riceva la richiesta di allocare un flusso a 2 Mbps verso il nodo D. La prima operazione che CSPF esegue, è eliminare tutti i link che non hanno banda allocabile maggiore o uguale a 2 Mbps (operazione di pruning); in questo modo viene eliminato il link diretto da A a D. A questo punto viene calcolato il percorso a costo minimo analogamente a quanto avviene in OSPF. Il risultato dell’operazione sarà il percorso B C D, che verrà inserito nel campo ERO del protocollo RSVP-TE. Supponiamo adesso che il nodo A debba allocare un altro flusso da 2 Mbps verso D. La situazione aggiornata della rete è mostrata in figura.
Figura 1-10 Esempio CSPF (dopo l’allocazione di un LSP)
Durante il pruning verranno scartati i link A-D e B-C per cui l’unico percorso accettabile sarà E F G D.
LSR B LSR F LSR E LSR C 2 1 2 3 2 LSR A LSR D LSR G 1 2 LSP Allocato
1.7.2
Load Balancing
Nello scenario mostrato in figura 1-11 due flussi di traffico, uno generato dal nodo A e uno dal nodo B, devono uscire dal dominio passando dal LER G. Con i sistemi di routing tradizionali entrambi i flussi transiterebbero dal percorso a metrica minima (si supponga C D E G), lasciando inutilizzati i link D-F e F-G. In MPLS si possono sfruttare in modo migliore le risorse di rete facendo in modo che il nodo C aggreghi i due flussi assegnando ad entrambi la medesima label di uscita. Così facendo i due flussi saranno indistinguibili fino alla loro uscita dal dominio. Tali flussi, verranno poi, suddivisi in due sottoflussi che verranno instradati sui due percorsi disponibili (D E G e D F G). Il vantaggio di queste operazioni è duplice: in primo luogo viene ottimizzato l’utilizzo delle label, aggregando i flussi che hanno destinazione comune , e sfruttando tutti i percorsi disponibili.
Figura 1-11 Load Balancing
1.7.3
Priorità degli LSP
MPLS-TE introduce il concetto di priorità assegnata agli LSP. Gli LSP vengono suddivisi per livello di importanza in modo tale da rendere possibile, se necessario, il rilascio forzato di un LSP a bassa priorità, liberando le risorse necessarie per instaurarne uno a priorità maggiore. Questo meccanismo si basa su due valori distinti associati ad un LSP nel momento della sua creazione:
• holding priority: indica la priorità di mantenimento di un LSP;
LSR A LSR B LSR D LSR G LSR F LSR C LSR E Flusso B Flusso Aggregato Suddiviso Flusso A Flusso Aggregato
Entrambi possono assumere un valore intero compreso tra 0 e 7, minore è il valore e maggiore è la priorità. Quando un nuovo LSP deve essere instaurato e le risorse di rete sono insufficienti, si confronta la sua setup priority con le holding priority degli LSP già instaurati, nel caso in cui uno di essi sia a priorità minore (e il suo eventuale rilascio liberi abbastanza risorse) viene deallocato e successivamente viene instaurato il nuovo LSP.
1.7.4
Fast Rerouting
Quando su una rete IP si verifica la rottura di un link, i router intraprendono le seguenti azioni:
• inizialmente i router adiacenti al link devono rilevare il guasto;
• tali router devono propagare questa informazione in tutto il dominio;
• tutti i router devono modificare le proprie tabelle di forwarding per creare percorsi alternativi
Durante lo svolgimento di queste azioni si verificano consistenti perdite di pacchetti. Per risolvere il problema MPLS prevede il meccanismo di Fast Rerouting che consiste nel creare un LSP di backup per un determinato link.
Nella rete mostrata in figura, il traffico di un LSP transita lungo il percorso A B C E; ed il link B-C abbia come LSP di backup il percorso B D C. Al
momento della rottura del link B-C il nodo B inoltra il traffico sul LSP di backup mediante il label stacking.
