39
2 Algoritmi Genetici per la sintesi di
Superfici Selettive in Frequenza
La maggior parte dei metodi di predizione numerica dei campi elettromagnetici si basa su tecniche e problemi di analisi: il problema che ci si trova ad affrontare è quello di determinare la configurazione di campo, assegnata una configurazione geometrica (antenna o dispositivo similare).
Spesso però, nella realtà è necessario affrontare un altro tipo di problema, esattamente speculare al precedente, un problema di sintesi: trovare la configurazione geometrica del dispositivo o dell’antenna che permette di realizzare una particolare configurazione di campo elettromagnetico. Anche l’oggetto di questo lavoro di tesi ricade nel secondo tipo di problematica, visto che si desidera sintetizzare nonché ottimizzare delle superfici selettive in frequenza. Per raggiungere questa finalità ci serviamo di un algoritmo stocastico basato sui principi evoluzionistici della teoria di Darwin che consente una progressiva ottimizzazione di strutture multistrato al fine di ottenere la configurazione di campo ricercata. Questo tipo di algoritmi prendono il nome di Algoritmi Genetici.
40
2.1
Algoritmi evoluzionari
Il matematico John Holland ha proposto, negli anni ‘80, un algoritmo, detto
genetico in quanto basato sulla teoria evoluzionistica di Darwin. Il concetto darwiniano
di evoluzione prevede che, considerati due genitori di una qualunque specie aventi caratteristiche genetiche “buone” (forti o dominanti), la probabilità che anche i figli mantengano tali caratteristiche è maggiore di quella che si avrebbe se i genitori non avessero simili qualità. Holland ha cercato di trasferire tale principio ai numeri: generata inizialmente una serie casuale di numeri (generalmente binari), si può pilotare in maniera opportuna ”l’accoppiamento” di tali numeri al fine di ottenere una soluzione ottima. Come vedremo fra breve, il problema diventa quindi quello di trovare una funzione, cosiddetta di fitness, che mostri l’indice di bontà di un numero ottenuto per generazione casuale prima e per accoppiamento di numeri con caratteristiche genetiche forti poi.
La funzione di fitness nella pratica, fornisce lo scostamento tra il valore ideale (quello da raggiungere, noto) e quello ottenuto dai numeri casuali creati ed evolutisi.
Come già affermato, gli Algoritmi Genetici (GA – Genetic Algorithm) sono dei metodi stocastici di ricerca volti all’ottimizzazione di apparati e strutture. In particolare, a noi interessano problemi di ottimizzazione elettromagnetica che richiedono spesso un gran numero di parametri.
Generalmente i GA sono classificati come “ottimizzatori globali”: la fondamentale caratteristica che li distingue da quelli locali è che essi forniscono un massimo assoluto della funzione-soluzione del problema. Le tecniche locali producono invece risultati fortemente dipendenti dalle condizioni iniziali e sono molto legate alla natura del dominio di soluzioni in termini di continuità e differenziabilità, tanto che spesso non sono applicabili nella pratica.
Le tecniche globali, invece, non solo sono indipendenti dalla natura dello spazio di soluzione, ma funzionano meglio quando questo contiene delle discontinuità ed ha molti massimi locali o parametri vincolanti. Un parametro fondamentale per il corretto funzionamento degli ottimizzatori globali è che la popolazione iniziale sia piuttosto ampia in modo che l’algoritmo vada ad esplorare il maggior numero di spazi delle soluzioni prima di convergere a una soluzione che, nel caso di una popolazione iniziale
41
composta da un numero ridotto di esemplari, potrebbe essere un massimo locale e quindi una soluzione sub-ottima. Un’altra caratteristica peculiare dei GA è che essi non operano direttamente la sintesi e l’ottimizzazione delle incognite del problema, ma, più spesso, agiscono su una loro rappresentazione parametrica nota come cromosoma. Inoltre, i GA ottimizzano l’intera popolazione in un unico processo (parallelismo
intrinseco) e non compiono l’ottimizzazione di parametri presi singolarmente.
