CAPITOLO 3
IL SISTEMA OFDM CON CODIFICA
TURBO
Introduzione
Nel capitolo precedente siamo riusciti a stimare una curva di capacità del canale OFDM comprensivo dell’amplificatore di potenza di tipo TWT, avendo ammesso che le probabilità a priori che massimizzano l’informazione mutua sono quelle equiprobabili. Adesso ci poniamo il problema di individuare una tecnica di codifica in grado di raggiungere questo massimo trasferimento informativo.
3.1
Introduzione ai Turbo Codici
Ad oggi, tra i metodi di codifica usati in pratica, i più efficienti dal punto di vista della protezione dagli errori sono quelli della famiglia dei cosiddetti codici Turbo. Essi sono stati presentati per la prima volta nel 1993 dai francesi Berrou e Glavieux, e sono stati successivamente studiati e perfezionati in tutto il mondo. I codici turbo sono quanto si sia mai visto di più vicino al concetto di codice casuale con parole lunghe adoperato da Shannon per la dimostrazione del secondo teorema della codifica, e questo ne giustifica le buone prestazioni in assoluto. Naturalmente, anche nel passato ci sono stati altri tentativi di giungere vicino alla curva di capacità di canale con l’uso di codici casuali con parole lunghe, ma essi si sono sempre scontrati con insormontabili difficoltà di decodifica, nel senso che i decodificatori per simili codici risultavano di complessità proibitiva (crescente esponenzialmente con la lunghezza delle parole). La chiave di volta per la risoluzione del problema è stata, per i codici turbo, l’invenzione di un algoritmo di decodifica iterativa (“turbo”) che ha appunto reso possibile, con complessità ragionevole, la decodifica di particolari codici “casuali”.
Il codificatore turbo è un codificatore a blocco, cioè riceve in ingresso un blocco di bit di sorgente e ne restituisce uno più grande comprensivo anche dei bit di parità introdotti dal codificatore. Il suo rate sarà pertanto:
k r
n
= (3.1)
dove n e k rappresentano rispettivamente i bit in uscita ed in ingresso.
Affinché il codice porti un miglioramento significativo alle prestazioni del sistema è necessario che n e k siano molto grandi, dell’ordine delle decine di migliaia. Il codificatore turbo ha una struttura di principio molto semplice, basata su due codificatori convoluzionali in forma ricorsiva sistematica (RSC, Recursive Systematic Convolutional), chiamati codificatori costituenti. Facendo un esempio in cui il tasso di codifica dei due codici costituenti è r=1/2, per ogni bit di sorgente ogni codificatore produce una replica dello stesso bit (codificatore sistematico) seguita da un bit in più specificamente prodotto dal codificatore stesso e detto di parità. Inoltre, gli schemi del codificatore sono con reazione, cioè ricorsivi, contrariamente allo schema dei codificatori convoluzionali standard più usati in pratica, che sono del tipo “in avanti” (feedforward) senza reazione. Un esempio di codificatore RSC è indicato in figura 3.1. La caratterizzazione del codificatore avviene mediante i polinomi della matrice di generazione. Per un codificatore RSC, quest’ultima ha la forma generale
2 1 ( ) ( ) 1, ( ) g D g D g D = (3.2)
Fig 3.1 Schema di un codificatore convoluzionale ricorsivo sistematico con rate r=1/2.
ed è da intendersi come un operatore che agisce sulla stringa di bit di sorgente per fornire la stringa di bit codificati. In particolare, il primo termine uguale a 1 indica la sistematicità (si crea cioè la replica inalterata del bit d’ingresso), mentre la variabile D usata nel secondo termine è l’operatore di ritardo unitario sulle sequenze di ingresso/uscita. Il rapporto g D2( ) /g D1( ) è allora una sorta di “funzione di trasferimento” uscita/ingresso espressa come rapporto di polinomi nella variabile D.
Indicando con S[n] i bit di sorgente e con P[n] i bit di parità, il rapporto di polinomi nella matrice di generazione va allora interpretato nel senso che
1( )( [ ]) 2( )( [ ])
g D P n =g D S n (3.3)
Nel codificatore turbo, i due RSC possono essere differenti o anche uguali.
Esistono due tipi di codificatori turbo: il codificatore turbo parallelo PCCC (Parallel Concatenated Convolutional Code) e quello seriale SCCC (Serial Concatenated Convolutional Code).
Si differenziano tra loro per come sono disposti i due codificatori RSC, come si può notare nelle figure 3.2 e 3.3.
