Capitolo 6
Sperimentazione e casi d’uso
Introduzione
Il software sviluppato nel corso del lavoro di tesi sostanzialmente riguarda l’interazione tra utente e sistema, di conseguenza il tipo di sperimentazione che si può fare una volta terminata l’implementazione, riguarda l’usabilità, il potere espressivo, e potenzialità offerte dal tool grafico a chi utilizza il sistema.
Diciamo subito che gran parte di questo capitolo è dedicato ad alcuni casi d’uso che riteniamo significativi per mostrare le funzionalità offerte dal sistema. Dedicheremo inoltre, una parte del capitolo per capire se gli obiettivi focalizzati attraverso una serie di requisiti, siano stati raggiunti in modo da delineare punti di forza, pecche e possibili sviluppi per migliorare il tool esistente.
6.1 Usabilità
L'usabilità in relazione al nostro contesto, si può definire come l'efficacia, l'efficienza e la soddisfazione con le quali gli utenti di un tool per Knowledge Discovery raggiungono gli obiettivi prefissati prima di intraprendere il processo di analisi dei dati. In pratica definisce il grado di facilità e soddisfazione con cui si compie l'interazione uomo-sistema.
Il problema dell'usabilità si pone quando il modello del progettista (ovvero le idee di questi riguardo al funzionamento del prodotto,che si ripercuotono sul prodotto finale) non coincide con il modello dell'utente finale (ovvero l'idea che l'utente concepisce del prodotto e del suo funzionamento).Il grado di usabilità si innalza proporzionalmente all'avvicinamento dei due modelli (modello del progettista, e modello dell'utente).
Quando abbiamo intrapreso lo studio per la realizzazione di uno strumento di interazione grafica per un sistema complesso (“per i non addetti ai lavori”) come è KDDML, abbiamo considerato anche la possibilità che il tool sia usato da persone non proprio esperte di programmazione, facendo in modo quindi da limitare del tutto il contatto diretto con il linguaggio KDDML. Nonostante tutto però, l’utente esigente deve possedere una certa conoscenza del sistema per poterne sfruttare completamente le potenzialità.
Abbiamo delineato quindi lacune linee guida per sviluppare il nostro sistema in maniera tale da essere più “user-friendly” possibile :
- adeguatezza: devono essere richiesti solo gli input necessari per svolgere un determinato compito.
- facilità di apprendimento: l'utilizzo deve essere chiaro ed intuitivo, rendendo minima la lettura di manuali o istruzioni d'uso (che a loro volta devono essere chiari e comprensibili).
- robustezza: l'impatto dell'errore deve essere inversamente proporzionale alla probabilità d'errore.
Infatti se consideriamo l’usabilità sotto questo punto di vista non dobbiamo però lasciare da parte la visione del sistema dalla prospettiva dell’utilizzatore: 1) che cosa vuole o deve ottenere l'utente.
2) qual è il background culturale e tecnico dell'utente. 3) qual è il contesto in cui opera l'utente.
4) che cosa deve essere demandato al sistema e che cosa invece va lasciato all'utente.
E’ chiaro che chi utilizza il sistema grafico per costruire delle query KDD si aspetta in qualche modo di essere guidato nella stesura del processo comunque di avere un aiuto significativo rispetto alla scrittura testuale di uno schema.
Il punto (2) fornisce uno spunto per fare una piccola osservazione. Non è necessario che l’utente sia un esperto del linguaggio per interrogare il sistema KDDML, ma ciò che gli permette di interagire con lo schema di KD è semplicemente la propria conoscenza nell’ambito del Knowledge Dyscoery ed in particolare sulle fasi attraverso le quali si evolve. Anche in questo caso possiamo dire di aver ampliato “l’utenza del sistema” nel senso che un maggior numero di persone con un background non proprio tecnico, possono accedere alle funzionalità, alche quelle più nascoste, del sistema KDDML.
In tal senso, lo scopo principale dell’introduzione di una metafora grafica e di un formalismo per la costruzione di query KDD, si può riassumere nei punti seguenti:
- aumentare l’efficienza degli utenti;
- ridurre gli errori e quindi aumentare la “sicurezza” nell’interazione con il sistema;
- ridurre il “periodo di adattamento” al linguaggio KDDML; - migliorare la visualizzazione dello schema.
Anche se non è possibile dare una misurazione generale di usabilità del sistema, sarebbe corretto in qualche modo fornire una valutazione di tutti i punti precedenti determinando così la qualità dell’interazione.
L’efficacia però, può essere valutata considerando gli obiettivi o i sotto-obiettivi che è possibile raggiungere utilizzando il sistema e il grado di accuratezza con il quale è possibile raggiungerli.
Nel caso dei linguaggi visuali di querying, l’obiettivo principale è sicuramente quello di estrarre informazioni,partendo da una sorgente di dati, effettuando una query visiva e mappando lo schema sul processo di KD. Nel nostro caso quindi, parlare di accuratezza, corrisponde a predisporre un ambiente per far sì che l’utente possa comporre delle query corrette dal punto di vista sintattico.
Da questo punto di vista possiamo dire che il sistema grafico risponde pienamente alla concezione di accuratezza espressa in precedenza in quanto, tende a guidare l’utente attraverso tutto il processo di creazione dello schema, compresa l’immissione dei parametri.
