CAPITOLO 4
VALIDAZIONE DEL SIMULATORE DI GUIDA
4.1 Definizioni
4.1.1 Validazione
Il concetto di validazione di un simulatore di guida è estremamente complesso e abbraccia diverse discipline: in letteratura viene visto come il processo attraverso il quale si verifica
il modo in cui il simulatore riproduce un ambiente comportamentale o come la capacità di provocare nell’operatore lo stesso tipo di risposta che questi avrebbe fornito in una reale situazione.
Una definizione più completa e recente indica, invece, la validazione di un simulatore come un processo composto da una componente fisica, che rappresenta la capacità di un simulatore di riprodurre gli stimoli sensoriali presenti in un ambiente reale, e di una comportamentale, basata sul confronto delle azioni del conducente nell’ambiente virtuale e nella realtà [1].
In definitiva, per dimostrare la validità di un sistema di simulazione è necessario far riferimento a due fattori principali, vale a dire la validità percettiva, rappresentativa del confronto tra la percezione del movimento al simulatore ed in una situazione reale, e la cosiddetta validità comportamentale relativa, che permette di confrontare gli effetti della variazione di alcuni parametri ambientali (strada, veicolo, condizioni di traffico) sul comportamento di guida [2].
Al di là delle suddette definizioni, che rappresentano un riferimento generale, il grado di validità di un simulatore va stabilito necessariamente in funzione del tipo di studi a cui lo stesso è destinato.
4.1.2 Malessere da simulatore
Il malessere da simulatore è un problema riscontrabile in tutti i simulatori di guida ed è provocato, generalmente, dall’interazione di due o più fenomeni rappresentati da:
- elevato ritardo tra le azioni del guidatore e le reazioni del simulatore: il guidatore, cioè, prosegue la sua azione per un tempo maggiore del solito per cui, quando il simulatore reagisce, il movimento risulta troppo ampio;
- sistema di moto del simulatore che produce movimenti nell’area del mal d’auto, vale a dire frequenze intorno a 0,2 Hz ed accelerazioni superiori a 0,2 m/s2;
- mancato sincronismo tra sistema visivo e sistema di moto: nasce un disorientamento nel conducente dovuto alla mancata corrispondenza tra ciò che viene proiettato ed il ritorno di forza ai comandi.
Il malessere dipende moltissimo da come il simulatore di guida è stato progettato e si manifesta sotto forma di nausea, che persiste anche per un certo periodo dopo la fine del test [3].
E’ altresì importante distinguere tra malessere da moto e da simulatore: il primo potrebbe infatti rappresentare un ulteriore parametro di verifica del grado di realismo raggiunto nel caso in cui si verifichi sia in ambito reale che virtuale. Il malessere da simulatore, al contrario, è un grosso problema da risolvere in quanto intacca i risultati dei test.
4.2 PROCESSO DI VALIDAZIONE DEL SIMULATORE DI GUIDA
In base alle definizioni precedentemente riportate nasce l’esigenza di definire quegli indici che meglio si prestano ad essere utilizzati come termine di confronto tra le azioni eseguite da un conducente in ambito reale e quelle eseguite dallo stesso conducente in ambiente virtuale. In base a quanto riportato in letteratura le tre variabili più importanti da analizzare per validare un simulatore sono senza dubbio la velocità di guida, la posizione laterale e l’angolo di sterzo.
Considerato che, attualmente, il simulatore di guida utilizzato è su piattaforma statica con unico canale frontale di proiezione video e che si prevedono studi legati alla percezione visiva del tracciato ed al comportamento degli utenti in ambito urbano, si è pensato di eseguire il processo di calibrazione del sistema sulla base dei dati di velocità e di angolo di sterzo.
La scelta del sito di studio è ricaduta su un’area all’interno del Comune di Rosignano Marittimo (LI), ubicata, in particolare, nell’abitato di Rosignano Solvay; i motivi di questa scelta sono legati alla disponibilità di un database molto dettagliato della rete stradale (rilievi di traffico, di velocità, fotografici, della segnaletica e della incidentalità) e alle relative caratteristiche geometriche e funzionali che ben si prestano a tutta una serie di future analisi particolareggiate.
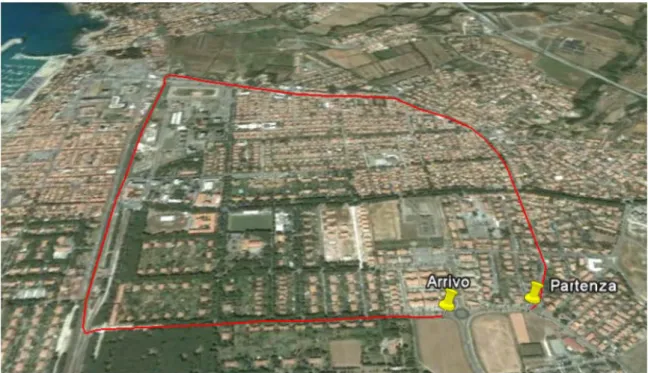
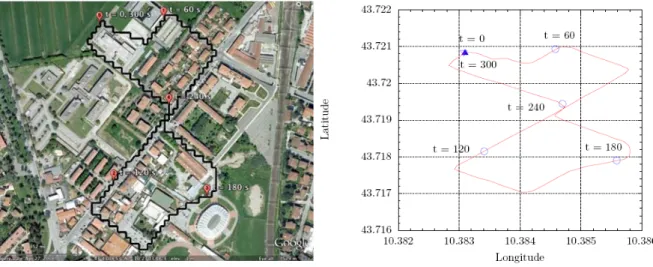
L’analisi dei dati disponibili ha portato alla individuazione di un percorso, riportato in Figura 1, opportunamente selezionato in base alla presenza di una varietà di scenari più o meno complessi, utili per differenziare i comportamenti degli utenti alla guida nelle fasi successive dell’analisi.
Figura 1: Percorso individuato all’interno di Rosignano Solvay per l’esecuzione dei test con veicolo strumentato
L’intero percorso è stato suddiviso in 8 sezioni omogenee, le cui estremità sono rappresentate da tutti quei punti locali (semafori, rotatorie, attraversamenti ecc) dove i conducenti sono costretti ad agire sul veicolo per evitare conflitti con gli altri veicoli della strada.
Lo studio sperimentale è consistito nella esecuzione di test di guida, con veicolo strumentato prima e con simulatore di guida in una fase successiva, da parte di un campione di n°94 soggetti rappresentativi di una fascia di popolazione compresa tra i 18
ed i 35 anni. I soggetti sono stati selezionati tra i residenti della città di Pisa, con origine, estrazione sociale e formazione culturale differente.
La sperimentazione è stata condotta in ore di scarso traffico (tra le 14 e le 17), in modo da evitare il condizionamento dei drivers da parte di altri veicoli, i quali hanno potuto viaggiare alla velocità desiderata, tenendo ovviamente conto dei limiti di velocità.
Per tenere conto della non abitudinarietà degli utenti è stato eseguito, per ogni soggetto testato, un giro di ricognizione prima di eseguire le relative registrazioni. Tutti i test eseguiti sono stati eseguiti nei mesi di Settembre ed Ottobre 2009.
4.2.1 Il veicolo strumentato
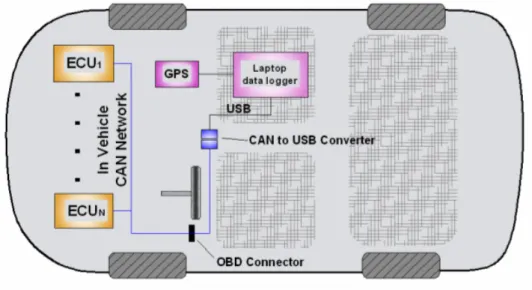
La campagna di test in scala reale è stata condotta utilizzando un’autovettura modello Fiat Grande Punto, 1300 cc, 90 CV. La misura dei parametri cinematici sfrutta il fatto che tali informazioni, acquisite dai sensori di bordo, sono disponibili sulla rete CAN (Controller Area Network) del veicolo (Figura 2). Quest’ultima risulta accessibile dal connettore di diagnostica OBD (On-Board Diagnostic), presente su tutte le autovetture di recente immatricolazione e, secondo normativa, facilmente raggiungibile dalla posizione del guidatore [4] [5] [6].
Figura 2: Layout strumentazione di bordo
Rispetto all’approccio classico, nel quale il veicolo viene strumentato con sensori esterni e con la relativa elettronica di acquisizione, la metodologia adottata per la misura dei parametri cinematici risulta di più semplice e veloce utilizzo e decisamente più
economica; di contro, il controllo su accuratezza e frequenza di campionamento dei dati è minore, in quanto tali parametri sono determinati dalle caratteristiche dei sensori di bordo e dalle modalità di trasmissione dei messaggi CAN contenenti i segnali di interesse.
Occorre comunque osservare che i dati acquisiti dal veicolo offrono una precisione pienamente adeguata al monitoraggio del comportamento alla guida e hanno il significativo vantaggio di essere coerenti con le informazioni presentate al guidatore dalla strumentazione di bordo.
Il sistema di acquisizione risulta perciò semplice e caratterizzato solo dai seguenti componenti (Figura 3):
- laptop dotato di un applicativo software dedicato per la decodifica in tempo reale dei messaggi CAN e la visualizzazione e registrazione dei dati di interesse;
- CAN-USB interface, che converte i segnali CAN presenti sul connettore OBD in un formato gestibile dal laptop;
- GPS Receiver per l’acquisizione dei dati di posizione e velocità assolute.