(a)
(b)
Fig 3.2 Esempio di Codificatore (a) e Decodificatore (b) Turbo PCCC
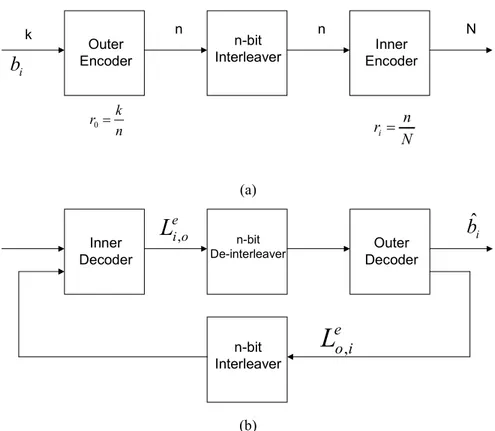
Outer Encoder
n-bit
Interleaver EncoderInner k n k r =0 n n N N n ri= i
b
(a) Inner Decoder n-bitDe-interleaver DecoderOuter
n-bit Interleaver e o i
L
, e i oL
, ibˆ
(b)Come si può osservare dalle figure 3.2 e 3.3, il nome “turbo” trae origine dallo schema di decodifica del codice. Esso consta, infatti, di due stadi, ciascuno sostanzialmente relativo ad ognuno dei due codificatori RSC. La peculiarità sta nel fatto che la decodifica è iterativa, cioè il decodificatore effettua più volte la stessa elaborazione sul segnale in uscita dal canale riportando però all’indietro ogni volta un’informazione relativa all’affidabilità, detta anche estrinseca, del bit di sorgente da decidere, affidabilità che di volta in volta tende ad aumentare. Questo “ripassare” la stessa informazione più volte viene assimilata al moto di rotazione vorticosa del turbocompressore di un motore a scoppio.
L’informazione estrinseca è di carattere continuo (soft), e per capirne la natura è necessario capire come sono costituiti i due stadi di decodifica. Essi sono basati sull’algoritmo di decodifica a massima probabilità a-posteriori di Bahl-Cocke-Jelinek-Raviv (BCJR) sviluppato negli anni ’70 e mai utilizzato in pratica fino all’avvento dei codici turbo. Questo algoritmo opera su di un blocco di valori soft (nella versione originale le uscite rumorose del canale) per fornire in uscita un blocco di N valori continui sui quali è possibile prendere una decisione finale a soglia. La decisione presa in questa maniera massimizza la probabilità di una corretta decisione su ogni singolo bit condizionata all’aver osservato tutto il blocco di valori soft dato in ingresso all’algoritmo, cioè segue un criterio di massima probabilità a-posteriori (MAP). La particolarità dell’algoritmo BCJR è che opera in maniera ricorsiva incrociata, con due ricorsioni che procedono in avanti a partire dal primo simbolo soft del blocco, come un algoritmo di decodifica tradizionale, ma anche a ritroso, cioè a partire dall’ultimo simbolo soft del blocco verso il primo. L’algoritmo, al contrario della decodifica di Viterbi non è causale e richiede, per effettuare una decisione ottima, anche l’osservazione di simboli soft futuri all’interno della finestra (blocco) di osservazione.
Questi valori continui sono i cosiddetti rapporti di log-probabilità a posteriori (LAPP), cioè il logaritmo del rapporto tra le probabilità che ogni singolo bit assuma il valore rispettivamente +1 o –1 (con modulazione antipodale), conseguentemente (cioè condizionatamente) all’osservazione del blocco di segnale dato. Se indichiamo con C il vettore dei campioni “soft” di segnale all’uscita del canale con disturbo prodotti da un singolo blocco di N bit di sorgente, il rapporto di log-probabilità a posteriori è
Pr{ [ ] 1| } ( [ ]) log Pr{ [ ] 0 | } S n C L S n S n C = = = (3.4)
Questo rapporto costituisce l’informazione di affidabilità prodotta dal decodificatore BCJR e necessaria al decoder turbo. Essa permette anche di prendere decisioni a soglia, perché è >0 quando il valore più probabile a posteriori è +1, viceversa se il valore più probabile è –1. Quanto maggiore è in modulo questa quantità, tanto maggiore è la probabilità del simbolo deciso rispetto all’altra, e quindi tanto maggiore è “l’affidabilità” della decisione.
