3
METODI DI PREVISIONE CON RETE NEURALE
3.1
Generalità sulle reti neurali
Questa parte iniziale del lavoro vuole essere una introduzione al mondo delle reti neurali lineari, ponendo l’attenzione principalmente alle strutture utilizzanti le Radial Basis Function. La possibilità di utilizzare reti neurali per la previsione della potenza assorbita da una utenza è un argomento di studio e di ricerca ancora molto vasto, dentro al quale si possono ritrovare diversi tipi di approccio al problema. La scelta fatta in questo caso è stata quella di utilizzare una architettura della rete molto semplice, descritta principalmente da relazioni matematiche lineari (sebbene vengano utilizzati, in alcune parti, criteri di ottimizzazione non lineari) con conseguenti prestazioni di tipo computazionale più veloce.
Le reti neurali artificiali sono composte da semplici elementi operanti in parallelo, così come avviene nei sistemi nervosi biologici. Come accennato precedentemente si possono adoperare architetture molto complesse per riproporre la struttura di un sistema nervoso naturale. Inoltre esistono vari tipi di funzioni utilizzate per la realizzazione del neurone, il cui modello più utilizzato è il percettrone.
In questa applicazione si è utilizzato una struttura con un unico livello di neuroni come mostrato nella seguente figura:
x1 xi xn h1(x) hi(x) hm(x) f(x) w1 wi wm vettore di ingresso strato di neuroni
Fig. 131 Struttura di una rete neurale ad un livello
dove:
i
h : funzioni di attivazione dei neuroni. i
w : pesi da applicare alle uscite di ogni neurone.
La scelta delle funzioni di attivazioni delle unità nascoste (neuroni) è ricaduta sulle RBF (basi di funzioni radiali). La caratteristica principale di queste funzioni è che sono locali, cioè la loro risposta decresce in maniera monotonica all’aumentare della distanza dal loro centro.
Una tipica funzione radiale è la Gaussiana
− − = 2 2 ) ( r c x e x h
Altre comuni scelte per le funzioni radiali sono la Inversa Multiquadratica
(
)
2 2 ) ( r c x r x h + − =la funzione di Cauchy,
(
)
2 2 2 ) ( r c x r x h + − =tutte funzioni di tipo locale.
Tutte le RBF presentate sono caratterizzate dalle grandezze c e r , ovvero il centro e
l’ampiezza o grandezza (in letteratura inglese r è descritta come “size” o “width”) della
funzione radiale. Una rete basata sulle RBF è non-lineare se, durante la fase di allenamento, le funzioni radiali possono muoversi (cioè cambiare centro), cambiare ampiezza oppure se sono presenti più di uno strato nascosto. Nella presente trattazione avendo la rete sia c che r fissati
e un solo strato di neuroni, il problema, come detto prima, è lineare, ed infatti l’uscita della rete è determinabile come combinazione lineare delle uscite di ogni neurone (o RBF) (vedi fig. 131):
∑
= ⋅ = m i i i h w x f 1 ) ( ) ( xLa struttura della rete, ovvero il numero di neuroni che la costituiscono e i pesi w , è i
determinata nella cosiddetta fase di allenamento (training). In questo processo, per ogni ingresso dato alla rete, viene anche fornito un riferimento (target) che deve essere generalmente uguagliato dall’uscita della rete al termine dell’allenamento.
Rete Neurale
ingresso uscita
comparazione riferimento
adeguamento pesi
Per questo motivo la struttura viene modificata affinché la rete restituisca in uscita una grandezza se non proprio uguale, quanto meno “più vicina” possibile al riferimento dato. Tipicamente vengono date più coppie ingresso/riferimento in questa fase di allenamento noto come allenamento supervisionato (supervised learning).
Nel seguente paragrafo viene analizzata nel dettaglio la procedura che porta alla realizzazione della rete neurale, introducendo i vari principi, tra cui quello del forward selection, che sono alla base della costruzione della rete utilizzata così come descritto da Mark J. L. Orr [5,6], del quale si sono inoltre utilizzate le functions che permettono di descrivere e realizzare nel linguaggio Matlab la rete neurale.
3.2
Creazione e struttura della rete neurale
Come accennato precedentemente il modello lineare cui si fa riferimento è
∑
= ⋅ = m i i i h w x f 1 ) ( ) ( x (5)dove le funzioni di attivazioni hi(x), o regressori, sono determinate allorché sono noti i centri
c, i raggi r e il vettore degli ingressi x , e dove le uniche incognite sono i pesiw . i
L’equazione 5 può essere scritta in forma matriciale e, introducendo l’insieme di allenamento
(training set)
{
xi,yi}
1p (dove y si suppongono scalari per semplicità), si può ottenere il iseguente sistema e w H y= ⋅ + (6) dove = ) ( ) ( ) ( ) ( 1 1 1 1 p m p m h h h h x x x x H L M O M L (7)
è la matrice p×m chiamata design matrix i cui elementi sono la risposta di ogni singolo neurone agli ingressi dell’insieme di allenamento,
[
]
T p y y L 1 = y (8)è il vettore delle uscite o riferimenti dell’insieme di allenamento, ed e è il vettore degli errori
tra i riferimenti e l’uscita effettiva della rete H⋅w.
Una volta stabilite la forma e la posizione delle RBF, il problema della creazione della rete si identifica nel determinare i pesi ottimali (ovvero la miglior combinazione lineare delle colonne di H) per ottenere l’errore più piccolo. Il processo di ottimizzazione dei pesi si riduce quindi ad un problema di minimi quadrati, ovvero nel minimizzare (rispetto a w ) una funzione costo
identificata nella somma degli errori quadratici:
e
e ⋅
= T
E (9)
La soluzione di questo problema è:
(
H H)
H yw = T ⋅ −1⋅ T ⋅
(10)
L’equazione 10 mostra come sia fondamentale per la soluzione del problema di ottimizzazione la conoscenza, oltre ovviamente dell’insieme di allenamento, della design matrix H e quindi
dei centri e dei raggi delle RBF. Per la scelta dei centri la procedura più comune che si possa trovare in letteratura è quella di porli uguale agli ingressi dell’insieme di allenamento, cioè
i
i x
c = (11)
Per quanto riguarda i raggi la scelta è più complicata non esistendo delle procedure standard che forniscano indicazioni a riguardo. Esiste innanzitutto la possibilità di utilizzare un valore di
r diverso per ogni RBF oppure di mantenere un valore costante comune a tutte le funzioni.
Generalmente si predilige adottare un valore unico per tutti i neuroni in quanto questo tipo di scelta non inficia assolutamente le prestazioni della rete.
Quale valore dare infine al raggio è un problema non ancora risolto; infatti non sono state ancora introdotte delle procedure standard che permettono di scegliere il valore ottimo per r.
Esistono diversi metodi di tipo euristico che permettono cioè di identificare un valore ottimo per r tramite solamente una serie di prove. Orr [7] suggerisce di adottare come valore la metà
della massima distanza che separa coppie di ingressi dell’insieme di allenamento. Dello stesso tipo è il metodo adottato da Kapetanios [8] nel cui articolo adotta un valore del raggio pari a al doppio del massimo cambiamento tra due consecutivi ingressi in fase di allenamento.
Nel presente lavoro si è scelto, utilizzando i criteri di selezione del modello descritti più avanti nel capitolo, di utilizzare un solo valore per il raggio scegliendolo da un insieme di valori fissati a priori. Ovvero per ogni valore dell’insieme è stato eseguito l’allenamento della rete, durante il quale i criteri citati stimavano quanto bene si sarebbe comportata la stessa in futuro con ingressi diversi da quelli d’allenamento, restituendo una stima dell’errore di predizione. Il raggio scelto è stato quello associato all’errore di predizione più piccolo.
La scelta di un numero elevato di centri (neuroni), e quindi un elevato numero di parametri liberi, può portare ad una sensibilità troppo elevata da parte della rete nei confronti dei dati di allenamento. Questa sensibilità si traduce in una eccessiva capacità interpolante dei dati di allenamento da parte della rete perdendo la caratteristica fondamentale della generalizzazione (problema dell’overfit). Il caso estremo di una scelta elevata di centri è quello in cui essi sono
posti uguali agli ingressi dell’insieme dell’allenamento (eq. 11). La matrice che si viene a formare è nota come full design matrix.