Figura 3: Strumentazione di bordo
È opportuno osservare che il connettore OBD (Figura 4), normalmente utilizzato per fornire informazioni di autodiagnostica relative ai sottosistemi di bordo, nella presente applicazione è usato come punto di accesso alla rete CAN del veicolo.
Le informazioni relative allo stato del veicolo transitano sulla rete CAN codificate in un formato “proprietario” del costruttore dell’autovettura. Si rende perciò necessaria una fase preliminare di test, in cui i segnali di interesse sono individuati e decodificati, attraverso la determinazione dei relativi fattori di scala.
Figura 4: Connettore per OBD
Dopo tale fase preliminare condotta sulla autovettura selezionata per i test, il sistema di acquisizione è risultato in grado di registrare in modo continuo e per tutta la durata della prova i seguente segnali: velocità istantanea, distanza percorsa, angolo di sterzo, posizione dei pedali del freno e dell’acceleratore, pressione nel circuito idraulico di frenatura, n°giri motore e apertura valvola a farfalla.
A questi dati il sistema aggiunge e memorizza i dati ricevuti da un dispositivo GPS, quali latitudine, longitudine, velocità e direzione.
Il software dedicato è stato sviluppato specificatamente per questo progetto presso il Dipartimento di Ingegneria dell’informazione dell’Università di Pisa, utilizzando l’ambiente di programmazione LabVIEW (Figura 5). L’applicativo sviluppato ha una struttura modulare ed è in grado di gestire l’acquisizione in tempo reale dei differenti flussi dati e di fornire un primo strumento per l’elaborazione offline dei dati acquisiti. In particolare, il valore di ogni segnale di interesse, decodificato dai dati grezzi ricevuti, è memorizzato su un file insieme al relativo timestamp (per ogni campione sono utilizzati al massimo 40 caratteri).
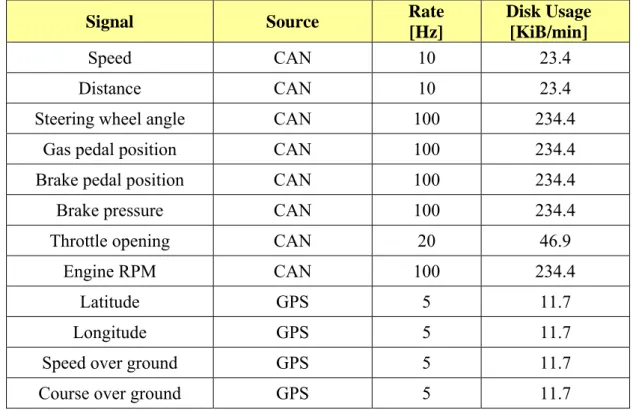
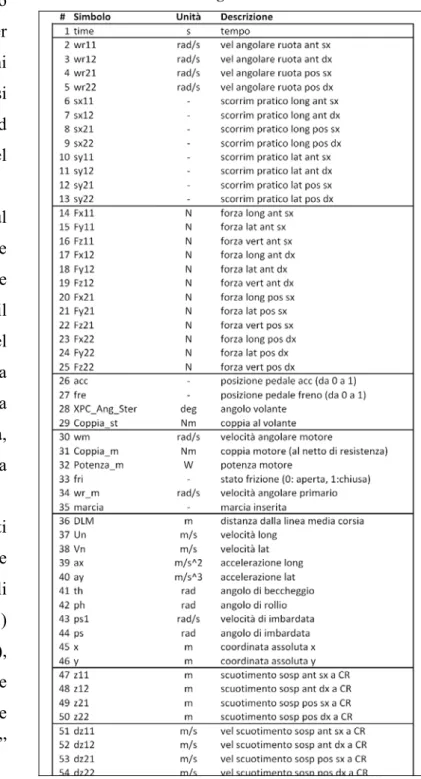
Nella Tabella 1 sono mostrati i segnali registrati, con la relativa frequenza di acquisizione e l’occupazione di spazio su HD per minuto di prova.
La memorizzazione dei segnali riportati in Tabella 1 comporta un’occupazione massima di spazio su HD pari a circa 1.3 MiB per minuto di prova. Considerando come durata della singola prova 10 min, si ha un’occupazione di spazio su HD di circa 13 MiB a prova. Le dimensioni di un HD standard risultano perciò pienamente adeguate a contenere i dati relativi a tutta la campagna di prove condotte sui 94 utenti. Si osserva infine che la scelta di sviluppare un applicativo dedicato in ambiente LabVIEW conferisce flessibilità al
sistema di acquisizione, che può essere facilmente esteso per incorporare altre sorgenti dati, quali sensori per la misura di parametri fisiologici o webcam, utile per il monitoraggio dei comportamenti del guidatore complementari alle azioni di guida.
Al termine di un test, per ciascun segnale di interesse è stato memorizzato un file, in formato testo, contenente i valori acquisiti con i relativi timestamp, prodotti dall’orologio interno alla sorgente del segnale. Per facilitare la successiva analisi dei dati, l’applicativo sviluppato fornisce uno strumento per la sincronizzazione temporale dei dati registrati. In particolare, l’applicativo si preoccupa di annullare un possibile disallineamento tra gli orologi delle due sorgenti dati (i valori di due segnali campionati nello stesso istante dalle due sorgenti possono essere registrati con due timestamp differenti).
Tabella 1: Descrizione dei segnali acquisiti Signal Source Rate
[Hz]
Disk Usage [KiB/min]
Speed CAN 10 23.4
Distance CAN 10 23.4
Steering wheel angle CAN 100 234.4
Gas pedal position CAN 100 234.4
Brake pedal position CAN 100 234.4
Brake pressure CAN 100 234.4
Throttle opening CAN 20 46.9
Engine RPM CAN 100 234.4
Latitude GPS 5 11.7
Longitude GPS 5 11.7
Speed over ground GPS 5 11.7
Course over ground GPS 5 11.7
Un'efficace soluzione a tale problema si ottiene sfruttando il fatto che entrambe le sorgenti, la rete CAN del veicolo e il ricevitore GPS, contengono la stessa informazione, ossia la velocità di avanzamento del veicolo. Attraverso la cross-correlazione dei due segnali velocità, ciascuno riferito alla propria origine del tempo, è possibile valutare lo sfasamento tra i due orologi, con il quale riallineare temporalmente tutti i segnali prodotti dalle due sorgenti dati. Il valore per il quale il segnale di cross-correlazione è massimo fornisce la differenza di fase tra i due segnali omologhi e quindi lo sfasamento tra i due
orologi. Questa soluzione assume che lo sfasamento tra i due orologi rimanga costante durante tutta la prova. In realtà tale ipotesi è ben supportata dall’elevata accuratezza relativa degli oscillatori sui quali si basano gli orologi interni delle due sorgenti dati utilizzate. L’orologio del GPS deriva da sistemi di riferimento atomici e quindi con accuratezze dell’ordine della parte per miliardo; nel breve periodo (decine di minuti) l’orologio quarzato del PC portatile presenta un’accuratezza di poche decine di ppm, giustificando una variazione complessiva nella fase tra i due sistemi, per l’intera durata della prova (10 min), inferiore a poche decine di millisecondi, valore che risulta pienamente accettabile per l’applicazione. Inoltre, a conferma di ciò, si può osservare che il massimo della cross-correlazione tra i due segnali omologhi è prossima all’unità.
Una volta eseguita la procedura di allineamento, il software permette di ricampionare tutti i dati, originariamente acquisiti a differenti rate, con un’unica frequenza di campionamento adeguata per le successive analisi e generare un unico file in formato spreadsheet con i dati sincronizzati e ricampionati.
4.2.2 Calibrazione del sistema di acquisizione
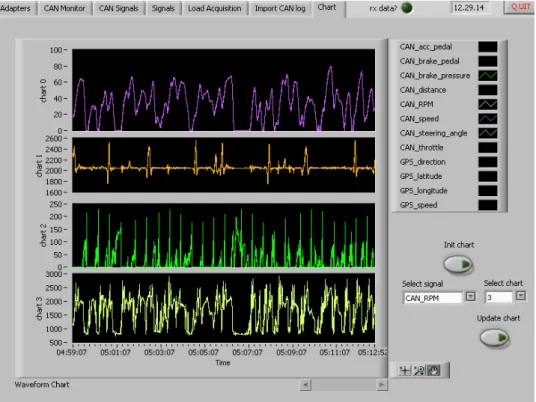
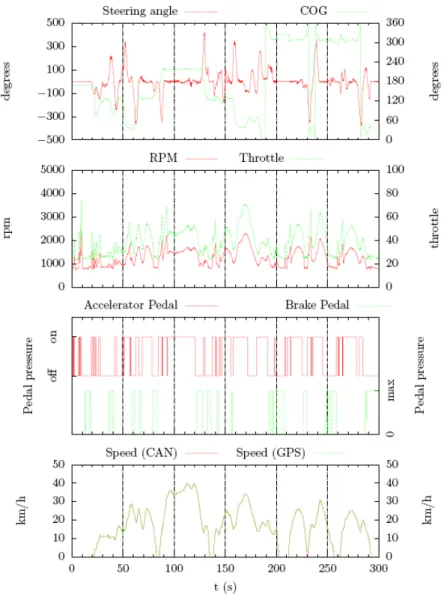
I dati trasmessi dalla centralina del veicolo sono stati prima di tutto decodificati e trasformati secondo opportuni fattori di scala individuati attraverso delle sessioni di prova. La Figura 6 e la Figura 7 riportano, ad esempio, i risultati di una sessione di acquisizione effettuata sulla FIAT Grande Punto, nei dintorni del Dipartimento di Ingegneria dell'Informazione dell'Università di Pisa, necessaria, appunto, a riconoscere ed individuare i fattori di scala delle grandezze circolanti sulla rete CAN del veicolo [7].
