4 - Descrizione dell'architettura del
sistema.
Lo studio del sistema per la stabilizzazione video può essere diviso in tre parti macroscopiche:
1. calcolo dei vettori di moto; 2. stima del movimento;
3. filtraggio dei movimenti veloci delle immagini.
Ognuna di questa tre parti costituisce un macro-blocco all'interno dell'hardware programmabile. L'FPGA deve anche interfacciarsi con altri componenti hardware integrati sulla scheda:
● memoria esterna, ● decoder video, ● encoder video.
Il dispositivo di memoria esterna è l'unico dispositivo tra quelli descritti sopra che è completamente controllato dalla FPGA ed e a suo utilizzo esclusivo. L'encoder video, una volta acceso, inizia a mandare in uscita il flusso video digitalizzato con lo standard digitale Y 4:2:2. Analogamente l'encoder video, dopo che è stato acceso, si aspetta in ingresso un segnale video digitale Y 4:2:2. Tra il flusso video uscente dal decoder e il flusso video entrante nell'encoder vi è il dispositivo FPGA. Questo, facendo uso della memoria esterna che è dedicata esclusivamente a questo dispositivo, realizza la stabilizzazione video e fornisce il flusso video risultante in ingresso all'encoder.
4.1 - Interfaccia con il decoder.
La prima interfaccia realizzata all'interno del dispositivo programmabile è quella con il decoder. Questo è configurato per fornire in uscita un clock LCC2 a 13.5 Mhz e 16 bit ogni fronte in salita del clock riguardanti un pixel dell'immagine: 8 bit per la luminanza e 8 per i segnali di colore Cr e Cb trasmessi alternati. Oltre a queste uscite, il decoder alimenta altre segnali molto importanti per la ricostruzione del sincronismo e il riconoscimento delle immagini all'interno del flusso video:
● HS: segnale di sincronismo orizzontale; ● VS: segnale di sincronismo verticale;
● FIELD: segnale di sincronismo di campo che identifica se vengono
trasmesse le righe pari o quelle dispari.
Questo set di segnali sono utilizzati dalla FPGA per riuscire a identificare l'inizio dell'informazione utile all'interno del flusso video. Il segnale di sincronismo più utile tra quelli citati è senza dubbio il clock in uscita dal dispositivo. Per riuscire a campionare correttamente le informazioni uscenti dal decoder si è scelto di collegare LCC2 all'ingresso di un registro alimentato con il clock interno della FPGA a 108 Mhz: quando LCC2 passa da un livello logico basso a uno alto, il flip-flop D edge triggered (DFF) manda in uscita un segnale alto. Successivamente una macchina a stati verifica che il segnale di clock LCC2 continui a rimanere a un livello logico alto, quindi genera un segnale di enable, per un ciclo di clock, che permette ai registri di ingresso della FPGA di campionare i dati. In questo modo si riesce a sincronizzare l'uscita dei dati a 13.5 Mhz con l'ingresso della FPGA che campiona i dati a 108 Mhz. È necessario notare che il clock in uscita dal decoder non è molto preciso e quindi potrebbe accadere che vari la distanza, in termini di cicli di clock, tra il campionamento di un dato e quello successivo. Questo significa che, tra la ricezione di un dato dall'encoder, e la ricezione del dato successivo ci possono essere un numero di cicli di clock interno alla FPGA, oscillante tra 7 e 9. Questa
particolarità deve essere considerata nello sviluppo di tutto il progetto successivo. Per questo i dati in uscita dal blocco di sincronizzazione sono sempre affiancati da un segnale di enable che attiva le varie parti del sistema.
Dopo aver sincronizzato i dati provenienti dal decoder con il clock interno alla FPGA, si inviano i dati campionati al blocco successivo che opera varie funzioni.
In questa fase si riorganizzano i dati acquisiti per essere utilizzati dal resto del sistema. I dati ricevuti da questo blocco sono sincroni con il clock interno della FPGA, ma devono essere interpretati per riuscire a estrapolare la parte di informazione utile. Il segnale di sincronismo orizzontale passa da un livello logico alto ad uno basso, 2 cicli di clock dopo che è terminata la trasmissione di una parte dell'informazione utile e Illustrazione 4 2: Diagramma a blocchi del circuito di interfacciamento con il decoder video.
successivamente passa da basso ad alto dopo un altro ciclo. Quindi, sapendo che una riga è formata da 864 cicli ci clock LCC2 e che l'immagine è composta da 720 pixel, si ricava che dopo 141 cicli di clock LCC2 rispetto al fronte in salita del segnale HS, inizia la trasmissione dell'informazione di riga. Il blocco in questione contiene al suo interno un contatore che permette di calcolare il giusto numero di impulsi del segnale di enable: a ogni fronte in salita del clock LCC2 corrisponde un segnale di enable e un aggiornamento dei dati in uscita. In questo modo si riesce a determinare l'inizio della trasmissione di una riga dell'immagine.
Non tutte le righe, però, contengono informazioni riguardanti l'immagine. Il segnale di sincronismo VS specifica quali righe contengono informazioni. Quest'ultimo resta a un livello logico basso dalla riga 1 alla 22, dalla riga 311 alla 335 e dalla 624 alla 625. Questo significa che in tutte le altre righe è abilitato e proprio queste contengono l'informazione. Utilizzando HS, VS e un po' di logica interna alla FPGA si riesce a calcolare il punto esatto dove inizia e termina la trasmissione dell'immagine. L'ultimo segnale di sincronismo informa semplicemente se vengono trasmesse le righe pari (livello logico alto) o quelle dispari (livello logico basso). Quindi si genera in uscita dei segnali di sincronismo, compresa la trasformazione in riga, colonna e campo del pixel arrivato.
Uno dei compiti di questo blocco è quello di fornire in uscita esclusivamente la parte del flusso video contenente l'informazione sull'immagine. Questa viene anche rielaborata internamente al blocco per formattarla in modo che possa essere memorizzata sulla memoria esterna. I dati dell'immagine reale, cioè quella proveniente direttamente dal decoder, vengono rielaborati in modo tale che: all'indirizzo zero della memoria ci sia il primo pixel dell'immagine, alla locazione 720 della memoria ci sia il primo pixel della seconda riga dell'immagine e così via. In questa fase di organizzazione dei dati, però, si opera anche un conversione di questi ultimi in modo tale che sia possibile sfruttare tutti i
18 bit appartenenti a una locazione della memoria esterna. Gli 8 bit della luminanza Y, vengono memorizzanti nella parte alta della locazione di memoria, mentre nei restanti 12 bit vengono memorizzate le informazioni di colore per Cb (6bit più significativi) e Cr (6 bit più significativi). Sostanzialmente si duplicano le informazioni relativa al colore, in modo tale che accedendo alla memoria per recuperare l'immagine, si conosca subito sia la componente di luminanza che di colore di quel pixel. Questa tecnica molto utile per la ricostruzione del flusso video in uscita dalla scheda, comporta degli svantaggi. Infatti, nello standard di trasmissione Y 4:2:2 utilizzato dal decoder, le informazioni sul colore sono composte da 8 bit e non da 6: i colori sullo schermo risultano leggermente differenti da quelli reali.
I dati così ottenuti vengono inviati al blocco di interfaccia con la memoria. Oltre a questa operazione, il blocco in esame effettua il filtraggio e sotto-campionamento delle immagini reali 720 x 576 pixel. Per effettuare il filtraggio dell'immagine senza dover aspettare l'arrivo di tutti e due i semi-quadranti si è scelto di utilizzare soltanto il campo iniziale delle immagini e di considerare solo parzialmente l'altra parte delle righe. In questo modo è come se si avesse subito a disposizione l'immagine e quindi è possibile filtrarla e sotto-campionarla in modo tale da ottenere una immagini di 360 x 288 pixel. Per ridurre ulteriormente i calcoli e minimizzale le risorse sulla FPGA si è scelto di utilizzare esclusivamente la componente di luminanza per effettuare la stabilizzare. Il filtraggio e sotto-campionamento dell'immagine viene fatto semplicemente effettuando una media dei valori a disposizione:
● nel caso di sotto-campionamento di fattore due dell'immagine si
effettua un media con due pixel della stessa riga del semi-quadrante: sotto-campionamento delle colonna di fattore due;
● nel caso di sotto-campionamento di fattore quattro dell'immagine si
riga del primo semi-quadrante e gli altri quattro appartenenti alla seconda riga dello stesso quadrante: sotto-campionamento delle colonna di fattore quattro e delle righe di fattore due.
