Capitolo 1
Knowledge Dyscovery in Database
1.1 Introduzione
Il KDD può essere visto come una conseguenza della naturale evoluzione della tecnologia dell’informazione: raccolta dei dati, creazione dei database, impiego di sistemi di gestione dei dati (compresi la memorizzazione sui diversi supporti e il recupero) e, infine, l’analisi dei dati e la loro interpretazione (data warehousing e data mining).
Nei diversi contesti, la grande distribuzione, la medicina, la scienza o l’amministrazione pubblica, la mole di dati immagazzinati è utile alla gestione, ma spesso non alle attività decisionali e strategiche.
Lo sviluppo di meccanismi per la raccolta dei dati e la creazione di database, quindi, hanno posto le premesse per l’archiviazione e il recupero più efficiente dei dati stessi, consentendo l’elaborazione online, la quale, a sua volta, ha reso possibile i processi di analisi e comprensione dei dati.
La nascita delle basi di dati risale agli anni 70: prima i database con struttura gerarchica e reticolare, poi i database relazionali, in cui le informazioni e le relazioni tra loro sono rappresentate tramite un insieme di tabelle. Questi ultimi sono accompagnati dai primi strumenti per generare modelli di dati e da tecniche per l’indicizzazione e l’organizzazione dei dati. Gli utenti incominciano a disporre di flessibili sistemi per l’accesso ai dati grazie ai linguaggi di interrogazione e alle interfacce utente. I database relazionali diventano ben presto il miglior strumento per la memorizzazione, il recupero e la gestione efficiente di grandi volumi di dati.
Durante gli anni 80, la tecnologia relazionale continua ad evolvere (database relazionali ad oggetti, ...) e iniziano ad emergere sistemi di informazione globale basati su Internet, quali il WEB (World Wide Web), destinati a giocare un ruolo fondamentale nell’industria dell’informazione. La pressione per incrementare la redditività collettiva, infatti, ha causato una spesa crescente per tutte le compagnie (da un punto di vista del tempo) per identificare diverse opportunità come vendite ed investimenti.
Quindi in maniera generale il “Database Mining” deve trarre dal campo del DBMS e seguire uno dei paradigmi chiave per gli ambienti DBMS: costruire compilatori ottimizzati per le query ad hoc per il sistema e inglobare le query nell’interfaccia utente del sistema stesso. Questo infatti, ha fatto aumentare l’interesse dei programmatori verso il KDDMS (Knowledge and Data Discovery Management Systems). Questo tipo di sistemi rappresenta la seconda generazione degli insiemi di strutture per il KDD.
A questo scopo quantità molto grandi di dati sono state raccolte nei propri database per ricavare informazioni significative in relazione al supporto alle decisioni.
Ecco due esempi che possono chiarire la situazione:
o Il sistema della NASA, EOS ( Earth Observing System) per i satelliti orbitanti e altri strumenti nati per utilizzi spaziali, invia ogni giorno un terabyte di dati che devono essere ricevuti ogni giorno dalle stazioni.
o Dall’anno 2000 la compagnia Fortune 500 è stata progettata per possedere più di 400 trilioni di caratteri nei proprio database elettronici;questo richiede 400 terabyte di memoria di massa.
Con il crescente utilizzo dei database la necessità di essere in grado di elaborare un grosso volume di dati che potenzialmente possono essere generati, è critica.
Secondo una stima (non proprio recentissima) è stato stimato che solamente il 10-15% dei database commerciali è stato analizzato almeno una volta [FPS99].
Come i due esperti Massey e Newing indicano, la tecnologia che si basa sui database può considerarsi vincitrice dal punto di vista di memorizzazione e mantenimento dei dati ma d’altra parte sicuramente può considerarsi fallimentare in relazione ad un passaggio dal data-processing al fatto di rendere questa attività una potenziale arma strategica per ingaggiare una competizione nell’attività economica della propria azienda .Il volume molto grande dei dati e la dimensione molto alta e in continua espansione dei database porta sicuramente a scartare la tradizionale “analisi umana dei dati”.
Il costante progresso di dspositivi hardware negli ultimi tre decenni consente di disporre di una vasta gamma di potenti computer e apparecchiature per la raccolta e la memorizzazione dei dati, che spingono alla creazione di database contenenti grandi volumi di dati disponibili, tra l’altro, per l’analisi.
Nasce il data warehouse, un grande contenitore di dati provenienti da fonti eterogenee, organizzati sulla base di un unico schema logico per facilitare i processi decisionali. E con il data warehouse fa la sua comparsa l’OLAP1, vale a dire tecniche di analisi multidimensionali dei dati (possibilità di analizzare i dati secondo diverse prospettive...).
Sebbene gli strumenti OLAP siano di supporto al processo decisionale, non sono sufficienti per svolgere analisi più approfondite, quali la classificazione , il clustering, la previsione ...
All’abbondanza di dati si accompagna l’esigenza di strumenti di analisi più potenti per far fronte a una situazione caratterizzata da ricchezza di dati ma povertà di informazione. Gli elevati volumi di dati impediscono all’abilità umana la loro comprensione, senza l’ausilio di tali strumenti. Il rischio che si
corre è quello di prendere decisioni non sulla base di dati ricchi di informazioni presenti nei grandi database, ma secondo il proprio intuito.
La ricchezza di dati può diventare ricchezza di conoscenza grazie al KDD che offre proprio questi potenti strumenti di analisi, strumenti che adottano tecniche di data mining.
1.2 Figure professionali collegate con il KDD
La Business Intelligence non è un investimento puramente tecnologico, ma sui tre piani Competenze, Organizzazione, Tecnologie.
Il segreto del successo è usarla come leva dell’evoluzione professionale delle diverse figure coinvolte Tecnici IT (amministratori e progettisti database) Analisti (dei dati e del business) Utenti finali (manager in senso lato, ad ogni livello).
Le capacità professionali di questi tre gruppi di figure devono crescere insieme per la (e grazie a) la diffusione della B.I. in azienda.
Quando si parla di Tecnici IT si intende quella categoria di professionisti del settore che vanno da progettisti e amministratori DB fino ai progettisti e amministratori DW e creatori di cubi tematici. Per
Analisti (dei dati e del business) si intendono quelle persone impiegate nella stesura manuale di report fino ai creatori di rapporti e cruscotti interattivi.
Gli Utenti finali invece (manager in senso lato, ad ogni livello) possono essere considerati dai consumatori di rapporti cartacei o, al massimo, di fogli Excel fino ad arrivare a navigatori di rapporti multi-dimensionali e di tabelle pivot di Excel.
1.3 KDD : Definizione e Processo
Il termine Knowledge Discovery in Databases (KDD), coniato nel 1989, si riferisce all’intero processo, interattivo ed iterativo, di scoperta della conoscenza che consiste nell’identificazione di relazioni tra dati chesiano valide, nuove, potenzialmente utili e comprensibili [FPS96]. Per una migliore comprensione di tale definizione si esaminano in dettaglio i concetti in essa coinvolti.
I dati sono una collezione di fatti F (per esempio tuple di una tabella di un database relazionale).
Una relazione (o modello o pattern) è un’espressione E in un linguaggio L che descrive fatti in un sottoinsieme FE di F. Ovviamente una relazione deve essere più semplice rispetto ad un dato criterio di semplicità della enumerazione di tutti i fatti in FE.
Un processo di scoperta della conoscenza è un insieme di attività che coinvolgono la preparazione dei dati, la ricerca di relazioni, la valutazione e il raffinamento della conoscenza estratta. Si assume che il processo sia non banale, cioè che le relazioni scoperte non siano già note.
Le relazioni scoperte sono valide se valgono, con un certo grado di certezza, anche su dati diversi da quelli usati per la scoperta delle stesse. Individuare un grado di certezza è essenziale per stabilire quanta fiducia si può riporre nel sistema e nella scoperta effettuata. Il concetto di certezza coinvolge diversi fattori quali l’integrità dei dati, la dimensione del campione su cui è effettuata la scoperta o la quantità
di conoscenza già disponibile. Le relazioni scoperte devono essere nuove almeno per il sistema. La novità può essere misurata rispetto ai cambiamenti nei dati (confrontando i valori correnti con quelli precedenti o quelli attesi) o nella conoscenza (cioè come una nuova scoperta è collegata a quella precedente).
Le relazioni dovrebbero potenzialmente condurre a delle azioni utili. Per esempio la scoperta di una dipendenza fra articoli acquistati da uno stesso cliente in un supermercato potrebbe attivare opportune strategie di marketing.
