Capitolo 2
2 Indagine conoscitiva sui protocolli scatternet
2.1
IntroduzioneIn questo capitolo ci distaccheremo solo apparentemente dallo scopo del nostro lavoro e cercheremo di fare un indagine conoscitiva sui vari tipi di scatternet. Si andranno ad esaminare, infatti, alcuni protocolli di connessione scatternet, reperibili in letteratura, analizzandoli dal punto di vista delle prestazioni quali il ritardo di connessione, il flusso dei dati che attraversano i vari nodi e il loro tempo di arrivo nel nodo destinatario. Questo sarà utile per conoscere a fondo le problematiche inerenti al funzionamento delle scatternet in ambito del nostro progetto ai fini di dare delle risposte circa la corretta realizzabilità del sistema.
2.2 Tipologie di reti scatternet
In letteratura la formazione delle reti scatternet non è trattata che dal punto di vista teorico; non è infatti presente alcun riferimento a realizzazioni pratiche. Tutt’al più è possibile rintracciare analisi il cui banco di prova è costituita da simulazioni eseguite al calcolatore. Questo e i successivi paragrafi vogliono essere un compendio di quanto è reperibile in letteratura sull’argomento scatternet.
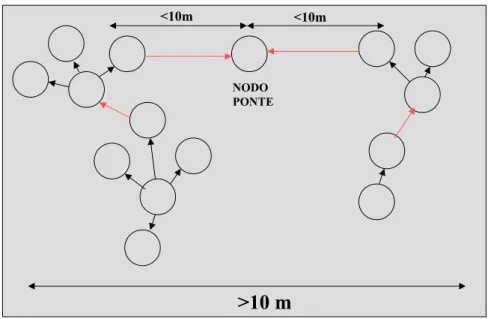
Le scatternet vengono comunemente classificate come multi-hop network, reti in cui un nodo è membro simultaneamente di due o più piconet diverse quindi utilizza due o più sequenze diverse di frequency hopping. La definizione di one-hop
network, invece, è riservata alla singola piconet, in cui ogni nodo usa un’unica
sequenza di frequency hopping stabilita dal master. Come nella piconet, la creazione di una rete scatternet si basa su una sequenza di azioni che ogni nodo esegue, in accordo con i nodi vicini, con lo scopo di stabilire e mantenere una connessione con essi. Quindi i nodi si scambiano delle informazioni sotto forma di comandi e risposte usando il protocollo Bluetooth, cioè, trasmettendo i dati secondo dei formati e delle regole specifiche condivise tra tutti i nodi in gioco. Per quello che concerne la formazione di scatternet in letteratura vengono proposti vari protocolli di connessione, ovvero procedure atte all’instaurazione di reti scatternet. Ogni procedura di creazione di una scatternet può essere suddivisa in fasi successive, diverse da un protocollo all’altro. La prima fase, però, quella della formazione di piconet tra i nodi adiacenti, è comune a tutti i protocolli. In seguito ogni protocollo prevede una via specifica per arrivare alla formazione della scatternet finale, via che dipende fortemente dalla tipologia della scatternet che si vuole instaurare. A tal proposito, analizzando vari protocolli presenti in letteratura si osserva che essi possono essere suddivisi in due grandi famiglie sulla base della posizione iniziale dei dispositivi. I protocolli appartenti alla prima famiglia prevedono che tutti i nodi stiano ad una distanza tale da rendere sempre possibile la connessione a due qualunque di essi ( come rappresentato in Figura 2-1). Gli altri, invece, sono meno restrittivi da questo punto di vista, e prevedono che non tutti i nodi di partenza debbano essere adiacenti, ossia localizzati entro la portata massima. Inizialmente solo i nodi adiacenti instaurano delle connessioni tra loro creando delle piconet o scatternet separate. In seguito, le reti siffatte stabiliscono delle connessioni tra loro, usando degli eventuali nodi ponte localizzati in modo da essere adiacenti a tutte le reti di partenza (in Figura 2-2). In seguito faremo un analisi approfondita di due protocolli, paradigmatico di una di queste due grandi
Figura 2-1 : la scatternet della prima famiglia
Figura 2-2 : la scatternet della seconda famiglia
10 m
>10 m
<10m <10m
NODO PONTE
I vari protocolli scatternet sono confrontabili mediante indici di prestazione tra cui elenchiamo:
a) Il tempo d’instaurazione – deve essere il più breve possibile per venire incontro alle esigenze degli utenti.
b) La quantità del traffico dati scambiata tra i vari nodi - è importante tenere basso questo indice per abbassare il consumo di energia, dato che si lavora a potenza limitata.
c) Il numero di piconet costituenti la scatternet – è un indice dell’efficienza dell’intero sistema. La scatternet deve includere un numero contenuto di piconet per la ragione seguente: dato che ogni piconet possiede una propria sequenza di frequency hopping e tutte le piconet condividono soltanto 79 canali di trasmissione è intuibile che, con l’aumento del numero delle piconet aumenta anche il numero di eventuali collisioni pregiudicando quindi l’efficienza della scatternet finale.
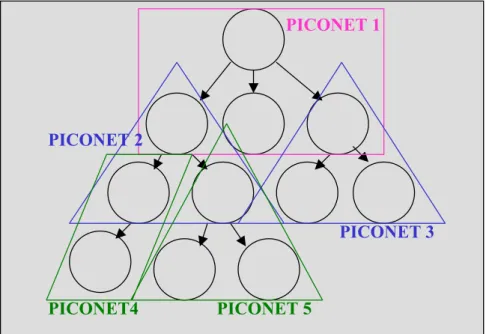
d) Il massimo livello di un apparecchio – indica il massimo numero di piconet a cui appartiene un dato oggetto. Se questo numero aumenta, l’oggetto in questione diventa il collo di bottiglia del traffico di dati nell’intero sistema, dato che il tempo in cui esso partecipa ad ogni piconet diminuisce. Bisogna, quindi, cercare di mantenere basso questo numero, possibilmente avere nodi appartenenti a non più di due piconet, in modo da non sovraccaricarli eccessivamente (in Error! Reference
source not found.).
e) La connettività della rete - indica la misura in cui esiste una connessione diretta tra due qualunque piconet all’interno della scatternet. Infatti, può capitare che due piconet che vogliano scambiare dei dati tra di essi debbano usare per questo una terza piconet, connessa ad entrambe. Questi dati avranno quindi degli ulteriori ritardi dovuti al passaggio tra tre piconet diverse. Dunque è meglio che ogni coppia di
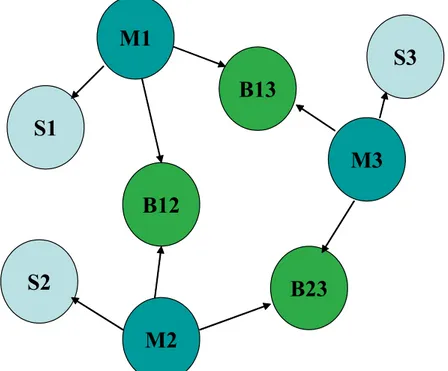
risultante viene definita fully connected (pienamente connessa) (in Figura 2-4) . Questo assicura una maggiore robustezza di connessione e migliori prestazioni alla rete.
Figura 2-3 : nodo ponte A di livello 2
Figura 2-4 : una scatternet fully connected
S1
M2
M1
B12
S3
S2
B23
M3
B13
2.3
Il protocollo BTCPIl protocollo che più di ogni altro rappresenta il concetto di rete scatternet appartenente alla prima famiglia è quello chiamato BTCP (Bluetooth Topology Construction Protocol)[6]. Viene definito come asincrono per il fatto che inizialmente ogni nodo ignora la presenza degli altri, e non esiste alcuna sincronia tra i tempi d’inizio della procedura per ciascun nodo. Inoltre si tratta di un protocollo di tipo distribuito, vale a dire un protocollo che viene eseguito da ciascun nodo indipendentemente dalla presenza o meno degli altri. Quindi il sistema di partenza si presenta in forma simmetrica, in cui tutti i nodi partono da condizioni iniziali identiche.