I compiti principali del nostro sistema grafico, sono sicuramente la composizione di query e la lettura di query, infatti proprio sul miglioramento della rappresentazione grafica si basa il nostro lavoro.
Da questo punto di vista possiamo dire sicuramente che è stato fatto un passo avanti. Se pensiamo infatti che prima di iniziare il nostro studio, l’unico modo per effettuare delle query utilizzando KDDML era quello di fornire un file XML-like al sistema, capiamo bene che abbiamo ottenuto in tal senso un buon miglioramento. Tuttavia esistono ancora svariati problemi aperti a cui accenneremo nell’ultima parte di questo capitolo.
6.2 Un caso d’uso
Ci sembra doveroso, dopo aver fornito una descrizione più accurata riguardo alle modalità di utilizzo del tool per la costruzione di query KDDML, fornire un esempio di utilizzo spiegando in dettaglio i passi necessari per la costruzione della query. Naturalmente metteremo in evidenza ognuna delle particolarità descritte nel capitolo precedente facendo in modo di evidenziare in che modo le scelte che stanno “al di sotto” dell’interfaccia si ripercuotano anche a questo livello.
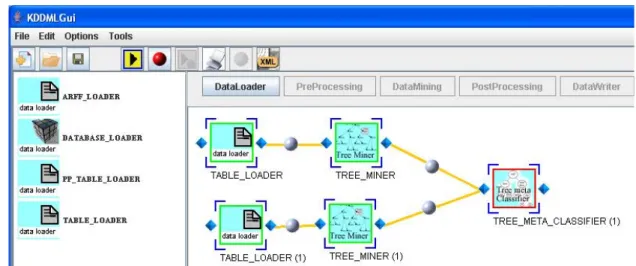
Per effettuare un processo di costruzione di una query significativa abbiamo scelto una query KDDML abbastanza complessa da un punto di vista grafico in modo da evidenziare un numero maggiore di funzionalità. La query in forma testuale è mostrata in figura 35 ed è l’applicazione di un operatore di meta-classificazione per che combina differenti modelli estratti e restituisce un tree-model utilizzando una tecnica di voting.
figura 38 : Esempio di query KDDML TreeMetaClassifier
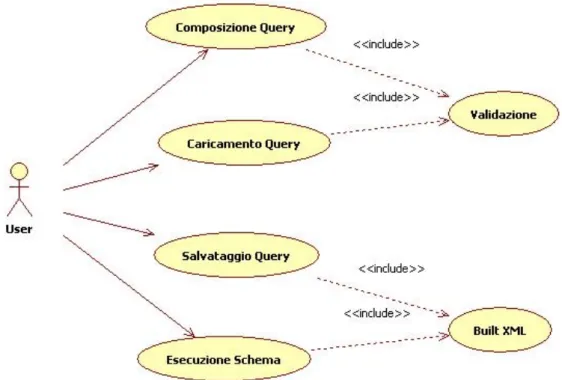
I TreeModel che vengono dati in pasto ai meta classificatori vengono elaborati attraverso l’operatore TreeMiner. Naturalmente l’operatore TREE_META_CLASSIFIER per poter applicare una tecnica di voting, ha la necessità che i data source iniziali siano uguali, quindi l’input iniziale per tutti gli operatori TREE_MINER sono è weather.xml. In questo caso l’albero DOM è abbastanza grande e evitiamo di inserirlo in questo paragrafo ma in seguito verrà mostrata la query costruita con il tool sviluppato che a nostro avviso risulta abbastanza esplicativo al fine di comprendere meglio la struttura dello schema. Per completezza in figura 48 è mostrato un diagramma di caso d’uso per il sistema realizzato. Ma iniziamo il nostro processo di costruzione di una query KDDML utilizzando l’interfaccia grafica.
Passo 1: Data input.
permette l’inserimento solamente di un operatore che sia stato marcato come DataSource. Questa soluzione è stata scelta pochè, come descritto nel capitolo precedente, quella che intendiamo realizzare è una vera e propria guida nella costruzione di un processo di KD e ogni estrazione di conoscenza non ha senso se non si parte da un dataset iniziale. Pertanto abbiamo scelto di “obbligare” l’utente a inserire il riferimento ad una sorgente di dati valida per poter continuare con la costruzione dello schema.
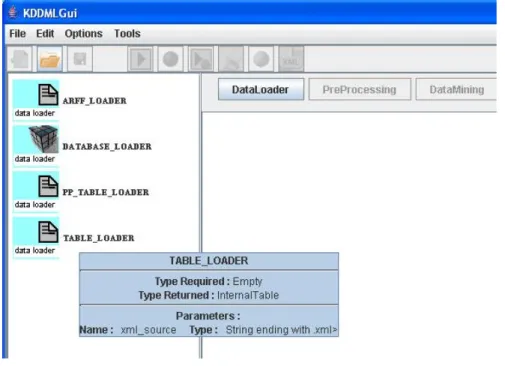
figura 39 : operatori di data-loader nella GUI
A questo punto l’utente può selezionare uno degli operatori che sono nel frame più a sinistra per inserirlo sul canvas. Poiché lo schema da costruire prevede una sorgente di dati in formato XML bisogna inserire nella nostra query il primo elemento per il caricamento di una tabella ( TABLE_LOADER). Per inserire l’elemento grafico è necessario semplicemente “cliccare” due volte su uno degli elementi della lista a sinistra.L’utente quando l’operatore viene aggiunto non ha nessun controllo sulla posizione all’interno dello schema ma una volta inserito l’elemento grafico può spostarlo a proprio piacimento (rispettando i vincoli grafici) nel pannello in cui è rappresentata la query. Facciamo notare 2 particolari della figura 37 :
1) Quando si passa con il mouse sugli operatori grafici viene mostrato un tooltip che racchiude una sintetica ma utilissima descrizione dell’elemento selezionato, permettendo in questo modo di pianificare la costruzione dello schema anche ragionando sui tipi restituiti ed i parametri necessari.