Una volta effettuato il calcolo è necessario memorizzare entrambe le immagini ottenute in modo tale che possano essere recuperate e rielaborate. Per questo motivo si è scelto di memorizzare entrambe le immagini nella memoria esterna alla FPGA, infatti la memoria dell'hardware programmabile ha dimensioni ridotte e non è in grado di contenere le immagini. Per questo motivo si è scelto di inserirle nella memoria esterna, arrotondando per eccesso il numero di banchi di cui hanno bisogno. Questo significa che alla immagine di dimensioni reali sono dedicati 51 banchi da 8 kbit della memoria esterna, 7 per l'immagine sotto-campionata due e 2 per quella sotto-campionata di fattore quattro. Inoltre è anche necessario fornire l'indirizzo di memoria al controllore della memoria esterna per riuscire a inserire il dato in memoria. Mentre i dati dell'immagine reale occupano 18 bit, quelli delle immagini sotto-campionate, ne occupano soltanto 8; infatti sono la media dei valori di luminanza dei pixel dell'immagine reale. Per questo motivo si è scelto di inserire due dati delle immagini sotto-campionate in ogni locazione della memoria esterna. Inoltre potrebbe accadere che i risultati del filtraggio siano pronti allo stesso ciclo di clock, per questo di è scelto di regolare gli accessi alla memoria tramite un multiplexer che permette l'inserimento dei dati in memoria in modo ciclico: prima i dati dell'immagine reale, poi quelli dell'immagine sotto-campionata due e infine quelli dell'immagine sotto-campionata quattro. I pixel dell'immagine sotto-campionata quattro sono anche i primi che devono essere utilizzati per il calcolo dei confronti, come descritto nell'algoritmo di ricerca gerarchica. Per questo motivo vi è un collegamento diretto tra questo blocco e il macro-blocco che consente il calcolo dei vettori di moto.
4.2 - Calcolo dei vettori di moto.
Il macro-blocco per il calcolo dei vettori di moto è composto da più parti. Il blocco che riceve direttamente i dati dell'immagine sotto-campionata quattro è il processore per il calcolo della somma delle differenze in valore assoluto tra pixel. I pixel forniti dal blocco di interfaccia con il decoder video entrano in questo blocco come pixel dell'immagine corrente.
La differenza tra il valore di luminanza del pixel dell'immagine di riferimento e quello dell'immagine corrente viene memorizzata in una piccola memoria interna alla FPGA che memorizza i risultati parziali delle somme di ogni singolo elemento.
A questo punto è necessario capire come implementare l'algoritmo SAD sul dispositivo. Le operazioni necessarie per il calcolo di questo algoritmo nella immagine reale sono molte e di diverso tipo. Supponendo di dover calcolare un vettore di moto utilizzando le dimensioni minime date dalle specifiche, il numero i differenze in valore assoluto risulterebbe essere:
operazioni di differenza e valore assoluto per un singolo vettore di moto. Queste effettuate alla frequenza di 108 Mhz
necessitano di s Mhz 0.023704 108 1 16 16 100 100⋅ ⋅ ⋅ ⋅ = secondi per
calcolare un unico vettore di moto. Questo risultato consentirebbe di calcolare un unico vettore di moto, infatti il tempo necessario per la trasmissione di un campo di un frame è di 0.02 s. Se invece si applica il calcolo del SAD alle immagini sotto-campionate di fattore due si ottiene che l'immagine di riferimento passa da 16 x 16 pixel a 8 x 8; analogamente l'area di ricerca si riduce da 116 x 116 pixel a 58 x 58. In questo caso il numero di operazioni da svolgere sarebbe:
(
50− 8+ 1) (
⋅ 50− 8+ 1)
⋅8⋅8= 166464, corrispondenti a(
) (
)
s Mhz 0.001541 108 1 8 8 1 8 50 1 8 50− + ⋅ − + ⋅ ⋅ ⋅ = . Considerando, però, 2560000 16 16 100 100⋅ ⋅ ⋅ =che si vogliono calcolare almeno 200 vettori di moto, sarebbero necessari ben 0.001541s⋅200 = 0.308200s. Si nota subito che tale periodo corrisponde all'arrivo di più fotogrammi dal decoder, che non possono essere presi in considerazione perché si sta ancora calcolando i vettori di moto per una altra immagine.
Se si effettua il confronto con immagini sotto-campionate di fattore quattro, il blocco di riferimento assume dimensioni di 4 x 4 pixel, mentre l'area di ricerca deve essere almeno di 29 x 29 pixel. Con questi dati si ottiene che il tempo necessario per il calcolo dei 200 vettori di moto è leggermente superiore ai 20 ms: 24.9185 ms. Questo caso assicura di poter eseguire i calcoli nel tempo richiesto. Per avere un po' di margine sul calcolo sulla dimensioni dei vettori di moto e soprattutto per migliorare le qualità del sistema di stabilizzazione si è scelto di utilizzare blocchi di riferimento di 4 x 4 pixel, con un area di ricerca di 36 x 36 pixel: equivalenti a blocchi di riferimento di 16 x 16 pixel nell'immagine reale con un area di ricerca di 144 x 144 pixel. Si calcola che sono necessari
(
36 − 4+ 1) (
⋅ 36 − 4+ 1)
⋅ 4⋅4 = 17424 confronti per il calcolo di ogni vettoredi moto nell'immagine sotto-campionata quattro; quindi considerando i 200 vettori voluti dalle specifiche si ottiene che il tempo necessario al calcolo è di 32.2667 ms. Per migliorare ulteriormente il progetto si è scelto di calcolare un numero di vettori superiore a quello richiesto seguendo uno schema che consente di suddividere l'immagine di riferimento in 266 blocchi. Con le dimensioni date si ottiene che per eseguire i calcoli per i 266 vettori di moto sono necessari 42.9147 ms. Questo periodo di tempo è leggermente superiore al periodo di tempo necessario affinché sia acquisita una intera immagine, ma non comporta problemi, perché è sufficiente moltiplicare le risorse sull'hardware per riuscire a diminuire i tempi di elaborazione. Nel caso dell'immagine sotto-campionata due è possibile moltiplicare le risorse hardware per riuscire ad implementare l'algoritmo, ma sono necessari tanti processori per il calcolo
del SAD quanti sono i vettori da calcolare in tempo reale. Se si implementasse questa tecnica sull'hardware si sarebbero sicuramente saturate tutte le risorse disponibili.