Il protocollo BTCP consiste in 3 fasi successive. La prima è quella denominata
coordinator election, in cui i dispositivi fanno un confronto tra di loro stabilendo,
alla fine, il vincitore che dovrà essere il coordinatore dell’intero sistema. La fase suddetta diventa molto utile in un sistema distribuito per rompere la sua simmetria congenita, infatti un coordinatore “eletto” è in grado di controllare la formazione della rete e di assicurare il rispetto di tutti i requisiti che una rete scatternet deve avere. La seconda fase viene chiamata role determination, e consiste nell’assegnamento del ruolo che ogni nodo dovrà svolgere nella rete (master, slave o bridge). Infine, nella terza fase, la scatternet formation, avviene la connessione vera e propria tra i nodi.
Entrando più in dettaglio, si può notare che durante la prima fase del protocollo i nodi, dopo l’inizializzazione, cercano di stabilire una connessione alternando fasi di
inquiry ed inquiry scan. Questo approccio è tipico del protocollo di connessione
simmetrico, nel quale tutti i nodi partono dalle stesse condizioni iniziali. In questo modo due nodi possono stabilire un collegamento solo se uno è nello stato inquiry e, contemporaneamente, l’altro in inquiry scan per un periodo sufficientemente lungo.
dispositivo. Due nodi x e y che hanno appena stabilito una connessione tra loro, mettono, inizialmente, a confronto le variabili voto. Il nodo vincitore risulta quello con il valore più grande, ma può capitare che le variabili voto risultino uguali. In tal caso, vengono confrontati gli indirizzi, unici, dei dispositivi e tale confronto ha sempre un vincitore. Senza perdere in generalità, si suppone che il nodo x vinca il confronto col nodo y, che interrompe la connessione ed entra subito nello stato PAGE SCAN. In questo modo il nodo y non sarà più in grado di ricevere nessun messaggio di INQUIRY, ma solo messaggi dai nodi che entreranno in PAGING col nodo in questione. Il nodo x, invece, incrementa il valore della sua variabile voto e rientra nella fase di stati alterni, passando tra l’Inquiry e l’Inquiry Scan. Dunque, esso è in grado di fare confronti con altri nodi e la procedura ricomincia da capo. Il vincitore tra N nodi, dopo N-1 confronti con gli altri rimasti, sarà il coordinatore dell’intera rete. Esso possiede N-1 pacchetti FHS, ricevuti in risposta all’inquiry, e contenenti le identità ed i clock degli altri nodi: conosce, quindi, il numero N dei nodi partecipanti alla futura scatternet.
La seconda fase, la Role Determination, consiste nell’assegnamento del ruolo che ciascun nodo dovrà svolgere all’interno della rete. Essa ha inizio con una verifica da parte del coordinatore sul numero N-1 dei nodi. Se tale numero è minore di 8, il coordinatore entra nella fase di PAGING, assumendo il ruolo di master nella rete finale, che risulta essere una piconet. Se il numero N-1 è maggiore di 8, significa che la rete finale sarà fatta da più piconet interconnesse tra loro tramite nodi
Bridge. Il coordinatore ha, quindi, il compito di scegliere i bridge in modo tale che
la scatternet finale abbia dei buoni indici di prestazione. Dunque, ogni nodo deve inviare al coordinatore, oltre al pacchetto FHS, un pacchetto contenente i propri criteri di partecipazione alla scatternet. Il coordinatore elabora tali informazioni e calcola, inizialmente, il numero minimo P delle piconet per cui la scatternet soddisfa l’indice della connettività (fully connected). Tale numero è dato dalla relazione: − − = 2 8 289 17 N
La limitazione a 36 del numero dei nodi necessita di una spiegazione, che verrà data più avanti.
Successivamente, il coordinatore seleziona, oltre sé stesso, altri P-1 nodi come master di altrettante piconet e P(P-1)/2 nodi come bridge. Infine, distribuisce equamente i nodi slave rimasti nelle varie piconet. A questo punto, per ogni master
x, il coordinatore possiede due liste contenenti dei pacchetti FHS. La prima, detta SLAVELIST(x) contiene i pacchetti degli slave della piconet x, mentre la seconda lista, la BRIDGELIST(x), contiene i pacchetti dei nodi ponte appartenenti alla stessa piconet. Esse vengono inviate dal coordinatore agli altri master dopo che lo stesso coordinatore, per fare ciò, abbia creato con essi una piconet temporanea. Le due liste fanno da punto di riferimento per ogni master, i quali, in una seconda battuta, possono fare il paging solamente ai nodi aventi i pacchetti FHS nelle proprie liste e creare più velocemente la piconet. Da notare che il numero P-1 dei master non deve essere maggiore di 7, dato che essi fanno da slave nella piconet temporanea. Di conseguenza esiste un limite massimo (fino a 36) del numero totale N dei nodi in gioco.
Durante il tempo di esistenza della piconet temporanea, il coordinatore invia agli altri master delle istruzioni su come procedere nella terza fase, quella della creazione di P-1 piconet. Infine, esso interrompe tutte le connessioni e si accinge a creare la propria piconet con i nodi individuati dalle informazioni presenti nelle due liste.
Nella terza fase ogni nodo slave viene contattato dal proprio master che usa, per questo, la propria SLAVELIST. Un nodo bridge, invece, deve attendere di essere contattato da due master e quando questo avviene esso invia il messaggio CONNECTED ad entrambi i master. Il protocollo termina quando ogni master riceve i messaggi CONNECTED da ogni suo bridge e la creazione della scatternet è quindi completata.
2.4
Stima del ritardo di connessionePer quanto riguarda il ritardo di connessione, la prima fase del protocollo, quella del coordinator election, costituisce la sua parte più significativa. Le fasi successive, invece, consistono nelle operazioni di paging e di connessione, piuttosto veloci rispetto alle operazioni della prima fase.
Per quantificare il ritardo complessivo analizziamo la sequenza delle operazioni che compongono la procedura. Durante la prima fase i dispositivi alternano gli stati di inquiry ed inquiry scanning, al fine di stabilire delle connessioni temporanee per riuscire a confrontarsi ed eleggere il nodo coordinatore. Innanzitutto, occorre precisare che durante le procedure di inquiry e page, anche se i due dispositivi usano la stessa sequenza di frequency hopping, è probabile che essi siano, per così dire, fuori fase, dato che ciascun oggetto inizia la trasmissione in una propria frequenza che dipende dal valore del suo clock interno. Per far fronte a tale incertezza di fase i due oggetti usano velocità diverse di frequency hopping. Il dispositivo nello stato di inquiry scan (il mittente) usa una minore velocità di hopping e tra un salto e l’altro sta in attesa di un messaggio da parte del mittente, che, dal canto suo, trasmette messaggi saltellando in frequenza a maggiore velocità e tra un messaggio e l’altro sta in ascolto di un eventuale risposta a quella frequenza da parte del ricevente. Il tempo trascorso fino a quando il mittente trasmette nella stessa frequenza del ricevente si chiama Frequency Synchronization delay (FS
delay), ed è presente soltanto nella fase di inquiry. Durante la procedura di paging, invece, anche se gli oggetti usano lo stesso meccanismo di sincronizzazione, il mittente può superare il problema del ritardo. Infatti, il mittente, nella fase di inquiry ottiene il valore di clock del ricevente, ed usa tale valore per ricavare la sua fase, cosicché la fasi di paging e di page scan possono cominciare contemporaneamente da parte degli oggetti.
