2.TEORIA DELLA STEREOVISIONE ATTIVA
2.Teoria della stereovisione attiva
In questo capitolo verrà esposta la base teorica delle metodologie di ricostruzione: analizzeremo quindi il modello matematico della camera (estendibile al proiettore) e accenneremo agli aspetti teorici della calibrazione; inoltre sarà presentato l'aspetto teorico della triangolazione necessaria per la ricostruzione tridimensionale; infine verranno illustrate varie tecniche attualmente utilizzate per il calcolo delle corrispondenze (nell’ambito dei sistemi a luce codificata) tra le quali troviamo anche quelle che sono state utilizzate nella nostra indagine.
2.1 Modello della camera
2.1.1 Modello semplificato
2.TEORIA DELLA STEREOVISIONE ATTIVA
Il modello di proiezione prospettica più utilizzato in letteratura è il cosiddetto modello prospettico o Pin-Hole (letteralmente buco di spillo), utilizzato sia per telecamere (o fotocamere) che per proiettori (visti come inverse-camera).
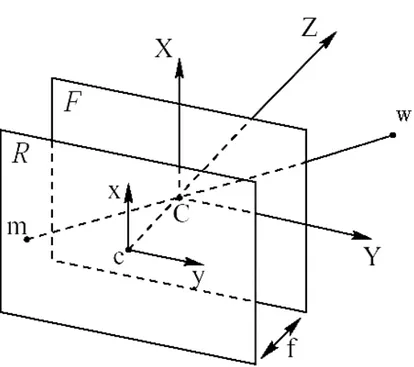
Facendo riferimento alla figura 2.1 abbiamo il centro ottico C e il piano retina R (in cui si proiettano i punti dello spazio) i quali distano fra loro di una quantità f detta distanza focale.
Il piano F su cui giace C e parallelo al piano retina è chiamato piano focale; l’asse passante per C e perpendicolare al piano retina è detto asse ottico; l’intersezione c di questo asse con il piano retina è detto punto principale.
Durante tutta la trattazione teorica faremo riferimento a due sistemi cartesiani: uno bidimensionale (x,y) solidale al piano retina centrato sul punto principale c ed uno tridimensionale (X,Y,Z) centrato in C e solidale al piano focale F con l’asse Z coincidente con l’asse principale e con orientazione degli assi X e Y analoga a quella degli assi x e y.
Un punto dello spazio w = (X,Y,Z) viene proiettato nel processo di formazione dell’immagine sul piano retina in un punto m = (x,y) tramite una trasformazione (proiezione prospettica) che può facilmente essere ricavata mediante le relazioni dei triangoli simili:
f y Z Y ; f x Z X =− =− ovvero : ⋅ − = ⋅ − = Z Y f y Z X f x (2.1)
La relazione tra coordinate (X,Y,Z) e (x,y) è dunque non lineare; per questo conviene sostituire le coordinate euclidee con quelle omogenee
2.TEORIA DELLA STEREOVISIONE ATTIVA
mediante le quali si riescono a rappresentare analiticamente le trasformazioni geometriche tramite operazioni lineari tra matrici.
Ai punti w e m di coordinate euclidee (X,Y,Z) e (x,y) corrispondono i punti
w~ e m~ di coordinate omogenee (X*,Y*,Z*,T) e (x*,y*,t) da cui si possono ricavare le relative coordinate euclidee tramite una semplice divisione per l’ultima coordinata omogenea.
Da un punto nello spazio di coordinate omogenee w~ =
(
X*,Y*,Z*,T)
si ricavano infatti immediatamente le coordinate euclidee in 3D:T Z Z T Y Y T X X * * * = = =
Poiché si ha che a quaterne di coordinate omogenee proporzionali corrisponde un unico punto in coordinate euclidee, è conveniente utilizzare, dato un punto w = (X,Y,Z), il corrispettivo w~ =
(
X*,Y*,Z*,T)
con X*=X , Y*=Y , Z*=Z , T=1 (per questo motivo d’ora in poi si tralascerà di utilizzare l’asterisco * riguardo alle coordinate omogenee tridimensionali, senza pericolo di ambiguità). Così da un punto proiettato di coordinate omogenee m~ =(
x*,y*,t)
si ricavano quelle euclidee in 2D:t y y t x x * * = =
Mediante questo espediente si può scrivere la trasformazione prospettica direttamente come:
w P m~= ~⋅~
2.TEORIA DELLA STEREOVISIONE ATTIVA
(d’ora in avanti il simbolo ~ si riferirà sempre alle coordinate omogenee) dove P è la matrice di proiezione prospettica (PPM) che i questo caso vale:
0 1 0 0 0 0 f 0 0 0 0 f P ~= − − (2.2)
La relazione pertanto si esplicita in questo modo:
⋅ − − = − − ⋅ = ⋅ ⋅ 1 0 1 0 0 0 0 0 0 0 0 * * Z Y X f f Z fY fX t y x t y t x t (2.3)
E’ da notare che alcuni preferiscono utilizzare e riferirsi ad un modello con il piano retina che si trova davanti a quello focale rispetto alla scena, così come è schematizzato in figura 2.2
figura 2.2 modello della camera con piano retina davanti a quello focale in tal caso valgono tutte le relazioni scritte finora a patto di togliere il segno – (meno) davanti al parametro f.
2.TEORIA DELLA STEREOVISIONE ATTIVA
2.1.2 Modello generale
Per poter rappresentare realmente il processo di formazione dell’immagine e per poter essere utilizzato in maniera ottimale in un sistema di visione stereo il modello Pin-Hole necessita di ulteriori considerazioni: così come è stato descritto infatti il modello non tiene conto dell’effetto di “pixelizzazione” (dovuto al fatto che l’immagine acquisita al calcolatore è discretizzata in pixel), e non risulta molto comodo nella trattazione di un sistema di visione stereo in quanto si riferisce alle coordinate solidali al piano focale di uno dei due componenti del sistema stesso, per cui è necessario svincolare il sistema di riferimento assoluto della scena da quello solidale al piano focale.
Si utilizza quindi un unico sistema di riferimento “mondo” a cui riferire la scena, e si riportano a questo i due sistemi di riferimento focali mediante una trasformazione rigida che grazie alle coordinate omogenee si esprime sempre tramite relazioni lineari.
2.TEORIA DELLA STEREOVISIONE ATTIVA
Trattandosi di una trasformazione rigida il cambio di coordinate avviene in generale tramite una rotazione seguita da una traslazione (è preferibile che avvengano nell’ordine indicato in quanto consentono un migliore funzionamento degli algoritmi di calibrazione).
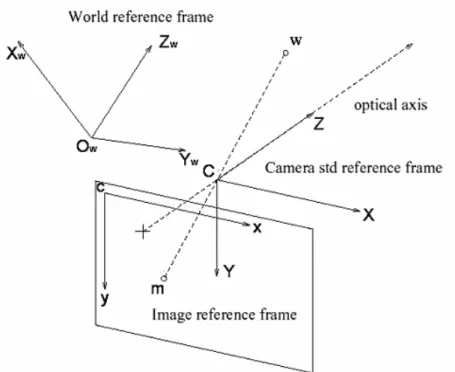
Se indichiamo con ww= (Xw,Yw,Zw) le coordinate del punto w rispetto al
sistema di riferimento mondo (figura 2.3) la relazione con le coordinate focali è:
+ ⋅ = z y x w w w 33 32 31 23 22 21 13 12 11 t t t Z Y X r r r r r r r r r Z Y X ovvero w=R⋅ww+T
utilizzando le coordinate omogenee la relazione risulta:
⋅ = 1 Z Y X 1 0 0 0 t r r r t r r r t r r r 1 Z Y X w w w z 33 32 31 y 23 22 21 x 13 12 11 ovvero w~=G~⋅w~w (2.4) Con 1 0 T R G~ 3 =
La matrice G esprime i cosiddetti parametri estrinseci del modello della telecamera che possono essere individuati mediante la calibrazione insieme a quelli intrinseci.