Per evitare l’overfit esistono due metodi, entrambi utilizzati nel presente lavoro. Il primo,
conosciuto come regolarizzazione di ordine zero (zero-order regularization) o regressione
ridge (ridge regression), consiste nell’introdurre una parametro, chiamato coefficiente di
regolarizzazione e solitamente indicato con λ, che penalizza i pesi troppo grandi che legano l’ingresso all’uscita della rete nel processo di minimizzazione della funzione costo (eq. 9). L’introduzione del coefficiente di regressione porta quindi ad una nuova funzione costo
w w e e ⋅ + ⋅ ⋅ = T T E λ (12)
che se minimizzata rispetto a w dà come soluzione:
(
F F I)
F yw = ⋅ + ⋅ − ⋅ T ⋅
P
T λ 1
dove:
F: è la full design matrix.
IP: è la matrice identica di dimensioni p× p
Il coefficiente di regolarizzazione deve essere scelto prima del processo di allenamento; in questo caso esistono dei metodi ricorsivi che, assegnato un valore iniziale a λ, permettono di calcolare ad ogni passo della costruzione della rete il coefficiente migliore. Più avanti verranno descritte brevemente queste procedure.
Il secondo metodo per evitare l’overfit è quello di limitare il numero dei neuroni che costituiscono la rete, riducendo quindi anche la complessità della struttura. Partendo dall’insieme di neuroni disponibili, ovvero le colonne di F, la procedura nota come forward selection consiste nel prelevare un neurone alla volta e inserirlo in un sottoinsieme inizialmente
vuoto fino a quando un termine di controllo del processo raggiunge un valore prefissato o ad esempio smette di diminuire. La forward selection fa parte di ciò che nella statistica è nota
come selezione di sottoinsiemi (subset selection). Non potendo paragonare tra loro tutte le
possibili frazioni dell’insieme di partenza, la procedura adottata rappresenta un modo per ricercare un sottoinsieme valido per il problema in esame, anche se non è assicurato che sia il migliore.
L’unione della ridge regression e del forward selection , nota come regularized forward selection (RFS), costituisce quindi la procedura adottata nel presente lavoro per ricavare la rete
neurale. Di seguito viene mostrato un esempio di come si aggiunge un neurone alla rete che si sta costruendo.
Supponiamo di essere al generico passo m della procedura, durante il quale alla matrice Hm−1
viene aggiunta una nuova colonna f , ottenendo i
[
m i]
m H f
H = −1 (14)
La colonna f è stata scelta tra quelle rimaste della matrice della full design matrix i F. Con la nuova matrice H si calcolano i nuovi pesi che sono m
(
H H I)
H y w = ⋅ m + ⋅ m − ⋅ Tm⋅ T m m 1 λ (15)ottenuti minimizzando l’equazione y P y w w e e ⋅ + ⋅ ⋅ = ⋅ ⋅ = m T m T m m T m i m E λ (16) dove
(
)
T m m m T m m p m I H H H I H P = − ⋅ ⋅ +λ⋅ −1⋅ (17) è la matrice nota come matrice di proiezione.La colonna scelta tra quelle di F è quella che dà il valore più piccolo di E o che in altre m
parole massimizza la seguente espressione:
(
)
i m T i i m T i m m f P f f P y E E ⋅ ⋅ + ⋅ ⋅ = − − − − 1 2 1 1 λ (18)che non è altro che la differenza tra l’errore al passo m-1 e l’errore al passo m.
Per velocizzare il processo di scelta del vettore, anziché ripetere tutti i conti da capo, si utilizzano espressioni incrementali che permettono di calcolare immediatamente la matrice di proiezione ad ogni passo utilizzando quella al passo precedente e il vettore f in prova i
i m T i m T i i m m m f P f P f f P P P ⋅ ⋅ ⋅ ⋅ ⋅ − = +1 (19)
e quindi massimizzare la (18) ad ogni passo più velocemente.
Un ulteriore riduzione del costo computazionale della RFS è ottenuto mediante l’ortogonalizzazione delle matrici e dei vettori utilizzati. Questa tecnica è conosciuta come dei minimi quadrati ortogonali (Ortogonal Least Square, OLS).
Per terminare il processo di creazione della rete vengono usati, ad ogni passo, cioè ogni volta che si aggiunge un neurone, dei metodi di stima della bontà della rete neurale chiamati criteri di selezione del modello [9], che restituiscono le stime dei futuri errori di predizione che la rete effettuerà. Questi coefficienti vengono controllati continuamente mano a mano che la rete cresce di dimensione e il processo continua fino a che si ha una diminuzione di queste stime
sull’errore di predizione; allorché le stime smettono di diminuire allora si arresta la procedura di creazione della rete. Si può ben capire come questi metodi di controllo possono essere anche usati per poter determinare l’architettura migliore di una rete nel caso ci ne sia più d’una tra cui scegliere. La struttura associata all’errore di predizione più piccolo sarà quindi quella scelta come definitiva (da qui la definizione di criteri di selezione del modello). Proprio per questo motivo le precedenti procedure sono risultate molto utili nel dover scegliere quale raggio utilizzare per le RBF; infatti per ogni r si creava la rete neurale associata e, in base ai risultati
ottenuti dalle stime dell’errore di predizione, si sceglieva la struttura che dava l’errore più piccolo.
La via utilizzata per effettuare questo tipo di stime dell’errore di predizione è quella di dividere l’insieme di allenamento generalmente in due parti: la prima viene utilizzata per costruire la rete e la seconda serve per verificare le prestazioni di previsione della stessa. Questo tipo di procedura è nota come cross-validation. Per utilizzare tutte le informazioni contenute
nell’insieme di allenamento, senza escludere quelle della partizione utilizzata per la verifica, si dividono i p punti contenuti in esso in due gruppi di dimensioni p-1 e 1 (p è la dimensione
dell’insieme di allenamento). Col primo si effettua l’allenamento e sul secondo la verifica delle prestazioni della rete. Questo procedimento si ripete per tutte le p suddivisioni possibili
dell’insieme di partenza calcolando infine l’errore quadratico medio delle p prove fatte e la
varianza. Tutto ciò è noto come leave-one-out cross-validation (LOO).
In caso di modelli lineari, l’errore di predizione secondo LOO può essere calcolato come segue:
( )
(
)
p diag T LOO y P P P y ⋅ ⋅ ⋅ ⋅ = − 2 2 σ (20)Un metodo simile al precedente ma di maggiore semplicità matematica è il GCV (generalized cross-validation):
( )
(
)
2 2 2 P y P y traccia p T GCV ⋅ ⋅ ⋅ = σ (21)I precedenti sono tutti metodi derivanti da aggiustamenti apportati all’espressione più generale della somma degli errori quadratici:
y P y
S = T ⋅ 2 ⋅
(22)
Dello stesso genere esistono molti altri criteri come l’UEV (unbiased estimate of variance), il
FPE (final prediction error) e il BIC (Bayesian information criterion) [10].
Come precedentemente è stato detto l’utilizzo del ridge regression per evitare problemi di eccessiva interpolazione dei dati di allenamento necessita di una relazione che permetta di calcolare un valore per il parametro λ. Anche in questo caso si utilizzano i criteri di selezione del modello esposti in precedenza. Come allora anche ora il valore scelto per λ è quello associato al più basso errore di predizione. In realtà non esiste una soluzione a questo problema poiché i criteri menzionati hanno una dipendenza non lineare da λ. Scegliendo quindi come strategia quella di utilizzare il valore del parametro di regolarizzazione che minimizza il GCV si ottiene la seguente formula iterativa:
(
)
( )
P w A w A A y P y traccia traccia T T ⋅ ⋅ ⋅ ⋅ − ⋅ ⋅ ⋅ = 2 −1 −1 λ −2 λ (23) dove(
)
1 1 − − = H ⋅H + ⋅I A T λ (24)è detta matrice varianza.
