3. Requisiti
3.1 interfacce utente per biblioteche digitali
Un’interfaccia utente è di solito intesa come una serie di menus, finestre, la tastiera, il mouse, ed in generale, tutti i canali informativi che permettono all’utente ed al computer di comunicare. Ma in un certo senso, non importa quanto bene essi siano implementati, l’interfaccia risulterà fallimentare se il sistema non soddisfa le esigenze dell’utenza, in un modo che all’utente risulta essere appropriato. In altre parole il sistema deve soddisfare tutti gli obiettivi dell’utente, in gergo “user’s tasks”.
Per tale motivo tutti gli approcci moderni per la realizzazione di interfacce, per lo meno quelli più significativi da un punto di vista qualitativo, seguono il cosiddetto approccio “Task-Centered” per la progettazione, teorizzato da Lewis e
Rieman[Rif-20].
Cominciamo innanzitutto con il definire in maniera precisa il significato di interfaccia utente per biblioteca digitale di Seconda Generazione.
Un’interfaccia utente, come suggerisce il termine, è in generale la parte che in un’applicazione permette l’interazione fra il sistema e l’utilizzatore finale, e nella stragrande maggioranza dei casi si basa sul presupposto che l’utente non conosca in dettaglio l’implementazione e la struttura interna del sistema. L’interfaccia per una biblioteca digitale presenta anche delle caratteristiche in più. Anzitutto deve rivolgersi ad un “range” di utenti molto vario. Un utente che usufruisce dei servizi offerti da una biblioteca digitale ha delle esigenze ben precise; per prima cosa il suo interesse primario non riguarda la particolare forma estetica dell’interfaccia o l’elaboratezza della sua struttura né tanto meno desidera conoscerne il funzionamento o quello del sistema a cui si interfaccia, ma piuttosto pretende funzionalità ed efficienza dall’interfaccia e dal sistema. In altri termini vuole che il sistema trovi brevemente ed in maniera soddisfacente quello che egli cerca ed in particolare dall’interfaccia pretende che sia di semplice utilizzo, intuitiva e funzionale specialmente nei riguardi della presentazione dei documenti, visto che presumibilmente dovrà trascorrervi
è in realtà qualcosa di complesso, costituito da diversi tipi e formati di dati i quali possono mutare in quantità e forma nel tempo non solo con l’aumentare del materiale relativo all’argomento trattato dal documento, ma anche con l’evolversi delle infrastrutture tecnologiche per la catalogazione e la visualizzazione degli stessi.
Recentemente diverse organizzazioni ed istituti hanno sviluppato dei sistemi di biblioteche digitali su diverse aree di applicazione, come ad esempio eredità culturale[Rif-21], alfabetizzazione statistica[Rif-22], accesso a documenti multilingue[Rif-23], ricerca bibliografica[Rif-24], ecc… Tuttavia degli studi hanno rivelato che molto ci si aspetta ancora dallo sviluppo delle interfacce utente per l’accesso a tali sistemi[Rif-25]. La critica maggiore che è stata mossa alle diverse implementazioni di interfacce per biblioteche digitali è che la loro scarsa usabilità è attribuibile all’assenza di un approccio orientato all’utente nello sviluppo di tali sistemi. Tuttavia questa è solo una parte del problema. Un altro aspetto ugualmente importante nello sviluppo delle interfacce è l’importanza di un cosiddetto “HCI design and development”, ovvero lo studio, l’analisi e l’implementazione di una struttura dell’interfaccia tale da rendere ottimale l’interazione fra l’utente finale ed il Computer[Rif-26]. In altri termini l’implementazione dell’interfaccia è importante tanto quanto un suo previo studio metodologico ed analitico.
3.2 Problematiche fondamentali
La maggior parte delle biblioteche digitali esistenti sono state implementate sulla base di requisiti molto specifici e per tale motivo il loro sviluppo è indirizzato alla risoluzione di problematiche piuttosto ristrette e settoriali. Questo se da una parte provvede a soddisfare in maniera abbastanza sufficiente una certa fascia di utenti, comunque molto ristretta, non consente dall’altra l’utilizzo del sistema per scopi di carattere più generale, rendendone peraltro molto difficile una espansione delle funzionalità per venire incontro a delle nuove necessità.
Quindi la problematica principale che una biblioteca digitale di Seconda Generazione si propone di risolvere, è quella di fornire un servizio di gestione di dati il più possibile eterogenei rivolgendosi ad una panoramica di comunità di utenti che sia la più ampia possibile.
Il punto fondamentale da tenere in considerazione è comunque il seguente: esattamente come accade per una biblioteca reale, nell’accezione più generale del termine, una biblioteca digitale utilizzata da una certa comunità di utenti deve comunque rispondere ad una serie di requisiti funzionali dettati dalla comunità stessa e specifici per essa. Ad esempio, una biblioteca di carattere scientifico avrà una struttura e delle esigenze senz’altro diverse da una biblioteca di carattere letterario. Sarebbe dunque sbagliato affrontare il problema cercando di implementare un sistema “statico” che cerchi di rispondere alla più vasta quantità di richieste possibili, bensì è necessario implementare un sistema che sia il più possibile configurabile ed espandibile, in modo che si adatti perfettamente alle esigenze delle specifiche comunità, anche future.
L’interfaccia utente per un sistema di tal genere è senz’altro un punto fondamentale della problematica. Essa infatti è la parte che in maniera più diretta si rivolge alle diverse comunità di utenti. Deve tener conto non solo della diversità dei dati richiesti dalle comunità, e quindi della diversa struttura degli stessi e dei diversi modi in cui essi possono essere ricercati e rappresentati, ma anche delle diversità culturali ed etniche delle comunità stesse. Ad esempio una biblioteca medica rivolta ad un pubblico di vario grado culturale avrà delle necessità di reperibilità e rappresentabilità dei dati diverse da quelle di una rivolta ad un comunità di medici o
professionisti del settore. La reperibilità e la rappresentabilità dei dati sono due punti chiave del problema dell’implementazione di un’interfaccia utente.
Il problema della reperibilità consiste nel presentare un’interfaccia di ricerca dei dati adatta alla comunità, che cioè fornisca dei risultati adeguati alla stessa, ovvero né pochi né troppi. Un esempio tipico di diversificazione dell’interfaccia utente in questo senso, consiste nei due diversi tipi di interfacce per la ricerca: “semplice” ed “avanzata”. Il concetto può comunque essere esteso a considerazioni di carattere più generale, per esempio si potrebbe diversificare anche la quantità e la qualità delle informazioni associate ai risultati della ricerca stessa.
Il problema della rappresentabilità consiste nel presentare un’interfaccia che sia il più possibile compatibile con le abitudini culturali degli utilizzatori. Infatti non solo si deve tener conto del fatto che i dati possono essere organizzati in maniera molto diversa, quindi si possono avere dei tipi e dei modelli di documenti molto diversi fra loro data la natura eterogenea dei dati immagazzinati nella biblioteca digitale (filmati, immagini, presentazioni ecc...), ma anche del fatto che vanno presentati in maniera differente alla comunità, sia in base al modo in cui la comunità è solita rappresentare e gestire l’informazione sia in base alle possibilità fisiche della comunità stessa. Ad esempio una biblioteca digitale rivolta ad un pubblico adulto avrà delle esigenze di rappresentabilità dell’informazione diverse da una rivolta ad un pubblico non adulto, come una biblioteca rivolta a delle persone non vedenti avrà delle esigenze differenti da quella rivolta ad un pubblico di persone vedenti.
Le interfacce utente oggi esistenti presentano delle notevoli mancanze. Esse infatti sono troppo standardizzate, ovvero offrono una insufficiente Interazione Uomo-Computer (HCI). Oltre a questo sono state implementate tutte tenendo poco presenti le reali esigenze degli utenti.
Da recenti studi sulle interfacce utente per biblioteche digitali, sono risaltati dei punti fondamentali. Le interfacce debbono essere disegnate in accordo al principio che l’utente deve massimizzare la sua interazione con le risorse, ovvero con le informazioni, e minimizzare la sua attenzione al funzionamento del sistema di per sé inoltre l’interfaccia deve “fornire sufficienti informazioni da guidare l’utente, ma non
abbastanza da farlo confondere”[Rif-27]. Tali principi possono essere riassunti nei seguenti punti fondamentali:
• Minimizzare il disorientamento riducendo la navigazione (scrolling, jumping, assenza di gerarchia) e ancorare l’utente in un contesto consistente.
• Fornire le informazioni principali più rapidamente possibile contestualmente all’interazione.
