4 Descrizione
del
firmware
caricato
nel
microcontrollore
In questo capitolo verrà descritta la progettazione della parte software del dispositivo incentrata principalmente nella scrittura di un programma in grado di far compiere al microcontrollore tutte le azioni richieste dal progetto.
Iniziamo rivedendo, per comodità del lettore, le specifiche del progetto per poi continuare con la parte di programmazione vera e propria.
4.1 Specifiche del progetto
In base alle caratteristiche di una rete domotica orientata in particolare alle esigenze delle persone disabili e anziane, indicate nel primo capitolo e ai criteri di progetto esposti, possiamo definire in maniera precisa le caratteristiche del nostro gateway.
Il dispositivo si presenterà come una scatola di piccole dimensioni totalmente senza fili. Sarà in grado di comunicare via radio con l’interfaccia utente e di comandare tramite raggi infrarossi tutti i dispositivi dotati di ricevitore IR. Per facilitarne al massimo l’inserimento e liberare l’utente da ogni vincolo, il dispositivo sarà autoalimentato. In questo modo
l’acquirente può porre l’oggetto nel punto che più gradisce senza il vincolo della presa elettrica.
Non è previsto l’utilizzo di un display in quanto l’utente non interagisce direttamente con il gateway, ma sull’interfaccia utente. Per dare un feedback visivo che il dispositivo funziona correttamente, verrà posto un LED di colore verde che si accenderà quando c’è interazione tra UI e gateway.
4.2 Applicazioni utilizzate durante la scrittura del programma
Per la scrittura del firmware, sono stati utilizzati principalmente due programmi freeware: WinAVR e AVR Studio. Diamo un breve sguardo alle loro caratteristiche.4.2.1 WinAVR
WinAVR è una suite di programmi open source nata per lo studio e lo sviluppo dei processori Atmel AVR su piattaforma Windows. Il pacchetto include il compilatore per il linguaggio C/C++ GCC (GNU Compiler Collection) settato per avere come target i processori AVR. Vediamo in dettaglio quali sono i contenuti del pacchetto:
•
GNU Binutils: utility per i processori AVR•
GNU GCC•
Avr-libc: serie di librerie standard per i processori AVR da usare con il GCC•
Avrdude: software per la programmazione open-source•
Uisp: come il precedente•
GNU Debugger (GDB): debugger da linea di comando•
Avarice: programma per interfacciare l’Atmel JTAG ICE con il GDB•
Simulavr: programma per la simulazione•
SRecord: programma per manipolare i file letti o da caricare in EPROM•
Programmers Notepad: utility per la scrittura di programmi che supporta svariati linguaggiPer la scrittura del firmware è stato utilizzato l’editor Programmers Notepad mentre sono state di grande aiuto le librerie avr-libc e le avrlib scritte da Pascal Stang. Di notevole importanza è anche il makefile, un programma che raggruppa insieme i diversi file, setta gli elenchi del compilatore e i flags del linker, detta le regole sul come compilare il sorgente e farlo diventare file oggetto, come linkare file oggetto, come convertire file da un tipo all’altro e molte altre cose.
4.2.2 AVR Studio 4
L’AVR Studio (giunto alla versione 4.13) è uno strumento professionale nato per analizzare e sviluppare applicazioni scritte per processori AVR. Include un assembler e un simulatore e permette inoltre l’interfacciamento con le schede di sviluppo ICE50/40, JTAGICE, STK500 e AVRISP. Grazie a queste funzioni è possibile caricare il firmware già compilato e simularlo in modo da eseguire un comodo debug in quanto il programma simula tutte le funzioni dei vari processori (timer, gestione interrupt, comunicazione seriale, ADC, sleep mode ecc.), visualizza tutti i registri e tutte le porte e permette inoltre la lettura/scrittura in EEPROM. Una volta sistemato il firmware, si può passare alla programmazione vera e propria del dispositivo attraverso una delle schede di sviluppo supportate.
4.3 Descrizione del firmware
In questo capitolo analizzeremo gli aspetti principali del programma scritto per il microcontrollore, rimandando il lettore all’appendice Aper una lettura integrale del codice.
4.3.1 Concetti di base
Nella scrittura del programma è stata utilizzata una struttura modulare, suddividendo il codice in vari file, ognuno dei quali provvede ad eseguire una particolare azione. In questo modo il programma risulta più leggibile, ed è inoltre possibile l’aggiornamento o l’aggiunta di una funzione senza necessariamente dover manipolare tutto il codice. Avremo quindi tre file principali:
• Main: è la parte principale, quella che viene eseguita all’avvio.
• Invia: provvede all’invio del segnale corretto al dispositivo indirizzato • Programmazione: trasferisce in EEPROM i dati relativi ad un dispositivo Le caratteristiche di base che deve avere il nostro programma sono:
• Ricezione sulla porta seriale del comando da eseguire
• Essere in grado di interpretare correttamente il messaggio ricevuto
• In base al dispositivo e al tipo di comando ricevuto, creare il giusto messaggio da inviare
• Passare il messaggio al circuito di invio raggi IR
• Essere in grado di scrivere in EEPROM i dati relativi ai dispositivi da indirizzare • Informare l’interfaccia utente che il messaggio è stato inviato correttamente
Come già anticipato, il codice è suddiviso in tre parti principali, ognuna delle quali ha un compito ben preciso. Il programma principale è il main che viene eseguito all’avvio e resta in attesa di eventuali comandi da parte dell’interfaccia utente.