Figura 6: Percorso individuato per il riconoscimento dei segnali
In particolare, la Figura 6 mostra l'andamento nel tempo di alcuni segnali significativi decodificati dai messaggi presenti sulla rete CAN, insieme alle informazioni ricevute dal ricevitore GPS. Si osserva che, grazie agli accorgimenti adottati nell'acquisitore, i segnali provenienti dalle due sorgenti dati (rete CAN e ricevitore GPS) risultano perfettamente sincronizzati, come è possibile verificare sul grafico più in basso della Figura 6, che mostra il segnale velocità decodificato dal relativo messaggio CAN_Speed (CAN), sovrapposto a quello ricevuto dal GPS_Speed (GPS).
Per indagare la generalità dell'approccio proposto, la campagna di prove condotta con la FIAT Grande Punto è stata ripetuta per una Toyota Auris, ottenendo risultati simili a quelli ottenuti per l'altra autovettura e confermando quindi la bontà della procedura proposta. In sintesi, dunque, il sistema di acquisizione così definito, permettendo di registrare semplicemente un ampio insieme di dati su un veicolo di serie, rappresenta un efficace strumento di calibrazione dell'ambiente di simulazione progettato: il confronto tra i dati
simulati e quelli reali, relativi ad analoghi percorsi di guida, può infatti fornire utili indicazioni per la messa a punto dei parametri del simulatore e per futuri sviluppi, che ne accrescano il realismo. In particolare, si rende possibile la verifica rigorosa che i comportamenti di guida al simulatore siano rappresentativi di quelli reali.
Figura 7: Andamento di alcuni segnali acquisiti durante i test di calibrazione del sistema
4.2.3 Acquisizione dati sul campo e da simulatore
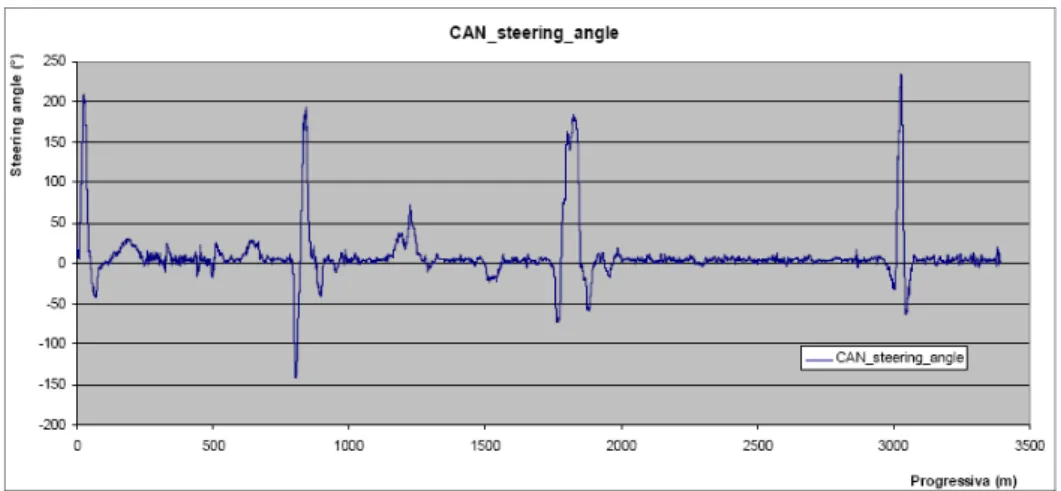
Eseguita questa preliminare operazione di messa a punto del sistema di acquisizione, si è proceduto alla esecuzione delle registrazioni, come già descritto precedentemente, lungo il percorso individuato nell’abitato di Rosignano Marittimo (Li) ottenendo, per ogni conducente soggetto a test di guida, due grafici (Figura 8 e Figura 9) rappresentativi delle variabili velocità ed angolo di sterzo.
Figura 8: Profilo di velocità misurato sul campo
Figura 9: Angolo di sterzo misurato sul campo
La variabile accelerazione è stata ottenuta per derivazione del profilo di velocità.
Conclusa la fase di acquisizione in ambiente reale con veicolo strumentato, si è proceduto ad una fase di controllo e di pre-processing dei dati, consistente in pratica nell’applicazione di filtri che hanno consentito di eliminare il rumore e rendere i dati registrati idonei alla fase di elaborazione.
A questo punto si è passati alla seconda fase consistente nella predisposizione del laboratorio di simulazione virtuale e nella esecuzione dei test di guida al simulatore. Prima di procedere alla esecuzione dei test è stato necessario riprodurre in realtà virtuale il percorso individuato nell’abitato di Rosignano Solvay, eseguito con un grado di accuratezza funzione degli studi condotti.
Nello scenario grafico, pertanto, sono state riprodotte fedelmente le intersezioni a rotatoria e quelle semaforizzate e sono stati introdotti gli attraversamenti pedonali rialzati: in quest’ultimo caso, trattandosi di un simulatore a base fissa, si è tenuto conto della loro presenza solo da un punto di vista di percezione visiva, simulando perciò un rallentamento nelle loro vicinanze.
In aggiunta a questi particolari lo scenario si caratterizza anche per la presenza di veicoli e pedoni indipendenti ed autonomi, che si muovono su percorsi random ed aumentano il grado di realismo del sistema.
Le acquisizioni effettuate sul campo sono state ripetute nell’ambiente simulato mediante una campagna di prove presso il Laboratorio di simulazione del Dipartimento di Ingegneria Meccanica, Nucleare e della Produzione dell’Università di Pisa, registrando i 54 segnali riportati a lato (Tabella 2).
Ai fini della calibrazione sono stati utilizzati, facendo sempre riferimento alla Figura 9, i segnali relativi all’angolo di sterzo (n°28) e alla velocità longitudinale (n°37), diagrammati di seguito in funzione della progressiva, desunta dalle coordinate assolute “x” e “y” (segnali n°45 e n°46).
Tabella 2 Elenco dei segnali acquisiti con il simulatore di guida
Per ognuno dei 94 volontari sono stati registrati i suddetti segnali; di seguito si riporta un diagramma rappresentativo del segnale velocità (Figura 10):
velocità 0 10 20 30 40 50 60 70 80 0 500 1000 1500 2000 2500 3000 3500 Progressiva (m) Ve lo c it à ( k m /h ) velocità
Figura 10: Profilo di velocità acquisito tramite simulatore di guida
Come è evidente dalla Figura 10 e dalla successiva Figura 11, in cui il segnale da simulatore viene sovrapposto a quello ottenuto da veicolo strumentato, l’andamento del segnale risulta molto simile per l’ambito reale e quello simulato, e porta quindi a pensare che il sistema, nelle attuali condizioni, abbia raggiunti un buon grado di realismo.
Confronto Reale-Simulatore 0 10 20 30 40 50 60 70 0 500 1000 1500 2000 2500 3000 Progressiva (m) V e lo c ità (k m /h ) Simulatore Reale
Figura 11: Sovrapposizione diagramma delle velocità reale/simulato per singolo utente
Per avere un riscontro sulla affidabilità dei dati acquisiti è necessario però procedere ad un’analisi statistica di validazione delle variabili in esame.
4.2.4 Validazione basata sui valori di velocità
I dati di velocità risultanti dalle prove reali e da simulatore sono stati analizzati per verificare il comportamento dei conducenti e capire se le risposte fornite in ambiente virtuale sono compatibili con i comportamenti reali desunti dall'esperienza di guida in scala reale [8].
I soggetti hanno innanzitutto eseguito una fase di training lungo il percorso di prova per diversi minuti prima dell'inizio della raccolta di dati effettivi, in modo da prendere confidenza con il sistema.
Un certo numero di soggetti, per lo più donne, hanno dichiarato di aver avuto sintomi correlati al cosiddetto “malessere da simulatore”.
Per questioni puramente logistiche, i soggetti hanno eseguito dapprima le prove in ambito reale e, successivamente, quelle simulate.
Ai fini dell’analisi statistica sono stati considerati i valori medi nello spazio ed i picchi di velocità riscontrati per ogni sezione omogenea; questi ultimi, in particolare, si ritengono particolarmente idonei ed attendibili a valutare la percezione della velocità durante la prova simulata e a discriminare lo stile di guida dei diversi conducenti.