Le relazioni scoperte devono essere comprensibili agli utenti per facilitare una migliore comprensione dei dati coinvolti. Poiché è difficile misurare precisamente “la comprensibilità di un pattern” spesso si ricorre a misure surrogate di semplicità
La prima conferenza internazionale sul tema KDD si è tenuta a Montreal, in Canada, nel 1995. In quell’occasione si è proposto che il temine knowledge discovery in databases doveva essere usato per definire l’intero processo di estrazione della conoscenza dai dati. Una “nuova” e non ovvia conoscenza per un impiego utile e conveniente.
Una definizione di KDD più esaustiva è la seguente:
KDD è il processo per identificare nei dati pattern (forme) con caratteristiche di validità, novità, utilità
potenziale e facilità di comprensione.
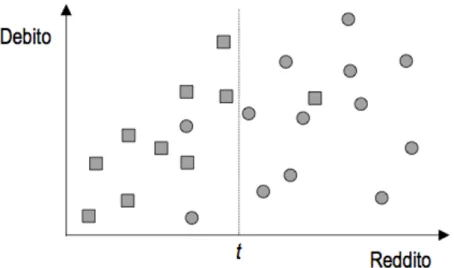
Per meglio comprendere la succitata definizione, si osservi l’esempio della figura 1.
figura 1 : esempio rappresentazione classi
E’ rappresentato su un piano bidimensionale un insieme di 23 casi: ogni punto sul grafico rappresenta una persona a cui una banca ha concesso un prestito; l’asse delle ascisse individua il reddito (la variabile indipendente), mentre quello delle ordinate il debito (la variabile dipendente). I 23 casi sono suddivisi in due classi, stabilendo una soglia t nella variabile reddito:
• A, clienti che non hanno onorato il debito; • B, clienti che hanno provveduto al rimborso.
Questi 23 esempi costituiscono un insieme di dati che racchiude conoscenza utile alla banca per prendere decisioni riguardo alla concessione di prestiti alla clientela.
Per quello che riguarda il processo KDD, si può dire che esso può essere scomposto in più fasi tra le quali il Data Mining riveste un ruolo centrale. Il primo passo del KDD, ossia individuare gli obiettivi dell’utente finale, ha molto in comune con le fasi iniziali di un qualunque progetto commerciale, durante le quali si individuano gli obiettivi di business da raggiungere. In questa fase è importante la collaborazione che si stabilisce tra gli analisti del business e gli analisti dei dati, i quali devono comprendere il dominio applicativo ed estrarre
la conoscenza già esistente.
Il punto di partenza per un qualsiasi progetto è la definizione dell’aspettativa in funzione della quale si potrà stabilire il successo o meno dello stesso Individuati gli obiettivi dell’utente, è necessario creare un insieme di dati selezionando un sottoinsieme delle variabili o un campione della Base di Dati da analizzare. L’obiettivo della selezione è identificare le sorgenti di dati disponibili ed estrarne un campione per le analisi preliminari. Oltre alle variabili selezionate, è necessario acquisire le corrispondenti informazioni semantiche (metadati), indispensabili per capire il significato di ciascuna variabile. I metadati potrebbero includere la definizione dei dati, la descrizione dei tipi, i valori potenziali, il loro sistema sorgente e formato.
I dati selezionati devono essere pre-elaborati al fine di rimuovere eventuali inconsistenze, rimuovere o ridurre l’effetto del rumore (noise), eliminare casi limite (outlier), decidere le strategie per la gestione dei valori nulli, scartare dati obsoleti. La pre-elaborazione è quindi finalizzata a migliorea la qualità dei dati selezionati. Spesso potrebbe essere necessario trasformare i dati selezionati al fine di isolare caratteristiche utili a rappresentare i dati in base agli obiettivi dell’analisi. In particolare i dati sono trasformati in un formato (modella analitico) compatibile con gli algoritmi disponibili. Il modello analitico dei dati rappresenta un ristrutturazione consolidata integrata e dipendente dal tempo dei dati selezionati e pre-elaborati. Questo passo è fondamentale per garantire l’accuratezza dei risultati che dipende da come gli analisti decidono di strutturare i dati di input.
Una complessa conversione è la riduzione dei dati, il cui obiettivo è ridurre il numero totale di variabili da analizzare combinandone alcune tra loro in modo da ottenerne una nuova. Altre possibili conversioni sono lo scalino che consente di ridurre input numerici a specifici intervalli, la discretizzazione che converte variabili quantitative in categoriche, e la binarizzazione che converte una variabile categorica in più variabili binarie .
regole di associazione,ecc..), è una fase fondamentale del processo KDD: essa influenza anche la scelta dell’algoritmo per scoprire nuove relazioni, dipendentemente dal tipo di rappresentazione che si decide di usare per le relazioni estratte, e conduce a risultati utili solo se i passi precedenti del processo KDD sono stati correttamente eseguiti. Infine nel processo KDD le relazioni scoperte devono essere interpretate alla luce della conoscenza pregressa, valutate rispetto all’obiettivo di business, e comunicate alle parti interessate mediante opportuna reportistica.è un motore per il Data Mining di dati complessi.
1.4 Necessità di tool che supportano il processo
Negli ultimi decenni il ciclo di vita dei processi decisionali nelle aziende è andato accorciandosi. La tempestività nell’individuare nuovi segmenti di mercato, nello scoprire preferenze e comportamenti da parte dei clienti, nel ridurre eventuali sprechi nella produzione o nel razionalizzare altri processi aziendali, è diventata vitale per la sopravvivenza delle aziende. Tale tempestività, tuttavia, a volte contrasta con la mole dei dati da elaborare per estrarre le informazioni necessarie a supportare il processo decisionale. Il ricorso alle tecnologie dell’informazione è quindi un passo obbligato.
E’ importante che l’attività di raccolta dei dati non si limiti ai soli dati generati e usati nei processi produttivi o operativi di un’impresa, ma che sia orientata anche ai dati decisionali, caratterizzati da una natura aggregata, una struttura flessibile, un uso non ripetitivo, un orizzonte temporale ampio, e una proprietà di staticità [INM96]. In un contesto aziendale, la conoscenza scoperta può avere un valore importante perché consente di aumentare i profitti riducendo i costi oppure aumentando le entrate. Questo spiega l’importanza di soluzioni KDD in ambito aziendale.
1.5 L’informazione come fattore di produzione
Perché la KDD e il DM sono considerati importanti settori, oggigiorno? Siccome le aziende (come qualsiasi privato che desideri cercare qualcosa attraverso la rete oppure tramite bibliografia) devono confrontarsi con una quantità di dati sempre crescente, è divenuto più difficile e dispendioso in termini di tempo accedere all’informazione desiderata.
Molte organizzazioni internazionali producono più informazioni in una settimana di quante una persona possa leggerne nella propria vita. La situazione è ancora più marcata nelle reti mondiali quali Internet. Ogni giorno centinaia di megabyte di dati sono distribuiti nel mondo, e non è più possibile monitorare questo sviluppo incredibilmente rapido – la crescita è esponenziale.
Nel futuro, l’abilità di leggere e interpretare da soli non sarà sufficiente per sopravvivere come organizzazione professionale, scientifica o commerciale. La produzione e riproduzione meccanica di dati ci obbliga a adattare le nostre strategie e a sviluppare metodi meccanici per filtrare, selezionare e interpretare i dati. Le organizzazione che eccelleranno in questo avranno una produzione di grande importanza.
L’uso del computer per scoprire informazioni nuove e significative è di grande importanza: c’è una profonda motivazione filosofica per la sfida di costruire macchine che possano imparare.
Pochi dubitano che un programma intelligente è anche un programma con fondamentali capacità d’apprendimento: non ci può essere Intelligenza Artificiale (AI) senza Apprendimento Artificiale (Machine Learning), ecco perché i programmi che possono “imparare” sono stati al centro dell’attenzione della ricerca AI dai primi giorni della tecnologia al computer, sin dagli anni ’50.
1.6 Gli obiettivi del KDD: la conoscenza e la
metaconoscenza
Al fine di meglio comprendere gli obiettivi del processo di KDD, è utile fare alcune osservazioni sul concetto di conoscenza.
La conoscenza, intesa come l’insieme di informazioni che si estraggono dai dati, può essere considerata sotto due diversi aspetti:
conoscenza reale: si considera tale una serie di informazioni contenute nei dati, che si possono realmente conoscere o non conoscere;
metaconoscenza: si considera tale un insime di informazioni che potrebbero essere presenti nei dati e che, a priori, si pensa (correttamente o erroneamente) di conoscere o di non conoscere.