Ognuno dei due decodificatori nello schema del decoder turbo ha tre ingressi, e cioè il segnale ricevuto e la parità rispettiva, come un qualunque decodificatore standard dei codici costituenti, più l’informazione estrinseca di affidabilità proveniente dall’altro decodificatore. È questa informazione addizionale che permette di “migliorare” ad ogni iterazione l’affidabilità delle decisioni, cioè diminuire ad ogni iterazione la probabilità di errore. Riscriviamo il rapporto di probabilità a posteriori come segue, sfruttando le regole di Bayes:
Pr{ [ ] 1| } Pr{ | [ ] 1} Pr{ [ ] 1}
( [ ]) log log log
Pr{ [ ] 0 | } Pr{ | [ ] 0} Pr{ [ ] 0} S n C C S n S n L S n S n C C S n S n = = = = = + = = = (3.5)
Normalmente, in assenza di ulteriori informazioni, il secondo termine di informazione cosiddetta a priori è nullo, perché i bit di sorgente sono equiprobabili. Ma se è già stata in qualche modo effettuata una operazione preliminare di decodifica “tentativa”, dopo questa operazione le probabilità dei due valori non sono più uguali e quindi anche L S n( [ ]) può essere ricalcolato iterativamente tenendo conto di questa nuova informazione estrinseca . Il gioco dei decodificatori de-permutatori è poi fatto in modo che il decoder n. 2 (D2 in figura 3.2 oppure outer decoder in figura 3.3) fornisce al decoder n. 1 (D1 in figura 3.2 oppure inner decoder in figura 3.3) un’informazione estrinseca calcolata sulla base di una quantità, cioè i bit di parità P n , cui il decoder n.1 non ha accesso e 2[ ] viceversa. Al termine di ogni iterazione l’affidabilità nel messaggio ricostruito tende a migliorare.
Dopo aver spiegato il principio di funzionamento dei turbo codici, nel prossimo paragrafo illustreremo quello utilizzato per le nostre simulazioni.
3.2
Specifiche del Turbo Codice
In questo paragrafo introdurremo il turbo codice utilizzato nell’ambito delle nostre simulazioni, descrivendo brevemente le sue caratteristiche.
Il turbo codice da noi utilizzato è di tipo SCCC (figura 3.4), però, come si può osservare, strutturato secondo uno schema innovativo rispetto al modello classico di figura 3.3.
Esso è costituito da due codificatori RSC (outer ed inner) a 4 stati, rate ½ del tipo schematizzato in figura 3.5.
Fig. 3.4 Schema a blocchi del codificatore turbo SCCC
Fig. 3.5 Codificatore convoluzionale RSC
I simboli in uscita dall’outer encoder, come si può vedere in figura 3.4, vengono raggruppati a blocchi di quattro e, tramite un’operazione di puncturing, vengono riadattati ad un rate pari a 2/3. Per ottenere il rate complessivo desiderato, si effettua un puncturing sull’uscita dell’inner encoder.
Dopo l’inner encoder vi sono due registri che operano algoritmi di puncturing. Il registro superiore contiene gli N + 2 bit sistematici, i quali coincidono con la parola di codice in uscita dall’outer permutata dall’interleaver, con in più due bit che riportano l’inner encoder nello stato iniziale. Il registro sottostante invece contiene gli N + 2 bit di parità.
Per questi due registri sono utilizzati due algoritmi di puncturing diversi. Per il registro sovrastante si opera un puncturing sugli N bit sistematici (esclusi pertanto i due bit finali) secondo un modello periodico di periodo 200 passi del traliccio, che corrispondono nel nostro caso a 300 bit codificati dall’outer encoder. Questo modello di puncturing è progettato in modo da massimizzare la distanza libera [6] dell’outer encoder.
3.3
Descrizione del sistema OFDM-Turbo Codice
Il simulatore che abbiamo utilizzato è sostanzialmente quello mostrato nel capitolo precedente (figura 2.4). A tale simulatore abbiamo aggiunto un turbo codice che genera una sequenza dei bit pseudocasuali, mappandoli in seguito nella costellazione 16-QAM codificata secondo Gray che riportiamo in figura 3.6:
-4 -2 0 2 4 Im -4 -2 0 2 4 Re 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111
Fig. 3.6 Costellazione 16-QAM con codifica di Gray
Il turbo codice utilizzato nel simulatore raffigurato nella figura 3.7 è quello descritto nel paragrafo precedente. Come già spiegato, esso è un turbo codice
seriale SCCC con rate variabile che genera in uscita blocchi di 8100 simboli 16-QAM.
I simboli così generati vengono mandati in ingresso al sistema OFDM che, per ragioni pratiche, spezzetta gli 8100 simboli in dieci blocchi OFDM, ciascuno contenente 810 simboli informativi e Nv=214 portanti virtuali, per un totale di
1024
N = portanti per ogni simbolo OFDM. In questo modo si lascia circa una porzione del 20% di spettro alle portanti virtuali per poter controbattere la sagomatura del filtro di cui ci siamo occupati nel paragrafo 2.2.2.
Il segnale ricevuto viene successivamente ricostruito e riallineato per poi essere mandato in ingresso ad un soft mapper. Successivamente l’uscita da tale de-mapper viene mandata in ingresso al decoder, il quale poi opererà le decisioni secondo la decodifica iterativa descritta nel paragrafo precedente. I bit così decisi saranno confrontati con quelli effettivamente trasmessi per fare una stima della BER del sistema.
