Capitolo2 Criteri di classificazione dei segnali
2.1
Decision-Theoretic Approach
Questo metodo considera il riconoscimento come un problema da testare con ipotesi multiple e/o probabilistiche, per mezzo delle quali si effettua una selezione tra una lista di modulazione candidate. Ogni ipotesi si basa sulla formulazione e sul calcolo di una caratteristica distintiva del segnale e sul confronto di questa con opportune soglie. S’intuisce già che un primo limite di tale approccio è il numero finito di modulazioni che vengono prese in esame. Il metodo per sua stessa natura non è in grado, infatti, di identificare segnali che non appartengono alla lista, ma la classifica risultante è quella che minimizza la funzione del costo (operazionale) medio. A tale approccio sono riconducibili anche metodi molti diversi tra loro.
2.1.1 Maximum likelihood approach (ML)
Il modello generale di un classificatore a massima verosimiglianza può essere rappresentato dal seguente schema:
Pre-processing (estrazione dati) Decisore segnale X (vettore dati) ( | 1) L x H ( | m) L x H j Fig. 1: Classificatore ML
dove L x H
(
| j)
rappresenta la funzione di verosomiglianza del vettore dei dati (caratteristiche) nell’ipotesi H associata alla j-ma di j m possibili modulazioni (fig.1).Se la sequenza dei dati X k( ), k=0,1....n è indipendente ed identicamente
distribuita, le funzioni possono essere definite come:
(
) (
)
(
)
1 | | ( ) | n j j j l L x H p x H p X k H = =∏
dove p x H(
| j)
sono appunto le pdf condizionate dei dati.Per un dato vettore di caratteristiche, sono calcolate le probabilità condizionate per ogni classe e quella con la probabilità più alta viene scelta come la classe del segnale. Spesso le espressioni delle pdf sono approssimate e si assumono alcune conoscenze a priori (come il symbol rate o l’SNR).
In [24] sono confrontate tre tecniche:
a) Average Likelihood Ratio Test (ALRT): il segnale sconosciuto e i parametri di
canale sono trattati come variabili aleatorie con funzioni densità di probabilità
(pdf) conosciute e la funzione a massima verosimiglianza è mediata su queste
pdf (indicate con f p H
(
| i)
per l’i-esima classe).( )
(
(
| ,) (
) (
|)
)
| , | Hi H j i i p A A j j p f r p H f p H dp r f r p H f p H dp λ ⋅ > Λ = < ⋅∫
∫
b) Generalized Likelihood Ratio Test (GLRT): I parametri sconosciuti sono
considerati come variabili deterministiche ma ignote e rispetto a queste si massimizza la funzione a massima verosimiglianza.
( )
max(
(
|)
)
max | Hi i H j j p i G G p j f r p r f r p λ > Λ = <c) Phase and Data GLRT (Ph&D-GLRT) e Average Data-Maximum Phase
(ADMP): test ibridi in cui alcuni parametri sono trattati come in (a) altri come in (b).
Si è considerato per tutte e tre una perfetta conoscenza della durata di simbolo, dell’istante di timing e della frequenza portante, quindi r rappresenta il vettore dei
dati in uscita dal filtro adattato mentre con p il vettore dei parametri sconosciuti sotto i
l’ipotesi Hi.
Il primo test presenta un approccio più generale, ma nonostante le ampie conoscenze a priori sul segnale incognito risulta anche analiticamente più difficile. Per questo lo stesso autore ha proposto solo approssimazioni alle soluzioni ottimali come gli algoritmi quasi Log-likelihood Ratio (qLLR) [23] e il Non-Coherent
Pseudo-Maximum Likelihood (NC-PML) [28]. Le prestazioni di queste tecniche vengono
confrontate analizzando, a gruppi di due, diversi segnali digitali (M-QAM, M-PSK) . Questo tipo di approccio è particolarmente utilizzato per distinguere i numeri di livelli di una modulazione: in [25] ad esempio è ampiamente studiata la classificazione tramite qLLR (e alcune sue approssimazioni) di un segnale PSK con un numero arbitrario di livelli. Al contrario [27] hanno sviluppato un metodo applicabile a qualsiasi modulazione che presenti una costellazione di simboli. Pur mantenendo come caratteristiche discriminanti le funzioni di massima verosimiglianza, questo studio può considerarsi come punto di riferimento per un altro tipo di approccio: SHAPE RECOGNITION.
Come si può intuire, lo svantaggio di queste tecniche è che bisogna conoscere (o stimare) molti parametri per rendere il metodo realmente applicabile, ma rispetto ad altri metodi è l’unico che porta ad una soluzione “ottimale“. In [33] prima di classificare tramite un GLRT segnali BPSKvsQPSK, è presentata una tecnica di stima del livello di segnale, considerato sconosciuto. In [22] e [26], invece, è evidenziato come metodi ad hoc (M-th law, phase–based classifier) e quindi ritenuti sub-ottimi, possano essere comunque ricondotti, sotto alcune condizioni, al metodo ML.
2.1.2 Constellation Shape
E’ una tecnica per la classificazione di segnali digitali che si sviluppa dal già citato “riconoscimento di forma” presentato in [27]. La premessa di tale approccio è che se una modulazione digitale può essere univocamente caratterizzata dalla sua costellazione, dovrebbe anche essere identificabile dalla costellazione recuperata in ricezione. La forma della costellazione dei simboli è la caratteristica selettiva per la classificazione; il punto centrale del metodo diviene la sua ricostruzione. Bisogna, infatti, considerare che la costellazione ricevuta è naturalmente distorta in vari modi
sia dal ricevitore specifico che dal canale: ad esempio il rumore ne modifica i vertici mentre gli errori di fase o di frequenza della portante ne causano una rotazione. In [29] N simboli ricevuti vengono filtrati da un banco parallelo di N correlatori la cui uscita di N×2 vettori (parte reale ed immaginaria) sono l’ingresso di un algoritmo iterativo per ricostruire la costellazione. Questo algoritmo, definito fuzzy c-means, è un procedimento iterativo di raggruppamento di dati basato sulla loro minima distanza e minima varianza. Il risultato è un gruppo di punti che rappresentano la costellazione ricevuta e modellando questa come un insieme di variabili discrete binomiali, la regola di decisione è di nuovo quella ML. A differenza delle precedenti regole ML basate sulle pdf delle forme d’onda osservate, l’autore evidenzia la robustezza del metodo proposto alle degradazioni introdotte da un ambiente totalmente non-cooperativo, quale errori di fase, frequenza, timing. Inoltre il metodo è applicabile a qualsiasi modulazione rappresentabile da una costellazione.