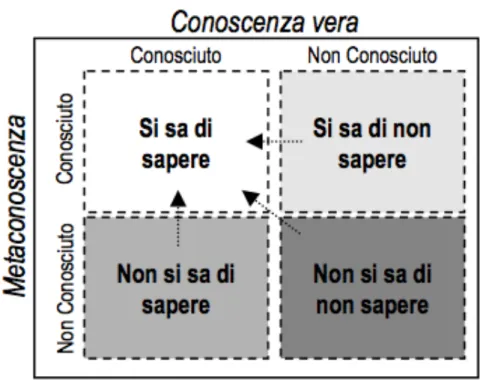
Questi due aspetti diversi della conoscenza possono essere rappresentati da una matrice a due dimensioni (vedi figura 2).
Commentiamo brevemente la figura :
o Si sa di sapere: a questo livello si considera una posizione in cui si capisce che le informazioni utili sono contenute nei dati.
figura 2 : conoscenza e metaconoscenza
o Non si sa di sapere: in questo caso non si capisce di avere a portata di mano le informazioni rilevanti che si vogliono cercare. Questo è il livello in cui un processo di estrazione di conoscenza (KDD) ricopre un ruolo fondamentale. Infatti attraverso il procedimento di KDD si riescono facilmente a scovare le informazioni utili all’interno dei dati.
o Non si sa di non sapere: questo punto è un vicolo cieco. Infatti non si hanno nemmeno possibilità di scoprire informazioni utili utilizzando un procedimento KDD dato che i dati saranno sicuramente incomplete e non si ha neanche la conoscenza di una lacuna del genere.
o Si sa di non sapere: a questo livello vengono rappresentate informazioni che non sono palesi o che semplicemente non sono facilmente accessibili a partire dai dati iniziali. In questo caso il KDD può essere sicuramente di aiuto.
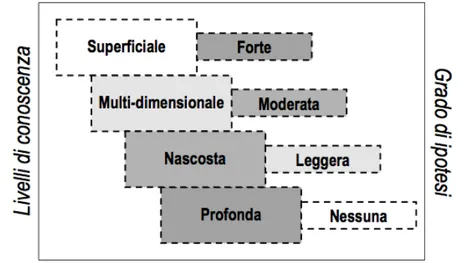
Si potrebbe esaminare la conoscenza anche sulla base del suo livello di profondità (vedi figura 3).
figura 3 : livelli di profondità della conoscenza
Conoscenza superficiale
Si tratta dell’informazione che si recupera dai database attraverso i diversi strumenti d’interrogazione disponibili. In questo caso si è consapevoli a priori riguardo a quello che si vuole trovare e a dove e come trovarlo.
Ad esempio si può richiedere la lista dei clienti il cui ammontare del traffico telefonico dell’ultimo bimestre è diminuito di almeno il 20% rispetto al bimestre precedente.
Conoscenza multidimensionale
E’ l’informazione che può essere analizzata con l’utilizzo di strumenti OLAP. Ad esempio, sulla base della lista succitata, si potrebbe chiedere quali di questi clienti hanno effettuato chiamate al di fuori della fascia oraria più conveniente rispetto al loro piano tariffario.
Si tratta in questo caso di un’ipotesi forte.
Conoscenza nascosta
Qui l’ipotesi da cui si parte diventa più leggera: si presume che vi possano essere degli elementi che distinguono i clienti fedeli da quelli che hanno
intenzione di disattivare il servizio di telefonia mobile (e probabilmente passare alla concorrenza), senza però avere la minima idea di quali siano.
Ed è questo l’ambito in cui il KDD la fa da padrone.
E’ la conoscenza che si può trovare impiegando algoritmi di pattern recognition o di machine learning. Tali algoritmi consentono di individuare delle somiglianze e similitudini tra numerosissimi dati.
Conoscenza profonda
In questa situazione non vi è nessuna ipotesi di base.
E’ l’informazione presente nel database che può essere trovata solo se si ha un’indicazione (o meglio un indizio) riguardo a dove cercare.
Sarebbe come trovarsi su un terreno di cui non si ha nulla riguardo alla sua natura geologica senza domandarsi se vi si possa estrarre petrolio.
1.7 Fasi del processo di KDD
Il processo di knowledge discovery nei database, come già accennato, consta di una sequenza iterativa di operazioni e più in particolare:
o Definizione del problema. Deve essere identificato l’obiettivo del progetto di knowledge discovery. L’obiettivo deve essere marcato come fattibile. I dati che devono essere usati hanno anche bisogno di una identificazione precisa. In questo caso è la figura dell’analista a farsi avanti. Infatti egli ha una relazione diretta con il cliente per decidere i punti salienti del problema analizzando già a questo punto le soluzioni esistenti e stabilendo l’impatto che il processo di scoperta dei contenuti può avere sul dominio di lavoro.
o Preprocessing dei dati. Include i sottoprocessi di data collecting, data cleaning, data selection, data integration e data transformation.
Data collecting. È la fase che consiste nell’ottenere dati sia da fonti interne che da fonti esterne. In generale c’è bisogno di risolvere le differenze che ci sono sia da un punto di vista di codifica che di rappresentazione. Oltre a questo c’è la necessità di operare una giunzione tra le varie tabelle dei dati in modo da creare una sorgente di dati abbastanza omogenea.
Data cleaning. In questa fase si cerca di risolvere i conflitti esistenti tra i dati come per esempio valori eccezionali o non usuali, confusi o addirittura sbagliati, dati mancanti o ambigui. Questa non uniformità dei dati molte volte può essere dovuta ad una scorretta trasmissione dei dati stessi o ad errori umani. Una mancata esecuzione di questa fase può portare a dei risultati parzialmente o completamente inconsistenti e quindi può portare all’impossibilità di applicare gli algoritmi di data mining. Tutti questi passi del data cleaning richiedono uno sforzo considerevole, spesso addirittura vicino al 70% del lavoro totale impiegato per l’operazione di data mining.
Data selection. In questo passo è selezionato un insieme di dati che appare di una importanza rilevante per il compito di analisi dei dati.In altre parole viene selezionato un dataset o l’attenzione viene focalizzata su un sottoinsieme delle variabili o su un campione dei dati sul quale il processo di discovery viene applicato.
Data integration. Questa fase consiste nella rimozione di tutte le inconsistenze e le ridondanze prodotte nelle sotto-fasi precedenti. Per esempio se un attributo viene riferito con due nomi differenti.
Data transformation. I dati sono trasformati o consolidati nella forma appropriata per il processo di mining attraverso gli operatori di aggregazione o semplificazione.
o Data Mining. È un processo fondamentale nel quale metodi “ragionati” vengono applicati con il fine di estrarre dei patterns (o modelli) o più in generale il tipo di informazione richiesta. Questo passo include anche la scelta dell’algoritmo da utilizzare per la ricerca dei patterns.
L’utente può agevolare in modo significativo il metodo di data mining applicando in modo corretto i passaggi precedenti.
o Post Data Mining. Questa fase del processo include patterns evaluation, deploying ,the model,maintenance e knowledge presentation.
Pattern Evaluation. Questa fase permette l’identificazione dei pattern a cui siamo realmente interessati basandosi su alcune misure di interesse. Inoltre provvede al testing dell’accuratezza del dataset che è stato utilizzato per creare il modello. Stima anche la sensibilità del modello utilizzato e pilota la fase di testing per verificarne “l’usabilità”. Per esempio se usiamo un modello per predire la risposta dei clienti ad una particolare promozione, può essere fatta una predizione e un test via a-mail ad un sottoinsieme dei clienti per verificare in che percentuale la predizione ha funzionato.
Deploying the model. Per un modello predittivo il modello attuale è utilizzato per predire risultati per nuovi casi. In seguito la predizione è usata per modificare l’aspetto dell’organizzazione generale. Il deployment può richiedere una costruzione con un sistema computerizzato per identificare i dati giusti e generare una predizione in tempo reale in modo tale che l’utente che sta utilizzando questa
funzionalità può applicarla immediatamente. Per esempio, un modello può determinare se una transazione di una carta di credito può essere fraudolenta.
Maintenance. Sebbene i dati siano modellati questi sono in un modo o in un altro soggetti a cambiamenti nel tempo. L’economia cambia, le aziende che “sono alla concorrenza” introducono nuovi prodotti. Per uno di questi motivi, per esempio, un modello che poteva essere corretto ieri oggi non lo è più. Per mantenere aggiornati i modelli è necessaria una costante ri-validazione dei modelli stessi con nuovi dati da controllare.
Knowledge Presentation. La visualizzazione e le tecniche di presentazione della conoscenza sono utilizzate in questa fase per presentare agli utenti i dati che hanno subito un processo di “mining”.