Il problema principale con cui ci siamo dovuti confrontare è derivato dalla enorme vastità dei codici IR. Possiamo affermare che quasi ogni marca principale (Sony, Philips, Panasonic, Nec, Nokia,…) ha il proprio codice e che sono totalmente differenti l’uno dall’altro. Cambia infatti sia il tipo di modulazione (bifase o PWM) che la frequenza della portante (che varia in genere da 35 kHz a 40 kHz) che la forma del bit, che la struttura del messaggio stesso. Da qui si capisce come l’idea iniziale di scrivere una funzione invia per ogni tipo di codice risultasse impossibile da applicare. L’unica alternativa era creare una funzione che, attraverso un protocollo standard, riuscisse ad inviare il messaggio
correttamente. A questo punto il problema si spostava sul fatto di non conoscere tutti i codici utilizzati per le trasmissioni IR in quanto le ditte produttrici non rilasciano le specifiche. È in questa fase di sviluppo che ci è venuto in aiuto LIRC.
4.3.2 Il software LIRC
LIRC è un progetto Open Source su piattaforma Unix che permette di inviare o ricevere segnali IR imitando moltissimi telecomandi oggi esistenti. Per mezzo di questo programma, con l’aggiunta dell’opportuno trasmettitore da collegare alla porta seriale del PC, è possibile quindi comandare TV, VCR, DVD e impianti HI-FI. Collegando al PC un circuito ricevente (del tipo di quello da noi utilizzato per la decodifica dei codici IR) e inserendo nel programma degli appositi plug-in è inoltre possibile comandare il proprio PC con un telecomando supportato. In questo modo è possibile aprire applicazioni, ascoltare musica, regolare il volume e anche spegnere il computer in remoto. Per conoscere tutti i moltissimi codici esistenti, il programma si basa su dei file di configurazione archiviati nel database presente nel sito del progetto (www.lirc.org). Il file di configurazione contiene tutte le informazioni relative al dispositivo indicato come formato del messaggio, modulazione e durata dei bit, frequenza della portante, presenza di toggle bit e codifica dei comandi. Questi file di configurazione sono generati dal programma stesso quando viene utilizzato per imparare un codice da un telecomando; infatti collegando al PC un dispositivo ricevente, è possibile far imparare a LIRC il codice di quasi tutti i telecomandi esistenti. Esiste anche una versione di LIRC che opera sotto Windows, ovvero WinLirc. È leggermente più arretrata della sorella sotto Unix, ma le funzioni di base sono le stesse. L’idea per lo sviluppo del firmware è stata di utilizzare questo enorme database per attingere ai codici dei vari dispositivi sia in fase di istallazione, sia in fase di aggiornamento, qualora l’utente decida di cambiare un elettrodomestico.
4.3.3 La codifica di comunicazione tra l’interfaccia utente e il gateway
Dato che l’interfaccia utente deve comunicare al gateway un comando o una impostazione riguardo un dispositivo da indirizzare, era necessario implementare una codifica per i messaggi scambiati tra le due parti del progetto.Tale codifica è stata fatta pensando di poter garantire la massima compatibilità verso le più comuni tipologie di abitazioni e in modo da poter supportare aggiornamenti futuri.
I messaggi scambiati possono essere di tre tipi: comando, programmazione e risposta.
•
CODIFICA DI COMANDOQuesta sequenza viene mandata ogni volta che deve essere trasmesso un comando ad un dato dispositivo.
Il messaggio è composto da 5 caratteri:
MSC LSC
T S D O F
T: Tipo di messaggio che viene trasmesso:
P: Modalità di programmazione che viene eseguita per informare l’interfaccia verso i dispositivi di quali e quanti oggetti da comandare sono presenti nella stanza.
I: Il messaggio contiene un comando da eseguire su un determinato dispositivo.
S: Carattere minuscolo (per una migliore leggibilità) che indica la stanza alla quale è riferito il messaggio: a: ingresso b: corridoio1 c: corridoio2 d: corridoio3 e: cucina f: bagno1 g: bagno2 h: soggiorno1 i: soggiorno2 l: camera1
m: camera2 n: camera3 o: camera4 p: studio q: r: s: t: u: v: w: z:
D: Indica il dispositivo che si vuole comandare o al quale ci si riferisce: 0: luce1 1: luce2 2: tv1 3: tv2 4: vcr 5: dvd 6: hi-fi 7: riscaldamento 8: finestra1 9: finestra2 a: porta1 b: porta2
O: Indica il tipo di operazione da svolgere per quel dispositivo: A: apri finestra o porta
B: chiudi finestra o porta C: stop operazione su finestra D: accensione/ spegnimento E: pr + su TV F: G: pr – su TV H: vol + su TV I: vol- su TV L: temp + su riscaldamento M: temp – su riscaldamento N: play su dvd e vcr O: stop su dvd e vcr P: pausa su dvd e vcr Q: avanti veloce su dvd e vcr R: dietro veloce su dvd e vcr S: open/close su dvd e vcr
T: U: V: W: Z:
F: Carattere che indica la fine del messaggio.