Tuttavia, è necessario evidenziare che le tecniche globali non sono particolarmente veloci nella convergenza al punto di massimo/minimo assoluto (anche se, in campo elettromagnetico, è importante giungere ad una soluzione molto vicina a quella ottima piuttosto che ottenerne una subottima in tempi rapidi).
Occorre poi notare come in ogni processo di ottimizzazione un tool di analisi e l’algoritmo di ricerca vero e proprio interagiscono di continuo e, per ogni set di parametri proposto dal GA, il solver elettromagnetico risolve l’equazione che governa il sistema, determinando i parametri di nostro interesse (nel caso delle superfici selettive in frequenza sono i coefficienti di trasmissione e riflessione) dei quali poi viene valutata la bontà tramite la funzione di fitness in relazione all’obiettivo che ci eravamo proposti. Cercheremo allora di mostrare in questo capitolo come sia possibile implementare un Algoritmo Genetico e come esso sia strettamente legato all’oggetto di questo lavoro, ossia alla progettazioni di superfici selettive in frequenza.
2.2
Funzionamento dell’Algoritmo Genetico
Un Algoritmo Genetico deve poter disporre di uno spazio di soluzioni iniziali composte da stringhe di numeri che nella maggior parte sono binari, ognuno di questi vettori costituisce un individuo; ogni individuo viene generalmente rappresentato da un
cromosoma che è a sua volta costituito dall’insieme dei geni detto genotipo. Ogni gene
rappresenta un parametro (dato) della struttura da ottimizzare, quindi un argomento della funzione, in genere multidimensionale, che caratterizza il sistema.
Durante l’ottimizzazione vengono scelte le migliori soluzioni (individui) mediante il calcolo della funzione di fitness e vengono fatte evolvere verso il risultato ottimale.
42
In natura ogni individuo ha sue caratteristiche e proprietà specifiche, manifestate esternamente, che ne costituiscono il cosiddetto fenotipo; è proprio il fenotipo a dettare le possibilità e i limiti delle interazioni dell’individuo con l’ambiente in cui vive. Ma così come il fenotipo è determinato sostanzialmente dall’invisibile patrimonio genetico (genotipo), costituito da una particolare sequenza di geni, allo stesso modo ogni caratteristica di una possibile soluzione viene codificata in una stringa e mappata, quindi, nel dominio di decisione della variabile.
L’insieme di tutti i geni caratterizzerà un cromosoma che codifica una soluzione; l’insieme dei cromosomi, a loro volta riuniti in una popolazione, mapperà il dominio delle soluzioni possibili.
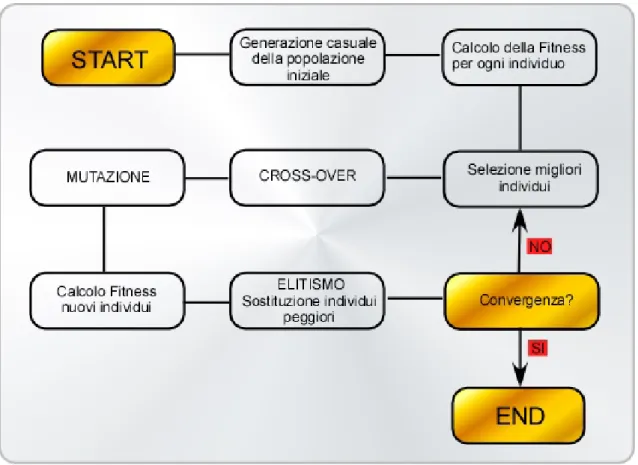
Per capire come lavora un GA facciamo riferimento al diagramma a blocchi mostrato in Figura 2.1.
Figura 2.1 - Funzionamento schematico di un GA.
43
• si dirà “popolazione” un set di individui.