2) Tutte le funzionalità di cui l’utente non può usufruire in quel momento vengono opportunamente disabilitate (vedi figura 38). Allo stesso modo vengono disabilitati tutti i pulsanti che permettono di visualizzare gli operatori delle altre fasi del processo KDD in maniera da non incappare nella possibilità che l’utente inserisca un operatore non compatibile con la fase dell’elemento selezionato.
figura 40 : le fasi non compatibili vengono disabilitate.
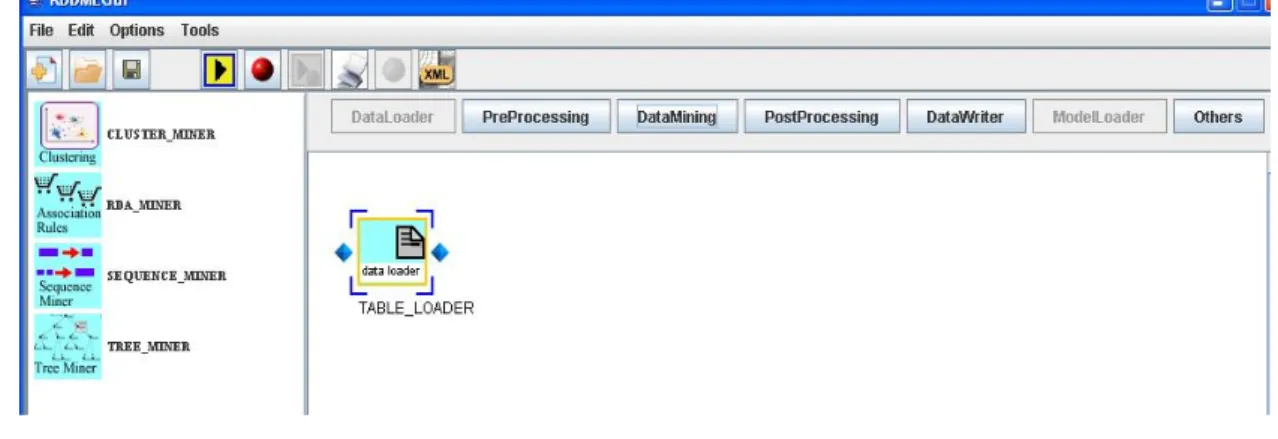
Ma ritorniamo all’inserimento del nostro primo operatore grafico. Dopo aver selezionato l’operatore TABLE_LOADER, un nuovo elemento grafico appare sullo schema(figura 39) e a questo punto è possibile procedere con l’evoluzione dello schema o inserire prima i parametri. Diciamo subito che l’ordine con cui si inseriscono i parametri per gli elementi grafici non ha importanza. Per capirci meglio, posso prima “disegnare” tutta la query e poi inserire i parametri per tutti
gli operatori presenti sul canvas o viceversa, senza che l’ordine con cui avvengono le operazioni condizioni in alcun modo l’esecuzione e la composizione dello schema.
A partire dalla query parziale di figura 39 ora è possibile accedere alle fasi successive del processo KD; infatti tutti i pulsanti che rappresentano le fasi compatibili con quella attuale (dell’operatore selezionato), vengono attivati e di conseguenza è possibile accedere agli elementi contenuti nelle liste che vengono visualizzati nel frame a sinistra.
Facciamo notare che quando un elemento grafico viene selezionato il colore del contorno diventa arancione.
A questo punto se vogliamo procedere con un ulteriore passo (in realtà la query rappresentata in figura 39 potrebbe considerarsi già valida) possiamo pensare di applicare un operatore di Data Mining al dataset iniziale (in questo caso abbiamo scelto di bypassare la fase di PreProcessing). Quindi selezioniamo il pulsante relativo alla fase di DataMining e la lista degli operatori disponibili nel frame di sinistra viene automaticamente aggiornata (vedi figura 40) in base al tipo di output dell’elemento selezionato (in questo caso la funzione “filtro” non viene applicata poiché tutti gli operatori di Data Mining prendono in input un tipo table).
figura 42 : operatori di DM
Passo 2 : DataMining
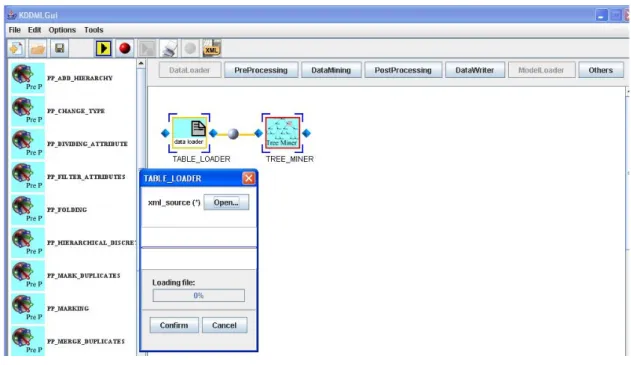
sorgente di dati. Noi chiaramente siamo interessati all’estrazione di un modello di classificazione quindi selezioniamo l’operatore TREE_MINER. Precisiamo che per poter inserire un operatore bisogna selezionare il nodo a cui lo si vuole agganciare (in questo caso TABLE_LOADER). La query risultante dopo questo passo è quella rappresentata in figura 41.