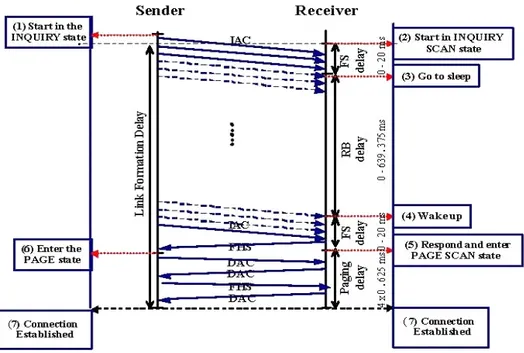
Per stimare il ritardo complessivo delle procedure di inquiry e di paging esaminiamo più in dettaglio i messaggi scambiati tra i due dispositivi, in Figura 2-5. In accordo con le specifiche Bluetooth, il protocollo inizia con il mittente nello stato
di inquiry ed il ricevente nello stato di inquiry scan. Come detto prima, esiste un ritardo (FS delay) dovuto alle diverse frequenze di hopping in cui lavorano mittente e ricevente. Esso può essere stimato facilmente considerando che il numero di frequenze di salto nella fase di inquiry o di paging è pari a 32 nei sistemi che operano in Europa e negli Stati Uniti e pari a 16 nei sistemi in Giappone, Francia e Spagna. Il tempo necessario per ricoprire le 32 frequenze è pari a T = 32 × 625 µs = 20 ms, ed è anche il valore di FS delay. Dopo aver ricevuto il pacchetto IAC, il ricevente entra in una fase durante la quale non è abilitato a ricevere alcun segnale, fase che può durare da 0 a 639.375 ms. La ragione di ciò sta nell’eventualità che due riceventi stiano ascoltando nella stessa frequenza di salto. Se entrambi i riceventi rispondono immediatamente, il messaggio può essere indecifrabile da parte del mittente impedendo, così, la sua ricezione. In questo modo, invece, la durata della fase in questione, chiamata Random Backoff delay (RB delay), è casuale per ogni ricevente, quindi il problema del conflitto temporale tra i messaggi dei riceventi non si presenta più. Quando il dispositivo ritorna allo stato nel quale può ricevere dei segnali, inizia ad ascoltare nella stessa frequenza di salto in cui lavorava prima della fase di Random Backoff. Dopo un altro FS delay, uguale a quello precedente, il dispositivo ha ottenuto il secondo pacchetto IAC dal mittente, e dunque, gli risponde inviando un pacchetto FHS. Esso contiene l’indirizzo del dispositivo, che verrà usato dal mittente per ricavare il pacchetto DAC da mandare durante il paging, ed il suo valore di clock, usato dal mittente per stimare la fase del ricevente ed eliminare l’FS delay in fase di paging. Dopo aver mandato l’FHS, il ricevente entra nella fase di page scan.
Figura 2-5 : procedura della creazione del link
Appena ricevuto il pacchetto FHS, il mittente entra nella fase di paging e manda al ricevente il pacchetto DAC, che, a sua volta, gli risponde con un altro pacchetto DAC. Subito dopo, il mittente invia un pacchetto FHS, che viene usato dal ricevente per determinare la sequenza di frequency hopping e la fase del mittente, diventando così lo slave. Inoltre il ricevente conferma il pacchetto ricevuto con un pacchetto DAC, che da via libera al mittente per diventare il master. Gli ultimi quattro pacchetti vengono trasmessi in slot consecutivi di durata 625 µs ciascuno, fissando il ritardo complessivo della fase di paging in 2,5 ms. Il ritardo dell’inquiry, invece, è nettamente maggiore ed è pari a:
R = 2FS + RB = 2 × 20 ms + 639.375 ms = 659.375 ms (2) (nei sistemi con 32 frequenze di hopping)
La procedura di connessione costituita dalle fasi di inquiry e di paging viene definita asimmetrica, per il fatto che i due dispositivi partono da stati già assegnati
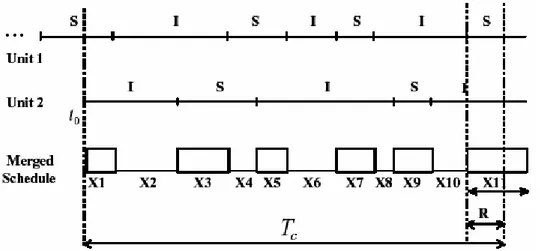
ed opposti tra loro, rispettivamente dall’inquiry e dall’inquiry scan. Il protocollo simmetrico BTCP, invece, non prevede dispostivi con stati fissi, pertanto ogni oggetto alterna le fasi di inquiry e inquiry scan con durata casuale. La Figura 2-6 mostra la connessione simmetrica tra due oggetti 1 e 2.
Figura 2-6 : protocollo simmetrico di creazione di un link
L’unità 2 inizia a cambiare, alternandoli, gli stati inquiry (I) ed inquiry scan (S) al tempo arbitrario t0, mentre l’unità 1 aveva iniziato in precedenza. Il grafico più in
basso, chiamato Merged Schedule, indica un andamento congiunto dei primi due che può essere visto come un processo “on-off”. Il valore alto (on) si riferisce al caso in cui le unità sono in stati opposti e stanno comunicando tra di esse. Per stabilire una connessione, i dispositivi devono rimanere in quegli stati almeno per un tempo pari al ritardo di connessione R. In caso contrario le unità devono attendere di trovarsi di nuovo nella condizione di prima. Quindi, il ritardo complessivo della fase di connessione in un protocollo simmetrico, chiamato Tc, è il
Il primo quesito a cui rispondere è il seguente: gli stati alterni devono avere durata fissa oppure casuale? Si dimostra analiticamente che il tempo medio di connessione tende all’infinito quando le unità cambiano stato in maniera deterministica. Infatti, se la durata di ogni stato è fissa per entrambe le unità, anche gli intervalli in cui esse si trovano in stati opposti hanno durata fissa. Quindi, il tempo di connessione è strettamente dipendente dalla differenza di fase dei grafici delle due unità, che determina la durata del periodo “on” del Merged Schedule. Se tale durata è minore del tempo R di connessione asimmetrica, non sarà mai possibile stabilire una connessione, quindi, è evidente il rischio che la scatternet non venga mai instaurata. In alternativa, le durate degli stati alterni possono essere definite seguendo una qualsiasi nota distribuzione di probabilità, quindi si riesce ad ottenere il valor medio e la varianza dell’intero ritardo di connessione simmetrico Tc. Se si suppone che le
due unità seguono la stessa distribuzione la probabilità Z, la media e la varianza del ritardo Tc sono date da:
[ ]
[ ]
(
[
]
[ ]
(
)
)
E[ ]
R p p X E X R X E X E T E c = + > + 1− + 2 (3)[ ]
[ ]
(
[
]
[ ]
(
)
)
Var[ ]
R p p X Var X R X Var X Var T Var c = + > + 1− + 2 (4)dove X è la durata casuale del periodo “on” di Merged Schedule e p è la probabilità che il ritardo R sia minore del periodo X, quindi: p=P
[
R≤ X]
.Un problema che si presenta al termine del coordinator election è quello di rendere noto l’identità del coordinatore a tutti i nodi in gioco perché, se ciò non avvenisse, la fase non terminerebbe mai. Bisogna quindi prevedere un parametro in ciascuno dei nodi che venga aggiornato in base all’evento in questione. L’idea proposta è quella di fissare per ogni nodo un periodo di TIMEOUT, che viene settato quando il nodo va allo stato ON e resettato quando vince un confronto con un altro nodo. Se il TIMEOUT finisce, significa che il nodo non ha trovato nessun altro per fare il confronto, quindi esso è il coordinatore e gli altri nodi sono in page scan. Il punto cruciale sta nello scegliere la durata del TIMEOUT. Un valore troppo grande fa allungare ulteriormente la durata del coordinator
election, dato che il coordinatore continua ad alternare gli stati senza accorgersi di essere stato eletto. D’altro canto, un breve TIMEOUT può portare nella situazione in cui più nodi si dichiarano coordinatori e ognuno di essi sceglie autonomamente i nodi master e i nodi ponte, creando una conflittualità all’interno della rete. Il valore ottimale di TIMEOUT, frutto di uno studio basato su calcoli probabilistici, è dato dalla formula empirica:
[ ]
T Var[ ]
T rmaxE
TIMEOUT = c + c + (5)
L’aggiunta del termine Var
[ ]
Tc è dovuta al fatto che la deviazione standard del termine Tc risulta quasi uguale al valor medio E[ ]
Tc , quindi la distribuzione diprobabilità del tempo di connessione non è centrato attorno al sua valor medio. Il termine rmax, invece, è stato aggiunto a conseguenza di un caso riscontrato molto
frequentemente, in cui il vincitore, dopo N-2 confronti, entra negli stati alterni e resetta il suo TIMEOUT, mentre l’ultimo nodo da confrontare sta nella fase di durata Random Backoff Delay, vista prima. Quindi, i due nodi si confronteranno solo dopo un tempo, limitato superiormente dal valore di rmax, tale che il nodo
ricevente sarà di nuovo attivo. Quantificando il tutto, si suppone che il valor medio della durata di ogni stato inquiry ed inquiry scan sia 600 ms, e si calcola che il minimo valore di TIMEOUT sia circa 2527 ms.
