C A P I T O L O
3
Soluzione proposta
La struttura dati più importante, anche in termini di spazio, per l’algoritmo di verifica della Sun è il dizionario, cioè l’insieme di tutti gli in-frames (dei targets delle istruzioni di salto) salvati per effettuare correttamente la data-flow analysis: è proprio questa struttura dati, a causa della sua estensione per i metodi più “complessi”, a rendere difficoltosa l’implementazione di un verificatore on-card per sistemi embedded.
La soluzione qui esposta è basata sull’idea di una gestione dinamica del dizionario, le entries del dizionario vengono cioè allocate/deallocate non tutte all’inizio ma durante il processo di verifica, e su una politica di scelta della sequenza delle istruzioni da verificare in modo da rendere “ottimo” tale processo [dynamicJBV] [ipdJTRES]. La soluzione si basa su una tecnica di ottimizzazione utilizzata, in un ambito differente, nei compilatori ed è fondata sul concetto di
immediate post dominators (ipds) del control-flow graph (cfg, grafo di flusso delle
istruzioni) che caratterizza ogni metodo.
3.1 Il Control Flow Graph
Ogni metodo, ed ogni programma in generale, è caratterizzato da un control-flow
graph (cfg) cioè da un insieme di nodi ed archi (il grafo appunto) orientato: ogni
nodo è una istruzione, ogni arco è una transizione tra i nodi connessi. Nel nostro caso la transizione è la relazione di sequenzialità nell’esecuzione delle istruzioni: in definitiva se seguiamo un percorso sul grafo, la sequenza di nodi che attraversiamo risulta essere una possibile sequenza di esecuzione del programma [fig. 3.1].
CAPITOLO 3:SOLUZIONE PROPOSTA 5 6 15 9 12 16 19 grafo di flusso associato al bytecode .... 5: baload[51](1) 6: ifne[154](3) -> 15: aload_1 9: sipush[17](3) -28412 12: invokestatic[184](3) 39 15: aload_1[43](1) 16: invokevirtual[182](3) 34 19: astore_2[77](1) .... bytecode possibili sequenze di esecuzione .... 5: baload[51](1) 6: ifne[154](3) -> 15: aload_1 15: aload_1[43](1) 16: invokevirtual[182](3) 34 19: astore_2[77](1) .... .... 5: baload[51](1) 6: ifne[154](3) -> 15: aload_1 9: sipush[17](3) -28412 12: invokestatic[184](3) 39 15: aload_1[43](1) 16: invokevirtual[182](3) 34 19: astore_2[77](1) .... se q u en za 1 se qu en za 2
fig. 3.1: Grafo e possibili sequenze di esecuzione del bytecode1
La maggior parte delle istruzioni (nodi) hanno un solo arco entrante ed un solo arco uscente, ma in generale questo non è vero: le istruzioni di salto condizionato, ad esempio, possono avere 2 o più archi entranti/uscenti, le istruzioni
return hanno invece sempre 0 archi uscenti ma possono avere un numero variabile
di archi entranti (perché magari sono il target di più istruzioni di salto). Per ora prenderemo in considerazione solo grafi ben strutturati: non prenderemo in considerazione ad esempio grafi con istruzioni di salto che hanno come target se stesse o che non hanno targets. Per comodità nell’esposizione, inoltre, tutti i grafi li supporremo “delimitati” da due nodi virtuali: START e END, che caratterizzano rispettivamente l’inizio e la fine del metodo [fig.3.2].