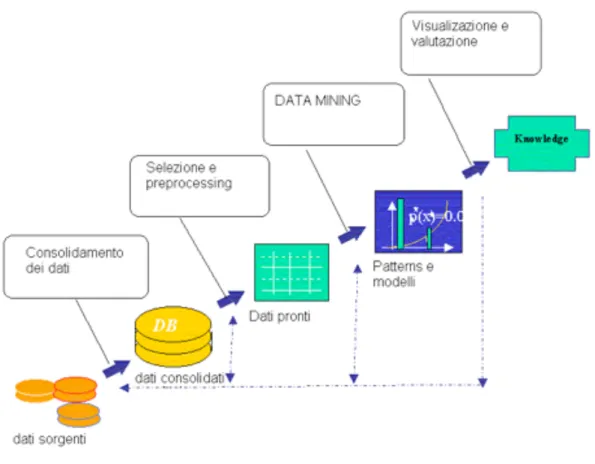
In modo schematico,come in figura 4, si può rappresentare l’intero processo di KDD.
Facendo riferimento a questo contesto è bene definire i ruoli dei partecipanti ad un progetto di data mining:
o Business analyst : dotato di una profonda conoscenza del dominio dell’applicazione, interpreta gli obiettivi e li traduce in esigenze di business, che serviranno per definire i dati e gli algoritmi di mining da utilizzare;
figura 4 : Processo KDD
o Data analyst : dotato di una profonda conoscenza delle tecniche di analisi dei dati, solitamente ha un forte background statistico. È in possesso dell’esperienza e dell’abilità necessarie per trasformare le esigenze di business in operazioni di data mining e per scegliere le tecniche di data mining più adatte ad ogni operazione;
o Data management specialist : dotato di competenze sulle tecniche di gestione e di raccolta dei dati a partire da sistemi operazionali, databases esterni o Datawarehouses.
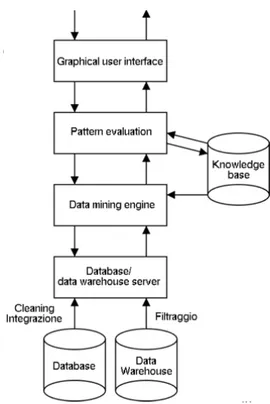
Si potrebbe certamente dire, che l’architettura complessiva di un sistema KDD è una conseguenza diretta del processo stesso. Una possibile architettura generale è mostrata in figura 5.
figura 5 : architettura di un sistema KDD
1.7.2 Applicazione della knowledge discovery nei database
Il data mining è potenzialmente applicabile sia in campo industriale che nell’area business in cui sono usati database e tecnologie informatiche.
Queste sono alcune delle applicazioni più frequenti:
• Rilevamento di frodi (identificazione di transazioni fraudolente) :
o Ottenere un profilo degli utenti che commettono delle frodi, allo scopo di riuscire a capire se un nuovo contratto può essere pericoloso per l’azienda.
• Approvazione dei prestiti : Richiesta da parte dei clienti dei prestiti. • Analisi degli investimenti .
• Analisi delle vendite :
o identificazione di utenti potenziali;
o ricerca di raggruppamenti che modellino gli acquirenti con stesse caratteristiche: interessi, abitudini di spesa, etc.
o analisi incrociate Associazioni/Correlazioni tra vendite di prodotti
• Analisi del processo di manifattura : identificazione delle cause di malfunzionamenti e\o problemi.
• Agenti intelligenti e navigazione web • Analisi di dati scientifici
• Analisi dei rischi:
o analisi e predizione dei flussi di cassa o valutazione dei profitti
o Resource planning: riassumi a confronte le risorse e le spese o Competition: monitora i vari competitori e le direzioni di mercato • Analisi di risultati di esperimenti: sinterizzazione dei risultati e
realizzazione di modelli predittivi
Più concretamente esempio si può pensare ad un impiego del processo di Data Mining in alcune situazioni del tipo:
- Una società che utilizza dati (per scopi di vendita) che riguardano le risposte o le adesioni ricevute mediante una qualsiasi forma di comunicazione (es. e-mail) per costruire dei modelli precisi o approssimati per la predizione di mercato.
- Una ricerca automatica attraverso un archivio di documenti per trovare degli articoli relativi ad un ben preciso argomento.
- Analisi di un grosso insieme di scontrini di una catena di supermercati per scoprire quali oggetti si comprano più spesso ed in relazione a quale periodo.
- Un’agenzia privata che predispone una serie molto lunga di questionari per rendersi conto del grado di soddisfazione dell’utente in relazione ai propri prodotti per permettere di incrementare il proprio profitto.
In generale, ultimamente, le agenzie private, le aziende ed il governo hanno utilizzato risorse enormi (sia materiali che umane) per la raccolta e la memorizzazione di informazioni di questa tipologia. Se questa grossa mole di informazioni è stata “ammassata” è perchè qualcuno ha pensato che potesse essere in qualche modo utile.
Il problema è che i moderni sistemi di elaborazione di database (DBMS) sono in grado di raccogliere, memorizzare ed elaborare i dati in maniera automatica (o quasi) ma non permettono l’utilizzo di strumenti per analizzare, comprendere e trasformare in informazioni che possono essere utilizzate in maniera utile da parte dell’utente.
In generale le metodologie e le tecnologie di data mining mirano in qualche modo a risolvere questo “piccolo” ostacolo.
1.8 Il Data Mining
Come abbiamo discusso nei paragrafi precedenti, Il DM è considerato come la parte centrale del processo di KDD.
Il processo di data mining vero e proprio consiste nello studio di vari modelli e la scelta del migliore di essi basato sulla loro performance predittiva.
Questa potrebbe sembrare un’operazione semplice, ma spesso e volentieri è un processo abbastanza complicato. Ci sono una varietà di tecniche sviluppate per raggiungere questo obiettivo molte delle quali sono basate su ciò che viene chiamato “valutazione competitiva dei modelli” cioè applicare modelli
differenti allo stesso dataset e poi comparare la loro performance per scegliere il migliore. Queste tecniche che sono spesso considerate il cuore del data mining predittivo includono: bagging (votazione e media), boosting, stacking e meta-learning .
La stima dell’errore è un buon metodo per la verifica della bontà di un modello, bisogna fare una distinzione tra il training set e il test set, il dataset di training è quella parte del dataset completo che viene usata per allenare il motore che estrae il modello. C’è da dire che le misure di errore sul dataset di training non sono dei buoni indicatori delle performance future del modello che si sta usando. Quando si fanno delle verifiche sul modello, insomma, si divide il dataset disponibile assegnando di solito ai 2/3 di questo il ruolo di training dataset e alla restante parte quello di test dataset .
Vediamo brevemente alcune tecniche di data mining predittivo.
Validazione incrociata
Se si ha solo una modesta quantità di dati per costruire il modello, una validazione semplice potrebbe portare a dei risultati errati perché l’insieme di dati usato per il training o il test potrebbe non essere rappresentativo. Ogni classe nel dataset dovrebbe essere rappresentata dalla giusta proporzione sia nel training set che nel test set. La validazione incrociata è un metodo che permette di usare tutti i dati disponibili. I dati sono divisi casualmente in due insiemi uguali per stimare l’accuratezza predittiva del modello. Prima, un modello viene costruito sul primo insieme e usato per predire i risultati sul secondo e calcolare il tasso di errore. Poi un modello è costruito sul secondo insieme e usato per predire i risultati nel primo insieme e calcolare di nuovo il tasso di errore. Quindi ci sono due stime di errore indipendenti con cui si può fare la media e dare una migliore stima della reale accuratezza del modello costruito su tutti i dati. Tipicamente, viene usata una validazione incrociata a 10 fold (partizioni). In questo metodo i dati sono divisi casualmente in 10 gruppi disgiunti.
è abbastanza instabile, piccoli cambiamenti nei training set possono facilmente risultare nella scelta di un attributo differente a un nodo particolare, ciò implica che ci saranno delle istanze test per cui alberi decisionali applicati allo stesso training set produrranno risultati diversi.
Esistono alcune tecniche che combinano le decisioni di differenti modelli per produrne uno finale più robusto. Alcune di queste sono le seguenti:
Bagging (votazione, media)
Il concetto di bagging (votazione per la classificazione, media per il problemi di regressione) si applica all’area del data mining predittivo, per combinare le classificazioni predette da modelli multipli o dallo stesso tipo di modello applicato su dati differenti.
E’ usato anche per mettere in evidenza l’instabilità intrinseca dei risultati quando si applicano modelli complessi a dataset relativamente piccoli.
Boosting
Il concetto di boosting si applica all’area del data mining predittivo per generare modelli multipli o classificatori e derivare pesi per combinare le predizioni da questi modelli in una singola predizione.
Consideriamo un database che contenga le abitudini (in quanto ad acquisti) di un gran numero di clienti di una determinata azienda. Il comportamento dei clienti può essere analizzato per prevedere quanti continueranno a fare acquisti presso la stessa azienda e quanti cambieranno venditore.