Il tempo complessivo di creazione della scatternet deve tenere conto di diversi fattori. Innanzitutto, il progressivo aumento del numero dei nodi porta ad un ragionevole aumento del ritardo di connessione. Si osserva che, fortunatamente, tale ritardo non varia linearmente con il numero dei nodi, ma ha un andamento che si avvicina a quello logaritmico. Tale andamento è dovuto al fatto che molti confronti tra due nodi avvengono in parallelo fino all’elezione del coordinatore, quindi, i ritardi non si sommano ma si sovrappongono. Inoltre, la procedura di connessione ha inizio solo quando tutti i nodi sono accesi, cioè dopo il tempo to dell’accensione
TIMEOUT T
Treale = ideale+ (6)
Il termine Tideale si riferisce al tempo in cui i nodi, attivandosi istantaneamente,
eleggono il coordinatore della rete, mentre il periodo di TIMEOUT viene aggiunto perché il nodo coordinatore deve attendere fino al termine di TIMEOUT per verificare l’avvenuta elezione.
Nel caso in cui gli istanti inziali to non sono identici, ci sarà un offset che influirà
nella durata totale di connessione. Nonostante ciò, il tempo di creazione della rete all’aumentare del numero dei nodi segue un andamento simile a quello senza offset. Si calcola che il tempo Tideale, nel caso di offset nullo, varia tra 1 sec e 3 sec
per un numero di nodi in gioco che varia tra 2 e 30. Quindi, il tempo complessivo Treale di connessione di 30 nodi è dato da:
3000 ms (Tideale) + 2500 ms (TIMEOUT) = 5500 ms (7)
La durata del TIMEOUT di 2500 ms assicura una probabilità del 96% di realizzazione della scatternet, un valore abbastanza rassicurante.
La procedura appena analizzata non è l’unica appartenente alla prima famiglia di scatternet. Sono state proposte altre simili procedure che lasciano intatta la prima fase del protocollo, quella dell’elezione del coordinatore, ma che variano per quanto riguarda il resto. Una delle versioni proposte consiste nel rimpiazzare le due fasi conclusive del protocollo BTCP con la seguente procedura: Dopo che il coordinatore è stato eletto, esso fa il paging solamente ai nodi con i quali si è confrontato ed ha vinto. Dopo essersi connesso come master, il coordinatore istruisce gli altri nodi a fare il paging, a connettersi come master ed a ripetere lo stesso procedimento con altri nodi ancora, in maniera ricorsiva, fino a quando tutti i nodi si siano connessi. La scatternet finale (in Figura 2-7) risulta avere una struttura ad albero (tree structure) e la sua connettività è garantita, anche se rispetto alla scatternet creata secondo il protocollo BTCP è meno efficiente e meno robusta, non essendo fully connected.
Figura 2-7 : la scatternet ad albero
2.5
Bluestars ProtocolPer quando riguarda le procedure per la creazione delle scatternet appartenenti alla seconda famiglia alcune di essi adottano delle soluzioni simili alle procedure analizzate prima. In particolare, la procedura di connessione “ad albero” viene ripresa per realizzare reti più ampie, con nodi posizionati fuori dal range della connessione Bluetooth. La differenza fondamentale tra i due tipi di protocolli
PICONET 1
PICONET 3 PICONET 2
coordinatore della rete, i protocolli di creazione delle scatternet più generalizzati consistono, inizialmente, nella creazione di sottoreti tra i nodi adiacenti, con dei metodi simili a quelli del protocollo BTCP, per poi realizzare tramite nodi ponte la scatternet finale. Non è concepito, quindi, il confronto tra tutti i nodi partecipanti e, di conseguenza, non esiste un nodo coordinatore che possiede tutte le informazioni sugli altri nodi in gioco.
Uno dei protocolli che meglio rappresenta il concetto di scatternet generalizzate è quello chiamato Bluestars Protocol[7]. Esso è caratterizzato da due fasi, la prima delle quali, consiste nella “scoperta” dei nodi vicini tra loro, e prevede la creazione di piconet chiamate BlueStars. Nella seconda, invece, le Bluestars si connettono tra di loro tramite nodi ponte, chiamati Gateway, per formare quella che viene chiamata BlueConstellation. Più avanti verrà analizzato il suo funzionamento in base agli indici di prestazione delle scatternet.
Entrando più in dettaglio, si può notare che la prima fase, denominata discovery
phase è simile a quella del protocollo BTCP e consiste nella scoperta dei nodi adiacenti. Infatti, i nodi alternano gli stati di inquiry ed inquiry scan, di durata casuale, fino a quando riescono ad instaurare una connessione. Da osservare che le durate di inquiry ed inquiry scan hanno un limite superiore dovuto ad un valore predefinito Tdisc (discovery), che indica la durata totale della fase di stati alterni. Per creare stati alterni di durata casuale, si genera un numero tra 0 e 1 tramite una funzione RAND(0,1); se il numero generato è minore di 0,5 il nodo entra o rimane in inquiry, in caso contrario cambia stato. Il protocollo prevede l’instaurazione di connessioni master-slave temporanee, per permettere ad ogni nodo di inviare all’altro le informazioni sulla propria identità, dopodiché tali connessioni si interrompono. Alla fine della procedura ogni nodo possiede molte informazioni riguardanti i nodi adiacenti, e l’insieme dei nodi può svolgere i passi successivi della procedura partendo da condizioni di simmetria. Ciò diventa importante per la correttezza della fase successive del protocollo. Tra le informazioni inviate da ogni nodo c’è un indice chiamato PESO che definisce la capacità del nodo di diventare master di una piconet, in base alla potenza di calcolo e alla quantità di memoria. I nodi fanno un confronto tra gli indici PESO per decidere chi sarà il master della
BlueStar. Se gli indici sono uguali, vengono confrontati gli indirizzi, e la vittoria va al modulo con indice maggiore.
La prima fase prosegue con una serie di procedure, atte a stabilire il ruolo che ogni nodo deve svolgere all’interno della propria BlueStar. La logica del procedimento è la seguente: il nodo X controlla le informazioni ottenute dai vari nodi, in particolare confronta i loro indici PESO. Dopo varie verifiche, il nodo X diventa slave di uno dei nodi di peso maggiore. Se l’indice PESO del nodo X risulta il più grande, allora esso diventa master, dopodiché comunica tale evento ai nodi con peso minore rispetto al suo. La procedura viene eseguita da ogni nodo e termina quando ognuno di essi ha acquisito un ruolo preciso nella BlueStar. In particolare, il nodo generico X rimane in page scan, fino a quando riceve un messaggio di paging da ogni suo “vicino” di maggior peso. In seguito, dopo aver stabilito il suo ruolo, esegue un paging finale a tutti i nodi in gioco per comunicare la propria decisione.
Una parte della procedura viene eseguita solo da alcuni particolari nodi, detti nodi INIZIALI. Essi sono i nodi con maggior indice PESO, che faranno da master nelle proprie BlueStar. Il confronto precedente tra gli indici fatto da ogni nodo risulta utile per stabilire i nodi INIZIALI, che entrano subito nello stato di paging cercando di acquisire vari slave.
Il generico nodo Y (in page scan), che riceve un messaggio di paging da un altro nodo X, confronta subito il proprio indice PESO con quello dell’altro. Se il peso di X risulta maggiore di quello di Y, quest’ultimo verifica che X abbia acquisito in precedenza il ruolo di master. In caso affermativo, il nodo Y si aggrega alla piconet con master X, solo se Y non apparteneva in precedenza ad alcuna piconet. Se, invece, Y era membro di una piconet, l’evento viene comunicato al nodo X, insieme all’identità del master di Y. Quindi, il nodo Y verifica che tutti i nodi di peso maggiore al suo abbiano eseguito il paging e se mancano ancora nodi all’appello, esso attende un’ulteriore messaggio di paging. Quando ha ricevuto tutti i messaggi di paging, il nodo Y acquisisce un ruolo nella rete, dopodiché va in page mode e comunica la propria decisione, prima ai “vicini” con minor valore di PESO, poi a
di paging ed attende un segnale da parte dei suoi vicini di minor peso per informarli sulla sua impossibilità di diventare il loro master.