START 0 2 END
5 6
9
12 14
fig. 3.2: Esempio di grafo con nodi virtuali START e END
1 Il bytecode disassemblato è presentato nella forma verbosa <label: opcode[cod](bytes) operands>:
label è un intero che rappresenta (in modo univoco) la posizione di una determinata istruzione nel
bytecode, opcode è l’istruzione in forma mnemonica, [cod] è la codifica dell’istruzione nel bytecode,
(bytes) sono il numero di bytes utilizzati per codificare l’istruzione, operands sono gli eventuali operandi
CAPITOLO 3:SOLUZIONE PROPOSTA
Nel seguito riportiamo esempi di control-flow graphs di programmi. Per ogni istruzione, il numero di archi uscenti dipende solo dalla particolare istruzione in questione: in particolare i salti condizionati (if, switch) hanno sempre 2 o più archi uscenti, solo l’istruzione virtuale END non ha archi uscenti e tutte le altre hanno un solo arco uscente. Gli archi uscenti da una istruzione di salto condizionato li chiameremo rami del salto condizionato.
Il numero di archi entranti invece è legato a tutta la struttura del grafo e quindi del programma: ogni istruzione ha solitamente un solo arco entrante (fatta eccezione per il nodo virtuale START che non ha archi entranti), ma in generale questo non è vero: infatti tutte le istruzioni che sono target di qualche salto condizionato possono avere più archi entranti. La figura 3.3 riporta un control-flow
graph con 4 archi entranti.
START 0 2 END 5 6 9 19 12 14 16 ( if ) ( switch ) ( target )
fig. 3.3: Esempio di grafo che ha un target con 4 archi entranti.
I grafi che noi prenderemo in considerazione, oltre ad essere ben strutturati, supporremo anche che soddisfino la condizione che partendo da qualsiasi istruzione sia sempre possibile trovare un percorso che porti al nodo END. Il grafo in figura 3.4.1 non soddisfa la condizione precedente perché i nodi 14 e 12 non raggiungono il nodo END, invece il grafo in figura 3.4.2 soddisfa la condizione.
START 0 2 END
5 6
9 19
12 14
fig. 3.4.1 Esempio di grafo con nodi (12 e 14) che non raggiungono il nodo END
START 0 2 END
5 6
9 19
12 14
fig 3.4.2: Esempio di grafo in cui tutti i nodi raggiungono il nodo END
CAPITOLO 3:SOLUZIONE PROPOSTA
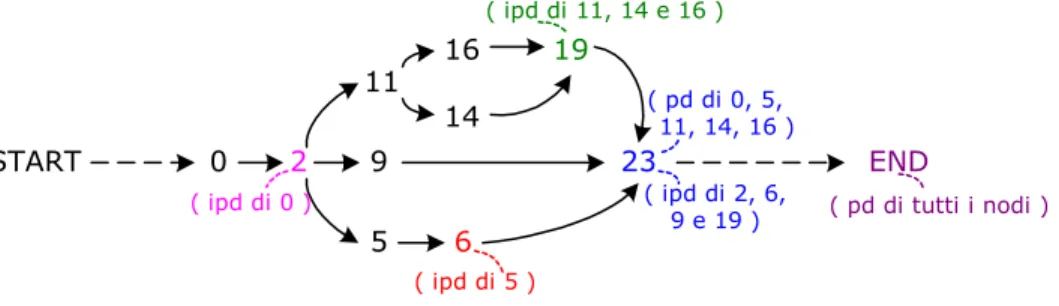
3.2 Immediate Post Dominators (IPDs)
Un post-dominator è una istruzione che si trova su tutti i possibili percorsi che partono dal nodo START ed arrivano al nodo END: prese quindi due istruzioni
instr1, instr2 di un grafo diremo che instr2 post-domina instr1 se tutti i percorsi che
partono dal nodo START, passanti per instr1 per arrivare al nodo END, passano anche per instr2. In particolare diremo che instr2 è l’immediate-post-dominator di
instr1 se instr2 è il primo post-dominator incontrato sul cammino da instr1 al nodo END. La figura 3.5 riporta un esempio di grafo in cui sono stati messi in evidenza immediate post-dominators e post-dominators.
