Capitolo 1
Architettura (G)MPLS
1.1 Introduzione
L’MPLS (MultiProtocol Label Switching) è una delle tecnologie di rete di maggior successo degli ultimi anni ed è già implementata nelle reti IP per fornire loro funzionalità di ingegneria del traffico e per velocizzare l’inoltro dei pacchetti.
Per fornire ingegneria del traffico, vengono utilizzate delle tabelle che mostrano il livello di qualità del servizio (QoS) che la rete può supportare, mentre, per velocizzare l’inoltro dei pacchetti, un dispositivo MPLS utilizza il confronto delle etichette (Label) piuttosto che gli indirizzi IP della sorgente e destinazione del traffico per determinare l’inoltro successivo di un pacchetto ricevuto. Le tabelle e le Label sono utilizzate per stabilire un percorso che va dal punto di origine fino al punto di destinazione detto LSP (Label Switched Path).
L’emergere dei sistemi di trasporto ottici ha drasticamente incrementato la naturale capacità delle reti ottiche ed ha consentito la circolazione di nuove e sofisticate applicazioni.
Add drop multiplexing (ADM), dense wavelenght division multiplexing (DWDM), l’optical cross connect (OXC), photonic cross-connect (PXC) sono solo alcuni dei dispositivi che compongono una rete ottica e sono gli
elementi portanti per sostenere la crescita del traffico dati in costante aumento.
Ma è proprio la complessità e la diversità riscontrata nella gestione di questi dispositivi che ha portato l’ International Engineering Task Force (IETF) ad estendere l’insieme dei protocolli MPLS per includere dispositivi che commutano anche nel dominio del tempo, in quello della lunghezza d’onda e dello spazio (commutazione di fibra).
È nato così il GMPLS che fornisce un piano di controllo comune per operare attraverso i differenti tipi e livelli di reti. L’insieme dei protocolli IP che gestiscono e controllano gli LSP che attraversano reti ottiche a pacchetto o TDM vengono modificati ed estesi all’interno del GMPLS. Il GMPLS è diventato uno standard nel networking ottico di prossima generazione proprio perché esso è in grado di fornire il ponte necessario fra lo strato IP e quello ottico consentendo alle reti di essere interoperabili e scalabili.
1.2 Evoluzione dell’architettura di rete
Negli ultimi anni abbiamo assistito ad una semplificazione dell’architettura di rete perché si è riusciti ad avere una maggiore integrazione delle funzionalità di controllo e gestione mediante l’utilizzo del GMPLS.
Ma ripercorriamo per gradi questa evoluzione e cerchiamo di comprendere i motivi che l’hanno resa necessaria.
Fino a qualche tempo fa le reti di trasporto SONET/SDH hanno fornito prestazioni e affidabilità elevate soprattutto per il traffico voce o comunque
laddove ci fosse bisogno di linee dedicate. Negli ultimi anni, però, con la diffusione di Internet e la proliferazione delle reti private virtuali (VPN), il traffico dati ha avuto un aumento esponenziale accompagnato da una domanda, da parte dei consumatori, di tenere bassi i prezzi del “networking”.
Di fronte a questa situazione i Service Provider (SP) hanno cercato soluzioni che consentissero loro di trasportare grossi volumi di traffico equilibrando il bilancio costi-efficienza. Mantenere questi obbiettivi utilizzando le attuali architetture di rete è sicuramente una sfida difficile perché le reti odierne sono generalmente organizzate in quattro strati: lo strato IP per le applicazioni e i servizi, ATM (Asynchronous Transfer Mode) per l’ingegneria del traffico, il SONET/SDH per il trasporto fisico e il DWDM per la capacità lungo la fibra ottica .
Si comprende bene, allora, che la sfida non può avere esito favorevole perché questa architettura, come un pò tutte quelle multi-strato, limita la scalabilità, oltre ad aggiungere costi, dell’intera rete.
DWDM è una tecnica di multiplexing efficiente dal punto di vista dei costi e vantaggiosa dal punto di vista tecnico: infatti può sfruttare in maniere più efficace la capacità di una singola fibra creando molti canali ognuno dei quali trasporta diversi Gigabit di traffico al secondo. Inoltre il suddetto incremento di banda è ottenuto senza apportare modifiche alle infrastrutture in fibra già esistenti.
Allo stesso modo gli OXC emergono sempre più come il modo migliore per commutare a livello ottico flussi di dati di Gigabit/sec o addirittura Terabit/sec perché consentono di evitare l’elaborazione elettronica del pacchetto.
Figura 1.1 : evoluzione dell’architettura di rete
Inoltre, poiché è previsto che la maggior parte del traffico trasportato sulle reti dati sarà basato su IP, lo sviluppo di tecnologie per ottenere router veloci è essenziale per l’aggregazione di flussi di dati con un bit rate più basso in flussi dati compatibili con gli OXC che sono ad alto rate.
Per cui, visto che le capacità dei router e degli OXC crescono rapidamente, l’alto data-rate del trasporto ottico suggerisce la possibilità di lasciare da parte gli strati SONET/SDH e ATM.
Ma per fare ciò è necessario che le necessarie funzioni di questi strati vengano cedute direttamente ai router e agli OXC (vedi figura 1.1) .
Otterremmo così quella semplificazione che abbiamo detto essere necessaria ma anche una rete che riesce a coniugare efficienza e costi ed è in grado di trasportare un’ampia tipologia di flussi dati ed un enorme volume di traffico.
1.3Architettura di rete a due strati
- Modello di rete ottica
Consideriamo un modello di rete in cui i client (router IP/MPLS) sono collegati al nucleo ottico della rete e vengono collegati ai loro pari attraverso dei percorsi ottici commutati dinamicamente (lightpaths). L’interazione tra il client e il nucleo ottico avviene attraverso una interfaccia, ben definita, di segnalazione e di routing che viene chiamata UNI (User Network Interface). Il nucleo ottico della rete si compone di molti OXC che sono interconnessi attraverso link ottici a formare una generica topologia a maglia. Nel modello di rete che stiamo valutando gli OXC possono anche formare delle sottoreti tra loro e ognuna di queste può avere anch’essa una topologia a maglia ed essere collegata attraverso una ben definita interfaccia di segnalazione e routing chiamata NNI (Network-Network Interface).
Ogni OXC è in grado di commutare un flusso di dati da una porta di ingresso ad una di uscita. Questa funzione è controllata da tabelle di cross-connessione propriamente configurate. La connessione con un’ampiezza di banda prefissata tra due elementi della rete, come i router IP/MPLS, viene stabilita attraverso gli OXC ed è chiamata “lighpath”.
Un “lightpath” continuo è un percorso che utilizza la stessa lunghezza d’onda su tutti i link lungo l’intero percorso, dalla sorgente alla destinazione.