Una volta evidenziati i potenziali clienti destinati ad abbandonare i servizi dell’azienda (attraverso un procedimento chiaramente di data mining) questi potranno per esempio essere bersagliati con promozioni e trattamenti particolari in modo da cercare di dissuaderli a rimanere fedeli all’azienda.
Questi trattamenti chiaramente sarebbero troppo dispendiosi (da un punto di vista economico) se applicati a tutti i clienti in modo globale. Invece, con un
comportamento mirato si può aggirare il problema ed avere dei risultati economicamente molto vantaggiosi. In alternativa, le stesse tecniche possono per esempio essere utilizzate per identificare i clienti che non hanno ancora provato un certo servizio fornito dall’azienda in modo da fare delle offerte vantaggiose che promuovono quel determinato servizio.
In generale nell’economia competitiva di oggi si può dire che :
I dati rappresentano la materia grezza che alimenta la crescita del business solo se essi possono essere esplorati.
Proprio per questo motivo questo processo automatico (o semi-automatico) in qualche modo, attraverso la scoperta di patterns deve portare a qualche vantaggio molto spesso da un punto di vista economico.
Il modello predittivo di Data Mining si può dire che si usa quando si conosce cosa cercare e si indirizzano gli sforzi d’analisi verso un obiettivo specifico. Questo modello è costruito secondo la modalità top-down a partire da esempi già noti e si applica poi a esempi non noti. Questo, infatti, è rappresentato da una black box: a volte non interessa il meccanismo di funzionamento ma interessa la migliore previsione possibile. Per esempio:
1. Previsione della possibile risposta del consumatore ad una certa campagna di mercato.
2. Previsione delle possibili perdite di consumatori nel medio/lungo periodo.
3. Classificare le richieste di prestiti, mutui, applicazioni per carte di credito in fasce di basso/medio/alto rischio.
1.8.1 Data Mining Tasks
I tasks del data mining possono essere in 2 categorie: data mining descrittivo e data mining predittivo.
In generale un sistema di data mining può comprendere uno o più dei seguenti tasks:
o Descrizione delle classi. La descrizione delle classi provvede ad un succinto e conciso riassunto (se così si può chiamare) di una collezione di dati .Una comparazione tra due o più collezioni di dati è chiamata “class comparison” o “discrimination”.
Per esempio la descrizione delle classi può essere usata per mettere a confronto i prezzi Europei e quelli Asiatici di una stessa azienda, identificando così diversi fattori che rendono differenti le due classi, presentando così un piccolo resoconto.
o Associazione . L’associazione è la scoperta di relazioni o correlazioni tra insiemi di oggetti (se ne parlerà in particolare in seguito).
Spesso sono espresse per mostrare delle condizioni (o valori-attributi) che occorrono in modo frequente (insieme) in un dato insieme di dati.
o Classificazione . La classificazione provvede all’analisi di un insieme di dati e a costruire un modello per ogni classe, basato sulle caratteristiche dei dati.
Ci sono molti metodi di classificazione che man mano si stanno sviluppando come ad esempio nel campo del machine learning, statistica, database, reti neurali, ecc.
o Predizione . Questa funzione di mining predice i possibili valori di un determinato dato mancante o la distribuzione di valori di certi attributi in un insieme di oggetti. Diciamo che la predizione sviluppa una ricerca di un insieme di attributi rilevanti in base a delle conoscenze già pre-acquisite. Per esempio il salario potenziale di alcuni dipendenti può essere “predetto” basandosi sulla distribuzione dei salari di dipendenti con caratteristiche simili nella compagnia.
Algoritmi genetici e modelli di reti neurali stanno avendo una crescente popolarità in questo ambito.
o Clustering . Per cluster si intende una collezione di oggetti che in qualche modo sono simili tra loro. Questa somiglianza può essere espressa attraverso alcune funzioni o specificata dagli utenti o da esperti. Un buon metodo di clustering produce dei cluster, o degli aggregati, di alta qualità, dove per alta qualità si intende il fatto che gli oggetti all’interno del cluster abbiano una somiglianza molto forte e quelli esterni a cluster abbiano una bassa somiglianza con gli oggetti di altri cluster.
o Analisi delle serie temporali . L’analisi delle serie temporali tiene presente un intervallo di tempo abbastanza ampio e un insieme di dati abbastanza cospicuo e cerca di determinare alcune regolarità e caratteristiche interessanti in questo flusso di dati. Questo include la ricerca di sequenze o sottosequenze simili, pattern sequenziali e periodicità. Per esempio si può prevedere la tendenza dei valori di stock di una compagnia basandosi su una lista in funzione del tempo dei propri stock, sulla situazione finanziaria, e sul mercato attuale.
1.8.2 Le tecniche di Data Mining
Brevemente si cercherà di descrivere le varie categorie che fanno parte delle tecniche di data mining allo scopo di comprendere meglio fli argomenti del capitolo seguente.
1.8.3 Il Clustering
Il clustering è la classificazione di patterns in gruppi (cluster). Si può considerare il clustering come il problema più importante di apprendimento non supervisionato. Il problema del clustering è stato trattato in diversi contesti e da diversi ricercatori in molte discipline. Le tecniche di clustering vengono utilizzate generalmente quando si hanno tanti dati eterogenei e si è alla ricerca di elementi anomali. Per esempio le compagnie telefoniche utilizzano le tecniche di clustering per cercare di individuare in anticipo gli utenti che diventeranno morosi. Normalmente questi utenti hanno un comportamento nettamente diverso rispetto alla maggioranza degli utenti telefonici e le tecniche di clustering riescono sovente ad individuarli o comunque definiscono un cluster dove vengono concentrati tutti gli utenti che hanno un'elevata probabilità di diventare utenti morosi.
Tipicamente l’attività di clustering evolve con i seguenti passi :
1. rappresentazione di patterns;
2. definizione di una misura appropriata per i pattern nel dominio dei dati; 3. clustering o raggruppamento;
4. astrazione dei dati;
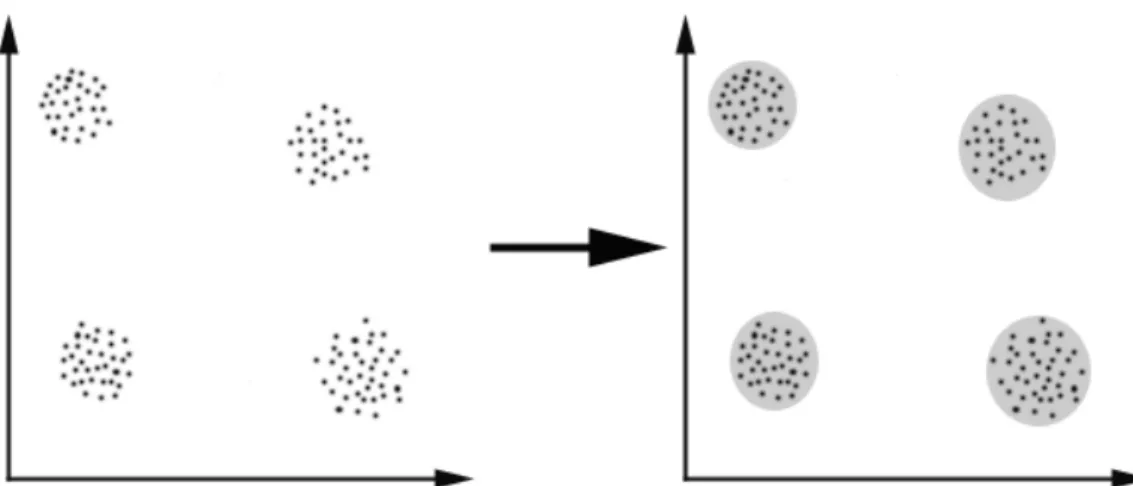
Come già accennato il clustering ha lo scopo di raggruppare gli oggetti di un determinato insieme di dati in un numero di classi che in qualche modo siano simili tra loro ma distinti il più possibile dalle altre classi. Si può vedere un esempio in figura 6.
figura 6: In questo esempio abbiamo identificato 4 cluster in cui i dati possono essere divisi; il criterio di similarità è la distanza. Due o più oggetti appartengono allo stesso cluster
se sono vicini in accordo con un certo criterio di distanza (in questo caso distanza geometrica).
Naturalmente per fare questo bisogna in qualche modo sapere il numero delle classi e le proprie caratteristiche principali.
Il raggruppamento molte volte dipende dal calcolo della somiglianza o di quanto due cluster sono distanti tra di loro (in base alle loro caratteristiche). I metodi di raggruppamento in generale possono essere valutati anche basandosi su una precedente “conoscenza” dei dati. Alcuni metodi per esempio richiedono come input il numero di classi anche se la descrizione delle classi e l’assegnamento di casi individuali può essere non noto.