E’ da notare che i parametri estrinseci da calibrare sono, a dispetto delle dimensioni della matrice rotazione R e del vettore traslazione T, solo 6 così come il numero dei parametri indipendenti della trasformazione (la matrice rotazione infatti deve essere ortogonale); i gradi di libertà sono quindi 6 di cui 3 relativi alla rotazione (gli angoli di Eulero) e 3 relativi alla traslazione.
2.TEORIA DELLA STEREOVISIONE ATTIVA
La natura discreta della campionatura delle immagini obbliga a tener conto dell’effetto di pixelizzazione che rende in realtà disponibili coordinate discrete per l’immagine acquisita.
Questo richiede l’adozione di due fattori di scala, uno orizzontale Ku ed
uno verticale Kv: essi possono essere calcolati come l’inverso delle dimensioni
efficaci del pixel in direzione orizzontale e verticale.
A questo proposito è bene introdurre alcune considerazioni sul processo di acquisizione delle immagini.
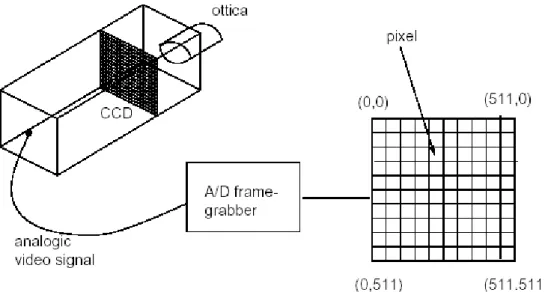
Tipicamente un sistema di acquisizione delle immagini è costituito da una camera, un frame grabber (scheda di acquisizione) e un calcolatore; la camera può essere schematizzata da una lente e una matrice di elementi fotosensibili chiamata CCD (Charged Coupled Device) che costituisce il piano immagine della camera.
figura 2.4 schema di un sistema di acquisizione di immagini
L’intensità luminosa che investe ogni cella della matrice viene trasformata in un segnale elettrico che viene estratto e letto in modo ordinato (uno alla volta, riga per riga), e opportunamente interpolato e filtrato in frequenza e trasformato quindi in un segnale analogico.
2.TEORIA DELLA STEREOVISIONE ATTIVA
Il segnale video analogico in uscita dalla telecamera è quindi digitalizzato dal frame grabber che crea una matrice N x M di valori interi (per esempio 0…255) che rappresentano il valore dell’intensità del segnale video per ogni elemento della matrice.
I valori di questa matrice vengono quindi trasferiti da una memoria locale del frame grabber (detta frame buffer) a quella centrale del calcolatore e diventano quindi dati pienamente utilizzabili.
L’immagine visualizzata al computer avrà lo stesso numero di elementi N x M della matrice creata dal frame grabber, ma non è detto che anche la matrice del CCD sia anch’essa N x M.
A causa di un’imperfetta corrispondenza (errori di temporizzazione ) tra l’hardware della telecamera (numero di elementi fotosensibili per riga del CCD) e del frame grabber (campionatura in direzione orizzontale ), nonché del filtraggio in frequenza e dell’interpolazione fatte per aumentare il rapporto segnale/rumore del segnale, la conversione analogico/digitale può portare a variazioni del valore di Ku previsto fino al 5%: le metodologie di calibrazione
della telecamera sviluppate in letteratura tengono tutte presente questo aspetto mediante un parametro correttivo.
Questo non si verifica in direzione verticale in quanto lungo tale direzione il campionamento è controllato dalla suddivisione delle celle del CCD.
A questo punto è bene precisare però che le telecamere digitali, come quella utilizzata per le nostre acquisizioni, non presentano questo tipo di inconveniente perché danno in uscita direttamente un segnale digitale.
Nel seguito non ci addentreremo dunque in una spiegazione dettagliata della calibrazione di questo fattore correttivo.
Tenendo quindi conto della pixelizzazione, ma trascurando l’effetto sopra esposto, le relazioni che descrivono il passaggio da coordinate euclidee del piano focale a quelle pixel sono:
+ ⋅ = + ⋅ = 0 v 0 u v k y v u k x u (2.5)
2.TEORIA DELLA STEREOVISIONE ATTIVA
dove u e v sono le coordinate dei punti dell’immagine espresse in pixel, mentre con u e 0 v si intendono le coordinate in pixel del punto principale. 0
I fattori di scala ku e kv si calcolano come l’inverso delle dimensioni del
pixel che sono forniti dal costruttore della telecamera con precisione inferiore al micron.
Integrando quindi le relazioni appena riportate nelle (2.1) si ottiene:
+ ⋅ ⋅ − = + ⋅ ⋅ − = 0 v 0 u v k Z Y f v u k Z X f u (2.6)
Introducendo anche questo aspetto la PPM diventa dunque:
1 0 T R 0 1 0 0 0 v k f 0 0 u 0 k f P ~ 3 0 v 0 u ⋅ ⋅ − ⋅ − =
che può essere scritta anche:
G~ ] 0 | I [ A 1 0 T R 0 1 0 0 0 v 0 0 u 0 P ~ 3 0 v 0 u ⋅ = ⋅ α α = (2.7) dove αu =−f ⋅ku , αv =−f⋅kv e 1 0 0 v 0 u 0 A v 0 0 u α α =
è da notare che nella forma (2.7) otteniamo la separazione dei parametri intrinseci (A) da quelli estrinseci (G).
2.TEORIA DELLA STEREOVISIONE ATTIVA
Questa PPM consente quindi di passare direttamente dalle coordinate mondo Mw = (Xw,Yw,Zw) a quelle sul piano retina espresse in pixel m = (u,v).
Il modello Pin-Hole così “esteso” non riuscirà comunque a tenere conto anche delle imperfezioni di realizzazione e di montaggio delle lenti che si traducono nella distorsione dell’immagine nel piano retina, fenomeno per il quale si dovranno fare considerazioni aggiuntive.