figura 43 : schema dopo l’inserimento di TREE_MINER
Come si può vedere anche dalla figura, l’elemento TREE_MINER è evidenziato con un contorno di colore rosso poiché non sono ancora stati inseriti degli attributi validi per tale operatore. Questo è sicuramente un modo molto semplice ed immediato per comunicare all’utente che la query che sta costruendo non si trova ancora in uno stato “consistente”. In tal caso infatti se l’utente cercasse di eseguire la query, il modulo che si occupa di effettuare la validazione, comunicherebbe all’utente che non è possibile eseguire la query e segnalerebbe i campi in cui è presente un errore. In questo modo ci assicuriamo che l’utente non mandi in esecuzione query scorrette.
In figura 41 è rappresentato anche un dialogo per l’immissione dei parametri per l’elemento TABLE_LOADER che ha come unico parametro il path del file che rappresenta la sorgente di dati. Se l’utente non specifica un path valido per
questo parametro, l’elemento grafico resterà ancor selezionato con il colore rosso che indica uno stato non valido per l’esecuzione.
Come avviene ad ogni inserimento di un nuovo elemento, il posizionamento sul work-flow avviene in maniera automatica, dopo l’inserimento l’utente ha la possibilità di modificare la propria vista del grafo. Facciamo notare che il collegamento tra i due nodi del grafo avviene in maniera automatica, infatti quando l’utente seleziona un nodo questo viene selezionato; ciò vuol dire che è pronto per essere collegato al successivo nodo che si desidera inserire. In questo modo il sistema provvede al collegamento tra i due nodi senza bisogno che all’utente sia demandato il compito di collegare gli elementi grafici. Facciamo notare come questo tipo di soluzione assomigli di più ad una rappresentazione ad albero in cui si seleziona il nodo al quale agganciare un nuovo figlio.
Per permettere all’utente di capire meglio ciò che sta costruendo, abbiamo aggiunto un segnalatore sugli archi che,se selezionato, avvia un tooltip in cui viene mostrato a video il “segnale” di output del nodo a cui è agganciato.
Passo 3 : Parametri TREE_MINER
per l’esecuzione inserendo i parametri opportuni. In figura 42 è mostrato il dialog box per l’inserimento dei parametri in cui è possibile scegliere il tipo di algoritmo di classificazione e i relativi parametri.
Dopo l’inserimento degli attributi necessari l’elemento grafico verrà marcato come valido e da un punto di vista grafico, diciamo che il nodo verrà evidenziato con il colore verde.
Passo 4-5 : estrazione di un altro modello di classificazione.
Per semplicità mostriamo lo stato della query dopo aver inserito altri due operatori nel nostro schema. Precisiamo che l’inserimento di tali operatori avviene in maniera del tutto analoga a quella descritta nei passi 1-3.
In figura 43 sei vede che due gli operatori sono della stessa tipologia di quelli precedentemente inseriti, pertanto viene aggiunto alla fine del nome, un indice per poter identificare nella stesura della query, quelli della stessa tipologia. Quando l’operatore TREE-MINER (1) viene selezionato, vengono automaticamente mostrati i possibili collegamenti per la fase successiva che è quella di Post-Processing. Nel frame a sinistra quindi compaiono solamente gli operatori di PostProcessing compatibili con il segnale di output dell’elemento corrente.
A questo punto supponiamo che l’utente decida di inserire un metaclassificatore da collegare ai due modelli estratti nella fase di DM. La situazione dopo tale
figura 44 : ulteriore estrazione di un albero di classificazione
inserimento è quella mostrata in figura 44.
figura 45 : inserimento di un metaclassificatore
Passo 6 : Collegamento di un nodo con più di un input.
A questo punto la situazione è la seguente: abbiamo due modelli di classificazione uno dei queli è collegato al segnale di input di un meta-classificatore. L’elemento grafico che rappresenta il meta-classificatore prende in pasto più di un segnale di input, quindi necessita di essere collegato almeno ad un altro operatore con tipo di output ClassificationModel. Per permettere all’utente di collegare in maniera semplice un nodo ad un altro che ha ancora un segnale di input non assegnato ( vedi capitolo precedente ), abbiamo inserito una funzionalità a nostro avviso molto immediata ed intuitiva. Infatti, quando si seleziona un qualsiasi nodo del grafo, se questi ha come segnale di output un tipo compatibile con qualche input di un nodo che non ha ancora tutti i segnali di input assegnati, viene mostrata una lampadina nell’angolo superiore dell’icona del nodo. Se si “clicca” con il pulsante sinistro del mouse su questo simbolo, si apre una finestra in cui vengono mostrati in una lista tutti i possibili operatori che si possono collegare a partire dal nodo selezionato. In questo modo si fornisce all’utente un potente strumento per la composizione dello schema, senza avere quindi bisogno di conoscere il tipo ed il numero degli attributi di tutti gli operatori del linguaggio.