•
CODIFICA DI PROGRAMMAZIONELa codifica di programmazione fornisce al gateway i dati per il comando dei dispositivi verso i quali è interfacciato. Per farlo manda una struttura, da memorizzare nella EEPROM del microcontrollore, in modo da caratterizzare completamente un dispositivo.
La codifica si basa sulla trasmissione di caratteri e numeri ed è così fatta:
T S N°
campo Valore
N°
campo Valore Valore ……….. F
T: carattere che indica il tipo di messaggio trasmesso:
P: Modalità di programmazione che viene eseguita per informare l’interfaccia verso i dispositivi di quali e quanti oggetti da comandare sono presenti nella stanza.
I: Il messaggio contiene un comando da eseguire su un determinato dispositivo.
S: indica la stanza alla quale è riferito il messaggio (vedi codifica di comando).
N° campo: in queste parti (lunghe un byte) viene mandato il numero del campo della struttura al quale va assegnato il valore seguente. Il programma, conoscendo il tipo dei campi della struttura, determina la lunghezza di tale valore. Ad esempio se il campo n°1 è un unsigned char, il programma sa che il valore da immettere in questo campo è il byte successivo. Mentre invece, se il campo n° è un intero, il programma interpreta i due successivi byte come valore per il campo 2. Per maggiori chiarimenti si rimanda il lettore al capitolo 4.3.8relativo al file di programmazione.
Valore: contiene il valore da assegnare al campo della struttura puntato dalla sezione n° campo. Puó essere lungo da 1 fino a 4 byte.
F: Carattere che indica la fine del messaggio.
•
RISPOSTAPurtroppo il sistema di comunicazione a raggi infrarossi non garantisce un qualche segnale di ritorno verso il telecomando. Infatti tutti gli elettrodomestici presenti nelle abitazioni non sono provvisti di un emettitore IR, ma solo di un ricevitore. Per dare un minimo feedback all’utente circa il corretto funzionamento del sistema, il gateway manda all’UI il carattere “O” se l’invio è andato a buon fine, e il carattere “E” se c’è stato un errore.
4.3.4 Gestione della memoria EEPROM
Per leggere e scrivere dati nella memoria EEPROM sono state utilizzate delle funzioni presenti nel tool di sviluppo WinAVR. In particolare sono state utilizzate:
eeprom_read_byte funzione che permette la lettura di un byte. Richiede il passaggio
di un puntatore ad una locazione di memoria (ovviamente EEPROM) e restituisce il dato ivi presente.
eeprom_read_word come la precedente solo che legge il contenuto di 2 celle di
memoria e le interpreta come un numero a 16 bit.
eeprom_read_block questa funzione permette di leggere il contenuto di un numero
arbitrario di celle di memoria e di porle in una variabile. Richiede il passaggio del numero di byte che vogliamo leggere, un puntatore alla prima locazione da leggere e un puntatore alla prima locazione della variabile dove vogliamo salvare i dati.
eeprom_write_byte scrive un byte in EEPROM. Richiede il dato da scrivere e un
puntatore alla locazione di memoria interessata.
eeprom_write_word come il precedente solo che scrive 2 byte e richiede un puntatore alla prima locazione di memoria da scrivere.
eeprom_write_block scrive un blocco di byte in memoria. Richiede il numero di byte da scrivere, un puntatore alla prima locazione contenente il dato da scrivere e un puntatore alla prima locazione di EEPROM dove il dato andrà scritto.
Tutte le funzioni sopra elencate controllano lo stato della EEPROM prima di effettuare qualsiasi operazione: se questa è pronta procedono con il loro compito, altrimenti attendono qualche ciclo di clock e poi eseguono nuovamente il controllo.
Da notare che la lettura o la scrittura in EEPROM sono operazioni sensibilmente più lunghe rispetto alle stesse operazioni eseguite in RAM; basti pensare che una lettura in EEPROM occupa la CPU per 4 cicli di clock.
4.3.4 Gestione della porta USART
La porta USART (Universal Synchronous and Asynchronous serial Receiver and
Transmitter) viene utilizzata in modalità asincrona per colloquiare con l’interfaccia utente.
Per la gestione di questa interfaccia sono stati creati due buffer: uartRxBuffer contenente i dati ricevuti e uartTxBuffer per i dati da trasmettere. Questi due buffer sono gestiti dalle seguenti funzioni:
uartInit funzione che inizializza la porta UART, abilita l’interrupt da UART in
ricezione e trasmissione, setta il baud rate e infine abilita l’interrupt sul microcontrollore. uartGetByte preleva un byte dal buffer dove sono posti tutti i dati ricevuti via seriale. uartAddToTxBuffer aggiunge un byte alla fine del buffer contenente i dati da trasmettere via seriale.
uartSendTxBuffer trasmette il primo byte contenuto nel buffer di trasmissione e successivamente cancella l’elemento trasmesso; in questo modo quando la funzione verrà richiamata potrà trasmettere l’elemento successivo.
Per sapere quando arriva un messaggio sulla porta seriale, viene utilizzato l’interrupt generato quando viene ricevuto un byte sulla porta UART. Per la gestione dell’interrupt è stata scritta la funzione UART_INTERRUPT_HANDLER di seguito riportata.