Il modello di rete a due strati, che mira ad una integrazione più stretta tra lo strato IP e quello ottico, offre una serie di vantaggi rispetto a quello multistrato ed il GMPLS è stato proposto come la struttura che completa ed integra lo strato IP e quello ottico.
Per esaminare le alternative architetturali proposte con i modelli a due strati (IP su rete ottica) è fondamentale distinguere tra piano dati e piano di controllo sull’interfaccia UNI.
- Il modello Overlay
In questo modello il dominio IP resta indipendente da quello ottico e fa da client inoltrando le proprie richieste di connessione allo strato ottico stesso. È come se in questo modello gli elementi interni della rete fossero nascosti e si capisce perciò la necessità di disporre di due piani di controllo differenti che esercitano una minima interazione tra loro. Un piano di controllo opera nel nucleo ottico della rete mentre l’altro gestisce le interazioni tra il nucleo e i dispositivi messi sul confine (UNI). Questi ultimi hanno la possibilità di segnalare i
vengono forniti dal nucleo in maniera statica, senza poterne vedere la topologia.
Figura 1.3 : a) modello Overlay , b) modello Peer
Tutto ciò è molto simile a quanto accade per le reti IP/ATM. Quindi questo modello impone vincoli sul controllo amministrativo tra il nucleo e il confine perché il contenuto del nucleo è effettivamente nascosto.
- Il modello peer
In questo modello un unico piano di controllo effettua le precedenti operazioni su di un dominio amministrativo che comprende sia il nucleo della rete ottica che i dispositivi messi sul confine. Gli OXC sono trattati quindi come dei router e non c’è più distinzione tra UNI, NNI ed ogni altro tipo di interfaccia tra routers. Così tutti i dispositivi utilizzati dai service providers sono a conoscenza della completa topologia della rete ottica. In questa situazione un comune protocollo di routing come l’OSPF o l’IS-IS può essere utilizzato per la distribuzione
delle informazioni sulla topologia. Gli OXC e i router seguono uno schema di indirizzamento comune.
- Il modello ibrido
Questo modello combina entrambi i modelli appena visti. Alcuni dei dispositivi di confine operano da peer condividendo lo stesso piano di controllo del nucleo della rete ottica. Altri dispositivi di confine possono avere il loro piano di controllo o una istanza separata del piano di controllo utilizzato dal nucleo della rete e interaffacciarsi con il nucleo attraverso l’UNI. Questa è una soluzione fortemente auspicata dai carrier e dai service provider perché fornisce un alto grado di flessibilità per le più diverse applicazioni e per sviluppare un modello redditizio e adatto alle loro necessità di amministrazione e di sicurezza. Da ciò che abbiamo detto si evince che il modello peer to peer contiene quello overlay ovvero che le funzioni richieste per supportare il modello overlay sono solo un sottoinsieme di quelle necessarie per implementare un modello peer. È evidente allora che invece di avere un insieme di protocolli per ogni modello è auspicabile avere un piano di controllo abbastanza flessibile che sia in grado di supportare entrambi.
A dare forza ad un piano di controllo flessibile sono gli obbiettivi di rapido provisioning , routing , monitoraggio e ripristino efficiente.
I requisiti di affidabilità rendono questi obbiettivi di prioritaria importanza soprattutto per le reti fotoniche.
Oggi i provider alla ricerca di soluzioni efficaci nel campo delle reti ottiche vogliono che ci sia una integrazione degli switch fotonici all’interno
di una rete ottica eterogenea che sappia combinare i dispositivi di prossima generazione con quelli precedenti. Risulta ancora più evidente, allora, come sia necessario giungere ad un piano di controllo comune standardizzato per fare in modo che i vari elementi di qualsivoglia generazione siano in grado di comunicare tra loro. Negli ultimi anni il routing IP si è evoluto includendo nuove funzionalità sotto l’ombrello dell’MPLS e si è lavorato per estendere l’MPLS come piano di controllo che può essere utilizzato non soltanto con i router ma anche con i dispositivi ottici come gli OXC. L’IETF sta riuscendo nell’arduo compito di standardizzare un piano di controllo comune come il GMPLS che è divenuto essenziale nell’ evoluzione di reti “aperte” ed interoperabili.
1.4 Multiprotocol Label Switching
1.4.1 Ingegneria del traffico MPLS
L’ MPLS nasce per sviluppare l’insieme dei protocolli IP in modo da rendere più rapidi ed efficienti gli schemi di forwarding utilizzati dai router IP. Prima dell’MPLS, i router hanno sempre fatto uso di schemi per determinare l’inoltro dei pacchetti ricevuti che essenzialmente si basano sull’esame dell’indirizzo IP di destinazione contenuto nell’header del pacchetto. L’MPLS ha decisamente semplificato questa funzione basando l’operazione di decisione del successivo inoltro sull’esame di una semplice etichetta . Un’altra caratteristica importante fornita dall’MPLS è quella di disporre il traffico IP su di un percorso definito attraverso la rete.
Nel tradizionale inoltro IP, il router considera due pacchetti appartenenti alla stessa FEC (classe equivalente d’inoltro) se questi hanno lo stesso prefisso nell’indirizzo IP di destinazione. Quando il pacchetto attraversa la rete viene riesaminato da ogni router che incontra sul percorso e viene riassegnato ad una FEC. L’MPLS utilizza un metodo di inoltro dei pacchetti molto più rapido che combina la velocità e le performance del livello 2 del modello OSI con la scalabilità e l’ ”intelligenza” IP del terzo livello. Come già accennato, alla base dell’MPLS si trova l’idea di associare una etichetta a tutti i pacchetti che devono ricevere lo stesso instradamento, ovvero, quando un pacchetto entra in una rete MPLS, in base all’indirizzo di destinazione viene associato ad una FEC.
Una FEC può essere vista come un insieme di pacchetti che sono inoltrati nello stesso modo attraverso la rete. Questa può includere tutti i pacchetti il cui indirizzo di destinazione eguaglia un particolare prefisso di rete IP o quei pacchetti che appartengono ad una particolare applicazione tra la sorgente e la destinazione.
Le FEC sono solitamente costruite attraverso le informazioni “apprese” attraverso un protocollo IGP come l’OSPF o IS-IS . Tutti i pacchetti che sono mappati con la stessa FEC sono indistinguibili.
È importante sottolineare che nell’MPLS l’associazione di un pacchetto con una FEC viene fatta una sola volta cioè quando il pacchetto entra nel dominio MPLS. La FEC cui è assegnato il pacchetto viene codificata con un’etichetta di lunghezza fissa. All’ingresso della rete sono i router di confine (LER, label edge router ) che esaminano i pacchetti IP ed assegnano l’etichetta. I pacchetti “etichettati ” sono poi inoltrati lungo un LSP (Label
Switched Path) dove ogni LSR (Label Switched Router) decide dove inoltrare il pacchetto basandosi sul campo-etichetta del pacchetto.