Figura 1-12 Situazione precedente alla rottura del link
LSR B LSR E LSR C LSR A LSR D LSR B LSR E LSR C LSR A LSR D
Il LSP di backup può essere utilizzato per tutti gli LSP che transitano su un determinato link, inoltre non deve necessariamente essere calcolato “a priori”; esso infatti può essere calcolato direttamente dal nodo B nel momento in cui questo si accorge della rottura del link.
2.1
Introduzione a DiffServ
Il protocollo IP sul quale è basata la rete Internet è di tipo Best Effort, quindi che si occupa esclusivamente di trasportare i pacchetti da un punto ad un altro della rete, senza fornire nessuna garanzia sul ritardo di arrivo, sull’ordine di arrivo e sulla perdita. Mentre questo approccio, in passato, ha dato ottimi risultati, adesso sta diventando sempre più inadeguato a causa della grande diffusione di applicazioni real-time che richiedono round trip time molto bassi. Questa incapacità di Internet di fornire QoS (Qualità of Service) ha portato alla realizzazione dell’architettura IntServ (Integrated Services) [1], un sistema che definisce tre classi di traffico differenti che vengono trattate in modo particolare dai router:
• Best Effort: è la classe delle normali reti IP, quindi non riceve
nessun trattamento particolare;
• Controlled Load Service: il traffico di questa classe viene trattato
in modo da sperimentare i rate di errore e di ritardo tipici di una rete quasi scarica
• Guaranteed Service: il traffico appartenente a questa classe non
sperimenta perdita di pacchetti ed ha un limite superiore al ritardo end-to-end
L’allocazione delle risorse viene fatta separatamente per ogni microflusso, quindi ogni router attraversato deve memorizzare le informazioni relative al tipo di traffico e alle risorse riservate per ogni microflusso. In reti di grandi dimensioni i router dovrebbero memorizzare una enorme quantità di dati difficilmente gestibili sia per la quantità di memoria occupata sia per la potenza di calcolo richiesta per consultare strutture dati così grandi. Data la sua limitata scalabilità, l’architettura IntServ, non è adatta per una applicazione ad Internet.
L’architettura DiffServ (Differentiated Services) [3] è nata per superare i problemi di scalabilità di IntServ.
2.1.1
Funzionamento di DiffServ
Alla base di DiffServ sta il concetto di CoS (Class of Service).
denominati BA (Behavior Aggregate). Ad ogni classe viene associato un PHB (Per Hop Behavior) che specifica il tipo di trattamento che i pacchetti riceveranno nelle code dei router.
L’approccio di DiffServ è sensibilmente diverso da quello di IntServ per i seguenti motivi:
• la differenziazione del traffico non avviene in base ad un numero potenzialmente illimitato di microflussi, ma in base ad un numero limitato di classi di servizio (al massimo 64), rendendo scalabile il sistema;
• le uniche informazioni che i router devono mantenere in memoria sono relative ad un numero limitato PHB che vengono configurati una tantum dall’amministratore di rete;
• nei primi sei bit del campo TOS dell’header IP viene inserito l’identificativo DSCP (Differentiated Services Code Point) che indica ai router il PHB da applicare al pacchetto; grazie a questo identificativo nell’architettura DiffServ non è utilizzato alcun protocollo di segnalazione
Le operazioni più complesse, necessarie al funzionamento di Diffserv, vengono svolte dai router posti sulla frontiera del dominio (boundary router); i loro principali compiti sono i seguenti:
• i pacchetti in ingresso al domino vengono analizzati ed assegnati ad una classe di servizio (classification);
• ad ogni pacchetto classificato, nel campo TOS dell’header IP, viene inserito il DSCP corrispondente al PHB richiesto (marking);
• le classi di traffico a priorità più alta devono inviare una quantità limitata di dati per poter essere servite con la QoS richiesta; i boundary router controllano che il traffico di tali classi sia conforme ai limiti, in caso contrario possono scartare i pacchetti in eccesso (dropping) o trattenere i pacchetti e ritrasmetterli quando i limiti lo permettono (reshaping) o assegnare ai pacchetti in eccesso un PHB con garanzie di servizio peggiori (remarking).
Il compito degli interior router è semplicemente quello di controllare il DSCP dei pachetti ricevuti e gestire le code di conseguenza (scheduling).