3.3 Requisiti utente
Obiettivi primari dell’interfaccia utente per una biblioteca digitale sono la Configurabilità e l’Espansibilità.
Abbiamo esaminato il concetto di biblioteca digitale giungendo alla conclusione che le informazioni in essa contenute possono essere consultate da diverse comunità di utenti, le quali differiscono tra loro per livello culturale, per fascia di età, per caratteristiche etniche, per capacità psico-fisiche. Inoltre abbiamo già sottolineato il fatto che i documenti archiviati nella biblioteca digitale in generale hanno un’evoluzione dinamica nel tempo, ovvero un documento che tratta di un determinato argomento difficilmente si esaurisce una volta archiviato, ma cresce man mano che nuove informazioni, scoperte o dissertazioni vengono sviluppate a proposito di questo stesso argomento. Non solo, un documento può cambiare anche strutturalmente nel tempo, infatti nuovi formati di memorizzazione e rappresentazione dell’informazione possono essere sviluppati nel tempo; così un documento nato come puro testo, può trasformarsi in un documento composto da testo, immagini, suoni, video ecc… ed ognuna di queste parti ha dei formati che mutano nel tempo in base allo sviluppo tecnologico o alle esigenze degli utenti della biblioteca digitale. In questo senso l’interfaccia per una biblioteca digitale deve essere:
a) Configurabile: per essere in grado di abbracciare il maggior numero di esigenze possibile. Gli eventuali amministratori della biblioteca digitale debbono essere in grado di modificare l’aspetto e la struttura dell’interfaccia utente senza essere costretti ad entrare in merito all’implementazione della stessa, così come gli utilizzatori dell’interfaccia debbono poter essere in grado di configurare semplicemente il proprio ambiente di lavoro, se necessario anche in maniera radicale, così da fornire loro un senso di controllo e di familiarità oltre che l’idea di un’interfaccia che vuole in qualche maniera venire incontro alle loro esigenze e non viceversa.
b) Espansibile: perché il sistema sia sempre al passo con i tempi e con lo sviluppo tecnologico. L’interfaccia deve essere concepita in modo che possa prevedere eventuali cambiamenti di struttura dei documenti e l’aggiunta di componenti e moduli che la rendano in grado di interpretare i nuovi formati di visualizzazione.
La miglior soluzione affinché l’interfaccia sia il più possibile Configurabile ed Espansibile è quella di concepirla strutturata in moduli. La struttura modulare permette infatti di scindere i compiti e le funzionalità, distribuendole, in base a dei criteri opportuni, ai diversi componenti. Perciò qualora fosse necessaria l’aggiunta o la modifica di alcune di queste funzionalità, sarà sufficiente aggiungere o modificare i moduli preposti. Inoltre questa soluzione consente di concepire in maniera abbastanza semplice un’interfaccia strutturata ad Oggetti. Se si immagina di avere un’interfaccia complessa costituita in realtà da una gerarchia di Oggetti più semplici, ecco che automaticamente otteniamo un qualcosa di profondamente malleabile, in quanto configurabile indipendentemente in ogni sua parte.
L’interfaccia è la parte della biblioteca digitale alla quale è delegato il compito di tradurre in qualche modo la volontà dell’utente in azioni concrete da effettuare sul sistema e di interpretare e rappresentare in maniera opportuna i risultati a cui queste hanno condotto. Abbiamo già in precedenza evidenziato il grosso problema della eterogeneità degli utenti del sistema.
L’obbiettivo implicito di questo progetto, è quello di elaborare una soluzione di interfaccia che conduca all’implementazione di un sistema dinamico ed altamente configurabile tale da poter essere plasmato ed adattato alle specifiche esigenze delle diverse classi di Utenza e che allo stesso tempo sia in grado di gestire la più vasta serie di esigenze possibili, piuttosto che un’interfaccia statica o semi-dinamica che pretenda di fornire una soluzione valida più o meno per tutti gli utenti del sistema. Soluzioni di tal genere infatti sono già state implementate e sono risultate fallimentari, soprattutto applicate ad un sistema quale è una biblioteca digitale, il quale non rappresenta solo una mera applicazione informatica, ma costituisce un vero e proprio servizio.
Lo scopo principale di una biblioteca digitale è quello di gestire una certa quantità di informazione, generalmente molto vasta, strutturata in un determinato modo e permettere all’Utenza interessata di reperirla e consultarla all’occorrenza. L’interfaccia deve fornire all’utente degli strumenti che lo rendano capace di navigare all’interno di questa vastità di informazioni, di reperire in maniera possibilmente rapida ed esaustiva le informazioni che desidera e di consultarle in maniera semplice e funzionale, ma soprattutto consona al suo profilo, cioè alle sue abitudini ed al suo
La corretta e funzionale Reperibilità delle informazioni è un obiettivo che l’interfaccia utente deve soddisfare. È importante presentare agli utenti delle interfacce e dei motori di ricerca adeguati ed efficienti, soprattutto per una biblioteca digitale in cui la parte di ricerca del materiale è un punto critico del servizio.
Come in una biblioteca Reale infatti l’utente si aspetta di essere aiutato il più possibile nella ricerca delle informazioni, e ritiene questo un servizio essenziale e dovuto. Con corretta e funzionale Reperibilità si intende la capacità da parte della biblioteca digitale di reperire la giusta quantità di informazioni desiderate, né più né meno, sarebbe infatti un grave errore presentare molti più risultati di quello che l’utente si aspetta, questo porterebbe infatti solo a disorientarlo e probabilmente a farlo desistere, e da parte dell’interfaccia la capacità non solo di guidare l’utente nell’utilizzo delle funzionalità di ricerca disponibili, ma anche di riuscire a venire incontro alle aspettative dell’utente dandogli magari la possibilità di scegliere fra più alternative e comunque presentandogli dei sistemi e dei modi di operare a lui il più possibile familiari e soprattutto comprensibili.
Un banale esempio di applicazione pratica di questo concetto lo si trova nella classica alternativa fra “ricerca semplice” e “ricerca avanzata” presente in praticamente tutti i motori di ricerca esistenti al mondo, ma può anche essere interpretato in maniera più astratta come la capacità del sistema di riuscire a capire in qualche modo cosa all’utente che ha di fronte possa realmente interessare così da procedere magari ad una prima scrematura dei dati reperiti. Per fare un esempio, consideriamo due diverse comunità di utenti che utilizzino una stessa biblioteca digitale, l’una costituita da studenti di scuole medie inferiori o superiori e l’altra da studenti universitari o ricercatori. È evidente come sia differente per le due comunità la necessità di reperire un certo tipo di informazione diversa sia dal punto di vista quantitativo che qualitativo. La stessa interfaccia dovrebbe proporsi alle due comunità per quanto riguarda i metodi di ricerca in maniera diversificata.
Al problema della Reperibilità è direttamente connesso il problema della Rappresentabilità dell’Informazione. Le stesse considerazioni fatte sulle diverse possibilità di reperire informazioni dalla biblioteca in base alle necessità dell’utente, possono essere fatte per la rappresentazione delle informazioni reperite.
Con rappresentazione intendiamo non solo l’aspetto grafico ed il design dell’interfaccia per la visualizzazione e la consultazione delle informazioni, ma anche
la capacità di discernere cosa sia più opportuno visualizzare o meno e, se esistono diverse scelte possibili, come rappresentare tali Informazioni.
Per fare un esempio eclatante, si pensino a due comunità di utenti, l’una costituita da un gruppo di bambini e l’altra costituita da un gruppo di adulti, oppure l’una costituita da un gruppo di non vedenti e l’altra costituita da un gruppo di non udenti. In entrambi i casi è evidente la necessità di avere delle interfacce differenti, nel primo caso in relazione alla quantità di Informazione ed alla diversa veste con cui andrebbe presentata e nel secondo caso in relazione proprio al diverso modo fisico di rappresentarla.
Da sottolineare il fatto che l’interfaccia rappresenta un particolare strato del sistema che dovrebbe cercare in ogni modo di soddisfare le esigenze dell’Utenza. Quindi nel progettare, o configurare, l’interfaccia è necessario prendere sempre come punto di riferimento l’utente finale piuttosto che il sistema da interfacciare, cosa che nella stragrande maggioranza dei casi non viene nemmeno presa in considerazione e che invece diventa obiettivo di questo progetto.