• si diranno “genitori” i membri della popolazione corrente. • si diranno “figli” i membri della generazione successiva. • si dirà “cromosoma” la forma di codifica del vettore delle soluzioni possibili costituito dai geni.
• si dirà “fitness” quel numero positivo, associato a ogni individuo, che ne misura la bontà rispetto alla funzione oggetto.
Come si può notare, il GA si sviluppa in più fasi: una prima fase di inizializzazione, una successiva di riproduzione e una finale di generazione di repliche.
La prima consiste nel creare una popolazione iniziale (set di soluzioni) mediante un numero predeterminato di cromosomi (stringhe di parametri codificati, scelti a caso). Ad ogni individuo (rappresentato da un cromosoma) che appartiene alla popolazione corrente viene poi associato un valore di fitness.
La riproduzione consente di produrre una nuova generazione: due individui della generazione corrente vengono selezionati come genitori; quindi subiscono l’operazione di cross-over1 e mutazione2 per produrre figli della nuova generazione; tali operazioni vengono ripetute finché ci sono elementi sufficienti per sostituire la generazione corrente con la nuova. Il GA è detto generazionale se la nuova popolazione ha lo stesso numero di elementi della precedente, altrimenti è detto stady-state; è possibile che elementi della vecchia generazione si sovrappongano e coesistano con quelli della nuova.
La terza fase consiste nella sostituzione, intera o parziale, della vecchia generazione con la nuova e con il calcolo dei nuovi valori di fitness che sono successivamente assegnati ai nuovi individui appena creati.
Se viene raggiunto il criterio di terminazione, l’algoritmo ha fine, altrimenti itera sui nuovi cromosomi creati.
Concentriamoci allora su come avviene la generazione della popolazione iniziale e su come si svolge il processo evolutivo, ovvero su quali sono le operazioni che il GA compie nel passaggio da una generazione ad una successiva.
1
Il cross-over è un operatore del GA descritto nel paragrafo 2.2.3
2
44
2.2.1 Generazione della popolazione stocastica iniziale
Il programma crea la popolazione iniziale sfruttando un generatore di numeri casuali. A tal proposito la subroutine inserisce, in una matrice di dimensioni prefissate da input, dei valori binari, a seconda del valore assunto da una variabile casuale uniformemente distribuita tra 0 e 100 che viene fornita dal generatore. Se questa variabile è maggiore di 50, verrà posto un 1 nella mappa, diversamente uno 0, ripetendo il procedimento per ogni elemento della matrice.
I vettori costituenti le colonne della matrice rappresenteranno le codifiche binarie dei cromosomi, la cui struttura verrà descritta in dettaglio nel paragrafo 2.5.
Il programma consente inoltre di sfruttare come popolazione iniziale un seme, ovvero una mappa cromosomica precedentemente salvata su file, allo scopo di continuare il processo evolutivo di una soluzione precedentemente determinata e particolarmente promettente.
2.2.2 Operatore “Selezione”
Il processo di sostituzione della popolazione viene guidato da alcune strategie di selezione che usano i valori della fitness, ovvero della misura della “bontà” di un individuo, per valutare quanto questo fornisca risultati vicini alla soluzione ottima. In generale, però, la selezione non deve basarsi unicamente sulla scelta del miglior elemento della popolazione corrente, poiché questo potrebbe effettivamente esser ben lontano dalla soluzione ottima al problema. Il compito dell’operatore selezione sarà allora quello di scegliere nella maniera più opportuna i cromosomi con caratteristiche tali da diventare dei “buoni genitori” .