2.1.3 Hierarchical Decision-trees
.Con quest’approccio si prendono decisioni in modo ramificato basandosi sulla relazione tra le caratteristiche discriminanti e predeterminate soglie che definiscono così i limiti di decisione. Tale metodo presenta alcuni vantaggi:
1. solitamente le decisioni sono organizzate in modo che le caratteristiche più importanti (per la distinzione dei segnali) possano essere determinate per prime: se una decisione può essere fatta “alta nell’albero”, allora non è necessario determinare tutte le altre caratteristiche.
2. il metodo gerarchico consente un approccio ibrido per fare una veloce ”grossolana” distinzione in larghe classi e poi continuare con una classificazione più “fine” in ogni sottoclasse ottenuta.
3. l’albero di decisione è una struttura che si presta bene ad una facile implementazione.
Bisogna considerare però anche gli svantaggi insiti nel metodo:
1. le decisioni possono cambiare a seconda dell’ordine in cui vengono testati i valori delle caratteristiche.
2. in generale è da considerarsi un metodo sub-ottimo (le soglie vengono scelte in modo euristico tramite simulazioni).
3. manca di flessibilità nel senso che se una nuova caratteristica o una classe di segnale è aggiunta, probabilmente sarà necessario determinare nuove soglie o perfino rivedere completamente la logica di decisione.
Nonostante questi problemi, tale approccio è quello più seguito negli ultimi tempi, forse anche per il grosso contributo dovuto ad Azzouz e Nandi [1][2][3][4].
L’albero di decisione in [1] parte nell’identificare il segnale come appartenente ad una delle tre sottoclassi: modulazione d’ampiezza, modulazione d’angolo o modulazione composita. Il primo passo non è quindi distinguere tra analogiche o digitali ma dove è contenuta l’informazione utile: per le modulazione d’ampiezza, nell’inviluppo del segnale (più precisamente si considera l’ampiezza istantanea), mentre per quelle d’angolo si trova nella fase istantanea o nella frequenza istantanea. Per le composite bisogna considerare sia l’ampiezza che la fase e la frequenza (istantanee). Ad esempio in [6] (e ripreso in [35] ) si può già trovare uno studio per classificare segnali analogici (AM, FM, SSB e DSB). Come quantità distintiva gli autori propongono il rapporto tra la varianza dell’inviluppo e il quadrato della media dell’inviluppo ( 2
2
R = σ µ ).
Infatti in assenza di rumore un segnale FM, al contrario di un AM, ha un inviluppo costante e quindi la loro distinzione tramite R dovrebbe essere marcata (R=0vsR ≠0). Il problema nasce (oltre che per l’introduzione di rumore che porterà ad inevitabili degradazioni nelle prestazioni) quando si ricevono segnali di tipo PM o FSK che verranno classificati ugualmente come FM. Questo vuol dire che l’albero di decisione non è completo ma che ha bisogno almeno di un ulteriore ramo.
In [3], invece, Azzouz e Nandi propongono nove caratteristiche derivate dallo spettro dei segnali e dall’ampiezza, la fase e la frequenza istantanea del segnale. L’algoritmo di decisione viene applicato ad un blocco di N campioni del segnale intercettato (lungo K secondi) e per ogni blocco viene presa una decisione sul tipo di modulazione. Alla fine dell’m-esimo blocco (M =Kfs/N ) vengono raggruppati i blocchi con uguale esito e viene scelta come decisione finale quella del gruppo più grande. In [1] e in [2] si possono trovare gli alberi di decisione rispettivamente per segnali analogici e digitali, con le relative formulazioni di segnali e caratteristiche distintive. Il punto cruciale del metodo è sicuramente la determinazione delle soglie, ma come già anticipato questo è anche uno dei suoi punti deboli. Il loro valore, infatti, è scelto ad
hoc e non seguendo criteri ottimali di scelta. Ad esempio in [3] il valore delle soglie viene calcolato dopo molte simulazioni, per ogni tipo di segnale, a diversi SNR (15 e 20 dB) ed è scelto in modo che si abbia ottima probabilità di corretta decisione.