Bisogna notare che l'algoritmo di ricerca piramidale prevede una ricerca, non solo nell'immagine sotto-campionata quattro, ma anche in quella sotto-campionata due e in quella a dimensioni reali. Questo comporta che, una volta terminato il calcolo dei vettori di moto per l'immagine sotto-campionata quattro, si inizi la ricerca sull'immagine sotto sotto-campionata due. Si deve effettuare una ricerca su di un area di 9 x 9 pixel con il blocco di riferimento (8 x 8 pixel) centrato sulla posizione a cui punta il vettori di moto precedentemente calcolato e raddoppiato nelle dimensioni. In questo modo si ottiene un nuovo vettori di moto che varia di ±1 pixel rispetto alla dimensione raddoppiata del primo vettore trovato. Questo procedimento dovrebbe essere fatto anche per l'immagine a dimensioni reali con blocchi di riferimento di 16 x 16 pixel e un area di ricerca di 17 x 17 pixel. In questo caso però si è scelto di non effettuare il calcolo perché aspettare l'arrivo di un frame completo avrebbe comportato di per se una attesa di 40 ms. Si rischia quindi di non riuscire a soddisfare le specifiche di latenza dell'immagine all'interno dello stabilizzatore. Oltre al tempo necessario per il calcolo dell'immagine sotto-campionata quattro è anche necessario considerare il tempo necessario al calcolo dei vettori di moto nell'immagine sotto-campionata due. Data l'area di ricerca di 9 x 9 pixel e una immagine di riferimento di 8 x 8 pixel si ottiene che il tempo di elaborazione per il numero totale di somme di differenze in valore assoluto
è:
(
) (
)
s Mhz 299µ 108 1 8 8 1 8 9 1 89 − + ⋅ − + ⋅ ⋅ ⋅ = . È un periodo molto minore
rispetto al tempo necessario al calcolo dei vettori di moto nell'immagine sotto-campionata quattro.
La scelta dei blocchi dell'immagine di riferimento da utilizzare è stata fatta considerando un nucleo centrale dell'immagine. Infatti prendere delle
immagini di riferimento che distano del bordo dell'immagine meno della lunghezza del vettore di moto, è poco pratico per l'esecuzione dei calcoli e si rischierebbe di calcolare vettori di moto affetti da errore certo: si rischierebbe di calcolare vettori di moto confrontando blocchi completamente diversi. Questo è possibile se un blocco di riferimento non è più inquadrato dalla telecamera perché questa si è spostata. Per eliminare questo problema si sceglie di considerare soltanto un nucleo centrale della immagine di riferimento che dista 16 pixel dal bordo dell'immagine sotto-campionata quattro. In questo modo a meno che l'immagine non si sposti più del vettore di moto, è sempre possibile trovare un confronto significativo.
Illustrazione 4 3: Schema che mostra come vengono scelti i blocchi di riferimento in una immagine sotto-campionata di fattore 4.
La dimensione dell'immagine sotto-campionata quattro è di 144 x 180 pixel, ma soltanto il nucleo centrale di 128 x 164 pixel è utilizzato per l'immagine di riferimento. Se si dividesse questa parte centrale dell'immagine in blocchi di 4 x 4 pixel si otterrebbero 32 x 41 = 1312 blocchi dell'immagine di riferimento. Questo numero di blocchi è ancora troppo elevato per effettuare calcoli in tempo reale e per questo si è scelto di prendere un blocco ogni quattro del nucleo dell'immagine di riferimento. In questo modo si ottengono blocchi in verticale e 18.5
2 1 4 16 16 180− − ⋅ =
in orizzontale. In totale si ottengono 14 x 19 = 266 blocchi per il calcolo dei vettori di moto; equivalenti allo stesso numero di blocchi dell'immagine di riferimento.
Per come è stata divisa una immagine ci si rende conto che una generica area di ricerca, centrata su di un blocco di riferimento, comprende al
massimo 9
16
144 = blocchi in ogni sua dimensione. Ma dato che si utilizza un blocco ogni quattro si ricava che il numero massimo di blocchi dell'immagine di riferimento, che riesce a coprire un area di ricerca è 25. Questo significa che per un generico pixel dell'immagine corrente può servire per il calcolo di 25 blocchi di riferimento.
Per non dover recuperare un grande numero di pixel dalla memoria esterna è necessario riuscire a utilizzare il generico pixel dell'immagine corrente appena questo è disponibile.
Quindi è necessario riuscire a calcolare al massimo 25 vettori di moto contemporaneamente. Per riuscire a realizzare questo obbiettivo è necessario utilizzare parte della memoria interna della FPGA per memorizzarvi i pixel dei blocchi di riferimento e un altra per la memorizzazione dei risultati parziali. La parte di memoria dedicata ai Illustrazione 4 4: La figura rappresenta una immagine in cui sono mostrate tutte le posizioni in cui vengono presi i blocchi di riferimento per il calcolo dei vettori di moto. Inoltre è evidenziato un rettangolo grigio che rappresenta l'area di ricerca con al centro il blocco di riferimento alla quale è legata. Si nota anche che in un'area di ricerca, appartenente all'immagine successiva rispetto a quella da cui sono ricavati i vettori di moto, sono contenuti 25 blocchi di riferimento.
blocchi di riferimento è piccola: 25⋅4⋅ 4⋅8 = 3200 bit per i 25 blocchi necessari al calcolo in tempo reale dei vettori di moto. Questo significa che mano a mano che i dati dell'immagine corrente vengono ricevuti, si devono aggiornare nella piccola memoria interna alla FPGA i dati relativi ai blocchi di riferimento. Gran parte della memoria interna alla FPGA è, invece, utilizzata per la memorizzazione dei risultati parziali del calcolo del SAD. Infatti per non dover più recuperare dalla memoria i dati di una immagine corrente è necessario utilizzare i dati non appena questi sono disponibili e memorizzare il risultato parziale del calcolo del SAD per quel confronto. Ogni area di ricerca contiene 36 − 4 + 1 = 33 blocchi di riferimento per ogni dimensione e ogni pixel dell'area di ricerca deve essere utilizzato per il calcolo del confronto con lo stesso blocco di riferimento al massimo 16 volte. Considerando che si devono calcolare almeno 25 vettori di spostamento contemporaneamente si ottiene che si devono memorizzare 13200 risultati parziali. Sapendo che questi risultati possono essere al massimo di 12 bit, perché ricavati come sommatoria di 16 elementi a 8 bit, si ottiene che il numero di bit da locare nella memoria interna alla FPGA è di 158400 bit. Questo numero è abbastanza piccolo e si potrebbe pensare di poter inserire questi dati nella memoria esterna. In realtà, però, questi dati devono essere disponibili molto rapidamente e più di uno alla volta, quindi si è scelto di lasciarli nella memoria interna e non intasare il flusso di dati con la memoria esterna con il recupero dei risultati parziali del calcolo del SAD.
Il risultato del primo confronto tra i due blocchi è disponibile in tempo reale all'arrivo dei pixel della quarta riga dell'immagine sotto-campionata quattro. Dopo i primi quattro pixel di questa riga è possibile ottenere in uscita il primo risultato del confronto. Con l'arrivo dei pixel successivi della quarta riga saranno disponibili anche gli altri 32 confronti che sono pervenuti calcolando la somma delle differenze in valore assoluto dei primo quadrato di 4 x 4 pixel dell'area di ricerca rispetto al blocco di
riferimento; successivamente si continua ad effettuare questa operazione confrontando l'immagine di riferimento con il secondo quadrato dell'area di ricerca. Il secondo quadrato è di 4 x 4 pixel ed è composto dal secondo, terzo, quarto e quinto pixel delle prime quattro righe dell'immagine corrente. Al trentasei-esimo pixel della quarta riga dell'area di ricerca sono stati calcolati 33 confronti.
Allo stesso tempo, mentre si sta calcolando i valori parziali del SAD della prima riga, duplicando le risorse hardware, è possibile calcolare i risultati parziali del SAD per la seconda riga che deve confrontare l'immagine di riferimento con tutti i pixel della seconda, terza, quarta e quinta riga dell'area di ricerca. Quindi al trentasei-esimo pixel della quinta riga dell'area di ricerca saranno stati calcolati da un altra struttura hardware parallela altri 33 confronti. Si nota, quindi, che è necessario memorizzare soltanto i dati parziali delle ultime quattro righe per il calcolo del SAD, quelle precedenti sono già state utilizzate e non servono più per i calcoli. I risultati ottenuti da queste righe possono essere confrontati tra loro per ricavarne il minimo e quindi il valore del SAD finale. Questo procedimento deve essere effettuato per il calcolo di tutti i vettori di moto che devono essere considerati quando arriva un pixel dell'immagine corrente. È quindi necessario effettuare il calcolo del SAD per 25 vettori di movimento ogni pixel dell'immagine corrente che viene calcolato.
verticale di un'area di ricerca (immagine corrente). I numeri all'interno di un pixel indicano il numero e l'ordine dei 1089 (33 x 33) confronti tra blocchi 4 x 4 che devono essere effettuati tra l'immagine di riferimento e quella corrente per trovare i risultati della somma di differenze in valore assolto. Bisogna notare che il calcolo di una sommatoria si propaga per 4 righe e 4 colonne.