Al termine di questa fase del protocollo ogni nodo ha un ruolo preciso nella rete ed appartiene ad una sola piconet. In particolare, il nodo generico Y comunica il suo ruolo ai vicini soltanto quando tutti i vicini di maggior peso rispetto al suo gli abbiano comunicato i loro ruoli.
L’inizio della seconda fase consiste nella scelta dei nodi Gateway che dovranno fare da ponte a due a più piconet. Essi vengono scelti dal master in base alle informazioni tra cui: L’identità ed il PESO dei nodi slave ad esso appartenenti, l’identità ed il PESO dei nodi vicini (informazioni raccolte dai propri slave) ed infine l’identità ed il PESO dei nodi che non si sono uniti alla propria piconet. Il criterio generale di scelta è il valore dei variabili PESO, il più grande dei quali corrisponde al nodo gateway.
Una volta stabiliti i nodi gateway, alcuni master detti iniziali (iMaster), esattamente quelli di PESO maggiore, iniziano la procedura istruendo i nodi gateway ad andare in page mode per contattare alcuni particolari tra cui:
• Un eventuale master X di una vicina piconet. In questo caso il nodo gateway diventa il master di X e subito dopo i due nodi eseguono un Role Switch (scambio dei ruoli). Dunque, il nodo gateway diventa slave di entrambi i master vicini.
• Un altro nodo gateway per stabilire una connessione a tre segmenti tra due piconet A e B. In questo caso uno dei due nodi gateway diventa il master dell’altro e si forma una piconet intermediaria tra i due master A e B.
A questo punto anche i master iniziali possono andare in modalità di paging per verificare se ci sono, nelle loro piconet, dei nodi contattati da altri nodi gateway. Gli altri master non iniziali (not iMaster), invece, istruiscono i propri nodi gateway ad andare in page scan ed attendere un segnale dai nodi gateway appartenenti a master iniziali, per dar vita ad eventuali piconet intermediari. In seguito, i not iMaster controllano se ci sono gateway appartenenti a piconet con master iniziali a contattarli, e rimangono in attesa di un paging da parte loro. Quando tutte le connessioni con i master iniziali si sono stabilite, i not iMaster
ripetono tutta la procedura di creazione delle BlueConstellation con i master di minor peso ancora, come se fossero master iniziali. La procedura termina con la creazione di una scatternet connessa in cui ogni nodo ha il ruolo di master in una sola piconet e può avere il ruolo di slave in diverse piconet.
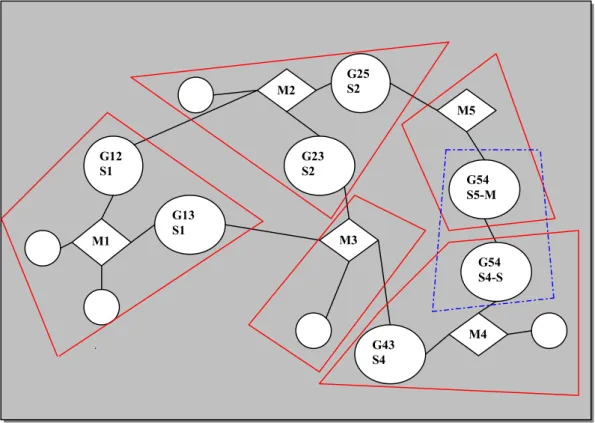
La Figura 2-8 rappresenta una BlueConstellation composta da 5 BlueStars (delimitate in rosso). Si può notare che tra la piconet 5 e la piconet 4 viene instaurata un’ulteriore piconet intermediaria (dentro la linea blu tratteggiata) formata dal nodo gateway appartenente alla piconet 5 (G54,S5-M) e dal gateway della piconet 5 (G54,S4-S), come master e slave, rispettivamente.
Figura 2-8 : La BlueConstellation M1 G12 S1 G23 S2 G13 S1 G25 S2 G43 S4 G54 S4-S G54 S5-M M2 M3 M4 M5
Per quanto riguarda i ritardi delle varie fasi del protocollo di creazione della BlueConstellation, se si fa l’ipotesi che il numero dei nodi operanti sia uguale a 30 unità, si ottengono i risultati seguenti:
• Nella fase di discovery, se si fissa il tempo Tdisc=10sec, e il numero dei nodi
pari a 30, in un tempo di 10 sec viene scoperto l’95% della totalità dei nodi. • Il protocollo nella fase di creazione della scatternet, con le stesse ipotesi di
prima ha una durata di 1 sec.
Il ritardo totale di connessione nel Bluestars Protocol è di circa 11 sec, quindi rispetto al protocollo BTCP, il ritardo di connessione risulta essere 2 volte più grande.
La connettività della scatternet siffatta non è garantita per il fatto che i nodi non si trovano sempre dentro la portata massima, quindi, la probabilità che alcune BlueStar non siano connesse tra di loro tramite nodi gateway è elevata.
2.6 La gestione del flusso di dati
Finora abbiamo analizzato soltanto il problema della creazione della scatternet ed esposto alcune delle soluzioni più efficienti relativamente al tempo di connessione e la connettività di rete. Un fattore importante da cui dipende la qualità della rete scatternet è senz’altro il modo di gestire il flusso di dati in ingresso ed in uscita ad ogni nodo.
Per semplificare l’analisi del traffico dati nei nodi appartenenti ad una scatternet, supponiamo di avere la scatternet più elementare, composta di sole due piconet collegate tra di loro tramite un nodo ponte (bridge). Il dispositivo Bluetooth dispone di una sola interfaccia RF, quindi il nodo ponte non può essere presente in entrambe le piconet contemporaneamente, ma deve dedicare una parte del suo tempo a ciascuno di esse. Quindi, la gestione del tempo di permanenza del nodo ponte in
ciascuna delle piconet, diventa fondamentale per ottimizzare le prestazioni dell’intera rete[8].
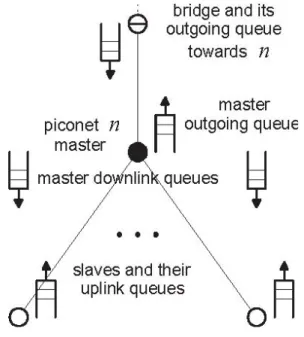
Il funzionamento della scatternet può essere analizzato usando un modello chiamato queueing model (modello a coda), nel quale ogni nodo slave mantiene una coda composta da messaggi da inviare al proprio master (uplink queue), ed entrambi i master mantengono delle code di messaggi, una per ogni slave
(downlink queue). Allo stesso tempo, i master mantengono una coda di
messaggi verso il nodo ponte, nell’ipotesi che quest’ultimo sia slave in entrambe le piconet (Figura 2-9).
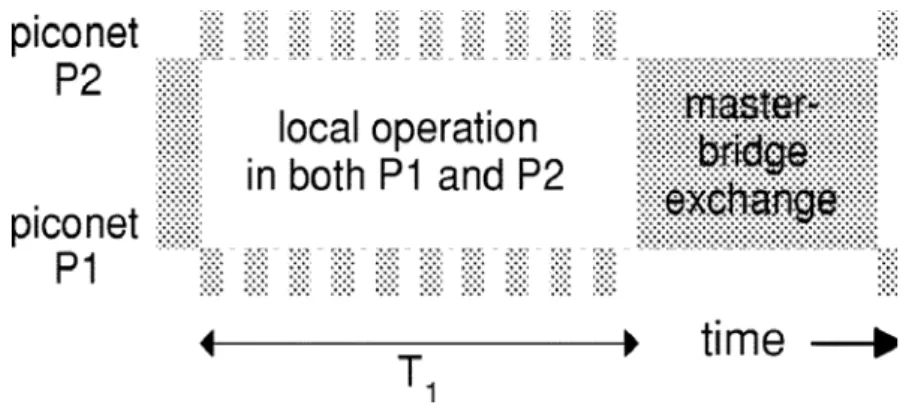
Supponiamo che il nodo ponte si unisca ad una piconet in una tempo predefinito. Una volta connesso, esso inizia a scambiare pacchetti col master. Dato che ogni comunicazione tra dispositivi Bluetooth è iniziata dal master, ed esso è impegnato con il nodo ponte, gli altri slave della piconet in questione non possono comunicare col master.
master. Il numero dei pacchetti nelle code dei due dispositivi è noto e non varia durante lo scambio, quindi, tale numero può essere determinato prima che inizi il loro scambio.