Dette A e B due generiche sottoclassi da separare tramite il valore della data caratteristica KF, la regola di decisione sarà:
A x KF opt
B
>
< , xopt =arg minx
{
K x( )
}
valore ottimo della soglia.Indicando con P A x A⎡⎣
( )
| ⎤⎦ e P B x B⎡⎣( )
| ⎤⎦ rispettivamente la probabilità di correttadecisione per la sottoclasse A e B, e con P A x B⎡⎣
( )
| ⎤⎦ e P B x A⎡⎣( )
| ⎤⎦ la probabilità dinon corretta decisione per A e per B, si ha:
( )
P A x B( )
( )
|| P B x A( )
( )
|| | 1( )
|( )
| | K x P A x B P A x A P A x A P B x B ⎡ ⎤ ⎡ ⎤ ⎣ ⎦ ⎣ ⎦ ⎡ ⎤ ⎡ ⎤ = ⎡ ⎤ + ⎡ ⎤ + − ⎣ ⎦ − ⎣ ⎦ ⎣ ⎦ ⎣ ⎦Per migliorare le prestazioni gli autori hanno anche presentato un nuovo approccio basato sulle Atificial Neural Networks (ANN) [2][4][5][10]. I valori delle soglie delle caratteristiche (sostanzialmente le stesse dell’approccio precedente) sono determinati in modo automatico da due blocchi funzionali di reti neurali, ma i risultati ottenuti (di poco migliori) non sembrano così esaltanti da incoraggiare l’uso di una tecnica di tale complessità. La scelta delle ANN evidenzia ancora una volta però che il punto debole del metodo sono i valori delle soglie. Il lavoro di Azzouz e Nandi rimane comunque uno dei più completi ed efficaci nel riconoscimento di modulazione. Infatti non solo comprende molti tipi di segnali sia digitali che analogici ( in [3] e [4] sono incluse anche modulazioni MSK e QAM ), ma nella scelta delle caratteristiche usate, ingloba anche tecniche diverse tra loro e usate in precedenza ([18][6][39]). A buona ragione il loro approccio è stato quindi ripreso anche da molti altri autori, a volte modificandolo per i propri scopi, altre per portare delle migliorie nelle prestazioni. Ad esempio [9] ha utilizzato questo metodo per la rivelazione di segnali solo analogici, inserendolo in un sistema di sorveglianza. In questo caso il riconoscimento di modulazione, a cui segue una vera demodulazione, è aiutato dalla stima della direzione d’arrivo (DOA) del segnale intercettato perché la conoscenza di questa ultima aumenta l’SNR del sistema.
In [7] invece, sono presi in considerazione solo segnali digitali (ASK, PSK, FSK) testando i parametri proposti in [2] a valori di SNR più bassi e proponendo una nuova caratteristica per distinguere a tali SNR i segnali FSK da PSK. Mentre le precedenti caratteristiche sono parametri statistici, l’autore propone di considerare anche le differenze nel tempo di differenti parametri introducendo la correlazione nel tempo del valore assoluto della frequenza istantanea (C E[| f t( )|| f t( )|]
orf = −τ ).
In [36] invece sono confrontate le prestazioni ottenute con σ rispetto a quelle af ottenute con una caratteristica più semplice: la media dell’inviluppo complesso. L’interesse degli autori è quello però di dimostrare la robustezza di questo parametro nella distinzione di segnali M-FSK dagli altri segnali digitali (M-PSK, ASK) e quindi non aggiunge nulla nella classificazione di altri segnali.
Una revisione e modifica delle caratteristiche e delle soglie per abbassare l’SNR, è presente anche in [11], ma per tutti i tipi di segnali. L’albero di decisione viene ripreso per l’implementazione di un sistema di monitoraggio dello spettro per il riconoscimento di alcuni formati di comunicazione (AMPS, GSM e US Digital
Cellular). Per questo motivo gli stessi autori prendono in considerazione anche segnali
GMSK.
2.1.4 Zero-Crossing techniques
Le applicazioni di questa tecnica sono ampie e vanno anche oltre il riconoscimento di modulazione (vedremo ad esempio una sua applicazione come stimatore della frequenza di portante [7]), ora invece è proposto per classificare segnali digitali ad inviluppo costante quali MPSK e MFSK. Il campionamento zero-crossing consiste nel registrare gli istanti in cui il segnale sotto osservazione attraversa lo zero fornendo così informazioni relative alle transizioni di fase della forma d’onda. In questo modo le caratteristiche su cui basare la classificazione sono gli istogrammi della differenza di fase e gli intervalli d’attraversamento dello zero. Dal campionamento si ottiene la sequenza
{ }
ti ( sono gli istanti di zero-crossing) e da questa si ottengono:dalla prima otteniamo una misura della frequenza istantanea, mentre dalla seconda una misura delle sue variazioni da cui si stima il rapporto tra la potenza della portante e quella di rumore (CNR).
In [18][19] sono riportate le funzioni densità di probabilità per queste sequenze oltre che i metodi di stima della frequenza di portante e del symbol rate tramite zero-crossing. Anche con questa tecnica, infatti, prima del riconoscimento del segnale, è necessario avere una stima di tali parametri. Il passo successivo è quello di discriminare tra segnali a “tono singolo” (MPSK) e quelli a “tono multiplo” (MFSK) tramite la varianza della sequenza
{ }
y i( )
. La soglia di decisione è ottenuta da un test arapporto di massima verosimiglianza (LRT) così come le probabilità di sbagliata decisione. Per il calcolo della cardinalità di un segnale MPSK si ricavano istogrammi di fase dalla sequenza
{ }
ti , mentre dalla distribuzioni dei campioni{ }
y i( )
siclassifica una MFSK. Il limite del metodo zero-crossing risiede nella relativa sensibilità al rumore. Lo stesso autore sottolinea come le prestazioni decadano sensibilmente al di sotto di un CNR di 15dB. In [20] e [21] gli stessi autori propongono un algoritmo per classificare una modulazione MPSK basato sul calcolo dei momenti statistici della fase del segnale ricevuto, ottenendo prestazioni migliori a bassi CNR. Dal calcolo della funzione di densità della fase di tali modulazioni o dalla sua approssimazione tramite la funzione di Tikhonov [17] si evince, infatti, che l’n-esimo momento (con n pari) della fase è una funzione crescente con M. Gli autori mostrano però che la conoscenza fino all’ottavo momento è sufficiente per la classificazione. L’importanza delle statistiche d’ordine superiore nella classificazione sarà ripresa nel pattern recognition approach.
Considerando ancora l’identificazione di segnali digitali ad inviluppo costante, Mammone ed altri in [16] proposero un albero di decisione basato sull’estrazione della frequenza (IF) e della banda istantanee (IB) del segnale osservato, tramite un’analisi
spettrale autoregressiva: dalla media della frequenza istantanea si stima la portante e
dalla sua deviazione standard si distinguono PSK (tono singolo, piccola varianza) da FSK (multi tono, varianza larga). Dalla larghezza di banda istantanea (dalla sua media e dalla sua deviazione standard) si classificano i segnali MPSK, mentre per segnali MFSK si considera la derivata della frequenza. Il metodo si presenta come un’alternativa alla classica analisi spettrale di Fourier facilitando l’estrazione dei parametri considerati ma ottenendo buone prestazioni fino ad un CNR di 15dB.