Ci sono diversi modi di implementare la selezione: il più elementare viene chiamato “Decimazione di Popolazione”. Gli individui vengono ordinati secondo il loro valore di
fitness, da quello con fitness minore a quello con fitness maggiore; si sceglie un punto di cut-off e tutti gli individui con fitness maggiore di tale valore vengono eliminati, mentre
i sopravvissuti danno origine alla nuova generazione mediante crossover. I vantaggi di un simile criterio consistono nella sua semplicità e in una maggiore velocità di
45
convergenza ma, operando in questo modo, si rischia di perdere parte del patrimonio genetico: cromosomi con fitness superiore al valore fissato come cut-off vengono eliminati pur possedendo delle caratteristiche (geni) che potrebbero apportare dei miglioramenti al processo evolutivo in una fase successiva del processo.
Un’altro tipo di selezione è la cosiddetta “Selezione per Torneo”: in tal caso, una sottopopolazione di N elementi viene scelta casualmente all’interno della generazione corrente; gli individui appartenenti a tale sottopopolazione competono tra di loro in base alla propria fitness: l’elemento con fitness più bassa passa alla generazione successiva, mentre gli altri vengono riposizionati nella popolazione corrente; il tutto si ripete fino a raggiungere il numero di cromosomi necessari per creare la generazione successiva. Lo svantaggio maggiore di questo tipo di selezione consiste nei tempi di convergenza, sicuramente più lunghi di quelli necessari ad una selezione con decimazione.
Si preferisce allora utilizzare la cosiddetta “Selezione Proporzionata” o “Roulette-wheel
Selection” (così come fatto nel programma implementato): gli individui sono scelti in
base alla loro probabilità di essere selezionati data da:
1 1
(
)
(
)
i sel n i if genitore
P
f genitore
= − =∑
,
(2.1)dove f è la fitness riferita al genitore i-esimo.
Più la Psel è alta, maggiore è la probabilità che l’individuo partecipi alle generazioni
future; nonostante ciò, individui con fitness non sufficientemente bassa sopravvivono alla selezione. Agendo in questo modo non si corre il rischio di perdere patrimonio genetico che potrebbe mostrare tutta la sua potenza evolutiva nel futuro e si assicura un’ottima velocità di convergenza all’algoritmo.
Nella figura successiva (Figura 2.2), viene mostrato un semplice esempio di selezione proporzionata: ad ogni individuo viene assegnato uno spazio sulla ruota della roulette, proporzionale alla sua Psel; la ruota viene fatta girare e alla fine il puntatore mostrato
indicherà un individuo specifico: minore è la sua fitness, più alta sarà la probabilità che esso venga selezionato.
46
Roulette-wheel
# 1 # 2 # 3 # 4 # 5 # 6 # 7 # 8 # 9 # 10Figura 2.2 - Esempio di selezione proporzionata.
2.2.3 Operatore “Cross-over”
Come già affermato, nel corso del processo evolutivo, individui con fenotipo tale da consentire il superamento della selezione naturale, scambiano parte del loro patrimonio genetico: è questa l’operazione di cross-over. Gli individui della generazione successiva conserveranno quindi le caratteristiche dei genitori e, potenzialmente, saranno migliori di questi. Le informazioni genetiche relative agli individui scartati verranno perse irreversibilmente.
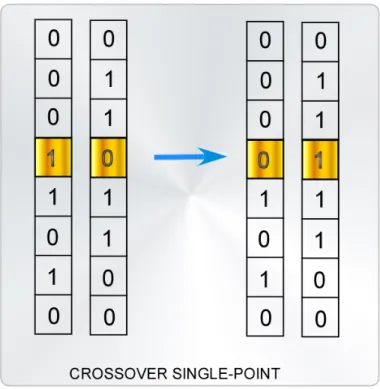
Esistono due tipi di cross-over, quello single-point e quello multi-point. Il primo, utilizzato con probabilità dell’ordine del 60%-90%, come consigliato in letteratura al fine di velocizzare la convergenza (nel nostro caso è sempre pari a 80%), viene realizzato nella seguente maniera: alla subroutine che compie tale operazione, viene passata la mappa cromosomica; vengono in seguito scelti casualmente due cromosomi. Si decide quindi con probabilità Pcross se eseguire o meno il cross-over. In caso
affermativo, si sceglie casualmente un punto nei due cromosomi e viene effettuato lo scambio delle porzioni di cromosoma. L’uscita della funzione è la mappa modificata. Nella Figura 2.3 viene mostrata l’operazione di cross-over single-point.