2.1.3 Introduzione di un modello di distorsione
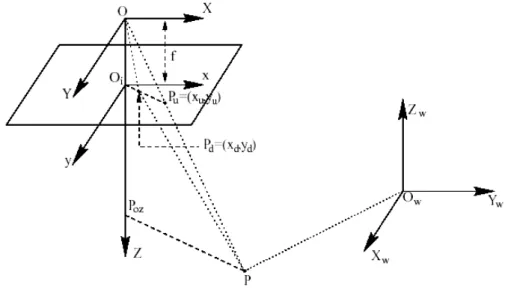
Quando abbiamo introdotto la pixelizzazione in realtà avremmo dovuto applicare la trasformazione:
dove con xd e yd si intendono le coordinate distorte: per l’effetto sopra
menzionato infatti la posizione reale di un punto immagine è diversa da quella predetta dalla (1.1).
figura 2.5 posizione del punto con e senza distorsione + ⋅ = + ⋅ = 0 0 v k y v u k x u v d u d
2.TEORIA DELLA STEREOVISIONE ATTIVA
Se con x e y, come abbiamo fatto finora, indichiamo le coordinate previste per il punto sul piano retina senza considerare la distorsione, le coordinate del punto effettive (distorte) sul piano retina sono date da:
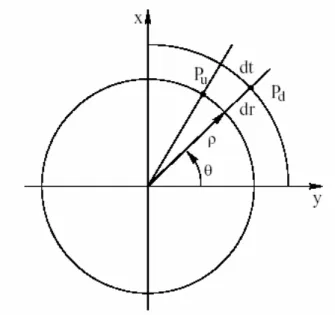
La distorsione dipende quindi dal punto e in particolare dalla distanza del centro di distorsione che in pratica è assunto coincidente al punto principale c = (0,0); esistono numerosi modelli matematici che possono tener conto della presenza della distorsione in modo più o meno complesso.
A grandi linee si può dire che esistono due tipi di distorsione: la distorsione radiale e quella tangenziale; così come si può capire dalla terminologia stessa la distorsione radiale determina uno spostamento della posizione prevista del punto nel piano retina lungo la congiungente con il punto principale, mentre per quella tangenziale la direzione dello spostamento è ortogonale a quella precedente (vedi figura 2.5).
figura 2.6 Distorsione radiale e tangenziale viste separatamente + ⋅ = + ⋅ = ) , ( ) , ( y x k y y y x k x x y v d x u d δ δ
2.TEORIA DELLA STEREOVISIONE ATTIVA
Volendo esprimere in formule si ha:
distorsione radiale: + ⋅ + ⋅ ⋅ = + ⋅ + ⋅ ⋅ = ...) r k r k ( y dy ...) r k r k ( x dx 4 2 2 1 4 2 2 1 distorsione tangenziale: + ⋅ + ⋅ ⋅ = + ⋅ + ⋅ ⋅ − = ...) r q r q ( x dy ...) r q r q ( y dx 4 2 2 1 4 2 2 1
dove r= x2 +y2 è la distanza dal punto principale del punto proiettato nel
piano retina.
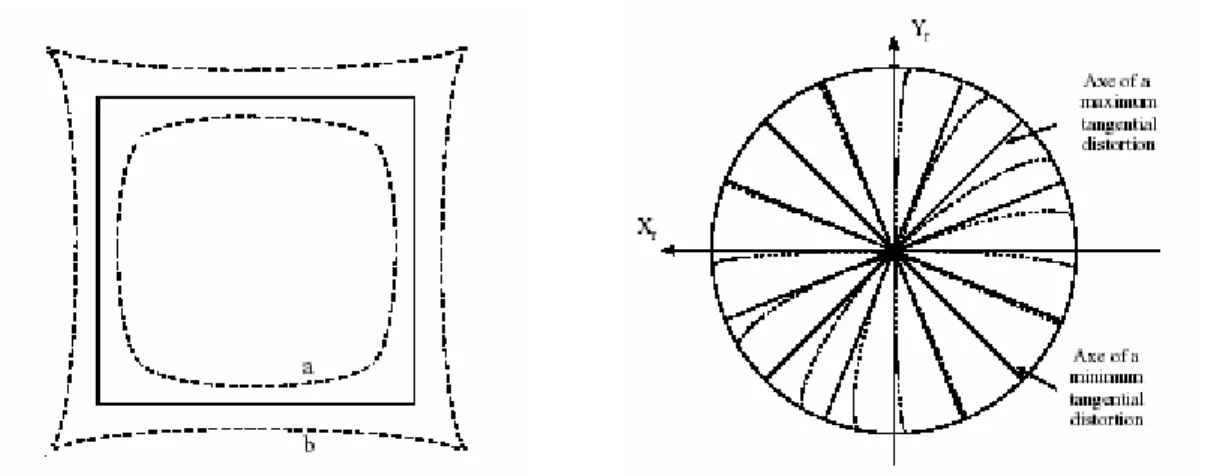
La distorsione radiale è dovuta principalmente a difetti costruttivi sulla curvatura delle lenti ed è quella più marcata, in particolare nel caso di obiettivi a corta lunghezza focale, mentre errori di allineamento tra i centri delle lenti danno un contributo sia in senso radiale che tangenziale.
C’è da dire che le telecamere che si trovano attualmente sul mercato, specialmente se non di fascia troppo economica, non richiedono spesso un modello di distorsione così generale: per questo negli algoritmi di calibrazione non si va mai oltre al 6° ordine per la distorsione radiale, e oltre al 4° per quella tangenziale (che spesso anzi non viene nemmeno considerata), ma vi sono anche casi in cui è sufficiente considerare unicamente il 2° ordine della sola distorsione radiale.
A questo proposito sottolineo che nella trattazione esposta non ho mai accennato al “fattore di obliquità” (skew coefficient) che rende conto della possibilità che gli assi u e v del piano retina non siano perfettamente ortogonali per la non perfetta forma rettangolare degli elementi del CCD: tale effetto in pratica è attualmente trascurabile data l’odierna tecnologia di costruzione dei sensori stessi, tanto che negli algoritmi di calibrazione generalmente questo coefficiente non è presente o è posto per default uguale a 0.
Risulta ovvio che l’individuazione dei parametri del modello di distorsione richiede l’acquisizione di un numero di punti tanto maggiore quanto più numerosi sono i parametri stessi che si vogliono considerare.
2.TEORIA DELLA STEREOVISIONE ATTIVA
Da notare che tutte le formule proposte si trovano spesso in letteratura anche espresse mediante le coordinate normalizzate, ovvero dividendo le coordinate precedentemente introdotte per la distanza focale f.
Riassumendo quindi il procedimento per passare dalle coordinate mondo a quelle reali (considerando la distorsione) in pixel nel piano retina abbiamo i seguenti passaggi:
1) Passaggio dal sistema di riferimento del mondo a quello della camera:
+ ⋅ = z y x w w w 33 32 31 23 22 21 13 12 11 t t t Z Y X r r r r r r r r r Z Y X ovvero w=R⋅ww+T
2) Trasformazione prospettica ideale dei punti del sistema camera nei punti immagine del piano retina della camera (coordinate ideali non distorte):
⋅ − = ⋅ − = Z Y f y Z X f x
3) Introduzione della distorsione (passaggio da coordinate ideali a reali):
4) Passaggio da coordinate immagine reali a coordinate immagine in pixel:
+ ⋅ = + ⋅ = 0 0 v k y v u k x u v d u d + ⋅ = + ⋅ = ) , ( ) , ( y x k y y y x k x x y v d x u d δ δ
2.TEORIA DELLA STEREOVISIONE ATTIVA
Da questa sintesi si può immediatamente notare come i parametri da calibrare siano quindi i 6 estrinseci del moto rigido tra sistema mondo e quello camera, e quelli intrinseci ovvero la lunghezza focale f, le coordinate del punto principale u0 e v0 e i vari parametri del modello di distorsione utilizzato.