2.2 Statistical Pattern Recognition
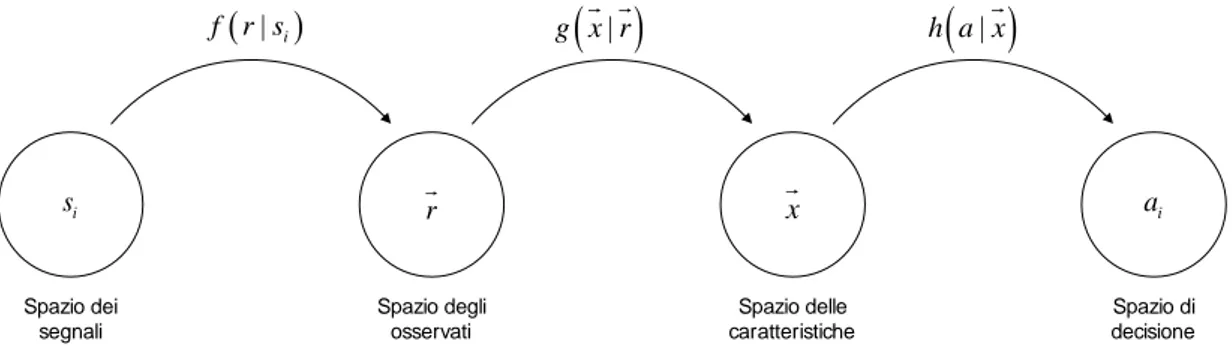
Un modello generale di quest’approccio è rappresentato in figura 2:
Spazio di decisione i s Spazio dei segnali Spazio degli osservati Spazio delle caratteristiche ( | i) f r s g x r
( )
| r( )
| h a x i a xFig. 2: Modello generale statistical pattern approach
Mentre il precedente approccio era basato su una formulazione di un test, questo si basa su una rappresentazione statistica del segnale e di alcuni dei suoi parametri. L’estrazione delle caratteristiche, infatti, non accompagna passo dopo passo l’albero di decisione (evitando di calcolarle quando non è necessario), ma viene generato un vettore di parametri (statistici) che continua a rappresentare in maniera univoca il segnale osservato e da cui, tramite alcune misure, successivamente si deciderà l’appartenenza ad un tipo di modulazione. Vengono così eliminate tutte le informazioni ridondanti presenti nello spazio dei segnali osservati riducendosi in uno spazio di dimensione minore, quello delle caratteristiche appunto. In linea generale, tale approccio ha bisogno di una lunga durata d’osservazione del segnale per la formulazione di tutto il vettore delle caratteristiche e non si presta bene ad un’analisi “real-time”. Infatti per creare un buon “spazio di decisioni” occorrono spesso molte simulazioni. Viceversa l’introduzione o l’eliminazione di una caratteristica non “travolge” l’intero processo di classificazione. Le tecniche che seguono questo tipo d’approccio differiscono soprattutto per il tipo di caratteristiche che prendono in considerazione e per le procedure di decisione introdotte. Per mantenere una trattazione lineare distingueremo i vari metodi a secondo del dominio di appartenenza delle caratteristiche estratte: tempo, frequenza o tempo-frequenza.
2.2.1 Time Domain Features
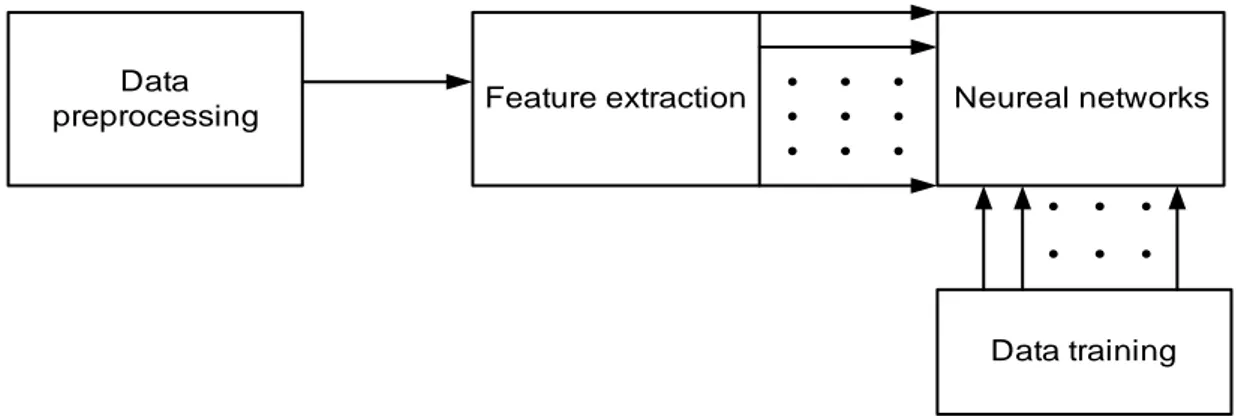
Come in molti casi precedenti l’inviluppo complesso rimane uno dei parametri più importanti per il riconoscimento di modulazione. In [32] è presentato un nuovo metodo d’estrazione dell’inviluppo per segnali analogici che evita il calcolo della trasformata di Hilbert, minimizzando la complessità computazionale. Partendo da questo ricava due parametri che congiuntamente formano un piano di decisione in cui si riescono a distinguere i segnali anche a bassi CNR ( 7 dB ). L’intero metodo è confrontato con quello in [6], che è basato sulla formulazione di un solo parametro. In [31], partendo dalla conoscenza della sola frequenza di portante e lavorando quindi con segnali in banda base, si classificano invece modulazioni digitali (QAM, PSK, FSK). Per ognuna di queste viene data una formulazione statistica di alcuni parametri: l’indice di kurtosi dell’inviluppo, l’istogramma della fase (pdf e sue approssimazioni), la media del valore assoluto della frequenza. Il processo di classificazione è affidato ad un “fuzzy classifier”, ottenendo buoni risultati fino ad un SNR di 5dB. Un maggior approfondimento su fuzzy classifier e le sue applicazioni nel pattern recognition si può trovare in [30], precedentemente già citato con il metodo a massima verosimiglianza. In [30], infatti, si confrontano i due metodi sottolineandone i punti comuni e la maggior robustezza del pattern recognition quando non si conoscono a priori alcuni parametri. Bisogna sottolineare, però, che per un fuzzy classifier, sono necessari dei dati di “training” (il più lunghi possibile), prima di un loro effettivo utilizzo. Analogo discorso può essere fatto per i metodi che introducono le “reti neurali“ (Neureal
Networks) come decisore, già introdotte da Azzouz e Nandi. Questi metodi possono
essere rappresentati dal modello di fig. 3:
Data
preprocessing Feature extraction Neureal networks
Data training
Le caratteristiche su cui si basa la classificazione sono spesso quelle già utilizzate in altri metodi. In [3] e [5] il blocco di reti neurali è introdotto in alternativa all’albero di decisione per migliorare le prestazioni. A partire da questi studi molti autori si sono concentrati sull’utilizzo delle reti prendendo in considerazione molti altri parametri (in [67] ad esempio il vettore delle caratteristiche è di 31 elementi), a scapito naturalmente della semplicità computazionale che un sistema di classificazione richiede.