Un altro requisito molto importante che l’interfaccia dovrà soddisfare è quello di “distrarre” l’utente il meno possibile. L’interfaccia dovrà essere strutturata in modo tale da presentare nella maniera più immediata ed evidente possibile i riferimenti importanti che realmente interessano l’utente, che cioè siano coerenti con quello che è il suo reale obiettivo o lo scopo della sua ricerca. Evitare quindi il più possibile di presentare link o alternative inutili, ma anche gerarchie troppo profonde e menù eccessivamente ramificati[Rif-28] che indurrebbero solo confusione e distrazione nell’utente.
L’interfaccia dovrebbe sempre fare in modo da mantenere ancorato l’utente nell’ambito di uno stesso contesto, cioè avere una struttura quanto più possibile coerente sia dal punto di vista grafico che dei contenuti, inoltre deve essere strutturata in modo da fornire sempre una visibilità globale delle azioni svolte e dei percorsi seguiti, cercando quanto più possibile di dare la possibilità all’utente di tornare indietro come e quando vuole.
Queste caratteristiche rivestono una particolare importanza per l’interfaccia di una biblioteca digitale, a causa del modo stesso in cui l’utente è obbligato ad operare nell’ambito del sistema; infatti la ricerca e la consultazione dei Documenti nella
fatto che ad un Documento sono collegate molte annotazioni e riferimenti ad altri Documenti, oppure al fatto che gli argomenti trattati da un Documento possono essere approfonditi consultandone degli altri.
Possiamo riassumere questo come un ulteriore obiettivo del progetto catalogato in generale sotto il termine “Ridotta Navigabilità”.
Infine l’interfaccia deve raggiungere una serie di obiettivi minori ma lo stesso molto importanti per la riuscita del progetto, ovvero
a) Interattività: l’interfaccia deve comunicare il più possibile con l’utente, ovvero fornire aiuti nei passaggi più complessi e presentare esempi di utilizzo, anche semplici e schematici, ma chiari, nei casi in cui vengono introdotti metodi nuovi o innovativi che potrebbero risultare poco chiari all’utente. Oltre a questo l’interfaccia dovrebbe aiutare quanto più possibile l’utente nelle sue scelte o nelle sue azioni, quindi ad esempio potrebbe essere arricchita di Dizionari che correggano automaticamente gli errori di sintassi degli utenti o suggeritori che aiutino l’utente a raffinare o tarare le sue ricerche.
b) Usabilità: prima di tutto l’interfaccia deve essere funzionale. È preferibile un’interfaccia meno ricca o elaborata ma più “usabile” ad una molto bella dal punto di vista del design ma complessa e macchinosa. Gli utenti, in particolar modo quelli di una biblioteca digitale, hanno come primaria necessità quella di ottenere e visualizzare le informazioni che desiderano il più velocemente possibile, nella maniera più accurata e comprensibile possibile.
c) Comprensibilità: nell’allestire l’interfaccia è necessario sempre tenere presente il punto di vista dell’utente. Spesso gli addetti ai lavori tendono a trascurare dei dettagli importanti che rendono l’utilizzo dell’interfaccia molto più semplice ed intuitivo all’utente che per la prima volta si confronta con il nuovo sistema e con le nuove metodologie di utilizzo. Pur di risultare ridondante è necessario che un’interfaccia offra la massima disponibilità e versatilità all’utente, cercando di non sottovalutare mai nessun aspetto.
Questi tre obiettivi possono essere raggruppati sotto un unico aspetto dell’interfaccia che possiamo definire Intelligenza. Ulteriore obiettivo dell’interfaccia sarà quindi quello di non risultare un semplice mezzo di traduzione, se vogliamo, fra
l’Uomo e la Macchina, ma piuttosto un sistema elaborato e complesso che faccia dialogare le due parti nella maniera più naturale possibile per entrambe.
Riepilogo degli Obiettivi dell’interfaccia utente per biblioteche digitali di Seconda Generazione: Requisiti Utente Configurabilità Espansibilità Reperibilità Rappresentabilità Ridotta Navigabilità Intelligenza
3.4 Requisiti software
L’interfaccia dovrà essere un sistema complesso costituito da una serie di moduli più semplici, dei quali se ne fornirà la struttura dettagliata in seguito. Rendere l’interfaccia Modulare permette di:
a) Impedire che l’interfaccia sia troppo vincolata al sistema sottostante: anche se il progetto prevede una struttura di massima del protocollo per l’interfacciamento alla biblioteca digitale, comunque grazie alla modularità dell’interfaccia sarà sempre possibile modificare la struttura di alcuni dei moduli per soddisfare le esigenze dello specifico sistema, senza dover essere costretti a rivedere e modificare parti anche sostanziali del progetto.
b) Rendere l’interfaccia flessibile a cambiamenti e revisioni nel tempo: una struttura di tal genere permette di modificare o aggiungere dei moduli per venire incontro a esigenze future anche non previste nel progetto originario, o a cambiamenti anche radicali del sistema da interfacciare. Poiché comunque le operazioni di modifica saranno fatte sempre su singoli moduli e non sull’intera interfaccia, l’onere di lavoro da sostenere per le modifiche sarà sempre ragionevolmente ridotto.
c) Rendere l’interfaccia più semplice da esaminare e correggere in caso di errori o malfunzionamenti: la struttura modulare consente prima di tutto di identificare e confinare in maniera abbastanza precisa eventuali errori o malfunzionamenti dell’interfaccia e poi di correggerli andando a lavorare solo sui moduli interessati così da evitare di intaccare altre parti del sistema e di ingenerare altri possibili problemi.
d) Rendere L’interfaccia più tollerante ai guasti: la ridondanza di alcuni moduli e la corretta impostazione del protocollo di comunicazione fra essi, può fare in modo che l’interfaccia continui a funzionare anche in caso di guasti su alcune parti del sistema.
Altro vincolo che vogliamo l’interfaccia rispetti, è quello di fare in modo che ogni parte del suo design sia descrivibile sistematicamente per mezzo di un appropriato linguaggio, che chiameremo UIL (User Interface Language).
Ogni pagina o schermata dell’interfaccia utente deve essere costruita e descritta per mezzo di un linguaggio formale, appositamente definito per ogni specifico sistema.
Il concetto è molto simile al linguaggio HTML, ma l’impostazione e le regole sintattico-semantiche andranno estese e ridefinite così da creare un linguaggio in grado di descrivere univocamente tutti gli oggetti ed i moduli componenti questa specifica interfaccia, in quanto sistema complesso costituito da un insieme di servizi integrato a sua volta in un sistema ancor più complesso quale è la biblioteca digitale, con le funzionalità e regole per essa definite.
È possibile a questo punto individuare diversi tipi di possibili attori che andranno ad utilizzare l’interfaccia. I più importanti sono i Configuratori o Amministratori dell’interfaccia, che sono particolari utenti il cui compito è quello di configurare i servizi dei vari moduli in modo tale che si adattino perfettamente all’architettura della biblioteca digitale da interfacciare, e gli Implementatori o Designers, che sono coloro i quali andranno a disegnare le diverse parti dell’interfaccia per mezzo dell’UIL in modo da utilizzare al meglio tutte le funzionalità che la biblioteca digitale specifica metterà loro a disposizione.
Da qui la necessità di avere a disposizione un UIL. La possibilità di descrivere le parti dell’interfaccia tramite un linguaggio permette di adattare facilmente il sistema alle diverse esigenze e di modificare l’interfaccia agevolmente, soprattutto nel caso in cui si rende necessario espanderla per interfacciare nuovi servizi messi a disposizione dalla biblioteca digitale, ma soprattutto permette di separare nettamente i ruoli dei diversi attori, cosicché gli Implementatori non devono necessariamente essere gli stessi tecnici che installano, configurano o sviluppano l’interfaccia e la biblioteca digitale. Questo aspetto è fondamentale per il nostro progetto. Infatti in quasi tutte le interfacce utente per biblioteche digitali esaminate finora, molte lamentele sono state mosse dagli utenti sul fatto che esse risultavano troppo macchinose e poco comprensibili, in quanto sviluppate dagli stessi tecnici che avevano sviluppato il resto della biblioteca digitale, i quali però avevano trascurato o sottovalutato molti piccoli aspetti ed accorgimenti che avrebbero reso l’interfaccia più funzionale e congeniale agli utenti più importanti e cioè gli utilizzatori della biblioteca.
Ultimo ma fondamentale vincolo che l’interfaccia utente dovrà rispettare, è quello di essere concepita per funzionare su terminali leggeri definiti, in gergo “Thin Clients”.