Nelle metodologie che utilizzano per la triangolazione i punti dell’immagine di una camera e quelli corrispondenti del pattern del proiettore, risulta necessario calibrare anche il proiettore; anche per i proiettori comunque si può fare lo stesso discorso appena fatto per le telecamere: quelli di fascia non economica (come quello utilizzato da noi) hanno tra l’altro una compensazione automatica della distorsione che produce buoni risultati anche senza tener conto della distorsione del proiettore.
Se consideriamo il proiettore come una camera inversa (in pratica invece di avere la matrice di elementi fotosensibili del CCD ne abbiamo una di elementi emettitori LCD a matrice attiva) le relazioni tra i punti del piano immagine e quelli dello spazio sono le stesse; vedremo però come la calibrazione del proiettore necessiti di qualche considerazione supplementare rispetto a quella della camera.
2.2 Accenni teorici alla calibrazione
La calibrazione di una camera (o di un proiettore) consiste nel ricavarne le caratteristiche ottiche e geometriche (parametri intrinseci) e la posizione nello spazio e l’orientazione rispetto ad un sistema di riferimento assoluto (parametri estrinseci) cosicché sia possibile conoscere analiticamente il passaggio dalle coordinate mondo a quelle reali nel piano retina per qualsiasi punto.
Vi sono diverse procedure di calibrazione che possono essere suddivise in base alla metodologia utilizzata: con riferimento alle relazioni scritte nel paragrafo precedente abbiamo visto come la trasformazione prospettica possa essere espressa nel caso generale da una matrice 3 x 4:
2.TEORIA DELLA STEREOVISIONE ATTIVA 34 33 32 31 24 23 22 21 14 13 12 11 p p p p p p p p p p p p P ~ =
I 12 parametri pij non hanno un significato fisico immediato, ma abbiamo
visto come si possa anche esprimere la PPM mediante il prodotto di matrici il cui significato è invece evidente, così come è evidente il significato dei parametri che le compongono.
Infatti A[I|0] G~ 1 0 T R 0 1 0 0 0 v 0 0 u 0 P ~ 3 0 v 0 u ⋅ = ⋅ α α =
In questa forma troviamo la matrice di trasformazione divisa in due parti distinte che contengono l’una i parametri intrinseci e l’altra quelli estrinseci.
Se la procedura di calibrazione avviene individuando direttamente i parametri pij che compongono la P~ si ha a che fare con un metodo diretto,
mentre se si individuano i parametri intrinseci ed estrinseci (da cui poi si può eventualmente dedurre la P~ nella forma con i 12 parametri pij) si parla di
metodo indiretto.
Oltre a questa suddivisione operata in base ai dati in uscita dall’algoritmo di calibrazione, si può fare una distinzione di tipo matematico: si hanno quindi metodi lineari, multi-step e non lineari a seconda del numero e del grado delle equazioni che presentano.
Gli algoritmi di calibrazione infatti si basano sul fatto che i parametri incogniti in sostanza governano il modo in cui i punti della scena si proiettano nel piano retina, per cui dato un certo numero di punti di cui si conoscono le coordinate assolute è possibile ricavare i parametri incogniti sostituendo i valori delle coordinate di questi punti alle incognite nelle equazioni della proiezione prospettica e risolvendo il sistema così ottenuto.
Se il numero di punti utilizzati è quello minimo necessario dal punto di vista matematico per ottenere una soluzione, si parla allora di metodo lineare:
2.TEORIA DELLA STEREOVISIONE ATTIVA
esso offre il vantaggio di maggiore rapidità a scapito però della precisione; se si utilizza invece un metodo non lineare viene utilizzato un numero di punti maggiore a quello strettamente necessario e bisognerà minimizzare una funzione obiettivo con metodi ricorsivi (minimizzazione vincolata non lineare): a fronte di una minore velocità di calcolo si otterrà una migliore precisione.
I metodi multi-step sono in pratica un compromesso tra i primi due in quanto affrontano inizialmente il problema in modo lineare e poi affinano il risultato basandosi sui risultati così ottenuti.
E’ da notare che non sempre si vuole ricavare mediante calibrazione tutti i parametri intrinseci della telecamera: si può desiderare infatti misurare alcuni di questi separatamente (direttamente con altri metodi ottici) o in altri casi ci si può fidare dei valori forniti dal costruttore stesso.
In base a ciò e considerando anche come vari notevolmente il numero di parametri che descrivono il fenomeno della distorsione (in base al modello scelto per descrivere la distorsione stessa) si capisce come la calibrazione possa richiedere la conoscenza di un numero di punti molto variabile e possa risultare più o meno rapida.
La conoscenza dei punti viene ottenuta mediante l’utilizzo di pannelli di calibrazione di geometria nota realizzati possibilmente con grandi precisioni di lavorazione: ve ne sono di planari e di biplanari e presentano punti di calibrazione o marker in varie forme.
La scelta del marker da utilizzare in un pannello di calibrazione dipende dall’efficacia e dalla precisione che risulta avere rispetto ad un sistema di rilevamento automatico al calcolatore.
2.TEORIA DELLA STEREOVISIONE ATTIVA
Infatti la forma di un marker può influenzare sia la facilità con cui algoritmi di elaborazione delle immagini rilevano automaticamente alcuni punti caratteristici, sia l’entità di possibili errori a seguito di una non perfetta messa a fuoco del punto (o di contrasto non soddisfacente) e dell’angolo con cui viene “visto” il pannello stesso dalla camera.
Nella nostra procedura di calibrazione sono utilizzati marker costituiti dai vertici dei quadrati chiari e scuri di una scacchiera (vedi figura 2.8): questa forma garantisce infatti buona precisione anche in caso di non perfetta messa a fuoco e non presenta gli errori dovuti alla prospettiva della vista i quali affliggono invece i marker che richiedono per la loro individuazione il calcolo del baricentro di una forma geometrica.
figura 2.8 vertici dei quadrati chiari e scuri della scacchiera utilizzati come marker Da notare che la calibrazione influisce sulla precisione di tutta la procedura di ricostruzione tridimensionale e quindi i risultati dipendono pesantemente dalla bontà della calibrazione stessa: è importante quindi usare
2.TEORIA DELLA STEREOVISIONE ATTIVA
un pannello di calibrazione il più possibile piano e con quadrati dalle dimensioni costanti e precise.
Posizionando accuratamente questi pannelli rispetto alla telecamera e adottando una metodologia di misura di tipo puramente meccanico, in linea di principio sarebbe possibile trovare le corrispondenze tra il sistema di coordinate solidale al pannello e quello solidale alla telecamera; nella pratica risulta però di gran lunga più comodo ricavare le corrispondenze sfruttando le relazioni stesse della proiezione prospettica tramite immagini ottenute dalla telecamera.
L’algoritmo di calibrazione da noi utilizzato ricalca in gran parte il metodo non lineare di Tsai [19] (che rappresenta uno dei metodi più utilizzati e quindi testati fino ad oggi) che grazie allo sfruttamento di particolari vincoli si traduce in un metodo multi-step.
Nonostante il metodo da noi seguito sia uno dei metodi proposti più accurati, esso risulta anche molto efficiente, veloce e presenta un’ottima robustezza della convergenza.
L’algoritmo di Tsai, modificato rispetto alla versione originale [7] anche per l’introduzione nel modello di calibrazione di alcuni parametri intrinseci che non erano stati inizialmente considerati, fornisce i parametri necessari per un modello di telecamera di tipo generale.