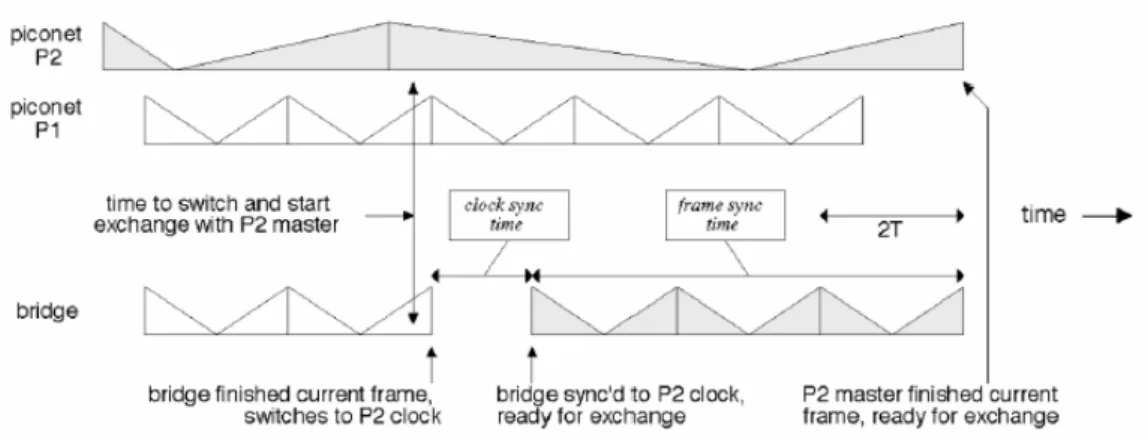
Una situazione per cui ci può essere un interruzione dello scambio dei pacchetti tra master e bridge è quella in cui il bridge entra a far parte dell’altra piconet. Di conseguenza, alcuni pacchetti devono attendere il prossimo intervallo di tempo in cui il nodo ponte si ricongiungerà alla piconet iniziale per essere scambiati. Se tale interruzione si vuole evitare si può fare in modo che il nuovo master attenda fino a che tutti i pacchetti tra bridge e vecchio master non siano scambiati. Al termine di ogni scambio con i due master, il bridge deve negoziare il tempo di ricongiungimento con ognuno di essi, ed è opportuno che questo tempo sia identico per entrambi, altrimenti il primo che cerca di connettersi deve attendere il proprio interlocutore. Tale negoziazione viene implementata usando la modalità HOLD. Quando il bridge tenta di unirsi ad una piconet, la prima operazione che esegue è quella di sincronizzare il proprio clock a quello del master, operazione che si completa con un ritardo medio di T=0,625 µs che è la durata di uno slot temporale del clock Bluetooth. In seguito, il bridge deve attendere un eventuale scambio di pacchetti ACL tra il master e un suo slave, la durata dei quali può arrivare fino a 5 slot temporali. A quel punto esso può iniziare lo scambio di pacchetti ACL con il master. La durata totale del periodo di attesa del nodo bridge ha un valore tra 0 e 8T, ed il suo valor medio è confrontabile con la lunghezza media del pacchetto. In Figura 2-10 è rappresentata la durata del periodo suddetto che viene chiamato anche
tempo di sincronizzazione del nodo ponte nel passaggio da una piconet P1 all’altra piconet P2.
Figura 2-10 : Tempo di sincronizzazione del nodo ponte
Si nota che, facendo un veloce confronto tra il tempo suddetto e i tempi di formazione della scatternet, stimati nei protocolli descritti nei paragrafi precedenti, risulta che il primo ritardo è poco significativo rispetto ai altri. Quindi, se il cambio di piconet da parte del bridge (piconet switch) avviene non troppo spesso, il tempo di sincronizzazione non influenza molto le prestazioni complessive della scatternet. Per quanto riguarda il flusso dei pacchetti all’interno di una piconet, si possono ottenere alte prestazioni usando delle procedure, come ad esempio quella denominata Stochastically Largest Queue (SQL), nelle quali il master concede la priorità assoluta alla comunicazione con lo slave che contiene la coda più lunga dei messaggi da inviare. Quindi, la durata dello scambio dei pacchetti tra il master ed uno specifico slave è definita in base al numero di pacchetti da scambiare tra di essi in entrambe le code. Di conseguenza, deve esistere uno schema ben preciso secondo cui il master, conoscendo in anticipo il numero dei pacchetti nelle code degli slave, seleziona quest’ultimi per scambiare dati ed informazioni. Questo schema (polling scheme) deve, peraltro, essere più semplice possibile in termini computazionali, dato che i dispositivi Bluetooth in genere posseggono limitate capacità di calcolo e di memoria.
schema del genere, quindi il problema della costruzione uno schema ottimo di gestione di flusso dati intra e inter-piconet è tutt’ora aperto. Sono stati proposti vari algoritmi di gestione del trafico dati che attraversa i nodi di una scatternet, ed in particolare i nodi bridge, per rendere più efficace e più veloce lo scambio dei dati tra piconet diverse.
2.7
Algoritmi di gestione di flusso.
Prendiamo ora in esame quello che viene chiamato Bridge scheduling, vale a dire la gestione del traffico dati in entrata ed in uscita da un nodo ponte. Ci sono varie soluzioni a proposito, ma ciascuna di esse si basa sulla determinazione di particolari istanti denominati Rendezvous points (punti d’incontro)[9]. I rendezvous points sono gli istanti in cui il nodo ponte deve iniziare a far parte in una piconet per iniziare a scambiare dati con il suo master. Gli istanti d’incontro possono essere fissati all’inizio e mantenuti per tutto il tempo di vita della scatternet, oppure possono essere stabiliti, se necessario, prima di ogni trasferimento dati tra il master e il nodo ponte. La prima alternativa ha il vantaggio che i nodi arrivano al contatto simultaneamente, mentre in caso contrario uno dei nodi deve attendere a vuoto, con una conseguente perdita di tempo e una diminuzione di banda. La procedura di gestione del traffico dati si può implementare facendo uso delle modalità di risparmio energia HOLD o SNIFF.
Alcune soluzioni proposte vanno nella direzione di una gestione globale dei rendezvous point, i quali vengono creati in precedenza, in base ai requisiti di banda di ogni singolo dispositivo. Ad ogni modo, questo metodo risulta eccessivamente complesso, e di conseguenza la scatternet finale risulta poco efficiente. Per far fronte e questo problema alcuni schemi assegnano dei rendezvous point fissi a ciascun nodo indipendentemente dagli altri, con una modalità pseudo-casuale. Nonostante ciò, il problema rimane per il semplice fatto che il traffico dei dati e,
soprattutto la topologia della rete scatternet può variare nel tempo, quindi, i rendezvous points assegnati opportunamente ad un certo instante non risultano più adatti ad un istante successivo e vanno quindi aggiornati in base alle esigenze della rete. Per risolvere questo problema, ci sono alcune proposte che consistono in una procedura preliminare che utilizza uno schema, denominata credit-based, teso a controllare ed adattare il livello dei servizi necessari ad uno slave in base al traffico dati istantaneo associato ad esso.
Per quanto le procedure siano ben strutturate, tuttavia, rimane abbastanza difficile la realizzazione di un ottima gestione di flusso dati, per il fatto che la durata temporale di una comunicazione tra master e nodo ponte non sempre si adatta all’intervallo tra due rendezvous points. Se lo scambio dei pacchetti termina troppo presto, il nodo ponte non può eseguire alcuna operazione fino alla successiva “chiamata” da parte del master che, nel frattempo, può sempre comunicare con i propri slave. D’altra parte, una comunicazione troppo lunga tra il master e il nodo ponte può interferire con il prossimo rendezvous point con l’altra piconet, il quale viene considerato un evento di massima priorità. Quindi, lo scambio precedente di dati verrà interrotto bruscamente e i pacchetti non inviati devono attendere il prossimo rendezvous point. Bisogna, dunque, cercare di adattare il più possibile gli intervalli suddetti in modo da ottenere la maggiore efficienza nello scambio dei dati.