Un LSR non ha bisogno di esaminare l’header IP del pacchetto per trovare una porta di uscita ma semplicemente rimuove l’etichetta esistente e ne applica una nuova per il passo successivo. È evidente che questo meccanismo rende più veloce e semplice il forwarding dei dati. A differenza di quanto accadeva in passato, con l’MPLS si adopera una enfatizzazione della separazione tra piano di forwarding e piano di controllo.
- Il piano di forwarding è responsabile del passaggio dei pacchetti da una interfaccia di ingresso ad una di uscita utilizzando due informazioni: una tabella di forwarding (LIB, Label Information Base) mantenuta dal LSR e le informazioni trasportate dal pacchetto (label) - Il piano di controllo è responsabile della costruzione e del
mantenimento della tabella di forwarding.
1.4.2 Piano di forwarding e label
La label, in generale, viene considerata come componente di forwarding. Una label è un identificatore con una lunghezza fissa (20 bit) ed un significato locale poiché ogni LSR provvede localmente all’associazione delle label alle FEC. Questa associazione viene fatta in base all’indirizzo di destinazione del pacchetto. La label può essere trasportata dal pacchetto in modi differenti, per esempio usando parte dell’header di livello 2, come VCI o VPI negli switch ATM o inserendola tra l’intestazione del protocollo di livello 2 e livello 3 come nei router IP.
Figura 1.5 :Incapsulamento della label
Nelle reti che utilizzano la tecnologia Frame Relay la label è inserita nell’intestazione dello strato data link del pacchetto nel campo DCLI. Per le altre tecnologie è stato pensato di porre l’etichetta in uno “SHIM label header” che è inserito tra l’intestazione dello strato link e network. Per eseguire il forwarding ci sono soluzioni differenti a seconda casi .
La prima prevede l’utilizzo della NHFLFE (Next Hop Label Forwarding Entry) che viene utilizzata per l’inoltro di un pacchetto etichettato. L’NHFLE contiene le seguenti informazioni:
- Il successivo inoltro del pacchetto
- L’operazione da compiere sulla pila di etichette del pacchetto. L’operazione può essere una delle seguenti:
o Rimpiazzare l’etichetta sulla cima della pila di etichette con una nuova etichetta specificata
o Estrarre la pila di etichette
o Rimpiazzare l’etichetta in cima alla pila con una nuova etichetta specificata e poi inserire una o più nuove etichette sulla pila
- L’incapsulamento del data link da utilizzare quando viene trasmesso il pacchetto
- Il modo di codificare la pila di etichette quando si trasmette il pacchetto La seconda soluzione prevede l’utilizzo dell’ILM (Incoming Label Map) quando devono essere inoltrati pacchetti che arrivano etichettati .
L’ILM mappa ogni etichetta in arrivo in un insieme di NHLFE.
La terza soluzione è utilizzata quando si inoltrano pacchetti che arrivano senza etichetta ma che devono essere etichettati prima di essere inoltrati. Questa soluzione prende il nome di FTN (Fec To NHLFE) . La procedura di trasferimento è detta label swapping e consiste in diverse procedure a seconda che ci si trovi su un LSR di confine o interno alla rete MPLS.
- Procedura di trasferimento per un LER
I LER hanno il compito di inserire le label nei pacchetti entranti nella rete MPLS e di toglierla da quelli uscenti.
Al loro interno il forwarding dei pacchetti avviene con procedure differenti a seconda della direzione in cui viaggia il pacchetto. Nel caso di un pacchetto IP che deve entrare nella rete MPLS, il LER analizza l’intestazione e determina la FEC corrispondente.
Dalla FEC risale ad una entry della tabella di forwarding in cui trova la label d’uscita (da inserire nel pacchetto) e l’interfaccia presso cui inviarlo. Nel caso in cui consideriamo un pacchetto proveniente dalla rete MPLS e diretto verso l’esterno, la label d’ingresso del pacchetto punta ad una riga della tabella in cui il next hop indicato è ancora il LER. Il LER , allora, estrae la label ed invia il pacchetto risultante a se stesso. Il pacchetto ritorna indietro, dunque, come un pacchetto IP nativo sul quale effettuerà il forwarding basandosi sul contenuto dell’intestazione dello strato di rete.
I LER hanno, dunque, la possibilità di svolgere entrambe le procedure di forwarding: una basata sulla label (come un LSR) ed una basata sull’indirizzo di destinazione come un comune router IP.
- Procedura di trasferimento per un LSR
Il forwarding di un LSR interno alla rete MPLS è più semplice di quello di un LER. Questi dispositivi hanno a che fare solo con pacchetti già etichettati quindi non devono né inserire label per la prima volta né toglierla definitivamente.
Il LSR estrae la label e la usa come indice nella tabella di forwarding.
Quando trova la entry con label d’ingresso uguale alla label estratta dal pacchetto, prende la relativa label di uscita e la inserisce nel pacchetto, dopodichè invia il pacchetto verso l’interfaccia indicata nella riga della tabella che lo conduce verso il suo next hop il cui indirizzo è anch’esso indicato nella riga della tabella.
1.4.3 Piano di controllo : Label Distribution Protocol
Il piano di controllo ha il compito di creare e mantenere aggiornata la tabella di forwarding all’interno di un LSR.
Per fare questo sono utilizzati due tipi di protocolli :
- Protocolli standard di routing come OSPF (Open Short Path First) e BGP (border gateway protocol) per costruire la tabella di routing e venire a conoscenza della topologia della rete.
- Un protocollo per lo scambio di informazioni riguardanti le associazioni tra label e FEC (binding) con cui è stata creata la LIB (label information base). Il protocollo usato a tale scopo è il Label Distribution Protocol (LDP). Una alternativa all’utilizzo di questo protocollo è quella di adoperare un protocollo già esistente : RSVP – TE (Resource reSerVation Protocol).
- I protocolli di routing permettono di mappare ogni FEC con l’indirizzo del prossimo router da raggiungere. Le procedure per legare le etichette con FEC assieme a quelle che permettono di distribuire le informazioni relative a tali legami permettono ad ogni LSR di mappare le FEC nelle etichette.
Figura 1.6: elementi per la costruzione della tabella di forwarding
- Procedure per creare e assegnare le Label
Un LSR può decidere l’assegnamento delle etichette a disposizione alle FEC in maniera autonoma o può attendere fino a che un altro LSR gli richieda l’associazione.