La velocità del metodo deriva dal fatto che si considera il problema del calcolo dei parametri in due parti: nella prima parte (inizializzazione) si opera una stima dei parametri senza considerare la distorsione; partendo da questi valori di base nella fase successiva (ottimizzazione non lineare) si includono anche i parametri di distorsione e si ricalcolano ricorsivamente quelli calcolati nella fase precedente di inizializzazione.
Questo accorgimento consente di lavorare inoltre con uno spazio dei parametri incogniti ridotto, cosa che riduce considerevolmente i tempi di calcolo.
La notevole precisione del metodo viene ottenuta grazie all’ottimizzazione non lineare dei parametri stessi, ovvero minimizzando una funzione obiettivo chiamata anche errore di riproiezione: in pratica rappresenta la differenza tra le
2.TEORIA DELLA STEREOVISIONE ATTIVA
coordinate acquisite dal CCD e quelle predette in base a quelle note dei punti di calibrazione e ai parametri della PPM calcolati nella iterazione precedente.
L’ottimizzazione è un processo iterativo che si interrompe quando la funzione obiettivo scende al di sotto di un determinato valore, e coinvolge un gran numero di punti (per varie posizioni del pannello di calibrazione nello spazio).
Per quanto riguarda la calibrazione del proiettore abbiamo ovviamente sempre le stesse relazioni (abbiamo detto precedentemente che il proiettore può essere considerato come una inverse-camera) ma rispetto al caso della telecamera cambiano i dati di partenza: ora non abbiamo più punti di posizione nota che si proiettano nel piano immagine in punti misurabili, ma abbiamo il risultato di una proiezione di un particolare pattern prodotto dal proiettore comandato da calcolatore sul piano di calibrazione.
Ne deriva che non si ha la possibilità immediata di sostituire valori noti nelle equazioni della trasformazione prospettica: è necessario dunque sfruttare i risultati ottenuti dalla calibrazione della telecamera e utilizzare le immagini da essa ottenute per risalire alle coordinate dei punti proiettati sul piano di calibrazione.
Mediante la calibrazione della camera infatti noi otteniamo i parametri intrinseci ed intrinseci della telecamera, ovvero conosciamo come si proiettano i punti dello spazio nel piano retina della telecamera, ma conosciamo anche la posizione assunta dal piano di calibrazione rispetto alla telecamera in ogni immagine (vedi figura 2.9).
Da queste informazioni si può trovare a ritroso la posizione dei punti proiettati sul piano di calibrazione (in pratica sono le intersezioni dei raggi ottici dei punti dell’immagine della telecamera con il piano di calibrazione).
Anche in questo caso si opera un’ottimizzazione dei risultati con il rilevamento di un gran numero di punti per varie posizioni del piano di calibrazione (ovviamente devono essere le stesse posizioni utilizzate nella calibrazione della telecamera).
2.TEORIA DELLA STEREOVISIONE ATTIVA
figura 2.9 posizioni assunte dal pannello di calibrazione nelle varie immagini Si può quindi capire che la bontà della calibrazione del proiettore dipenderà inevitabilmente dalla bontà della calibrazione della telecamera; più precisamente se la calibrazione della telecamera non è precisa, sicuramente non lo sarà nemmeno quella del proiettore.
Tralasciamo la trattazione analitica della calibrazione in quanto esula dagli scopi specifici di questa tesi; per un approfondimento è possibile consultare [7], [19], [5] e [6].
La procedura di calibrazione dal punto di vista dello svolgimento pratico verrà illustrata dettagliatamente nel capitolo 5 in cui verrà esposto tutto il procedimento di ricostruzione tridimensionale, dall’acquisizione delle immagini fino all’ottenimento dei parametri di ogni acquisizione.
2.TEORIA DELLA STEREOVISIONE ATTIVA
2.3 Triangolazione e calcolo delle coordinate tridimensionali
Come è stato illustrato la proiezione prospettica è un processo geometrico che determina il passaggio da uno spazio a tre dimensioni ad uno a due dimensioni: la perdita di una coordinata è perciò una “perdita di informazione” di fatto intrinseca al processo stesso: l’informazione che viene a mancare è appunto quella della profondità della scena.
Da una singola immagine è perciò impossibile la ricostruzione di forma a ritroso, si può infatti immediatamente notare come tutti i punti che giacciono sullo stesso raggio ottico abbiano la stessa proiezione sul piano retina (ossia il processo di proiezione prospettica non è biunivoco, vedi figura 2.10).
figura 2.10 incertezza sulla profondità per una ricostruzione da una immagine
Se vogliamo ricostruire una forma tridimensionale è necessario sopperire in qualche modo a questa perdita di informazione ottenendo informazioni aggiuntive rispetto alla singola immagine.
Una possibilità è quella di avere a disposizione due immagini della stessa scena prese da due punti di vista differenti e sfruttare le relazioni tra queste due immagini per risalire alla forma della scena: questo è il cosiddetto processo di ottica inversa chiamato imaging stereoscopico o fusione binoculare.
Considerando infatti il processo di proiezione in due piani retina differenti si ha che esso risulta biunivoco: ad un punto nello spazio corrisponde infatti una
2.TEORIA DELLA STEREOVISIONE ATTIVA
sola coppia di punti nei due piani retina, e ora anche a ritroso si ha che ad una coppia di punti nei due piani retina corrisponde un solo punto nello spazio.
Il processi di fusione binoculare viene svolto praticamente in modo automatico dal cervello che dispone delle due immagini della scena (percepite dai due occhi) e, sfruttando la cosiddetta disparità delle due immagini (ovvero la differenza relativa nella posizione degli oggetti) riesce a dare la sensazione della profondità.
2.3.1 Ricostruzione tridimensionale da corrispondenza punto-punto
Analizziamo la situazione più approfonditamente dal punto di vista analitico: consideriamo la situazione in figura 2.11, dove m=(u,v) e m’=(u’,v’) sono due punti coniugati, ovvero proiezione nelle due immagini dello stesso punto dello spazio.
Conviene ora esprimere la PPM secondo una forma molto utilizzata in visione artificiale: ) p~ | P ( q q q q q q p p p p p p p p p p p p P ~ 34 24 14 T 3 T 2 T 1 34 33 32 31 24 23 22 21 14 13 12 11 = = =
2.TEORIA DELLA STEREOVISIONE ATTIVA
Possiamo dunque scrivere:
+ ⋅ + ⋅ = + ⋅ + ⋅ = 34 T 3 24 T 2 34 T 3 14 T 1 q w q q w q v q w q q w q u Ovvero: = ⋅ − + ⋅ ⋅ − = ⋅ − + ⋅ ⋅ − 0 q v q w ) q v q ( 0 q u q w ) q u q ( 34 24 T 3 2 34 14 T 3 1 Ossia: ⋅ + − ⋅ + − = ⋅ ⋅ − ⋅ − 34 24 34 14 T 3 2 T 3 1 q v q q u q w ) q v q ( ) q u q (
Riscrivendo tutte le precedenti relazioni anche per m’ si ottiene:
⋅ + − ⋅ + − ⋅ + − ⋅ + − = ⋅ ⋅ − ⋅ − ⋅ − ⋅ − 34 24 34 14 34 24 34 14 T 3 2 T 3 1 T 3 2 T 3 1 ' q ' v ' q ' q ' u ' q q v q q u q w ) ' q ' v ' q ( ) ' q ' u ' q ( ) q v q ( ) q u q (
Questo è un sistema lineare sovradimensionato e quindi può essere risolto con l’utilizzo della pseudoinversa: infatti, usando le coordinate omogenee, la PPM è lineare ma essendo 4x3 non è invertibile.