UART_INTERRUPT_HANDLER(SIG_UART_RECV) {
u08 z;
//incremento il contatore di caratteri count++;
//acquisisco il byte ricevuto da uart0
z = inb(UDR);
// controllo l'arrivo del fine messaggio if (z == 'F') fine = 'F';
//metto il byte ricevuto nel buffer_uart_rx
bufferAddToEnd(&uartRxBuffer, z);
}
Come possiamo vedere, è prevista una variabile count per contare il numero di byte ricevuti. La funzione acquisisce il byte ricevuto e verifica che sia stato ricevuto il byte di fine messaggio; questo indica che il messaggio è terminato e la funzione pone la variabile fine = “F” in modo da indicare al main che la ricezione è terminata e si può passare all’analisi dei dati.
4.3.5 Gestione del Timer
Per realizzare la frequenza portante dei vari codici, è stato utilizzato il contatore interno al microcontrollore TIMER2 a 8 bit. Effettuando questa scelta, la CPU può svolgere anche altre operazioni mentre viene generata la portante. I timer presenti nel microcontrollore possono funzionare in differenti modalità: normale, CTC, PWM con controllo di fase e FAST PWM. Noi utilizziamo la modalità CTC (Clear Timer on Compare match) nella quale il contatore si resetta una volta raggiunto un particolare valore (da immettere nel registro OCR2) impostabile dall’utente. La modalità di funzionamento del timer2 può essere impostata mediante il registro di stato TCCR2 il quale permette anche di settare il comportamento del bit di uscita del timer (il bit OC2) e di scegliere la frequenza di clock con cui effettuare il conteggio. Più precisamente, immettendo in TCCR2 il valore 25 si setta il funzionamento in modalità CTC con uscita collegata al pin PD7 (ovvero il bit più significativo della porta 7 del microcontrollore) che si inverte ogni volta che il contatore arriva al valore immesso nel registro OCR2.
Il numero da porre come tetto nel conteggio in modo da ottenere la frequenza voluta è calcolabile tramite la formula citata nel datasheet:
(
2 1)
2∗ ∗ + = OCR N f f clk timerdove N indica il fattore di divisione della frequenza di clock (detto prescaler).
In questo modo è possibile realizzare la portante nel range di frequenze utilizzate dalla codifica IR (tipicamente 35 kHz – 40 kHz) con un’ottima precisione.
4.3.6 Gestione del risparmio energetico
Questo aspetto è molto importante per il nostro dispositivo in quanto è dotato di autoalimentazione. Il microcontrollore Atmel ATMega32 prevede diverse modalità di power saving: si va dall’idle mode al più parsimonioso Extended stand-by.
Riflettendo un attimo sul possibile uso del nostro dispositivo, possiamo supporre che questo passerà la maggior parte del proprio tempo in attesa di un messaggio da parte dell’interfaccia utente. È quindi plausibile la scelta di far stare il microcontrollore in power saving durante questa attesa. Purtroppo l’unica modalità adatta ai nostri scopi è la meno economica idle mode in quanto è l’unica dalla quale il microcontrollore può uscire alla ricezione di un interrupt sulla porta USART. Possiamo osservare il vantaggio economico che si ottiene con questa scelta dalla tabella 4.1 ricavata dai datasheet della Atmel.
Tabella 4.1: Risparmio energetico ottenibile con l'idle mode
PARAMETER CONDITION MIN. TYP. MAX. UNITS
Active 8 MHz, Vcc=5 V 12 15 mA
Power Supply
Current Idle 8 MHz, Vcc=5 V 5.5 8 mA
Per attivare la modalità di risparmio energetico, dobbiamo agire sul registro principale del microcontrollore (MCU Register). Più precisamente dobbiamo settare il bit 7 SE (Sleep
Enable) per abilitare il power saving e settare opportunamente i bit 6-4 (rispettivamente
gli SM. Una volta abilitato settato il bit SE, il microcontrollore entrerà in sleep mode quando incontrerà l’istruzione SLEEP. Per evitare che errori, il produttore raccomanda di settare il bit SE vicino all’istruzione SLEEP e di resettarlo non appena questa è stata eseguita.
4.3.7 Il bootloader
Uno degli aspetti più interessanti dei nuovi processori Atmel, è quello di poter adibire parte della memoria flash ad un bootloader. I bootloader sono programmi che vengono eseguiti al power-on del microcontrollore e possono eseguire due operazioni: iniziare il normale funzionamento lanciando il programma principale, oppure possono entrare in una modalità di programmazione durante la quale è possibile aggiornare il programma principale senza l’ausilio di hardware particolari o dedicati (Self Programming). Questo per il progettista è un grande vantaggio in quanto permette l’assemblaggio hardware anche se il firmware non è giunto all’ultima versione. Dal bootloader trae vantaggi anche l’acquirente che può aggiornare l’ultimo firmware rilasciato dal produttore senza grandi conoscenze informatiche o elettroniche.
I processori della serie ATMega hanno la memoria FLASH organizzata in due sezioni principali: la Application Section e la Boot Loader Section. La sezione Application è usata per contenere il codice principale del firmware mentre la Boot Loader Section contiene appunto il bootloader. La divisione tra le due parti non è fisica, ma viene effettuata in base alla grandezza del bootloader tramite il setting di alcuni fuse bits.
E’ molto interessante notare che, durante il Self-Programming il microcontrollore può continuare a rispondere alle richieste degli interrupt critici avendo la possibilità software di spostare il vettore degli interrupt della Application Section alla Boot Section.