Associazione FEC e next hop Procedure ordered control e indipendent control
+
Protocolli di routing OSPF PIM BGP Creazione e mantenimento+
della Associazione tabella di FEC-LABEL forwarding in un LSR Distribuzione informazioni Protocolli LDP ed RSVPQueste due procedure prendono il nome, rispettivamente di: independent control ed ordered control.
La procedura independent control prevede che ogni LSR stabilisca quali FEC prendere in considerazione e quali label associargli.
L’altra procedura prevede che l’assegnazione dell’etichetta ad una FEC avvenga da una estremità all’altra dell’LSP.
Un LSR, appartenente ad una delle due estremità del LSP, decide di assegnare una label ad una FEC ed informa il suo vicino (appartenente all’ LSP) di questo assegnamento. Quest’ ultimo farà lo stesso con il suo vicino che farà lo stesso e così via finché le label per quella FEC non saranno state assegnate lungo tutto l’ LSP.
- Procedure per la distribuzione delle informazioni FEC-LABEL Come già accennato le procedure che l’LSR utilizza per informare tutti gli altri LSR dell’associazione FEC-LABEL sono principalmente due: 1. LDP è un protocollo appositamente sviluppato che
prevede un meccanismo per la scoperta dei neighbor (vicini) e che vengano aperte delle sessioni TCP durante le quali avviene lo scambio delle associazioni FEC-LABEL. Viene scelta una connessione TCP perché è necessario che ogni informazione di mappaggio sia confermata prima di essere attivata.
Esistono tre tecniche di LDP: downstream allocation, upstream allocation e downstream allocation on demand.
2. la seconda procedura consiste nell’utilizzo di un protocollo già esistente RSVP.
L’utilizzo di questo protocollo è preferito all’utilizzo del LDP perché, essendo questo un protocollo già utilizzato, non porta ulteriori complicazioni del sistema.
1.5 Ulteriori vantaggi dell’MPLS
Nell’MPLS abbiamo un’unica procedura di forwarding ( il label swapping ) e molte procedure di routing. Per questo motivo si è resa necessaria una separazione tra piani di controllo e di forwarding che ha il vantaggio di consentire modifiche parallele ma indipendenti tra loro: è indiscusso il vantaggio di poter cambiare protocollo di routing senza che sia necessario dover cambiare l’apparato utilizzato per il forwarding.
La separazione delle informazioni di forwarding dal contenuto dell’header IP consente all’MPLS di essere utilizzato con dispositivi come gli OXC il cui piano dati non può riconoscere gli indirizzi IP.
Gli LSR inoltrano pacchetti utilizzando le label trasportate dagli stessi. Queste, associate alle porte su cui i pacchetti sono ricevuti, vengono utilizzate per determinare la porta di uscita e la label di uscita per i pacchetti stessi.
Bisogna anche considerare l’adattabilità introdotta dall’MPLS che consente diversi impieghi del paradigma di forwarding a seconda della tecnologia impiegata nello strato inferiore.
Tutto questo perché ci sono molti modi differenti per includere una label nei dati che vengono inviati come quello di vedere la label stessa come una lunghezza d’onda su cui viaggiano i dati.
Un ulteriore vantaggio dell’MPLS è fornito dal Label Stacking che può essere visto come l’ inserimento di un LSP all’interno di un altro.
Figura 1.7 :esempio di Label Stacking
Assumiamo che l’LSP assegnato al pacchetto IP tramite il LSR A sia trasportato all’interno di un altro LSP che dal LSR B va a all’LSR D passando dall’LSR C. In questo modo B diventa il LSR di ingresso per il secondo LSP e il LSR D diventa il router di confine per questo LSP. Il viaggio di un pacchetto IP attraverso il dominio MPLS può essere spiegato in questo modo:
- LSR B inserisce una nuova label nello stack inoltra il pacchetto all’LSR C
- LSR C si “accorge” che ci sono più label all’interno dello stack (può farlo tramite un flag nell’header del pacchetto che è messo al valore 1) utilizza solo la label che sta in cima allo stack.
- LSR D prende la label che si trova in cima allo stack e processa la parte rimanente del pacchetto etichettato; nel caso della figura 1.8 toglie la label ed inoltra il pacchetto all’LSR E.
Altra funzionalità importante nell’MPLS è il constraint-based-routing che, tramite opportune estensioni ai protocolli di routing e di segnalazione, permette di decidere a priori il percorso da far seguire ad un determinato flusso di traffico. Questa caratteristica potrebbe essere sfruttata sia dall’ingegneria del traffico che dalle procedure di fast rerouting, legate, queste ultime, ad un improvviso malfunzionamento della rete. In queste situazioni si ha la possibilità di decidere di reindirizzare flussi di traffico verso percorsi differenti, redirigendo così tutto il traffico che attraversava il collegamento che ha subito il malfunzionamento.
1.6 Dall’MPLS al GMPLS
Negli ultimi anni l’ IETF (Internet Engineering Task Force) ha sviluppato l’insieme di protocolli dell’MPLS con l’obbiettivo di avere un piano di controllo, il GMPLS, che potesse essere usato non solo con i router ma anche con i dispositivi che commutano nel dominio del tempo, della lunghezza d’onda e dello spazio.
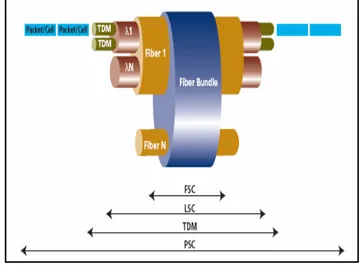
La tabella 1 espone i diversi domini ed i principali dispositivi che è possibile utilizzare.
Dominio
Switching traffico Tipo di
Schema di forwarding Esempio dispositivo Nomenclatura Pacchetto, cella Pacchetto IP, asyncronous transfer mode (ATM) Label come “shim” header, VCC(virtual channel connection) Router IP, switch ATM PSC (packet switch capable) Tempo Frame TDM/SONET Slot nel tempo che si ripete ciclicamente DCS (digital cross connect system) , ADM TDM capable
Lunghezza
d’onda Trasparente Lambda
Apparati DWDM LSC (lambda switch capable) Spazio
Fisico Trasparente Fibra OXC
FSC(fiber switch capable)
Tabella 1.1 : tipi di traffico e dispositivi nel GMPLS
I miglioramenti apportati fanno del piano di controllo comune GMPLS un componente essenziale nell’evoluzione delle reti ottiche.
Il GMPLS, infatti, semplifica le operazioni e l’amministrazione segnando una riduzione dei costi delle operazioni oltre a fornire un’ampia gamma di scenari di impiego che vanno dal peer all’overlay.
Il GMPLS consente che si possa scegliere tra peer, overlay o una combinazione di entrambi ma la scelta è indirizzata soprattutto da considerazioni di convenienza economica piuttosto che da costrizioni tecnologiche.