Ad ogni modo, quando l’utente sceglie di collegare TREE_MINER con TREE_META_CLASSIFIER (1), in maniera automatizzata è creato un collegamento tra il nodo selezionato e quello scelto nel dialog box descritto precedentemente.
Lo schema quindi cambia e la query ora diventa quella in figura 45.
Precisiamo che l’elemento TREE_META_CLASSIFIER (1) rimane evidenziato con il colore rosso poiché permette l’inserimento di n modelli di classificazione come input e di conseguenza è sempre inserito nella lista degli operatori che potenzialmente necessitano di ulteriori parametri di input. Questo però non comporta che, quando si effettua la validazione della query grafica, l’elemento TREE_META_CLASSIFIER (1) sia considerato come non pronto per l’esecuzione. Infatti il controllo sul numero di input per questo operatore viene bypassato se il compilatore della query grafica si accorge che sono presenti due o più segnali in input per tale elemento.
figura 46 : query dopo l’inserimento dell’arco tra TREE_MINER e TREE_META_CLASSIFIER
A questo punto la query rappresentata in figura 45 si può considerare già valida (a patto che gli argomenti degli algoritmi di TREE_MINER e TREE_MINER(1) siano stati inseriti in maniera corretta) e potremmo pensare di mandare in esecuzione lo schema corrente. In ogni caso l’esempio fornito all’inizio del paragrafo (vedi figura 35) mostrava un modello di query un po’ più complessa,
perciò la query che consideriamo a questo punto è quella di figura 46.
figura 47 : query equivalente a quella di figura 35
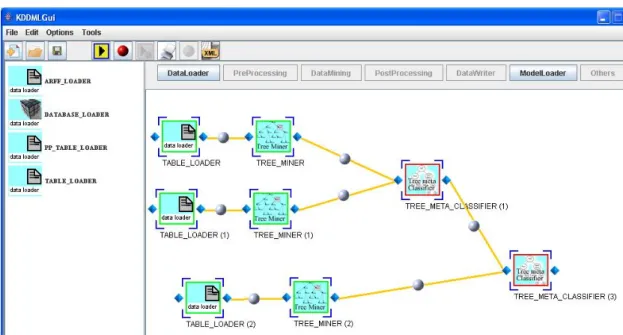
Passo 7 : inserimento di un’altra sotto-query per l’estrazione di un modello.
Come si vede dalla figura 46, sono stati aggiunti allo schema altri tre operatori effettuando i passi come nei punti precedenti. Per l’operatore TREE_MINER(2) sono stati settati dei parametri differenti rispetto algli altri classificatori in modo da ottenere dallo stesso dataset modelli diversi. Il procedimento che abbiamo effettato per la costruzione della query della figura 46 consiste nella composizione di più sotto query differenti. Questa secondo noi, è una caratteristica molto importante che fornisce una ulteriore potenzialità al sistema. Infatti, si può pensare di costruire due query separate, mostrare il risultato di entrambe le modellazioni e poi agganciarle insieme per costruire un’unica query. Naturalmente questo risulta possibile solo ed esclusivamente se sono rispettati i vincoli sui tipi dei segnali di input e di output (vedi capitolo 4). Ebbene, quello che abbiamo fatto in questo passo è stato proprio comporre la query di figura 45 con una nuova query fatta da TABLE_LOADER(2) → TREE_MINER(3) dando l’input di entrambe (che è di tipo TreeModel) ad un nuovo meta-classificatore (TREE_META_CLASSIFIER(3)). Ricordiamo che esiste l’opportunità di cambiare il nome agli elementi grafici in modo da tenere
una propria organizzazione; in questo caso abbiamo lasciato alle etichette dei nodi tutti i nomi di default.
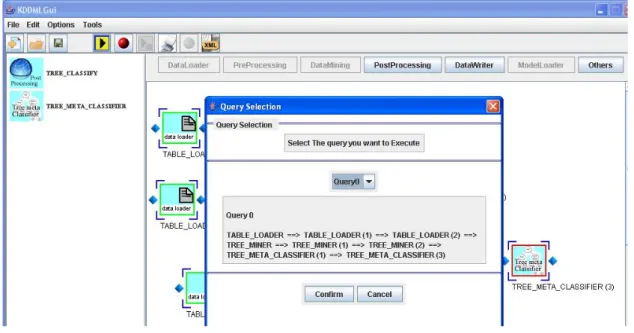
Passo 8 : esecuzione della query.
Quando la query è stata completata, si può scegliere se salvarla, validarla per trovare eventuali errori, o mandarla in esecuzione.
La figura 47 mostra la finestra di selezione della query. E’ presente un combo box poiché è possibile comporre query differenti sullo stesso canvas e poi scegliere solo alla fine quale mandare in esecuzione. In questo caso l’unica query presente nel pannello è quella di figura 46 poiché l’unica foglia del grafo (ad eccezione dei nodi di data-source) è TREE_META_CLASSIFIER (3).
figura 48 : esecuzione della query
Dopo aver scelto la query da eseguire avviene la fase di compilazione della query, trasformandola da rappresentazione visiva ad un formato valido per KDDML (XML-like). A questo punto il file costruito viene passato come parametro ad un Thread che integra l’interprete KDDML e quando l’elaborazione dei dati è terminata, viene aperto il browser per la visualizzazione dei risultati. Precisiamo che l’esecuzione dell’interprete
KDDML non è bloccante per l’interfaccia grafica, quindi si può continuare ad utilizzare la GUI mentre è in esecuzione l’elaborazione di uno schema.