Abbiamo dunque A⋅w =b dove A= ⋅ − ⋅ − ⋅ − ⋅ − T 3 2 T 3 1 T 3 2 T 3 1 ) ' q ' v ' q ( ) ' q ' u ' q ( ) q v q ( ) q u q ( e b= ⋅ + − ⋅ + − ⋅ + − ⋅ + − 34 24 34 14 34 24 34 14 ' q ' v ' q ' q ' u ' q q v q q u q si ha allora che w=A+⋅b (2.8)
2.TEORIA DELLA STEREOVISIONE ATTIVA
dove la pseudoinversa è data da A+ =(AT ⋅A)−1⋅AT
La 2.8 ci mostra che se si dispone delle coordinate di due punti coniugati m e m’ e i parametri di calibrazione (ovvero si conoscono A+ e b) è possibile risalire alle coordinate del punto dello spazio w le cui proiezioni sono appunto tali punti coniugati; il problema centrale della visione stereoscopica è quindi il disporre di queste coppie coniugate (il cosiddetto “calcolo delle corrispondenze"), ovvero dato un punto della prima immagine è fondamentale sapere con esattezza qual è il coniugato della seconda.
Il cervello umano riesce egregiamente a risolvere questo problema in quanto sfrutta automaticamente moltissime informazioni supplementari, attivando tutta una serie di processi connessi con gli stimoli visivi, attingendo inoltre dall’esperienza, e inoltre non deve fornire misure esatte ma dare solo la “sensazione” della profondità.
In un sistema di visione stereoscopica invece, dove è richiesta una vera e propria ricostruzione tridimensionale, è necessario adottare degli strumenti o sfruttare dei vincoli di vario tipo per risolvere efficacemente il problema delle corrispondenze.
2.3.2 Ricostruzione tridimensionale da corrispondenza punto-retta
Non è detto che per poter risalire alla posizione di un punto nello spazio si debba necessariamente partire da due punti coniugati: nel caso si disponga di un proiettore e di una telecamera la ricostruzione può anche essere effettuata in un modo leggermente diverso.
In pratica si sfruttano i piani di luce prodotti dal proiettore i quali possono essere associati ai punti dell’immagine della camera per mezzo di alcune tecniche di codifica come ad esempio quella utilizzata da noi (gray-code).
Per ottenere le coordinate di un punto nello spazio basta intersecare il raggio ottico relativo all’immagine del punto stesso nella camera con il piano di
2.TEORIA DELLA STEREOVISIONE ATTIVA
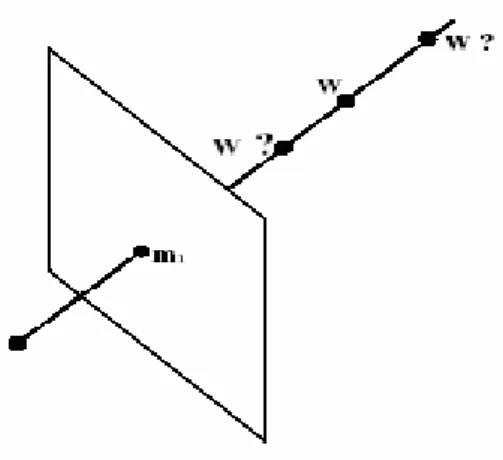
luce del proiettore che passa per il punto: si veda la figura 2.12 che illustra tale procedimento.
figura 2.12 ottenimento del punto 3D da una corrispondenza linea-punto
Il punto nello spazio è dato quindi dall’intersezione di un raggio ottico (che nella camera si traduce in un punto) e da un piano di luce (che nel proiettore risulta una retta): è possibile quindi ricostruire tridimensionalmente un oggetto anche da una corrispondenza punto-retta; questa metodologia di ricostruzione 3D rientra sempre nella casistica della triangolazione attiva (si usa il termine attivo in quanto si sfrutta la luce emessa dal proiettore).
Vediamo ora il lato analitico di questo procedimento; dato che abbiamo a che fare con camera e proiettore (e non con due camere), nelle relazioni che qui seguiranno indicheremo con il pedice “c” tutte le grandezze riferite al sistema della camera e con “p” tutte quelle riferite a quello del proiettore.
Abbiamo visto che la trasformazione rigida per passare dal sistema di riferimento della camera a quello del proiettore è data da una matrice rotazione R e da un vettore traslazione T ; un punto w di coordinate wc=(Xc,Yc,Zc)T nel
sistema di riferimento della camera risulta quindi avere in quello del proiettore le coordinate wp=Rwc+T.
2.TEORIA DELLA STEREOVISIONE ATTIVA
In termini di coordinate normalizzate la relazione prospettica si scrive:
per la camera c c c c c c T c c c w Z 1 1 , Z Y , Z X ) 1 , y , x ( m~ = = = per il proiettore p p p p p p T p p p w Z 1 1 , Z Y , Z X ) 1 , y , x ( m~ = = =
Ricordiamo che il proiettore è stato modellato come una telecamera inversa (potendo proiettare però solo piani di luce verticali in realtà l’equazione relativa alla ypnon risulta significativa).
Sostituendo le relazioni prospettiche relative ai due sistemi di coordinate nella relazione di trasformazione tra gli stessi si ottengono tre equazioni:
x c T 1 c p px Z r m~ t Z − = y c T 2 c p py Z r m~ t Z − = z c T 3 c p Z r m~ t Z − =
Sostituendo nella prima equazione la zp ricavata nella prima si ottiene,
dopo alcuni passaggi:
c T 1 T 3 p p z x c m~ ) r r x ( x t t Z − − =
Dal punto di vista teorico dunque è possibile calcolare le coordinate di un punto della scena partendo da una corrispondenza punto-punto in un sistema camera-camera o proiettore-camera, oppure da una corrispondenza linea-punto nel caso di proiettore-camera; esporremo ora alcune metodologie nell’ambito delle tecniche a luce codificata (tra le quali anche quelle utilizzate nella nostra indagine) con le quali è possibile ottenere questi due tipi di corrispondenze.
2.TEORIA DELLA STEREOVISIONE ATTIVA
2.4 Coded Light Approach: codifica Gray-Code
Quando abbiamo classificato i sistemi di ricostruzione di forma abbiamo visto come una particolare categoria dei sistemi ottici attivi sia costituita dalle tecniche a luce codificata (Coded Light Approach) in cui si fa in modo che ad ogni pixel del proiettore sia associato un codice; poiché l’oggetto da scansionare è investito dai pattern del proiettore, il codice si “trasferisce” all’oggetto stesso e quindi ai pixel delle immagini acquisite cosicché risulta possibile risolvere il problema della corrispondenza.
Nella quasi totalità delle tecniche a luce codificata ogni codice non viene assegnato a singoli pixel, ma a strisce rettilinee di pixel del proiettore, che proiettate sull’oggetto si deformano e nelle camere vengono visualizzate come linee curve e talvolta discontinue.