START 0 2 END 5 6 9 19 11 14 ( ipd di 11, 14 e 16 ) 23 ( ipd di 2, 6, 9 e 19 ) ( pd di 0, 5, 11, 14, 16 ) ( ipd di 5 ) ( pd di tutti i nodi ) 16 ( ipd di 0 )
fig. 3.5: Esempio di post-dominators (pds) e immediate-post-dominators (ipds)
3.3 Verifica
basata
sull’ipd
L’algoritmo di verifica basato sull’ipd modifica la gestione del dizionario durante la
data-flow analysis (passo 3) dell’algoritmo della Sun ed i principi su cui si basa
sono:
1- ogni control-flow graph viene virtualmente diviso in blocchi ed ogni blocco “non banale” parte con una istruzione di salto e termina con il suo ipd: in questo modo è possibile associare una sorta di “tempo di vita” alle entries del dizionario per capire quando crearle e quando rimuoverle;
2- vengono lasciate in memoria solo le entries necessarie per la verifica di un blocco;
CAPITOLO 3:SOLUZIONE PROPOSTA
3- il dizionario viene gestito in modo da non contenere frames duplicati: questa caratteristica in realtà non è strettamente necessaria, è solo una ottimizzazione: chiariremo nel paragrafo 6 di questo stesso capitolo come e perché può essere molto vantaggiosa.
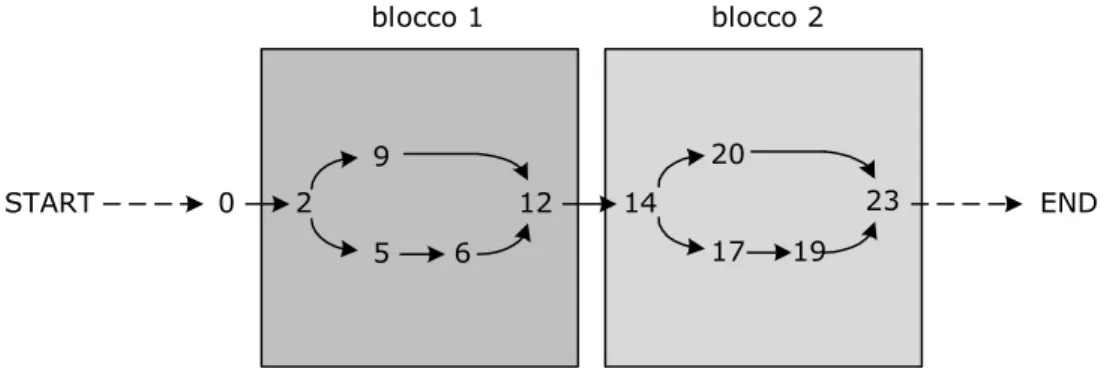
Per sfruttare al meglio il partizionamento in blocchi del control-flow graph le istruzioni vanno verificate seguendo l’ordine sequenziale dato dal programma ed ogni volta che si lascia un blocco tutte le istruzioni del blocco devono essere state verificate. I blocchi non banali partono sempre con una istruzione di salto condizionato e terminano con il relativo ipd, quindi verificare completamente un blocco vuol dire verificare tutte le istruzioni di tutti i rami del salto condizionato. La figura 3.6 riporta un esempio di grafo ripartito in blocchi.
START 0 2 END 5 6 9 12 14 17 19 20 23 blocco 1 blocco 2
fig. 3.6: Blocchi di un grafo di flusso
A differenza dell’algoritmo della Sun che alloca staticamente nel dizionario una entry per ogni target all’inizio della verifica, la strategia proposta alloca memoria solo quando viene “aperto” un salto condizionato e dealloca quando viene “chiuso”. Un salto condizionato si dice “aperto” quando i suoi rami non sono stati ancora tutti verificati in modo completo, si dice “chiuso” in caso contrario [fig 3.7]. In particolare, quando un salto condizionato viene aperto le informazioni da salvare del dizionario sono i frames di tutti i suoi targets e del suo ipd. Inoltre bisogna memorizzare, in un’altra struttura dati, la coppia [salto_aperto_i,m_rami] che specifica, per il salto condizionato aperto, il numero di rami ancora da verificare.