2.1.2
PHB standard
L’IETF ha definito gli standard per 14 PHB, suddivisi in tre tipologie:
• Best Effort (BE): tale classe di traffico permette alla rete DiffServ
di integrarsi e risultare compatibile con la rete IP già esistente. Il PHB che corrisponde al servizio BE viene detto di default, e deve
essere disponibile in tutti i router del dominio DiffServ. Una possibile implementazione di tale PHB potrebbe utilizzare una
disciplina di coda che inoltri i pacchetti BE appena l’interfaccia di uscita non è occupata a soddisfare un pacchetto caratterizzato da un altro PHB. Il DSCP raccomandato per tale classe è “000000”.
• Expedited Forwarding (EF): rappresenta il miglior trattamento
riservato ai pacchetti che transitano nel dominio DiffServ. I micro-flussi che appartengono al BA corrispondente devono essere inoltrati rispettando i requisiti più stringenti in termini di ritardo, perdita dei pacchetti e jitter. Per poter garantire tale servizio privilegiato, i nodi attraversati devono imporre che la velocità di arrivo di tali pacchetti sia inferiore alla velocità di servizio. Così facendo, la permanenza all’interno delle code dei pacchetti appartenenti a questa classe risulta essere la minima possibile,
evitando lunghe attese e perdite intollerabili. Il PHB EF è associato ad esempio ai traffici voce e video, i quali
richiedono minimo ritardo e minima perdita di pacchetti.
Esistono diversi metodi per implementare l’EF: ad esempio, attraverso il meccanismo di scheduling Priority Queueing (PQ), che prevede la classificazione dei flussi in classi di priorità e l’inserimento di tali flussi in code diverse; le code vengono quindi servite in base al livello di priorità assegnato. In tal caso è opportuno utilizzare opportune funzionalità (ad esempio Token Bucket) che permettano di controllare e limitare il volume di traffico EF ammesso in rete, evitando “danni” a scapito di altre tipologie di traffico. Un'altra implementazione possibile prevede l’uso del meccanismo di scheduling Weighted Fair Queueing (WFQ), assegnando così al PHB EF una percentuale di banda molto elevata. Il DSCP riservato per EF è “101110”.
• Assured Forwarding (AF): la classe AF è in grado di offrire un
servizio che risulta peggiore sì di quello offerto da EF, ma migliore di quello offerto dal BE. Tale classe è divisa in quattro sottoclassi, ognuna caratterizzata da una differente priorità di coda. All’interno di ogni sottoclasse esistono tre diversi livelli di trattamento nello scarto (drop precedence) dei pacchetti. In tal modo si ottengono dodici PHB AF, indicati con la notazione AFxy, dove x rappresenta la sottoclasse (può assumere valori da 1 a 4, assegnando servizio migliore al traffico con indice più basso) e y indica la drop precedence (può variare da 1 a 3, assegnando una probabilità di perdita minore al traffico con indice più basso). I PHB AF sono applicabili a tipologie di traffico che richiedono la consegna garantita dei pacchetti, ma che non impongono tuttavia particolari vincoli su ritardo e jitter. Per implementare tale gruppo di PHB, sono necessari meccanismi di scheduling che consentano la gestione di più code con diversa priorità, ad esempio il Weighted Round Robin (WRR).
Tabella 2-1 Codici DSCP raccomandati per il gruppo AF
Occorre evidenziare che, una volta che il pacchetto è contrassegnato dal boundary node con un opportuno valore del DSCP (valore che corrisponde al desiderato PHB), il suo trattamento dal punto di vista della QoS è definito in ogni hop del suo percorso. Per questa ragione, è importante che gli internal node del dominio DiffServ mantengano la corretta corrispondenza tra DSCP e PHB e di conseguenza siano in grado di associare il traffico in arrivo alla coda opportuna in base al DSCP.