Per utilizzare la 23 deve essere scelto un λ iniziale per poter calcolare un valore per l’espressione a destra dell’uguale. Dopo di che è possibile ripetere il processo e calcolare un nuovo valore del parametro di regressione fino a ad ottenere la convergenza.
Un problema in cui si può incorrere in questo metodo è quello dei minimi locali che la curva di GCV in funzione di λ può presentare. Infatti potrebbe accadere che il processo di stima del parametro di regolarizzazione si fermi allorché λ raggiunga un minimo locale della funzione e non il minimo assoluto. Per evitare questo nelle applicazioni si continua a calcolare il valore di
GCV. Se non si notano ulteriori cali di GCV per i nuovi valori di λ allora la procedura viene terminata definitivamente.
Prima di procedere nella descrizione dei due metodi di previsione che utilizzano la rete neurale è opportuno fare una piccola aggiunta. Come precedentemente è stato detto, la procedura della forward selection prevede la scelta di ogni neurone che andrà a formare la rete da un insieme iniziale nel quale sono presenti tanti neuroni quanto è la dimensione degli ingressi dell’insieme
di allenamento (ponendo ovviamente ci = xi e utilizzando un valore di raggio comune a tutti i neuroni). Quindi, ad esempio, se gli elementi in ingresso sono 50, si avranno anche 50 neuroni e quindi una matrice iniziale (la full design matrix) di dimensioni 50×50.
Le functions Matlab utilizzate per la creazione e descrizione della rete permettono di aumentare ulteriormente l’insieme di partenza da cui scegliere le RBF fornendo più di un valore al raggio. Ovvero per ogni r , nel nostro esempio, verranno creati 50 neuroni e quindi la
full design matrix avrà dimensioni 50×
(
50⋅numeroraggi)
. Quindi adottando tre valori di r lamatrice sarà 50×150. Per il resto la procedura di scelta dei neuroni è esattamente la stessa esposta precedentemente. E’ chiaro che al termine della creazione della rete, se vengono adottati più di un valore del raggio, nella struttura finale potranno comparire RBF con raggi diversi e a priori non potrà essere noto quante per ogni singolo r.
Aumentare l’opportunità di scelta su un numero maggiore di neuroni comunque non comporta necessariamente la creazione di una rete con prestazioni migliori. Infatti la struttura della rete viene ottimizzata passo-passo aggiungendo il neurone che ad ogni iterazione dà il risultato migliore nel massimizzare l’equazione 18. Pertanto i processi di creazione di due reti, con la prima che fa riferimento ad un insieme di partenza più piccolo e contenuto nell’insieme di partenza della seconda, possono portare alla scelta degli stessi neuroni per i primi n passi e poi
differenziarsi dal passo n+1 nel quale alla seconda rete viene aggiunta una RBF che non fa parte del primo insieme. Intuitivamente si può dire che a questo punto la seconda rete sarà migliore della prima, ma ormai le vie intraprese per la creazione delle reti sono diverse e l’aggiunta di nuovi neuroni porta a strutture completamente diverse sulle cui prestazioni niente si può dire se non in fase di prova.
Da un lato pertanto non si ha la sicurezza di ottenere risultati migliori, dall’altro è però evidente come aumenti il costo computazionale dell’intero problema di ottimizzazione nel caso si debba partire da insiemi più grandi adottando più di un valore per il raggio.
3.3
Stima con rete neurale con identificazione di modelli di tendenza.
Il primo programma sviluppato esegue la previsione della potenza attiva media sul generico quarto d’ora utilizzando una serie di modelli che alla rete vengono forniti in fase di allenamento (pattern recognition). I modelli presentati sono gli andamenti della potenza media
attiva avuti nello stesso periodo di tempo ma nei giorni precedenti a quello in esame. I giorni scelti, da cui estrarre porzioni della funzione potenza media attiva da utilizzare come riferimenti dalla rete, sono quelli omonimi a quello in esame ma delle otto settimane precedenti.
Il problema legato a questo tipo di utilizzo della rete è proprio quello di dare alla stessa, in fase di allenamento, dei modelli che siano rappresentativi del fenomeno ed evitare esempi che invece possano influenzare negativamente le prestazioni della rete. Per questo motivo si è scelto di utilizzare solo i giorni omonimi, ritenendo che, per carichi ripetitivi come quelli in esame, gli andamenti della potenza assorbita in questi giorni siano più simili tra loro e dai quali quindi si possano estrarre più facilmente dei modelli di tendenza (ad esempio se la potenza da prevedere è su di un quarto d’ora di un lunedì, i giorni presi a riferimento sono gli otto lunedì precedenti).
La scelta di utilizzare otto giorni è dettata dalla necessità di avere una discreta gamma di esempi da assegnare come modelli. Utilizzarne di meno potrebbe comportare dei problemi nel caso in cui esistano dei giorni in cui l’andamento della potenza media si differenzia notevolmente da quello atteso perché compresi in periodi di festa, scioperi o a causa di altri eventi che possano alterare la normale attività lavorativa all’interno della struttura di ingegneria. Utilizzare invece un numero maggiore di giorni probabilmente non porterebbe sostanziali vantaggi a discapito invece di un maggiore costo di calcolo da parte del computer in fase di allenamento.
I tratti di curva che vengono estratti da ognuno questi otto giorni sono proprio quelli costituiti dal valore della potenza media assorbita nel quarto d’ora omonimo a quello che si vuole prevedere nel giorno in esame, più i valori della potenza media assorbita nei due quarti d’ora precedenti. Ad esempio se il quarto d’ora di cui si vuole prevedere la potenza assorbita è il decimo allora negli otto giorni presi come riferimento si estraggono i valori della potenza
assorbita nei quarti d’ora 8,9 e 10. Nella seguente figura sono stati messi in risalto questi tre valori per un giorno solo (la curva rappresentata è la potenza media sul quarto d’ora assorbita in un giorno fino alle ore 12:00):
quarto d’ora 10, omonimo di quello cui si deve prevedere la potenza media assorbita
KW
t
quarti d’ora 8 e 9
valori di potenza media assorbita estratti
Fig. 133 esempio campioni di potenza media sul quarto d’ora estratti per l’allenamento della rete
In questo modo abbiamo otto terne di valori (una per ogni giorno) da utilizzare in fase di allenamento della rete.
Gli ingressi dell’insieme d’allenamento sono formati da otto vettori, uno per ogni giorno, contenenti ognuno i valori della potenza assorbita nei due quarti d’ora precedenti quello in esame (indicati in verde nella fig. 133); ad ogni vettore è associato un riferimento (target) rappresentato dal valore della potenza assorbita nel quarto d’ora omonimo a quello di previsione (indicato in rosso in fig. 133).
i media i media i media P P P , 1 , 2 , → − − (25) dove i media
P , è la potenza media assorbita nell’i-esimo quarto d’ora (omonimo a quello su cui
fare la previsione).
1 ,i− media
P è la potenza media assorbita nell’(i-1)-esimo quarto d’ora.
2 ,i− media
P è la potenza media assorbita nell’(i-2)-esimo quarto d’ora.
Pertanto si è creata una associazione tra vettori e scalari del tipo causa-effetto per mezzo della quale si forniscono alla rete esempi di cosa può succedere nel futuro in base a quanto è successo nell’immediato passato. Infatti in fase di prova, che da ora sarà la fase di previsione, in ingresso alla rete viene dato un vettore contenente i valori della potenza media assorbita nei due quarti d’ora precedenti quello su cui si vuole effettuare la previsione; la rete cercherà tra gli esempi dati quello più simile alla situazione proposta e restituirà un valore di potenza media assorbita nel quarto d’ora che sta iniziando in base a quanto “imparato” (un esempio chiarificatore su quale sia il comportamento della rete neurale in fase di previsione, ovvero come scelga l’esempio più simile alla situazione di carico proposta ogni quarto d’ora è fornito nel paragrafo seguente 3.3.1).