Uno dei principali obiettivi di questo progetto, è quello di generare una interfaccia che sia adattabile alla più vasta fascia di utenti possibile. Sulla base di questa osservazione, è ovvio che non tutti gli utenti potranno usufruire di terminali per la visualizzazione dell’interfaccia aventi le stesse caratteristiche. Anzi le potenzialità dei terminali saranno molto eterogenee. Si pensi anche al fatto che un’interfaccia di tal genere potrebbe essere costituita anche solo da suoni o addirittura da alfabeto brail nel caso in cui debba rivolgersi ad un pubblico di non vedenti. Pertanto è necessario che tutto il lavoro di rendering dell’interfaccia avvenga a monte del terminale stesso, e che ad esso arrivino esclusivamente le informazioni minime per la visualizzazione.
Quindi non è previsto lo sviluppo di un software Client da installare sui terminali degli utenti per accedere alla biblioteca digitale, quanto piuttosto lo sviluppo di moduli appropriati che interpretino UIL e lo traducano in qualcosa di comprensibile allo specifico Client ed alla biblioteca digitale.
Una struttura si questo tipo per l’interfaccia è molto importante, in quanto la svincola completamente dal Client su cui dovrà essere visualizzata.
Riassumiamo ora schematicamente i vincoli che l’interfaccia dovrà rispettare:
Requisiti Software
Modularità U.I.L.
3.5 Metodologie e specifiche dei requisiti
Visto che nell’ambito del progetto OpenDLib era considerato molto importante documentare tutte le fasi di progetto e sviluppo softeware, abbiamo deciso di adottare delle metodologie di analisi ben consolidate ed in linea con gli standard del mercato attuali. Inoltre questo approccio non solo permetterà di specificare dettagliatamente i requisiti e i casi d’uso, ma anche il modello di dettaglio ovvero il design dell’applicazione.
La Specifica dei Requisiti verrà svolta adottando la metodologia di analisi RUP (Rational Unified Process), la quale prevede una progressiva specializzazione dei Requisiti a partire da una descrizione formale dell’Applicazione a livello “Business”, fino ad arrivare al Dettaglio del Diagramma delle Classi, avvalendosi di Use Case Diagrams, Activity Diagrams, Class Diagrams e Sequence Diagrams.
Se necessario tali diagrammi descrittivi dei Principali processi del sistema, saranno accompagnati da Data Flow Diagrams, Entity Relathionship Diagrams e Use Case Stereotypes (o Mappe di Navigazione).
Cenni sul Modello di analisi RUP
[Rif-29]
"It is very important to Sears' management to reduce the time it takes to deliver a software product to the user. While many factors contribute to time to market, by implementing the Rational Unified Process you can begin to get the consistent, repeatable processes throughout your company that ultimately result in reduced software product delivery time." (John Morrison, Solutions Consultant, Sears)
Rational Unified Process®, o RUP®, creata da IBM, è una piattaforma di processo configurabile per lo sviluppo del Software, la quale fornisce gli strumenti necessari per una corretta e dettagliata analisi del software ad ogni stadio del progetto.
La Metodologia RUP si basa sulla reale esperienza di applicazioni pratiche dell’Ingegneria del Software, attentamente sintetizzata in un insieme di metodlogie
Una delle fondamentali metodologie di RUP è la nozione di Sviluppo Iterativo. La metodologia prevede l’organizzazione dei progetti in termini di “discipline” e “fasi”, ognuna delle quali costituita da una o più iterazioni. Tramite l’approccio iterativo, ogni stadio del ciclo di vita del processo avrà un’enfasi diversa. Tale approccio inoltre ci permette di calcolare un determinato margine di rischio brevemente e in maniera continuativa, attraverso dei processi dimostrabili.
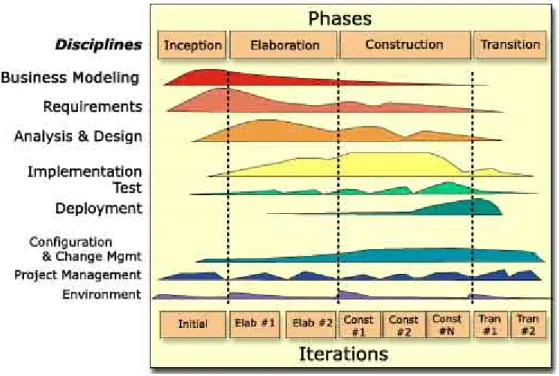
Il diagramma sottostante mostra l’impiego di risorse durante le varie fasi dello sviluppo suddiviso per Discipline.
Figura 4 : RUP Process Diagram
La struttura è suddivisa in due dimensioni:
• L’asse orizzontale rappresenta il tempo e mostra gli aspetti del ciclo di vita del processo di analisi e sviluppo.
• L’asse verticale, rappresenta le varie discipline, le quali raggruppano le varie attività in base alla loro natura e connessione logica.
La prima dimensione tiene conto degli aspetti dinamici del processo, ed è espresso in termini di “fasi”, “iterazioni” e “stadi” (o “milesotnes”). La seconda
dimensione invece rappresenta gli aspetti statici del processo, ovvero come esso è descritto in termini di componenti, discipline, attività, workflows e ruoli.
Il grafico sottostante, mostra invece come l’enfasi da porre sulle varie attività varia nel corso del tempo.
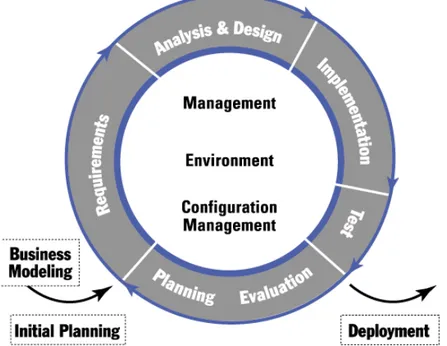
Il RUP prevede una schematizzazione dell’analisi come segue:
1. Business Modeling : “il modello a livello Business serve a capire la struttura e
le dinamiche dell’applicazione; fornire un modello comune di concetto ai progettisti, ai customers ed agli sviluppatori; derivare i necessari requisiti sui sistemi a supporto dell’applicazione”
a. Business Actors : “questi rappresentano dei ruoli relativamente al livello
business dell’Applicazione, interpretati da qualcuno o qualcosa appartenente al dominio in questione”
b. Business Use-Cases : “modellazione delle funzioni e dei processi a
livello Business associate ai Business Actors. Utilizzato come input essenziale all’identificazione dei ruoli e delle consegne all’interno dell’organizzazione”
c. Business Object-Model : “modellazione ad Oggetti che descrive la parte
realizzativa dei Business Use-Cases. Questi è utilizzato come un’astrazione di come i Business Workers e le Business Entities debbano essere correlate e come essi debbono collaborare in modo tale da realizzare i processi relativi al Business”
2. Use-Case Model : “Modello delle funzionalità e dell’ambiente del Sistema. In
genere è utilizzato come punto di accordo fra i customers e gli sviluppatori”
3. Logical View
a. Analysis Model : “comprende l’analisi delle classi ed ogni diagramma
associato. Rappresenta un modello ad Oggetti per la realizzazione degli Use-Cases, nonché un’astrazione del Design Model”
b. Design Model : “rappresenta la modellazione fisica del sistema in
termini di classi e relazioni fra oggetti, la quale realizza tutte le funzionalità descritte dagli Use-Cases del sistema”
Use-Case Model The Use-Case Model is
traceable to (and derives from) the Business Model. The system (as described in the Use Case Model) provides behavior that supports the business.
Business Use-Case Model
The purposes of business modeling are:
- To understand the structure and dynamics of the organization. - To ens ure that customers, end users, and developers have a common unders tanding of the organization.
- To derive requirements on systems to support the organization.
The use-case model is a model of the system's intended functions and its environment, and serves as a contract between the customer and the developers. The us e-case model is used as an essential input to activities in analys is, design, and test.
Modello Architetturale
“The user interface, perhaps the most important digital library component, must incorporate a wide variety of techniques to afford rich interaction between users and the information they seek. For computer workstations, graphical user interfaces such as X-Windows, Microsoft Windows, and Macintosh System 7 interfaces are the status quo.
A user interface for digital libraries must display large volumes of data effectively. Typically the user is presented with one or more overlapping windows that can be resized and rearranged. In digital libraries, a large amount of data spread through a number of resources necessitates intuitive interfaces for users to query and retrieve information. The ability to smoothly change the user’s perspective from high-level summarization information down to a specific paragraph of a document or scene from a film remains a challenge to user interface researchers.”