Una descrizione delle analisi statistiche utilizzate per la validazione è presentato qui di seguito utilizzando la seguente notazione:
• m = numero di misurazioni di velocità istantanea effettuate (velocità di picco e velocità di approccio a rotatorie ed attraversamenti pedonali rialzati);
• n = numero di soggetti che hanno eseguito il test sia in ambito reale che virtuale; • i = pedice indicante il driver specifico, i = 1, 2 ,3, ….., n;
• j = pedice indicante la specifica sezione di misura di velocità istantanea, j = 1, 2,
3,…., m;
• dij = differenza di velocità tra il simulatore e le misure sul campo per l’i-esimo driver
alla j-esima sezione;
• dj = media delle differenze di velocità tra il simulatore e le misure sul campo per ogni
driver alla j-esima sezione; • dj,c= valore critico per dj;
• F = apice indicante le misure eseguite sul campo; • S = apice indicante le misure eseguite al simulatore;
• v = misurazioni di velocità (km/h);
• mjF = media delle velocità misurate sul campo per la popolazione di driver (km/h) alla
j-esima sezione;
• mjS = media delle velocità misurate al simulatore per la popolazione di driver (km/h)
alla j-esima sezione;
• Dj = differenza di velocità (variabile random) tra ambito reale e virtuale alla j-esima
sezione (km/h);
• mDj = media della distribuzione di probabilità di Dj (km/h);
•
j
d
σ = errore standard della stima di dj (km/h);
•
j
d
s = deviazione standard del campione (stimatore di j
D
σ ) (km/h); • zc = valore critico di z;
• D = valore di soglia per la definizione di ipotesi alternative (km/h); • a = probabilità (rischio) di rifiutare l’ipotesi nulla vera;
• b = probabilità (rischio) di accettare la falsa ipotesi nulla.
Al termine della procedura di acquisizione si ottengono due matrici di dimensione [n x m]. L’analisi della distribuzione dei valori di velocità per il dato reale e per quello simulato, per ogni sezione j, evidenzia come questi tendano, nella maggior parte dei casi, a distribuirsi secondo una gaussiana: la Figura 12 di seguito riportata, relativa ad una generica postazione di misura (sezione omogenea n.1), non fa altro che supportare l’assunto di velocità distribuite normalmente.
A questo punto è stato definito un opportuno test statistico allo scopo di valutare l’affidabilità del sistema virtuale in relazione alle differenze tra le misure eseguite in ambito reale e quelle da simulatore, per le due popolazioni di dati, in ogni postazione di misura individuata.
L’ipotesi statistica è stata formulata stabilendo che tra le misure reali e quelle simulate non ci debba essere alcuna differenza: i dati delle due matrici sono stati quindi utilizzati per corroborare tale ipotesi o respingerla. Ognuna delle due conclusioni prevede un certo rischio/probabilità di non essere corretta: tale affermazione è legata al fatto che, pur essendo la dimensione del campione (n = 94) consistente per il test statistico, la differenza
media dj delle velocità tra il simulatore e le misure sul campo, per ogni driver alla
j-esima sezione, non sempre presenta una distribuzione di tipo normale, comportando dei rischi accettabili di conclusioni errate.
vel F req ue nc y 30 40 50 60 70 80 0 5 10 15 20 25 V F req ue nc y 40 50 60 70 80 0 5 10 1 5 20
Figura 12: Distribuzione delle velocità di picco misurate sul campo e in ambiente virtuale in due sezioni omogenee
Per ogni postazione di misura j = 1, 2, 3,…., m sono state definite le cosiddette ipotesi nulle H0 e le rispettive ipotesi alternative H1:
0 : 0 = − = F j S j Dj H μ μ μ 0 : 1 = − ≠ F j S j Dj H μ μ μ j = 1, 2, 3,….., m
L’ipotesi alternativa può essere espressa anche nella seguente forma: Δ > − = F j S j Dj H1: μ μ μ
dove D è una soglia di velocità opportunamente individuata per definire il grado di affidabilità e di verosimiglianza del sistema.
La differenza di velocità media di tutti i driver alla postazione j-esima è stata calcolata attraverso la formula:
(
)
∑
∑
= = − = = n i F j i S j i n i j i j v v n d n d 1 , , 1 , 1 1L’errore standard di dj viene approssimato utilizzando la deviazione standard del campione s : dj n sdj j d = σ
mentre il valore critico d , relativo ad un errore del I Tipo (rigetto dell’ipotesi nulla Hc 0)
che si verifica con una probabilità α, è definito da:
n s z
dc = 1−α/2 dj
La probabilità di un errore del II Tipo (accettazione di una ipotesi nulla falsa) è β, e può essere determinata attraverso la relazione:
(
)
dj c s n d zβ = −ΔLa regola di decisione per poter accettare l’ipotesi nulla H0, vale a dire affermare che non
esistono differenze sostanziali tra i valori di velocità misurati sul campo e quelli acquisiti al simulatore, è rappresentata da:
Accetto H0 se −dc ≤dj ≤dc
Rifiuto H0 se dj >dc.
4.2.5 Analisi dei risultati.
La tabella di seguito riportata (Tabella 3) mostra le velocità misurate in una determinata sezione della tratta omogenea n.1 per ognuno dei driver che hanno partecipato ai test reali e simulati.
I valori delle differenze osservate (Tabella 3) tendono a distribuirsi secondo una gaussiana (Figura 13) con media del campione d = -2,22 e deviazione standard pari a 1 s = 5,39. d1
Scegliendo a = 0,05, z1-a/2 = z0,975 = 1,96, il valore critico d sarà dato da: c
= = − n s z d di c 1ε/2 1,09.
Histogram of V V De n s it y -15 -10 -5 0 5 10 15 0. 00 0 .0 2 0. 04 0. 0 6 0 .0 8
Figura 13: Distribuzione delle differenze osservate
Dal momento che di <dc l’ipotesi nulla H0 è rifiutata in corrispondenza della sezione
considerata.
Ponendo pari a D = 1,80 km/h il valore di soglia che definisce l’accettazione dell’ipotesi alternativa,
(
−Δ)
= = j d c s n d zβ -1,28si ottiene una probabilità di commettere un errore di Tipo II (accettazione di una falsa ipotesi nulla) pari a b= 10%.
Un intervallo di confidenza per la definizione della effettiva differenza tra le medie delle velocità μDj, tra le misure in sito e quelle al simulatore, è ottenuto attraverso la seguente
relazione: n s z d dj j ± 1−α .
ID Driver V reali [km/h] V simulate [km/h] Differenze [km/h] 1 58.69 58.08 -0.61 2 66.20 58.16 -8.04 3 45.23 47.45 2.22 4 46.33 48.94 2.61 5 60.31 55.10 -5.21 6 53.92 48.97 -4.95 7 61.22 58.96 -2.26 8 63.55 60.02 -3.53 9 53.23 54.20 0.97 10 50.12 42.48 -7.64 11 43.92 49.34 5.42 12 57.16 54.35 -2.81 13 61.60 61.20 -0.40 14 67.44 68.71 1.27 15 61.07 54.83 -6.24 16 52.42 49.65 -2.77 17 59.85 55.27 -4.58 18 60.70 53.44 -7.26 19 51.10 54.27 3.17 20 53.18 53.56 0.38 21 65.20 60.25 -4.95 22 53.62 55.79 2.17 23 53.23 49.87 -3.36 24 56.75 60.80 4.05 25 68.33 55.49 -12.84 26 72.04 62.90 -9.14 27 60.49 51.00 -9.49 28 63.70 51.36 -12.34 29 52.70 51.95 -0.75 30 55.12 54.72 -0.40 31 56.20 60.01 3.81 32 63.26 66.18 2.92 33 73.13 67.38 -5.75 34 55.86 56.30 0.44 35 54.27 60.59 6.32 36 50.22 53.84 3.62 37 48.23 52.83 4.60 38 48.53 47.15 -1.38 39 51.58 49.09 -2.49 40 70.58 68.81 -1.77 41 80.38 77.80 -2.58 42 66.93 60.88 -6.05 43 67.59 62.67 -4.92 44 46.53 51.14 4.61 45 47.70 52.52 4.82 46 65.80 61.81 -3.99 47 54.57 53.28 -1.29 48 60.30 51.44 -8.86 49 60.14 46.73 -13.41 50 50.75 53.55 2.80 51 58.93 53.51 -5.42 52 50.74 63.27 12.53 53 50.84 55.57 4.73 54 66.43 61.50 -4.93 55 65.61 63.17 -2.44 56 75.07 61.42 -13.65 57 74.88 63.89 -10.99 58 69.73 69.41 -0.32 59 66.46 62.74 -3.72 60 48.37 51.20 2.83 61 55.00 53.00 -2.00 62 57.08 57.78 0.70 63 69.50 64.87 -4.63 64 60.47 58.31 -2.16 65 80.57 73.52 -7.05 66 52.00 56.80 4.80 67 52.40 60.94 8.54 68 51.91 53.98 2.07 69 64.88 61.80 -3.08 70 51.67 46.89 -4.78 71 52.33 48.12 -4.21 72 50.42 48.51 -1.91 73 51.45 49.20 -2.25 74 63.10 53.98 -9.12 75 72.92 65.67 -7.25 76 69.84 62.43 -7.41 77 72.03 58.05 -13.98 78 65.32 63.42 -1.90 79 59.00 62.52 3.52 80 55.73 57.59 1.86 81 68.31 63.15 -5.16 82 51.37 48.04 -3.33 83 44.40 47.53 3.13 84 56.15 64.03 7.88 85 66.03 63.62 -2.41 86 57.21 49.10 -8.11 87 66.00 50.56 -15.44 88 61.30 59.48 -1.82 89 62.58 58.30 -4.28 90 49.03 48.75 -0.28 91 56.12 55.12 -1.00 92 52.00 55.13 3.13 93 52.69 51.19 -1.50
Tabella 3: Velocità di picco osservate nella Sezione omogenea n.1 e differenze per utente
In Tabella 3 sono riportati 93 valori di velocità in quanto un dato si presentava rumoroso e non è stato considerato ai fini dell’analisi.