47
Figura 2.3 - Cross-over single-point.
Nel secondo caso (crossover multi-point), lo scambio riguarda più porzioni di cromosoma, così come illustrato nella Figura 2.4.
48
2.2.4 Operatore “Mutazione”
L’operatore di mutazione consente l’esplorazione di spazi di soluzione che non sono rappresentati nell’assetto genetico della popolazione corrente: infatti tali individui non possono contenere tutte le combinazioni di geni possibili ma ne contengono un numero molto limitato che spesso, anche se combinate tra loro (cross-over), non potranno mai origine ad alcuni tipi di cromosomi.
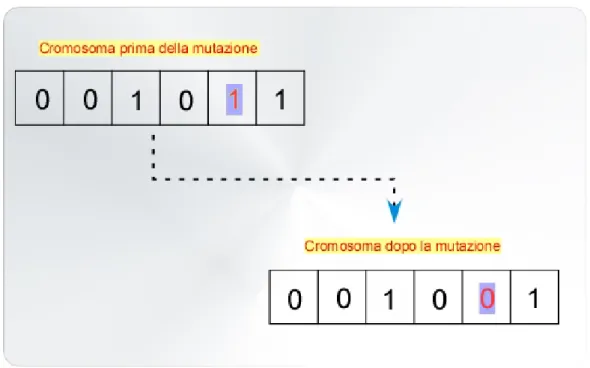
L’implementazione di tale operatore è molto semplice: se si usa una codifica binaria, gli zeri saranno cambiati in uno e viceversa (Figura 2.5), attraverso l’applicazione dell’operatore NOT; la probabilità con cui può intervenire la mutazione è data dal valore della variabile Pmut.
Figura 2.5 - Operatore Mutazione.
La mutazione viene in genere indicata come un operatore evolutivo secondario rispetto alla selezione ed al cross-over. Tuttavia è in gran parte dovuta ad essa la notevole capacità, propria degli Algoritmi Genetici, di determinare soluzioni per problemi complessi prossime a quella ottima. In letteratura, come visto, si consigliano valori di probabilità di intervento del cross-over nell’ordine del 60-90 % (almeno per quanto riguarda l’ottimizzazione di problemi elettromagnetici), mentre per la probabilità di
49
mutazione le percentuali sono notevolmente inferiori, tipicamente pari all’10-20 %. L’evoluzione viene quindi affidata principalmente al cross-over per ottenere maggiori proprietà di convergenza dell’algoritmo. Se però il dominio delle soluzioni possibili è molto vasto, l’apporto della mutazione può risultare produttivo reintroducendo in alcuni casi parte del patrimonio genetico andato perduto e potenzialmente utile. Aumentare la probabilità di mutazione significa sostanzialmente affidarsi in maniera più marcata alla casualità.
Nell’algoritmo genetico preesistente, si trova una subroutine in grado di variare dinamicamente la probabilità di mutazione, essendo questa l’operatore genetico che può reintrodurre nella mappa dei cromosomi caratteristiche genetiche andate perdute.
Partendo dalla considerazione che l’intervento della mutazione può essere utile quando l’evoluzione tende a fermarsi (cioè quando il valore di fitness tende a rimanere costante al crescere del numero delle generazioni), mentre deve intervenire raramente durante il corso dell’evoluzione (che deve essere svolta principalmente dall’operatore cross-over), si è introdotta una probabilità di mutazione variabile in maniera lineare tra due soglie, scelte da input così come accade per il valore dell’incremento.