(from IEEE Digital Library Technical Committee)[Rif-30]
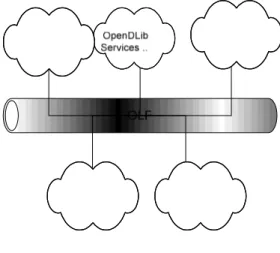
Sulla base di quanto finora dedotto estrapoliamo un modello architetturale descrittivo dell’interfaccia.
Essa si presenta come un servizio Replicato di tipo NoInput del kernel OpenDLIB e come tale interagisce con gli altri servizi per mezzo di OLP.
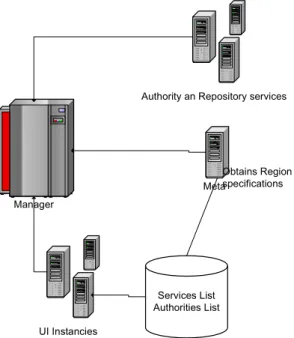
Dalla definizione stessa del servizio, deduciamo che possono essere create più istanze dell’interfaccia completamente indipendenti l’una dall’altra. Ogni Istanza distribuisce informazioni al Manager e ricava dal Meta Service le informazioni sulle Authorities, i Reposiroties, le Collections ed i Search Methods disponibili nella Regione/i di appartenenza, informazioni dalle quali sarà in grado in seguito di reperire la Struttura del Documento e dei Metadati per mezzo del Repository Service.
UI Instancies Manager
Services List Authorities List
Authority an Repository services
Meta
Obtains Region specifications
Figura 7 : Istanze dei servizi
Dal momento in cui l’Istanza dell’UI è stata avviata, sarà possibile per mezzo dei suoi verbi stabilire su quali Collezioni andare a reperire i Documenti, come reperirli per mezzo dei Metodi di Ricerca disponibili ed infine come Rappresentarli nella maniera più opportuna.
Forniamo una schematizzazione delle funzionalità fondamentali del servizio.
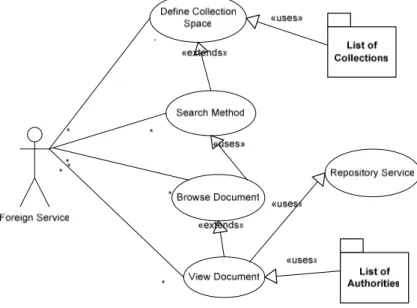
Figura 9 : UI Service Use Case
Come illustrato, quindi, l’UI Service dovrà dapprima consentire di scegliere su quali Collections impostare la Ricerca dei Documenti digitali, presentare all’utente perlomeno due metodi di Ricerca (Semplice ed Avanzata) che gli permettano di trovare il/i Documenti desiderati, illustrare l’elenco dei Documenti reperiti ed infine Rappresentarli in maniera adeguata alla Struttura delle loro Viste e Metadati.
Maggiori dettagli saranno esposti nei capitoli riguardanti la definizione dei requisiti del Sistema.
A questo punto si presenta la principale problematica che ci proponiamo di risolvere in questa sede, ovvero quella di rendere l’interfaccia in grado di assolvere ai fondamentali compiti fin’ora esposti nella maniera più consona alla Comunità che sta utilizzando il servizio.
ed indipendente in modo da poter assolvere ai Vincoli ed Obiettivi preposti, pur mantenendo l’infrastruttura ed il modello architetturale di base.
Riassumendo brevemente, sulla base di quanto detto, il servizio a questo punto dovrà consentire di:
a) Modificare la modalità di rappresentazione delle schermate a seconda dell’Environment a disposizione del Client.
b) Modificare l’aspetto stilistico delle schermate a seconda delle preferenze della Comunità.
c) Consentire al Client di impostare dei parametri di configurazione nell’aspetto dell’interfaccia e di mantenerli per i futuri accessi.
Ognuno degli aspetti presentati, introduce delle fondamentali problematiche, le quali soluzioni non possono ricondursi ad una singola entità, ovvero è necessario identificare gli Attori che avranno il compito direttamente o indirettamente di assolvere a tali servizi.
Nella definizione dei Vincoli abbiamo individuato tre tipi di attori principali: 1. Amministratori o Configuratori
2. Designers 3. Utilizzatori
Ad ognuno di tali Attori rispettivamente è associabile uno degli aspetti di cui al punto precedente.
I Configuratori infatti sono in grado di conoscere il mezzo fisico con cui l’interfaccia verrà rappresentata, i suoi limiti e le sue caratteristiche, ovvero l’Environment operativo del Cliente.
I Designers sono in grado invece di adattare nel miglior modo possibile l’aspetto dell’interfaccia ai requisiti specifici dell’Environment e della Comunità, non solo si richiede a questo livello la conoscenza delle preferenze e delle abitudini degli utenti, come ad esempio l’attitudine a certi colori rispetto che ad altri o ad un determinato
linguaggio rispetto che ad un altro, ma anche l’abilità di saper adattare nel miglior modo possibile le informazioni al mezzo fisico di rappresentazione.
Mentre gli Utilizzatori sono gli unici a poter predisporre il proprio ambiente di lavoro nella maniera a loro più consona, in base agli strumenti messi a disposizione dall’interfaccia, dai Configuratori e dai Designers.
Compito del servizio ovviamente è quello di fornire ad ognuno degli Attori gli strumenti e le metodologie necessarie allo svolgimento dei propri compiti.
L’idea di base è quella di affiancare al servizio principale dell’interfaccia altri tre servizi di supporto. Tali servizi hanno delle specifiche funzionalità nell’ambito dell’interfaccia e sono i seguenti:
servizio Descrizione Funzionalità
Object Service Fornisce informazioni sulla
struttura, sulle proprietà ed i metodi relativi agli Oggetti componenti l’interfaccia.
Ha il compito di fornire i modelli strutturali degli oggetti.
Environment Service
Fornisce informazioni sull’ambiente fisico di rappresentazione dell’interfaccia.
Ha il compito di stabilire quali parti del singolo Oggetto sono o meno rappresentabili, e se vi sono più possibili rappresentazioni
dell’Oggetto quale è accettabile dall’ambiente.
User Service Fornisce informazioni sulle
preferenze di rappresentazione della Comunità e mantiene le specifiche dei profili dei singoli utenti.
Ha il compito di tradurre gli aspetti stilistici del singolo Oggetto in modo conforme alle preferenze della Comunità o dell’utente.
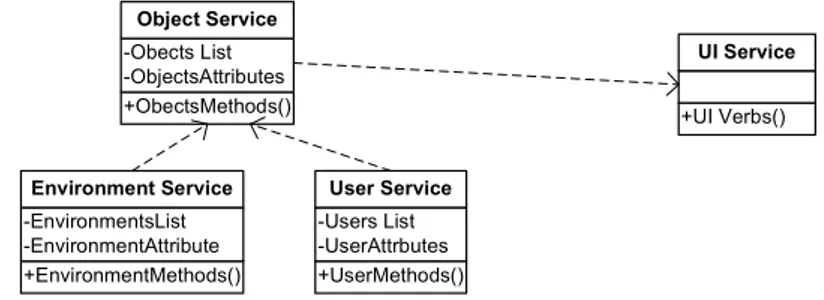
Architetturalmente l’UI Service sarà strutturato come segue: +UI Verbs() UI Service +ObectsMethods() -Obects List -ObjectsAttributes Object Service +EnvironmentMethods() -EnvironmentsList -EnvironmentAttribute Environment Service +UserMethods() -Users List -UserAttrbutes User Service
Figura 10 : UI Service Architecture Overview
Quindi l’OS definisce gli Oggetti disponibili e rappresentabili dall’interfaccia, mentre ES ed US definiscono i parametri fondamentali di configurazione di tali Oggetti.
Tale struttura rende l’interfaccia perfettamente modulare e riadattabile.
Sarà sempre possibile definire dei nuovi Oggetti per poter venire incontro a nuove esigenze, senza dover riprogettare l’Architettura dell’interfaccia e la Struttura dei servizi.
La definizione delle schermate, ovvero la loro infrastruttura, deve però essere indipendente dall’implementazione interna degli Oggetti e dei servizi, anche perché requisito fondamentale dell’interfaccia è che essa debba poter essere disegnata o modificata da degli Attori i quali non hanno alcuna conoscenza dell’ambiente architetturale, i Designers.