Nel caso in cui la query non fosse valida, viene aperto un frame in cui è presente una lista degli errori riscontrati durante la fase di validazione e l’esecuzione della query selezionata non viene avviata. In questo caso infatti si può procedere con la correzione degli errori rilevati dal “validatore” ed eseguire la query in un momento successivo.
Nel caso si voglia salvare lo schema composto, è possibile selezionare dal menu “File → Salva” l’opzione relativa e scegliere un nome per il file in cui è codificata la query.
Per ricaricare lo schema precedentemente salvato occorre solamente cliccare sull’icona di nella toolbar (o in maniera equivalente dal menu File) e scegliere il file che si desidera caricare. In questo caso un modulo del sistema si occuperà del caricamento sullo schema della query e sarà possibile modificarlo o eseguirlo come se fosse stato costruito da zero.
6.3 Il progetto software
IntroduzioneIn questo paragrafo si cercherà di dare una breve descrizione di come sono organizzati i package relativi all’implementazione delle funzionalità descritte nei paragrafi precedenti mostrando, ove ritenuto particolarmente interessante, i diagrammi UML delle classi coinvolte.
Il progetto è stato sviluppato in ambiente Windows Xp utilizzando il linguaggio di programmazione JAVA. La scelta del linguaggio di programmazione è stata pressoché obbligata poiché il sistema KDDML è interamente sviluppato in JAVA. Per ciò che riguarda le librerie diciamo che abbiamo usato Swing per realizzare le funzionalità grafiche, abbiamo scelto la libreria JDom per effettuale la manipolazione di documenti XML, per realizzare la funzionalità di parsing di DTD abbiamo utilizzato wutka.
6.3.1 Package GuiKDDML
Questo package contiene le classi che realizzano le principali funzionalità grafiche dell’interfaccia del sistema. Procediamo ad una breve descrizione delle funzionalità delle classi più importanti del package.
DTDReaderInterface
Interfaccia che descrive le operazioni di base di un modulo che si occupa della lettura delle DTD (contengono le informazioni di base degli operatori del sistema).
Questa classe contiene il metodo astratto:
fillList() : utilizza il parser DTD per inserire in opportune strutture dati le informazioni riguardo agli operatori del sistema. Nel caso si volesse cambiare il
parser, bisognerebbe fornire semplicemente una differente implementazione di questo metodo.
DTDReader
Realizza la funzionalità della relativa interfaccia descritta in precedenza. Il costruttore di questa classe prende in input il path relativo della file .dtd su cui si desidera effettuare il parsing.
GraphHandlerInterface
Questa interfaccia fornisce i le linee guida per la realizzazione dei metodi che gestiscono il posizionamento automatico sul canvas in cui è posizionato il grafo degli elementi grafici. I metodi astratti per questa interfaccia sono:
- getNextOperatorPosition(Point previousOperatorPosition); - linkNextOperator();
- setNodeParam(int arcNumber,Point lastVerticalOperator);
In questo modo se si vuole fornire l’interfaccia di un differente “motore” per il posizionamento degli ogetti nel work flow, basta implementare questa interfaccia e aggiungere la classe nel package senza modificare altro codice.
GraphHandler
Questa classe è la realizzazione dell’interfaccia descritta in precedenza e provvede a fornire una implementazione per i metodi :
- getNextOperatorPosition(Point previousOperatorPosition) :
dato il punto (riferito al GraphPanel) dell’ultimo operatore inserito, restituisce un nuovo punto che rappresenta la posizione del prossimo operatore che si desidera inserire nel grafo. Provvede a controllare che gli oggetti grafici inseriti non si sovrappongano.
effettua il collegamento tra due elementi grafici, quello selezionato e quello appena inserito.
- setNodeParam(int arcNumber,Point lastVerticalOperator) :
Ogni volta che è inserito un operatore vengono settati i parametri arcNumber che è il numero di archi uscenti che ha un elemento grafico e lastVerticalOperator che rappresenta la posizione dell’operatore con il valore delle ordinate più alto.
GraphPanel
E’ uno degli elementi principali del sistema grafico. Questa classe realizza tutte le funzionalità di elaborazione del grafo utilizzando i metodi messi a disposizione da altri moduli del sistema. Questa classe è un pannello che estende la classe JPanel e quindi fornisce una implementazione del metodo paintComponent (Graphics g) per la stampa del grafo a video. Nel caso si volesse cambiare la vista del sistema bisognerebbe fornire una implementazione alternativa di tale metodo senza toccare i campi della classe (modello di dati rappresentato).
Include alcuni metodi per la manipolazione del grafo tra cui: addGraphicObject(KDDMLGuiObject element):
- aggiunge un nuovo elemento grafico allo schema. intersectAnOperator(Point mousePosition):
- restituisce true o false a seconda che il mouse (mousePosition) sia cliccato sulla regione relativa ad uno degli elementi grafici
setLabel(int guiObjIndex,String newName):
- permette di cambiare l’etichetta di un nodo. getNextOperatorPosition():
- restituisce la prossima posizione utile sul canvas per il posizionamento di un altro elemento.
- aggiunge un collegamento visivo tra il nodo operatorIndex e nextOperatorIndex.
removeOperator(int operatorIndex):
- provvede alla rimozione di un operatore dal grafo. In questo caso natulamente si deve tenere conto della posizione dell’elemento da eliminare. Ad esempio, se si tratta di un nodo interno si devono eliminare sia gli archi uscenti che quelli entranti associati ad esso.