Si tratta in effetti di un semplice sistema in retroazione: se la fitness resta invariata tra due generazioni consecutive, si incrementa leggermente il valore di Pmute questo procedimento si ripete fino a quando non si raggiunge la soglia superiore. Quando poi si registra il miglioramento, la probabilità di mutazione torna al suo valore inferiore.
Dall’esperienza maturata durante le simulazioni è comunque consigliabile impostare valori massimi pari al 20%, in accordo con la maggior parte dei riferimenti bibliografici, e valori ancora più piccoli per gli incrementi ( 0.1% -0.5%).
2.2.5 “Elitismo”
L’elitismo è una strategia evolutiva che va a completare il processo di
sostituzione della popolazione iniziato dall’operatore selezione. Distinguiamo tre tipi di
elitismo, quello semplice e quello globale e quello selettivo.
Nel primo caso, il miglior individuo (padre) della generazione i viene mantenuto nella successiva i+1 se presenta fitness migliore di quella del figlio. Nella pratica e per quanto riguarda il programma implementato (Periodic Elements Genetic Algorithms
50
Synthesizing & Optimizing – PEGASO), questa tecnica viene sempre usata per non
perdere informazioni sul cromosoma migliore nelle operazioni di selezione, crossover e mutazione che portano da una generazione all’altra. Nel secondo caso, quello di elitismo
globale, ogni individuo della generazione successiva può essere sostituito dal padre se
questo presenta prestazioni migliori.
L’elitismo semplice, al pari della selezione, del cross-over o della mutazione, diventa così un operatore fondamentale del GA in quanto permette di non perdere informazioni sul miglior risultato ottenuto fino a quel momento e di aumentare la velocità di convergenza. Ecco perché tale operatore viene utilizzato dal programma senza la necessità che il progettista debba inserire tale opzione da input.
Facendo uso dell’elitismo globale si garantisce una velocità di convergenza dell’algoritmo decisamente superiore a quella ottenibile con l’elitismo semplice. Questa scelta, pur consentendo di ottenere dei tempi di convergenza molto bassi, può pregiudicare il risultato finale in quanto causa, molto spesso, la perdita di caratteristiche genetiche che, pur apparentemente negative o comunque non buone in senso darwiniano, potrebbero dimostrare la loro potenza evolutiva solo dopo un certo numero di generazioni: cromosomi “non buoni” in termini assoluti (ovvero visti nella loro interezza) potrebbero nascondere dei geni (ovvero gli effettivi parametri del problema in esame) utili al raggiungimento della soluzione voluta. I geni provenienti da pochi individui con una fitness comparabilmente bassa (ma non ottimale) possono rapidamente dominare la popolazione, causando la convergenza a un minimo locale. Una volta che la popolazione converge, l’abilità del GA di continuare la ricerca per una soluzione migliore è affidata soltanto all’operatore mutazione e questo semplicemente porta ad una ricerca lenta e casuale. Il cross-over di individui quasi identici può portare ben pochi miglioramenti.
Recentemente è stata introdotta una nuova strategia evolutiva che prende il nome di
elitismo selettivo; si lascia che il GA evolva autonomamente per un certo numero di
generazioni, per poi inserire automaticamente l’opzione di elitismo globale. In tal modo si raggiunge un doppio risultato: si lascia al GA la possibilità di esplorare un più vasto campo di soluzioni, senza tralasciare alcun cromosoma che potrebbe potenziare lo sviluppo genetico e, una volta esaurito tale campo, grazie all’elitismo globale, si raggiungono, in tempi molto brevi, valori di fitness davvero bassi.
51
2.3
Convergenza dell’algoritmo
Durante il processo evolutivo, a causa dell’applicazione degli operatori, può accadere che la mappa cromosomica peggiori.
Il peggioramento non è necessariamente un avvenimento negativo, perché, come già detto a proposito dell’operatore cross-over, in una ottimizzazione multi-oggetto, soluzioni globalmente non valide possono apportare con il loro patrimonio genetico miglioramenti alla popolazione, celando al loro interno valori ottimi di singoli parametri.