Per quanto riguarda la scelta del raggio delle RBF da utilizzare è stata usata una procedura che, sfruttando le function matlab che traducono i criteri di selezione dei modelli esposti prima, per ogni r assegnato calcola l’errore di predizione che commetterebbe la rete.
Queste prove sono state fatte con 12 valori di r, da 500 a 6000 con passo di 500. La scelta di
questi valori è stato il risultato di una serie di prove che hanno evidenziato come al crescere del
raggio l’uscita della rete, partendo da zero per raggi molto piccoli dell’ordine di 10−1, cresceva sempre più fino ad ottenere un valore massimo nell’intervallo sopra indicato (per valori ancora più grandi di r l’uscita della rete tendeva a diminuire molto poco). Il valore massimo ottenuto era anche il valore più vicino al riferimento dato alla rete nell’allenamento. Il raggio poi utilizzato è proprio quello associato all’errore di predizione più piccolo.
Con ulteriori esperimenti si è notato una certa uguaglianza dei risultati a prescindere dall’utilizzo della gaussiana o della inversa multiquadratica. In questo lavoro si è comunque scelto di utilizzare la gaussiana.
Inoltre è stato scelto di utilizzare un valore di λ fisso e pari a 10−10, ovvero non è stato utilizzato nessun metodo di stima ad ogni iterazione del valore di λ.
Infine è stato scelto di utilizzare come criterio di stop nella procedura di costruzione della rete il LOO cross-validation.
Per come è stato concepito questo programma di previsione, non si ha la possibilità di effettuare delle stime della potenza media a quarto d’ora iniziato, come è invece possibile con i metodi statistici. Pertanto tutte le previsioni sono eseguite al minuto 0, ovvero all’inizio del quarto d’ora. Per futuri paragoni si dovranno mettere a confronto solo le previsioni effettuate al minuto zero dei metodi statistici con queste fatte con la rete neurale.
Per mantenere la stessa struttura del software che permette di effettuare le previsioni del carico e anche per ottenere maggiore leggibilità (in eventuali paragoni), nel presente metodo previsionale in tutti i grafici o diagrammi disegnati in funzione del minuto di previsione le curve saranno delle rette orizzontali in quanto l’unico valore a disposizione (quello al minuto di previsione 0) è stato riportato anche per i successivi minuti.
3.3.1
Risultati ottenuti nella previsione del carico di Ingegneria
Analogamente a quanto fatto nel capitolo 2 nel presente paragrafo e nei successivi è mostrato, con ausilio di grafici e diagrammi, ciò che si è ottenuto nell’applicare il metodo di previsione descritto nel paragrafo precedente al carico di Ingegneria, esempio di utenza di media tensione. I giorni e i mesi che si prenderanno ad esempio delle prestazioni del metodo sono gli stessi utilizzati nel capitolo 2.
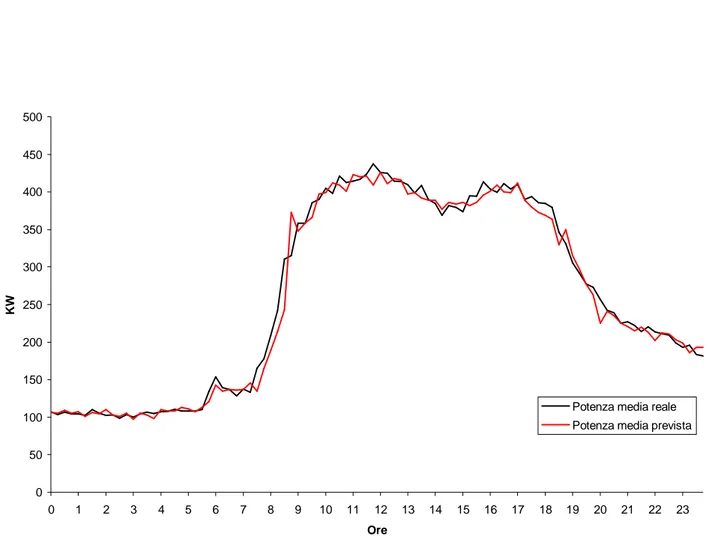
Pertanto si inizia fornendo la curva reale e prevista e l’errore commesso per il giorno 5 Giugno 2000. 0 50 100 150 200 250 300 350 400 450 500 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore K W
Potenza media reale Potenza media prevista
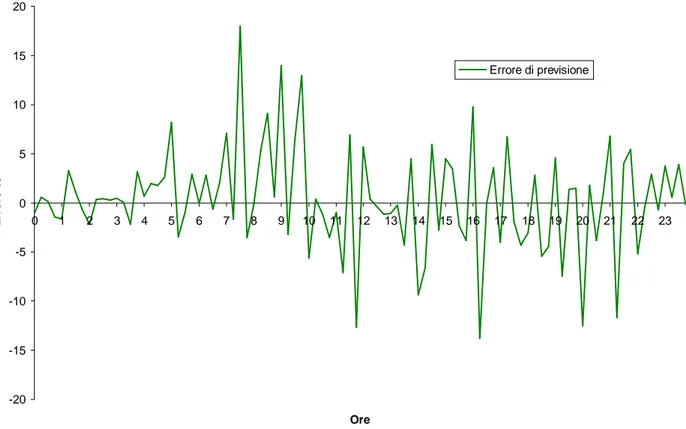
-25 -20 -15 -10 -5 0 5 10 15 20 25 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore E rr o re % Errore di previsione
Fig. 134a Andamento errore di previsione commesso dalla rete nel giorno 5 Giungo 2000
L’errore commesso nell’arco della giornata ha dei picchi sensibili nelle ore che vanno dalle 7 alle 9 di mattina. In questo periodo di tempo la curva della potenza media assorbita ha un tratto fortemente crescente e si nota che la curva prevista ha un certo ritardo che provoca, in questi tratti con forte pendenza, degli errori considerevoli.
Anziché mostrare altri esempi su giorni diversi è interessante sfruttare un evento singolare avvenuto nell’anno 2000 per mostrare il comportamento della rete in fase di previsione.
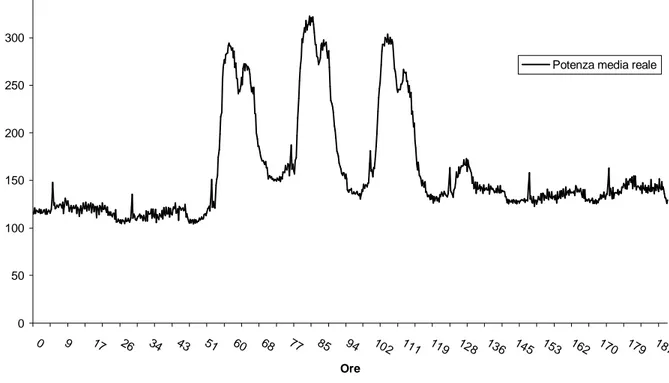
Nell’anno in questione il giorno 25 Aprile (festivo in Italia) è caduto di Martedì e il giorno 1 Maggio (anch’esso festivo in Italia) è caduto di Lunedì. Come si può notare dall’andamento del carico (fig. 135) Lunedì 24 Aprile c’è stato un “ponte festivo” e quindi non c’è stata alcuna attività lavorativa all’interno di Ingegneria. Nella fig. 136 oltre la potenza media reale è riportata anche quella prevista dalla rete:
0 50 100 150 200 250 300 350 0 9 17 26 34 43 51 60 68 77 85 94 102 111 119 128 136 145 153 162 170 179 187 Ore K W
Potenza media reale
Fig. 135 Andamento potenza media attiva da Lunedì 24 Aprile a Lunedì 1 Maggio
-750 -550 -350 -150 50 250 450 0 9 18 27 35 44 53 62 70 79 88 97 105 114 123 132 140 149 158 167 175 184 Ore K W
Potenza media reale Potenza media prevista
E’ evidente come la rete sbagli completamente le previsioni del 24 e 25 Aprile; d’altronde per il 24 la rete ha come modelli dei tratti di curva ricavati dagli otto lunedì precedenti, tutti lavorativi e quindi tutti con l’andamento classico della potenza assorbita nell’intera giornata. Stesso discorso vale per il 25 Aprile, che ha come modelli otto martedì lavorativi.