Come una branca della statistica, il clustering è stato studiato per diversi anni. Dei sostanziali progressi sicuramente sono stati fatti nell’ambito delle reti neurali in applicazioni che riguardano l’identificazione e la diagnosi di errori nei processi industriali.
Tramite il clustering per esempio si possono identificare regioni popolate o sparse, elaborazione di immagini o ricerche di mercato.
Ma come si può decidere se abbiamo effettuato un buon clustering?
Si può certamente dire che non esiste un criterio ottimo assoluto indipendente dallo scopo finale del clustering. Conseguentemente è l’utente che deve sopperire alla mancanza di questo criterio. Per esempio potremmo essere interessati alla ricerca di gruppi omogenei rappresentativi (data reduction) nella ricerca di ”cluster naturali” e descrivere le caratteristiche nascoste, o ricercare oggetti nei dati non usuali (ricerca degli outliers).
1.8.3.2 Applicazioni del Clustering
Gli algoritmi di clustering possono essere applicati in alcuni campi, per esempio:
• Marketing: dato un grande database contenente dati riguardo ai clienti (come informazioni personali e ultimi acquisti effettuati), cercare un insieme di clienti con comportamento simile;
• Biologia: classificazione di piante ed animali date le proprie caratteristiche;
• Assicurazione: identificare gruppi di persone che hanno polizze auto o moto con un certo tasso di incidenti; identificazione delle ffrodi in questo ambito;
• Pianificazione cittadine: identificare gruppi di case con caratteristiche, valore o posizionamento geografico simili alla propria;
• Studio dei terremoti: clustering degli epicentri dei terremoti osservati per identificare zone a rischio;
• WWW: classificazione di documenti;clustering di file dio log per scoprire gruppi di pattern simili.
1.8.3.3 Algoritmi di Clustering
Esistono molti algoritmi di clustering. In generale si effettua una scelta sulla base del tipo di dati disponibile e sulla particolare applicazione ce se ne sta facendo.
In generale però si deve dire che gli algoritmi di clustering devono soddisfare una serie di requisiti tra cui:
1. Scalabilità
2. Compatibilità con differenti tipi di attributi 3. Scoperta di cluster con forme differenti
4. Minime richieste per il dominio di conoscenza per determinare i parametri di input
5. Capacità di essere trasparente al rumore e agli outliers 6. Insensibilità all’ordine dei record di input
7. Facilmente interpretabili ed usabili
8. Capacità di elaborazione di grosse quantità di dati
Di pari passo con i requisiti ci sono una serie di problematiche strettamente legate:
- Le tecniche di clustering correnti non indirizzano tutti i requisiti adeguatamente;
- Quando si ha a che fare con grosse quantità di dati, può essere ci possono essere alcuni problemi legati alla complessità temporale; - L’effettiva efficienza dei metodi di clustering può dipendere dal
concetto di distanza (per i metodi distance-based);
- Se non esiste un’ovvia misura di distanza dobbiamo crearne una ad hoc, questo non è sempre banale, spesso quando si ha a che fare con problemi multidimensionali;
- Il risultato degli algoritmi di clustering ( che in molti casi può essere esso stesso arbitrario) può essere interpretato in modi differenti.
Infatti, come precedentemente accennato, la bontà delle analisi ottenute dagli algoritmi di clustering dipende essenzialmente da quanto è significativa la metrica e quindi da come è stata definita la distanza. La distanza è un concetto fondamentale dato che gli algoritmi di clustering raggruppano gli elementi a seconda della distanza e quindi l'appartenenza o meno ad un insieme dipende da quanto l'elemento preso in esame è distante dall'insieme. Le tecniche di clustering si possono basare principalmente su due filosofie.
Bottom Up:
Questa filosofia prevede che inizialmente tutti gli elementi siano considerati cluster a sé e poi l'algoritmo provvede ad unire i cluster più vicini. L'algoritmo continua ad unire elementi al cluster fino ad ottenere un numero prefissato di cluster oppure fino a che la distanza minima tra i cluster non supera un certo valore.
Top Down:
All'inizio tutti gli elementi sono un unico cluster e poi l'algoritmo inizia a dividere il cluster in tanti cluster di dimensioni inferiori. Il criterio che guida la divisione è sempre quello di cercare di ottenere elementi omogenei. L'algoritmo procede fino a che non ha raggiunto un numero prefissato di cluster. Questo approccio è anche detto gerarchico.
A prescindere da ciò detto precedentemente si possono riconoscere le seguenti categorie di algoritmi di clustering:
clustering gerarchico,clustering esclusivo, clustering probabilistico, overlapping clustering .
1.8.3.4 Clustering gerarchico
cluster vicini. La condizione iniziale è realizzata settando ogni dato come un cluster. Dopo alcune iterazioni si raggiunge la configurazione di cluster desiderata. Questi algoritmi sono tra i più semplice da visualizzare.
Questo tipo di clustering può essere supervisionato cioè utilizzare informazioni note sui dati prima dell’esecuzione degli algoritmi.
Ed è agglomerativo cioè parte da un singolo record per poi arrivare a costruire dei gruppi di record raccolti in cluster, fondendo i cluster in maniera iterativa. Un’altra opzione è quella di rendere il processo di clustering divisivo, cioè si parte da un insieme in cui esiste un solo cluster che include tutti gli item e poi man mano si effettuano degli split dividendo il cluster principale in altri sotto-cluster più piccoli (questi metodi vengono applicati più di rado).
Vediamo un esempio di come lavora un algoritmo di clustering gerarchico. Dato un insieme di N item da classificare e una matrice delle distanze N*N, il processo di base del clustering gerarchico si può riassumere come:
1. Si inizia assegnando ogni item ad un cluster; in questo modo abbiamo N item ed N cluster (ognuno contenente un solo item). La distanza tra i cluster è uguale alla distanza che c’è tra i singoli oggetti.
2. Si cerca la coppia di cluster più simili tra loro e si fa un merge, generando così un nuovo cluster (si ha un cluster in meno).
3. Si ricalcala la distanza tra il nuovo cluster e tutti gli altri cluster che sono nell’insieme.
4. Si ripetono i passi 2 e 3 fin quando tutti gli elementi sono clusterizzati in un singolo cluster di dimensione N.
Il passo 3 può essere fatto in modi differenti, si può infatti distinguere tra average-linkage, single linkage, complete-linkage.
Con un metodo average-linkage consideriamo come distanza tra due cluster A e B, la media delle distanze di ogni membro del cluster A con ogni membro del cluster B.
Il clustering con single-linkage (chiamato anche metodo del minimo) invece, si considera come distanza tra un cluster A e un cluster B , la distanza più corta tra ogni membro di A e ogni membro di B.
Il metodo del complete-linkage (chiamato anche metodo del massimo) invece, prevede di assegnare come distanza tra i cluster A e B il la distanza più grande tra gli elementi che appartengono ad A e quelli che fanno parte di B.
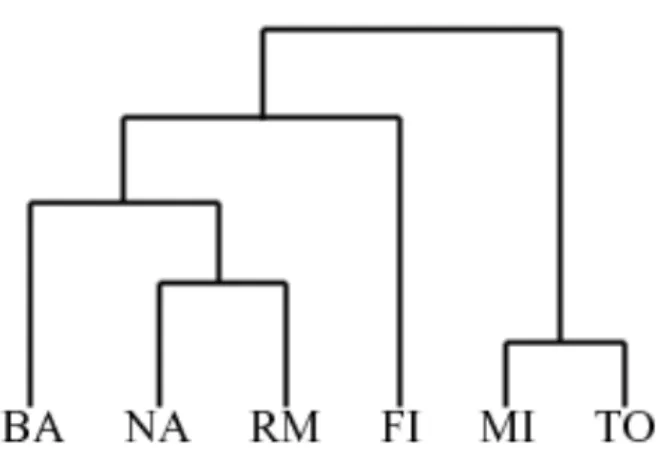
Mostriamo di seguito un semplice esempio di clustering gerarchico in cui è utilizzato il metodo single-linkage e le distanze tra le entry della tabella sono espresse in chilometri:
La coppia di città più vicine è (MI ,TO) che si trovano ad una distanza di 138 Km. Questi due cluster vengono fusi in uno solo chiamato MI/TO. Ora si deve ricalcolare la distanza da tutti gli altri cluster utilizzando la modalità single linkage (la distanza tra RM e MI/TO )e si ottiene la matrice seguente:
A questo punto si ha che min distanza(i,j) = distanza(NA,RM) = 219 quindi può fare un merge del cluster NA e del cluster RM fondendoli insieme in un nuovo cluster che chiameremo NA/RM. In seguito quindi, verrà assegnata L(NA/RM) = 219. Di qui si otterà la matrice seguente:
Alla terza iterazione si ha che min distanza(i,j) = distanza(BA,NA/RM) = 255. Cioè si può effettuare una fusione dei cluster BA e NA/RM fondendo le righe della tabella in una sola (un altro cluster) che possiamo chiamare BA/NA/RM. Come al solito si aggiorna il valore del livello del nuovo cluster impostandolo a L(BA/NA/RM) = 255. La matrice ottenuta ricalcolando tutte le distanze sarà:
Al quarto passo si ottiene : min distanza(i,j) = distanza(BA/NA/RM,FI) = 268. Ciò vuol dire che si deve effettuare una fusione delle righe della tabella BA/NA/RM e FI creando una sola riga denominata BA/FI/NA/RM che ha un livello pari a L(BA/FI/NA/RM) = 268. La tabella al passo successivo sarà :
Alla fine verranno fusi gli ultimi due cluster al livello 295. L’intero processo mostrato in questo esempio può essere riassunto con l’albero mostrato in figura 7.