2.2
DiffServ over MPLS
Come visto nei paragrafi precedenti l’architettura DiffServ è in grado di offrire garanzie sul tempo di attesa e probabilità di scarto che i pacchetti sperimentano all’interno delle code dei router, ma non offre nessuna garanzia sull’allocazione di capacità trasmissiva della rete. Per questo motivo, DiffServ, non può essere considerato un sistema di gestione QoS
010000 011000 100000 101000
010010 011010 100010 101010
010100 011100 100100 101100
AF1y
AF2y AF3y AF4y
y = 1
y = 2
completo. L’ architettura MPLS, grazie ai protocolli di routing estesi per fornire TE, può offrire un ambiente connection-oriented garantendo risorse trasmissive ad aggregati di traffico ma non discriminando i pacchetti nel trattamento ad essi riservato nei nodi. L’integrazione delle due architetture porta quindi allo sviluppo di un meccanismo per gestire in modo completo la QoS. Entrambe le tecnologie hanno una buona scalabilità in quanto possono lavorare su un numero contenuto di grandi aggregati di traffico e svolgono le funzioni più complesse, come la classificazione, agli estremi della rete.
Uno dei vantaggi di MPLS è quello di prendere le decisioni di switching solo esaminando lo shim header. Questo sistema garantisce una maggiore velocità rispetto al routing IP, ma genera un problema che si incontra nell’integrazione con DiffServ: DiffServ inserisce i dati necessari a differenziare i flussi (il valore DSCP) nel campo TOS dell’header IP, quindi è necessario un meccanismo che permetta agli LSR di essere a conoscenza dei DSCP associati ai pacchetti in modo da poter applicare loro il PHB corrispondente. Per poter utilizzare il DiffServ in reti MPLS, sono state proposte due soluzioni per trasferire l’informazione contenuta nel campo DSCP, all’interno dello shim header. I campi dello shim header utilizzabili per trasportare tale informazione sono LABEL e EXP. A seconda del campo utilizzato vengono definiti due tipologie di LSP:
• E-LSP: EXP-Inferred-PHB Scheduling Class LSP • L-LSP: Label-Only-Inferred-PHB Scheduling Class LSP
2.2.1
E-LSP
Viene utilizzato il campo EXP dello shim header come sostituto del campo DSCP per portare l’informazione sul DSCP all’interno del dominio MPLS. L’inconveniente di questo approccio consiste nella dimensione del campo EXP, di soli tre bit contro i sei del campo DSCP: in questo modo si possono supportare al massimo otto diversi DSCP e quindi otto diversi PHB. Nel caso di una rete nella quale siano effettivamente implementati o richiesti al massimo otto PHB, le funzioni DiffServ possono essere esplicate semplicemente leggendo negli LSR il valore del campo Exp ed assegnando di conseguenza i pacchetti al corretto BA. Questo metodo ha il pregio di essere semplice e non richiedere alcuna segnalazione di controllo aggiuntiva.
2.2.2
L-LSP
La seconda soluzione proposta è utile qualora si debbano trattare più di otto PHB. In tal caso il campo EXP non è più sufficiente, si è quindi deciso di utilizzare il campo label, per far sì che indichi sia l’appartenenza ad una certa FEC che l’appartenenza ad un certo BA. Il campo Exp viene utilizzato per esprimere il valore della drop precedence, in modo da trattare i pacchetti secondo l’opportuno PHB. Ad esempio nella categoria di PHB AF, la label trasporta l’informazione sullo scheduling cioè riguardo alla coda sulla quale instradare il pacchetto; nel campo Exp si trova il valore (tra i tre possibili per ogni classe di scheduling di AF) della drop precedence.
E’ necessario far confluire i pacchetti del medesimo BA in un L-LSP comune, poiché sono destinati tutti alla stessa coda: un L-LSP può trasportare una sola classe di servizio. Questo modo di procedere consente di non avere limitazioni particolari sul numero di differenti PHB, a spese di una complicazione nella componente di controllo MPLS. Infatti è necessario estendere i protocolli per la distribuzione dei binding tra label e FEC, che adesso devono includere anche il binding tra label e PHB. La distribuzione deve essere effettuata al momento della creazione di un L-LSP.
Le due alternative per gli LSP con supporto di DiffServ non sono mutuamente esclusive e possono coesistere non solo a livello di dominio MPLS ma anche a livello di un singolo link.