CAPITOLO 3:SOLUZIONE PROPOSTA
Come sarà chiaro tra poco, queste informazioni sono necessarie per applicare correttamente le “regole dell’ipd”. Oltre al dizionario quindi esiste anche un’altra struttura dati, chiamata contesto, che contiene queste informazioni. Lo spazio occupato dal contesto è minimo ed è quindi irrilevante ai fini dello studio della fattibilità della verifica on-card.
START 0 2 END 5 6 9 12 14 ( salto condizionato aperto ) START 0 2 END 5 6 9 12 14 ( salto condizionato chiuso ) istruzioni verificate istruzioni da verificare i i
fig. 3.7: Esempio di salto condizionato aperto / chiuso
Quando un salto condizionato (il j-esimo ad esempio) viene chiuso vengono deallocate tutte le entries del dizionario che non occorrono più, cioè tutte le entries create quando il salto condizionato è stato aperto, e tolta dal contesto la coppia
[salto_aperto_j,m_rami].
E’ possibile osservare inoltre che il contesto è una struttura dati organizzata a stack perché, nei grafi ben strutturati, l’ordine con cui vengono chiusi i salti condizionati è inverso rispetto all’ordine con cui vengono aperti.
CAPITOLO 3:SOLUZIONE PROPOSTA
3.4 Regole del verificatore basato sull’ipd
Esaminiamo ora in dettaglio le regole del verificatore basato sull’ipd; due gruppi di regole fanno la differenza rispetto al verificatore standard della Sun: le “regole dei
salti condizionati” e le “regole dell’ipd” [dynamicJBV].
Le regole dei salti condizionati vengono utilizzate quando viene aperto un salto condizionato: vengono create entries nel dizionario e nel contesto, e vengono effettuati controlli che garantiscono il buon funzionamento dell’algoritmo.
Regola b1: branch∉ (branch non appartiene).
Quando viene incontrata una nuova istruzione di salto condizionato nel dizionario viene creata, se non era già presente, una entry per ogni target ed una entry per l’ipd; se le entries erano già presenti viene fatto il merge2.
Inoltre, supponendo che l’istruzione abbia m targets, nel contesto viene salvata la coppia [salto_condizionato_j,m_rami].
Regola b2: branch= (branch uguale).
Se un salto condizionato già aperto viene incontrato nuovamente ed il merge per i suoi targets non provoca cambiamenti nel dizionario (queste entries erano sicuramente già presenti nel dizionario perchè il salto condizionato era aperto) allora non accorre verificare di nuovo i suoi rami: possiamo assumere di averli già verificati ed andare direttamente all’ipd del salto condizionato aperto. Questa regola garantisce la terminazione dell’algoritmo di verifica.
Regola b3: branch≠ (branch diverso).
Questa regola gestisce il caso opposto al precedente: se un salto condizionato già aperto viene incontrato nuovamente ed il merge per i suoi
targets fa cambiare almeno un frame del dizionario, allora il salto
condizionato va verificato nuovamente, come se venisse incontrato per la prima volta. Si devono quindi rimuovere tutte le coppie
[salto_condizionato_j,m_rami] dal contesto fino a quella (inclusa) del salto
2Il merge è l’operatore che permette di individuare il least upper bound di due tipi, cioè il primo
CAPITOLO 3:SOLUZIONE PROPOSTA
condizionato che si deve ripetere e poi quindi si applica di nuovo la regola
branch∉.
La figura 3.8 mostra delle strutture tipiche di grafi in cui si applicano le regole dei salti condizionati. START 0 END 9 11 5 6 14 branch= 12 START 0 2 9 11 5 6 14 12 END branch≠ START 0 END 5 6 9 12 14 branch∉ A B 9 2 A A 9 2 A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n n istruzioni verificate istruzioni da verificare istruzione corrente i i i 2 2
fig. 3.8: Regole dei salti condizionati
Le regole dell’ipd garantiscono invece che tutti i rami di un salto condizionato vengano verificati prima di procedere oltre: solo quando un salto condizionato viene chiuso è possibile deallocare entries dal dizionario.