Ad essi viene richiesta esclusivamente la conoscenza di:
a) Un apposito formalismo ed una metodologia per la definizione delle schermate
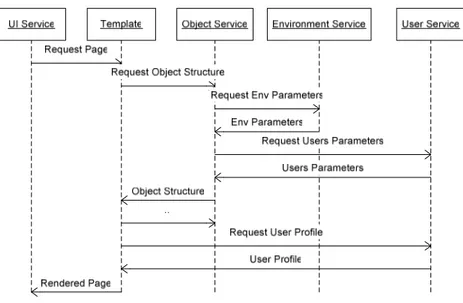
Figura 11 : UI Service Specific Sequence Diagram
Lo schema di sequenza presenta i passaggi che l’UI Service insieme ai sottoservizi percorre per rappresentare una schermata sulla base di un Template.
I Template sono lo strumento principale a disposizione dei Designers per la definizione dello stile grafico dell’interfaccia utente.
Essi sono costituiti da dei files scritti in un formalismo “XML-Like”, come ad esempio XUL (Extensible User-Interface Language), un apposito formalismo costruito sulle specifiche del W3C adottato per la descrizione di interfacce utente, i quali conterranno le informazioni specifiche delle varie schermate (es.: Menus, Buttons, Links, …) ma soprattutto la disposizione e l’organizzazione degli Oggetti da rappresentare messi a disposizione da OS.
Dettaglio dei Requisiti
Administrator – Installing Services
L’installazione di un servizio consta di due fasi principali: 1. Configurazione di Base
2. Deploy del servizio
La Configurazione di Base prevede la creazione della struttura della Directory sull’eventuale Server e l’opportuna disposizione dei files componenti e dei files di configurazione, l’eventuale modifica dei parametri necessari nei files di configurazione, tra cui in particolare il valore di ‘$HOST’ e ‘$PORT’, il valore dei timeout dei Task di aggiornamento ed eventuali altri parametri propri del servizio.
La configurazione comprende inoltre la corretta disposizione dei files di Template e dei files componenti, quali eventuali immagini, video o quant’altro esplicitato nel Template.
Il Deploy del servizio prevede invece la compilazione di eventuali files sorgente, l’installazione e l’avvio dei servizi sul Server.
Administrator – Updating Services/Building-Deploying Objects
L’Update di un servizio si sviluppa in tre fasi distinte e separate: 1. Modifica o Aggiunta di Oggetti
2. Modifica o Aggiunta di Environments 3. Modifica o Aggiunta di Profili
Questi sono i tre elementi fondamentali che costituiscono la base operativa dell’UI Service. Essi sono elencati in ordine di importanza. L’UI Service infatti non sarebbe in grado di accedere ai servizi della biblioteca digitale se non per mezzo degli Attributi e dei Metodi messi a disposizione dagli Oggetti.
Ogni Oggetto ha definiti uno o più Environment Set. Questo elemento in effetti non è fondamentale ai fini del funzionamento dell’interfaccia, ma è necessario invece ai fini della Adattabilità del sistema. Ogni Environment Set descrive infatti le modalità di rappresentazione dell’Oggetto sull’interfaccia fisica per cui esso è definito. Tale servizio consente di riutilizzare la stessa implementazione di un Oggetto su diverse interfacce, anziché costringere l’Amministratore a ridefinire il comportamento dell’UI Service e le modalità di rappresentazione e visualizzazione degli Oggetti a seconda del Sistema di rappresentazione.
Infine i Profili consentono all’UI Service di disegnare, disporre, visualizzare o meno gli Oggetti che compongono una data schermata in base alle preferenze di uno specifico utente, inoltre essi contengono informazioni sui Collection Spaces e sui Resultsets memorizzati dallo stesso. Un utente infatti potrebbe voler definire degli Insiemi di Collezioni su cui operare le sue ricerche nonché salvare i risultati delle ricerche stesse. Anche questo elemento non è necessario ai fini dell’operativitá del servizio, ma offre un valore aggiunto di Configurabilitá all’utente finale di notevole importanza.
Dal punto di vista dell’Amministratore, inteso come colui il quale conosce la struttura e l’architettura del Sistema e che abbia le capacità di sviluppare o
essenzialmente “scrivere” un modulo interpretabile dall’Object Service che contiene gli Attributi ed i Metodi necessari all’interazione con i servizi della biblioteca digitale. Tali Oggetti possono essere anche implementati da terzi, nel qual caso l’Amministratore ha il solo compito di configurare eventuali parametri del modulo e di propagare la conoscenza dei Metodi dell’Oggetto ai servizi preposti, ovvero “Deploying” dell’Oggetto.
In base a quanto detto, un Oggetto è essenzialmente una Classe. Tale Classe prevede almeno due tipi di interfacce, che possiamo identificare come Locale e Remota.
L’interfaccia Locale racchiude tutti i Metodi di interazione a basso livello con i servizi della biblioteca digitale, mentre l’interfaccia Remota racchiude tutti i Metodi di interazione con agenti esterni i quali non devono conoscere nulla del funzionamento interno dell’Oggetto, ma solo le sue funzionalità macroscopiche. In particolare tali agenti sono l’Object Template e l’Environment Set. L’uno definisce l’aspetto stilistico dell’Oggetto e l’altro stabilisce come rappresentarlo nel mezzo fisico. Generalmente tali aspetti sono curati dai Designers.
Quando un Oggetto è stato definito, così come un Environment o un Profilo, è necessario disseminarne i Verbi, o Metodi, agli altri servizi.
Ovviamente i Verbi da disseminare ai servizi Esterni sono esclusivamente quelli appartenenti all’interfaccia Remota dell’elemento.
Questa azione è identificata come “Deploying” dell’elemento, ovvero l’instanziazione dello stesso nel servizio preposto.
In base alla definizione di OLP, i servizi possono comunicare fra loro solo tramite un apposito formalismo XML. Ciò al fine di garantire una perfetta indipendenza nella struttura dei servizi e Moduli della biblioteca digitale. Pertanto i nuovi Oggetti andranno installati e configurati nell’OS così come i nuovi Environments nell’ES ed i Profili nell’US.
Ognuno di tali servizi prevede un Verbo “List” che elenca gli elementi in esso presenti ed un Verbo “Structure” che dissemina tutte le informazioni relative all’Elemento desiderato.
Gli Attributi ed i Metodi del singolo Elemento, poi, sono accessibili per mezzo dell’interfaccia Standard del servizio preposto, ovvero per mezzo di un Verbo “Disseminate” e degli Argomenti del Verbo stesso, così come sono definiti da OLP.
Si fa riferimento al Dettaglio di Progetto per la specifica dei Verbi e delle loro funzionalità.
Designer – Designing Objects/Templates
Il Design di Oggetti e Templates deve prescindere quanto più possibile dalla struttura fisica dei servizi della biblioteca digitale.
Un Template è un insieme di Oggetti, mentre un Oggetto costituisce l’implementazione a livello di interfaccia di una o più Funzionalità di un servizio della biblioteca digitale.
Il Designer non è assolutamente tenuto a conoscere l’implementazione interna dell’Oggetto, ma esclusivamente le sue funzionalità, raccolte in un Descrittore in formalismo XML e richiamabili in qualche modo a livello di RPC (Remote Procedure Calling).
Per fare un esempio, l’interfaccia utente può mettere a disposizione un Oggetto per rappresentare l’Anteprima delle Viste di un Documento ed un altro per l’Anteprima delle Manifestazioni di ogni Vista; ovvero un Oggetto rappresentante una Form o Menù dinamico per la ricerca Semplice parametrica, o ancora Oggetti di supporto, come Helpers e Widgets.
Il Template di un Oggetto in realtà descrive esclusivamente il modo di rappresentare lo specifico Oggetto in un determinato Environment. Il Designer deve scrivere suddetto Template avvalendosi di uno specifico formalismo, che prescinde dalla struttura fisica dell’interfaccia ovviamente.
Un Oggetto può avere più rappresentazioni, in modo da poter consentire all’utente di personalizzarne la visualizzazione, o addirittura di nascondere Oggetti che non ritiene utili alla sua navigazione.
Lo stesso dicesi per le pagine o schermate costituenti l’interfaccia utente. Ogni pagina è descritta da un Template, ed esso può contenere uno o più riferimenti a Template di Oggetti, in modo tale che l’UI Service sia in grado di costruire la pagina in maniera completamente personalizzata e personalizzabile.
Il linguaggio descrittivo di tali Templates deve essere coerentemente in formalismo XML. Una proposta interessante è data dall’ “Extensible User Interface
Language” (XUL) introdotto per la prima volta nel progetto Mozzilla all’incirca nel 1999[Rif-31]. Questi è un linguaggio XML-Based orientato alla descrizione dei contenuti di Windows e Dialogs. XUL ha dei costrutti linguistici per tutti i controlli tipici delle Dialog-Box, nonché per i più diffusi widgets come toolbars, menu ad albero, progress bars e menus. Mentre HTML descrive il contenuto di un singolo documento, XUL descrive il contenuto di una intera “finestra”, la quale può contenere a sua volta uno o più documenti.