HOS (Higher order statistics)
Abbiamo già detto come le informazioni contenute nelle HOS possano facilitare la distinzione di alcuni tipi di modulazioni a bassi SNR e come si prestino ad un albero di decisione, ma tipicamente esse schematizzano in modo efficiente i segnali e sono state quindi ampiamente utilizzate come spazio delle caratteristiche in un pattern
recognition approach. Il metodo di [34], ad esempio, si basa sulla rappresentazione del
segnale nel piano complesso tramite estrazione delle componenti in fase e quadratura. Come caratteristiche per l’identificazione di segnali M-FSK, M-PSK, QAM, si considerano combinazioni lineari dei momenti congiunti (di vario ordine) della fase e dell’ ampiezza, fornendo una “immagine I-Q” del segnale. Tali momenti risultano resistenti alle degradazioni introdotte dal rumore, da un angolo di fase e da una ampiezza di segnale incogniti. Questo studio sviluppa il lavoro in [21], dove però ci si fermava al calcolo del momento d’ottavo ordine e della sola fase, ora invece è necessario il calcolo di una matrice di ordine elevato che aumenta notevolmente la complessità operazionale. In [42] vengono invece utilizzate le funzioni di correlazione di ordine superiore (HOC, Higher Order Correlation) per la rivelazione e l’identificazione di segnali M-FSK. Lo scopo degli autori è doppio: il primo è quello di proporre le HOC come strumento d’approssimazione delle funzioni a massima verosimiglianza, riprendendo quindi l’approccio decision-theoretic, ma considerando una struttura con frequenza stabilita. Il secondo invece è introdurre un classificatore che si basi su informazioni fornite da misure fatte strettamente nel dominio delle HOC (provvedendo cioè ad una completa caratterizzazione statistica del segnale) e dimostrare la maggior robustezza rispetto al primo metodo (che ricordiamo è quello “ottimo”) in presenza di offset di frequenza. In [43] inoltre, il metodo è riproposto considerando incogniti gli istanti d’arrivo del segnale e introducendo quindi degli
offset temporali. Nuovamente il confronto delle performance dei due approcci mostra la maggior robustezza del pattern recognition.
2.2.2 Frequency domain features
Molti segnali reali, a causa di alcune trasformazioni periodiche in fase di trasmissione, manifestano forte ciclostazionarietà (cioè media e autocorrelazione sono funzioni periodiche). Questa proprietà può essere sfruttata nell’identificazione del tipo di segnali prendendo in considerazione lo “spettro ciclico”, invece del normale spettro di potenza che fornisce una misura della correlazione tra le componenti frequenziali del segnale. Ad esempio tipi diversi di segnali PSK (come QPSK e BPSK) che hanno uno spettro di potenza identico, possono avere invece uno spettro ciclico molto differente. L’estrazione di caratteristiche dallo spettro ciclico inoltre presentano maggior robustezza al rumore e alle varie interferenze. In fase di preprocessing, quindi, è utile introdurre anche il calcolo dello spettro ciclico del segnale la cui onerosità computazionale può essere ridotta tramite i vari algoritmi proposti in [44][45]: il FFT
Accumulation method (FAM) e lo Strip correlation Algorithm (SSCA). Lo spettro
ciclico è definito come la trasformata di Fourier della funzione di autocorrelazione ciclica:
( )
/ 2(
) (
)
2 2 1 lim T 2 2 j t x T T R x t x t e dt T α τ τ ∗ τ − πα − →∞∫
+ −( )
{
( )
}
( )
j2 f x x x Sα f Rα τ ∞ Rα τ e− π τdτ −∞ =F =∫
dove α è detta cicle frequency e per α=0 si ottiene rispettivamente la classica funzione di autocorrelazione e la densità spettrale di potenza.
Le proprietà di questa “correlazione spettrale” sono state spesso considerate per rivelare o intercettare deboli segnali immersi in rumore o in presenza di interferenti ([46][47]), ma più recentemente sono state utilizzate anche per l’identificazione dei segnali: in [48] viene mostrata la diversità tra gli spettri di vari segnali digitali e analogici, in [52] si estraggono alcune caratteristiche dallo spettro ciclico e si affida il compito di classificazione ad una rete neurale.