Allo stesso tempo la costruzione del piano di controllo comune partendo da risultati nel campo del routing e della segnalazione già acquisiti evita di
ripartire da zero per sviluppare i protocolli minimizzando allo stesso tempo i rischi che ne sarebbero derivati.
L’IETF (Internet Engineering Task Force) ha standardizzato diverse modifiche richieste dai protocolli di routing e di segnalazione allo scopo di adattarsi alle peculiarità degli switch fotonici;
Le riassumo:
1. un nuovo protocollo LMP (Link Management Protocol) progettato per risolvere i problemi legati alla gestione dei link nelle reti ottiche che utilizzano switch fotonici.
2. miglioramenti ai protocolli Open Shortest Path First/ Intermediate System to Intermediate System (OSPF/ISIS) per notificare la disponibilità di risorse ottiche all’interno della rete e tecniche per migliorare la scalabilità come la formazione di LSP gerarchici, link bundling e unnumbered link.
3. modifiche ai protocolli di segnalazione come Resource Reservation Protocol (RSVP) / Constraint-Based Routing Label-Distributed Protocol (CR-LDP) affinché permettano ad un LSP di essere specificato in maniera esplicita attraverso il nucleo ottico della rete.
La tabella che segue ha il compito di riassumere e illustrare i protocolli utilizzati nel GMPLS che vengono racchiusi in tre categorie: routine, segnalazione e management.
Tipo Protocolli Sigle
Descrizione
Routing OSPF-TE
IS-IS-TE
Protocolli di routing per scoprire la topologia di rete ed e diffondere informazioni sulla disponibilità di risorse (ampiezza di banda…)
Estensioni GMPLS: - Gerarchia LSP - Link Bundling - Unnumbered links Signaling RSVP-TE CR-LDP
Protocolli di segnalazione per stabilire LSP TE.
Estensioni GMPLS: - Suggested label
- Ridurre il soft state overhead - Efficiente gestione dei guasti - LSP bidirezionali
Link
Management LMP
- Gestione del canale di controllo - Verifica della connettività del link - Correlazione delle proprietà del
link
- Autenticazione
Tabella 1.2 : Protocolli GMPLS
1.7 Modifiche ai protocolli di routing
Le modifiche si sono rese necessarie per risolvere i problemi che seguono e che si sono verificati nel momento in cui si è cercato di utilizzare l’MPLS per controllare reti ottiche SONET/SDH e a divisione di tempo:
- Numero limitato di lambda e canali TDM
- La banda per i LSP nell’MPLS può variare in uno spettro continuo mentre quella destinata ad un canale ottico o TDM può assumere valori solo all’interno di un piccolo e discreto insieme di valori
- Poiché tra due nodi possono esserci decine di link paralleli e per supportare la crescente richiesta di banda c’è bisogno molte fibre parallele ognuna delle quali può avere centinaia di lambda, è evidente che l’elevato numero di link porta ai seguenti sottoproblemi:
o Il numero di link in una rete ottica/TDM può essere di diversi ordini di grandezza più grande rispetto ad una rete MPLS o Assegnare indirizzi IP ad ogni fibra, lambda e canale TDM è
problematico considerando l’insufficienza di indirizzi IP disponibili.
o E’ molto difficoltoso e soggetto ad errori identificare quale porta su di un elemento di rete è collegata ad un’altra su di un altro elemento di una rete vicina.
- Gerarchia LSP
All’ interno dei link state database dei protocolli OSPF ed IS-IS è possibile considerare un LSP come un link ed annidare gli LSP all’interno di altri LSP dando origine ad una gerarchia di LSP.
I Label Switched Path che entrano attraverso un nodo comune in un dominio di trasporto ottico ed escono da un nodo appartenente allo stesso dominio hanno la possibilità di essere aggregati ed inseriti all’interno di un singolo path ottico. In questo modo, sfruttando la possibilità di aggregazione, si può ridurre il numero di lambda utilizzate dai domini MPLS .
La gerarchia di LSP fornisce un aiuto anche con la natura discreta della banda di un canale ottico (in questo modo risolvo i primi due problemi esposti). Infatti, dal momento in cui per un path ottico viene stabilita ed assegnata l’ampiezza di banda, questa appartiene ad un insieme discreto di valori (ad esempio 2.488 Gbit/sec). Quando, poi, l’LSP viene considerato come un link la sua ampiezza di banda non ha più bisogno di essere considerata discreta e se al path MPLS assegniamo una banda di 100 Mbit/sec, quando attraversa il dominio ottico può essere inserito all’interno di un LSP ottico lasciando a disposizione degli altri LSP ben 2.388 Gbit/s. Esiste una gerarchia naturale che disciplina l’ ordine in cui gli LSP possono essere annidati. Essa è basata sulla possibilità di multiplexing degli LSP. Dalla figura 1.8 si può notare che gli LSP cominciano e finiscono sempre su interfacce dello stesso tipo e che i flussi PSC sono racchiusi in un flusso TDM che a sua volta è racchiuso in un flusso LSC che è racchiuso in uno FSC. Nel database dei protocolli OSPF/IS-IS, l’LSP compare come un nuovo tipo di link che ha il vantaggio di essere compatibile con i metodi esistenti di flooding utilizzati per condividere le informazioni convenzionali. In questo modo ogni nodo ha un identico link state database che contiene informazioni inerenti non soltanto ai link convenzionali ma anche agli LSP e può realizzare il calcolo del percorso.
- Link bundling
Il Link State DataBase (LSDB) si compone di tutti i nodi ed i link della rete uniti agli attributi di ogni link e, poiché il numero dei link in una rete ottica è molto maggiore rispetto a quello di una rete GMPLS, è ovvio che le sue
dimensioni diventerebbero ordini di grandezza più grandi rispetto a quelli di reti non GMPLS . Per evitare questo problema è possibile considerare i link paralleli come un collegamento unico . Questo procedimento prende il nome di “bundling” e produce un link “logico” formato da link “fisici”. Il primo è chiamato “bundled link” mentre i link “fisici” vengono chiamati “link componenti” .