Il processore deve riuscire a calcolare alcuni risultati parziali del SAD. Per effettuare questo calcolo si è scelto di non moltiplicare le risorse, ma di utilizzare una piccola memoria interna alla FPGA che memorizzi i 25 dati all'interno del processore e li ricarichi in memoria a tempo debito. Dopo il trentasei-esimo pixel, i calcoli per il primo vettore di moto sono terminati e per questo si riutilizza la struttura per il calcolo della sesta colonna delle immagini di riferimento. In questo modo il processore SAD viene utilizzato per il calcolo di tutti i vettori di moto.
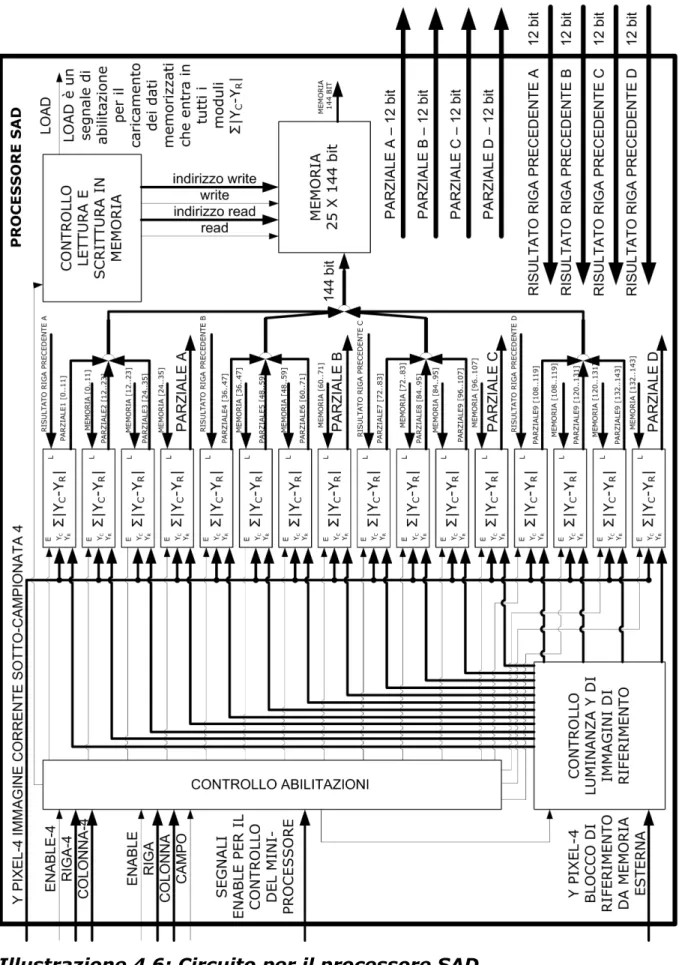
Il processore SAD è composto da 16 blocchi che effettuano la somma della differenze in valore assoluto tra i vari pixel.
Quando arriva un pixel dell'immagine sotto-campionata, questo viene utilizzato per il calcolo di 25 vettori di moto in tempo reale. Il pixel dell'immagine corrente viene caricato nei sedici blocchi e si effettua la differenza tra questo e i pixel dei 25 blocchi di riferimento. I risultati a 12 bit vengono caricati tutti in parallelo in una memoria interna alla FPGA che ha 25 locazioni da 144 bit, cioè 12 x 12 bit. Il dato in uscita dal primo blocco viene memorizzato come dato parziale e viene mandato a caricare il sommatore del secondo blocco. In questo modo quando arriva il quarto pixel dell'immagine è già possibile mandare in uscita un risultato parziale per il calcolo del SAD alla memoria di grandi dimensioni.
All'arrivo del primo pixel dell'immagine sotto-campionata 4, soltanto il primo elemento per il calcolo delle differenze in valore assoluto è attivo. Questo realizza il modulo della differenza tra il pixel dell'immagine corrente e quello dell'immagine di riferimento, pre-caricato nell'elemento da parte del controllore della luminanza Y per l'immagine di riferimento. Quindi somma a questo valore quello proveniente dai risultati parziali del SAD precedenti, che nel caso non sono presenti e quindi somma zero. Il risultato della sommatoria viene inserito in memoria insieme a tutti i gli altri risultati, ma dato che è l'unico abilitato, tutti gli altri elementi forniscono tutti zero in uscita. Quando arriva il secondo pixel dell'area di ricerca vengono attivati due elementi SAD: il primo effettua il modulo della differenza tra il secondo pixel dell'area di ricerca e il primo pixel dell'immagine di riferimento e vi somma zero; il secondo effettua il modulo della differenza tra il secondo pixel dell'area di ricerca e il secondo pixel dell'immagine di riferimento e vi somma il risultato calcolato dal primo elemento SAD all'arrivo del primo pixel dell'area di ricerca. Al giungere del terzo pixel dell'immagine corrente vengono attivati tre elementi SAD: il primo, analogamente al caso precedente, calcola il modulo della differenza tra il pixel appena arrivato e il primo dell'immagine di riferimento e vi somma zero; il secondo elemento SAD effettua i calcoli tra il pixel appena arrivato e il secondo dell'immagine di riferimento e vi somma il risultato parziale del SAD calcolato dal primo blocco all'arrivo del pixel precedente rispetto a quello attuale; il terzo elemento restituisce il modulo della differenza tra il terzo pixel dell'immagine corrente e il terzo pixel dell'immagine di riferimento e vi somma il risultato precedentemente calcolato dal secondo elemento. Quando arriva il quarto pixel dell'area di ricerca sono attivi quattro blocchi e effettuano tutti la stesse operazioni, soltanto che gli elementi SAD 2, 3 e 4 sommano al modulo della differenza il risultato del SAD dell'elemento precedente: calcolato al pixel all'arrivo del pixel precedente, memorizzato
nella memoria e recuperato. Il primo elemento continua a sommare zero. Il risultato del quarto elemento SAD non viene memorizzato da memoria locale, ma viene mandato all'esterno del blocco per essere memorizzato nella memoria globale del processore SAD. Questo dato viene recuperato all'arrivo della seconda riga dell'immagine corrente, per essere sommato al risultato del modulo della differenza del primo elemento. In questo momento viene attivato anche il quinto elemento per il calcolo del SAD, che calcola il modulo della differenza tra il primo pixel della seconda riga dell'immagine di riferimento e quello dell'immagine corrente. All'arrivo del quarto pixel della seconda riga sono stati attivati i primo otto elementi del mini-processore e vengono mandati in uscita da quest'ultimo altri valori parziali che devono essere memorizzati, nella memoria globale, per il calcolo della riga successiva. Procedendo in questo modo al termine della trasmissione della quarta riga di area di ricerca è terminato il calcolo dei primi 33 valori dell'algoritmo SAD e sono stati utilizzati tutti e 16 gli elementi per il calcolo del SAD. I risultati SAD(1,j) vengono trasmessi dal quarto elemento verso l'esterno del processore: è possibile confrontare tra loro i risultati e quindi iniziare immediatamente il calcolo del minimo. Trovare il minimo significa trovare la posizione all'interno dell'area di ricerca dove vi è il confronto ottimo, per questo al termine dei paragoni, non si memorizza il valore del minimo, ma la sua posizione.