"XUL is an XML based grammer for specifying the static GUI. An Application Service is the code that both has access to the GUI elements and the code for doing the specificed work. The definition of an cross-platform (XP) application is a small kernel that is able to load the static definition of the UI, the XUL or mulitple XUL files, and the Application Service(s), the code for processing the XUL. The AppRunner is available today for this purpose."[Rif-32].
Il contesto minimo di un Descrittore XUL appare come segue: <?xml version="1.0"?>
<?xml-stylesheet href="chrome://global/skin/" type="text/css"?> <window id="window-ID" title="Window Title" xmlns="…">
</window>
La disposizione dei widgets in interfaccia XUL è ottenuta principalmente grazie all’uso dei boxes. Si rimanda alle specifiche per un maggior dettaglio dei costrutti relativi a XUL.
Per concludere, il Designer deve prevedere nella stesura dei Templates, più possibili rappresentazioni, se possibili, di un Oggetto e di una Pagina. Le rappresentazioni possono variare in base all’Environment fisico delle interfacce ed alle Preferenze dell’utente. Nel primo caso il Template deve descrivere come e cosa dell’elemento può essere rappresentato in base alle capacità di rappresentazione dell’Environment; ad esempio si può avere un Environment avanzato in cui è possibile rappresentare immagini, filmati e suoni liberamente ovvero un Environment molto limitato in cui possono essere rappresentate solo informazioni testuali. Nel
stabiliscano cosa e come dell’elemento può essere modificato dall’utente; ad esempio i colori, la forma o le informazioni. In una Pagina ad esempio l’utente potrebbe decidere di nascondere alcuni Oggetti, o disporli in maniera diversa da quella di default.
User : Requiring/Customizing Pages
Dal punto di vista del servizio, l’utente in pratica svolge due azioni principali: 1. Navigazione
2. Personalizzazione
Con il termine Navigazione, si intende le azioni che portano l’utente a visualizzare e richiamare le diverse Pagine costituenti l’interfaccia utente.
Tali pagine possono essere richiamate dall’utente in maniera diretta o indiretta. L’UI Service in pratica può essere visto come un substrato che interpreta gli Input forniti dall’utente per mezzo della Navigazione e li traduce in chiamate ai metodi degli altri servizi della biblioteca digitale.
Onde rispettare il più possibile gli Obiettivi proposti, è prevista la possibilità all’utente di spostare, nascondere/visualizzare o alterare lo stato degli Oggetti componenti la singola Pagina.
In realtà la struttura della Pagina a box ed Oggetti è nata per questo preciso scopo.
Cosa l’utente può fare o meno nell’ambito della Pagina e del singolo Oggetto è definito dal rispettivo Template. Un Template, se vogliamo, è costituito da una serie di Sub-Templates, ognuno preposto alla specifica rappresentazione dell’Oggetto o della Pagina. Tali Templates inoltre hanno dei parametri comuni, con dei valori di default, controllabili per mezzo dei Profili utenti.
Si rimanda alla sezione “Dettaglio di Progetto” per la descrizione di alcune possibili strutture di Templates.
Business Modeling
La modellazione a livello “Business”, consta di tre sezioni fondamentali: 1) Business Actors;
2) Business Use-Cases; 3) Business Object Model.
Un Business Actor rappresenta un ruolo interpretato da qualcuno o qualcosa nell’intero ambiente applicativo, ovvero un agente che non interagisce con i processi interni e di dettaglio dell’Applicazione, ma ha esclusivamente una visibilità globale e macroscopica delle principali funzionalità dell’Applicazione. Un Business Actor va individuato sulla base dei principali processi che si intendono analizzare.
I Business Use-Cases rappresentano i principali processi
dell’Applicazione. Il loro scopo fondamentale è quello di far capire in prima battuta nella maniera più esplicita e chiara possibile cosa il Sistema può offrire a livello di funzionalità e definire inoltre il Dominio di applicazione dello stesso. I Business Use-Cases hanno come soggetto sempre ed esclusivamente un Business Actor, ovvero vanno intesi come processi del sistema attuati e mirati da e ad un Business Actor.
Il Business Object-Model intende esplicitare i sottoprocessi componenti ogni singolo Business Use-Case, dando un’idea sempre a livello astratto e macroscopica della realizzazione dello stesso, in termini di interazioni fra Business Workers, oggetti che eseguono azioni sul Sistema fra cui i Business Actors, e Business Entities, oggetti in grado di assolvere a specifiche funzionalità del sistema tra cui la gestione dei Dati.
Business Actors
Business Use-Cases
Business Modeling
A business actor represents a role played in relation to the business by someone or something in the business environment.
The business use-case model is a model of the business intended functions. The business use-case model is used as an essential input to identify roles and deliverables in the organization.
Business Object Model
The business object model is an object model describing the realization of business use cases. It serves as an abstraction of how business workers and business entities need to be related and how they need to collaborate in order to perform the business.
Figura 12 : Business Modeling
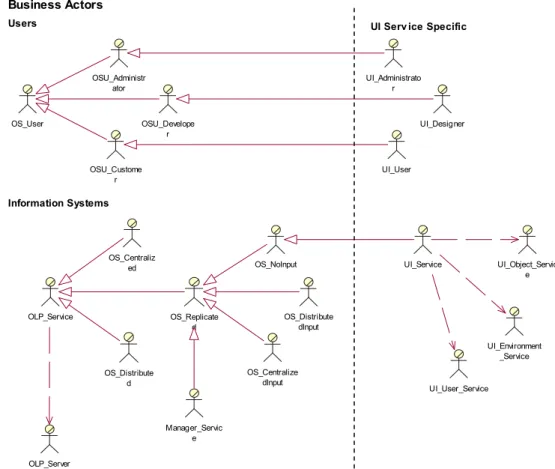
Business Actors OLP_Service OLP_Server OS_Centraliz ed OS_Distribute d OS_Replicate d OS_NoInput OS_Centralize dInput OS_Distribute dInput Business Actors Users Information Systems OS_User OSU_Administr ator OSU_Develope r OSU_Custome r
UI Serv ice Specific
UI_Administrato r UI_Designer UI_User UI_Service Manager_Servic e UI_Object_Servic e UI_Environment _Service UI_User_Service
In generale un servizio ha degli utenti, tra cui possiamo individuare un Administrator ed un Designer, i quali hanno il compito di ideare, implementare, configurare, installare e mantenere il singolo servizio offerto da OpenDLib, e il Customer, ovvero l’entità che utilizza il servizio ed in genere è a sua volta un servizio, ma può essere in alcuni casi anche una persona fisica.
Dal punto di vista dell’UI Service, i Customer sono rappresentati dagli utenti della biblioteca digitale, gli Administrator dai Configuratori e Deployers ed i Designers da coloro che scrivono i Templates per gli Oggetti e le Pagine dell’interfaccia.
Inoltre un generico servizio di OpenDLib afferisce ad un Server e come sancito dal protocollo può essere di tre tipi, Centralizzato, Distribuito o Replicato. Si rimanda alle specifiche del protocollo per i dettagli sulle tipologie di servizio.
Il Manager Service è un caso particolare di servizio Replicato, così come l’UI Service è un caso particolare di servizio NoInput derivante da un servizio Replicato.
L’UI Service è costituito da tre sottoservizi, l’Object Service, l’Environment Service e lo User (Profile) Service.
Business Use-Cases
Business Use Cases (Processes)
Principal System Interactions
Users Principal Use Cases
Management and Supporting Use Cases
Management
Management and supporting business use cases do not necessarily need to connect to a business actor, although they normally have some kind of external contact. A management business use case, for instance, might have the owners of the business, or the board, as its business actor.