Oltre a questi metodi ci sono dei semplici getter e setter che non elenchiamo (vedi sorgenti).
KDDMLGuiObject
Questa è la classe che modella gli operatori del sistema recuperando informazioni dal livello KDDML.Core e realizzando in questo modo una mappatura tra gli elementi grafici e operatori del linguaggio KDDML. Questa classe infatti rappresenta un grosso contenitore di informazioni che vanno da dati che descrivono l’operatore da un punto di vista grafico fino agli attributi inseriti dall’utente tramite i Dialog Box. Naturalmente sono presenti tutti i metodi necessati per interagire con questo “container”.
Evitiamo di descrivere i metodi presenti in tale classe rimandando maggiori dettagli alle API del sistema grafico.
MouseGraphListener
Come nella maggior parte delle interfacce grafiche, anche nella nostra implementazione è presente un ascoltatore di eventi del mouse.
Questa classe infatti implementa la classe astratta MouseAdapter e fornisce una implementazione per tutti i metodi astratti collegati con essa (mousePressed(), mouseDragged(),ecc.). Inoltre in questa classe viene fornita l’implementazione per i metodi:
showTip(String text, Point p):
- mostra nel punto p un tooltip contenente la stringa text. Questo metodo è utilizzato quando si vuole visualizzare il tipo di output di un operatore.
selectOperator(MouseEvent e):
- metodo utilizzato quando un la regione di un operatore contiene il punto in cui si clicca con in mouse. Questo metodo effettua tutte le operazioni sia logiche che grafiche per selezionare un elemento grafico
OperatorsFilterInterface
Interfaccia che fornisce un metodo astratto per la realizzazione della funzione filtro (definita nel capitolo 4) sugli operatori.
Public abstract void FilterByAttributes(String type, boolean [] phaseTest, StringAndConstants.Phase selectedOperatorPhase):
- questa funzione astratta definisce il prototipo per effettuare il filtraggio degli operatori non compatibili con quello selezionato in modo da mostrare all’utente solo quelli che può aggiungere allo schema.
OperatorsFilter
Questa classe è una realizzazione dell’interfaccia descritta in precedenza. Naturalmente fornisce l’implementazione per il metodo astratto dell’interfaccia OperatorsFilterInterface e in più vengono forniti i metodi:
deleteIncompatibleAtt( int listIndex,String type):
- elimina dalla lista degli operatori da mostrare all’utente quelli che non hanno superato il test del filtro in modo da mostrare all’utente solo gli elementi compatibili.
filterOthers():
un segnale di input libero.
PhaseHandler
Questa classe permette di capire quali sono le fasi che è possibile visualizzare a partire dalla fase dell’operatore selezionati in un determinato istante.
Ha al suo interno il metodo boolean[] CanShow(Phase status_phase):
- data la fase del processo di KDD phase restituisce un array di booleani che descrivono se è possibile o meno visualizzare la fase di indice i-esimo nell’array. Si assume che l’ordine delle fasi sia : DataLoader, PreProcessing, DataMining, PostProcessing, ModelLoader, DataWriter.
6.3.2 Package DialogBox
Questo package racchiude la gerarchia di dialog box utilizzati dal sistema per interagire con l’utente quando si inseriscono i parametri per gli operatori KDDML. In figura 50 è mostrato il diagramma delle classi per il package. Mostreremo nel seguito per ogni classe le differenze implementative che hanno portato ad una suddivisione di tale genere.
StandardDialog
Questa classe estende JDialog e fornisce una serie di parametri utilizzati da tutti i dialog box per l’input degli operatori. Qui è codificato il comportamento standard di una finestra di dialogo.
InputDialog
Rispetto allo StandardDialog questo dialog box ha la necessità di caricare un file sorgente e attraverso la progress bar mostrare all’utente l’avanzamento della meta-esecuzione di tale operatore. Questa necessità, comune a tutti gli operatori
che prendono in input un data-source, ha portato allo sviluppo di un dialog box separato pur ereditando dalla superclasse StandardDialog tutti i parametri e le funzionalità di base.
PreProcessingDialog
Anche in questo caso abbiamo raccolto in questa classe tutte le caratteristiche che devono avere i dialog box per i nostri operatori di preprocessing. In questo caso sono stati parametrizzati gli attributi di input per tali operatori e creati opportuni box per quegli elementi che prevedono tra i propri input un algoritmo o una condition. Queste modifiche non sono visibili dal diagramma delle classi di figura 50 poiché tali funzionalità sono incapsulate interamente nel costruttore. In generale quindi basta un override del costruttore di StandardDialog per ridefinire la logica di rappresentazione del dilogo di input per PreProcessing.
DataMinigDialog
In questo caso è necessario memorizzare anche altre informazioni relative al posizionamento del pannello per immettere i parametri dell’algoritmo memorizzato e altre strutture grafiche legate alla corretta formattazione del dialog box. Inoltre è necessario interagire con il Core del sistema KDDML per recuperare informazioni specifiche riguardo agli algoritmi di mining come : numero e tipo dei parametri, nome e numero degli algoritmi,ecc.
In tal caso viene implementata la funzione getAlgorthmInformation() che provvede all’interazione con il sistema sottostante.