E’ stato proposto, recentemente, un algoritmo di gestione di flusso che cerca di ovviare al problema postoError! Reference source not found.. Esso possiede due varianti, una nel caso del nodo ponte che fa da master ad una piconet, detta LAMS
(Load Adaptive Master/slave Scheduling), ed altra nel caso in cui il nodo ponte è slave in entrambe le piconet, denominata LASS (Load Adaptive Slave/slave
Figura 2-11 : La temporizzazione del nodo ponte M/S
Figura 2-12 : La temporizzazione del nodo ponte S/S
Passiamo ad analizzare nel dettaglio i due algoritmi LAMS e LASS[10]. La Figura 2-11 e la Figura 2-12 rappresentano, rispettivamente, la temporizzazione del nodo ponte master/slave e del nodo ponte slave/slave. Nella prima, il tempo complessivo è diviso in due di cui una parte (l’intervallo T1) è dedicata al funzionamento di
entrambi i master nelle rispettive piconet, e l’altra parte, dopo il rendezvous point, dedicata alla loro connessione. Nella seconda, invece, il nodo ponte spende un tempo T2 nella piconet P2, mentre il master della piconet P1 comunica con i propri
invertono ed il nodo ponte si connette alla piconet P1 per un tempo T1, mentre il
master della P2 gestisce i suoi slave.
Innanzitutto occorre notare che i parametri di prestazione più indicativi saranno i ritardi nella trasmissione di un pacchetto dalla sorgente fino al destinatario, dentro la piconet oppure tra piconet diverse. Viene definito ritardo locale il tempo di trasmissione del pacchetto dal sorgente al destinatario all’interno della stessa piconet. Tale ritardo include il tempo di connessione tra i due nodi, il tempo di attesa del pacchetto nella coda dello slave, e l’attesa nella coda del master. I ritardi
non locali, ossia quelli nel caso di trasmissione dati tra piconet diverse includono tutti i ritardi di prima, cui si deve aggiungere il tempo d’attesa del pacchetto nella coda del nodo ponte.
L’ipotesi iniziale da cui si parte è quella secondo la quale l’informazione non viene inviata tramite un solo pacchetto, ma tramite una raffica di pacchetti (burst) ognuno dei quali arriva in intervalli temporali distribuiti secondo la nota funzione di Poisson:
( )
= λ e−λx x
f x
! dove λ è la frequenza di arrivo media. Questa ipotesi risulta adatta a tutti i casi in cui i dati da trasmettere sono in quantità maggiore di quelli contenuti in un pacchetto ACL, quindi vengono distribuiti in diversi pacchetti, creando così il burst menzionato prima.
La lunghezza di un burst segue una distribuzione di probabilità che può essere descritta con la funzione di generazione di probabilità (PGF):
( )
=∑
∞=0 k k k b x b x G
dove bk è la probabilità che il burst contenga esattamente k pacchetti. Si assume,
quindi, che la distribuzione sia quella geometrica con valor medio '
( )
1b
G
B= . Tutti i generatori di pacchetti in una piconet condividono la stessa probabilità Pl che la
sorgente ed il destinatario del burst di pacchetti partecipino alla stessa piconet. Inoltre, la probabilità che la lunghezza del singolo pacchetto sia di 1, 3 o 5 slot temporali è rispettivamente p1, p3 e p5 tale che: p1 + p3 + p5 = 1. La corrispondente
funzione PGF è
( )
5 5 3 3 1x p x p x p xL’analisi fa uso della trasformata di Laplace-Stieltjes (LST) delle distribuzioni di probabilità. Essa si ricava dalla corrispondente funzione PGF sostituendo la variabile x con e−s. Ad esempio, la LST della distribuzione della lunghezza dei
burst è ∗
( )
=∑
∞= − 0 k ks k b s b eG , mentre la LST della distribuzione della lunghezza dei
pacchetti Bluetooth è
( )
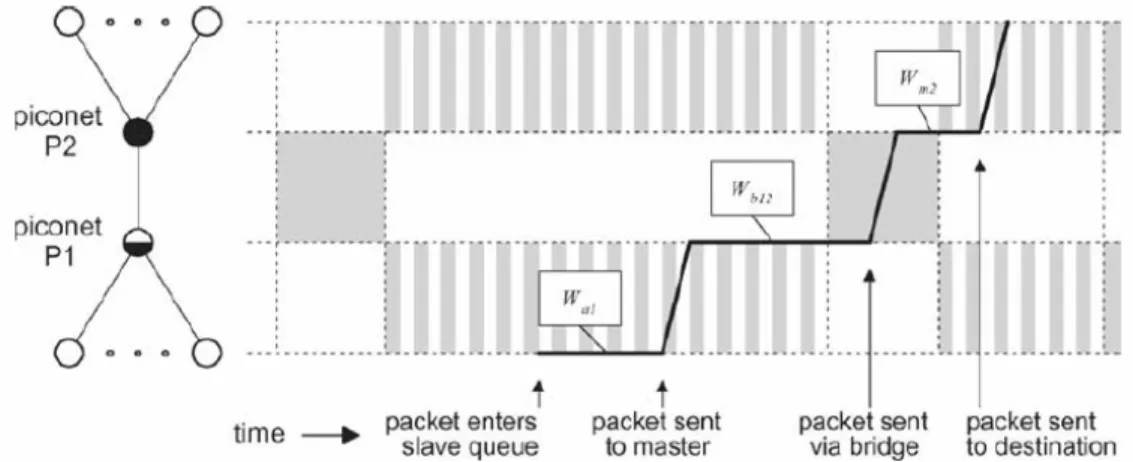
s s s p s pe p e p e G 5 5 3 3 1 − − − ∗ = + + .Il procedimento di calcolo, fatto in Error! Reference source not found., consiste nel determinare il ritardo complessivo W 12 della trasmissione di un pacchetto da uno slave appartenente alla piconet 1 ad un altro slave appartenente alla piconet 2. Nel primo caso, quello del nodo ponte M/S (il master della piconet 1), il ritardo totale è dato dalla somma di 3 ritardi locali. Il primo è quello denominato Mean
Access Delay (ritardo medio di accesso) Wa1, che consiste nell’intervallo temporale dall’ingresso del pacchetto nella coda dello slave fino al suo arrivo al master. Le componenti fondamentali di questo ritardo sono: il tempo medio del ciclo piconet (il tempo in cui il master visita tutti gli slave), integrato al tempo necessario per operare su un singolo pacchetto in caso di una rete scatternet (da notare che dopo ogni intervallo T1 in cui il master opera sugli slave locali, esso si connette all’altro
master per trasferire eventuali informazioni). Il secondo ritardo locale si riferisce all’ attesa nella coda bridge del nodo ponte Bridge queueing delay Wb12, ed il terzo, invece, si riferisce alla coda del master della piconet 2, ed è denominata
Queueing master delay Wm2 . Inoltre, il risultato dell’analisi indica che il ritardo complessivo W risulta dipendente, tra l’altro, dalla frequenza d’arrivo dei burst λ, 12
dal valor medio B della distribuzione della lunghezza dei pacchetti burst, e dal momento di primo e secondo ordine della distribuzione della lunghezza dei pacchetti Bluetooth L ed L2, rispettivamente.
Figura 2-13 : Il ritardo di trasmissione nella scatternet con nodo ponte M/S
La Figura 2-13 rappresenta, appunto, il ritardo complessivo dovuto ai tre ritardi locali per ognuno dei tre segmenti di percorso: dalla sorgente al master 1, dal master 1 al master 2 e dal master 2 al destinatario.
Per quanto riguarda il ritardo di trasmissione di un pacchetto attraverso il nodo ponte slave/slave (in Figura 2-14), si nota che, oltre ai due ritardi locali sopraccitati
1
a
W e Wm2 , esistono due ulteriori ritardi che interessano il nodo ponte: essi sono il tempo di attesa Wm1b del pacchetto nella coda del master 1 fino al raggiungimento del nodo ponte, ed il ritardo di accesso Wa1b (Mean access delay), che è la durata dell’attesa del pacchetto nella coda del nodo ponte associata al master della piconet 2. Anche in questo caso il ritardo complessivo è strettamente dipendente dalla frequenza dei burst e dai valori medi delle distribuzioni della lunghezza dei burst e della lunghezza dei pacchetti Bluetooth.