Quello che va però notato è la previsione per il giorno Lunedì 1 Maggio. Essendo un lunedì di festa ci si potrebbe aspettare una previsione completamente sballata come in precedenza. La previsione che viene fatta è invece sostanzialmente buona, decisamente migliore di quanto successo il 24 e 25 Aprile, come si può dedurre dalla seguente figura che mostra l’errore commesso durante la giornata:
-20 -15 -10 -5 0 5 10 15 20 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore E rr o re % Errore di previsione
Fig. 137 Andamento errore di previsione commesso dalla rete nel giorno 1 Maggio 2000
In questo caso la rete come modelli ha 7 lunedì lavorativi e un lunedì festivo, proprio il 24 Aprile. Evidentemente tra gli otto esempi, in fase di previsione, la rete ne trova uno molto simile all’andamento di potenza attiva del giorno sotto esame e in base a questo unico esempio restituisce la stima della potenza media attiva. Pertanto si può capire come sia importante avere
una grossa casistica, ovvero un elevato numero di modelli in modo da poter coprire il più possibile ogni tipo di situazione che si può avere.
3.3.2
Curve errori medi e massimi.
In questo paragrafo si riportano gli andamenti dell’errore medio e dell’errore massimo commessi dalla rete nel prevedere la media sui quarti d’ora. Come è stato detto precedentemente non esistono previsioni oltre il minuto 0 per questo metodo; l’unico valore disponibile dell’errore commesso (relativo appunto alla previsione al minuto 0) è riportato anche per i successivi minuti di previsione in modo da ottenere una curva confrontabile con quelle degli altri metodi. I grafici sono relativi all’errore commesso nel giorno 5 Giugno e nei mesi di Marzo, Aprile, Maggio, Giugno e di tutto il periodo da Marzo a Giugno.
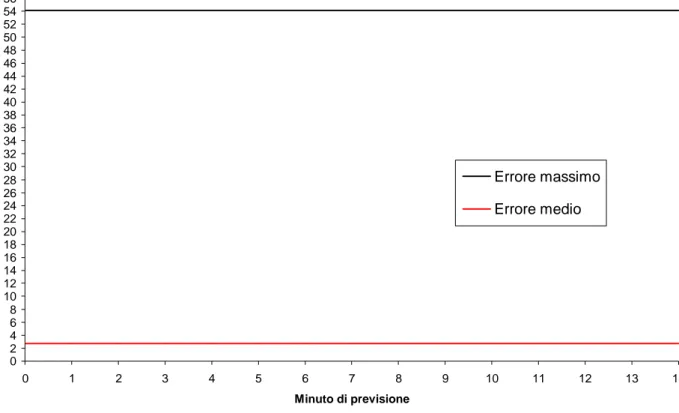
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
Fig. 139 Errori medio e massimo commessi dalla rete su tutto Marzo 2000
Per i problemi connessi ai periodi di festività di Aprile descritti precedentemente per questo mese si riporta solo il valor medio e non quello massimo (anche se il valore dell’errore medio comunque tiene conto dei grossi errori commessi il 24 e il 25 Aprile)
0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore medio
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
Fig. 141 Errori medio e massimo commessi dalla rete su tutto Maggio 2000
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
Per la stessa ragione espressa prima di seguito è presente solo l’errore medio commesso nell’arco di tempo Marzo-Giugno 2000
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Minuto di previsione E rr o re % Errore medio
Fig. 140 Errori medio commesso dalla rete su tutto Marzo-Giugno 2000
Il metodo proposto, considerando che sono previsioni al minuto 0, da dei buoni risultati. Infatti si riescono a ottenere previsione con un errore mediamente ben al di sotto del 3% nei mesi di Maggio e Marzo. Anche negli altri mesi si hanno buoni risultati se si tiene anche conto di quali problemi abbia la rete nell’effettuare delle previsioni in situazioni particolari come quella descritta nel paragrafo precedente, dove si raggiungono errori anche del 700%.
3.3.3
Diagrammi di distribuzione dell’errore.
In questo paragrafo sono presenti i diagrammi di distribuzione dell’errore di previsione commesso dalla rete neurale per i mesi di Marzo, Maggio e Giugno (Aprile è stato scartato per gli stessi motivi per cui si è scelto di non disegnare la curva dell’errore massimo a pag. 125; infatti essendo l’errore massimo commesso molto elevato la curva di distribuzione in questo caso sarebbe stata un solo classe con altezza quasi 100%). Per chiarimenti riguardo la scelta delle classi e la creazione dei diagrammi vedere capitolo 2 paragrafo 2.1.3.
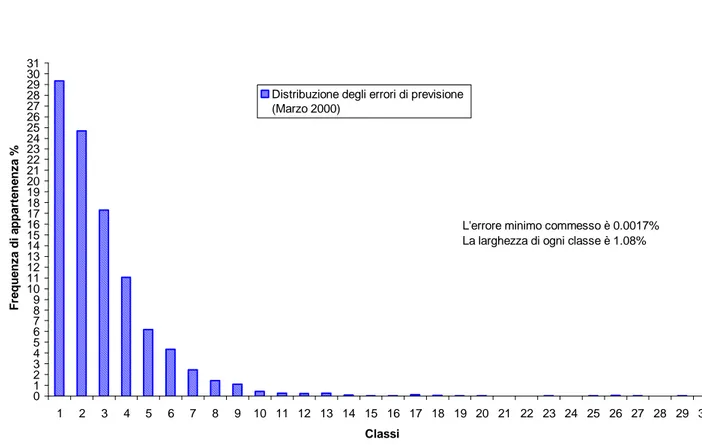
L'errore minimo commesso è 0.0017% La larghezza di ogni classe è 1.08%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Classi F re q u e n z a d i a p p a rt e n e n z a %
Distribuzione degli errori di previsione (Marzo 2000)
L'errore minimo commesso è 0% La larghezza di ogni classe è 0.6%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Classi F re q u e n z a d i a p p a rt e n e n z a %
Distribuzione degli errori di previsione (Maggio 2000)
Fig. 145 Curva di distribuzione degli errori commessi dalla rete nelle previsioni di Maggio 2000
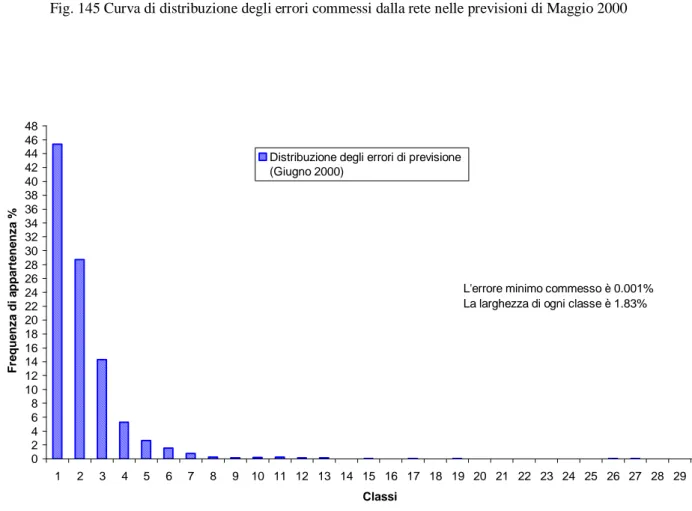
L'errore minimo commesso è 0.001% La larghezza di ogni classe è 1.83%
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Classi F re q u e n z a d i a p p a rt e n e n z a %
Distribuzione degli errori di previsione (Giugno 2000)
Dalle figure precedenti si nota che per Marzo circa la metà degli errori commessi è compresa nelle prime 2 classi, per Maggio nelle prime 3 classi e per Giugno nella prima classe. Dalla larghezza delle classi in ogni mese si ricava che mediamente la rete neurale commette degli errori di cui circa il 50% è minore del 2%.