Al termine della trasmissione della quinta riga dell'immagine corrente, l'ottavo elemento sarà in grado di fornire in uscita i valori del SAD(2,j) e il primo elemento per il calcolo del SAD inizierà i calcoli per riuscire a trasmettere nel corso dell'ottava riga i dati SAD(5,j).
Il procedimento sopra esposto consente di calcolare in tempo reale i valori del SAD(i,j) di un blocco di riferimento rispetto alla sua area di ricerca. Utilizzando i soliti elementi circuitali e aumentando la complessità della logica di controllo è possibile utilizzare il processore per calcolare più risultati parziali durante la trasmissione di un pixel. Per come sono state
scelte le posizioni dei blocchi di riferimento e le dimensioni delle aree di ricerca, succede che un pixel dell'immagine corrente deve essere utilizzato per più aree di ricerca. Per questo motivo si è scelto di non aumentare ulteriormente il numero di processori SAD, ma di utilizzare lo stesso e di utilizzare più memoria. Infatti un generico pixel vicino al centro dell'immagine corrente deve essere utilizzato per il calcolo del SAD da 25 blocchi di riferimento. Quindi si è scelto di creare un unico processore e di utilizzarlo per tutti e 25 blocchi di riferimento, senza moltiplicare ulteriormente le risorse hardware. Infatti l'informazione sull'immagine corrente è sempre la stessa, mentre per calcolare i valori del SAD su più blocchi è sufficiente cambiare i pixel dell'immagine di riferimento che sono contenuti all'interno del blocco controllore della luminanza Y. Con questo metodo è possibile realizzare tutti i calcoli per tutti i blocchi di riferimento, prima dell'arrivo del pixel successivo. È stato possibile realizzare questa struttura perché la frequenza di clock a 108 Mhz, interna alla FPGA e imposta dalle specifiche di temperatura, consente di avere a disposizione dai 28 ai 36 cicli di clock, tra un pixel e l'arrivo del successivo. In teoria la distanza tra due pixel dovrebbe essere di un ciclo di clock a 13.5 Mhz, equivalente a otto cicli di clock a 108 Mhz. In realtà, però, il clock uscente dal decoder è molto poco preciso e quindi può accadere che due fronti in salita distino da 7 a 9 cicli di clock interno alla FPGA a 108 Mhz. Per assicurarsi che tutto funzioni correttamente è necessario che tutte le operazioni per il calcolo del SAD terminino entro 28 cicli di clock della FPGA. Per questo motivo si è scelto di realizzare una struttura hardware a pipeline che permette di eseguire tutti i calcoli in sequenza. Per effettuare tutti i calcoli, è necessario iterare il procedimento di somma di modulo della differenza per al massimo 25 volte, inferiore ai 28 cicli di clock che distanziano, come minimo, due pixel dell'immagine sotto-campionata 4. Per questo motivo è stato possibile realizzare tutti i calcoli utilizzando una unica struttura hardware. Inoltre, anche se un dato dovesse arrivare
prima che l'ultimo pixel sia stato processato, ciò non comporta errori, perché la memoria interna al processore è a doppia porta e consente le lettura e scrittura di dati in contemporanea, con la particolarità di fornire il dato più vecchio in uscita, nel caso in cui vi sia una lettura e scrittura contemporanea della solita cella di memoria.
Il processore SAD ha 4 uscite che entrano sia nella memoria globale, sia in un blocco di selezione dei dati validi. Il funzionamento interno del processore, descritto precedentemente, è valido per il calcolo di un vettore di moto, se si vogliono calcolare più vettori è necessario iterare il procedimento; ma ogni volta che si inizia il calcolo di un blocco si dovrebbero abilitare alcuni elementi e disattivarne altri. Il blocco di selezione sceglie quali dati sono il risultato del calcolo del SAD(i,j) e li invia al blocco che cerca il minimo.
Iterando il processo di calcolo, tenendo fisso il pixel dell'immagine di riferimento e facendo cambiare i pixel del blocco di riferimento, si creano dei problemi sulle abilitazioni. Per esempio, quando il calcolo del primo blocco di riferimento è arrivato al decimo pixel, quello per il calcolo del secondo blocco è soltanto al secondo; per questo, inizialmente dovevano essere attivati 10 elementi per il calcolo del SAD, poi soltanto due. Inoltre anche il segnale di caricamento deve essere modificato per seguire le variazioni richieste dal calcolo. Per questo motivo è necessario un circuito che selezioni i dati validi conoscendo sia la riga che la colonna dell'immagine sotto-campionata 4.
Illustrazione 4 7: Schema circuitale del blocco che effettua il calcolo del SAD, fornendo in uscita le informazioni di traslazione orizzontale e verticale del blocco di riferimento rispetto a quello corrente.
La ricerca del minimo dell'algoritmo SAD viene effettuata utilizzando un blocco dedicato che riceve in ingresso i dati forniti dal blocco di mascheramento e selezione per riuscire a trovare il minimo di ogni singolo blocco di riferimento. Questo circuito viene abilitato ogni volta che viene selezionato un dato valido, confronta il valore del SAD(i,j) con quelli precedenti e memorizza sia il minore, sia la sua posizione. Quest'ultima è calcolata utilizzando un contatore, infatti per ogni vettore di movimento si ottengono 1089 valori SAD(i,j) che sono forniti in ordine dal processore: 33 per riga. Quindi, conoscendo il valore del contare, è possibile capire la posizione del blocco che ha dato il miglior confronto. Si è scelto di realizzare un sommatore che incrementata dati contenuti in memoria: quando una locazione arriva a 1089 viene letto il contento della memoria relativo a quel blocco e viene inviata la posizione del minimo a un circuito esterno che trasforma il numero nelle due componenti di traslazione e, conoscendo il blocco di riferimento e l'area di ricerca, fornisce a una memoria l'indirizzo in cui deve essere recuperata l'informazione per il calcolo dell'immagine sotto-campionata 2.
Il termine dei calcoli per il calcolo del SAD nell'immagine sotto-campionata quattro coincide con il termine delle trasmissione del primo semi-quadro di un frame. Appena questo è terminato si iniziano a leggere le 266 posizioni dei pixel nell'immagine sotto-campionata due. Vengono ricavati dalla memoria esterna i pixel per il calcolo del SAD sia del blocco di riferimento, sia quelli dell'immagine corrente, in modo tale che il calcolo del SAD sia immediato e si ottenga subito il valore del vettore di moto. In questo caso si è scelto di organizzare i calcoli diversamente, in modo tale che per il calcolo del SAD siamo necessari soltanto quattro blocchi che effettuano la sommatoria di differenze in valore assoluto. Così facendo ogni elemento calcola un risultato SAD(i,j) e il calcolo termina pochi cicli di clock oltre il recupero dalla memoria dell'ultimo pixel.
Illustrazione 4 8: Elemento per il calcolo del SAD che effettua dirattamente il calcolo di un valore SAD(i,j).
Trovato il minimo del SAD, si ricava la traslazione di ±1 pixel, in orizzontale e verticale. Il calcolo del minimo in questo caso è molto semplificato e non si fa uso della memoria perché si calcolano soltanto quattro valori del SAD. A ogni elemento per il calcolo del SAD viene associata una posizione, il blocco che contiene il minimo fornisce l'informazione al blocco successivo. Questa viene sommata alla traslazione, di dimensioni raddoppiate, precedentemente calcolata nell'immagine sotto-campionata quattro. A questo punto il dato è fornito in uscita nelle sue due componenti: traslazione orizzontale e traslazione verticale.
4.3 - Interpretazione dei vettori di moto.
Il calcolo dei vettori di moto ha comportato un notevole dispendio di risorse hardware. Per questo motivo è stato necessario cercare di semplificare molto la seconda parte del progetto.