Figura 1.9 : link bundling
Questa operazione, però, se da un lato migliora la scalabilità dall’altro comporta la perdita di alcune informazioni. Per questo motivo sono essenziali delle limitazioni sul tipo di informazione che può essere associata. Infatti, i link del “bundling”, oltre a dover cominciare e finire sugli stessi due LSR devono avere le seguenti caratteristiche comuni:
o Tipo del link (link punto-punto, multiaccesso)
o Resources Classes o Metrica TE
- Link “unnumbered”
Nelle reti MPLS viene solitamente assegnato un indirizzo IP a tutti i link e , quando si determina un percorso , i link che lo costituiscono sono tutti identificati dal loro indirizzo IP. Nelle reti GMPLS, però, sorge un problema nel momento in cui tra due nodi adiacenti vengono utilizzate centinaia di fibre parallele ed ognuna di queste trasporta un numero elevato di lambda. Si intuisce facilmente che il problema è legato al fatto che è impossibile assegnare un indirizzo IP ad ogni fibra o ad ogni lambda sia per la scarsità di indirizzi IP che per il carico amministrativo elevato che ne deriverebbe . Per risolvere questi problemi vengono utilizzati i link “unnumbered”. L’idea che sta alla base è quella di avere un identificativo unico dei link all’interno della rete e ciò è possibile adoperando un identificativo che distingua ogni nodo all’interno della rete ed uno che identifichi i link che escono dal nodo.
Poiché ogni nodo della rete è caratterizzato dal Router ID e le sue interfacce sono numerate localmente, la coppia <Router ID , numero interfaccia> fa al caso nostro perché grazie ad essa è possibile identificare univocamente tutti i link nella rete.
L’utilizzo degli unnumbered link ci consente di risparmiare molto in termini di carico amministrativo derivante dall’allocazione di tutti gli indirizzi IP che sarebbero stati necessari in una rete GMPLS.
L’IETF ha in questo modo dato soluzione ai problemi che abbiamo esposto in precedenza. Per quanto riguarda il terzo “sotto-problema” enunciato relativo all’identificazione delle coppie di nodi adiacenti esporremo la soluzione
data più avanti poiché questa è correlata alle funzioni del Link Management Protocol che merita una trattazione più attenta ed articolata essendo questo fautore della separazione tra le informazioni del piano di controllo e i dati dell’utente.
1.8 Modifiche ai protocolli di
segnalazione
Nell’MPLS le estensioni ai protocolli di routing (OSPF ed IS-IS) hanno permesso che i nodi potessero scambiare informazioni inerenti non solo la topologia della rete ma anche relative alla disponibilità di risorse e ai vincoli amministrativi. Acquisite le informazioni dai protocolli di routing, un opportuno modulo sviluppa il calcolo del percorso.
Dopo aver eseguito questo calcolo, i protocolli di segnalazione, come RSVP-TE o CR-LDP vengono utilizzati per distribuire le label lungo il percorso. Nel momento in cui decidiamo di utilizzare i protocolli di segnalazione all’interno di reti di trasporto ottiche andiamo incontro a difficoltà che sono state risolte estendendo i protocolli di segnalazione stessi. Questi, una volta standardizzati dall’IETF, sono rientrati nella struttura del GMPLS.
Le questioni che l’IETF si è trovata a dover risolvere sono così riassumibili :
- Necessità di avere LSP bidirezionali in una singola richiesta: i collegamenti col nucleo di una rete ottica sono solitamente bidirezionali ed è implicito che il GMPLS debba prevedere ad installare gli LSP bidirezionali.
- Necessità di avere un piano di controllo separato completamente da quello dati non più soltanto a livello logico (come avveniva nell’MPLS) ma anche a livello fisico.
Di seguito saranno esposte le estensioni fatte ai protocolli RSVP-TE ed CR-LDP e il modo in cui i concetti di connessione gerarchica interagiscono per supportare una architettura generalizzata, amministrabile e scalabile.
- LSP gerarchici
Abbiamo già visto che il GMPLS supporta gli LSP gerarchici cioè la possibilità di inserire LSP all’interno di altri LSP di ordine maggiore ed utilizzare quest’ultimo come se fosse un link tra nodi.
Innanzitutto, l’ordine maggiore o minore degli LSP è riferito alla capacità di multiplexing dei nodi. I nodi che si trovano ai confini di due regioni sono responsabili della formazione di LSP di ordine più alto e aggregano LSP di ordine inferiore.
Supponiamo, con riferimento alla figura 1.10, di avere un percorso LSP1 con una capacità trasmissiva a disposizione di 500Mbit/sec; tutti
i link che vengono attraversati dall’LSP1 devono avere una banda sufficiente a soddisfare la richiesta del primo path.
Figura 1.10: gerarchia LSP
Il router R0 classifica e mappa i pacchetti nell’ LSP1 e controlla che la capacità trasmissiva utilizzata non superi i 500Mb/s. Il router R1 inserisce LSP1 con i suoi 500 Mb/s all’interno dell’ LSP2 che dispone di una banda molto maggiore. A questo punto lo switch S2 inserisce il collegamento OC-12c, dedicato all’LSP2 , nell’LSP3 che fa uso di un OC-192 tra S2 ed O3. Lo switch ottico O3, a sua volta, prende il collegamento OC-192 e lo inoltra, attraverso l’ LSP4 sostituito da un canale WDM, verso P4. Il collegamento OC-193, che corrisponde
all’LSP3 , è inoltrato attraverso P4,P5 e P6 fino ad O7. Continuando in questo modo, O7 seleziona la lamda corretta e passa il segnale alla porta adiacente a S8 che selezionerà l’appropriato OC-12c dall’OC-192 e lo inoltrerà ad R9. Alla fine R9 prenderà i pacchetti da OC-12c e li inoltrerà verso R10.
Il processo che porta alla creazione di un LSP utilizzando le estensioni all’RSVP definite nel GMPLS è mostrato in figura 1.11. Sotto l’ipotesi che la capacità trasmissiva richiesta sia disponibile su ognuno dei link che vengono attraversati. Oltre alla formazione di LSP1, questo processo attiverà l’instaurazione dei seguenti LSP aggiuntivi:
o LSP2, una connesione STS-12c tra R1 ed R9 o LSP3,una connesione OC-192 tra S2 ed S8 o LSP4,canali WDM tra O3 ed O7
Dobbiamo sottolineare che la banda residua disponibile nell’ LSP gerarchico è comunicata attraverso l’IGP nel modo che segue:
o Il nodo R1 annuncia un link PSC da R1 ad R9 con una ampiezza di banda uguale alla differenza tra STS-12c (622 Mb/s) e i 500Mb/sec che sono stati assegnati all’LSP1
o Il nodo S2 segnala l’equivalente di 180 STS-1 di capacità trasmissiva per un link TDM.