3.3.4
Sforamenti previsti e falsi allarmi
Infine anche per il metodo di previsione che utilizza la rete neurale come revisore della potenza media attiva assorbita dal carico si presentano i diagrammi degli sforamenti previsti giustamente e dei falsi allarmi per i mesi di Marzo, Giugno, Luglio e di tutto il periodo da Marzo a Luglio (la tabella degli sforamenti è a nel capitolo 2 par. 2.1.4).
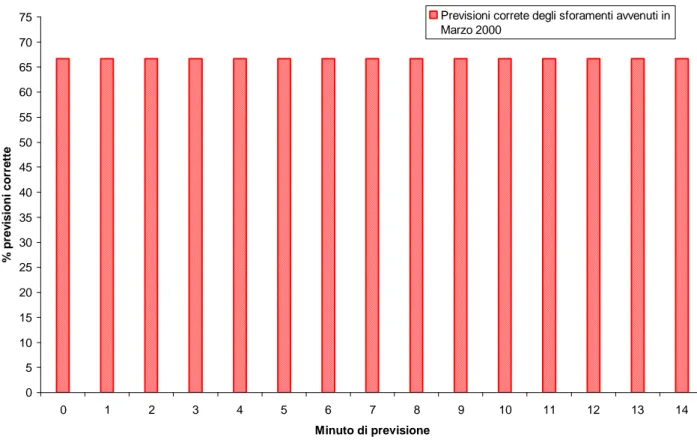
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % p re v is io n i c o rr e tt e
Previsioni correte degli sforamenti avvenuti in Marzo 2000
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 0.11 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % f a ls i a ll a rm e
Falsi allarmi avvenuti in Marzo 2000
Fig. 148 Percentuale di falsi allarme prodotti dalla rete rispetto al numero di quarti d’ora in cui non è avvenuto sforamento in Marzo 2000 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % p re v is io n i c o rr e tt e
Previsioni correte degli sforamenti avvenuti in Giugno 2000
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 0.11 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % f a ls i a ll a rm e
Falsi allarmi avvenuti in Giugno 2000
Fig. 150 Percentuale di falsi allarme prodotti dalla rete rispetto al numero di quarti d’ora in cui non è avvenuto sforamento in Giugno 2000 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % p re v is io n i c o rr e tt e
Previsioni correte degli sforamenti avvenuti in Luglio 2000
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 0.22 0.24 0.26 0.28 0.3 0.32 0.34 0.36 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % f a ls i a ll a rm e
Falsi allarmi avvenuti in Luglio 2000
Fig. 152 Percentuale di falsi allarme prodotti dalla rete rispetto al numero di quarti d’ora in cui non è avvenuto sforamento in Luglio 2000 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % p re v is io n i c o rr e tt e
Previsioni correte degli sforamenti avvenuti da Marzo a Luglio 2000
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 0.11 0.12 0.13 0.14 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % f a ls i a ll a rm e
Falsi allarmi avvenuti da Marzo a Luglio 2000
Fig. 154 Percentuale di falsi allarme prodotti dalla rete rispetto al numero di quarti d’ora in cui non è avvenuto sforamento da Marzo a Luglio 2000
Dai diagrammi precedenti (specialmente dalle figure 153 e 154) è evidente come la rete neurale preveda correttamente uno sforamento nel 66% circa dei casi ed invece come sbagli provocando un falso allarme nello 0.13% dei casi.
3.3.5
Risultati ottenuti nella previsione del carico dell’Hotel.
Con la stessa architettura descritta precedentemente, la rete neurale è stata applicata al carico costituito dall’Hotel S. Francesco, esempio di utenza di bassa tensione. Il primo esempio, come fatto in precedenza coi metodi statistici, è l’andamento della potenza prevista e di quella realmente assorbita nel giorno 5 Luglio 2001
0 5000 10000 15000 20000 25000 30000 35000 40000 45000 50000 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore W
Potenza media reale Potenza media prevista
Fig. 155 Andamento potenza media assorbita reale e prevista il 5 Luglio 2001
E’ subito molto evidente come la rete neurale sfruttata con la logica del pattern recognition, così come è stata strutturata in questo lavoro, non è assolutamente applicabile nel prevedere l’andamento della potenza media attiva dell’Hotel.
0 5000 10000 15000 20000 25000 30000 35000 40000 45000 50000 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore W
Potenza media reale Potenza media prevista
Fig. 156 Andamento potenza media assorbita reale e prevista il 3 Giugno 2001
0 5000 10000 15000 20000 25000 30000 35000 40000 45000 50000 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore W
Potenza media reale Potenza media prevista
Il motivo del netto fallimento di questo sistema di previsione è probabilmente da ricercare proprio nell’andamento della potenza assorbita dall’Hotel. Il fatto che ci siano forti variazioni nell’arco di pochi quarti d’ora, fa saltare la ricerca, nei giorni precedenti quello in esame, dei modelli di tendenza a cui fare riferimento in fase di previsione.
Effettivamente la logica di cercare nei giorni omonimi tratti di curva che possano rappresentare degli esempi per la rete salta, non esistendo per questo tipo di carico delle ripetitività così evidenti come quelle trovate nell’andamento del carico di ingegneria.
E’ evidente quindi che serve una analisi più minuziosa del carico, eventualmente cercando nell’andamento della potenza istantanea quelle ripetitività necessarie per questo metodo. E’ inoltre opportuno rivedere l’approccio utilizzato nel creare la rete per modificarlo onde ottenere risultati migliori.
3.4
Stima con rete neurale con estrapolazione della funzione.
Col presente metodo di previsione si è utilizzato invece un approccio completamente diverso da quello precedentemente esposto. In questo caso, utilizzando gli ultimi campioni di potenza media attiva assorbita dall’utenza, in fase di allenamento la rete cerca la funzione che meglio descrive l’andamento dei campioni dati in ingresso. La struttura della rete neurale che ne scaturisce ha la capacità di descrivere proprio la funzione interpolante dei campioni presentati in fase di allenamento.
In letteratura si trovano molti esempi di utilizzo della rete neurale come funzione interpolante di dati, generalmente sporcati da rumore, ed è quindi frequente un utilizzo di questo tipo di rete come filtro di segnali, o in generale come strumento che permette di estrarre un’informazione da un insieme di dati “sporchi”. In questa sua applicazione la rete neurale dà ottimi risultati [11]. Ad esempio la figura 155 mostra come la rete estragga la funzione sin( x da un insieme )
di dati, tratti dalla funzione seno, ma sporcati con rumore di tipo gaussiana con σ =0.2:
-1.5 -1 -0.5 0 0.5 1 1.5 0 .0 0 0 .0 3 0 .0 6 0 .0 9 0 .1 2 0 .1 5 0 .1 8 0 .2 1 0 .2 4 0 .2 7 0 .3 0 0 .3 3 0 .3 6 0 .3 9 0 .4 2 0 .4 5 0 .4 8 0 .5 2 0 .5 5 0 .5 8 0 .6 1 0 .6 4 0 .6 7 0 .7 0 0 .7 3 0 .7 6 0 .7 9 0 .8 2 0 .8 5 0 .8 8 0 .9 1 0 .9 4 0 .9 7 1 .0 0 sin(x)
Interpolante ottenuta dalla rete Dati di allenamento
Fig. 158 Esempio di come la rete riesca ad estrarre da dati affetti da rumore (punti blu) il segnale originale, cioè la funzione sin(x).
La figura precedente mostra proprio che un buon settaggio dei parametri della rete quali i raggi, il coefficiente di regolarizzazione λ ecc.., porta a notevoli risultati.
Nell’utilizzo fatto della rete in questo lavoro si è voluto sfruttare la stessa non tanto come interpolatore, ma come estrapolatore, ovvero utilizzarla per prevedere quali possano essere i futuri valori di una determinata serie storica di dati.