Con l’assunzione della ciclostazionarietà dei segnali da trattare, si possono ridefinire gli stessi parametri d’ordine superiore dei segnali stazionari come ad esempio i cumulanti d’ordine n-esimo detti, in questo caso, cyclic cumulants (CC). Basandosi sull’estrazione di queste ultime caratteristiche, in [49] si cerca di affrontare il problema dell’identificazione in modo generico, con l’assunzione di tutti i parametri sconosciuti e soprattutto con la presenza nello stesso canale di più segnali da identificare. Lo studio di Spooner ([49][50]) si presenta come uno dei pochi in letteratura a prendere in considerazione anche l’interferenza prodotta da segnali contigui e ad affrontare il problema della classificazione nella sua generalità. Naturalmente l’inconveniente di questo metodo è l’eccessiva complessità operazionale, matematica e concettuale necessaria per il calcolo di tutti i cumulanti (almeno fino al sesto ordine per riuscire a discriminare gli interferenti). Maggiori dettagli sulla teoria dei cumulanti ciclici e sulle loro applicazioni si possono trovare in [48].
2.3 M-th Law non-linearity
Alcune delle tecniche presenti in letteratura non possono essere ricondotte in modo rigoroso ad uno dei due precedenti approcci. Reichert e Schreyogg ad esempio proposero di compiere alcune trasformazioni non lineari all’inviluppo complesso del segnale prima di effettuare l’estrazione delle caratteristiche. Nel pre-processing quindi bisogna includere trasformazioni come l’elevazione al quadrato e alla quarta potenza. In [54] è mostrato infatti come lo spettro di potenza di tali trasformazioni sia distintivo per alcuni tipi di modulazione digitali (M-PSK, FSK, MSK). In realtà questo è un metodo parallelo al calcolo dello spettro ciclico, per evidenziare le periodicità nascoste (dette anche periodicità d’ordine superiore perchè non sono visibili con lo spettro di potenza) dei segnali ciclostazionari. La simmetria rispetto all’origine delle costellazioni dei segnali si traduce in uno spettro di potenza pressoché piatto (ad es. QPSK e BPSK hanno uguale spettro). L’elevazione del segnale cerca di ottenere un segnale con una costellazione non più simmetrica che si traduce in righe spettrale (la mancanza di simmetria produce una componente continua) nei multipli della frequenza di portante: lo spettro del quadrato di una BPSK presenterà dei picchi a 2f , c
l’elevazione alla quarta potenza di un QPSK invece a 4f (il quadrato di una QPSK c
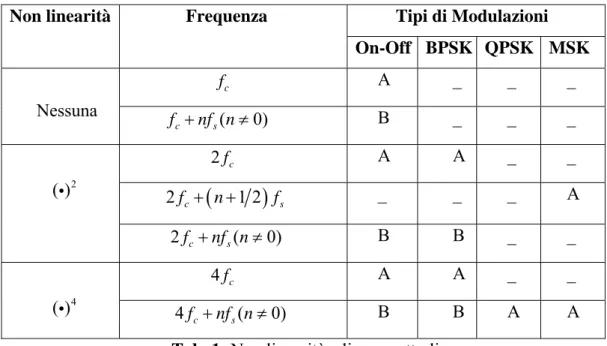
infatti non è ancora sufficiente perché la sua costellazione è simile a quella di una BPSK) . Questo metodo diventa quindi anche una tecnica per stimare la frequenza portante di un segnale. Inoltre, a secondo del tipo di modulazione, gli spettri del segnale trasformato (cioè dopo la non linearità), presenteranno anche delle righe spettrali a multipli della frequenza di sinbolo che quindi con opportuni accorgimenti può essere stimata. Nella tabella sottostante (tab. 1) sono riportate le linee generate nello spettro dopo l’applicazione delle non linearità, per alcune modulazioni:
Tab. 1: Non linearità e linee spettrali
Con “A” si indicano linee pressoché indipendenti dalla forma dell’impulso di trasmissione, con “B” invece quelle linee che sono strettamente legate al tipo di impulso.
La creazione di un vettore di caratteristiche si basa sulla rivelazione di tali linee e perciò l’autore calcola la loro probabilità di rilevamento e la loro probabilità di falso allarme (causata ad esempio da linee di segnali interferenti). L’operazione di classificazione consiste nel formulare per ogni tipo di modulazione dei modelli di Markov (propriamente Hidden-Markov-Models, HMM) i quali aumentano la robustezza riducendo la probabilità di falso allarme, ma rendono l’intero sistema più lento e complesso rispetto alla semplice formulazione di un algoritmo tipo
decision-theoretic (vedi [53]).
Tipi di Modulazioni Non linearità Frequenza
On-Off BPSK QPSK MSK f c A _ _ _ Nessuna ( 0) c s f +nf n≠ B _ _ _ 2f c A A _ _ 2fc+
(
n+1 2)
fs _ _ _ A ( )i 2 2fc+nf ns( ≠ 0) B B _ _ 4f c A A _ _ ( )i 4 4fc+nf ns( ≠ 0) B B A A2.4 Time –Frequency Methods
Tutte le tecniche trattate finora, a prescindere dall’approccio utilizzato, propongono di ottenere le informazioni per l’identificazione trattando il segnale o nel dominio del tempo o in quello della frequenza tramite le trasformate di Fourier. Per segnali ciclostazionari si è già visto come tali analisi non siano in grado di rappresentare tutte le proprietà presenti nei segnali. L’introduzione di trasformazioni bidimensionali nel dominio tempo-frequenza (vedi [55]) consentono invece di descrivere in modo congiunto l’andamento dell’energia del segnale al variare del tempo e della frequenza. Tali trasformate, dette appunto distribuzioni tempo-frequenza, permettono infatti di stabilire “quando” il segnale presenta alcune componenti frequenziali. Per un segnale stazionario, cioè indipendente dal tempo, non si hanno informazioni aggiuntive rispetto alla classica trasformata di Fourier, ma con segnali non-stazionari si ottiene una rappresentazione più chiara delle loro caratteristiche. L’interesse iniziale di queste trasformazioni (oltre che matematico) era rivolto allo studio, la rivelazione e classificazione di segnali transitori o transienti di vario tipo trovando varie applicazioni in diversi campi scientifici. Negli ultimi decenni anche nel mondo delle comunicazioni sono state introdotte tecniche (sia in fase di analisi dei segali che in quella di sintesi) basate sulle rappresentazioni tempo-frequenza.