o Il nodo O3 segnala 15 lambda disponibili ognuna delle quali ha la capacità trasmissiva pari a quella di un OC-192 per
Figura 1.11 : creazione di un LSP
- L’ etichetta suggerita
La segnalazione GMPLS consente che un’ etichetta sia suggerita da un nodo upstream. Questo è un suggerimento che può essere trascurato dal nodo downstram ma, nella maggior parte dei casi, si andrebbe incontro ad un tempo di setup più elevato e ad una allocazione non ottimale delle risorse di rete. Il suggerimento di una etichetta è particolarmente utile quando si desidera stabilire un LSP bidirezionale utilizzando coppie di interfacce di trasmissione e di ricezione sulla stessa porta fisica o quando si vuole istituire un LSP che attraversa determinati tipi di switch ottici nei quali un certo tipo di latenza sia associata alla configurazione della matrice di switching. Questa procedura è utile anche nelle sottoreti ottiche che abbiano una limitata capacità di
conversione della lunghezza d’onda ed in cui l’assegnazione della stessa può essere ottenuta dal nodo di origine di un path ottico minimizzando la probabilità di mancata richiesta a causa di rifiuto. Il concetto di etichetta suggerita permette che il nodo upstream possa cominciare a configurare la propria matrice di switch senza dover attendere che sia il nodo downstream a comunicargli una lamda. Una configurazione anticipata, ottenuta attraverso una etichetta suggerita, permette di ridurre i tempi di latenza utilizzati per stabilire un path e può essere importante per gli scopi di restoration .in cui i path hanno bisogno di essere rapidamente stabiliti. Ad ogni modo, se un nodo downstream rifiuta il suggerimento e assegna una etichetta differente all’upstream, questo deve necessariamente accettare l’etichetta specificata dal nodo downstream mantenendo così un controllo “downstram” dell’allocazione dell’etichetta. In questa situazione lo switching viene configurato in una diversa direzione e l’operazione di “binding” dell’etichetta e la propagazione del messaggio Resv/Mapping in upstream può non aver bisogno di essere ritardata ad ogni passo per poter stabilire un cammino d’inoltro utilizzabile.
- LSP bidirezionali
Si presuppone che gli LSP abbiano in entrambe le direzioni gli stessi requisiti di ingegneria del traffico includendo l’ SRLG, la protezione e
la restoration come pure gli stessi requisiti di risorse. Chiariamo prima
un po’ la terminologia dicendo che il termine initiator si riferisce ad un nodo che stabilisce un LSP bidirezionale mentre il termine terminator
si riferisce al nodo su cui termina il path stesso. Vale la pena sottolineare che in un LSP bidirezionale i nodi initiator e terminator sono unici e che nell’architettura MPLS gli LSP sono unidirezionali così , per ottenerne uno bidirezionale , è necessario instaurare due LSP bidirezionali indipendenti ed in direzioni opposte tra loro. Questo criterio comporta delle controindicazioni elencate di seguito:
o La latenza necessaria per stabilire un path bidirezionale è maggiore di quella necessaria a stabilirne uno unidirezionale ed aumenta anche il tempo che è necessario attendere per scoprire una richiesta di LSP non andata a buon fine . Questi ritardi sono particolarmente significativi quando si riscontrano guasti ed è necessario che l’ LSP venga ristabilito celermente. o L’ overhead di controllo è due volte quello di un LSP
unidirezionale perché devono essere generati messaggi di controllo separati per entrambi i segmenti di un LSP bidirezionale.
o Poiché le risorse sono stabilite in due segmenti separati, la selezione del percorso può essere piuttosto complicata e, visto che ci potrebbe essere competizione per l’allocazione delle risorse, la possibilità di stabilire con successo una connesione bidirezionale sarebbe sicuramente più bassa.
Metodi aggiuntivi sono stati definiti per consentire di avere LSP bidirezionali sia in downstream che in upstream utilizzando un singolo insieme di messagi path/request ed resv/mapping.
Questo si traduce in una riduzione della latenza di setup e nel limitare l’overhead di controllo allo stesso numero di messagi di un LSP unidirezionale.
- Messaggi di notifica
Un requisito basilare per fornire affidabilità alla rete è quello che stabilisce che la reazione ai guasti debba essere rapida e le decisioni siano prese “intelligentemente”. Un nodo di transito (dal quale cioè la connessione non ha origine né fine ) dovrebbe essere in grado di notificare il guasto ai nodi responsabili del ristabilimento del collegamento senza che nodi intermedi processino i messaggi o modifichino lo stato delle connessioni coinvolte. Questo è importante perché il processing non necessario dei messaggi può ritardare la notifica del guasto e alterare lo stato della connessione nei nodi intermedi. Nel GMPLS è stato aggiunto il messaggio di notifica all’interno del protocollo RSVP-TE che fornisce un meccanismo per informare i nodi non adiacenti dei guasti del path. Un meccanismo di questo tipo non è stato previsto nel CR-LDP che pure è presente nella struttura GMPLS.
Il messaggio di notifica non rimpiazza il messaggio d’errore RSVP ma si distingue da questo perché da la possibilità di essere indirizzato ad un nodo specifico e non necessariamente al precedente o al successivo. Una applicazione degna di nota che rafforza l’importanza di questi messaggi è la possibilità di notificare il guasto di un link del piano di controllo mentre il piano dati è ancora funzionante. Un link in queste condizioni è detto “degradato”. L’importanza di questa applicazione si comprende ancora meglio quando ricordiamo che nel GMPLS il piano di controllo e il piano
dati possono essere fisicamente diversi ed i guasti indipendenti. In molti casi è inaccettabile dover rimuovere una connessione soltanto perché il piano di controllo ha subito dei guasti . I guasti del piano di controllo possono, però, limitare le caratteristiche amministrative di un LSP come la localizzazione e il ripristino del guasto. Nel messaggio di notifica vengono identificati gli LSP interessati e vengono previsti nuovi codici d’errore per identificare i link “degradati”.
1.9 Link Management Protocol
Nel GMPLS è stata adoperata una netta separazione tra il piano dati e il piano di controllo al punto che i canali di controllo non vengono realizzati sui data links che uniscono i due nodi ma possono essere realizzati su una fibra o su una lunghezza d’onda diversa, su di un collegamento ethernet, su di un tunnel IP instradato su una differente rete di gestione o su una rete IP multi-hop. Una importante conseguenza di questo disaccoppiamento fisico tra piano di controllo e dati si ritrova nel fatto che lo “stato di salute” del canale di controllo non è più necessariamente connesso a quello dei data links e viceversa. Come sappiamo una coppia di nodi può avere migliaia di interconnessioni e, realizzando il multiplexing, ogni connessione può essere costituita da molteplici data link. Per mantenere la scalabilità, allora, i
data-link vengono combinati in un unico TE-data-link, mentre, per consentire la
comunicazione tra nodi ed eseguire routing, segnalazione e gestione del link sono necessarie due interfacce IP che siano entrambe raggiungibili. Questa coppia di interfacce costituisce il control channel (canale di controllo).