2.2.3
Estensioni di RSVP-TE per DiffServ over MPLSIETF ha specificato, mediante la RFC 3270, quali ulteriori estensioni vanno apportate al protocollo RSVP, per supportare il DiffServ over MPLS. E’ stato aggiunto nuovo oggetto, denominato DIFFSERV OBJECT. Tale oggetto è differente a seconda del tipo di LSP che deve essere instaurato (E-LSP o L-(E-LSP).
E-LSP
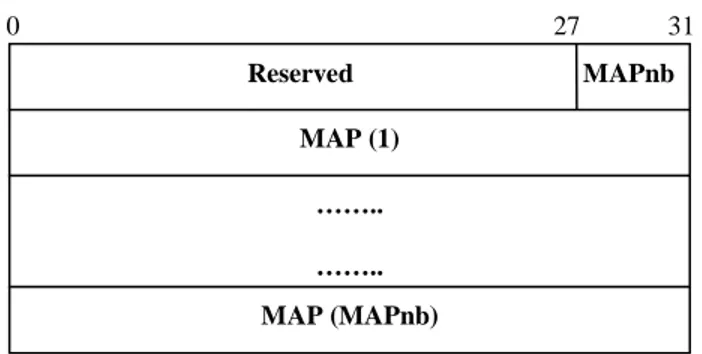
Figura 2-1 DIFFSERV OBJECT per un E-LSP
L’oggetto DIFFSERV nel caso di E-LSP è mostrato in figura e contiene i seguenti campi:
• Reserved (28 bit): è settato a 0 in trasmissione ed ignorato in
ricezione;
• MAPnb (4 bit): indica il numero di MAP (fino ad un massimo di
8) che sono trasportate nell’oggetto;
• MAP (32 bit): definiscono la corrispondenza tra un valore del
campo EXP ed il relativo PHB e sono in quantità pari al numero di PHB trasportabili in un unico E-LSP. Il singolo MAP è formato da:
o Reseved (12 bit): pari a 0 in trasmissione ed ignorato in
ricezione; MAP (1) …….. …….. MAP (MAPnb) 0 27 31 Reserved MAPnb
o EXP (3 bit): ha un valore a cui corrisponde il PHB
identificato nel campo PHBID;
o PHBID (16 bit): indica Il codice identificativo del PHB
come specificato specificato nella RFC 3140.
Figura 2-2 MAP entry nel DIFFSERV OBJECT per un E-LSP
Come già detto nei paragrafi precedenti, la modalità E-LSP non deve necessariamente far ricorso alla segnalazione, infatti nel caso in cui la corrispondenza tra EXP e PHB sia preconfigurata, l’oggetto DIFFSERV può non essere inserito nei messaggi di Path (nel caso in cui sia invece presente, non deve contenere alcun elemento MAP).
L-LSP
A differenza del caso precedente, se si vuole stabilire un L-LSP, è obbligatorio inserire l’oggetto DIFFSERV in tutti i messaggi di Path, poiché è fondamentale dare indicazione della PSC supportata dall’LSP. In questo caso la struttura dell’oggetto è la seguente:
• Reserved (16 bit): è settato a 0 in trasmissione ed ignorato in
ricezione;
Reserved EXP PHBID
• PSC (16 bit): indica la PHB scheduling class del LSP come
specificato nella RFC 3140
Figura 2-3 DIFFSERV OBJECT per un L-LSP
2.2.4
Label Switching DiffServ
Un LSR con il supporto del modello DiffServ deve svolgere le seguenti operazioni per eseguire il label switching:
• determinazione del PHB entrante: individuare il Behaviour
Aggregate a cui appartiene il pacchetto e determinare il PHB da applicargli;
• determinazione del PHB di uscita: nel caso in cui il traffico,
appartenente ad un flusso, non rispetti le limitazioni imposte può essere effettuata una riclassificazione ed in tal caso il PHB che i nodi successivi applicheranno verrà modificato; un LSR deve, quindi, essere in grado di cambiare dinamicamente il BA al quale il pacchetto appartiene;
0 15 31
• inoltro del pacchetto: le tabelle previste per la gestione delle label
(FTN, ILM, NHLFE), devono essere opportunamente ampliate per contenere informazioni aggiuntive riguardanti DiffServ; in particolare, nella NHFLE vengono inserite le informazioni necessarie al corretto trattamento del pacchetto; l’insieme di tali informazioni viene definito Diff-Serv Context e specifica il tipo di LSP (E-LSP o L-LSP), i PHB supportati, la corrispondenza che associa le informazioni DiffServ contenute nel pacchetto entrante ad un PHB e, infine, la modalità di codifica delle informazioni DiffServ nel pacchetto uscente;
• codifica dell’informazione DiffServ sul pacchetto uscente: se il
pacchetto viene inoltrato ad un altro nodo MPLS l’informazione DiffServ viene inserita nello shim header (a parte casi particolari come MPLS over ATM nel quale lo shim header non è previsto), ma se il pacchetto esce dal dominio MPLS, tale informazione deve essere codificata all’interno dell' header IP.