PostProcessDialog
Anche in questo caso non vi sono particolari differenze con lo StandardDialog se si tiene presente la figura 50, ma allo stesso modo del PreProcessingDialog le differenze a livello di implementazione riguardano soprattutto la logica di posizionamento degli elementi che in questo caso si presenta più difficoltosa.
DataWriteDialog
L’esigenza di creare un dialog box differente per gli operatori di DataWriter viebe sicuramente dal fatto che è necessario avere una serie di controlli per decidere dove salvare la tabella corrente. Infatti nel caso si scelga di salvare su un file serve semplicemente avere un JFileChooser che permette di navigare le cartelle del file system e scegliere la destinazione. Nel caso si voglia procedere al salvataggio tramite DB sono necessari parametri di connessione al database e una finestra per l’evetuale autenticazione.
6.3.3 Package GraphCompiler
per il sistema grafico. Cercheremo quindi di dare una descrizione abbastanza completa per ogni elemento e mostrare alcuni diagrammi delle classi significativi.
GraphModifierInterface
Questa interfaccia fornisce le linee guida per l’elaborazione della query grafica. Se si vuole fornire una implementazione per questa interfaccia è necessario realizzare i due metodi astratti su cui essa si poggia : builtQuery() e executeQuery().
GraphModifier
Questa classe rappresenta una implementazione dell’interfaccia descritta in precedenza e fornisce i seguenti metodi per l’elaborazione della query grafica (vedi figura 51):
builtQuery()
- a partire da una query rappresentata da un grafo, prepara le apposite strutture dati, memorizzando le query presenti sul canvas in ArrayList<Query>.
builtXMLQuery(int queryID):
- data la query memorizzata crea la corrispondente query in formato XML. Facciamo notare che questa è sicuramente una delle funzionalità più delicate per il sistema. Ogni problema di formattazione deve essere risolto a questo livello.
refactorQuery(Element root):
- questa funzione permette, dato un elemento dell’albero DOM, di effettuare un’operazione di refactoring della query se vi sono
inconsistenze tra gli attributi presenti nelle DTD ed i parametri inseriti dall’utente (vedi cap. 5).
figura 51 : diagramma GraphCompiler
QueryCompiler
Permette di effettuare la “compilazione” della query nel senso che viene effettuata una analisi statica e fatto un controllo di correttezza degli attributi. I metodi che forniscono queste funzionalità sono:
validateGraphicQuery():
- fornisce eventuali errori di inserimento degli atrtibuti della query grafica. validateDebugGraphicQuery():
- fornisce eventuali errori di inserimento degli atrtibuti della query grafica delimitata dal marcatore di esecuzione parziale.
- controlla la correttezza dei parametri immessi per l’algoritmo selezionato per l’operaore di indice (nel grafo) “opIndex”.
QuerySaverInterface
Ha sostanzialmente due metodi astratti cha devono essere realizzati qualora si voglia fornire una realizzazione concreta di un modulo per il salvataggio di una query parziale (vedi figura 52). I metodi sono addGraphicAttributes(Element elem,int opIndex) saveQuery(Document doc).
QuerySaver
Realizza la funzionalità di salvataggio su file delle query presenti sul canvas. Fornisce l’implementazione per i metodi :
addGraphicAttributes(Element elem,int opIndex):
- aggiunge ad ogni elemento del DOM della query KDDML attributi aggiuntivi che riguardano esclusiovamente aspetti grafici.
saveQuery(Documet doc):
- Salva su file il documento xml rappresentato da doc. addArcNode(Element elem,ArrayList<Integer>operatorIndexes):
- data la lista di archi presenti sul grafo, li salva all’interno della query utilizzando opportuni tag.
QueryLoaderInterface
E’ la classe astratta che definisce le modalità di caricamento delle query salvate in precedenza (vedi figura 53). Ha i seguenti metodi astratti: loadQueryFromFile(String filePath), loadParameters(Element elem, KDDMLGuiObject newItem), loadAlgorithParam(Element alg).
QueryLoader
E’ la realizzazione di QueryLoaderInterface. Fornisce gli strumenti necessari al caricamento di uno schema dato un file xml.
loadQueryFromFile(String filePath):
- è il metodo principale, carica all’interno dell’applicazione la query salvata sul file con path “filePath”.
loadParameters((Element elem, KDDMLGuiObject newItem):
- Dato un elemento dell’albero DOM ed il corrispondente elemento grafico, carica all’interno di “newItem” i parametri memorizzati nel nodo “elem”.
controlFileCorrectness():
- Effettua un controllo di correttezza sul corretto formato del file che si sta cercando di caricare. Restituisce un messaggio di errore se si tenta di caricare un file non compatibile.
loadAlgorithmParam(Element alg):
- dato un elemento dell’albero DOM che identifica un algoritmo, permette di caricare tutti i parametri necessari per l’esecuzione.
DataLoaderMetaExecute
Relizza un thread che va in esecuzione in background quando si seleziona un data-source o si carica un modello. Questo permette di visualizzare all’interno della gui tutte le meta-informazioni relative al file caricato. Il thread provvede a creare una query fittizia e lanciare l’interprete KDDML. Oltre all’implementazione del metodo run()(obbligatorio poiché è implementata l’interfaccia Runnable) è presente il metodo savingMetaQuery() che costruisce
la meta-query e la salva sul disco prima dell’esecuzione.
figura 52 : QuerySaver