CAPITOLO 3:SOLUZIONE PROPOSTA
Regola i1: ipd≠0 (ipd diverso da 0)
Se l’istruzione raggiunta è un ipd ed i rami del relativo salto condizionato non sono stati ancora tutti verificati (supponiamo che rimangano k rami da verificare), allora l’esecuzione simbolica dell’ipd viene rimandata: viene quindi aggiornato l’in-frame del dizionario relativo all’ipd facendo il merge con il frame attuale, viene caricato nel frame corrente l’entry del dizionario relativa alla prima istruzione del prossimo ramo da verificare, in modo da poter ricominciare correttamente l’esecuzione simbolica, e viene decrementato il contatore (k) della coppia [salto_condizionato_j, k] che si trova in testa al contesto.
Regola i2: ipd=0 (ipd uguale a 0)
Se il salto condizionato è pronto per esser chiuso, cioè l’istruzione raggiunta è un ipd e tutti i rami del relativo salto condizionato sono state verificate, allora è possibile rimuovere dal dizionario le entries che non sono più necessarie (cioè tutte le entries create quando il salto condizionato era stato aperto) e la coppia [salto_condizionato_j, 0] che si trova in testa al contesto (per indicare che il salto condizionato è chiuso).
In figura 3.9 è mostrato un esempio di applicazione delle regole dell’ipd.
START 0 2 END 5 6 9 12 14 ipd=0 START 0 2 END 5 6 9 12 14 ipd≠0 istruzioni verificate istruzioni da verificare istruzione corrente i i i
CAPITOLO 3:SOLUZIONE PROPOSTA
Le regole su enunciate possono essere formalizzate e scritte in forma compatta utilizzando la seguente notazione3:
- branch(m) è una istruzione di salto condizionato con m targets: per semplicità faremo riferimento ad istruzioni che prelevano un intero dallo stack e lo confrontano con un altro intero salvato nel registro specificato come operando (ad esempio esistono anche istruzioni if che confrontano due interi dello stack, ed altre che hanno invece come operando un riferimento ad un oggetto perché controllano se vale null: per maggiori dettagli far riferimento dalle specifiche Java 2 [vmspecv2])
- L = {L1,...,Lm}è l’insieme dei targets di un salto condizionato;
- ipd(j) è l’ipd del salto condizionato j;
- c=[j,m]·c’ è la struttura del contesto e sta ad indicare che in testa al contesto c c’è la coppia [j,m], ovvero ‘·’ è l’operatore di concatenazione (il contesto è una struttura dati organizzata a stack);
- <h, c, S, D> è la struttura che caratterizza uno stato dell’interprete astratto:
h è l’istruzione da eseguire simbolicamente, c è il contesto, S è il suo stato
(ovvero il suo in-frame) e D è il dizionario. Ogni regola è caratterizzata da una transizione di stato dell’interprete astratto;
- {M,St} è la struttura di un frame: variabili locali (M) e stack (St);
- top(c) restituisce l’istruzione j della coppia {j,m} che si trova in testa al contesto (il contesto è una struttura organizzata a stack);
- extract(c,j) restituisce un contesto c’ da cui sono state estratte tutte le coppie {l,k} fino alla coppia {j,m} inclusa: extract(c1▪{j,m}▪c2) restituisce
c2;
- j+1 è il successore naturale di una istruzione di salto condizionato j; -
k
L
D restituisce il frame, salvato nel dizionario, relativo al k-esimo target (Lk);
CAPITOLO 3:SOLUZIONE PROPOSTA
- le 4 operazioni consentite sul dizionario sono:
o D↑ [Dj L:=S] (creazione o eventuale aggiornamento delle entries
relative ai targets dell’insieme L={L1,..,Lm} e all’ipd del salto
condizionato j4);
o D ↓c (rimozione delle entries relative alle istruzioni di salto
condizionato che non sono presenti in nessuna coppia del contesto5);
o D[Dk:=S] (aggiornamento della k-esima entry del dizionario).
o lub(S,Dh) (least upper bound, ovvero merge tra il frame corrente S e
l’entry del dizionario Dhrelativa all’istruzione h-esima)
- le pre-condizioni sono specificate in uno statement if e la regola può essere applicata solo se le sue pre-condizioni sono tutte soddisfatte.