La programmazione può avvenire attraverso qualsiasi interfaccia del microcontrollore (USART, SPI, TWI, …) agevolando le operazioni nel caso di posizioni fisiche difficili da raggiungere. Nel nostro caso, utilizzando la porta UART per la comunicazione con l’interfaccia utente, è possibile effettuare un aggiornamento del firmware del
microcontrollore direttamente dall’UI via radio senza dover accedere fisicamente all’oggetto.
Il boot loader da noi utilizzato è 512 words ovvero 1024 byte ed è implementato per interfacciarsi con l’applicazione Megaload (di cui abbiamo già parlato in precedenza).
4.3.8 Il file PROGRAMMAZIONE
Per garantire la compatibilità con un grande numero di dispositivi e utilizzare il database fornito da LIRC, è stato necessario ricostruire una struttura simile e quella utilizzata dal programma open source per caratterizzare un dato telecomando. Le dimensioni e la complessità di tale struttura sono piuttosto imponenti, ma questo è stato necessario per caratterizzare i moltissimi tipi di dispositivi indirizzabili indipendentemente dal tipo di protocollo utilizzato per la trasmissione.
L’idea è quella di inserire nella EEPROM di ogni microcontrollore della rete casalinga un insieme di strutture (chiamate remote) caratterizzanti i dispositivi presenti nella stanza che devono essere comandati. Ciascuna struttura è formata da vari campi: andiamo a descriverli.
•
Nome: lungo un byte, indica il tipo di dispositivo a cui si riferisce la struttura in accordo col campo S della codifica di comunicazione.•
Bits: indica da quanti bit è formato il messaggio da trasmettere.•
Flags: lungo 2 byte, permette di riconoscere il tipo di modulazione utilizzato dal dispositivo.•
Pheader, Sheader: indicano rispettivamente tempo di impulso alto e basso dell’header (se presente). Ciascuno è lungo 2 byte e il valore del tempo è espresso in microsecondi.•
Pone, Sone: come il precedente in relazione al bit 1.•
Plead: lungo 2 byte, indica la durata di un impulso che viene mandato tra l’header e il corpo del messaggio.•
Ptrail: come il precedente, solo che viene mandato dopo il corpo del messaggio.•
Pfoot, Sfoot: indica la temporizzazione della parte alta e parte bassa dell’impulso che viene spedito alla fine del messaggio.•
Pre_data_bits: indica da quanti bit è formato il pre data.•
Pre_data: lungo 4 byte, indica la codifica del dispositivo e viene mandato prima del corpo messaggio.•
Post_data_bits: indica da quanti bit è formato il post data.•
Post_data: lungo 4 byte, indica la codifica del dispositivo e viene mandato dopo il corpo del messaggio.•
Toggle_bits: se presente indica quale dei bit del messaggio è il toggle bit.•
Freq: indica la frequenza della portante espressa in hz.•
Nome_cmd1: indica, in accordo alla codifica di comunicazione, a quale comando si riferisce il campo successivo. Ad esempio, se il dispositivo è un TV, nome_cmd1 può contenere il carattere “D” o “E” ecc.•
Cmd1: lungo 4 byte, contiene la codifica del comando indicato dal campo precedente. Seguendo l’esempio precedente, nel primo caso conterrà la codifica del comando accensione/spegnimento, mentre nel secondo quella relativa al comando Pr+.•
Nome_cmd2: come il campo nome_cmd1.•
Cmd2: come cmd1.•
Seguono altri 8 campi uguali ai precedenti fino ad arrivare a cmd6.Per fare un firmware adatto a tutte le stanze di un’abitazione, in EEPROM vengono inizializzate le strutture relative a tutti dispositivi previsti dal campo “D” della codifica di comunicazione. Al momento dell’istallazione, in relazione alla stanza in cui verrà posto il gateway e al tipo di dispositivi presenti, verranno spediti dall’UI solo i dati relativi agli elettrodomestici realmente disponibili. Avremo quindi le variabili LUCE1, LUCE2,
PORTA1, TV1, ecc presenti in tutti i microcontrollori del sistema; successivamente verranno spedite via radio dall’interfaccia utente solo le strutture relative ai dispositivi presenti in una data stanza (ad esempio se su gateway è posto in una stanza dove c’è un solo TV, verranno mandati solo i dati relativi alla TV1, non quelli della TV2).
La funzione progr si occupa di copiare i dati arrivati col messaggio di programmazione, nella EEPROM del microcontrollore. Viene chiamata nel main e riceve il puntatore alla terza locazione dell’array dei dati ricevuti che, come si vede dalla codifica di programmazione, è quella contenente il primo numero di campo. Lo scopo di questa funzione è di trascrivere i dati arrivati dall’UI nella locazione di EEPROM appropriata. Il maggiore problema incontrato è stato quello relativo alla differente grandezza dei campi della struttura remote. Per questo motivo nella codifica di programmazione non era possibile mandare solo i dati che dovevano essere scritti, ma dovevamo mandare anche un riferimento al campo a cui erano collegati tali valori.