L'interpretazione dei vettori di moto per il calcolo dello spostamento della videocamera è stato effettuato semplicemente calcolando la moda sulle due direzioni di traslazione, orizzontale e verticale, dei vettori di moto. Calcolare la moda è una operazione molto semplice e che richiede in numero abbastanza limitato di risorse.
Il blocco per il calcolo del SAD fornisce in uscita 266 vettori di moto nelle due componenti orizzontale e verticale. Il calcolo della moda è fatto su ciascuna delle due componenti. Il calcolo della moda ricava la traslazione che si presenta con una frequenza maggiore tra i vettori di moto. Per riuscire a calcolare la moda lungo una direzione di traslazione, si è scelto di realizzare un unico vettore di memoria con 128 locazioni a 9 bit e contare la traslazione che si presenta con maggiore frequenza. La dimensione, orizzontale e verticale, dei vettori di moto corrisponde alla locazione all'interno di un blocco di memoria: la memoria ha 128 locazioni come la dimensione massima dei vettori di moto ±64 pixel. Ogni locazione è composta da 8 bit che consente di memorizzare il numero di volte che si presentano le traslazioni: al massimo 266 come il numero dei vettori di moto. Quando arriva, in ingresso a questo blocco, un vettore di moto, si utilizza l'informazione sulla sua dimensione per effettuare una accesso in Illustrazione 4 9: Schema circuitale che descrive il blocco per l'interpretazione dei vettori di moto.
memoria e leggere la locazione corrispondente alla traslazione. Il contenuto della cella di memoria viene letto, incrementato di uno e memorizzato nuovamente in memoria. Al termine della trasmissione dei vettori di moto si inizia a leggere tutte le locazioni di memoria confrontando una cella con quella successiva a memorizzando il valore interno alla cella e l'indirizzo della sua locazione. Una volta letta la locazione viene cancellato il contenuto inserendo tutti zero. Il contenuto della cella permette di capire quale traslazione si presenta più di frequente e l'indirizzo della locazione coincide con la dimensione della traslazione. Effettuando queste operazioni per entrambe le componenti di traslazione si ricavano le traslazioni orizzontali e verticali che si presentano più di frequente nei vettori di moto. Si sono quindi calcolati i valori di traslazioni dell'immagine.
Le due componenti del moto trovare vengono mandate in uscita verso il blocco di filtraggio.
4.4 - Filtraggio delle oscillazioni dell'immagine.
Il macro-blocco che effettua il filtraggio delle componenti di spostamento dell'immagine è costituito da due parti identiche che filtrano le due componenti delle traslazioni dell'immagine. La scelta del tipo e dell'ordine del filtro è stata fatta in modo approssimativo, dato che non si hanno informazioni precise sulla banda di frequenze che devono essere filtrate: si sa per certo soltanto che deve essere un filtro passa basso. La frequenza massima della banda del filtro deve essere scelta in funzione delle oscillazioni e dei movimenti a cui è soggetta la videocamera. Infatti utilizzare una frequenza massima del filtro troppo bassa o troppo alta può causare disturbi: se si eliminano frequenze troppo basse è possibile che il filtro risulti “lento”; mentre se non vengono filtrate le alte frequenze si rischia di non ottenere una stabilizzazione. Con il termine “lento” siintende un filtro che non riesce a seguire bene le variazioni dell'immagine e che tende ad annullare qualsiasi traslazione dell'immagine. Questo può causare un disturbo perché le immagini visualizzate sono molto lontane da quelle reali e potrebbe accadere che ,eliminando anche le frequenza più basse, il filtro non sia più in grado di restare abbastanza vicino alle variazioni del flusso video. Il risultato visivo è quello di vedere alcune immagini molto terme e ogni tanto degli scatti dell'immagine.
Dato che non è nota la frequenza massima che deve essere filtrata, perché deve essere valutata tramite prove pratiche sul mezzo su cui deve essere installato il sistema di stabilizzazione, si è scelto di realizzare un filtro passa basso del secondo ordine di Butteworth con una frequenza massima in banda di 50 Hz. Questo filtro è stato studiato nel capitolo precedente ed effettuando la trasformazione dal piano s a quello z si ottengono i fattori moltiplicativi del filtro in cui si è impostata una frequenza di campionamento, e quindi un periodo di campionamento τ di
40 ms:
( )
2 2 1 1 2 2 1 1 0 1 − − − − ⋅ + ⋅ + ⋅ + ⋅ + = z z z z z B ϕ ϕ χ χ χfunzione di trasferimento del filtro nel
dominio z, con = = ⋅ = = = 798834 . 0 77619 . 1 799738 . 0 2 799738 . 0 2 1 1 2 0 ϕ ϕ χ χ χ
che corrispondono ai fattori moltiplicativi
dei vari campioni necessari alla realizzazione dello stesso:
( )
n = 0⋅ X( )
n + 1⋅ X(
n− 1)
+ 2⋅ X(
n− 2)
− 1⋅Y(
n− 1)
− 2⋅Y(
n− 2)
Illustrazione 4 11: Fase della risposta in frequenza del filtro digitale di Butteworth.
Illustrazione 4 10: Modulo della risposta in frequenza normalizzata del filtro digitale di Butteworth.
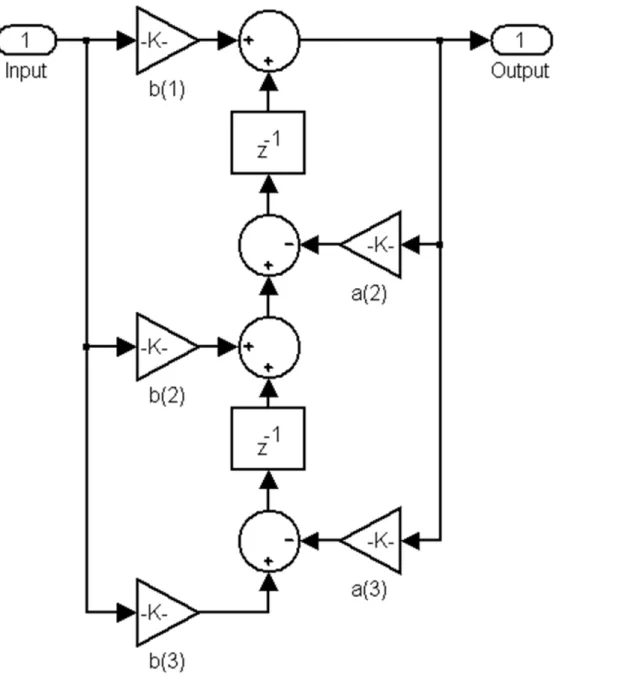
Questo filtro digitale può essere realizzato utilizzando due blocchi sommatori, due blocchi che effettuano la differenza e cinque elementi moltiplicatori, che sono realizzati tramite l'uso di circuiti DSP presenti sulla FPGA.
Illustrazione 4 12: Diagramma funzionale del filtro: b(1)=
χ
0,b(2)=
χ
1, b(3)=χ
2, a(1)=ϕ
1, a(2)=ϕ
2 e i blocchi z-1 indicano la necassità di attendere un passo del processo.È necessario notare che i fattori moltiplicativi del filtro non sono interi e devono essere utilizzate il maggior numero di cifre decimali. Gli arrotondamenti possono causare l'instabilità del filtro. In questo caso il
filtro, utilizzando = = ⋅ = = = 999999998 0.63999099 99999999 1.55895999 9999995 7997379999 9999995 7997379999 2 1 1 2 0 . 0 2 . 0 ϕ ϕ χ χ χ
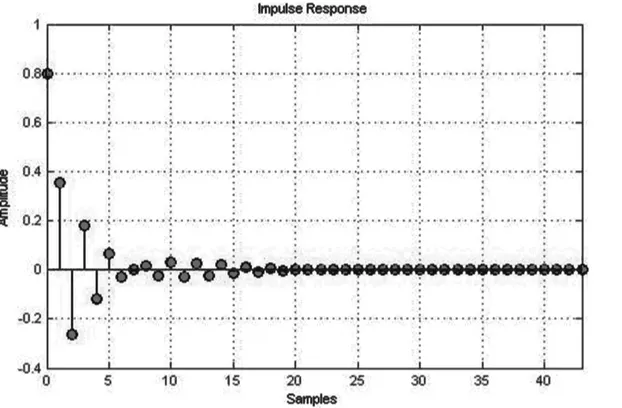
è risultato stabile. Infatti
dalle simulazioni si ottiene che il filtro risponde a sollecitazioni limitate nel tempo con uscite limitate.