Le tabelle relative alle altre sezioni sono riportate alle pagine successive con l’indicazione dei rispettivi intervalli critici e la definizione dei valori di affidabilità. In particolare, nella Tabella n.4 vengono riportati gli intervalli di confidenza al 95% ed al 99% per la postazione appena esaminata, mentre nella successiva Tabella n.5 sono riportati i soliti intervalli per ognuna delle 8 postazioni individuate. Come si può evincere da queste tabelle, il “test t-paired” porta al rifiuto della ipotesi nulla in ognuna delle sezioni omogenee esaminate, ad eccezione della n.3 e della n.7 (per α = 0,05) e della sezione n.4 (per α = 0,01), ragion per cui è possibile affermare con estrema precisione, data l’elevata potenza del test, che esiste una differenza tra le osservazioni reali e quelle simulate.
Tabella 4: Intervalli di confidenza per la Sezione omogenea n.1 Risk
α
Affidabilità 100(1-α)%
Intervallo di confidenza per
F j S j Dj μ μ μ = − 0,01 99% 93 39 , 5 58 , 2 22 , 2 ± ⋅ − -3,66 < m D < -0,78 0,05 95% 93 39 , 5 96 , 1 22 , 2 ± ⋅ − -3,31 < m D < -1,13
Tabella 5: Intervalli di confidenza e probabilità di errore del II tipo per le 8 sezioni omogenee (velocità massime sulle tratte omogenee)
Sez. Omogenea H0 accettata con (Y/N) β Probabilità di errore del II tipo (%) Intervallo di confidenza 95% [km/h] Intervallo di confidenza 99% [km/h] α = 0,05 α = 0,01 1 N N 10 (-3,32; -1,13) (-3,66;-0,78) 2 N N 24 (-4,41; -1,75) (-4,83; -1,33) 3 Y Y 10 (-1,20; 1,00) (-1,54; 1,35) 4 N Y 13 (-2,57; -0,27) (-2,93; 0,09) 5 N N 17 (-4,67; -2,24) (-5,05; -1,86) 6 N N 7 (-1,5;, 0,48) (-1,91; 0,80) 7 Y Y 18 (-5,07; -2,61) (-5,46; -2,23) 8 N N 24 (-5,47; 2,82) (-5,89; -2,40)
La stessa operazione è stata ripetuta per i valori di velocità media nello spazio ottenuti per ogni tratta omogenea esaminata ed ha fornito i risultati evidenziati in Tabella 6.
Tabella 6: Intervalli di confidenza e probabilità di errore del II tipo per le 8 sezioni omogenee (velocità media) Sez. Omogenea H0 accettata con (Y/N) β Probabilità di errore del II tipo (%) Intervallo di confidenza 95% [km/h] Intervallo di confidenza 99% [km/h] α = 0,05 α = 0,01 1 N Y 8 (-2,80; -0,26) (-3,21; 0,14) 2 Y Y 41 (-2,95; 0,40) (-3,48; 0,93) 3 Y Y 11 (-0,13; 2,51) (-0,55; 2,93) 4 N N 44 (-6,09; -2,64) (-6,64; -2,10) 5 Y Y 10 (-2,75; -0,14) (-3,16; 0,27) 6 Y Y 7 (-0,56; 1,89) (-0,95; 2,28) 7 N N 42 (-6,74; -3,33) (-7,28; -2,80) 8 N N 24 (-6,79; -3,61) (-7,29; -3,11)
La tabella evidenzia, in pratica, quanto già visto per le velocità di picco con l’unica eccezione della sezione omogenea n.2 e n.6 dove, in questo caso, si ha l’accettazione della ipotesi nulla. Questo si spiega col fatto che la variabile velocità media è caratterizzata da una deviazione standard maggiore rispetto a quella riscontrata per i valori massimi.
Considerata la presenza di sezioni in cui l’ipotesi nulla è accettata e sulle quali, quindi, non possiamo concludere nulla di definitivo, ed altre in cui siamo certi della differenza tra ambiente reale e simulato, sorgono delle domande conseguenti proprio alle conclusioni fornite dal test statistico applicato: come è quantificabile tale “certa” differenza tra i due ambiti di misura? E’ una differenza influente ai fini delle analisi che saranno condotte attraverso il sistema di simulazione?
La risposta a queste domande ci viene fornita ricorrendo ad uno studio più approfondito basato sulle tecniche di regressione [9].
L'analisi di regressione è una tecnica usata per modellare ed analizzare una serie di dati che consistono in una variabile dipendente e una o più variabili indipendenti. La variabile dipendente nella equazione di regressione è modellata come una funzione delle variabili indipendenti più un termine d'errore; quest’ultimo è una variabile casuale e rappresenta
una variazione non controllabile e imprevedibile della variabile dipendente. I parametri sono stimati in modo da descrivere al meglio i dati.
La regressione, quindi, formalizza e risolve il problema di una relazione funzionale tra variabili misurate sulla base di dati campionari estratti da un'ipotetica popolazione infinita. Originariamente Galton utilizzava il termine come sinonimo di correlazione, tuttavia oggi in statistica l'analisi della regressione è associata alla risoluzione del modello lineare: in particolare, in ambito statistico la regressione lineare rappresenta un metodo di stima del valore atteso condizionato di una variabile dipendente Y, dati i valori di altre variabili indipendenti, X1,…..Xk : E[Y|X1,….,Xk].
Il modello di regressione lineare è il seguente:
Yi = β0 + β1Xi + ui [1]
dove:
- i varia tra le osservazioni, i = 1, ...., n; - Yi è la variabile dipendente;
- Xi è la variabile indipendente o regressore;
- β0 + β1X è la retta di regressione o funzione di regressione della popolazione;
- β0 è l'intercetta della retta di regressione della popolazione;
- β1 è il coefficiente angolare della retta di regressione della popolazione;
- ui è l'errore statistico.
Sul termine di errore e sulla variabile esplicativa si assumono le seguenti ipotesi: - E[ui] = 0 per qualunque i;
- Var (ui) = s2 per qualunque i;
- Cov (ui, uj) = 0 per i diverso da j;
- X è una variabile deterministica.
Il modello di regressione lineare semplice e le ipotesi indicate definiscono il modello
classico di regressione lineare semplice. La prima ipotesi afferma che il valore atteso
degli errori è nullo per qualsiasi valore xi dxi. La seconda, nota anche come ipotesi
di omoschedasticità, afferma che gli errori hanno tutti la stessa varianza s2 per qualunque xi. La terza ipotesi implica che gli errori ui e uj, corrispondenti a due diversi valori xi e
deterministica, anziché una variabile casuale, significa assumere che i suoi valori siano sotto il controllo del ricercatore.
Il metodo più comunemente utilizzato per ottenere le migliori stime è il metodo dei "minimi quadrati" (OLS: Ordinary Least Squares).
La bontà del modello di stima che si individua con l’applicazione del metodo suddetto viene valutata attraverso il coefficiente di determinazione, più comunemente R2, che rappresenta una proporzione tra la variabilità dei dati e la correttezza del modello statistico utilizzato.
Non esiste una definizione concordata di R2: nelle regressioni lineari esso è semplicemente definito come il quadrato del coefficiente di correlazione:
TSS RSS TSS ESS R2 = =1− dove: - ESS =
∑
(
)
= − n i i y y 1 2ˆ è la devianza spiegata dal modello (Explained Sum of Squares);
- TSS =
∑
(
)
= − n i i y y 1 2è la devianza totale (Total Sum of Squares);
- RSS =
∑
∑
(
)
= = − = n i i i n i i y y e 1 2 1 2 ˆè la devianza residua (Residual Sum of Squares); - yi sono i dati osservati;
- y è la loro media;
- yˆ sono i dati stimati dal modello ottenuto dalla regressione.
La metodologia illustrata è stata utilizzata nel presente studio di validazione e calibrazione allo scopo di:
- quantificare l’entità della differenza emersa e individuarne le cause principali, con particolare riferimento alla definizione di errori sistematici o legati a variabili esterne; - capire se il sistema è in grado di riprodurre le condizioni di guida reali e permette studi
con un elevato livello di precisione.
L’analisi di regressione è stata eseguita sia valutando i dati nel loro complesso che per singole sezioni omogenee, prendendo in considerazione sia i valori massimi di velocità sui tratti che le velocità medie.
4.2.6 Regressione sui picchi di velocità
L’analisi di regressione eseguita sui valori massimi di velocità per ogni sezione omogenea, acquisiti da veicolo strumentato e da simulatore, evidenzia quanto segue (Figura 14 e Tabelle del processo di regressione):
- esiste una forte correlazione tra le misure (R=0,818) ;
- l’uguaglianza si verifica in un intorno di un valore di velocità pari a circa 60 km/h; - l’errore commesso ha un ordine di grandezza pari all’8-9%, per una velocità di picco
superiore a 80 km/h, e pari al 3-4% in corrispondenza di velocità pari a 40 km/h, ragion per cui nell’intervallo di studio i due sistemi risultano essere molto vicini.