figura 7 : albero di cluster
1.8.3.5 Misura della Distanza
Da come abbiamo potuto notare dagli esempi precedenti, il concetto di distanza ricopre un ruolo di prima importanza. In particolare quando si parla di algoritmi di clustering, differenti misure di “distanza” possono portare a variazioni significative nei risultati.
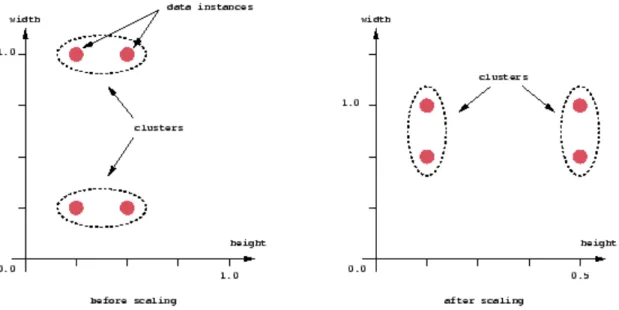
Se le componenti dei vettori delle distanze tra i dati sono nella stessa unità fisica, è possibile che una semplice distanza euclidea possa bastare per ottenere dei buoni cluster. Ma molte volte il concetto di distanza euclidea può non essere sufficiente per ottenere dei cluster in cui gli oggetti siano accumunati da carateristiche simili. Consideriamo ad esempio il caso in cui si voglia effettuare una scaling nella rappresentazione dei dati ( come mostrato in figura 8). In questo caso infatti, anche se le misure sono state prese nella stessa unità fisica, modalità differenti di rappresentazione in scala portano a risultati completamente diversi per ciò che riguarda il clustering.
Si deve notare che questo non è un problema puramente grafico, ma la questione deriva esclusivamente dalla formula matematica usata per combinare le distanze dei singoli componenti dei vettori che caratterizzano i dati in un’unica misura di distanza che può essere utilizzata con un impiego specifico nell’ambito del clustering.
figura 8 : scaling rappresentazione dei dati
1.8.4 La Classificazione
La classificazione è il processo che permette di cercare proprietà comuni in un insieme di oggetti in un database.
Lo scopo della classificazione è di assegnare ciascun oggetto del database ad un gruppo o ad una classe in accordo ad alcuni “modelli di classificazione”.
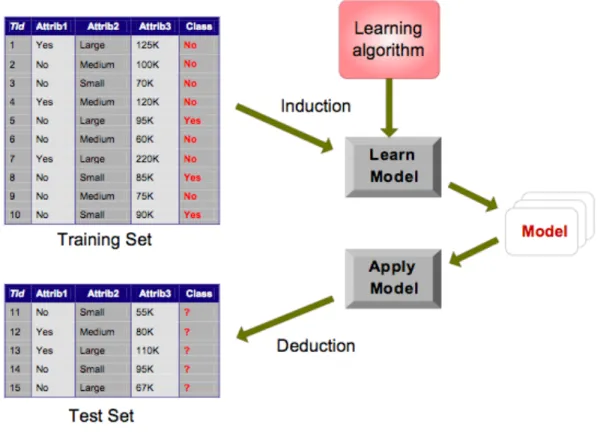
Di seguito (figura 9) è illustrato il Task completo di un processo di classificazione per la costruzione di un modello.
Per costruire un modello di questo tipo una parte del database viene considerata come “training set” che permette all’algoritmo di classificazione di incrementare la sua conoscenza in relazione alle classi e alle loro proprietà in modo tale da poter creare correttamente il modello di classificazione e può quindi essere usato per classificare tutti i record rimanenti del database.
figura 9 : processo di classificazione
In modo molto generico il processo di classificazione viene diviso in tre fasi:
1) Apprendimento: L’algoritmo scandisce tutti i record del cosiddetto “training set” e crea una descrizione del modello di classificazione. Questo modello deve essere allo stesso tempo breve e preciso;
2) Il modello creato al primo passo è di nuovo testato su un sottoinsieme di prova del database. Come per il training set anche i record dell’insieme utilizzato per il test devono essere classificati.
3) Classificazione : Il modello di classificazione è usato per classificare il resto dei records del database.
IL più diffuso modello di classificazione è sicuramente l’albero di decisione (decision tree), ma sono ampiamente utilizzati anche altri metodi di classificazione come Reti Neurali, operatori Bayesiani, Support Vector Machines e operatori basati sulle regole.
Un albero decisionale prende come input un oggetto o una situazione descritti da un insieme di attributi e dà in uscita una “decisione” cioè il valore di output predetto sull’input inserito. Gli attributi in input possono essere discreti o continui. Anche l’output può essere discreto o continuo.
L’apprendimento di una funzione a valori discreti è chiamato classificazione; l’apprendimento di una funzione a valori continui è chiamato regressione.
Il problema della costruzione di un albero decisionale può essere espresso ricorsivamente. Prima si seleziona un attributo da posizionare al nodo radice e costruire un ramo per ogni possibile valore.
Cosi facendo si divide il dataset in dataset più piccoli. Il processo può ora essere ripetuto ricorsivamente per ogni ramo, usando solo quelle istanze che nel passaggio corrente raggiungono il ramo. Se in ogni momento tutte le istanze al nodo hanno la stessa classificazione, si blocca lo sviluppo di quella parte dell’albero. Un albero decisionale raggiunge la sua decisione eseguendo una serie di test. Ogni nodo interno all’albero corrisponde ad un test del valore di una delle proprietà e i rami provenienti dal nodo sono etichettati con i possibili valori del test. Ogni nodo-foglia nell’albero specifica il valore da ritornare se quella foglia viene raggiunta.
La figura 10 mostra un esempio di albero decisionale i nodi interni sono rappresentati da ellissi e i nodi foglia da quadrati.
Quando si ha la disponibilità di un grande insieme di ipotesi disponibili, bisogna stare attenti a non usare questa vasta scelta per trovare regolarità insignificanti nei dati. Questo problema è chiamato overfitting (sovrastima). Un modo per risolvere questo problema è quello di usare delle tecniche di sfoltitura (pruning).
Pruning
Vi sono due strategie generali di pruning applicabili agli alberi decisionali: • pre-pruning
• post-pruning
Pre-pruning
Il pre-pruning riguarda la scelta di fermare lo sviluppo dei sottoalberi durante il processo di costruzione dell’albero decisionale.
Applicando il pre-pruning si individua una misura del livello di associazione tra un attributo e la classe, in un determinato nodo dell'albero e si divide un nodo solo se esiste un attributo che ha un livello di associazione che supera una soglia prefissata.
Il metodo di pre-pruning ha vari problemi come scegliere il valore di soglia e quello che viene chiamato early stopping, cioé l’interruzione prematura della costruzione dell'albero.
Post-pruning
Nella tecnica del post-pruning si utilizza un insieme di dati indipendenti sia da quelli di test che da quelli di training. Si calcola il tasso di errore dell'albero prima e dopo dell'operazione di sfoltimento e si sceglie di effettuare lo
sfoltimento se il tasso di errore diminuisce. La maggior parte degli algoritmi di induzione di alberi decisionali preferisce usare il post-pruning che dà spesso risultati migliori.
Vi sono inoltre, due opzioni possibili per sfoltire l’albero con la tecnica del post-pruning:
• Subtree-replacement
Utilizzando il subtree-raising viene rimpiazzato un sottoalbero con una foglia. Questa è un’operazione che peggiora le prestazioni dell'albero sull'insieme di addestramento, ma può migliorarle su un insieme di dati indipendente.