Illustrazione 4 13: Risposta all'impulso del filtro digitale di Butteworth.
Inoltre le posizioni dei poli della funzione di trasferimento sono sufficientemente distanti dal bordo della circonferenza unitaria. Anche approssimando con meno cifre decimali è possibile ottenere un filtro stabile.
Illustrazione 4 14: Risposta al gradino unitario del filtro digitale di Butteworth.
L'implementazione su hardware del filtro ottenuto richiede l'uso di quattro moltiplicatori, infatti un blocco moltiplicatore può essere risparmiato perché il fattore moltiplicativo è lo stesso. Questi però richiedono in ingresso numeri in virgola mobile su 32 bit, quindi il risultato ottenuto dal blocco precedente, che era contenuto in un numero a 9 bit, deve essere convertito.
La rappresentazione di un numero binario in virgola mobile è fatta secondo lo standard IEEE P754 a 32 bit: il primo bit contiene l'informazione sul segno s, gli 8 bit successivi contengono l'esponente del numero in base binaria e e gli ultimi 23 bit sono la mantissa m. Quindi un generico numero n può essere rappresentato su 32 bit come:
s eeeeeeee mmmmmmmmmmmmmmmmmmmmmmm equivalente a eeeeeeee
mmm
mmmmmmmmmm
mmmmmmmmmm
s
n
=
⋅
1
,
⋅
2
.Trasformare un numero binario in complemento a due su 9 bit in un numero binario a virgola mobile a 32 bit è una operazione relativamente complessa. Il primo bit del numero a complemento a due viene riportato direttamente nella prima locazione del registro finale a 32 1 bit. Successivamente è necessario calcolate il modulo del numero a 9 bit in ingresso, quindi il numero così ottenuto viene mandato in ingresso ad un modulo che cerca il bit a uno più significativo. Per effettuare questa operazione sono necessari 9 cicli di clock, infatti si deve leggere la locazione di ogni bit del numero. Un contatore fa avanzare la lettura partendo da zero: se la locazione del bit è a uno, si somma il numero ottenuto dal contatore a 127=(1111111)2 e si memorizza negli 8 bit del registro finale dedicati all'esponente, altrimenti non si effettua nessuna operazione. In questo modo si è calcolato l'esponente del numero, resta da inserire la mantissa. Questa corrisponde a tutti i bit meno significativi del bit più significativo del numero mandato in ingresso al blocco che cerca gli uno. I bit così ottenuti vengono scritti nella locazione della mantissa partendo da sinistra con il bit più significativo e lasciando a zero
le locazioni verso destra che non vengono utilizzate. Per calcolare la mantissa è necessario utilizzare il risultato del contatore utilizzato nel blocco precedente: la locazione del bit più significativo viene memorizzata e vengono letti i bit del numero partendo da quello più significativo verso quello meno significativo; successivamente vengono memorizzati all'interno all'interno del registro finale nell'ordine voluto.
Effettuata la conversione è possibile iniziare ad effettuare il filtraggio. Oltre ai moltiplicatori sono necessari sommatori e sottrattori a virgola mobile per comporre il filtro. Questi blocchi sono molto complessi da realizzare, infatti non è possibile effettuare un sommatore semplice, perché i numeri in virgola mobile, per essere sommati, devono essere trasformati in modo tale che si possa sommare numeri consistenti, cioè è necessario considerare l'esponente del numero. L'operazione di ricostruzione del numero è la successiva somma sono operazioni decisamente complesse e computazionalmente complicate, per questo si è scelto di utilizzare i componenti logici forniti con il software Altera.
All'uscita del filtro è necessario un elemento che permetta la conversione inversa di quella effettuata precedentemente, cioè da numeri a virgola mobile a numeri interi in complemento a due.
Questo elemento non è stato fornito con il software, anche perché è relativamente semplice da realizzare, infatti è necessario prendere un numero di bit della mantissa pari al numero contenuto nell'esponente e inserire un bit a uno prima di tale risultato. In questo modo si è ricostruita la parte intera del numero. Per effettuare un arrotondamento è necessario considerare anche le cifre dopo la virgola. In questo caso si è scelto di considerare soltanto la prima cifra dopo la virgola e di effettuare una approssimazione aggiungendo, o no, uno alle otto cifre dell'intero calcolato precedentemente. Questa conversione deve essere effettuata perché le non ha senso che le traslazioni dell'immagine siamo numeri frazionari, infatti le traslazioni sono calcolate in pixel, quindi numeri interi.
L'introduzione dei numeri a virgola mobile è stata necessaria a causa dell'uso della trasformata z, necessaria per la realizzazione di un filtro. Arrotondare i valori ottenuti per i coefficienti del filtro a numeri interi avrebbe comportato la realizzazione di un filtro totalmente diverso da quello che si soleva realizzare.
Il filtro ottenuto è un passa basso del secondo ordine con una frequenza massima della banda passante di 50 Hz. Il vantaggio notevole dell'aver utilizzato questa tipologia di filtro digitale risiede nel fatto che è possibile, utilizzando la stessa struttura hardware e cambiando soltanto i coefficienti moltiplicativi, ottenere altri filtri passa basso del secondo ordine alla frequenza desiderata.
Un filtro di questo tipo è stato scelto anche perché consente di realizzare un filtraggio dei dati con un numero abbastanza limitato di elementi circuitali. Nel caso in cui la logica occupata da questo filtro sia eccessiva per un determinato hardware, si è scelto di proporre un altro filtro della stessa tipologia, ma ad un unico polo. Un filtro così realizzato è meno selettivo, ma occupa anche meno risorse hardware. Per questo motivo si è scelto di studiare anche un filtro di Butteworth passa basso del primo ordine con frequenza massima della banda passante di 50 Hz. La
descrizione del filtro con parametri s è:
( )
MAX MAX s s B ω ω + = . Quindi applicando la trasformazione si ottiene:
( )
1 1 1 1 01
− −⋅
+
⋅
+
=
z
z
z
B
ϕ
χ
χ
con = = = = 0.725395 1 862697 2 1 1 0 0. ϕ ϕ χ χ .Illustrazione 4 16: Risposta in modulo del filtro digitale passa basso del primo ordine di Butteworth.
Illustrazione 4 17: Risposta in fase del filtro digitale del primo ordine di Butteworth.
Il filtro è stabile e anche approssimando a qualche cifra decimale non può diventare instabile perché il polo è ampiamente all'interno della circonferenza unitaria.
Inoltre il filtro risponde in modo finito a sollecitazioni impulsive.
Illustrazione 4 18: Posizione dei poli X e zeri 0 della funzione di trasferimento del filtro digitale di primo ordine di Butteworth.
4.5 - De-interlacciamento dell'immagine.