Regression Statistics Multiple R 0.818 R Square 0.670 Adjusted R Square 0.669 Standard Error 5.388 Observations 744
REGRESSIONE VELOCITA' DI PICCO
y = 0.9533x R2 = 0.6153 y = 0.7451x + 12.536 R2 = 0.6691 20 30 40 50 60 70 80 90 0 10 20 30 40 50 60 70 80 90 100 V_sim (km/h) V_rea ( k m/h)
ANOVA df SS MS F Significance F Regression 2 43638.22 21819.11 751.46 5.2422E-179 Residual 741 21515.42 29.03 Total 743 65153.63 Coefficients Standard
Error t Stat P-value Lower 95%
Upper 95% Intercept 18.524 5.09 3.64 0.000296 8.52 28.52 sim 0.539 0.17 3.13 0.001839 0.20 0.88 Tracciato dei residui ‐40 ‐30 ‐20 ‐10 0 10 20 30 0.00 20.00 40.00 60.00 80.00 100.00 V_sim (km/h) Re si d u al s Histogram of residui residui F req uency -15 -10 -5 0 5 10 15 20 0 2 0 4 0 6 0 8 0 100
Figura 15: Retta di regressione dei residui e relativa distribuzione
Dalla Figura 15 si osserva, invece, l’andamento dei residui che verifica il test di normalità. In particolare, dall’analisi della retta di regressione riportata in Figura 14 si nota come il sistema di simulazione, allo stato attuale, comporta sistematicamente un’andatura poco più lenta nei tratti percorsi a velocità moderate (v comprese tra 40 e 60 km/h) e un’andatura
Il fenomeno si spiega nel modo seguente:
- ad andature moderate l’errore, che può considerarsi del tutto trascurabile, è legato alla differente percezione visiva degli utenti tra il caso reale e quello simulato: il sistema di simulazione prevede, infatti, un unico canale di proiezione frontale che non permette una adeguata visione degli elementi laterali il cui scorrimento fornisce al driver informazioni essenziali sulle velocità tenute durante la marcia;
- a velocità sostenute il simulatore sovrastima i valori di velocità reali in virtù dell’assenza di elementi dinamici che trasmettono vibrazioni ed accelerazioni al driver: la piattaforma statica attualmente presente fa si che l’utente si senta più sicuro e tenda ad incrementare la velocità rispetto a quanto farebbe nella pratica reale.
L’analisi di regressione è stata poi condotta per le singole sezioni omogenee definendo per ognuna di esse il relativo errore commesso rispetto all’ipotesi nulla di uguaglianza. L’andamento può essere visualizzato nelle figure riportate qui di seguito con relative tabelle esplicative. Sezione omogenea 1: Regression Statistics Multiple R 0.768 R Square 0.589 Adjusted R Square 0.585 Standard Error 4.280 Observations 93 Sezione omogenea 1 y = 0.6072x + 20.921 30 40 50 60 70 80 90 30 40 50 60 70 80 90 V_sim (km /h) V_ re a ( k m /h ) x=y regressione lineare ANOVA df SS MS F Significance F Regression 1 2392.84 2392.84 130.63 2.78E-19 Residual 91 1666.94 18.32 Total 92 4059.79 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 20.921 3.16 6.62 2.460E-09 14.64 27.20 Sim 0.607 0.05 11.43 2.775E-19 0.50 0.71
Sezione omogenea 2: Regression Statistics Multiple R 0.676 R Square 0.456 Adjusted R Square 0.450 Standard Error 6.088 Observations 93 Sezione omogenea 2 y = 0.6924x + 14.967 30 40 50 60 70 80 90 30 40 50 60 70 80 90 V_sim (km /h) V_ re a ( k m /h ) x=y regressione lineare ANOVA df SS MS F Significance F Regression 1 2832.82 2832.82 76.42 1.09E-13 Residual 91 3373.19 37.0680 Total 92 6206.01 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 14.967 4.69 3.19 1.938E-03 5.65 24.28 Sim 0.692 0.08 8.74 1.094E-13 0.53 0.85 Sezione omogenea n.3: Regression Statistics Multiple R 0.523 R Square 0.273 Adjusted R Square 0.265 Standard Error 4.707 Observations 93 Sezione omogenea 3 y = 0.5152x + 21.747 20 25 30 35 40 45 50 55 60 65 70 20 25 30 35 40 45 50 55 60 65 70 V_sim (km /h) V _ rea ( k m /h ) x=y regressione lineare ANOVA df SS MS F Significance F Regression 1 758.06 758.06 34.21 7.68E-08 Residual 91 2016.49 22.16 Total 92 2774.55 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 21.747 3.99 5.44 4.489E-07 13.80 29.69 Sim 0.515 0.09 5.85 7.676E-08 0.34 0.69
Sezione omogenea n.4: Regression Statistics Multiple R 0.656 R Square 0.430 Adjusted R Square 0.424 Standard Error 5.122 Observations 93 Sezione omogenea 4 y = 0.6444x + 18.864 30 35 40 45 50 55 60 65 70 75 80 30 35 40 45 50 55 60 65 70 75 80 V_sim (km /h) V _ rea ( k m /h ) x=y regressione lineare ANOVA df SS MS F Significance F Regression 1 1801.00 1801.00 68.65 9.77E-13 Residual 91 2387.15 26.23 Total 92 4188.15 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 18.864 4.47 4.22 5.734E-05 9.98 27.74 Sim 0.644 0.08 8.29 9.773E-13 0.49 0.80 Sezione omogenea n.5: Regression Statistics Multiple R 0.650 R Square 0.422 Adjusted R Square 0.416 Standard Error 5.426 Observations 93 Sezione omogenea 5 y = 0.6362x + 17.287 30 40 50 60 70 80 90 30 35 40 45 50 55 60 65 70 75 80 V_sim (km /h) V_ re a ( k m /h ) x=y regressione lineare ANOVA df SS MS F Significance F Regression 1 1955.67 1955.67 66.42 1.87E-12 Residual 91 2679.38 29.44 Total 92 4635.05 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 17.287 4.55 3.68 3.881E-04 7.74 25.83 Sim 0.636 0.08 8.15 1.873E-12 0.49 0.80
Sezione omogenea n.6: Regression Statistics Multiple R 0.724 R Square 0.525 Adjusted R Square 0.519 Standard Error 5.004 Observations 93 Sezione omogenea 6 y = 0.8419x + 8.0762 30 40 50 60 70 80 90 30 40 50 60 70 80 90 V_sim (km /h) V _ re a (k m/ h) x=y regressione lineare ANOVA df SS MS F Significance F Regression 1 2514.69 2514.69 100.44 2.298E-16 Residual 91 2278.41 25.04 Total 92 4793.10 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 8.076 4.61 1.75 8.349E-02 -1.09 17.24 Sim 0.842 0.08 10.02 2.298E-16 0.67 1.01 Sezione omogenea n.7: Regression Statistics Multiple R 0.784 R Square 0.614 Adjusted R Square 0.610 Standard Error 5.738 Observations 93 Sezione omogenea 7 y = 0.7854x + 10.701 30 40 50 60 70 80 90 40 45 50 55 60 65 70 75 80 85 90 V_sim (km /h) V_ re a ( k m /h ) x=y regressione lineare ANOVA df SS MS F Significance F Regression 1 4773.26 4773.26 144.98 1.56E-20 Residual 91 2995.90 32.92 Total 92 7769.17 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 10.701 4.46 2.39 1.846E-02 1.84 19.56 Sim
Sezione omogenea n.8: Regression Statistics Multiple R 0.726 R Square 0.527 Adjusted R Square 0.521 Standard Error 5.853 Observations 93 Sezione omogenea 8 y = 0.675x + 18.013 30 40 50 60 70 80 90 40 45 50 55 60 65 70 75 80 85 90 V_sim (km /h) V_ re a ( k m /h ) x=y regressione lineare ANOVA df SS MS F Significance F Regression 1 3467.00 3467.00 101.21 1.91E-16 Residual 91 3117.27 34.25 Total 92 6584.27 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 18.013 4.61 3.90 1.822E-04 8.84 27.18 Sim 0.675 0.06 10.06 1.910E-16 0.54 0.81
L’analisi del segnale velocità riferito ai valori di picco fornisce dei risultati soddisfacenti in quanto evidenzia come i due sistemi siano molto vicini tra di loro e l’errore commesso sia molto piccolo. Si potrebbe, pertanto, concludere che la percezione della velocità fornita dal sistema di simulazione è già di per sé soddisfacente.
La velocità di picco è un parametro molto efficace nell’individuare l’errore che nasce a causa di difetti percettivi della velocità ogni volta che si ricorre alla simulazione in realtà virtuale; tuttavia, non è un segnale completo ai fini del processo di validazione e calibrazione, in quanto non permette di spiegare il funzionamento del sistema a velocità ridotte.
Se si analizza, infatti, la retta di regressione e la dispersione dei punti intorno ad essa si nota come i punti tendano ad addensarsi in corrispondenza delle velocità più basse (dell’ordine dei 40 km/h) e ad avere dispersione maggiore in corrispondenza delle andature più elevate (valori intorno agli 80 km/h); questo andamento evidenzia una proporzionalità diretta tra la deviazione standard delle velocità reali, in corrispondenza di un valore fissato di velocità simulata, e la radice della velocità simulata, per cui,
nell’intervallo rappresentativo delle basse velocità, vale a dire al di sotto dei 40 km/h, ci si aspetta un comportamento di tipo parabolico passante per l’origine (Figura 16).