∉
branch <j,c,S,D>→ < j+1, [j,m]▪c, {M,St}, D↑ [Dj L:=lub(DL ,{M,St})] >
if ( (j∉c) AND (S={M,int▪St}) )
branch non appartiene: Se j, istruzione di salto condizionato, non appartiene al
contesto (j∉c) e il frame corrente è caratterizzato da uno stack con in cima un
intero (S={M,int▪St}) allora lo stato corrente dell’interprete astratto effettua questa transizione: la prossima istruzione da esaminare è il successore naturale (j+1), in cima al contesto viene inserita la coppia relativa al salto condizionato necessaria per contare quanti rami restano da verificare ([j,m]▪c), l’istruzione viene eseguita simbolicamente cioè si preleva l’intero in cima allo stack e quindi il nuovo frame è {M,St}, si aggiungono al dizionario le entries necessarie per la verifica del blocco cioè vengono create, aggiornate se già esistenti, le entries relative ai targets e all’ipd.
4 Se l’ipd del salto condizionato j non è tra i targets e non è già presente nel dizionario, allora viene
inserita una entry vuota (null-entry) per l’ipd, perché ancora non è possibile conoscere il suo in-frame.
CAPITOLO 3:SOLUZIONE PROPOSTA
branch= <j,c,S,D>→ < ipd(top(c)), c, Dipd(top(c)), D >
if ( (j∈c) AND (S={M,int▪St}) AND (DL=lub(DL ,{M,St})) )
branch uguale: Se j, istruzione di salto condizionato, appartiene al contesto (j∈c) e
il frame corrente è caratterizzato da uno stack con in cima un intero (S={M,int▪St}) e un eventuale merge tra l’out-frame corrente e le entries dei targets contenute nel
dizionario NON provoca un cambiamento nel dizionario (DL=lub(DL ,{M,St})) allora
lo stato corrente dell’interprete astratto effettua questa transizione: la prossima istruzione da esaminare è l’ipd del salto condizionato in cima al contesto (ipd(top(c))), il contesto resta invariato, il nuovo frame è quello salvato nel dizionario e relativo alla prossima istruzione da eseguire, cioè relativo all’ipd (Dipd(top(c))), il dizionario resta invariato.
branch≠ <j,c,S,D>→ < j, c’= extract(c,j), S, D↓c' >
if ( (j∈c) AND (S={M,int▪St}) AND (DL≠lub(DL ,{M,St})) )
branch diverso: Se j, istruzione di salto condizionato, appartiene al contesto (j∈c) e il frame corrente è caratterizzato da uno stack con in cima un intero (S={M,int▪St}) e un eventuale merge tra l’out-frame corrente e le entries dei targets contenute nel
dizionario provoca un cambiamento nel dizionario (DL≠lub(DL ,{M,St})) allora lo
stato corrente dell’interprete astratto effettua questa transizione: la prossima istruzione da esaminare resta l’istruzione di salto corrente (j), vengono estratte dal contesto tutte le coppie fino a quella (compresa) del salto condizionato corrente
(c’= extract(c,j)), il frame resta invariato (S), vengono lasciate nel dizionario SOLO
le entries necessarie alla verifica dei salti condizionati rimasti nel nuovo contesto c’ (D↓c').