• Subtree-raising
Questa operazione risale l’albero tagliando delle porzioni, essa è più complessa della precedente e non è ben chiaro se offra una vera utilità.
Un problema frequente nel processo di induzione di un albero decisionale è la scelta di una funzione euristica che serva a decidere le divisioni da compiere nell’albero. Un principio generale che si segue in questi casi è quello del rasoio di Ockham che afferma che bisogna sempre preferire la più semplice delle ipotesi purché questa sia consistente con i dati. Applicando questo principio agli alberi decisionali, esso implica che bisogna costruire un albero più piccolo possibile.
I metodi per decidere le divisioni in un albero sono diversi, forse quello più noto è quello basato sul concetto di entropia mutuato dalla teoria dell’informazione, vi è poi il test del chi quadrato e l’analisi quadratica del discriminante.
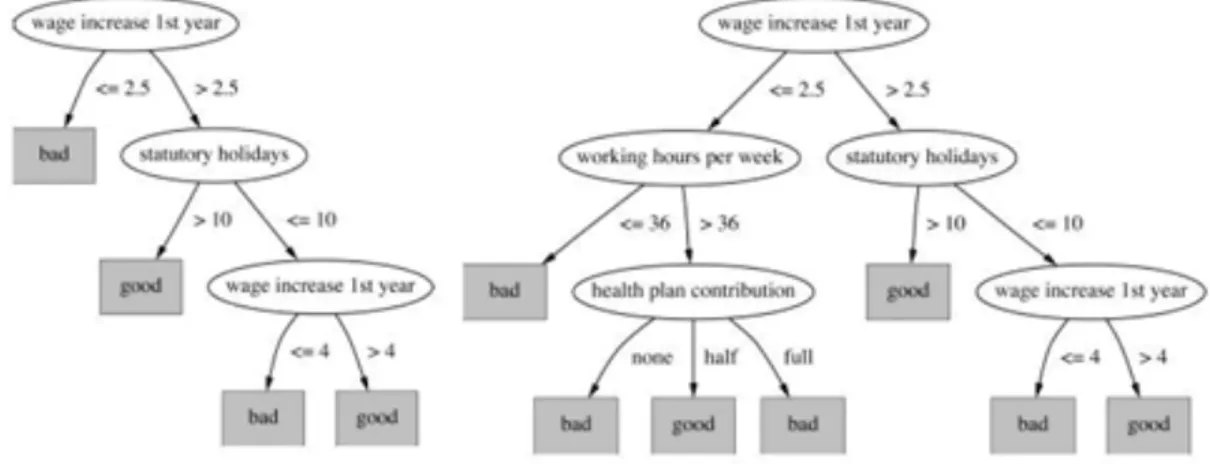
Consideriamo adesso un esempio di classificazione con un albero di decisione. L’albero di decisione è un albero in cui ogni nodo è associato ad un test per un attributo di un record del database. Un esempio di albero di decisione è riportato in figura 11.
figura 11 : esempio di albero di decisione
La classificazione di ogni record è fatta semplicemente seguendo l’albero dalla radice alle foglie e scegliendo il figlio giusto ad ogni iterazione secondo il risultato del test dei rami. Le foglie dell’albero indicano la classe del record (vedi figura 12).
Quando il problema però si fa più complesso il modello di classificazione non dà il giusto esito per ogni record. Questo perchè il modello in qualche modo deve essere testato per rendersi conto se è o meno realistico. Creando un modello con un probabilità di errore molto bassa la cosa complicata è quella di creare contemporaneamente un modello con una descrizione molto breve.
Dato che la classificazione aiuta a dividere un database in piccolo gruppi omogenei, la classificazione è considerata come uno dei compiti di base del data mining.
figura 12 : classe del record di esempio
1.8.5 Regole Associative e Market Basket
L'association rules model riguarda l'analisi di pattern frequenti in un insieme di dati.
Infatti il “modello a regole associative” è utilizzato proprio per la cosiddetta Market Basket Analysis il cui scopo è quello di trovare delle regolarità nel comportamento dei clienti di un supermercato, compagnie che fanno ordinazioni via posta, o negozi on-line.
In pratica con questo metodo di solito si cercano dei prodotti che vengono acquistati insieme tenendo conto di alcuni parametri che verranno spiegati in seguito.
Tutte queste informazioni espresse sotto forma di regole associative, possono essere usate per aumentare il numero di prodotti venduti, per esempio disponendo in un modo particolare i prodotti sugli scaffali di un supermercato (per esempio i prodotti che risultano far parte di itemset frequenti possono
essere messi vicini sullo scaffale per portare i clienti ad acquistarli contemporaneamente).
Il problema principale delle regole associative è che considerando un database abbastanza vasto le possibili regole sono tantissime. È ovvio che un vasto numero di regole non può essere elaborato analizzandole una per una.
Sono necessari quindi degli algoritmi efficienti per restringere lo spazio di ricerca,analizzando solo un sottoinsieme delle regole associative senza tralasciare quelle importanti.
Il modello a regole associative consente la creazione di regole che permettono di associare un set di elementi ad un altro set di elementi.
Un esempio ( classico) di scenario di utilizzo di questo modello potrebbe essere quello del supermercato: quello che si vuole ottenere è di riuscire a legare in qualche modo l'acquisto di un prodotto all'acquisto di (uno o) altri prodotti.
Per capire meglio l'ambito in cui ci si trova è opportuno fare un esempio (naturalmente in miniatura) di un ambiente di questo tipo.
Consideriamo per esempio il seguente insieme di transazioni (in questo caso sono degli scontrini) in un database di un supermercato:
T1 : acqua , pane , vino , dentifricio T2 : acqua , mela , vino
T3 : acqua , dentifricio , vino
Quello che si vuole ottenere è un insieme di regole che permettono di stabilire alcune relazioni tenendo conto della frequenza degli articoli nel database.
Considerando l'esempio precedente si potrebbe arrivare alla conclusione che l'articolo “vino” è presente ogni volta che lo è anche l'articolo “acqua”, mentre l'articolo “dentifricio” è presente con “acqua” solo in una certa frazione delle transazioni.
Detto in altre parole dall’analisi dei record dell’esempio precedente potremmo giungere alla conclusione che l’articolo “vino” è presente ogni volta che lo è
l’articolo “acqua”, mentre l’articolo dentifricio è presente insieme ad acqua solo in una certa frazione dei record.
In modo molto generico lo scopo di questo tipo di analisi è quello di produrre delle regole del tipo:
if ( acqua AND vino ) THEN dentifricio
Per ogni regola è possibile definire alcune grandezze che in un certo senso ne misurano la “bontà”.
In particolare si introduce il concetto di supporto definito come la probabilità di osservare ciascun articolo presente nella regola in un record del database.
Per questo motivo, data la grandezza del database (#D) e il numero di transazioni del database in cui è presente l’elemento considerato (#P), il supporto per l’elemento è:
!
Supporto = # P # D
Un altro parametro significativo in questo ambito è dato dalla cosiddetta confidenza. Questo parametro specifica il livello di confidenza minimo richiesto per una regola.
La confidenza di una regola X ⇒ Y è data da:
!
Supporto(X " Y )
Supporto(X)
Piatetsky-Shapiro ([PSF91]) hanno proposto la simbologia delle regola associative e più in particolare che:
i. le regole delle tabelle relazionali fossero della forma C → D , dove C e D sono condizioni o tuple della tabella relazionale;
ii. una regola può essere esatta; ciò vuol dire che tutte le tuple che soddisfano C soddisfano anche D;
iii. una regola può essere forte; ciò vuol dire che le tuple che soddisfano C quasi sempre soddisfano anche D;
iv. una regola può essere approssimata; ciò vuol dire che alcune delle tuple che soddisfano C soddisfano anche D;
Uno dei risultati più importanti riportati in [PSF91] è che una regola del tipo X → Y non è interessante se support( X → Y) ≈ support(X) × support(Y).
In definitiva il problema della ricerca delle regole associative può essere spezzato nettamente in due sotto-problemi e più in particolare:
(1) Generare tutti gli itemsets che hanno un supporto più grande o uguale al minimo supporto specificato dall’utente.
(2) Generare tutte le regole che hanno una confidenza minima e un minimo supporto in questo modo:
Per ogni itemset frequente X, e ogni B contenuto in X , sia A = X – B. Se la confidenza di una regola A → B è maggiore o uguale alla minima confidenza questa allora può essere estratta e segnalata come una regola valida.
Si può affermare in modo abbastanza certo che sulla complessità di un sistema che si basa su un modello a regole associative impatta pesantemente la complessità del corrispondente algoritmo per l’estrazione di itemset frequenti. Infatti il secondo passo è molto più semplice del primo, quindi la performance globale di un sistema a regole associative è determinata dal passo (1).