OpenDLib Kernel Functions
OpenDLIb Protocol
Administrators Designers Users UI Service
Figura 14 : Business Processes
OLP_Server
(f rom Business Actors)
Provides OLP_Service
(f rom Business Actors)
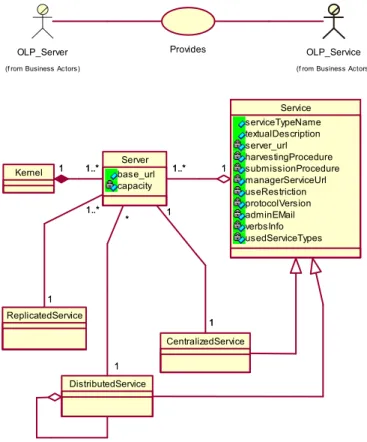
OpenDLib Kernel Service serviceTypeName textualDescription server_url harvestingProcedure submissionProcedure managerServiceUrl useRestriction protocolVersion adminEMail verbsInfo usedServiceTypes CentralizedService DistributedService ReplicatedService Server base_url capacity 1 1..* 1 1 1 1 * 1 * 1 1..* 1 1..* 1 Kernel 11 1..*1..* 1..* 1
Le funzionalità di OpenDLib sono implementate dai diversi servizi della biblioteca digitale. Ogni istanza di servizio, o sue repliche, debbono necessariamente risiedere su un Server. Il servizio è accessibile specificando l’URL del Server ed il nome del servizio. Il protocollo OLP stabilisce delle regole formali per l’accesso ai Metodi del servizio e per il passaggio dei Parametri.
Il sistema può essere composto da uno o più Server, ed ogni Server può ospitare uno o più servizi.
Mentre nel Kernel può esistere una ed una sola istanza di servizio Centralizzato, possono invece sussistere più istanze di servizio Replicato, una su ogni Server, o più istanze di servizio Distribuito, dislocanti le varie funzionalità del servizio su uno o più Server.
Manager_Service
(from Business Actors)
Services State OLP_Config
Send Config Request <<extend>>
Initialize
Acquire Service Federation State Configure Service Federations
<<extend>>
OLP_Service
(from Business Actors)
OLP_Config <<communicate>>
<<communicate>>
Service State Request
OLP_Explain <<communicate>>
Kernel
(from OpenDLib Kernel Functions)
Service Function Request
OLP_Service_Specific <<communicate>> OpenDLib Protocol Manager Service Federation Service Instance Periodically
Request Fed State
Request Srv State Service State Fed State Configuration Options Service Initialization Config Parameters Periodically Request Fed State
Services Configurations State Operation OLP_Explain OLP_Service_Specific OLP_Config
Il Manager Service mantiene sempre lo stato aggiornato dei servizi del Kernel. In ogni istante questi è in grado di fornire informazioni sullo stato di configurazione dei servizi, o di spedire messaggi ai servizi della federazione onde aggiornare lo stato del Kernel e riconfigurare taluni parametri, quali il path più breve per raggiungere un determinato servizio o il carico di lavoro dei Server.
Tali informazioni sono utilizzate periodicamente dai servizi istanziati per assestare il loro status ed ogni volta che un nuovo servizio viene aggiunto alla federazione.
Inoltre ogni servizio o agente abilitato può ottenere informazioni sullo stato del singolo servizio nonché richiamarne i metodi per mezzo di OLP, che fornisce tutta l’infrastruttura di comunicazione del Kernel.
OLP si basa sul protocollo HTTP per formalizzare le richieste. La struttura dei messaggi è specificata per mezzo del formalismo XML. Ad ogni richiesta spedita in HTTP ad un servizio, viene generata una risposta XML.
Il protocollo è una evoluzione del protocollo Dienst. Questi ne eredita le regole di base e le convenzioni, nonché molte delle richieste di protocollo.
1. VERBI e VERSIONI
Le richieste di protocollo in OLP sono chiamate “verbi”. Ogni servizio supporta un insieme di Verbi.
Un servizio può supportare più di una versione di un verbo, ed ogni versione può differire dall’altra sia sintatticamente che semanticamente. La versione è costituita da due interi separati da un punto. Questa versione è applicata al verbo individualmente non all’intero protocollo.
L’inclusione del numero di versione nel messaggio permette la compatibilità fra le varie estensioni del protocollo.
Un Server che offre uno o più OLP Services può supportarne anche i verbi nelle varie versioni. Un servizio che riceve un messaggio contenente un numero di versione precedente alla corrente, deve rispondere o con la sintassi e semantica corretta o con un messaggio d’errore. Se un servizio riceve un messaggio contenente un numero di versione più recente, invece, deve rispondere con un messaggio d’errore. Il software a supporto del protocollo OLP può o non può a sua volta avere un numero di versione, il quale tuttavia è indipendente dai numeri di versione supportati dai Verbi di OLP e dai numeri di Versione supportati invece dai verbi del software in questione.
Le richieste del protocollo OLP sono rappresentate da URLs all’interno di richieste HTTP. In generale queste sono tutte richieste HTTP. Una implementazione tipica utilizza un Web Server, come ad esempio Apache, il quale è configurato in modo da redirigere gli OLP URLs agli appropriati OLP Services.
2. FORMATO DEI MESSAGGI
In questa sezione vediamo le specifiche delle richieste OLP inserite in richieste HTTP.
Tutti i Messaggi sono codificati in URLs dove la parte del percorso dell’URL consiste delle seguenti parti nel rispettivo ordine:
• OLP: Questa parte appare scritta letteralmente nell’URL.
• Service name: Il nome del servizio in grado di gestire la richiesta,
ad esempio “Repository”.
• Version: La versione del verbo che sarà invocato.
• Verb: Questo rappresenta il nome del Messaggio, ad esempio
“Structure”. Un verbo è univoco all’interno di un servizio.
• Fixed Arguments: Ogni Verbo può avere un certo numero di
argomenti fissi, i quali ovviamente devono sempre essere specificati, ed apparire nell’ordine citato.
• Fixed_post Arguments: Ogni Verbo può avere un certo numero di argomenti fissi, i quali debbono sempre essere passati come HTTP POST. La sintassi di un fixed_post assume la forma “key=value”.
• Optional Arguments: La sintassi di questi argomenti assume la
forma “key=value”. Se presente più di un argomento opzionale, essi debbono essere separati da una e commerciale “&”. Gli argomenti possono apparire in un qualsiasi ordine. Se non diversamente specificato, gli argomenti opzionali sono sempre facoltativi e non devono essere ripetuti.
• Optional_post Arguments: La sintassi di tali argomenti assume la
forma “key=value”. Essi possono apparire in un ordine qualunque e debbono sempre essere passati come HTTP POST. Se non diversamente specificato, tali argomenti sono sempre facoltativi e non devono essere ripetuti.
Il separatore fra le varie sezioni del Messaggio è sempre lo “slash” (/) del path, tranne che per gli argomenti opzionali, per i quali è un punto interrogativo.
Esempio:
Se il Repository Service implementa il Verbo “Structure”, e la versione “1” di detto verbo accetta argomenti fissi e due argomenti opzionali (version e view), allora la richiesta sarà composta come segue:
/OLP/Repository/1.0/Structure/handlecorp/docid?version=2&view=book
L’URL completo per tale richiesta ad una particolare Web Server potrebbe essere come segue:
3. CARATTERI SPECIALI
Le regole sintattiche per gli URI, impongono alcuni vincoli per particolari caratteri, i quali vanno rappresentati per mezzo di sequenze di escape: un simbolo di percento “%” seguito dal codice esadecimale del carattere.
Tali caratteri sono:
• "/" - Path Component Separator: %2F • "?" - Query Component Separator: %3F • "#" - Fragment Identifier: %23
• "=" - Name/Value Separator: %3D
• "&" - Argument Separator in Query Component: %26 • ":" - Host Port Separator: %3A
• ";" - Authority/Set Namespace Separator: %3B • " " - Authority/Set List Separator: %20
quest’ultimo carattere può apparire a volte anche come un “+”. 4. MESSAGGI DI RISPOSTA
I messaggi di risposta sono formattati come risposte HTTP, con appropriati campi header. Il tipo specifico per ogni Messaggio sarà quindi specificato dal tipo MIME del campo header HTTP Content-Type (se la risposta HTTP contiene un Messaggio, il Content-Type corrisponderà al tipo del Messaggio contenuto). Allo stesso modo una qualunque codifica applicata al contenuto, sarà specificata nel campo header HTTP Content-Encoding.
Le risposte alle richieste OLP variano tra i seguenti tipi MIME:
• “text/plain”: utilizzato per risposte contenenti informazioni non
strutturate.
• “text/xml”: utilizzato per risposte contenenti informazioni
strutturate (come ad esempio il verbo per la richiesta della struttura interna di un oggetto digitale). Tutte le risposte XML dell’OLP Protocol presentano le seguenti caratteristiche. Il primo TAG è una dichiarazione XML in cui la versione è sempre la 1.0 e la codifica UTF-8. Il restante contenuto è incluso all’interno di un