Figura 2-14 : Il ritardo di trasmissione nella scatternet con nodo ponte S/S
In definitiva, i ritardi di trasmissione dei pacchetti attraverso i due tipi di nodi ponte sono dati da:
2 12 1
12 Wa Wb Wm
W = + + per il nodo ponte master/slave (8)
2 2
1 1
12 Wa Wmb Wb m Wm
W = + + + per il nodo ponte slave/slave (9)
Una stima dei ritardi suddetti, è calcolata in Error! Reference source not found., e viene espressa in funzione di alcuni parametri come l’intervallo T1 in cui i master
comunicano soltanto con i propri slave, e la frequenza dei burst λ. I ritardi vengono espressi in multipli del periodo T=0,625 ms (la durata di uno slot temporale nella comunicazione Bluetooth) ed aumentano all’aumentare della frequenza d’arrivo dei burst λ. Inoltre, tale aumento ha un andamento più ripido in corrispondenza di λ più grandi. Stesso discorso vale per quanto riguarda la dipendenza dal parametro T1. Si
nota, però, che nel caso del nodo ponte master/slave, il ritardo cresce poco all’aumentare di T1, mentre nel caso del nodo slave/slave ha una andamento lineare
ottiene, nel primo caso, un ritardo complessivo pari a 300T, mentre nel secondo caso pari a 400T. Tale risultato era prevedibile dato che il nodo slave/slave deve attendere il proprio turno di visita da parte dei master in entrambe le piconet, mentre il nodo master/slave ha il vantaggio di gestire esso stesso una delle piconet, quindi, il percorso che un pacchetto deve fare per raggiungere la destinazione è più breve. L’analisi del ritardo è un fondamentale punto di partenza per capire dove e come si può intervenire per migliorare le prestazioni della rete. Il fatto che il ritardo dipenda da vari parametri ci porta alla scelta ovvia di variare dinamicamente uno di essi per minimizzare il ritardo complessivo. Occorre notare che, nonostante la presenza di diversi parametri su cui si può intervenire, solo il parametro T1 può essere variato
abbastanza frequentemente e può essere adattato facilmente al traffico dati attuale, mentre gli altri parametri come λ e B (il valor medio della distribuzione della lunghezza dei burst) sono legati alla quantità di dati da trasmettere, quindi non possono essere continuamente aggiornati.
Per determinare il valore ottimo di T1 l’algoritmo di gestione del flusso dati
necessita di un dato riguardante l’intensità di traffico R, che corrisponde al valore istantaneo del carico di dati. Inoltre, l’intensità di traffico R contiene altre informazioni quali il numero degli slave nella piconet, la frequenza dei burst ecc. Un altro dato importante è quello che indica la porzione P del traffico totale di dati che passa attraverso il nodo ponte. Una stima dei dati suddetti può essere ottenuta semplicemente contando il numero dei pacchetti oppure contando gli slot temporali dei pacchetti ricevuti dal master e dal nodo ponte nel ciclo precedente in cui il master opera nella propria piconet. Dato che le stime possono avere ampie variazioni, è opportuno usare i loro valori medi ρ e π, rispettivamente per il primo e il secondo dato. Il primo valor medio viene aggiornato periodicamente ad ogni ciclo in cui il master si occupa dei propri slave secondo la relazione:
(
α)
ρ αρ1 = R+ 1− (10)
dove α è una costante di smorzamento. Allo stesso modo viene aggiornato il secondo valor medio π.
(
)
π ρ2 1 1 − + =a b T (11)dove a=12T è il minimo valore di T1 (compatibile con il ritardo di sincronizzazione
del nodo bridge, visto nel paragrafo precedente) e b=24T viene scelto in base ai risultati ottenuti dalle simulazioni.
Passiamo alla descrizione vera a propria dell’algoritmo LAMS. Durante la fase in cui entrambi i master P2 e P1 (che è anche il nodo ponte) comunicano con i propri slave, essi tengono traccia del numero totale degli slot temporali del traffico locale dati, N2 ed N1 rispettivamente. Inoltre, il nodo ponte P1 tiene traccia del numero degli slot del traffico dati in uscita dalla piconet Nout. All’arrivo del rendezvous
point il nodo ponte si connette come slave al master P2 ed inizia lo scambio dei dati tra essi, durante il quale il nodo P1 tiene traccia anche dei pacchetti in ingresso Nin.
Quando lo scambio dei dati è al termine, il master P2 comunica al nodo ponte il valore N2 del traffico locale nella piconet 2. Il nodo ponte, dal canto suo, calcola le stime dei parametri R e P tramite le relazioni:
(
)
d in out T N N N N R= 1 + 2 + + (12) e(
)
(
N N Nout Nin)
N N P + + + + = 2 1 2 1 (13)e ricava i valori medi ρ e π, rispettivamente. In seguito calcola il nuovo periodo T1 (tempo fino al prossimo rendezvous point) tramite la relazione precedente ed
invia al master P2 una richiesta di entrare nella modalità HOLD (con tempo di hold pari a T1). Il master P2 riconosce tale richiesta dopodiché entrambi i master tornano
ad occuparsi dei propri slave.
Nel caso del nodo ponte slave/slave questo procedimento non dà buoni risultati per una ragione riguardante la topologia della scatternet. Essa consiste nel fatto che quando il nodo passa dalla piconet 1 alla piconet 2, la decisione sul periodo Td fino
al prossimo rendezvous point si fa sulla base dell’informazione riguardante il traffico dati nella piconet 1 senza considerare il traffico dati attuale sulla piconet 2. In questo modo può accadere che il rendezvous point del nodo ponte col master 1 avvenga prima del tempo necessario per scambiare i dati col master 2 con la conseguente perdita dell’efficienza di trasmissione. Inoltre, per acquisire anche informazioni sul traffico nella piconet 2, il nodo ponte dovrebbe far un salto nella
piconet 2 per un breve tempo, mentre sta operando nella piconet 1. Questo porta ad un eccessivo numero di scambi di piconet da parte del nodo ponte, e, di conseguenza, ad ulteriori ritardi dovuti alla sincronizzazione.
Per ovviare a questo problema si è pensato di far terminare uno scambio di dati in modo forzato quando il tempo T1 è troppo breve per far scambiare tutti i dati. In
questo modo alcuni pacchetti devono attendere il prossimo rendezvous point per essere scambiati. Tale ritardo si può minimizzare riducendo o addirittura azzerando il numero dei pacchetti in eccesso, quindi limitando al minimo le fasi di scambio dei dati che devono essere forzatamente terminati.
L’algoritmo LASS opera nel modo seguente: Se tutti i pacchetti sono stati scambiati prima dell’arrivo del rendezvous point la procedura termina normalmente. Ciò significa che il tempo T1 attuale è sufficiente per l’attuale traffico di dati, e che esso
può essere decrementato se risulta eccessivo. Se, invece, il rendezvous point arriva prima della trasmissione di alcuni pacchetti, viene eseguita la terminazione forzata. Dato che il tempo T1 attuale risulta non sufficiente, esso verrà aumentato al
prossimo scambio di dati.
Il procedimento è simile a quello dell’algoritmo LAMS con la differenza che in questo caso il nodo ponte ha bisogno di più informazioni, non solo riguardanti la piconet attuale in cui opera il nodo, ma anche la piconet in cui operava in precedenza. Quindi, i parametri di ritardo dovuto al traffico locale dei dati sono 4, 2 per ogni piconet, e vengono denominati δxy, dove x e y sono le due piconet in gioco.
Il periodo T’1 fino al prossimo rendezvous point viene ottimizzato aggiungendo o
togliendo opportunamente uno di questi parametri tramite la relazione:
δ 2 1 ' 1 = T + T (14)
Il periodo minimo T1min si pone uguale a 12T, che è un valore abbastanza
ragionevole. In ogni caso, il periodo T1 non necessita di un limite superiore perché
Facendo una rapida sintesi di ciò che è stato detto in questo capitolo, si può dedurre che gli algoritmi prima esposti, uniti alle procedure viste nei precedenti paragrafi danno un’idea sui metodi usati, seppure in linea teorica, per costruire delle scatternet efficienti in termini di velocità di connessione, di connettività e di gestione del flusso di dati da parte dei vari nodi nella rete. Rimane, invece, aperta la questione della messa in pratica di tali teorie, che, se risolta, porterebbe ad una vera e propria rivoluzione per quanto riguarda le reti scatternet. Nei capitoli successivi cercheremo di dare un contributo in questo senso.