L’idea utilizzata nella progettazione di questa funzione è stata proprio quella di capire la grandezza del dato da scrivere in base al valore del “Numero campo” nel messaggio ricevuto. Per prima cosa il programma si allinea alla struttura del dispositivo indicato nel messaggio arrivato dall’interfaccia utente. Successivamente viene eseguito un case sul “Numero campo” e, conoscendo in anticipo la grandezza dei dati a esso collegati, si vanno a leggere e scrivere un numero adeguato di byte. Possiamo genericamente riassumere le azioni che il programma compie per scrivere i dati:
• Inizializza una variabile (ncamp) mediante un puntatore variabile alla locazione dove è contenuto il primo “Numero campo” del messaggio ricevuto.
• Opera il case sulla variabile.
• In base alla scelta precedente, scrive in una variabile il contenuto di un numero variabile (da 1 a 4) di byte successivi al “Numero campo”.
• Scrive la variabile di cui sopra nel campo, scelto in base al case, della struttura residente in EEPROM relativa al dispositivo indicato nel messaggio ricevuto dall’UI.
• Incrementa il puntatore variabile della prima operazione in base al numero di byte che sono stati letti e aggiorna la variabile ncamp.
Figura 4.6: Diagramma di flusso della funzione progr
Facciamo un esempio per chiarire meglio le idee. Chiamiamo radio il puntatore variabile, supponiamo di essere al primo passaggio e vediamo in dettaglio le operazioni eseguite:
• Radio punta al campo “Numero campo” = 1.
• La variabile ncamp viene inzializzata al contenuto della locazione puntata da radio
• Faccio il case su ncamp .
• Essendo il primo campo della struttura remote formato da un solo byte, il programma legge il contenuto della locazione puntata da radio + 1.
• Il dato precedentemente letto, viene scritto nel campo nome (in quanto “Numero campo” = 1) della struttura remote residente in EEPROM.
• Il puntatore radio viene incrementato di 1 in quanto è stato letto un solo byte. • Si ripete il ciclo.
Agendo in questa maniera, riusciamo a scorrere tutto il messaggio arrivato e a porre i dati arrivati nei campi giusti.
Per prevenire gli errori si fanno due controlli. Il primo viene fatto all’inizio della funzione analizzando il primo “Numero campo” ricevuto. Se questo è uguale a 1 allora si passa al controllo successivo, nel quale si guarda il secondo byte ricevuto che dovrebbe contenere il nome del dispositivo da programmare. Se questo è tra quelli conosciuti allora si può passare alla scrittura della struttura inizializzata grazie a questo controllo. Infine l’ultimo controllo che si esegue è nel case: se arrivano più di 29 campi si esce riportando l’errore. Nel caso in cui uno dei controlli sia andato storto, si esce dalla funzione “ritornando” il carattere “E” caratterizzante la presenza di un errore. In caso contrario il carattere si trasforma in “O” per indicare che tutto è andato bene.
4.3.9 Il file INVIA
Questa parte del programma è stata senza ombra di dubbio la più difficile da concepire e realizzare dato l’enorme numero di codici IR attualmente in circolazione. Inoltre le difficoltà sono aumentate in quanto i codici differiscono per tipo di modulazione, frequenza della portante e struttura del messaggio stesso. Questo non ha permesso l’utilizzo di una funzione scritta ad hoc per un particolare codice, in quanto ne sarebbero servite moltissime. L’unica altra strada da percorrere era la realizzazione di una funzione “universale” in grado di inviare qualsiasi struttura. Anche in questo caso però, le difficoltà erano molte. Come abbiamo visto nel capitolo 2, ogni codice ha le proprie caratteristiche che non vengono neanche rilasciate dalla casa produttrice e quindi vanno trovate sperimentalmente o mediante il lavoro di altri. In questo senso ci è stato di grande aiuto il database di LIRC che contiene i dati relativi a moltissimi dispositivi esistenti archiviati sotto forma di file di configurazione del programma stesso. Questi file contengono tutte le informazioni necessarie per l’invio del codice di un particolare dispositivo: è quindi bastato “decifrare” queste informazioni per ottenere i dati necessari.
Il file invia contiene numerose funzioni tra cui uno, zero, unos, zeros e unob che si incaricano dell’invio del singolo bit. Uno e zero vengono chiamate nel caso di
modulazione PWM mentre unos e zeros vengono utilizzate qualora si abbia una modulazione PWM nella quale i bit siano inviati prima spazio e poi impulso. Infine unob viene invocata, insieme a zero, qualora si abbia una modulazione bifase.
La funzione invia è quella che provvede alla conversione delle informazioni mandate in codice e al successivo invio. L’idea nella realizzazione di questa funzione è di analizzare i dati presenti in EEPROM circa il dispositivo che dobbiamo indirizzare e in base a questi creare una stringa di bit che costituisce il messaggio da inviare. Nel fare questo, si è cercato di concepire un metodo che fosse il più universale possibile in modo da poter indirizzare il maggior numero di dispositivi e di poterci adattare semplicemente e velocemente verso nuovi codici.
Come già visto precedentemente, per realizzare la portante è stato utilizzato il contatore interno al microcontrollore TIMER2 utilizzato in modalità CTC.