CAPITOLO 3:SOLUZIONE PROPOSTA
ipd≠0 <i,c,S,D>→ < Lk, [j,k-1]▪c’ , ′D , D’=D[DLk i:=lub(S,Di)] >
if ( (c=[j,k]▪c’) AND (k≠0) AND (i=ipd(j)) )
ipd diverso da zero: Se j, istruzione di salto condizionato, si trova in testa al contesto (c=[j,k]▪c’) con un contatore di rami da verificare diverso da zero (k≠0) e l’istruzione corrente (i) è ipd di quel salto condizionato (i=ipd(j)), allora lo stato corrente dell’interprete astratto effettua questa transizione: l’ipd non viene eseguito e la prossima istruzione da esaminare è il prossimo target del salto condizionato j
(Lk ), viene decrementato il contatore del salto condizionato j cioè quello in cima al
contesto ([j,k-1]▪c’), il nuovo frame è quello salvato nel dizionario e relativo alla prossima istruzione da eseguire, cioè relativo al k-esimo target ( ′
k
L
D ), avendo cura,
prima di caricare il frame dal dizionario, di aggiornare l’entry relativa all’istruzione
attuale6, che è un ipd, nel dizionario (D’=D[D
i:=lub(S,Di)]).
ipd=0
<i,c,S,D> → < i, c’, lub(S,Di), D↓c' > if ( (c=[j,0]▪c’) AND (i=ipd(j)) )
ipd uguale a zero: Se j, istruzione di salto condizionato, si trova in testa al contesto (c=[j,k]▪c’) con un contatore di rami da verificare uguale a zero (k=0) e l’istruzione corrente (i) è ipd di quel salto condizionato (i=ipd(j)), allora lo stato corrente dell’interprete astratto effettua questa transizione: l’ipd è pronto per essere eseguito, quindi la prossima istruzione da esaminare è proprio l’istruzione corrente (i), viene estratta dal contesto la coppia relativa al salto condizionato j, quindi il contesto diventa c’, il nuovo frame è quello ottenuto dal merge tra l’in-frame
corrente e quello salvato nel dizionario lub(S,Di), vengono estratte dal dizionario
tutte le entries che non sono target o ipd dei salti condizionati che restano nel contesto c’ (D↓c').
6 E’ necessario aggiornare il dizionario prima di caricare il frame del target perché l’ipd potrebbe essere il
CAPITOLO 3:SOLUZIONE PROPOSTA
3.5 Strutture dinamiche: un esempio di esecuzione
dell’algoritmo
Procediamo ora con la verifica step-by-step di un metodo del JavaCard Kit [JCkit]:
per comodità viene proposto solo la parte di codice che ci interessa, cioè quella che consente di applicare le regole esposte precedentemente. Il bytecode disassemblato è presentato nella forma verbosa <label: opcode[cod](bytes) operands>: label è un
intero che rappresenta (in modo univoco) la posizione di una determinata istruzione nel bytecode, opcode è l’istruzione in forma mnemonica, [cod] è la codifica
dell’istruzione nel bytecode, (bytes) sono il numero di bytes utilizzati per codificare
l’istruzione, operands sono gli eventuali operandi dell’istruzione. Per le istruzioni di
salto condizionato vengono specificati anche i targets e, per comodità, l’ipd.
Nel seguito riportiamo il bytecode del metodo private void processCompleteTransaction(...) del file JavaPurse.class del JavaCard kit 2.2:
... 373: goto[167](3) -> 411: iload 10 376: aload_0[42](1) 377: getfield[180](3) 7 380: iload[21](2) 10 382: saload[53](1) 383: iload[21](2) 9
385: if_icmpne[160](3) -> 404: iload 10 IPD = 417: aload_0
388: aload_0[42](1) 389: getfield[180](3) 9 392: iload[21](2) 10 394: aaload[50](1) 395: aload_2[44](1) 396: invokeinterface[185](5) 61 401: goto[167](3) -> 417: aload_0 404: iload[21](2) 10 406: iconst_1[4](1) 407: iadd[96](1) 408: i2b[145](1) 409: istore[54](2) 10 411: iload[21](2) 10 413: iconst_4[7](1)
414: if_icmplt[161](3) -> 376: aload_0 IPD = 417: aload_0
417: aload_0[42](1) ...