E’ opportuno notare che l’Algoritmo Genetico non necessariamente fornirà una soluzione ottima o prossima a questa. Spesso la soluzione ottenuta è sub-ottima e sarà compito del progettista decidere quando arrestare l’evoluzione della popolazione selezionata. Nel caso specifico sono previste tre possibili “vie d’uscite” dall’algoritmo:
• se il valore di fitness è sceso al di sotto di una soglia predeterminata da input; • se si è superato un certo numero massimo preimpostato di generazioni;
• mediante intervento diretto del progettista tramite il file ’stopexe’ che blocca l’esecuzione dopo aver calcolato i valori parziali e salvato ogni informazione utile nei file ’rinfobe’ e ‘restart’, oltre ovviamente ai dati parziali nei relativi file.
2.4
Funzione di Fitness
La funzione di fitness è la connessione tra il problema reale e il GA. Le grandezze tramite le quali essa è valutata dovranno allora rappresentare nel modo più fedele possibile il sistema e dovranno essere indicatrici in maniera completa (e possibilmente semplice) delle proprietà dello stesso che devono essere ottimizzate.
In problemi di ottimizzazione di superfici selettive in frequenza i parametri che rappresentano in maniera esaustiva il comportamento di queste struttura sono i coefficienti di trasmissione e riflessione in modulo e fase. Per alcune applicazioni in cui siamo interessati alla potenza trasmessa dallo schermo possiamo prendere in
52
considerazione solo il modulo del coefficiente di trasmissione o di riflessione poiché sono legati dalla seguente relazione:
2 2
(ΓE) +(τE) =1
(2.2)
Il problema analizzato è una ricerca di un minimo assoluto in un dominio multidimensionale su cui sono presenti molti massimi e minimi locali. Anche se il problema è di difficile risoluzione, il modo con cui valutiamo di volta in volta la bontà della soluzione raggiunta è piuttosto semplice perché si basa sulla minimizzazione di una funzione di una variabile. La funzione di fitness implementata all’interno dell’Algoritmo Genetico calcola la distanza geometrica tra il coefficiente di trasmissione o di riflessione voluto e quello ottenuto nella soluzione esaminata. Questo calcolo viene effettuato su ogni campione frequenziale preso in considerazione e poi mediato sul numero di punti totale.
La fitness ci dovrebbe consentire di capire quando l’iterazione ha raggiunto il minimo assoluto, ma nella maggior parte dei casi riusciremo solo ad avvicinarci a questo minimo man mano che diminuisce il valore della funzione distanza implementata. Non è possibile sapere a priori quali sono i valori di fitness sufficientemente piccoli per poter affermare di aver ottenuto un buon livello di convergenza poiché questi dipendono fortemente dal tipo di problema studiato e dalla difficoltà che si ha nell’ottenere il comportamento voluto con la struttura scelta.
2.5
Struttura del Cromosoma
A questo punto, dobbiamo evidenziare il legame tra le superfici selettive in frequenza e l’Algoritmo Genetico. Innanzitutto è necessario definire quei parametri che descrivono in maniera semplice e completa il sistema che vogliamo sintetizzare e ottimizzare, ovvero una superficie selettiva in frequenza posta in una struttura dielettrica multistrato. Le caratteristiche principali di una struttura di questo tipo possono essere riassunte nel seguente elenco:
53
• spessore degli strati di dielettrico (thickness) • costanteεr degli strati di dielettrico
• eventuale simmetria che la cella può presentare rispetto ad un particolare asse.
Ognuno di questi parametri rappresenterà un gene di ogni cromosoma-individuo delle popolazioni in esame.