Pertanto la rete è stata allenata con gli ultimi campioni di potenza media attiva disponibili, in modo tale che essa rappresentasse, finito l’allenamento, la funzione interpolante dei dati. In seguito è stata utilizzata per prevedere i campioni immediatamente successivi. La figura seguente mostra questo tipo di approccio:
Cam pioni utilizzati per l’allenam ento della rete
Serie storica di dati
Campioni futuri da prevedere
Serie futura di dati
Nelle varie prove effettuate con questo tipo di utilizzo della rete si è notato che, qualunque fossero i dati utilizzati nell’allenamento (campioni di potenza attiva istantanea, valori della potenza media attiva, valori di media mobile della potenza attiva, ecc..), pur ottenendo una rete neurale che interpolava ottimamente i dati della serie storica, in fase di previsione aveva grosse difficoltà nel seguire l’andamento dei campioni futuri anche dal primo di essi, successivo a quelli noti. Ovvero la funzione che doveva descrivere l’andamento futuro dei dati forniti durante l’allenamento, molto spesso degenerava schizzando a valori elevatissimi o comunque ben distanti da quelli reali sin dal primo valore.
Per ovviare a tutto questo si sono svolte molte prove complicando anche ulteriormente la struttura della rete fornendo più di un raggio di valori diversi (quindi permettendo alla rete di scegliere tra un numero maggiori di neuroni in fase di allenamento), variando più volte il valore iniziale del parametro di regolarizzazione nella procedura ricorsiva di stima dello stesso o lasciando in tante altre prove il valore di λ fisso, adottando i criteri di selezione del modello tra un numero elevato di strutture della rete. A discapito di un aumento molto sensibile dei tempi di calcolo da parte del computer, in alcuni casi si è riuscito ad ottenere ottime previsioni per un discreto numero di valori futuri. Però l’architettura della rete che ottimizzava la previsione per una determinata serie storica di dati, falliva completamente allorché si applicava a diverse serie storiche, ovvero effettuando la procedura di allenamento e previsione con dati diversi da quelli con cui si era ottimizzato il modello. Ad esempio le due figure seguenti mostrano nel primo caso come una determinata struttura della rete porti a notevoli risultati nelle previsioni, e nel secondo come la stessa rete invece non sia assolutamente adatta nel caso venga cambiato l’insieme di allenamento (la serie storica). I dati utilizzati nei due esempi sono i valori della potenza attiva media del 5 Giugno 2000; nel primo caso la serie storica è costituita dai 20 valori della potenza media assorbita nei quarti d’ora che vanno dal 31 al 50; nel secondo caso invece il numero di valori storici è sempre 20 ma dei quarti d’ora che vanno da 43 a 62. Infine si sono previsti 10 campioni della potenza media attiva, che coprono quindi le 2 ore e mezzo successive la serie storica.
150 175 200 225 250 275 300 325 350 375 400 425 450 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 Quarto d'ora K
W Funzione interpolante campioni di
allenamento
Funzione campioni futuri previsiti (ottenuti per estrapolazione)
Campioni di allenamento Campioni futuri veri
Fig. 160 Rappresentazione dei dati di allenamento (punti blu), della loro funzione interpolante (curva nera), dei campioni futuri veri (triangoli verdi) e della funzione ottenuta in fase di previsione dalla rete (curva rossa) per i quarto
d’ora che vanno dal 31 al 60
350 375 400 425 450 475 500 525 550 575 600 625 650 675 700 725 750 775 800 825 850 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 Quarto d'ora K W
Funzione interpolante campioni di allenamento
Funzione campioni futuri previsti (ottenuti per estrapolazione)
Campioni di allenamento Campioni futuri veri
Fig. 161 Rappresentazione dei dati di allenamento (punti blu), della loro funzione interpolante (curva nera), dei campioni futuri veri (triangoli verdi) e della funzione ottenuta in fase di previsione dalla rete (curva rossa) per i quarto
L’ottimizzazione per la prima previsione, per la quale è stata usata in allenamento la serie storica delle potenze medie assorbite dei quarti d’ora che vanno dal 31 fino al 60, è stata fatta utilizzando tre valori di raggi, 12,17 e 22, con procedura ricorsiva di calcolo del parametro di regolarizzazione.
Come si può notare dalla figura 160 la previsione è molto buona. Se utilizziamo però gli stessi parametri, cioè stessi raggi e fattore di regolarizzazione, per prevedere la potenza assorbita nei quarto d’ora che vanno dal 63 al 72, allenando la rete con la serie storica delle potenze medie assorbite nei quarto d’ora che vanno dal 43 al 62, il risultato che si ottiene non è affatto soddisfacente, vedi figura 162. Infatti in questo caso, eccetto il primo valore previsto, dal secondo al decimo la previsione non è certamente buona come in precedenza.
E’ comunque fattibile anche una ottimizzazione dei parametri anche per il secondo caso. Utilizzando una terna di raggi pari a 6.8,7.8 e 8.8, sempre con procedura ricorsiva nel calcolo di λ ad ogni passo, infatti si ottiene il seguente risultato.
360 370 380 390 400 410 420 430 440 450 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 Quarto d'ora K W
Funzione interpolante campioni di allenamento
Funzione campioni futuri previsti (ottenuti per estrapolazione) Campioni di allenamento
Campioni futuri veri
Questi esempi mostrano come il metodo di estrapolazione abbia grosse potenzialità. Infatti, se opportunamente fissati i parametri che descrivono la rete, si è in grado di prevedere anche valori della potenza media assorbita nelle future due o tre ore. Ma il procedimento è risultato anche di difficile stabilizzazione. Infatti è stato difficile trovare una procedura che permetta di trovare, ogni volta che cambia la serie storica di allenamento, i parametri ottimali per la previsione di un discreto numero di valori futuri di potenza media assorbita come negli esempi precedenti.
In questo lavoro pertanto è stata scartata l’eventualità di effettuare previsioni per più di un valore oltre la serie storica. Utilizzando i valori della potenza media assorbita sui quarti d’ora si è deciso pertanto di prevedere un solo valore, che risulta essere esattamente la potenza media assorbita sul quarto d’ora che sta iniziando.
Dalle numerose prove fatte è stato constatato che la struttura della rete che comprendeva una terna di raggi pari a 6,11 e 16, un utilizzo della inversa multiquadratica come RBF e l’adozione
di un valore fisso del parametro di regolarizzazione pari a 1⋅10−3, portava ai migliori risultati. Inoltre l’insieme di allenamento è stato fissato negli ultimi 20 valori della potenza media assorbita, dai quali ottenere la funzione interpolante che serve nel seguito a prevedere l’unico valore coincidente con la potenza media assorbita nel quarto d’ora che sta iniziando.
Per questa sua caratteristica anche questo metodo di previsione che utilizza la rete neurale, come il precedente, non ha la caratteristica di poter effettuare stime a quarto d’ora iniziato. Con questa architettura si sono ottenuti i risultati presentati nei seguenti paragrafi.
3.4.1
Risultati ottenuti nella previsione del carico di Ingegneria.
Come precedentemente è stato fatto anche in questo caso si inizia fornendo la curva reale e prevista e l’errore commesso per il giorno 5 Giugno 2000.
0 50 100 150 200 250 300 350 400 450 500 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore K W
Potenza media reale Potenza media prevista
-25 -22.5 -20 -17.5 -15 -12.5 -10 -7.5 -5 -2.5 0 2.5 5 7.5 10 12.5 15 17.5 20 22.5 25 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore E rr o re % Errore di previsione
Fig. 163a Andamento errore di previsione commesso dalla rete nel giorno 5 Giungo 2000
Dalle precedenti figure si può notare un buon comportamento da parte della rete in fase di previsione. Gli unici grossi problemi si riscontrano nel prevedere il picco delle 6 di mattina. Infatti si possono notare sia un errore nel prevedere il valore del picco, sia che la previsione è fatta in ritardo, due fattori che portano ad avere un errore massimo di circa il 25%.
Un comportamento del genere è spiegabile facendo notare che viene allenata in quel periodo sostanzialmente con una serie storica di dati che formano una curva circa costante. Quindi in fase di previsione si ottengono dei valori in linea con quelli precedenti, anche se effettivamente la curva reale ha un brusco aumento nel gito di un paio di quarti d’ora (un paio di campioni quindi).
Col passare del tempo, come nell’insieme di allenamento entrano a far parte i valori più grandi che caratterizzano il picco delle 6, ecco che la rete restituisce dei valori ancora più grandi prevedendo che in futuro la curva tenda comunque a crescere.