REGRESSIONE VELOCITA' DI PICCO
y = -0.0033x2 + 1.1608x R2 = 0.6639 y = 0.7451x + 12.536 R2 = 0.6691 0 10 20 30 40 50 60 70 80 90 100 0 10 20 30 40 50 60 70 80 90 100 V_sim (km/h) V_ re a ( k m /h ) x=y regressione 2°grado regressione lineare
Figura 16: Verifica della regressione per le basse velocità
Per valutare, quindi, la bontà del sistema di simulazione sarà necessario integrare i dati ottenuti con altri derivanti da prove effettuate a basse velocità.
Una ulteriore riprova si è avuta analizzando i dati di velocità media nello spazio per le tratte omogenee: l’analisi di regressione ha evidenziato quanto segue (Figura 17):
REGRESSIONE VELOCITA' MEDIA
y = -0.0095x2 + 1.4x y = 0.5512x + 18.586 0 10 20 30 40 50 60 70 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 V_sim (km /h) V _ rea ( k m /h ) x=y regressione 2°grado regressione lineare
- l’andamento della retta di regressione segue quello visto per i valori di picco;
- i dati presentano maggiore dispersione, probabilmente legata all’incidenza della variabilità delle condizioni al contorno (traffico veicolare e pedonale su tutti) e alla lunghezza della sezione omogenea;
- gli scostamenti dalla condizione ideale, rappresentata dalla retta x=y, restano dell’ordine del 3-4% nella zona delle basse velocità.
Le conclusioni che si possono trarre dall’analisi condotta sul segnale velocità pone immediatamente due questioni fondamentali da affrontare:
- la sistematicità di questo errore è strettamente legata al sistema di simulazione o a questo errore concorrono ulteriori variabili esterne non considerate?
- l’errore commesso quanto influisce sulla bontà dei dati acquisibili dal sistema e sulla affidabilità di futuri studi legati all’analisi del sistema complesso uomo-veicolo-infrastruttura-ambiente?
La risposta alla prima domanda è necessaria per capire se l’errore riscontrato è legato solo alle caratteristiche costruttive del simulatore di guida o se queste incidono solo per una piccola aliquota combinandosi, ad esempio, con l’esperienza, con l’abitudine, e con la variabilità delle condizioni di guida e, soprattutto, delle condizioni psico-fisiche dell’utente al volante.
La procedura seguita per chiarire la questione ha previsto il confronto dell’errore valutato con l’analisi di regressione appena vista con l’errore calcolato su una serie di dati appaiati relativi a test eseguiti esclusivamente in ambito reale.
In particolare, per la metà degli utenti (n=47) è stata eseguita una seconda registrazione in modo che questo insieme di misure potesse essere utilizzato come gruppo di controllo, per verificare le variazioni che possono sussistere tra un test ed un altro per il solito utente nelle solite condizioni di guida.
I dati registrati durante i due test con veicolo strumentato sono stati messi a confronto e si è osservato il solito andamento visto nel confronto tra reale e simulato: i conducenti, in pratica, sono influenzati da variabili esterne per cui, nonostante le condizioni al contorno siano rimaste praticamente immutate, hanno raggiunto velocità di picco differenti tra un test ed il successivo (Figura 18).
Confronto velocità reali y = 0.4658x + 31.7 y = -0.009x2 + 1.5478x 0.00 10.00 20.00 30.00 40.00 50.00 60.00 70.00 80.00 90.00 100.00 0.00 10.00 20.00 30.00 40.00 50.00 60.00 70.00 80.00 90.00 100.00 V_rea_1 (km /h) V_ re a _ 2 ( k m /h ) x=y regressione lineare regressione 2°grado
Figura 18: Confronto velocità reali
Questa osservazione indicherebbe, dunque, che le oscillazioni registrate al simulatore rientrano all’interno di quelle che sono le normali oscillazioni dei valori di velocità che possono aversi su un tratto stradale in istanti temporali differenti con le solite condizioni di circolazione, e legate quindi alle caratteristiche percettive degli utenti al volante.
Per quanto concerne i dubbi che si sollevano con la seconda questione è necessario invece stabilire un valore di soglia o di accettabilità delle misure effettuate, ritenuto accettabile ai fini della validazione ed in funzione delle particolari analisi di sicurezza che si vogliono perseguire con lo strumento di simulazione. Considerate le sperimentazioni previste nell’ambito del presente progetto di ricerca, e di seguito analizzate nel dettaglio, e la variabilità che uno stesso utente può presentare tra una guida ed un’altra nelle stesse condizioni di circolazione, legata agli aspetti percettivi e allo status psicologico, il gruppo di ricerca ha fissato la soglia di accettabilità delle misure in 5 km/h, in quanto si ritiene che tale valore sia un margine di errore accettabile e poco influente ai fini delle elaborazioni da condurre. Considerato che il simulatore determina un errore sistematico che rientra all’interno del valore soglia suddetto per il range di velocità esaminate, si può ritenere che il sistema sia affidabile e idoneo per le sperimentazioni previste.
4.2.7 Validazione basata sui valori di angolo di sterzo
La procedura di validazione appena descritta è stata quindi riutilizzata per verificare il grado di realismo del sistema di simulazione in relazione alla variabile “angolo di sterzo”, in modo da capire se le caratteristiche legate al volante (smorzamento e ritorno di forza ad esempio) e la percezione dello scenario riprodotto determinano reazioni compatibili con quelle registrate sul campo per i soggetti testati.
La procedura adottata per la validazione e la calibrazione è la medesima vista per il segnale velocità.
Tralasciando l’applicazione del test statistico “t-paired” si analizzano direttamente i dati ricorrendo alla tecnica di regressione lineare sui valori di picco osservati per il segnale in corrispondenza di punti singolari del percorso individuato.
Rispetto al segnale di velocità i valori di picco per l’angolo di sterzo si prestano invece molto bene a valutare il grado di realismo dello scenario prodotto e quindi a consentire la validazione e la calibrazione del sistema in quanto rappresentano i punti in cui l’azione sul volante da parte del conducente è più netta e distinguibile rispetto al resto del tracciato (Figura 19).
Il segnale angolo di sterzo è risultato, in alcuni casi, particolarmente disturbato, per cui alcuni profili sono stati esclusi dall’analisi.
Regression Statistics Multiple R 0.994 R Square 0.988 Adjusted R Square 0.988 Standard Error 14.914 Observations 640 ANOVA df SS MS F Significance F Regression 1 13346085 13346085 60001.08 0 Residual 638 161484.7 222.43 Total 639 13507570 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 2.519 0.59 4.21 2.87E-05 1.34 3.69 sim 1.013 0.0041 244.95 0 1.00 1.02
Angolo di sterzo y = 0.9751x - 1.7894 R2 = 0.9881 -300 -200 -100 0 100 200 300 400 -300 -200 -100 0 100 200 300 400 angolo_sim (°) a n gol o_ re a ( °) Angolo di sterzo Regressione
Figura 19: Retta di regressione del parametro angolo di sterzo
L’analisi della retta di regressione mostra come il livello di realismo raggiunto a livello grafico sia ottimale, determinando cioè delle reazioni del conducente, durante i test simulati, praticamente simili a quelle che il conducente ha esplicato durante il test con veicolo reale. L’errore commesso, infatti, è praticamente nullo ed esiste una fortissima correlazione tra le misure ottenute da veicolo strumentato e quelle da simulatore.
Se a questo si associa il fatto che i profili della variabile in esame sono praticamente sovrapponibili possiamo affermare che anche le sensazioni fornite dall’utente in ambito simulato sono molto prossime a quelle reali (Figura 20).
Figura 20: Sovrapposizione segnale angolo di sterzo reale e simulato
L’analisi dei residui (Figura 21 e Figura 22) evidenzia, infatti, come questi verifichino il Steering angle -250 -200 -150 -100 -50 0 50 100 150 200 250 300 500 750 1000 1250 1500 1750 2000 2250 2500 Progressiva (m) S te e ri ng a ngl e ( °) reale simulata
Tracciato dei residui y = 1E-16x - 4E-14 R2 = 1E-30 -200 -100 0 100 200 -300 -200 -100 0 100 200 300 R esi d u i residui
Figura 19: Tracciato dei residui
Histogram of V V F requ ency -40 -20 0 20 40 0 5 0 100 1 5 0 2 00 2 5 0
Figura 20: Distribuzione dei residui
In particolare, si può affermare che:
- lo scenario grafico rispecchia fedelmente le caratteristiche geometriche reali;
- il livello di frame rate raggiunto, dell’ordine di 45 Hz in ambito urbano, è tale da garantire una certa fluidità dell’immagine, per cui l’utente non è condizionato durante il compito di guida relativamente all’aspetto visivo;
- il modello del volante fornisce reazioni tali da provocare nell’utente le solite sensazioni che questi ha avvertito durante la guida reale.
Analizziamo ora la variabile “angolo di sterzo” per ognuna delle sezioni omogenee individuate, così come fatto per il segnale velocità: trattandosi di comportamenti localizzati va fatto notare che il confronto tra la retta di uguaglianza “x=y”, rappresentativa della condizione ideale, e la retta di regressione è strettamente legato all’intervallo analizzato e non ha validità fisica al di fuori di esso, ragion per cui il valore dell’intercetta assume un significato relativo.