2.3
DiffServ-Aware MPLS Traffic Engineering
L’architettura DiffServ over MPLS effettua il constraint based routing utilizzando come vincolo la banda disponibile dei singoli link, allocando la banda con il medesimo criterio per ogni classe di servizio. Anche se questo sistema fornisce ottimi risultati, in alcuni casi si traggono grandi benefici adottando differenti criteri di allocazione banda a seconda della classe di
DS-TE (DiffServ-Aware MPLS Traffic Engineering). I vantaggi di DS-TE sono più evidenti quando si verifica almeno una delle seguenti condizioni:
• si opera in reti con limitata capacità trasmissiva (ad esempio le reti transcontinentali);
• vi è una percentuale significativa di traffico delay-sensitive all’interno della rete;
• la proporzione relativa di traffico tra le classi di servizio (DiffServ) non è uniforme.
2.3.1
Scenari applicativi di DS-TE
Nella RFC 3564, vengono presentati alcune possibili situazioni in cui DS-TE garantisce, al traffico, un servizio migliore di quello offerto dal DiffServ over MPLS. Nel seguito vengono presi in esame due tra gli scenari proposti.
Limitazione della proporzione di traffico di una classe su un link
Si prenda in considerazione una rete caratterizzata da due tipi di traffico: dati e voce. L’obiettivo è quello di garantire una buona qualità al traffico voce (ovvero mantenere bassi jitter, delay e loss), ma allo stesso tempo offrire comunque servizio al traffico dati (delay and jitter in sensitive). Utilizzando DiffServ, si potrebbe associare, al traffico voce, un determinato PHB, ad esempio EF, che mantenga bassi i valori di loss e delay. Tuttavia il delay totale è dato dalla somma di diverse componenti: ritardo di
propagazione, subito dal pacchetto nell’attraversamento della rete, ritardo di accodamento e ritardo di trasmissione subiti ad ogni hop. Essendo i ritardi di propagazione e di trasmissione quantità costanti, l’unica quantità che può essere minimizzata è il ritardo di accodamento, andando a limitare la dimensione del buffer per il traffico voce. Ciò significa limitare la proporzione di traffico voce su ogni link. DiffServ da solo non è in grado di effettuare una simile scelta, che invece può essere realizzata limitando artificiosamente la banda disponibile sui link nella misura adatta a soddisfare esclusivamente i requisiti di tale traffico.
Nel caso si verifichino cambiamenti alla topologia, ad esempio in seguito a guasti a nodi o link, il traffico voce potrebbe inoltre andare ad occupare quasi tutta la banda a disposizione su alcuni link. Per ragioni di delay o jitter, alcuni amministratori di rete preferiscono quindi evitare di trasportare più di una certa quantità di traffico voce su alcuni link; il resto della banda disponibile potrebbe essere utilizzato per trasportare le altre tipologie di traffico, in questo caso il traffico dati (che ricordiamo non è sensibile né al ritardo né al jitter).