Il de-interlacciamento dell'immagine è una parte a se del progetto, infatti questo elemento teoricamente indispensabile è risultato essere inutile. Infatti il blocco di de-interlacciamento è necessario per riuscire a ricostruire una singola immagine del flusso video PAL, riallineando le righe pari con quelle dispari. Quindi, dato che nella scheda entra un segnale analogico PAL e esce un segnale codificato nello stesso modo, il blocco di interlacciamento risulta essere inutile perché tutti i monitor in commercio sono in grado di de-interlacciare le immagini in modo autonomo. Si deve risolvere, necessariamente, il problema del de-interlacciamento solo se si vuole visualizzare una singola immagine di un flusso video. Infatti, in questo caso, è necessario riallineare i due campi dell'immagine per riuscire Illustrazione 4 20: Risposta al gradino unitario del filtro digitale di primo ordine di Butteworth.
a vedere correttamente il frame. Questo problema si sarebbe dovuto risolvere se si fosse applicato completamente l'algoritmo di ricerca gerarchica. Infatti questo prevede di effettuare dei confronti con immagini di dimensioni reali, cioè un frame di 576 x 720 pixel. Per poter effettuare confronti è necessario avere una immagine non disturbata dal fatto che le righe pari e quella dispari sono sfasate, quindi è necessario de-interlacciare l'immagine. In realtà, però, a causa delle scarse risorse hardware, si è scelto di non effettuare dei confronti con l'immagine a dimensioni reali, ma di fermarsi a confrontare l'immagine sotto-campionata di fattore due. Per questo motivo il blocco di de-interlacciamento dell'immagine, teoricamente indispensabile è stato eliminato dal progetto e sostituito con un unico collegamento che dal decoder video porta i dati verso il blocco controllore della memoria esterna.
Il blocco di de-interlacciamento è indispensabile nel caso in cui si voglia pilotare direttamente un monitor. Infatti, in questo caso, le righe del frame devono essere mandate in modo progressivo e quindi è necessario, allo scopo di visualizzare correttamente l'immagine, che questa sia de-interlacciata. Chiaramente in questo caso anche il blocco di ricostruzione del flusso video e quello di interfaccia dovrebbero essere differenti, rispetto alla attuale realizzazione.
Il de-interallacciamento dell'immagine non è una operazione computazionalmente complessa; infatti sarebbe bastato implementare l'algoritmo verticale temporale mediano per risolvere il problema. Questo prevede di recuperate il de-interallacciamento dell'immagine effettuando una media su sette pixel; 6 appartenenti al primo campo dell'immagine e uno appartenente al secondo. In questo modo, però, si dovrebbe effettuare una divisione per 7 del valore ottenuto dalla somma del valore dei pixel. Dato che l'operazione di divisione per 7 richiederebbe un blocco dedicato, si potrebbe modificare l'algoritmo allo scopo di ottenere una
divisione per 8, in modo tale che per eseguire questa operazione sia sufficiente shift-are di 3 bit verso destra il risultato ottenuto dal sommatore.
Questa operazione non richiede nessun elemento circuitale, infatti è sufficiente considerare solamente i bit più significativi del risultato del sommatore e trascurare gli ultimi tre. Il pixel è quindi formato da una
media di 8 elementi:
(
)
8 2 ,y a b c d e f g x P = + + + + + + ⋅ . Il dato, che dovrebbe essere fornito in uscita per il modulo di interfaccia con il decoder, serebbe composto da tre informazioni distinte: luminanza, colore rosso Cr e colore blu Cb. La media dovrebbe essere fatta su ciascuna componente del pixel in modo distinto. Il risultato dovrebbe essere memorizzato nella memoria esterna.Come è già stato detto questa operazione non è computazionalmente complessa, ma richiede la disponibilità al accedere molte volte alla memoria esterna. Per questo motivo si dovrebbe effettuare questa operazione in contemporanea con l'arrivo del pixel del secondo campo dell'immagine. In questa fase del flusso video vengono effettuate due operazioni il de-interallacciamento dell'immagine e la ricostruzione del flusso in uscita. Per svolgere questa operazione sarebbero necessari, per Illustrazione 4 21: Schema dei pixel da utilizzare per realizzare un filtro veticale-temporale mediano.
ogni pixel del secondo campo dell'immagine corrente, 6 accessi in memoria per recuperare i dati mancanti, appartenenti al primo campo, e uno per la scrittura del dato in memoria. Praticamente nel periodo di tempo in cui verrebbe trasmesso il secondo campo, una porta della memoria sarebbe utilizzata per i
8
7 del tempo dal blocco di
de-inerallacciamento. Per questo motivo sarebbe opportuno effettuare questa operazione nel corso della trasmissione del secondo semi-quadro.
4.6 - Ricostruzione del flusso video in uscita.
Il macro-blocco in esame consente di risolvere il problema della ricostruzione del flusso video in uscita. Il sistema per la stabilizzazione fornisce in uscita la direzione e il verso delle traslazioni orizzontali e verticali dell'immagine, quindi il blocco in esame trasla le immagini e ricostruisce il flusso video inserendo pixel di colore nero per le regioni in cui l'immagine non è presente a causa delle traslazioni.
L'encoder video è in grado di interpretare il formato video digitale Y 4:2:2 con flusso di bit a 27 MHz, con tre segnali di sincronismo. Questo metodo di trasmissione prevede di inviare prima un campo dell'immagine, poi l'altro. La prima parte delle righe è già presente in memoria, e quindi è possibile recuperarla per ricostruire il flusso video in uscita. La seconda parte deve essere trasmessa. L'operazione di ricostruzione del flusso video in uscita viene fatta in contemporanea con tutte le altre operazioni. Questa, dato che si deve effettuare una traslazione orizzontale e verticale dell'immagine, è una operazione semplice che richiede poca logica e soltanto un accesso alla memoria ogni otto cicli di clock della FPGA.
La traslazione di una immagine è identica a una traslazione geometrica di un piano rispetto ad un altro, quindi:
dove XSTABILIZZATA e YSTABILIZZATA sono le coordinate dell'immagine stabilizzata rispetto ai riferimenti dell'immagine reale, XREALE e YREALE sono le coordinate dell'immagine reale e ΔX e ΔY sono le traslazioni fornite dal sistema di stabilizzazione. Se si vuole ricavare la posizione dell'immagine reale rispetto a quella stabilizzata è sufficiente calcolare:
Inserendo in XSTABILIZZATA e YSTABILIZZATA i valori delle coordinate dei pixel dello schermo, è possibile capire se a quel pixel dello schermo coincide un pixel dell'immagine reale, oppure se deve essere lasciato nero. Questa operazione è facilmente eseguibile, infatti se:
Nel caso in cui un pixel appartiene al video si effettua il recupero in memoria, altrimenti si invia un pixel che abbia sia la componente di luminanza che di colore composte da tutti uno.
4.7 - Controllore della memoria esterna.
L'elemento circuitale che ha il compito di gestire al memoria esterna è il controllore della memoria esterna. Questo blocco ha il compito di permettere l'accesso a memoria agli altri blocchi del sistema e di fornire loro i dati. Alcuni macro-blocchi della FPGA forniscono direttamente al controllore le informazioni necessarie per inserire o recuperare i dati dalla memoria. Il blocco di interfaccia con il decoder, per esempio, fornisce in uscita direttamente l'indirizzo del pixel che deve essere inserito in memoria, mentre tutti gli altri blocchi, che fanno uso della memoria esterna, aspettano i dati da questo blocco nei tempi e modi prefissati. È
∆ − = ∆ + = Y Y Y X X X REALE TA STABILIZZA REALE TA STABILIZZA ∆ + = ∆ − = Y Y Y X X X TA STABILIZZA REALE TA STABILIZZA REALE
(
) (
) (
)
∉ ∈ ⇒ ≤ ≤ ≤ ≤ video altrimenti video Y X YXREALE 719 0 REALE 575 REALE, REALE
stato scelto di realizzare questo blocco abbastanza complesso per far si che un unico blocco controllasse gli accessi alla memoria esterna e per non permettere a parti diverse del circuito di richiedere contemporaneamente l'accesso alla risorsa di memoria. Il controllore di memoria è sincronizzato con l'uscita dei dati dal decoder video che fornisce i segnali di sincronismo a tutti i blocchi. Tutte le operazioni sono scandite da tali segnali e quindi si è scelto di utilizzare questi sincronismi e dei contatori per recuperare le informazioni in memoria.