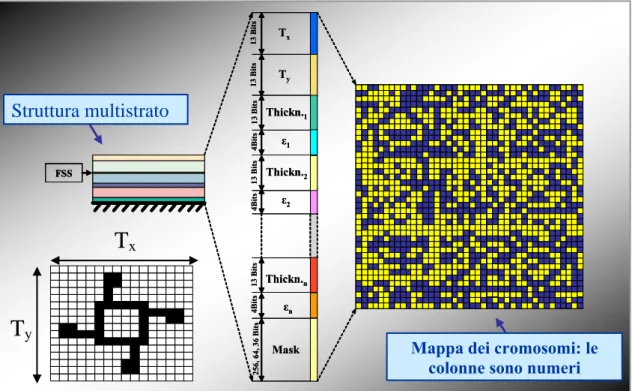
Poiché, per quanto affermato in precedenza, i cromosomi non sono altro che i vettori colonna della mappa cromosomica generata casualmente prima e ottenuta per evoluzione poi, nel GA originario è stata assunta la suddivisione mostrata nella Figura 2.6 per ciascuno di essi.
I primi due geni, lunghi 13 bit ciascuno, codificano le dimensioni della cella elementare. Di seguito sono posti i campi relativi agli spessori dei dielettrici (13 bit), e alle costanti dielettriche (4 bit). Il numero di bit utilizzato per la costante dielettrica potrebbe apparire esiguo se confrontato con quello dello spessore del dielettrico o delle dimensioni della cella: mediante 13 bit sono rappresentabili 13
2 =8192 numeri decimali, mentre i numeri esprimibili con 4 bit sono solo 24 =16. In effetti, l’Algoritmo
Tx Ty Thickn.1 Thickn.2 Thickn.n ε1 ε2 εn Mask 13 B it s 13 Bi ts 13 Bi ts 4Bi ts 13 B its 4B its 13 Bi ts 4B its 256, 64, 36 Bi ts FSS Tx Ty Thickn.1 Thickn.2 Thickn.n ε1 ε2 εn Mask 13 B it s 13 Bi ts 13 Bi ts 4Bi ts 13 B its 4B its 13 Bi ts 4B its 256, 64, 36 Bi ts FSS FSS Struttura multistrato
Mappa dei cromosomi: le colonne sono numeri
T
yT
x54
Genetico non è deputato all’ottimizzazione della costante dielettrica in termini assolutamente casuali e questo per prevenire che la soluzione proposta presenti un valore di εr non riscontrabile in materiali presenti in commercio. In questo modo il gene conterrà solo un indice che servirà da puntatore in un database appositamente creato di materiali dielettrici effettivamente reperibili. All’inizio della simulazione il programma legge dal database i valori di costante dielettrica di ogni materiale (espresse come numeri complessi
ε ε
=
r+
j
ε
i) e li trasferisce ad un array; l’intero estratto dal campoε
j rappresenterà la posizione nell’array della costante dielettrica del materiale che occupa la posizione j-esima nella struttura multistrato.E’ possibile inoltre scegliere da un file di ingresso il numero di strati posti al di sopra e al di sotto dello schermo FSS; è stata imposta una limitazione superiore al numero di dielettrici utilizzabili (il numero massimo è 8 ma tale limitazione è peraltro eliminabile intervenendo sul simulatore FSS2), poiché per valori troppo elevati le dimensioni della matrice da invertire diventano ragguardevoli e, di conseguenza, diventano anche inaccettabilmente lunghe le simulazioni.
Infine, come si può notare dalla figura precedente, l’ultimo campo, di lunghezza variabile, riguarda la forma della cella elementare. Dal file di ingresso è possibile scegliere la simmetria della maschera: secondo dati sperimentali, una cella simmetrica comporterà una risposta omogenea dello schermo FSS al variare della polarizzazione. La simmetria 1/8 e quella radiale consentono di avere comportamenti quasi identici per le polarizzazioni TE e TM. Tuttavia l’Algoritmo Genetico prevede anche la possibilità di determinare conformazioni asimmetriche dello schermo totalmente casuali, che talvolta manifestano interessanti proprietà.