Tramite le tecniche di TE già esaminate, tale obiettivo non può essere totalmente raggiunto, infatti l’unico modo per limitare la banda per il traffico voce sarebbe quello di limitare, totalmente, la banda allocabile sui link e questo comporterebbe anche una limitazione della banda utilizzabile dal traffico dati con una conseguente sottoutilizzazione dei link. Tale modello non è infatti in grado di distinguere i due tipi di traffico e di realizzare un’allocazione con una granularità per-traffic-type. In questo caso infatti, utilizzando il constraint based routing, si fa riferimento ad un unico
bandwidth constraint, comune a tutte le classi di servizio, che quindi non è in grado di soddisfare l’esigenza sopra descritta.
Tramite DS-TE, si può risolvere il problema utilizzando appropriati modelli di allocazione delle risorse (che analizzeremo in dettaglio nelle prossime sezioni) che siano in grado di garantire un diverso bandwidth constraint per ogni tipologia di traffico.
Nell’esempio descritto, si potrebbe quindi riservare al traffico voce una certa percentuale della banda di ogni link (e questo rappresenta il bandwidth constraint associato a tale classe), mentre al traffico dati si potrebbe garantire o il resto della capacità del link o un proprio bandwidth constraint.
Mantenere le proporzioni del traffico sui link
In questo secondo scenario si consideri una rete che supporta tre tipologie di traffico che corrispondono a tre diverse classi di servizio. L’amministratore di rete si propone quindi di utilizzare tecniche di TE per distribuire il carico di traffico.
In tal caso è molto importante configurare le dimensioni delle code e le discipline di scheduling da adottare su ogni link per assicurare che ad ogni classe sia associato il corretto PHB. Risulta difficile configurare questi parametri basandosi sulle condizioni di carico dei link ad ogni istante, in quanto la proporzione di traffico su ogni link è una quantità che varia dinamicamente in base a molti fattori, quali l’ordine con cui gli LSP vengono instaurati, la priorità associata ad essi, la presenza di guasti a nodi e link. Ciò potrebbe rendere difficile o addirittura impossibile la
configurazione dei diversi PHB per garantire l’opportuno trattamento ad ogni classe di servizio.
La soluzione ideale per risolvere il problema è quella di fissare le proporzioni relative ad ogni tipologia di traffico sui link, stabilire le dimensioni delle code e le discipline di scheduling in base a tale scelta e utilizzare il DS-TE per associare diversi constraint, in termini di banda, alle varie classi di traffico. Il nuovo modello può essere infatti usato per assicurare che, indipendentemente dall’ordine di setup degli LSP, dalla priorità associata ad essi e da situazioni di guasto, la quantità di traffico di ogni classe di servizio inoltrata su un link corrisponda alla configurazione dello scheduler DiffServ su quel link, per quella particolare classe.
Il DS-TE si rivela dunque in grado di bilanciare la quantità di traffico di ogni classe di servizio su un link basandosi sulla configurazione dello scheduler e sulla banda disponibile associata a tale classe.
2.3.2
Class-Type e TE-Class
Class-Type e TE-Class sono due concetti che stanno alla base del meccanismo che consente a DS-TE di effettuare allocazioni di banda separate per ogni classe di traffico.
Nella RFC 3564, il Class-Type (CT) viene definito nel modo seguente:
“Il set di traffic trunk (TT) che attraversano un link governato da uno specifico set di bandwidth constraint. Il CT è utilizzato allo scopo di
allocare la banda sul link, effettuare il constraint based routing e operazioni di admission control. Un dato TT appartiene allo stesso CT su tutti i link.”
Il numero massimo di class-type che DS-TE può gestire è otto e si indicano con la notazione CT0, CT1…fino a CT7. E’ comunque consigliabile utilizzare solo il minimo necessario numero di CT in modo da semplificare la gestione della rete ed aumentare le prestazioni degli LSR.
A CT0 viene associato il traffico best effort, in modo da garantire la compatibilità con reti che non supportano DS-TE. Ogni LSP è caratterizzato da un solo CT e viene instradato rispettando le regole di allocazione delle risorse previste per tale CT. Di conseguenza, traffici caratterizzati da CT distinti possono seguire percorsi diversi e rispettare vincoli differenti in fase di admission control. Ogni TT deve appartenere allo stesso CT su tutti i link e la corrispondenza tra classe di servizio e class-type deve essere rispettata in ogni zona del dominio DS-TE.