La codifica viene ottenuta mediante opportune sequenze spazio-temporali di pattern, utilizzando il colore, i livelli di grigio o semplicemente il bianco e nero. Per risolvere il problema della corrispondenza noi abbiamo utilizzato la codifica Gray Code che rispetto ad altre soluzioni ( [4], [13] e [14] )attualmente studiate ed utilizzate richiede un numero maggiore di pattern proiettati e quindi un tempo di acquisizione maggiore, ma risulta molto affidabile e robusto e ad ogni modo risulta comunque più rapido di un sistema che utilizza laser (in pratica una sequenza di n pattern con la tecnica Gray Code corrisponde a 2n acquisizioni con la metodologia del piano laser).
La codifica Gray Code consiste nella proiezione di una particolare sequenza di pattern luminosi sull’oggetto da scansionare: ogni frame di questa sequenza presenta strisce bianche e nere alternate opportunamente disposte la cui larghezza è pari alla metà di quella nel frame precedente.
In base al numero n di frame proiettati si possono differenziare 2n strisce
(larghe come le strisce dell’ultimo pattern proiettato): ogni striscia risulta avere associato un codice binario a n bit il la cui cifra n-esima è 1 o 0 a seconda che nel frame n-esimo tale striscia risulti bianca o nera (vedi figura 2.13).
2.TEORIA DELLA STEREOVISIONE ATTIVA
figura 2.13 principio di funzionamento della codifica Gray-Code
Chiaramente è inutile adoperare un codice binario con un numero di bit n superiore a quello minimo necessario per poter distinguere un numero di strisce pari al numero di pixel del proiettore in direzione ortogonale alle strisce: in poche parole se la risoluzione del proiettore consente di proiettare un certo numero di strisce, è inutile usare un codice in grado di distinguerne un numero maggiore.
Noi abbiamo utilizzato un codice a 9 bit con cui è possibile distinguere 29=512 linee che sono la metà esatta della risoluzione orizzontale del proiettore: nella pratica infatti utilizzare strisce larghe solo un pixel comporta problemi di scarsa definizione delle proiezioni delle stesse sulle superfici dell’oggetto.
Per una codifica a 9 bit bisogna proiettare una sequenza di 9 pattern, in realtà le sequenze utilizzate da noi consistevano in 10 pattern perché il programma di acquisizione utilizzato era impostato per utilizzare un codice a 10 bit; ad ogni modo in sede di elaborazione delle immagini è possibile considerare il numero di immagini voluto (in pratica è possibile usare un codice a n di bit qualsiasi, ma inferiore a 10).
2.TEORIA DELLA STEREOVISIONE ATTIVA
Dato che le superfici dell’oggetto sono investite da questa sequenza di strisce bianche e nere, anche ogni pixel dell’immagine dell’oggetto presenterà una certa sequenza di illuminazione (vedi figura 2.14), dalla quale si può ricavare un codice: a questo punto siamo in grado di stabilire per ogni punto dell’immagine dell’oggetto quale sia la striscia corrispondente nel proiettore;
figura 2.14 Cilindro investito dalla sequenza proiettata di 10 pattern
Si deve comunque tenere presente il fatto che, mentre il codice delle strisce del proiettore è perfettamente noto (infatti lo imponiamo noi e comunque nel monitor del calcolatore che controlla il proiettore sono visualizzate righe perfettamente bianche e nere), nel caso dei pixel della camera si possono avere notevoli ambiguità.
Il colore e la riflettività non uniforme dell’oggetto, la diversa inclinazione e la mutua illuminazione delle sue superfici, la non netta separazione tra le zone illuminate e quelle non illuminate, i possibili problemi di scarso contrasto e di saturazione delle immagini, la risoluzione differente e limitata e della camera e del proiettore e la conseguente pixelizzazione fanno sì che nella realtà i punti
2.TEORIA DELLA STEREOVISIONE ATTIVA
dell’immagine acquisita dalla camera siano di tutta una gamma di livelli di grigio intermedi tra il bianco e il nero e quindi il codice non è individuabile in modo così semplice come avviene per il proiettore (vedi figura 2.15).
figura 2.15 separazione tra zona chiara e scura
Un accorgimento utilizzato per migliorare la situazione consiste nel pitturare l’oggetto in modo uniforme con una vernice bianca, ovviamente opaca per evitare o limitare l’insorgere della saturazione nelle zone in cui si hanno i riflessi della luce; ad ogni modo per poter ottenere un codice binario è necessario comunque operare una binarizzazione dell’immagine.
La binarizzazione consiste nell’assegnare il valore 1 o 0 nel caso il livello di grigio sia rispettivamente inferiore o superiore ad un valore di soglia scelto opportunamente: tale procedimento può essere applicato direttamente alle immagini come tool grafico che trasforma un immagine a livelli di grigio in una immagine in bianco e nero (figura 2.16)
2.TEORIA DELLA STEREOVISIONE ATTIVA
Da notare che in Matlab le immagini non sono altro che matrici dal numero di righe pari alla risoluzione verticale e di colonne pari a quella orizzontale: si può quindi comprendere come sia semplice operare operazioni sulle immagini (per esempio una binarizzazione) disponendo della matrice ad esse associata.
Ad ogni modo, per limitare gli effetti di possibili errori nello stabilire il codice binario dei punti dell’immagine, i pattern proiettati vengono scelti in modo che ogni striscia abbia un codice che differisca da quello delle due strisce adiacenti di solo un bit, cosicché nell’eventualità di un’interpretazione non corretta nella binarizzazione di un pixel in un frame si otterrà l’errore minimo tra tutti quelli possibili .
Un altro espediente per migliorare le prestazioni della ricostruzione è quello di utilizzare una maschera (vedi figura 2.17) definibile dall’utente che esclude i punti non di interesse dal calcolo delle coordinate tridimensionali; questa maschera di solito prevede anche l’impostazione di un valore soglia del livello di grigio minimo che consente di escludere dalla ricostruzione anche quei punti che stanno nelle zone d’ombra; nel nostro caso però, dovendo ricostruire esclusivamente piani e cilindri (che non hanno quindi rilievi) non c’è mai stato bisogno di utilizzare questa soglia.
figura 2.17 effetto dell’applicazione della maschera
Nonostante questi accorgimenti, rimane un problema fondamentale per poter ottenere una precisione accettabile: nella pratica non si ha a che fare con piani, punti e raggi ottici ideali (cioè di dimensione infinitesima) così come nella
2.TEORIA DELLA STEREOVISIONE ATTIVA
teoria: un pixel del proiettore illumina infatti una zona del corpo da scansionare la cui proiezione acquisita dalla camera risulta in generale di dimensione maggiore di un pixel (tanto maggiore quanto è lontano il proiettore e vicina la telecamera).
Risulta quindi delicato il problema di eseguire le intersezioni tra raggi ottici e piani proiettati, date le dimensioni non infinitesime degli stessi: a questo proposito solitamente si vanno ad individuare mediante opportuni algoritmi linee e punti baricentrali che vengono poi utilizzati nei calcoli delle intersezioni e quindi nel processo di ricostruzione tridimensionale.
Nei procedimenti di ricostruzione da noi analizzati si utilizza invece la soluzione di codificare e di utilizzare per le intersezioni le zone di separazione tra le strisce: la dimensione della separazione infatti è molto minore di quella delle strisce , per cui ci si avvicina maggiormente al caso ideale.