La durata dei bit è stata implementata mediante un contatore software che viene inizializzato al valore adatto per quel particolare codice. In pratica quando dobbiamo inviare la parte alta dell’impulso, viene fatta partire la portante e avviato il contatore con un preciso valore. Al termine del conteggio, viene disattivata la portante, messo a zero il relativo piedino e viene iniziato un altro conteggio per la parte bassa del bit. Il ritardo introdotto dalle operazioni indicate sulla durata del bit, è del tutto trascurabile in quanto il microcontrollore lavora ad una frequenza (8 MHz) che è ordini di grandezza superiore rispetto alla durata dei bit (oscillante tra 500 µs e 1200 µs circa). La funzione utilizzata è la _delay_loop_2 che si basa su un contatore a 16 bit. È stata scelta questa funzione in
quanto, considerando che il nostro clock ha una frequenza di 8 MHz e che la funzione dura 4 cicli macchina, consente conteggi fino a 32,7 ms.
La funzione invia si divide in due parti principali: la parte di preparazione del messaggio e la parte di invio vero e proprio.
Nella prima parte, viene copiata la struttura relativa al dispositivo da indirizzare in RAM per un accesso più veloce e ne vengono analizzati i campi in modo da trarne la corretta stringa di bit da inviare. Si parte dall’analizzare il campo pre data bits che, se diverso da zero, indica da quanti bit è formata la prima parte del codice. Se il valore è diverso da zero, viene operata una conversione sul campo pre data per trasformarlo da
numero intero a stringa di bit. La conversione viene effettuata attraverso delle divisioni successive in cui il pre data è il dividendo, la variabile pot è il divisore e il risultato viene posto nel vettore send[]. La variabile pot contiene la massima potenza del 2 raggiungibile con il numero di bit indicato dal campo pre data bits. Ad esempio, se il campo pre data è formato da 3 bit, la variabile pot verrà inizializzata al valore 4 (dato da 2²). Ad ogni passaggio della divisione, pot viene dimezzata, il resto della divisione viene posto in pre data e si passa alla locazione successiva del vettore send[].
Una volta analizzato il campo pre data, si passa al campo comando dove avviene il primo controllo sul messaggio arrivato. Si guarda infatti, che il dispositivo indicato abbia tra i comandi che è in grado di eseguire, quello arrivato dall’UI. In caso negativo si esce mandando il segnale di errore mentre in caso affermativo si continua con una divisione del tutto analoga alla precedente. In questo caso la variabile com fa da dividendo e pot continua a fare da divisore dopo essere stata calcolata nuovamente. I quozienti delle divisioni vengono ancora messi in send[] accodandoli ai precedenti dati esistenti (ovviamente sempre che questi siano presenti).
La creazione della stringa di bit da inviare si chiude con l’analisi del campo post data bits del tutto simile a quella utilizzata per il campo pre data bits.
L’ultima cosa da verificare è se il campo flags contiene il dato reverse (ovvero i dati contenuti nel file di configurazione vanno invertiti prima dell’invio). In caso affermativo si inverte il vettore send[] appoggiandosi su un secondo vettore send_inv[], altrimenti non si effettua nessuna operazione.
A questo punto la stringa di bit da inviare è completa, ma prima di passare all’invio, si calcolano tutti i valori da mettere nei contatori software in modo da velocizzare la fase di invio e ottenere un segnale che sia il più accurato possibile. Il calcolo dei valori viene effettuato in diverse operazioni per garantire il corretto troncamento dei dati da parte del compilatore. La formula globale utilizzata è :
(
)
(
)
[
durata_in_µs * freq_CPU/106]
/4Per inviare i dati, occorre sapere la frequenza della portante. Quindi si guarda il campo freq della struttura relativa al nostro dispositivo. Se questo è zero, la portante viene inizializzata alla frequenza standard di 38 kHz in quanto nei file di configurazione di LIRC
è prevista tale frequenza se non indicato diversamente. Se invece il campo freq è diverso da zero, si calcola il valore di tetto per il nostro contatore hardware TIMER2 secondo la formula specificata precedentemente.
Una volta stabilita la frequenza della portante si può iniziare ad inviare il messaggio partendo dall’header che, se presente, è il primo campo da inviare. Il programma fa un controllo sul campo pheader (quello in cui si trova il dato relativo alla parte alta dell’impulso header) e se questo è diverso da zero spedisce il campo, altrimenti va avanti effettuando lo stesso controllo sul campo plead.
A questo punto la funzione analizza il campo flags per vedere di che tipo sono i dati da inviare; infatti come abbiamo precedentemente visto, ci sono diverse funzioni relative all’invio del bit uno e del bit zero dipendenti dal tipo di modulazione e codifica adottati dal protocollo. In base al valore nel campo flags, si sceglie quale funzione chiamare per l’invio del bit (uno, unos, unob ecc.) e si scorre la stringa send[] fino a che non si è terminato l’invio. Ma come fare per sapere da quanti bit è composto il messaggio? Si usa una variabile che viene aggiornata ogni volta che si scrive un dato nell’array send[] e la si mette come limite superiore nel ciclo for utilizzato per scorrere l’array.
Terminato l’invio dei bit, si guarda se il protocollo di quel particolare dispositivo ha un ptrail o un pfoot ed eventualmente lo si spedisce trovando il valore relativo alla durata degli impulsi nei rispettivi campi della struttura.
Figura 4.7: Diagramma di flusso della funzione invia
Terminato l’invio del comando al dispositivo indicato, la funzione invia “ritorna” al main il carattere “O” se tutto è andato correttamente oppure il carattere “E” se qualcosa è andato storto.
4.3.10 Il file MAIN
Questo file è quello che contiene la funzione principale (detta main appunto) dell’intero programma.