Sezione omogenea 1: Regression Statistics Multiple R 0.590 R Square 0.348 Adjusted R Square 0.340 Standard Error 10.760 Observations 80
angolo di sterzo - sezione omogenea 1
y = 0,8834x + 28,559 150 160 170 180 190 200 210 220 230 150 160 170 180 190 200 210 220 230 angolo_sim (°) an g o lo _r ea ( °) angolo di sterzo x=y ANOVA df SS MS F Significance F Regression 1 4818.74 4818.74 41.64 8.48E-09 Residual 78 9025.86 115.72 Total 79 13844.60 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 28.559 20.32 3.03 0.003336 21.08 100 Sim 0.883 0.11 6.45 8.48E-09 0.49 0.92 Sezione omogenea 2: Regression Statistics Multiple R 0.844 R Square 0.712 Adjusted R Square 0.708 Standard Error 5.045 Observations 80
angolo di sterzo - sezione omogenea 2
y = 1,2202x + 6,86 -100 -90 -80 -70 -60 -50 -40 -30 -20 -80 -70 -60 -50 -40 -30 -20 -10 0 angolo_sim (°) a n golo_ re a ( °) angolo di sterzo x=y ANOVA df SS MS F Significance F Regression 1 4730.65 4730.65 185.84 5.43E-22 Residual 78 1909.14 25.45 Total 79 6639.79 Coefficients Standard
Error t Stat P-value
Lower 95%
Upper 95%
Sezione omogenea 3: Regression Statistics Multiple R 0.913665 R Square 0.834784 Adjusted R Square 0.832638 Standard Error 9.635147 Observations 80
angolo di sterzo - sezione omogenea 3
y = 0,8122x - 24,369 -200 -180 -160 -140 -120 -100 -80 -60 -200 -180 -160 -140 -120 -100 -80 -60 angolo_sim (°) a ngolo_ re a ( °) angolo di sterzo x=y ANOVA df SS MS F Significance F Regression 1 36118.38 36118.38 389.05 7.77E-32 Residual 78 7148.38 92.84 Total 79 43266.76 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept -24,369 6.179 -3.529 0.000708 -34.11 -9.50 sim 0.8122 0.042 19.725 7.77E-32 0.746 0.91 Sezione omogenea 4: Regression Statistics Multiple R 0.581 R Square 0.337 Adjusted R Square 0.329 Standard Error 5.388 Observations 80 ANOVA df SS MS F Significance F Regression 1 1151.32 1151.32 39.65 1.65E-08 Residual 78 2264.67 29.03 Total 79 3416.00 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 21.402 6.71 3.18 0.00206 8.03 34.76 sim 0.730 0.11 6.29 1.65E-08 0.49 0.96 y = 0.7296x + 21.402 30 40 50 60 70 80 30 35 40 45 50 55 60 65 70 75 80 an gol o_rea ( °) angolo_sim (°)
angolo di sterzo - sezione omogenea 4
angolo di sterzo x=y
Sezione omogenea 5: Regression Statistics Multiple R 0.750 R Square 0.563 Adjusted R Square 0.557 Standard Error 7.805 Observations 80
angolo di sterzo - sezione omogenea 5
y = 0,8497x - 11,191 -90 -80 -70 -60 -50 -40 -90 -85 -80 -75 -70 -65 -60 -55 -50 -45 -40 angolo_sim (°) a ngolo_ re a ( °) angolo di sterzo x=y ANOVA df SS MS F Significance F Regression 1 6118.82 6118.82 100.44 1.15E-15 Residual 78 4751.98 60.92 Total 79 10870.80 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept -11.191 6.458 -0.72 0.472 -17.53 8.19 sim 0.849 0.094 10.02 1.15E-15 0.76 1.13 Sezione omogenea 6: Regression Statistics Multiple R 0.794 R Square 0.631 Adjusted R Square 0.626 Standard Error 8.808 Observations 80
angolo di sterzo - sezione omogenea 6
y = 0,9519x + 14,569 130 140 150 160 170 180 190 200 210 220 130 140 150 160 170 180 190 200 210 220 angolo_sim (°) a ngolo _ re a ( °) angolo di sterzo x=y ANOVA df SS MS F Significance F Regression 1 10334.89 10334.89 133.22 1.51E-18 Residual 78 6051.00 77.58 Total 79 16385.89 Coefficients Standard
Error t Stat P-value
Lower 95%
Upper 95%
Sezione omogenea 7: Regression Statistics Multiple R 0.731 R Square 0.534 Adjusted R Square 0.528 Standard Error 6.676 Observations 80
angolo di sterzo - sezione omogenea 7
y = 0,6165x - 21,044 -100 -90 -80 -70 -60 -50 -40 -30 -100 -90 -80 -70 -60 -50 -40 -30 angolo_sim (°) a ngolo_ re a ( °) angolo di sterzo x=y ANOVA df SS MS F Significance F Regression 1 3778.61 3778.61 84.77 6.77E-14 Residual 78 3298.58 44.57 Total 79 7077.19 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept -21.044 4.807 -4.27 5.72E-05 -30.11 -10.95 sim 0.6165 0.068 9.21 6.77E-14 0.49 0.76 Sezione omogenea 8: Regression Statistics Multiple R 0.837 R Square 0.700 Adjusted R Square 0.696 Standard Error 9.330 Observations 80
angolo di sterzo - sezione omogenea 8
y = 0,8661x + 39,241 180 190 200 210 220 230 240 250 260 270 280 180 190 200 210 220 230 240 250 260 270 280 angolo_sim (°) a ngolo _ re a ( °) angolo di sterzo x=y ANOVA df SS MS F Significance F Regression 1 15850.22 15850.22 182.06 4.3E-22 Residual 78 6790.58 87.06 Total 79 22640.80 Coefficients Standard
Error t Stat P-value
Lower 95% Upper 95% Intercept 39.241 14.278 2.95 0.00417 13.73 70.58 sim 0.866 0.063 13.49 4.3E-22 0.73 0.98
4.2.9 Conclusioni relative al processo di validazione
La procedura di validazione del simulatore di guida del DIMNP appena descritta permette di fare le seguenti osservazioni conclusive:
- la percezione della velocità, nonostante il sistema sia a piattaforma statica e a video-proiezione frontale, è alquanto affidabile, in quanto gli errori commessi sono dell’ordine del 4% per le basse velocità e dell’8-9% per le andature più sostenute, determinando così scostamenti dalla condizione ideale (velocità simulata Vsim uguale
alla velocità reale Vrea) che rientrano nella soglia massima di accettabilità prefissata di
5 km/h;
- il ritorno di forza ai comandi derivante dal modello di veicolo trasmette agli utenti una buona sensazione di realismo: le variabili velocità e angolo di sterzo, infatti, presentano andamenti molto simili a quelli registrati con veicolo strumentato il che determina reazioni sui pedali e manovre che rispecchiano quelle verificatesi in ambito reale;
- lo scenario grafico è caratterizzato da valori di frame rate oscillanti intorno ai 45 Hz E’ovvio che il processo di calibrazione appena descritto vale per la tipologia di studio che è stata condotta e per condizioni analoghe (studi in area urbana o su strade dove il range di variazione delle velocità si mantiene tra i 30 ed i 70 km/h); al variare delle condizioni di marcia sarà quindi necessario impostare un nuovo processo di validazione, individuando quelle variabili che meglio descrivono l’uguaglianza tra l’ambito reale ed il sistema di simulazione.
In virtù di quanto detto, allo scopo di avere un sistema che sia in grado di simulare le diverse condizioni di marcia in ambiti differenti con un buon grado di realismo, gli sviluppi futuri del sistema di simulazione saranno incentrati sul miglioramento della percezione visiva attraverso l’installazione di due schermi laterali (o in alternativa di uno schermo cilindrico), al fine di aumentare l’angolo di visione fino a 120°, e sulla progettazione e la realizzazione di una pedana mobile che consenta al conducente di avvertire tutte quelle sollecitazioni che normalmente percepisce alla guida di un veicolo reale.
BIBLIOGRAFIA
1. Xuedong Yan, M. Abdel-Aty, E. Radwan, Xuesong Wang, P. Chilakapati,
Validating a driving simulator using surrogate safety measures, Accident Analysis
and Prevention 40 (2008) 274–288, 2007.
2. G.Reymond, A.Kemeny, Motion cueing in the Renault driving simulator, Vehicle System Dynamic, 2000.
3. R.S. Kennedy, Simulator sickness and other after effects implications for the
design of driving simulator, In Proceedings of Driving Simulation Conference
Europe, 1997.
4. P. Greening, On-board diagnostics for control of vehicle emissions, In Vehicle Diagnostics in Europe, IEE Colloquium on. pp. 1-5. London. Febbraio 1994.
5. HS-3000/2006, On-Board Diagnostics for Light and Medium Duty Vehicles
Standards Manual - 2006 Edition, SAE International. 2006.
6. Auterra, OBD CAN Bus Equipped Vehicles. http://www.auterraweb.com/
aboutcan.html, 2009.
7. Università di Pisa, Strumenti di diagnostica per il riconoscimento del livello di
attenzione alla guida - Relazione finale progetto PRIN2006-2008, 2008.
8. H. Klee, C. Bauer, E. Radwan, and H. Al-Deek, Preliminary Validation of Driving
SimulatorBased on Forward Speed, Transportation Research Record 1689, 1999.
9. H.J. Larson, Introduction to probability theory and statistical inference – Ed. John Wiley & Sons, 1969.