3.4.2
Curve errori medi e massimi.
Come nel paragrafo 3.3.2 di seguito si riportano gli andamenti dell’errore medio e massimo per il giorno 5 Giugno 2000 e dei mesi da Marzo a Giugno, incluso il grafico che tiene conto di tutto il periodo indicato. Anche questa volta, avendo a disposizione solo la previsione al minuto 0, l’unico valore viene riportato anche per i minuti di previsione successivi.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
Fig. 165 Errori medio e massimo commessi dalla rete su tutto Marzo 2000
0 1.5 3 4.5 6 7.5 9 10.5 12 13.5 15 16.5 18 19.5 21 22.5 24 25.5 27 28.5 30 31.5 33 34.5 36 37.5 39 40.5 42 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
Fig. 167 Errori medio e massimo commessi dalla rete su tutto Maggio 2000
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
0 1.5 3 4.5 6 7.5 9 10.5 12 13.5 15 16.5 18 19.5 21 22.5 24 25.5 27 28.5 30 31.5 33 34.5 36 37.539 40.5 42 43.5 45 46.5 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio
Fig. 169 Errori medio e massimo commessi dalla rete su tutto il periodo Marzo-Giugno 2000
Dalla figure precedenti si può rilevare un buon comportamento della rete in fase di previsione commettendo mediamente un errore poco più grande del 3%. Il livello abbastanza grande dell’errore massimo commesso è legato al problema descritto precedentemente del picco di potenza assorbita intorno alle 6 di mattina.
3.4.3
Diagrammi di distribuzione dell’errore.
In questo paragrafo vengono presentati i diagrammi di distribuzione dell’errore per i mesi di Marzo, Aprile, Maggio e Giungo. (Per chiarimenti sul metodo di creazione dei diagrammi fare riferimento al paragrafo 2.1.3 del capitolo 2)
L'errore minimo commesso è 0% La larghezza di ogni classe è 0.71%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Classi F re q u e n z a d i a p p a rt e n e n z a %
Distribuzione degli errori di previsione (Marzo 2000)
Fig. 170 Curva di distribuzione degli errori commessi dalla rete nelle previsioni di Marzo 2000
L'errore minimo commesso è 0% La larghezza di ogni classe è 0.78%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Classi F re q u e n z a d i a p p a rt e n e n z a %
Distribuzione degli errori di previsione (Aprile 2000)
L'errore minimo commesso è 0% La larghezza di ogni classe è 0.70%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Classi F re q u e n z a d i a p p a rt e n e n z a %
Distribuzione degli errori di previsione (Maggio 2000)
Fig. 172 Curva di distribuzione degli errori commessi dalla rete nelle previsioni di Maggio 2000
L'errore minimo commesso è 0% La larghezza di ogni classe è 0.88%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Classi F re q u e n z a d i a p p a rt e n e n z a %
Distribuzione degli errori di previsione (Giugno 2000)
Analizzando le curve di distribuzione si rileva che circa il 50% degli errori è compreso nelle prime 3-4 classi. Questo porta a concludere che circa le metà degli errori commessi dal metodo di previsione che utilizza la rete neurale come estrapolatore di funzione è minore del 2.7-2.9%.
3.4.4
Sforamenti previsti e falsi allarmi
Infine vengono presentati i diagrammi che indicano quante previsioni giuste degli sforamenti e quanti invece falsi allarmi il presente metodo di previsione ha prodotto nei mesi di Marzo, Giugno, Luglio e in tutto il periodo da Marzo a Luglio.
0 5 10 15 20 25 30 35 40 45 50 55 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % p re v is io n i c o rr e tt e
Previsioni correte degli sforamenti avvenuti in Marzo 2000
0 0.01 0.02 0.03 0.04 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % f a ls i a ll a rm e
Falsi allarmi avvenuti in Marzo 2000
Fig. 175 Percentuale di falsi allarme prodotti dalla rete rispetto al numero di quarti d’ora in cui non è avvenuto sforamento in Marzo 2000 0 5 10 15 20 25 30 35 40 45 50 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % p re v is io n i c o rr e tt e
Previsioni correte degli sforamenti avvenuti in Giugno 2000
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 0.11 0.12 0.13 0.14 0.15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % f a ls i a ll a rm e
Falsi allarmi avvenuti in Giugno 2000
Fig. 177 Percentuale di falsi allarme prodotti dalla rete rispetto al numero di quarti d’ora in cui non è avvenuto sforamento in Giugno 2000 0 5 10 15 20 25 30 35 40 45 50 55 60 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % p re v is io n i c o rr e tt e
Previsioni correte degli sforamenti avvenuti in Luglio 2000
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 0.22 0.24 0.26 0.28 0.3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % f a ls i a ll a rm e
Falsi allarmi avvenuti in Luglio 2000
Fig. 179 Percentuale di falsi allarme prodotti dalla rete rispetto al numero di quarti d’ora in cui non è avvenuto sforamento in Luglio 2000 0 5 10 15 20 25 30 35 40 45 50 55 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % p re v is io n i c o rr e tt e
Previsioni correte degli sforamenti avvenuti da Marzo a Luglio 2000
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 0.11 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione % f a ls i a ll a rm e
Falsi allarmi avvenuti da Marzo a Luglio 2000
Fig. 181 Percentuale di falsi allarme prodotti dalla rete rispetto al numero di quarti d’ora in cui non è avvenuto sforamento nel periodo Marzo-Luglio 2000
Il metodo di previsione in esame non sembra avere alte qualità nel prevedere gli sforamenti che sono avvenuti. In effetti stima correttamente un futuro sforamento in circa la metà dei casi. A questa si aggiunge però una buona capacità di non produrre falsi allarmi, avvenendo questi solo nell’uno per mille dei casi.
3.4.5
Risultati ottenuti nella previsione del carico dell’Hotel.
Adesso applichiamo lo stesso metodo di estrapolazione utilizzando la rete neurale nel caso del carico dell’Hotel.
Come precedentemente fatto per i metodi di previsione statistici di seguito verranno presentati degli esempi di curva di potenza attiva prevista nei giorni 5 Luglio e 19 Settembre 2001.
0 10000 20000 30000 40000 50000 60000 70000 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore W
Potenza media reale Potenza media prevista
-100 -75 -50 -25 0 25 50 75 100 125 150 175 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore E rr o re % Errore di previsione
Fig. 183 Errore commesso nella previsione del 5 Luglio 2001.
0 10000 20000 30000 40000 50000 60000 70000 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore W
Potenza media reale Potenza media prevista
-100 -75 -50 -25 0 25 50 75 100 125 150 175 200 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Ore E rr o re % Errore di previsione
Fig. 185 Errore commesso nella previsione del 19 Settembre 2001.
E’ evidente come la rete neurale in questa applicazione abbia notevoli difficoltà nel prevedere la potenza media futura. L’andamento fortemente variabile della curva della potenza media infatti non permette al metodo, così come è stato creato, di poter efficacemente estrapolare l’andamento futuro della funzione. Infatti dove la curva ha un andamento un po’ più dolce, come nella prima metà del giorno 19 Settembre, la previsione è decisamente migliore.
Si può notare come invece la rete tenda a restituire una curva della potenza media prevista che interpola l’andamento reale. Questo fatto è evidente se si guarda la figura 182, nelle ore della seconda metà del giorno.
Comunque questi risultati sono in linea con quanto ottenuto dai metodi statistici. Per questo motivo presenteremo anche i diagrammi dell’errore medio, la distribuzione dell’errore e le prestazioni del metodo nel prevedere gli sforamenti futuri dei limiti di potenza. Infine faremo quindi i paragoni di questo metodo e dei due statistici nel presente caso dell’Hotel.
3.4.6
Curve errori medi e massimi.
In questo paragrafo sono presenti le curve degli errori medi e massimi dei mesi che vanno da Maggio a Settembre. 0 25 50 75 100 125 150 175 200 225 250 275 300 325 350 375 400 425 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Minuto di previsione E rr o re % Errore massimo Errore medio