Il Link Management Protocol è un nuovo protocollo che si occupa proprio di verificare la raggiungibilità del canale di controllo oltre che di gestire il TE-link e, per risolvere le nuove questioni che derivano dalla separazione fisica del piano di controllo e dati, adotta nuovi meccanismi per la gestione dei data link, sia in termini di link previsioning che di fault management.
Figura 1.11 : LMP tra due nodi adiacenti
- Procedure del protocollo LMP
Le procedure cardine del Link Management Protocol sono il “control
channel management” e la “link property correlation”.
Il “control channel management” serve per determinare e mantenere i canali di controllo tra due nodi adiacenti. I canali di controllo possono essere utilizzati per scambiare informazioni legate al piano di controllo (“link previsioning”, “fault management”, ”path mangement” e “label distribuition”) ma anche informazioni relative alla topologia della rete. L’attivazione del canale di controllo ha inizio con lo scambio dei
parametri di negoziazione usando i messaggi Config, Config Ack e Config Nack. Per attivare il canale un messaggio di Config deve essere trasmesso al nodo remoto e, in risposta ad esso, deve essere ricevuto dal nodo locale un Config Ack . Quest’ultimo è utilizzato per riconoscere la ricezione del Config Message ed esprimere accordo su tutti i parametri di configurazione.
Il messaggio Config Nack è utilizzato per riconoscere la ricezione del Config Message ma indicando, se ci sono, quali oggetti non negoziabili del messaggio sono inaccettabili e proponendo valori alternativi per quei parametri di oggetti negoziabili. Una volta che il canale di controllo tra due nodi adiacenti è attivo, viene utilizzato il protocollo Hello per mantenerne la connettività e scoprirne eventuali guasti . Prima di inviare il messaggio Hello, il nodo locale e quello remoto si sono già accordati su due parametri: Hello Interval ed Hello
Dead Interval tramite il messaggio Config.
Ogni messaggio Hello contiene due numeri in successione: il primo (TxSeqNum) è quello relativo al messaggio Hello che è stato trasmesso mentre il secondo (RcvSeqNum) è quello dell’ultimo messaggio Hello ricevuto dal nodo adiacente su quel canale di controllo. Il TxSeqNum non può mai assumere valore pari a zero. Quando il suo valore è messo ad uno vuol dire che il nodo ha cominciato l’invio di messaggi Hello o che non ha memoria dell’ultimo TxSeqNum inviato. Così il primo Hello che viene inviato ha un TxSeqNum pari ad uno e un RxSeqNum pari a zero. Quando non ci sono problemi la differenza tra il RxSeqNum in un messaggio Hello ricevuto e il TxSeqNum che viene inviato sarà al più pari ad uno. Questi due numeri in successione, in
definitiva, permettono che ogni nodo possa verificare che l’altro sta ricevendo il suo messaggio Hello (vedi figura 1.12).
Figura 1.12 : procedura Hello
(vedi figura 1.13) che viene definita e utilizzata per la gestione del TE-link e fa uso dei seguenti messaggi : Link Summary, Link Summary Ack e Link Summary Nack. Ogni TE-link ha un identificativo (Link_ID) che è assegnato ad entrambe le estremità del link. I Link_ID devono essere dello stesso tipo (IPv4,IPv6…) ad entrambe le estremità. Se un Link Summary Message viene ricevuto con un tipo di TE-link locale diverso da quello remoto, deve essere inviato un LinkSummaryNack con il codice d’errore “ Bad TE-link object ”. Analogamente è assegnato ad entrambe le estremità del data link un identificativo chiamato “Interface_ID”. Anche in questo caso è necessario che l’identificativo sia dello stesso tipo ad entrambe le estremità del link altrimenti viene inviato un analogo “Link Summary Nack” con il codice d’errore “Bad Data Link object ”.
Oltre a verificare la consistenza del Data link e del TE-link, il Link Summary Message è utilizzato per aggregare più data link in un unico TE-link, per scambiare, correlare o variare semplicemente i parametri del TE-link e dei Data link.
È bene ricordare che il protocollo LMP richiede che una coppia di nodi abbia almeno un canale di controllo bidirezionale attivo tra loro. Ogni direzione del canale di controllo è identificata da un Ch_
Control_ID e le due direzioni sono accoppiate tramite lo scambio dell’
LMP Config Message. Tutti i pacchetti LMP vengono inviati al livello UDP utilizzando un numero di porta.
Accanto a queste due funzioni ne troviamo altre due: “link connectivity
verification” e il “fault management”.
Entrambe acquistano risalto e sono utili proprio quando canale di controllo e data link si trovano su piani separati.
La procedura “link connectivity verification” può essere utilizzata per verificare la connettività fisica dei data link e apprendere in maniera dinamica le associazioni del TE-link e dell’Interface_Id (Identificativo dell’Interfaccia). Per interconnettere due nodi è necessario che almeno un TE-link sia definito tra loro e che ci sia almeno un canale di controllo attivo tra i nodi.
La procedura di Link Verification prevede che tra due nodi ci sia almeno un Data Link. Una volta che il canale di controllo è attivo tra i due nodi, la connettività del data link può essere verificata scambiando un messaggio Test su ogni data link del TE-link. Per cominciare la procedura di verifica del link, il nodo locale deve inviare un messaggio
un Begin Verify Message ed è pronto a processare un messaggio di test, deve inviare un BeginVerifyAck al nodo locale specificando il meccanismo di trasporto da usare per il messaggio di Test. Quando il nodo locale riceve un messaggio BeginVerifyAck dal remoto, può cominciare a “testare” i data link trasmettendo un messaggio Test periodico su ogni data-link. Una volta ricevuto il messaggio Test, viene registrata l’Interface_Id e confrontata con l’Interface_Id locale relativa a quel data link e successivamente viene inviato un messaggio TestStatusSuccess. La ricezione TestStatusMessage indica che il messaggio Test è stato ricevuto dal nodo remoto ed è stata verificata la connettività fisica del data link. Quando un messaggio TestStatusSuccess viene ricevuto, il nodo locale dovrebbe contrassegnare il data link per indicare che la sua connettività fisica è regolare e mandare un TestStatusAck al nodo remoto.
Il “fault management” permette di gestire i guasti ed isolarli.
La scoperta del guasto può essere gestita dallo strato più vicino a quello del guasto stesso. Per le reti ottiche quello più vicino è lo strato fisico.
Un modo per scoprire il guasto nello strato fisico può essere quello di accertarsi che ci sia una perdita luce (LOL loss of light). Per localizzare il guasto di un particolare link tra nodi adiacenti, un nodo che si trova a valle del flusso di dati che scopre il guasto invia un messaggio Channel Status al nodo che gli sta a monte indicando che è stato trovato un guasto. Il nodo a monte che riceve il messaggio deve inviare un messaggio Channel Status Ack al nodo a valle col quale indica la ricezione del precedente messaggio.