Oltre che in applicazioni radar come rilevamento e intercettazioni di segnali LPI (Low Probability of Interception), molti studiosi hanno cercato di utilizzare le proprietà di queste trasformate per classificare e identificare i moderni tipi di modulazione. In tale contesto le rappresentazioni tempo-frequenza si presentano come un utile strumento per estrarre nuove e più robuste caratteristiche su cui basare il procedimento di classificazione con alcuni degli approcci precedenti. La rappresentazione del segnale nel piano del tempo-frequenza è ottenuta tramite la trasformata di Wigner-Ville:
( )
, 2 2 2 jf x W t f x t τ x t τ e π τdτ ∞ ∗ − −∞ ⎛ ⎞ ⎛ ⎞ = ⎜ + ⎟ ⎜ − ⎟ ⎝ ⎠ ⎝ ⎠∫
Basandosi sulla rappresentazione ottenuta gli autori definiscono alcune distanze nel piano in grado di dare una misura dei cambiamenti nel tempo e nella frequenza. Le prestazioni di queste distanze (dette indici di stazionarietà) e i vari errori di stima sono testati al variare dell’SNR. La stessa trasformata è utilizzata in [56] per estrarre la
decisione per classificare segnali FSK, FM, SSB e BPSK. La Wigner-Ville è infatti una delle trasformate più utilizzate nell’analisi dei segnali perché provvede ad una buona localizzazione nel tempo di una particolare frequenza e una buona localizzazione in frequenza di una particolare componente temporale. La distribuzione di più di due segnali, però, genera alcuni artefatti, detti cross-term, e quindi spesso per l’identificazione sono usate versioni modificate di questa trasformata dette
Pseudo-Wigner-Ville (PWV) e definite come:
( )
,( )
2 2 2 jf x PWV t f x t τ x t τ h τ e π τdτ ∞ ∗ − −∞ ⎛ ⎞ ⎛ ⎞ = ⎜ + ⎟ ⎜ − ⎟ ⎝ ⎠ ⎝ ⎠∫
La scelta del filtro e soprattutto la sua larghezza deve essere tale da poter ottenere il miglior compromesso tra semplicità ed efficienza nel ridurre i termini interferenti. In [8] con tale trasformata si ottiene una buona rappresentazione del segnale nel dominio del tempo-frequenza e viene evidenziato come le informazioni aggiuntive di questo dominio sopperiscano a quelle della sola frequenza. Infatti mentre per distinguere tra modulazioni FSK e quelle PSK-QAM è sufficiente stimare l’energia media del segnale tramite la densità spettrale, per la successiva distinzione tra PSK e QAM è necessario capire come cambia l’energia del segnale nel tempo. Per questo motivo non può essere usata un’analisi spettrale, ma si ricavano delle funzioni dal dominio tempo-frequenza. Gli autori mostrano come queste stesse funzioni siano in grado di cogliere anche le discontinuità generate dalle transizioni tra i simboli del segnale modulato e quindi forniscono una stima della durata del simbolo. Gli autori formulano quattro funzioni statistiche confrontando le loro prestazioni nella classificazione e nella stima del symbol rate ad un SNR di 0, 5 e 10 dB. Naturalmente la Wigner-Ville (o le sue versioni filtrate) non sono le uniche trasformate tempo-frequenza proposte per l’identificazione dei segnali. Per estrarre le informazioni della fase e del segnale in [58] è presentato un approccio tipo pattern recognition basato sulla distribuzione incrociata di Margenau-Hill (CMHD) definita come:
( )
(
) ( ) ( ) (
)
2 , 1 , 2 j f x y CMHD t f x t τ y t x t y t τ e π τdτ ∞ ∗ ∗ − −∞ ⎡ ⎤ =∫
⎣ + + − ⎦L’autore considera y t( )=ej2π τfc e quindi propone un metodo di stima della frequenza
di portante per poi calcolare la funzione q t
( )
=|CMHD t f( , = fc) | che evidenzia i cambiamenti di fase (e quindi le informazioni ad essa relative). La tecnica proposta risulta robusta sino ad un SNR di 10dB per la classificazione di alcuni segnali digitali(MPSK, QAM, FSK, On-Off). Infine in [60] viene riproposto l’albero di decisione di [3] ma utilizza come rilevatore di segnale e come stimatore della frequenza istantanea la versione discreta della Short Time Fourier Transform (STFT):
( ) (
)
2 ( 1) ( , ) , 0,..., 1 k n L j m L m n STFT n k x m w m n e k L π + − − = =∑
− = −dove w n
( )
rappresenta una finestra d’analisi definita per n da 0 a L-1.Al contrario delle altre trasformazioni tempo frequenza la STFT(f,t) non provvede ad una rappresentazione compatta del segnale perchè equivale ad un’analisi spettrale di Fourier ripetuta ad intervalli regolari nel tempo (la finestratura). La STFT, pur non creando cross-term non fornisce contemporaneamente una buona rappresentazione nel tempo (con l’uso di una finestra larga) e nella frequenza (con finestra stretta) e bisogna quindi lavorare nuovamente con un compromesso. In [59] è presentato un confronto tra varie distribuzioni tempo-frequenza nell’analisi di un segnale FSK, evidenziando le diverse prestazioni in riguardo la buona rappresentazione del segnale nel piano tempo-frequenza e la formazione di termini interferenti. Da [59] si evince inoltre che la scelta della migliore distribuzione dipende dal tipo di segnale sotto analisi e dal successivo utilizzo. In alternativa ai limiti di tutte queste trasformate ha trovato largo utilizzo nell’analisi e sintesi di segnali la trasformata Wavelet. A differenza delle STFT, questa trasformata utilizza una finestra di lunghezza variabile e non fissa in modo da ottenere buona risoluzione temporale ad alte frequenze e buona risoluzione frequenziale a basse frequenze, nel rispetto del “Principio d’Incertezza”. Questa proprietà rende la wavelet ideale per la rivelazione e l’analisi di segnali transienti, come ad esempio quelli generati dalle transizione di simbolo. Rispetto inoltre alle altre trasformate (che sono di tipo quadratico) la wavelet è una trasformazione lineare e quindi non genera
cross-term. La loro capacità di ben localizzare le transizioni del segnale può essere
quindi utilizzata come stima del simbol-rate [62], ma naturalmente la wavelet si presenta anche come un buon strumento per l’identificazione del segnale. Consideriamo per prime le applicazioni con la trasformata wavelet continua (CWT) di
x(t) definita come: CWT a b( , ) 1 x t( ) t b dt a a ψ +∞ ∗ −∞ − ⎛ ⎞ = ⎜ ⎟ ⎝ ⎠
∫
a≠ 0dove la funzione ψ(t) (la nostra finestra) è detta wavelet madre, mentre a è detto
fattore di scaling (legato all’inverso della frequenza). Più propriamente avremo quindi
una rappresentazione nel dominio tempo-scaling e non nel dominio tempo-frequenza. In [64] si considera 1 0,5 0 1 0 0,5
( )
{
per t per tt
ψ
− < < − < <=
e 0 altrove,detta funzione di Haar.