Nella realtà però, come si è detto in precedenza, tale separazione non è facilmente individuabile nell’immagine acquisita dalla camera (non certo come quella del pattern del proiettore) dato che il passaggio tra chiaro e scuro avviene con un gradiente non molto elevato.
E’ stato utilizzato quindi un espediente di elaborazione delle immagini proposto in [41] utile per migliorare la binarizzazione e per ottenere risoluzioni al sub-pixel: invece di proiettare una sequenza di n immagini (per un codice binario a n bit) se ne proiettano 2n (nel nostro caso risultano quindi 20) per cui ad ogni immagine (dispari) ne segue una (pari) che risulta l’inversa di quella precedente (ovvero in cui sono invertiti i livelli di grigio).
Andando ad eseguire la differenza tra le matrici associate ad ogni coppia di immagini si ottiene una nuova matrice a cui si può associare una immagine in cui la definizione e il contrasto risultano maggiori (in pratica il gradiente del passaggio tra scuro e chiaro raddoppia) per cui il confine tra zona illuminata e zona non illuminata risulta più facilmente individuabile (vedi figure 2.18 e 2.19): da queste n immagini si procede alla binarizzazione e alla codifica.
2.TEORIA DELLA STEREOVISIONE ATTIVA
figura 2.18 Confronto tra una immagine ottenuta come differenza e quella originale (nella stessa scala di grigio)
figura 2.19 Dettaglio della zona di separazione delle immagini precedenti
In pratica invece di considerare come passaggio tra zona chiara e scura il punto dove la spline dei livelli di grigio dell’immagine ha il maggior gradiente, si trova il punto (coordinata in pixel ma numero reale) in cui si ha l’intersezione dei livelli di grigio dell’immagine negativa e di quella positiva (figura 2.20).
2.TEORIA DELLA STEREOVISIONE ATTIVA
Questo espediente è una delle varie tecniche esistenti chiamate nel linguaggio della visione artificiale “sub-pixel algorithms” con cui è possibile lavorare con coordinate rappresentate da numeri reali come se si avesse una risoluzione che supera il limite fisico del pixel, e questo è importantissimo per ottenere le precisioni desiderate.
Nel caso le strisce proiettate siano verticali, e quindi le transizioni tra chiaro e scuro vengono cercate orizzontalmente riga per riga, otterremmo una situazione come quella di figura 2.21 (si tratta di una riga di pixel del CCD): sono state calcolate le coordinate in pixel (che risultano numeri reali) dove avvengono le transizioni; una situazione simile si avrà anche per tutte le altre righe del CCD: il computer assegna il codice a tutte queste transizioni e le memorizza in una tabella.
In pratica per la triangolazione verranno utilizzati i punti infinitesimi sulla transizione a metà del pixel che vengono triangolati con le linee infinitesime di separazione delle strisce bianche e nere dei pattern del proiettore.
figura 2.21 individuazione delle zone chiare e scure con risoluzione al sub-pixel
A questo punto ogni striscia del proiettore ed ogni pixel della camera hanno un codice associato per mezzo del quale si trasformano le sequenze di immagini del proiettore e di quelle (binarizzate) della camera in due immagini a colori (una per il proiettore e una per la camera) in cui ogni colore corrisponde ad un valore del codice binario (nel nostro caso ogni pixel ha un valore tra 0 e 511 dato che il codice è a 9 bit).
In questo modo le informazioni per la corrispondenza sono racchiuse interamente in una matrice per il proiettore e una per la camera: a questo punto per avere una forma ancora più comoda si passa ad una matrice in cui i valori corrispondano più direttamente alla coordinata significativa del proiettore.
2.TEORIA DELLA STEREOVISIONE ATTIVA
Il proiettore infatti è proietta 512 linee per cui ogni pixel del proiettore avrà un valore variabile tra 0 (margine sinistro) e 511 (margine destro); in base alla corrispondenza già individuata si può assegnare anche per i punti dell’immagine della camera un valore tra 0 e 511 che darà un’indicazione più immediata sulla corrispondenza con i punti del proiettore.
Tutto questo serve solo per una maggiore comodità riguardo alla corrispondenza: ricordiamo però che nell’effettivo processo di ricostruzione tridimensionale (ovvero nel calcolo delle intersezioni tra piani proiettati e raggi ottici) si utilizzano i punti infinitesimi e le linee infinitesime di cui si è parlato.
La tecnica di codifica Gray Code appena illustrata è in grado quindi di consentire la risoluzione del problema della corrispondenza linea-punto che sarebbe di per sé sufficiente a consentire la ricostruzione tridimensionale.
Nella nostra analisi abbiamo considerato questo metodo di ricostruzione in due varianti: in questa università infatti è stato messo a punto un metodo per calibrare il proiettore tenendo conto anche della distorsione dello stesso; volendo avere una conferma della bontà del lavoro effettuato, è stato utilizzato il metodo di ricostruzione che utilizza proiettore e camera per risolvere il problema della corrispondenza, eseguendo la calibrazione del proiettore sia tenendo conto della distorsione (verrà chiamato tipo di ricostruzione “mono con distorsione”), sia eseguendo la calibrazione senza andare a considerare la distorsione (tipo di ricostruzione “mono senza distorsione”).
Le due varianti sono state in pratica considerate come due tipi di ricostruzione diversi, anche se in realtà il procedimento è praticamente identico e differisce solo nella fase di calibrazione del proiettore al momento del calcolo dei parametri intrinseci.
Accanto a questi due metodi, ne è stato considerato un altro (che chiameremo “stereo”) che utilizza due telecamere per risolvere il problema della corrispondenza ma che in pratica utilizza inizialmente la stessa procedura degli altri due, ma una volta ottenuta la codifica dei punti mediante la codifica Gray-Code, invece di associare i punti alle strisce verticali del proiettore, riesegue
2.TEORIA DELLA STEREOVISIONE ATTIVA
un’altra codifica Gray-Code in base ad un’ulteriore sequenza di pattern in cui stavolta le strisce sono ortogonali rispetto a prima.
In tal modo riusciamo ad assegnare un codice diverso per ogni punto (mentre nella tecnica precedente tutti i punti corrispondenti ad una stessa striscia hanno lo stesso codice); questa doppia codifica viene fatta per entrambe le immagini consentendo quindi di trovare la corrispondenza punto-punto tra le due viste.
In pratica il tipo di ricostruzione stereo utilizza una doppia codifica che non è altro che l’applicazione della tecnica del Gray Code sia in senso verticale che in quello orizzontale: i pattern proiettati sono quindi 40 (20 con strisce orizzontali e 20 verticali, vedi figura 2.22) per ogni camera di cui 36 utilizzati effettivamente dato che il codice è a 9 bit.
figura 2.22 cilindro investito dalla sequenza dei 40 pattern (20 con strisce orizzontali e 20 verticali)
Il metodo della doppia codifica non è l’unico che consente di sfruttare una corrispondenza punto-punto: abbiamo per esempio quello che, dopo aver ottenuto una corrispondenza linea-punto mediante la codifica gray-Code, sfrutta
2.TEORIA DELLA STEREOVISIONE ATTIVA
il cosiddetto “vincolo epipolare” [35] (una particolare relazione geometrica che devono soddisfare i punti corrispondenti nei piani retina: infatti questi punti e i centri ottici delle due camere devono stare in un piano chiamato piano epipolare, vedi figura 2.23); tale metodo è attualmente in fase di implementazione e messa a punto proprio nella nostra università.