DS-TE può utilizzare la preemption, nei casi in cui , in condizioni di rete occupata da classi di traffico a bassa priorità, una classe ad alta priorità necessita di essere servita. In tal caso essa può svolgere un’azione di preemption sui traffici a priorità più bassa, facendo in modo che questi ultimi rilascino la banda loro riservata a suo favore.
Si definisce TE-Class la combinazione dei seguenti valori:
1. Class-Type 2. Preemption priority
La preemption priority è un valore numerico compreso tra 0 e 7 (con 0 priorità massima e 7 priorità minima) e può essere associato ad uno o ad entrambi i parametri di priorità già presenti in MPLS: setup priority e holding priority.
Dato che esistono al massimo otto CT e otto valori di priorità, esistono al massimo 64 TE-Class, tuttavia se possono utilizzare fino ad un massimo di otto (scelti tra i 64 disponibili). Questa decisione è stata presa tenendo in considerazione il fatto che il protocollo di routing deve segnalare, ad ogni nodo, l’informazione sulla banda allocata per ogni TE-Class su ogni link del domino; quindi si è ritenuto utile ridurre il numero di TE-Class utilizzabili in modo da diminuire sia la quantità di dati scambiata dal protocollo IGP utilizzato, sia le dimensioni delle tabelle interne agli LSR.
Esempio creazione TE-Class
Si definiscono le seguenti TE-Class:
1. CT=CT0 PP=0
2. CT=CT0 PP=2
3. CT=CT1 PP=1
4. CT=CT1 PP=3
Con queste quattro TE-Class sarà possibile trasportare i traffic trunk sugli LSP con CT uguale a CT0 o CT1 e come setup e holding priority uno dei valori associati a tale CT. Ad esempio sarà possibile allocare i seguenti
• CT=CT0 setup priority=0 holding priority=0
• CT=CT0 setup priority=2 holding priority=0
• CT=CT1 setup priority=1 holding priority=1
• CT=CT1 setup priority=3 holding priority=1
Non sarà, invece, possibile allocare i seguenti LSP:
• CT=CT0 setup priority=1 holding priority=1
• CT=CT1 setup priority=0 holding priority=0
Per eliminare la preemption si può assegnare la stessa preemption priority ad ogni TE-Class definita.
Come già visto, le CT specificano esclusivamente un set di bandwidth constraint usati per l’allocazione della banda. Per utilizzare gli strumenti che DiffServ fornisce è necessario associare le CT alle CoS. Tale associazione è liberamente configurabile dall’amministratore di rete.
2.3.3
Bandwidth Constraints Model
L’allocazione della banda ad un determinato CT avviene sulla base del rispettivo BC (Bandwidth Constraint) che indica quanta banda di ogni link può essere allocata ad una specifica CT (o ad un gruppo di CT). Le modalità con cui viene allocata la banda sulla base del valore dei BC è definite dal
Bandwidth Constraints Model che si decide di applicare. IETF ha definito i seguenti Bandwidth Constraints Model:
• MAM (Maximum Allocation Model) RFC 4125
• RDM (Russian Dolls Model) RFC 4127
Maximum Allocation Model (MAM)
MAM è il modello di allocazione banda più intuitivo, perché in esso ogni BC determina direttamente la banda massima allocabile di un’ unica CT. I vincoli che descrivono MAM sono i seguenti:
1. Il massimo numero di bandwidth constraint (MaxBC) uguaglia il massimo numero di class-type (MaxCT) ed è pari ad 8:
(MaxBC) = (MaxCT) = 8
2. Per ogni CT di indice c vale la seguente relazione:
Bandwidth
-Reservable
-Max
BCc
Tc)
Reserved(C
≤
≤
1)
-(MaxCT
c
0
con
≤
≤
3. La banda complessivamente riservata su un link non può mai superare la massima banda riservabile: