CAPITOLO 3
Costruzione del sistema di memoria
In senso lato la memoria può essere definita come qualsiasi effetto permanente dell’esperienza, ma in tale accezione il termine è così vago da includere anche la concezione più grossolana che intende la memoria come l’abilità di ricordare esplicitamente fatti, figure, eventi, nomi e così via. Abitualmente, l’idea che si ha della memoria è limita dalla mancanza di strumenti necessari per apprezzare la diversità e la peculiarità delle aree del cervello e delle rappresentazioni che intervengono nella codifica di una data informazione. In questo capitolo ci concentriamo sui contributi delle diverse zone e sul modo in cui esse sono specializzate per diversi tipi di memoria. Come nel precedente capitolo, evidenzieremo i meccanismi neurali che sono alla base dei processi cognitivi, e quindi, invece di classificare i tipi di memoria in base al contenuto, li distingueremo in base alle proprietà dei loro meccanismi.
3.1 Weight-based e activation-based memory
In una rete neurale, gli effetti persistenti della memoria possono assumere due forme generali che si caratterizzano con il cambio dei pesi (weight-based memory) o con un’attivazione durevole (activation-based memory). I principi di apprendimento e di elaborazione esposti nel precedente capitolo sono stati sviluppati per essere applicati
comunemente alla corteccia, quindi il nostro primo passo sarà esplorare le capacità di un generico modello corticale, specificatamente un sistema postero-corticale. Tra quelle esibite dalle aree posteriori della corteccia, le rappresentazioni che sono causate dagli effetti integrati su numerose esperienze costituiscono forse le forme più importanti di memoria, e sono indicate con il nome di semantica e procedurale, a seconda che catturino rispettivamente gli aspetti stabili dell’ambiente o le componenti ripetitive di un certo compito. Short-term priming e long-term priming sono altri due importanti fenomeni della memoria che vengono svolti nella regione corticale posteriore. Il termine priming si riferisce ad un effetto graduale che rende più facile e veloce l’elaborazione di determinate informazioni, perché precedentemente sono state elaborate informazioni simili. Il processo a breve termine può essere compreso in termini di attivazione residuale dell’elaborazione immediatamente precedente e si dissipa con relativa velocità, mentre quello a lungo termine riflette il consolidamento avvenuto nelle epoche passate relativo ai singoli cambi di peso, di ampiezza abbastanza piccola, e in definitiva può essere accostato ai meccanismi che sono alla base della memoria semantico-procedurale. Sebbene il sistema posteriore sia molto robusto per l’apprendimento e l’attivazione, e fornisca le fondamenta per vari tipi di memoria, ha anche importanti limitazioni, come ad esempio ampi livelli di interferenza catastrofica emergenti dal tradeoff tra apprendimento a lungo termine delle rappresentazioni semantiche e capacità di acquisire in modo arbitrariamente veloce informazioni. Ma la graduale dimenticanza delle vecchie informazioni quando ne vengono acquisite di nuove è uno dei fatti fondamentali della cognizione, per cui ogni modello plausibile dovrebbe esibire livelli progressivi di dimenticanza. Solo raramente le nuove informazioni apprese da un sistema cognitivo naturale interferiscono completamente, o
“catastroficamente”, con ciò che era stato imparato in precedenza. Tuttavia si è scoperto che la maggior parte dei modelli connessionisti comunemente usati, ossia quelli con un singolo set di pesi moltiplicativi in reti feed-forward standard, apprendendo nuove informazioni possono perdere in modo estremamente facile e veloce gli esempi passati. L’interferenza catastrofica è una manifestazione estrema del problema di stabilità e plasticità per tutti i modelli di memoria, che dovrebbero invece essere sensibili a nuovi ingressi e simultaneamente non distrutti radicalmente da essi. Per superare queste difficoltà, la corteccia ha bisogno della cooperazione con altri sistemi a cui è demandato il compito dell’apprendimento veloce. Tra tali sistemi spicca l’ippocampo e i tipi di memoria da esso mediati sono indicati come episodica, quando rappresenta il contenuto di episodi o eventi, dichiarativa, quando si riferisce all’informazione direttamente accessibile, e spaziale, in relazione alla posizione nello spazio. In questo capitolo ci soffermeremo sul modo in cui la formazione ippocampale riesce ad evitare l’interferenza catastrofica sfruttando rappresentazioni definite sparse e congiunte, le quali hanno come conseguenza quel pattern separation che tanta importanza riveste nel ridurre l’interferenza, codificando l’informazione in maniera molto separata, e nel legare insieme caratteristiche differenti, rendendo possibile il ricordo di interi episodi a partire da segnali parziali. Nel dominio della memoria activation-based, particolare importanza riveste la working memory, finalizzata al compimento di un particolare task attraverso il mantenimento di dati rilevanti per tale scopo: un tipico caso consiste nello svolgimento di operazioni algebriche a mente (ad esempio 5 3 7 4⋅ + ⋅ ), in cui ad un rinnovamento veloce dell’informazione (calcolare
5 3⋅ in un tempo ragionevole) si deve unire un mantenimento robusto del risultato appena raggiunto (ricordare 15 mentre si svolge 7 4⋅ ).
3.1.1 Long-term priming
Nella corteccia posteriore si manifesta un priming a lungo termine, che si palesa ogni volta si presenta un singolo stimolo ed ha come conseguenza lo stesso cambio dei pesi della memoria semantico-procedurale. E’ quello che succede, ad esempio, quando si legge più volte una lista di parole: man mano che ci si allena, si leggeranno sempre più velocemente. In letteratura sono state descritte varie forme di priming, che noi, proseguendo in una prospettiva rivolta soprattutto ai meccanismi neurali, possiamo riunire in tre tipi differenti in base alla durata, al contenuto e alla somiglianza. La durata non è altro che la distinzione che abbiamo già effettuato tra priming a breve e a lungo termine. Il contenuto si riferisce alla natura delle rappresentazioni interessate (visive, lessicali o semantiche); infine la somiglianza riflette la vicinanza tra lo stimolo fondamentale e quello seguente di test. Più in generale, in questo meccanismo è coinvolto il propagarsi dell’attivazione lungo i legami associativi, rendendo più immediato il confronto tra la situazione presente e l’esempio fondamentale. Questa propagazione dell’attivazione può produrre anche cambi di peso, quindi ci si potrebbe aspettare sia ripercussioni nel breve che nel lungo periodo. Noi prendiamo come paradigma di long-term priming il caso in cui la dimensione caratteristica sia la somiglianza, e all’interno di questa dimensione consideriamo in special modo eventi ripetitivi, ossia tali che il caso base e il successivo di test siano identici. La principale metodologia comportamentale per lo studio del priming ripetitivo è detta completamento della radice, test durante il quale al partecipante viene prima fatta studiare una lista di parole e poi gli viene presentata un’altra lista in cui si ha solo la parte iniziale (radice). All’insaputa del soggetto, molte radici possono essere completate con le parole precedentemente studiate: nella prima lista potrebbe aver studiato la parola “partito”, e
dopo potrebbe trovarsi a completare la parola “par…”. Poiché le radici sono pensate per essere completate in vari modi e sono preventivamente testate perché le possibilità prodotte siano all’incirca uguali, con riferimento alla frequenza con cui le parole vengono utilizzate nel lessico comune, qualunque incremento di probabilità, rispetto al livello pre-test, collegato allo spunto implicito dovuto all’assimilazione precedente, può essere considerato come un indicatore dell’effetto residuo dell’elaborazione. In altri termini, lo studio preliminare di una data parola facilita la successiva elaborazione di quella stessa parola. Poiché lo studio della lista è separato dal successivo compito di completamento delle radici da un periodo di tempo relativamente lungo (circa dieci minuti) e poiché l’elenco contiene anche alcune delle parole che potrebbero essere conservate in memoria, si crede che sia attivo un meccanismo a lungo termine come il long-term priming. Un procedimento per rendere tangibile questa situazione di lavoro e adattarla in modo congruo allo sviluppo e alla modellizzazione propri di una rete neurale è un mappaggio one-to-many, visto che un ingresso nella forma tronca può essere completato in più di un modo. In questo ambito il task che meglio esplicita i problemi sollevati è quello omofonico proposto nel 1982 da Jacoby e Witherspoon, in cui vengono presentate due parole che hanno la stessa pronuncia ma diversa ortografia (nella lingua inglese). Un semplice caso è quello tra read (leggere) e reed (canna di strumento musicale). L’ingresso, per un’ipotetica rete, è una pronuncia ambigua e l’uscita è una delle due possibilità ortografiche. O’Reilly e Munakata simulano tale test, usando per semplicità dei patterns di attivazione casuale e associando due differenti uscite per un dato ingresso. Nel periodo di training la rete cerca di acquisire le associazioni corrette, e questa operazione può essere considerata equivalente al percorso storico di apprendimento che una persona, normalmente, deve effettuare per
riconoscere i casi più rilevanti e usuali di omofonia. Così la rete viene dotata di una memoria “semantica” e produce una delle due uscite appropriate in risposta ad un pattern d’ingresso.
Figura 3.1: rete per lo studio del priming a lungo termine.
Durante la fase di test, viene presentato un certo ingresso e si guarda quale delle due parole viene associata. Quello che si nota è che in un singolo ciclo, mantenendo costante il learning rate e usando gli stessi meccanismi di apprendimento che permettono alla rete di reperire inizialmente le informazioni semantiche, si genera una forte componente di bias connessa alla produzione delle uscite facilitate. In definitiva, l’architettura presentata mostra che il long-term priming può essere visto come una conseguenza degli stessi processi di apprendimento che stabiliscono le rappresentazioni corticali su lunghi periodi di esposizione ad un certo ambiente.
3.1.2 Test di apprendimento AB-AC
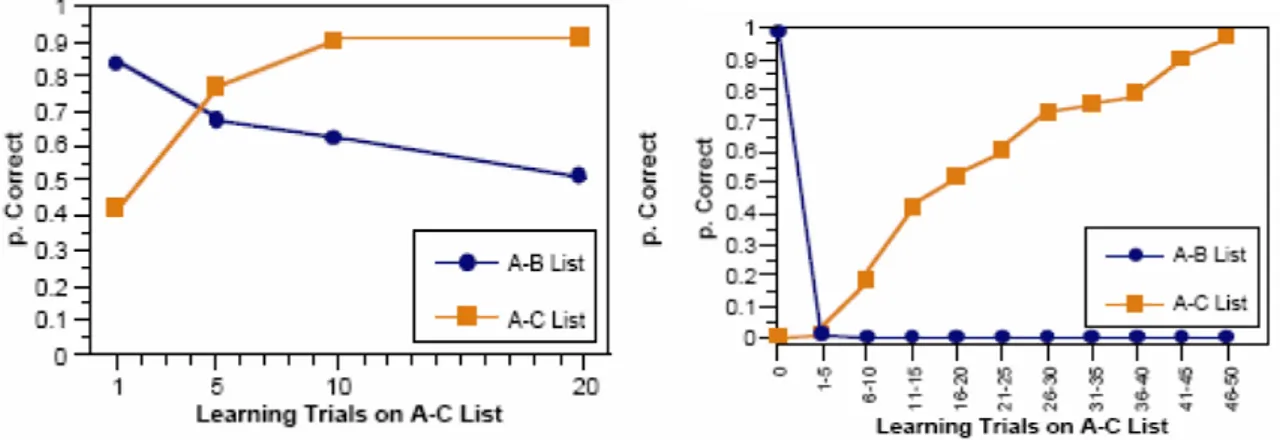
Il semplice modello di corteccia brevemente visto può usare apprendimento lento per sviluppare sia nuove rappresentazioni che effetti facilitatori in risposta a singole esposizioni ad oggetti familiari, cioè già classificati in fase di training. Spesso però si incorre in situazioni in cui si devono raccogliere rapidamente nuove informazioni sulla base di pochi cicli di addestramento, con poca preparazione. Il fenomeno di priming nella corteccia non sembra essere in grado di risolvere tali esigenze. Un task sperimentale comunemente usato per stimolare il rapido apprendimento di nuove associazioni è il test AB-AC, particolarmente adatto perché porta in sé un alto livello di sovrapposizione tra le nuove associazioni. Con A si indica una lista di parole a cui sono associate due altre liste differenti, B e C: ad esempio la parola pensiero può essere legata a cielo nella lista AB e a tavolo in quella AC. Dopo aver studiato le associazioni AB, il soggetto viene interrogato chiedendogli di ricordare ogni parola di B corrispondente all’appropriata parola di A. Poi il soggetto deve studiare la lista AC e quindi viene interrogato su entrambe. Sebbene coloro che vengono sottoposti al test esibiscano dei livelli di interferenza sul ricordo degli elementi associati in AB come risultato dello studio di AC, essi hanno una percentuale di successi intorno al 60%. McCloskey e Cohen hanno cercato di simulare questa situazione sperimentale con una rete neurale con backpropagation ma si sono trovati a fare i conti con l’insorgere di alti livelli di interferenza catastrofica, infatti mentre negli individui sottoposti al test il ricordo corretto della lista AB passa dal 100%, prima di presentare AC, al 60%, dopo aver studiato anche AC, per la rete si ha un drastico crollo a 0 della percentuale. L’interferenza nella rete sorge dal riutilizzo delle stesse unità, con i relativi pesi, per apprendere diverse associazioni, ossia l’aggiornamento ∆ dovuto alla presentazione wij
sequenziale di nuovi esempi tende a far perdere ciò che la rete aveva precedentemente imparato.
Figura 3.2: andamento dell’apprendimento della lista AB-AC per l’uomo(a sinistra) e per una rete
neurale(a destra). Si può notare come la rete presenti livelli di interferenza catastrofica inaccettabili.
Un modo per superare questo tipo di interferenza è di predisporre unità differenti a codificare associazioni differenti, anche se questa soluzione è in conflitto con l’uso di rappresentazioni distribuite in modo sovrapposto, in cui le stesse unità partecipano alla descrizione di un certo numero di oggetti diversi. Si deve scegliere tra i due casi limite di rappresentazioni sovrapposte, generanti interferenza, e rappresentazioni sparse, quindi con pochi neuroni attivi, e separate che presentano basso decadimento del ricordo ma non hanno la validità ecologica delle altre. L’unica soluzione risiede nel sistema di memoria ippocampale specializzato su rappresentazioni sparse e distribuite favorevoli ad un apprendimento rapido che non soffra di indesiderata interferenza.
3.1.3 Short-term priming
Sempre O’Reilly e Munakata, per lo studio del priming a breve termine hanno proposto la stessa metodologia vista per la simulazione della memoria weight-based costruita sul task di classificazione omofonica con mappaggio one-to-many. La differenza sostanziale è che
in questo caso viene disattivato il meccanismo di cambio dei pesi durante la fase di priming e osservata la conseguente performance della rete, mettendo a confronto i due tipi di apprendimento in modo che l’esperienza passata consolidi i pesi per favorire una certa risposta, mentre l’esperienza immediatamente precedente ne favorisca un’altra. La struttura topologica della rete rimane inalterata, ma ora si hanno due risposte, “a” e “b”, per un dato ingresso e si vuole vedere quale sia l’impatto di “a” sulla risposta per “b”. Quando si presenta il pattern d’ingresso associato ad “a”, si impone che il pattern di uscita sia proprio “a”, mentre per il caso “b” si fornisce solo l’input in modo che si possa effettuare un confronto tra l’output attuale prodotto dalla rete e l’ingresso dato. In questo modo si osserva che la rete ha come uscita finale “a” anche in risposta allo stimolo “b”, e questo è il risultato della persistenza dell’attivazione allo stimolo immediatamente precedente. In modo arbitrariamente semplice la rete simula il priming basato sui pesi presente nella corteccia posteriore.
3.2 Il sistema di memoria ippocampale
Il modello che presentiamo è stato implementato da O’Reilly e McClelland nel 1998 all’interno del progetto di ricerca PDP (Parallel Distribuited Processing) e riunisce le proprietà biologiche principali che permettono all’ippocampo di apprendere velocemente senza risentire dei problemi di interferenza di cui soffre una rete corticale. Nel primo capitolo ci siamo soffermati su una descrizione anatomo-funzionale dell’ippocampo, mentre adesso passiamo alla modellizzazione “ingegneristica”. La figura 3.3 mostra il principio a cui ci siamo ispirati: abbiamo cercato di salvaguardare la distinzione delle regioni principali e la loro connettività, nella convinzione, e speranza, che ciò potesse
servire per far emergere le proprietà funzionali, secondo quello che è il modello Hebb-Marr.
Figura 3.3: passaggio dall’ippocampo biologico al suo schema a blocchi.
Esso fornisce le proprietà associative della memoria grazie sia alla connessione feed-forward che dalla corteccia entorinale (EC), via DG, arriva alla regione CA3, favorendo
l’immagazzinamento di nuove informazioni, sia alle connessioni rientranti in reazione dentro la CA3 stessa, fondamentali per il richiamo di memorie accumulate precedentemente. Quello che sta emergendo dagli ultimi studi sui processi mnemonici è che l’ippocampo svolge un ruolo di binding, ha cioè un ruolo regolatore nell’unire in modo coerente e organico le rappresentazioni corticali per costruire una particolare memoria, il cui contenuto particolareggiato sta nella corteccia. L’ippocampo unisce insieme le rappresentazioni corticali, senza attribuire loro un’informazione semantica, che è rappresentata invece proprio dalla fitta interconnessione e dalle rappresentazioni sovrapposte della corteccia.
Il contenuto di memoria dell’ippocampo può essere considerato essenzialmente come episodico: la tendenza a riprodurre episodi specifici assume un significato più stringente se si pensa che le sue rappresentazioni sono separate, in modo tale che ogni arco temporale racchiuso in un ricordo sia immagazzinato in rappresentazioni separate. Non si deve però immaginare che l’ippocampo abbia una memoria integrale, con rapporto uno a uno tra vissuto e ricordato, di tutti i fotogrammi di esperienza passata, perché tutto svanisce nell’oblio se non viene reintegrato e rinfrescato periodicamente.
Ippocampo e corteccia lavorano in modo inscindibilmente dipendente e molti fenomeni possono essere spiegati solo in termini di loro reciproca interazione, come ad esempio accade durante il passaggio associativo che porta le rappresentazioni inizialmente codificate nell’ippocampo ad essere gradualmente incorporate nell’insieme di elementi acquisiti dalla corteccia stessa, attraverso il processo standard di apprendimento lento. Questo fenomeno è conosciuto come consolidamento e può spigare alcune importanti proprietà delle amnesie derivanti da danneggiamento dell’ippocampo. A tal proposito, un
esempio emblematico è fornito dall’amnesia retrograda, patologia che compromette il richiamo corretto della memoria recente fino al momento del danno cerebrale a livello ippocampale, mentre preserva inalterati i ricordi più vecchi. La peculiarità dell’amnesia retrograda va contro il senso comune dell’andamento della memoria, secondo cui dovrebbe sfumare progressivamente col tempo, ma perlomeno ha aiutato i ricercatori a capire che i ricordi antichi vengono consolidati nel sistema corticale, mentre i più recenti sono elaborati dall’ippocampo.
Il funzionamento dell’ippocampo può essere spiegato facendo riferimento a due meccanismi in competizione l’uno con l’altro: pattern separation e pattern completion. Il primo, è il principale responsabile della formazione di una mappatura non sovrapposta di memorie differenti, che, come abbiamo visto in precedenza, attivando unità neurali differenti, abbattono i livelli di interferenza perché non c’è incrocio nell’aggiornamento dei pesi. Il secondo permette che segnali parziali possano triggerare l’attivazione completa di un memoria codificata in precedenza (manifestazione macroscopica di tale processo, ad esempio, è presente nella priming del test del completamento della radice). In definitiva, il meccanismo di pattern separation interviene quando l’ippocampo immagazzina nuove memorie, mentre quello di pattern completion è attivo nel recupero di memorie già esistenti.
Fin’ora abbiamo sempre indicato con il termine generale ippocampo una delle strutture che maggior peso ha nella gestione della memoria umana, senza preoccuparci di approfondire il ruolo delle singole regioni al suo interno. Nella prospettiva della modellizzazione, serve necessariamente una base su cui costruire la simulazione, a partire proprio dalla codifica e dal recupero delle memorie, non più occupandoci solo delle fenomenologie macroscopiche
dei processi mnemonici ma riferendoci alle regioni e alle loro proiezioni. L’attivazione fluisce dalla corteccia profonda verso la zona entorinale, da qui sale verso la regione DG e di conseguenza verso la CA3 formando un pattern di rappresentazione separato agendo su gruppi di unità sparsi e separati, che vengono poi uniti insieme dall’azione dell’apprendimento hebbiano veloce, reso particolarmente efficace dalle connessioni ricorrenti all’interno di CA3 stessa. Per altra via, o meglio da una diramazione della via principale, l’attivazione dal giro dentato si propaga simultaneamente anche alla zona CA1, formando qui delle rappresentazioni non solo separate ma anche invertibili, il che significa che la configurazione di attivazione di CA1 può essere invertita per risalire al corrispondente pattern su EC che in origine ha determinato la rappresentazione proprio su CA1. L’associazione tra i patterns CA3 e CA1 è codificata tramite l’apprendimento hebbiano nei valori dei pesi delle connessioni tra i due strati. Con l’informazione codificata in questo modo, il recupero di memorie avviene a partire da stimoli parziali basati su segnali elaborati dalla corteccia. Come prima l’attivazione arriva allo strato EC e quindi a DG e CA3, ma adesso l’apprendimento consolidato sulla strada feed-forward e su quella rientrante porta ad alti livelli l’abilità di completare ingressi parziali e ricostruire la rappresentazione CA3 originale. La configurazione CA3 così completata attiva la zona CA1, che, essendo invertibile, è capace di riprodurre l’attivazione di EC. Se, dopo elaborazione corticale, nella regione entorinale arriva un segnale nuovo, ossia che non è ancora stato classificato, i pesi non hanno subito il processo di priming e la CA3 non è in grado di pilotare la CA1 e quindi questa non può invertire il suo contenuto per riportarlo alla corteccia.
3.2.1 Pattern separation e pattern completion
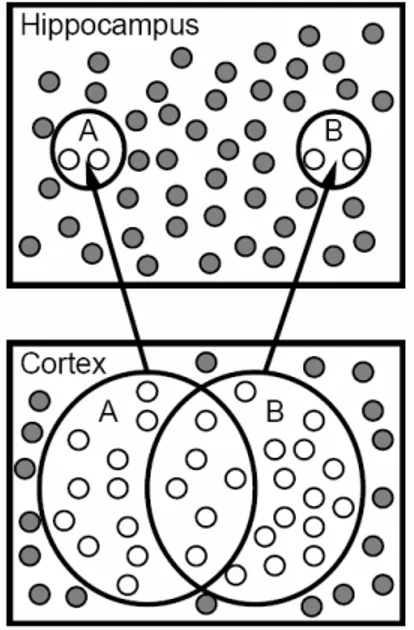
L’ippocampo riesce ad effettuare pattern separation grazie alla capacità di generare rappresentazioni con un numero esiguo di neuroni attivi. Noi cercheremo di riprodurre tale situazione seguendo la strada indicata da McCloskey e Cohen nel loro modello corticale di base per la simulazione del test AB-AC. Il controllo implicito sul numero di unità attive in uno strato viene svolto dalla funzione inibitoria che nel nostro caso è del tipo Winners-Take-All. Per capire il passaggio da rappresentazioni sparse a pattern separation, si può immaginare l’ingresso ippocampale generato in modo casuale con una probabilità fissata di avere un’unità attiva, trascurando per semplicità il condizionamento introdotto dalle connessioni pesate con lo strato da cui fluisce l’attivazione. Se la funzione inibitoria garantisce che il numero totale di neuroni accesi sia basso, l’eventualità che le stesse unità siano attive su due patterns differenti sarà ancor minore.
Figura 3.4: schematizzazione pratica di pattern separation nell’ippocampo. A e B indicano due
rappresentazioni composte da patterns di neuroni: nella corteccia sono sovrapposte e con un numero di
unità relativamente alto, mentre nell’ippocampo sono sparse e composte da una quantità minore. I neuroni
Per dare un’idea dei numeri in gioco, se l’inibizione consente che restino attive un quarto delle unità di uno strato, ossia se ogni unità ha una probabilità di attivazione dello 0.25, allora la probabilità che una stessa unità sia sopra il valore di soglia su due patterns distinti è pari a 0.0625=
(
0.25)
2. L’andamento della probabilità del pattern separation è dunque parabolico in misura di quanto la distribuzione sia sparsa.Figura 3.5: rappresentazioni congiunte. Le due unità riceventi hanno lo stesso numero di connessioni, gli
ingressi sono altamente sovrapposti, ma vengono attivate alternativamente quelle che hanno il maggior
numero di ingressi sopra soglia.
In modo duale, si arriva ad avere rappresentazioni molto sparse se la soglia di attivazione dei singoli neuroni è abbastanza alta in corrispondenza di una somma di ingressi eccitatori costante. La figura 3.5 mostra in modo sintetico come un’inibizione con soglia elevata favorisca sia il processo di separazione delle rappresentazioni sia la creazione di configurazioni congiunte, le quali dipendono globalmente dalla disposizione delle unità attive all’interno dello strato d’ingresso. La sensibilità all’accoppiamento delle unità attive sullo strato di input, dovuto alla scelta di un valore di Θ appropriato, porta dei vantaggi considerevoli perché, anche se due patterns hanno a comune molte unità sovrapposte, basta che nella configurazione globale della corteccia ci sia anche una sola unità attiva in più o in
meno per attivare unità differenti nell’ippocampo. Solo quelle unità che hanno la distanza minore tra il vettore dei pesi e quello delle attivazioni correnti riceveranno un segnale eccitatorio in grado di farle diventare attive, e tale segnale dovrà quindi provenire da una frazione relativamente alta del numero di unità attive nello strato immediatamente inferiore. La figura precedente esemplifica ancora questa situazione nel caso limite in cui sia attivo solo il neurone formale più eccitato, anche se in realtà nell’ippocampo è attiva una percentuale di neuroni che si aggira intorno al 5%. Affinché il meccanismo di separazione funzioni in modo ideale è necessario che un dato insieme di unità riceventi venga spinto al livello massimo di attivazione da un dato pattern d’ingresso. Ci sono due alternative possibili per rendere praticabile questa esigenza: o si aumenta la varianza della distribuzione con cui vengono inizializzati i pesi o si predispone una connettività parziale con gli ingressi. Nel nostro modello, per implementare il test di apprendimento AB-AC, abbiamo scelto la prima opzione, che riduce di molto l’interferenza. Nell’ippocampo chi assicura la separazione delle rappresentazioni è la via perforante, che, con proiezioni diffuse e casuali, garantisce che singoli neuroni delle zone DG e CA3 siano portati al massimo valore di attivazione da patterns d’ingresso differenti.
Per le funzioni mnemoniche, il meccanismo di pattern completion è altrettanto importante che quello di pattern separation. Se fosse presente solo il secondo automatismo, ogni volta che un individuo si dovesse trovare nella necessità di recuperare un’informazione precedentemente immagazzinata, usando qualcos’altro che non l’identico pattern d’attivazione originale (il che corrisponde alle più svariate e comuni situazioni quotidiane), l’ippocampo dovrebbe creare, codificare e immagazzinare una nuova versione, ancora separata, dell’ingresso invece di riconoscerlo come un segnale recuperato da una memoria
già esistente. Quindi, per utilizzare nel presente delle memorie accumulate nel passato, nell’ippocampo, è strettamente necessario il meccanismo di pattern completion. Tuttavia discriminare un dato ingresso come segnale parziale o come dato completamente nuovo è spesso difficoltoso per la “rumorosità” dell’input e per la velocità con cui si degradano i contenuti di memoria. L’ippocampo affronta questa decisione sulla base di un set di meccanismi elementari operanti sui patterns d’ingresso, e non sempre fa quello che da una prospettiva di conoscenza onnisciente sembrerebbe essere la cosa giusta per risolvere i fattori rilevanti di un particolare task: questo può complicare il compito dell’ippocampo e richiedere la sua partecipazione a problemi di decisione non lineare.
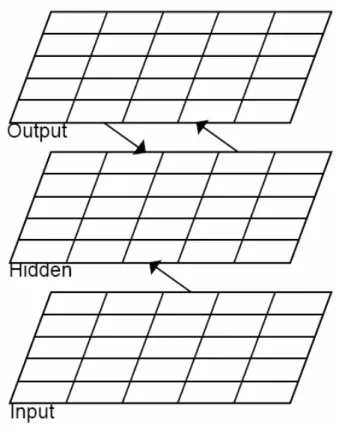
3.3 Dettagli del modello: comportamento generale e architettura
Figura 3.6: il modello dell’ippocampo.(a) Aree e connettività .(b) Un esempio di pattern di attività.
Non resta che aggiungere gli ultimi particolari per terminare il quadro complessivo del modello che abbiamo implementato in questa tesi. Cercheremo ancora una volta di mettere
in evidenza sia come tentiamo di tener dietro alla verosimiglianza biologica sia come ci arrendiamo di fronte alla complessità e quindi intraprendiamo scelte prettamente utilitaristiche per il nostro fine: l’efficienza. Nella figura 3.6 è mostrato il diagramma del nostro modello con le regioni anatomiche fondamentali della formazione ippocampale e con la corteccia entorinale, che ha la funzione di percorso bufferizzato primario di ingresso/uscita per l’ippocampo. Il pattern d’attività dello strato Input rappresenta lo stato della corteccia entorinale che risulta dopo la presentazione di un dato stimolo. Assumiamo che l’ippocampo immagazzini e recuperi memorie come rappresentazioni ridotte nella regione EC, che corrispondono a rappresentazioni più elaborate in altre aree della corteccia, sviluppate tramite priming a lungo termine. Inoltre assumiamo che ci sia una relazione topologica, seppur approssimativa, per l’organizzazione della EC, con differenti aree o sottoaree raffigurate da differenti slots, che possono essere pensati come rappresentanti particolari dimensioni caratteristiche dell’ingresso (colore, forma, proprietà semantica, ecc.). Abbiamo costruito una EC di 36 slots, ognuno formato da 4 unità che racchiudono il valore codificato di una particolare dimensione, anche se per il momento sono inizializzati in modo casuale con una distribuzione uniforme. Avvicinandoci alla formazione ippocampale, ci sono due strati entorinali funzionalmente distinti, uno che riceve l’input dalle aree corticali e proietta verso l’ippocampo ( EC_in o corteccia entorinale superficiale), e uno che riceve le proiezioni provenienti dalla regione CA1 e le riporta verso la corteccia ( EC_out corteccia entorinale profonda). Probabilmente le rappresentazioni in questi due strati sono diverse nei loro particolari, ma noi assumiamo che siano equivalenti e quindi, per convenienza, usiamo le stesse rappresentazioni per entrambi. EC_in proietta a tutte e tre le aree dell’ippocampo: DG, CA1, CA3.
L’immagazzinamento del pattern d’ingresso avviene tramite i cambi di pesi nelle proiezioni feed-forward e ricorrenti dentro CA3 e nelle connessioni tra CA3 e CA1. I due strati all’apice del nostro modello contengono le due rappresentazioni primarie del pattern d’ingresso mentre DG ha un ruolo importante nel rafforzare il pattern separation per lo strato CA3. Chi fornisce la rappresentazione sparsa, congiunta, con il meccanismo della separazione descritto nel paragrafo precedente è la regione CA3, grazie ad una connettività casuale e parziale con EC_in e ad una soglia per l’attivazione molto alta, in modo tale che le poche unità attivate ( il 5% nel nostro modello) siano quelle che ricevono più ingressi dai neuroni attivi su EC_in. Con una così grande proporzione di ingressi, la probabilità che si presenti un’unità attiva per due configurazioni EC relativamente simili è molto bassa, e questo, in qualche modo, implementa il meccanismo di pattern separation. Le rappresentazioni CA3 sono estremamente utili sia perché favoriscono un apprendimento rapido senza l’insorgere di interferenza indesiderata e dannosa sia perché il meccanismo di pattern separation elimina qualsiasi legame sistematico tra la rappresentazione ippocampale e quella originale nella corteccia. Tuttavia, deve pur esistere un modo per ritradurre il pattern CA3 nel linguaggio di EC, con attivazione molto meno rada. La soluzione più semplice consistente nell’associare direttamente CA3 con il corrispondente EC_out presenta notevoli difficoltà dovute all’interferenza causata appunto dal livello di attività della corteccia (nel nostro caso 25%). Per questo motivo abbiamo affidato la traslazione alla regione CA1, che è capace, come risultato dell’apprendimento a lungo termine, di sviluppare ed espandere le rappresentazioni corticali in modo più sparso di CA3 e quindi di rimapparle indietro nel livello entorinale profondo. La CA1 ha rappresentazioni separate di piccole combinazioni di slots e tali colonne possono essere combinate
arbitrariamente per riprodurre qualsiasi rappresentazione valida di EC_in, ossia sono una via di mezzo tra quelle completamente congiunte di CA3 e quelle combinatorie di EC. Questa situazione di compromesso è raggiunta allenando ogni singola colonna di CA1 composta da 32 unità, con livello di attività scelto intorno al 10% (9,4% per l’esattezza), a mappare qualsivoglia combinazione di patterns presente nei 3 slots (quindi 12 neuroni) che formano una colonna di EC_in sull’omologa colonna di EC_out. Il livello di attività nello strato corticale è pari al 25% e ogni slot è formato da 4 unità, quindi una sola di queste può essere attiva in un’epoca; in una colonna allora ne saranno attive contemporaneamente 3 e quindi le possibili combinazioni saranno 3
4 =64. Ovviamente il training viene svolto una sola volta su un trio di colonne di EC_in, CA1 e EC_out e poi i pesi replicati coprendo l’intera struttura. Il costo di questa operazione è che sono richieste 32 unità CA1 per colonna contro le dodici di EC, nondimeno consistente con la proporzione dell’estensione di questa regione rispetto alle altre aree.
Dopo la fase di apprendimento il nostro modello ricorda gli oggetti studiati semplicemente riattivando i patterns CA3, CA1 e EC_out con i pesi facilitati. Con ingressi parziali o rumorosi, quindi affetti da interferenza, i valori dei pesi e due forme di ricorrenza, l’anello rientrante in CA3 e quello che parte da EC_in e ritorna a EC_out, permettono all’ippocampo di orientarsi all’interno del richiamo e completare il pattern originale (pattern completion). D’altra parte, se sullo strato Input viene presentato un oggetto non precedentemente studiato, i pesi non avranno goduto dell’effetto di priming e quindi l’ingresso non sarà in grado di guidare correttamente la CA1 e di conseguenza l’intera rete. Il ricordo corretto è considerato il richiamo riuscito di un pattern già studiato. Ma a questo punto si solleva un problema basilare: la rete deve essere in grado di distinguere tra
l’attivazione dovuta all’ingresso presente su EC_in, direttamente o via CA1, e quella proveniente dal richiamo vero e proprio lungo la strada CA3-CA1. La soluzione biologica a questo problema, chiarificata grazie agli studi sull’EEG profonda, è che i segnali di ritorno da CA3 e da CA1 sono sfasati di 180D rispetto al ritmo theta limbico: quando CA3 pilota la regione CA1, la mantiene attiva fino a quando i suoi neuroni dovrebbero essere sotto la soglia di attivazione, fornendo così un modo per riconoscere l’attivazione dovuta alla corteccia e quella dovuta all’ippocampo. Nell’impossibilità di replicare questo sofisticato meccanismo di sincronismo, noi lo approssimiamo semplicemente disattivando il collegamento tra EC_in e CA1 durante la fase di test.
3.3.1 Funzionamento del modello
In questa esplorazione utilizziamo il test di associazione AB-AC come spiegato nel paragrafo 3.1.2 per una generica rete corticale, e mostriamo come l’ippocampo sia in grado di apprendere delle nuove coppie di oggetti abbinati, quelli della lista AC, senza subire gli effetti negativi dell’interferenza su quelli precedentemente acquisiti, ossia AB. Abbiamo due fasi di training successive, la prima è quella in cui la rete viene allenata con gli oggetti AB, mentre la seconda con AC. Ogni ingresso è composto da un pattern di 12 slots, come si può vedere dalla figura 3.6, di cui i primi quattro costituiscono la rappresentazione di A, i secondi quattro alternativamente quella o di B o di C, mentre gli ultimi sono il “contesto”, una codifica delle informazioni interne alla rete che varia di poco per tutte le coppie di oggetti. Il pattern di ingresso ha le specifiche di inibizione prima indicate: 36 unità attive sullo strato, 3 per ogni slot. In un primo momento abbiamo costruito i patterns grazie ad una funzione di generazione di numeri casuali, in modo che mettesse nello stato di attivazione un neurone ogni quattro. Durante le fasi di training le tre parti formanti l’input
vengono fornite contemporaneamente, invece nella fase di test il secondo elemento, B o C, è omesso, perché si richiede alla rete ippocampale di ricordarlo basandosi solo sull’ingresso parziale costituito da A e dal contesto. Una volta che la rete ha ricevuto l’input, si vede l’attivazione fluire nella rete a partire da EC_in, salendo verso DG e CA3 e parallelamente verso CA1, affinché la rappresentazione sparsa su CA3 possa essere associata con quella invertibile di CA1, restituendo su EC_out il “ricordo” di EC_in. I patterns su EC sono molto sovrapposti (36 neuroni attivi su 144), quelli su CA1 in maniera minore (36 su 384), mentre quelli su CA3 (12 su 240) e specialmente su DG (12 su 625) sono molto radi. Ogni epoca di training consiste di una lista di 10 oggetti, seguita da 2 prove di test: il primo contiene la lista AB e il secondo la lista AC, sempre con la parte mediana del pattern mancante per permettere alla rete il recupero. Questo ciclo di eventi si ripete per tre volte. Alla fine si nota che la rete ricorda bene gli oggetti su cui era stata allenata nella fase di addestramento, ma non riesce a fare altrettanto su AC,e questo è ciò che ci si aspettava visto che sarebbe come pretendere di chiedere ad una persona di indovinare delle associazioni mentali senza che gli fosse data la possibilità di studiarle. Il dato rilevante è che se adesso si ripete l’intero ciclo, facendo però il training sulla lista AC, nella fase di test sulla lista AB, al contrario di quello che avviene con le normali reti corticali, non si ha interferenza catastrofica, con ricordo nullo, ma persiste una traccia dell’esperienza passata, quantificabile intorno al 50% di richiami corretti e paragonabile con i dati basati sull'osservazione di individui sottoposti all’esperimento (vedi fig. 3.2). Per stabilire se la rete ha svolto correttamente l’operazione di ricordo effettuiamo una confronto tra il pattern di attivazione su le parti superficiale e profonda della corteccia entorinale con due parametri: err_on e err_off. Il primo indica la frazione di unità che sono
state erroneamente attivate su EC_out ma non presenti nel target, il secondo è la frazione di unità che non sono state attivate su EC_out ma lo sono sul target. Quando entrambi gli indici sono nulli significa che EC_in e EC_out sono identici, se err_on è vicino a 1 allora la rete ha “confuso” o richiamato un pattern diverso da quello che era stato presentato come target, infine un err_off abbastanza grande implica che la rete abbia fallito il richiamo. Per codificare in modo sintetico la risposta della nostra struttura abbiamo bisogno di fissare una soglia per questi parametri. La scelta è arbitraria, ma fatta in modo da garantire una performance ragionevole: se err_on≤ 0.2 e err_off ≤ 0.4, affermiamo che l’ippocampo ha eseguito correttamente il richiamo.
3.3.2 Descrizione dell’architettura software
Uno dei modi più semplici per descrivere l’architettura di un sistema software nei suoi dettagli è l’utilizzo del linguaggio UML (Unified Modeling Language), il quale si avvale di un procedimento che consente la visualizzazione grafica del modello del progetto a partire direttamente dal codice sorgente del sistema. L’UML è nato dall’esigenza di disporre di un codice universale per modellizzare gli oggetti utilizzabile da ogni industria di software, e permettere a tutti i fruitori di accedere ed esaminare in modo efficiente il sistema, e caso mai modificarlo per migliorarlo. Si parte dalla descrizione della classe di base a cui sono collegate svariate altre tramite delle relazioni. Ogni classe è rappresentata da un rettangolo: il suo nome rimane nella parte alta e per convenzione è una parola con iniziale maiuscola. La lista degli attributi della classe, scritti sempre in carattere minuscolo, viene automaticamente separata dalla classe stessa attraverso una linea orizzontale; di seguito alla lista degli attributi vi è quella dei metodi. Tra le classi della nostra architettura esiste una gerarchia, ossia alcune derivano da altre. Una classe derivata può essere considerata
come ereditante le proprietà e i metodi da un’altra classe. La classe originaria è definita madre mentre quella derivata figlia, e il grado di ereditarietà è visualizzato da una freccia che parte dalla classe figlia e termina sulla madre. L’UML è in grado di gestire la visibilità tra le classi, ossia la possibilità di usare gli attributi e le operazioni di un’altra classe. Sono consentiti tre livelli di visibilità, distinti con altrettanti simboli grafici:
• livello pubblico: l’utilizzo è esteso a tutte le classi (simbolo: +);
• livello privato: gli attributi e le operazioni così definite possono essere utilizzati solo dalla classe all’interno della quale sono dichiarati (simbolo: -);
• livello protetto: l’utilizzo è concesso alle classi che derivano dalla classe originale (simbolo: #).
Il fulcro di questo lavoro di tesi, oltre la costruzione del modello del neurone e della mappa ippocampale, è stato l’implementazione software del modello stesso, realizzata con Microsoft Visual C++ 6.0. Questo è stato reso possibile grazie all’utilizzo dell’architettura sviluppata nel corso degli anni del dottorato da parte dell’ingegnere Marcello Ferro presso il centro interdipartimentale “E. Piaggio”. Ed è proprio grazie alla flessibilità del suo impianto che abbiamo potuto innestarvi la struttura Leabra.
Il progetto è composto da una collezione di librerie, che nel loro insieme formano l’entità ARI, il cui elemento di base è ARI_3DObject. Un ARI_3DObject è un oggetto fisico identificato da un nome e dotato di caratteristiche geometriche quali posizione e volume occupato. ARI_3DObject contiene dei flags per specificare le operazioni overridables disponibili all'utilizzatore. Tali operazioni (Render(), SetInput(), Update()) sono definite virtuali così da potere essere ridefinite nelle classi derivate e poter essere così utilizzate da chi le invoca sulla classe base ARI_3DObject. Tali funzione di default non fanno nulla, se
altrimenti indicato svolgono rispettivamente il rendering OpenGL, le operazioni a seguito del trigger di pre-update e l’aggiornamento dopo il tempo di inter-frame. Per inizializzare nuovamente i parametri di ARI_3DObject si utilizzano le apposite funzioni Get/ Set/ Add/ Rem. SetInput() ed Update() sono realizzate separatamente per consentire una elaborazione indipendente dall'ordine di processamento.
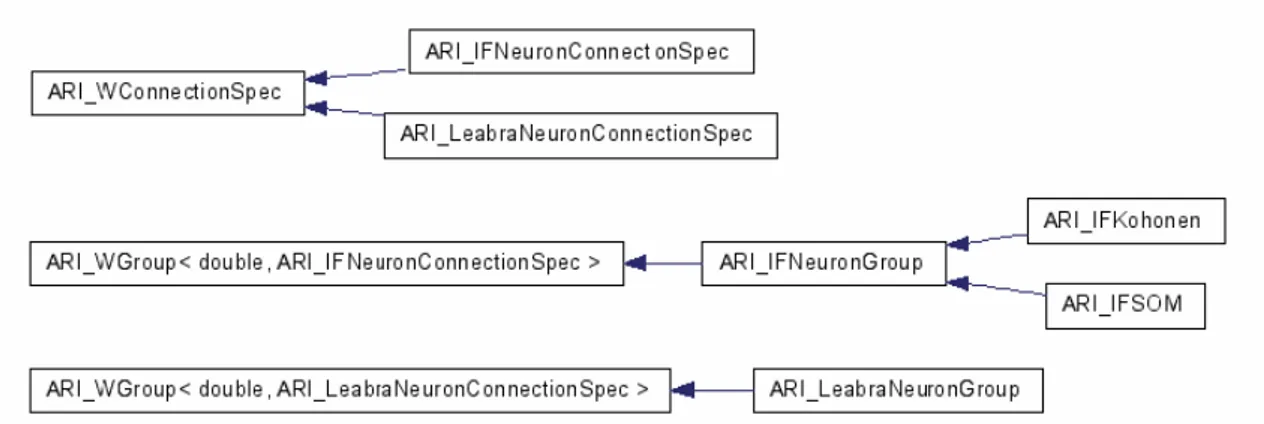
Figura 3.7: gerarchia delle classi.
Nel diagramma a blocchi precedente si ha la rappresentazione grafica della gerarchia delle classi. Dopo ARI_3DObject abbiamo ARI_3DWorld che non è altro che una collezione di ARI_3DObject e l'ambiente nel quale si collocano le entità che compongono ARI. Mentre ogni ARI_3DObject conosce la propria collocazione geometrica e le entità direttamente connesse in ingresso e in uscita, solo ARI_3DWorld conosce i collegamenti topologici e la collocazione spaziale di tutte le entità, comprese quelle topologicamente sconnesse. Le funzioni Render(), SetInput() e Update(), membri privati di ARI_3DWorld, si occuperanno di propagare il rispettivo messaggio a tutte le entità che hanno abilitato tra i propri flags la corrispondente operazione di override. Tramite le apposite funzioni Add/Remove è possibile popolare l'ARI_3DWorld. ARI_3DWorld conserva solo i riferimenti agli ARI_3DObject.
Da ARI_3DObject derivano le due classi ARI_W e ARI_WGroup. ARI_W è un ARI_3DObject e rappresenta una funzione di trasferimento con n ingressi ed 1 uscita. ARI_W<OUTDATA,CONNSPEC> fornisce una uscita di tipo DATA e riceve gli ingressi tramite connessioni ARI_WConnection<OUTDATA,CONNSPEC>. Il costruttore di default azzera il valore di uscita, imposta i flag di Render(), SetInput() e Update() e azzera
gli iteratori interni di WCInput e WCOutput. Per inizializzare il valore di uscita è sufficiente invocare SetOutput(). Per connettere ARI_W ad altre entità dello stesso tipo si devono impiegare le apposite funzioni Add/Remove. Durante l'inserimento vengono passate le CONNSPEC da utilizzare all'interno della connessione. Internamente viene conservata una _inputList che contiene le ARI_WConnection stabilite con altre entità trasmittenti. Per motivi di efficienza viene inoltre conservata una _outputList che contiene i riferimenti agli ARI_W riceventi. Tale informazione è ridondante ma consente di connettere in maniera efficiente le entità riceventi in caso, per esempio, di distruzione dell'entità trasmittente. Per enumerare le ARI_WConnection di input e le ARI_W di output usare First/End/Next/Get. GetOutput() ritorna l'output corrente, che è assegnabile e reso disponibile con SetOutput() ed è aggiornato e reso disponibile con Update(). Update() non aggiorna gli Inputs correnti, che invece sono assegnati e resi disponibili tramite SetInput(). ARI_WConnection<OUTDATA,CONNSPEC> rappresenta una connessione tra due ARI_W e la connessione è inglobata nell'entità ricevente. All'interno della connessione è memorizzato il riferimento all'entità trasmittente, ossia il valore OUTDATA dell'uscita di quest'ultima, ed infine la CONNSPEC che contiene le informazioni aggiuntive introdotte nelle entità derivate da ARI_W. I valori della connessione saranno aggiornati e sincronizzati dall'entità ARI_W ricevente, proprietaria della connessione stessa. SetInput() dell'entità ricevente si occuperà di invocare GetOutput() sull'entità trasmittente e di memorizzare l'informazione di tipo OUTDATA. La CONNSPEC sarà utilizzata per consentire l'utilizzo di parametri di connessione non previsti da ARI_W.
Il passaggio logico successivo è riunire insieme vari ARI_W in modo da rendere possibile la loro comunicazione. Per fare questo abbiamo costruito ARI_WGroup, che è un
ARI_3DObject e rappresenta una collezione di ARI_W. Il costruttore di default imposta i flag di Render(), SetInput() e Update() e azzera l'iteratore interno di W. Il gruppo può essere popolato per mezzo delle apposite funzioni Add/Remove. I messaggi di Render(), SetInput() ed Update() sono propagati ad ogni entità ARI_W in base agli appositi flags. Le connessioni possono essere realizzate tramite proiezioni per mezzo delle apposite funzioni Add/Remove, impostando il tipo di proiezione:
- ARI_PROJECTION_FLAG_NTON: connette tutti i neuroni di uno strato con quelli di un altro, ed è contemplato il caso particolare in cui i due strati coincidano (come nella connessione rientrante di CA3);
- ARI_PROJECTION_FLAG_1TO1: connette i neuroni omologhi di due strati con le stesse dimensioni;
- ARI_PROJECTION_FLAG_UNIRND: connette in modo casuale i neuroni di due strati, il numero di connessioni è dato da: probabilità_di_connessione*num_unità_mittenti; - ARI_PROJECTION_FLAG_GP1TO1: connette tutti i neuroni di uno slot mittente con tutti i neuroni dell’omologo slot ricevente ( è il modo in cui è realizzato il collegamento invertibile EC_in ->CA1 ->EC_out).
Internamente, ARI_WGroup conserva una lista di riferimenti ad ARI_W ed, essendo un ARI_3DObject, può essere inserito in ARI_3DWorld.
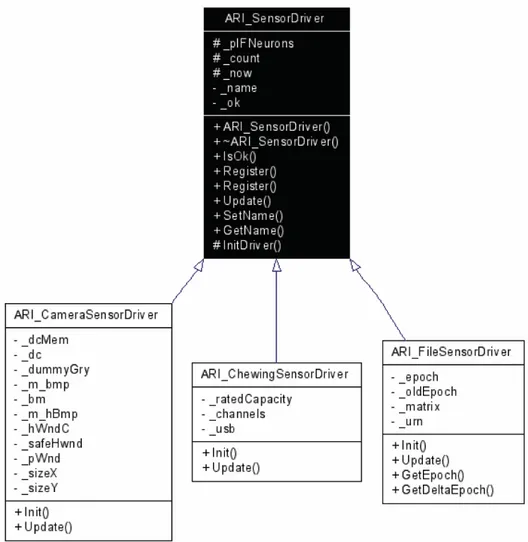
Il sistema ARI comunica con il mondo esterno grazie a ARI_SensorDriver, che lo connette al sistema sensoriale. In generale l'interfaccia è realizzata per mezzo di IFNeurons, neuroni Integrate-and-Fire, disattivando i flags di SetInput() ed Update() ed utilizzandoli come una sorta di buffer. Tale soluzione, tenuto in considerazione la natura digitale dei dati di basso livello in ingresso, consente di non perdere di generalità, consentendo al driver, in fase di
Update(), di imporre l'output degli IFNeurons coinvolti. Al proprio interno ARI_SensorDriver conserva un vettore dinamico di riferimenti a IFNeuron. In fase di inizializzazione tale vettore viene allocato dinamicamente tramite la funzione InitDriver(), che deve essere invocata dal driver specifico all'interno di Init(), da ridefinire nella classe appositamente derivata. A seguito dell’intervento di InitDriver(), funzione invocata internamente, sarà possibile registrare gli IFNeurons dall'esterno tramite le funzioni Register(). L'utilizzatore esterno dovrà dunque avere cura di registrare tutti gli IFNeurons richiesti dal driver. Gli IFNeurons registrati non riceveranno più i messaggi di SetInput() ed Update() ed i loro output saranno governati dal driver.
Nel diagramma precedente si possono vedere le relazioni di dipendenza tra la classe fondamentale ARI_SensorDriver e le sue derivate. Nel nostro lavoro è stato necessario solo l’utilizzo di ARI_FileSensorDriver che consente di utilizzare come input un file di testo in formato DataEngine.
Adesso si può entrare nello specifico del nostro modello, a partire dalle specifiche sulle connessioni e sulle unità elementari. La classe ARI_LeabraNeuron è un ARI_W<double, ARI_LeabraNeuronConnectionSpec>, che a sua volta deriva da ARI_W. ARI_LeabraNeuronConnectionSpec è una struttura in cui sono indicati i paramentri specifici delle connessioni Leabra ( i pesi wij, i pesi delle proiezioni, le variabili della
funzione di filtraggio dei pesi, il learning rate) e in cui sono inserite le funzioni per la loro inizializzazione. L’inizializzazione dei pesi, all’interno della ARI_LeabraNeuronConnectionSpec, è gestita dalla classe ARI_Value, una struttura dotata di un flag per la scelta del tipo di funzione di distribuzione casuale con cui inizializzare i pesi e alcune variabili interne per le distribuzioni. Inoltre la classe ARI_LeabraNeuron si occupa di gestire le costanti di tempo per l’aggiornamento dell’ingresso eccitatorio e del potenziale di membrana propri di ogni singolo neurone. Attraverso la funzione privata Process(dt) si occupa del calcolo di g te
( )
ad ogni ciclo di clock per poi passare la corrispondente informazione alla classe che si occupa della gestione dello strato di neuroni: ARI_LeabraNeuronGroup. ARI_ LeabraNeuronGroup è un ARI_WGroup e rappresenta una collezione di ARI_ LeabraNeuron. ARI_LeabraNeuronGroup si occupa di tutte quelle operazioni inerenti il modello che non competono al singolo neurone: calcola il valore dell’inibizione per ogni unità, ordina le unità per inibizione decrescente (sfruttando l’algoritmo QuickSort()) e quindi trova la g ti( )
dell’intera mappa in questione.L’informazione concernente g ti
( )
viene sfruttata da tutti i neuroni per l’aggiornamento del potenziale Vm( )
t , che a sua volta rientra nel calcolo dell’attivazione, valore di uscita dell’unità che al clock successivo diventa l’ingresso per i neuroni a cui è connessa. Finita questa prima parte computazionale, la classe aggiorna i pesi di tutte le unità connesse nella misura che compete a quello strato, con una sorta di sovrapposizione degli effetti, secondo la regola hebbiana.Quelle descritte sopra sono le classi fondamentali della struttura ARI, ma per aumentare la sua efficienza ci siamo serviti di alcune librerie ausiliarie contenenti le istruzioni per operazioni standard di supporto. ARI_FastDynamicArray contiene l’implementazione inline di tutta una serie di azioni sugli array che vanno dall’allocazione dinamica alla distruzione, dalla copia di valori da un’altra lista all’assegnamento, dall’inserzione di un nuovo elemento alla rimozione. Tutte le funzioni sono dichiarate come template. Un’altra libreria di cui abbiamo fatto ampio uso, soprattutto nella generazione dei pattern di attività random e nell’assegnamento dei valori dei pesi nella fase di inizializzazione, è CUrn, una classe template che ha il compito di generare numeri reali casuali tra 0 e 1 senza ripetizione. Infine le operazioni di rendering si appoggiano sulle funzioni incluse nel file ARI_GLUtils, in cui sono definite quattro funzioni: ARI_GLDrawPyramid, ARI_GLDrawCube, ARI_GLViewAlign, ARI_GLDrawColor. ARI_GLDrawPyramid serve per tracciare graficamente le connessioni tra neuroni, con un collegamento di forma piramidale il cui spessore è proporzionale al valore del peso. ARI_GLDrawCube serve per disegnare le unità di uno strato, ARI_GLViewAlign per posizionarle all’interno di uno strato nello spazio bidimensionale, ARI_GLDrawColor per colorarle in modo proporzionale al valore dell’attivazione. Chi si occupa della gestione dell’interfaccia
grafica è glCDialog che costruisce la finestra in cui si può visualizzare l’evoluzione nel tempo del nostro modello. glCDialog insieme con MKeyboard permette di effettuare alcune semplici operazioni sull’immagine: rotazione, shift, traslazione rigida, ricollocazione al centro della finestra, selezione con il mouse di singoli neuroni e pesi con loro visualizzazione dell’attivazione e dei wij.
La gestione del modello avviene attraverso i file MainFrm.h e MainFrm.cpp che sono rispettivamente l’interfaccia e l’implementazione della classe CMainFrame. Il file di estensione .h contiene la dichiarazione pubblica degli attributi di tutti gli strati in gioco (Input, EC_in, EC_out, DG, CA1, CA3) e delle funzioni di costruzione, di inizializzazione e di aggiornamento implementate nel dominio Leabra. Nel file MainFrm.cpp si ha innanzitutto una serie di istruzioni preliminari atte alla diagnostica della memoria coinvolta nell’applicazione corrente, poi attraverso la funzione Init() avviene il posizionamento nello spazio bidimensionale all’interno della finestra di dialogo delle mappe di neuroni ippocampale. Lo strato Input, che è una sorta di buffer tra il mondo esterno e la nostra struttura, legge i dati da un file di testo in cui erano stati preventivamente registrati in un formato opportuno i pattern di attivazione casuale delle liste AB e AC. Tramite le funzioni InitSpec e InitLearn, dichiarate e definite in ARI_LeabraNeuronConnectionSpec, inizializza tutti i parametri di tutte le proiezioni e per ognuna di esse invoca AddInputFrom, a cui viene passato il riferimento allo strato, il riferimento al tipo di funzione di inizializzazione dei pesi e il riferimento alla specifica della connessione. Poi vengono inizializzate le variabili proprie di un insieme di neuroni (k e q per il calcolo dell’inibizione di tipo k-WTA).
3.5 Conclusioni
Questa tesi si trova a dover affrontare questioni inerenti le neuroscienze cognitive computazionali per risolvere un problema ricorrente nella modellizzazione di sistemi biologici: analizzare e interpretare segnali derivanti dall’implementazione di sistemi biomimetici, come ad esempio accade per segnali provenienti da un naso elettronico o da un sistema di navigazione spaziale. Ci siamo avvicinati alle neuroscienze da una prospettiva connessionista e costruttivista: solo ricreando le condizioni biologiche di un sistema naturale si possono studiare al calcolatore i processi che si instaurano nel cervello per poi simularne particolari aspetti, e solo il funzionamento del modello dimostra la validità dei principi su cui esso è fondato. A questo punto la scelta è caduta, quasi seguendo una strada obbligata, sull’ippocampo, struttura che all’interno del sistema nervoso centrale svolge un ruolo di “binding” delle informazioni mappate nella corteccia ed è fondamentale nella decodifica di nuove informazioni e nella formazione di associazioni rapide finalizzate a guidare i comportamenti che a noi interessava simulare e sfruttare. Siamo partiti dalla teoria classica delle reti neurali su cui abbiamo innestato il modello Leabra, che tende a superare lo schematismo dei neuroni formali. Esso, partendo dalla descrizione di Hodgkin e Huxley, è adattato alle esigenze implementative di compromesso tra velocità di calcolo e verosimiglianza biologica, tiene conto di molti aspetti del neurone reale: eccitabilità e inibizione, ruolo regolatore di set-point degli interneuroni inibitori, raggruppamento in strati e proiezioni, apprendimento dall’esperienza. Abbiamo utilizzato tale unità di base come appoggio su cui fondare il nostro modello di ippocampo. Il nostro intento era cogliere non tanto i meccanismi della formazione ippocampale nella sua interezza quanto il suo ruolo nella risoluzione del
problema della memoria a breve termine e per fare questo abbiamo riprodotto, con inevitabili ma necessarie semplificazioni, la topologia delle regioni e delle connessioni. Siamo quindi partiti dall’ippocampo reale e attraverso una schematizzazione a blocchi siamo giunti ad un modello di massima che ne rispettasse appunto la topologia. Quindi siamo passati all’implementazione software della struttura e su di essa abbiamo anche simulato il test clinico AB-AC per la stimolazione e la misura dell’associatività a breve termine della memoria. Con reti neurali standard tale test non può essere effettuato perché si presentano dei livelli inaccettabili di interferenza catastrofica, ossia dopo che una rete ha appreso le corrette associazioni tra le liste A e B, se le vengono fatte studiare quelle tra A e C, essa dimentica completamente e per sempre la correlazione AB. La nostra rete invece non soffre di questo problema e riesce a mantenere un ricordo ragionevole delle associazioni precedentemente studiate, con un livello di richiami corretti intorno al 50%, confrontabile con i dati sperimentali presenti in letteratura che si attestano attorno al 60%. Abbiamo quindi da un lato compiuto una verifica della validità del modello e del suo corretto funzionamento, dall’altro ottenuto l’implementazione di una rete che riesce a risolvere i problemi di memoria a breve termine insorgenti nell’interpretazione di dati provenienti da sistemi biomimetici.
Uno dei possibili utilizzi futuri della rete può consistere nello sfruttare l’associatività non con le parole, come avviene nel test clinico a cui ci siamo ispirati, ma ad esempio per il controllo di dati provenienti da sistemi artificiali. Solo per citare un caso studiato presso il centro “E. Piaggio”, possiamo pensare di adattare il pattern d’ingresso ai dati provenienti da un sensore olfattivo elettronico, e classificare un campione di oli in base al tipo e alla provenienza. Il risultato così ottenuto sarebbe duplice: da un lato la classificazione di
informazioni in gruppi di appartenenza scorrelati classicamente richiederebbe due reti, mentre con il nostro modello un’unica rete sarebbe in grado di supportare questa scelta, dall’altro si avrebbe un “enhancement”, un miglioramento delle prestazioni, perché la capacità di associazione olfattiva nell’uomo è molto meno spiccata che quella basata sui vocaboli.