Gli aspetti principali di questa funzione sono:
• Ricevere via seriale il messaggio dall’interfaccia utente • Capire se il messaggio è corretto
• Chiamare la funzione invia o la funzione progr e passargli i giusti parametri • Trasmettere all’interfaccia utente la buona o cattiva riuscita dell’operazione
Dato che è previsto l’inserimento di un gateway in ogni stanza dell’abitazione, ogni microcontrollore ha nella propria EEPROM una variabile identificativa della stanza in cui è posto.
All’accensione del sistema, il programma inizializza la porta USART e abilita la ricezione di interrupt. Fatto questo attiva il power-saving e si mette in modalità idle aspettando l’invio di un messaggio da parte dell’interfaccia utente.
All’arrivo di un byte, il programma si sposta nella routine di interrupt nella quale prende il dato arrivato e lo analizza per vedere se è il carattere di fine messaggio e se la quantità di caratteri arrivata è giusta.
Quando un messaggio è arrivato completamente, il programma inizia a controllarne la validità. Per prima cosa viene controllato il byte relativo alla stanza per vedere se il messaggio era effettivamente indirizzato al dispositivo in questione. Successivamente si guarda il tipo di messaggio arrivato: se è un messaggio di programmazione, si passano i dati alla relativa funzione; altrimenti se è un messaggio di comando, si passa ad analizzare il byte relativo al comando per assicurarsi che sia un campo valido. Infine, se tutte le verifiche hanno avuto successo, si chiama la funzione invia passandogli i dati arrivati via USART.
Una volta inviato il messaggio, il programma segnala all’interfaccia utente l’esito dell’operazione inviando il carattere “O” in caso di successo e il carattere “E” in caso di errore. In questo modo si riesce a dare un minimo di feedback all’utente in modo da fargli
sapere se il funzionamento del sistema è stato corretto. Purtroppo non è possibile realizzare un feedback circa l’effettiva attuazione del comando in quanto il protocollo IR non prevede che gli elettrodomestici possano inviare segnali.
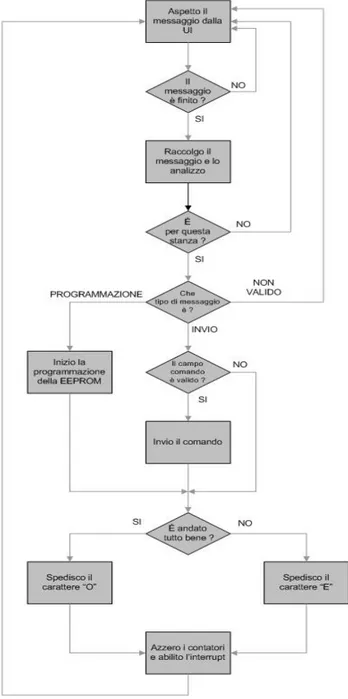
Figura 4.3: schema a blocchi della funzione main
Come possiamo vedere abbiamo quattro livelli di sicurezza nel controllo del messaggio ricevuto. Nel primo si controlla il byte relativo alla stanza, nel secondo si effettua un
controllo sul tipo di messaggio, nel terzo ci si accerta che il campo comando sia valido e infine nel quarto si verifica la reale esistenza del dispositivo che si vuole indirizzare.
4.3.11 Debug del software
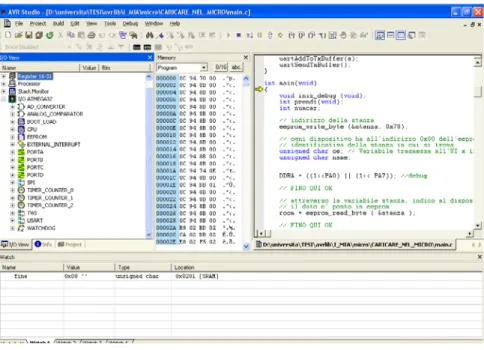
L’organizzazione modulare del firmware ha permesso un comodo debug di alcune parti mentre ne venivano scritte altre e ha inoltre facilitato l’eliminazione di malfunzionamenti. Il debug è avvenuto principalmente utilizzando il potente simulatore contenuto all’interno del programma AVR Studio 4. Tale simulatore permette di scegliere il microcontrollore e di impostarne tutti i parametri. Offre inoltre la visione di tutti i registri, di tutte le porte e anche dei vari dispositivi hardware presenti all’interno del microcontrollore nonché delle varie memorie. Il simulatore permette inoltre di visualizzare il contenuto delle variabili che vogliamo tenere sotto controllo. È quindi possibile caricarvi il programma compilato e scegliere se eseguire un procedimento step-by-step oppure un run diretto.
Grazie a questo potente strumento è stato possibile analizzare i vari file di cui è composto il nostro firmware individualmente eliminando le imperfezioni e i problemi per poi passare ad una simulazione completa in modo da risolvere gli eventuali problemi di interfacciamento tra i vari blocchi del programma globale.
Figura 4.4: Schermata dell'AVR Studio 4
Da notare che è possibile sia inserire il file già compilato, sia farlo compilare al simulatore stesso.
L’utilizzo di questo programma è stato molto importante in quanto ci ha permesso di poter risolvere i problemi software senza dover ricorrere alla programmazione del microcontrollore, velocizzando molto lo sviluppo.