Basandosi su questa funzione si calcolano i coefficienti HWT(a,b) e tramite l’ampiezza e la varianza di tali coefficienti si discriminano i segnali FSK da PSK. L’andamento dell’ampiezza |HWT(a,b)| per segnali PSK è quasi costante, presentando picchi quando si ha un cambiamento di fase, mentre per gli FSK è a gradini. Eliminando i picchi si ha che la varianza della prima è quasi zero, mentre per la seconda è molto più grande. Per distinguere una QAM invece bisogna considerare |HWT(a,b)| del segnale ricevuto e quella dello stesso normalizzato rispetto all’ampiezza. In [64] è mostrato come per segnali FSK e PSK i due andamenti siano uguali, mentre per i QAM la prima è costante con picchi e la seconda a gradini. L’identificatore è quindi formato da due rami paralleli (uno analizza il segnale ricevuto e uno il segnale normalizzato) che confluiscono in un blocco di decisione (fig.4).
Il numero di questi picchi rappresentano una stima della cardinalità per MPSK e il numero di gradini (cioè livelli costanti) quella di un MFSK.
|HWT| filtraggio Calcolo varianza |HWT| filtraggio Calcolo varianza Blocco didecisione FSK PSK QAM >0 <0 >0 >0 <0 <0
-SOGLIA Normalizz. ampiezzaFig. 4: Classificatore tramite Wavelet Transform
In [63], tale metodo è ripreso, proponendo la versione discreta della trasformata wavelet e della funzione di Haar che ben si presta ad un’implementazione digitale. Un diverso metodo di classificazione per questi tipi di modulazion sempre tramite wavelet è presentato anche in [68].
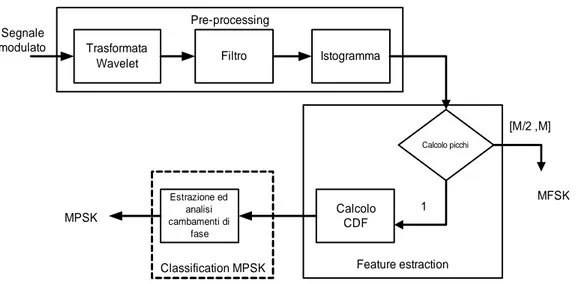
La figura successiva (fig. 5) sintetizza l’algoritmo:
MFSK Trasformata
Wavelet Filtro Istogramma
Calcolo CDF Estrazione ed analisi cambamenti di fase Calcolo picchi 1 [M/2 ,M] MPSK Segnale modulato
Classification MPSK Feature estraction Pre-processing
Fig. 5: Algoritmo di decisione per segnali PSK/FSK tramite trasformata Wavelet
La distinzione tra modulazioni FSK-PSK si basa sul numero dei picchi presenti nell’istogramma dei coefficienti della trasformata wavelet del segnale. Per una modulazione PSK si ha solo un picco (i coefficienti, tranne che nei cambiamenti di fase, sono costanti) mentre per una M-FSK si hanno M/2+1 oppure M picchi. La classificazione di una M-PSK si basa invece sul calcolo della funzione di distribuzione cumulativa (CDF) dei coefficienti per meglio analizzare ed evidenziare i cambiamenti di fase dei segnali. Le prestazioni di tale metodo degradano ad uno SNR minore di 10dB. Grazie allo sviluppo di algoritmi di calcolo veloci, le wavelets risultano uno strumento oltre che efficace, anche relativamente semplice e soprattutto veloce per un automatica identificazione del segnale.
Per una presentazione rigorosa e per ulteriori informazioni sulla teoria delle wavelets, le sue applicazioni e le sue implementazioni, si rimanda a [61] e agli altri riferimenti riportati. Infine consideriamo un nuovo tipo d’approccio che cerca di congiungere e sfruttare le proprietà delle wavelets con il calcolo dell’entropia d’informazione. In [69] ad esempio si cerca di ottenere una migliore classificazione di segnali BPSK/QPSK considerando appunto come caratteristica l’entropia di sorgente di segnali reali, dopo che questi sono stati decomposti da un’analisi wavelet. L’utilizzo della distanza entropica come metodo di decisione per due tipi di modulazione è presentato anche in [70] dove le prestazioni di questa tecnica sono confrontate con quelle di una tecnica basata sul calcolo della funzione di coerenza.