L’informazione mutua, come al solito, verrà calcolata tra l’ingresso del modulatore OFDM, e l’uscita dell’AGC, perciò senza tener conto il turbo codice.
Il rumore verrà calibrato sulla base dell’Es/ N0 secondo la (2.21) che riportiamo per comodità di seguito:
0 2 / s sa w s P N E N
σ
= ⋅ ⋅ (3.6)Il modello di amplificatore di potenza è lo stesso utilizzato nel capitolo precedente [14], il quale ha le risposte AM/AM e AM/PM modellate secondo:
2 9945 . 0 1 9638 . 1 ) ( r r r A + = (3.7) 2 2 8168 . 2 1 5293 . 2 ) ( r r r + =
φ
(3.8) Dove r= x n[ ]
.Nel prossimo paragrafo illustreremo i risultati ottenuti mediante l’utilizzo di questo simulatore.
3.4
Risultati delle simulazioni
Per le nostre simulazioni, come già spiegato nel paragrafo precedente, abbiamo utilizzato un turbo codice a blocchi con rate variabile che in uscita fornisce 8100 simboli, in questo caso abbiamo utilizzato simboli 16-QAM. Questo blocco viene suddiviso in dieci sottoblocchi da 810 simboli, a cui vanno aggiunte 214 portanti virtuali per ottenere le N =1024 sottoportanti del simbolo OFDM.
Il fattore di oversampling utilizzato è Nsa =10 ed il filtro sagomatore utilizzato è RRCR(0.2).
A titolo d’esempio in figura 3.8 riportiamo l’andamento della BER del turbo codice con rate pari a 0.726 su canale ideale, ossia in assenza di non linearità introdotte dal TWT. 10-5 10-4 10-3 10-2 10-1 B E R 10 9 8 7 6 Es/No (dB)
Fig. 3.8 Andamento della BER ideale del Turbo Codice con rate=0.726
Come già accennato nel §2.4.2 abbiamo utilizzato gli andamenti dell’informazione mutua riportati nelle figure 2.26 (a)-(b)-(c) per scegliere dei punti di funzionamento del nostro simulatore. Nelle seguenti figure sono rappresentati i risultati ottenuti.
4.0 3.5 3.0 2.5 2.0 1.5 1.0 In fo rm a z io n e M u tu a 20 15 10 5 0 Es/No (dB) Es/No=8.8dB OBO=11.22dB (a) 10-5 10-4 10-3 10-2 10-1 B E R 9.0 8.5 8.0 7.5 7.0 Es/No (dB) Es/No=8.8dB OBO=11.22dB (b)
4.0 3.5 3.0 2.5 2.0 1.5 1.0 In fo rm a z io n e M u tu a 20 15 10 5 0 Es/No (dB) Es/No=6.3dB IBO=15dB OBO=11.22dB (a) 10-5 10-4 10-3 10-2 10-1 B E R 7 6 5 4 Es/No (dB) Es/No=6.3dB OBO=11.22dB (b)
3.5 3.0 2.5 2.0 In fo rm a z io n e M u tu a 30 25 20 15 10 5 0 Es/No (dB) Es/No=9.6dB OBO=5.3dB (a) 10-5 10-4 10-3 10-2 10-1 B E R 10.0 9.5 9.0 8.5 8.0 7.5 7.0 Es/No (dB) Es/No=9.6dB OBO=5.34dB (b)
3.8 3.6 3.4 3.2 3.0 2.8 2.6 2.4 In fo rm a z io n e M u tu a 30 25 20 15 10 5 0 Es/No (dB) Es/No=10.7dB OBO=3.4dB (a) 10-5 10-4 10-3 10-2 10-1 B E R 11.0 10.5 10.0 9.5 9.0 Es/No (dB) Es/No=10.7dB OBO=3.41dB (b)
Fig. 3.13 Punti di lavoro del turbo codice rappresentati sulla curva di capacità del canale
Come si può notare dalle precedenti figure, abbiamo fatto lavorare il nostro sistema al limite della capacità del canale. Fintanto che ci teniamo sopra tale valore di capacità, come si può notare in tutti e quattro i casi, il turbo codice mantiene un certo floor di BER. Una volta superato tale limite però la BER crolla in maniera molto vistosa, fenomeno tipico dei turbo codici. Questo conferma il teorema della capacità di Shannon, ossia fintanto che ci teniamo su punti di lavoro al di sopra della capacità del canale, la probabilità d’errore del sistema non può andare al di sotto di un certo limite, superata tale soglia ed individuato un giusto codice, quello turbo nel nostro caso, tale sistema riesce a raggiungere BER piccole a piacere.