CAPITOLO 3:SOLUZIONE PROPOSTA 377 376 380 382 383 385 389 388 392 394 395 401 396 406 404 407 408 409 413 411 414 417 373
CAPITOLO 3:SOLUZIONE PROPOSTA
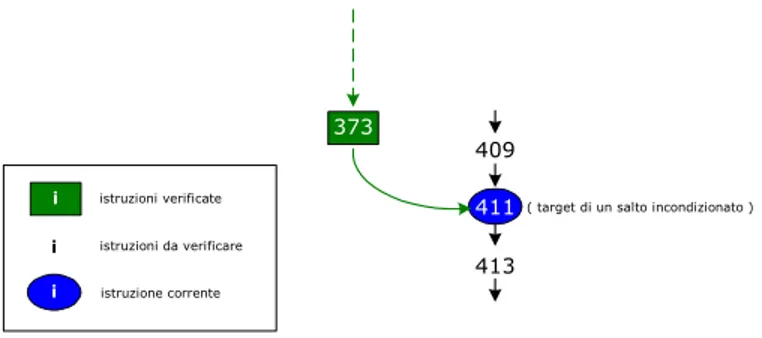
Nel seguito riportiamo l’esecuzione step-by-step del metodo. Supponiamo di
eseguire le istruzioni senza violare i vincoli statici e strutturali. Il dizionario è vuoto: cominciamo con l’istruzione 373, che è un salto incondizionato che porta all’istruzione 411 (goto 411). Già qui è possibile notare una differenza rispetto al verificatore della Sun: infatti non abbiamo memorizzato nel dizionario l’in-frame
dell’istruzione 411, target della 373 (vedi figura 3.11).
409
411 373
413
( target di un salto incondizionato ) istruzioni verificate istruzioni da verificare istruzione corrente i i i
fig. 3.11: goto 411, nessun frame salvato nel dizionario
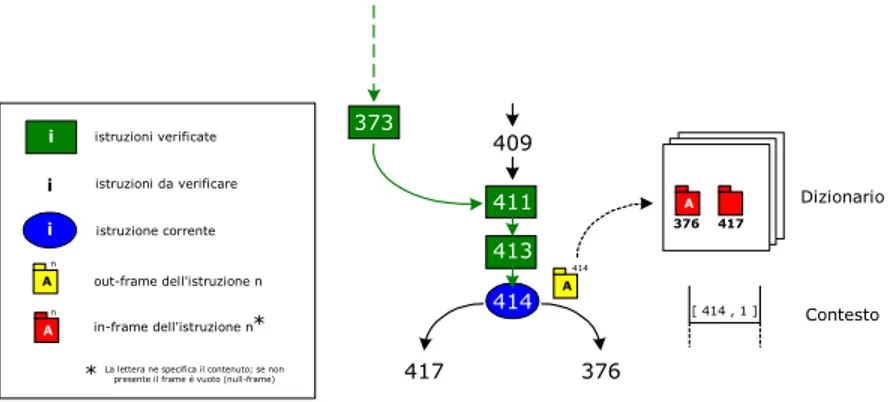
Si procede quindi fino al primo salto condizionato, cioè fino all’istruzione 414 (if_icmplt): l’istruzione estrae dallo stack due interi, ne fa il compare ed a seconda del risultato (non valutabile perché l’esecuzione è simbolica, siamo cioè a livello di tipi) l’istruzione successiva può essere il successore naturale (417) oppure
il target (376).
Il salto condizionato 414 viene incontrato per la prima volta quindi applichiamo la regola branch∉: eseguiamo simbolicamente l’istruzione (i due interi in testa allo stack vengono estratti), salviamo nel dizionario un frame per il target
(376) e un null-frame per l’ipd (417), e salviamo nel contesto la coppia [414:if_icmplt, 1] (vedi figura 3.12).
CAPITOLO 3:SOLUZIONE PROPOSTA 409 413 411 414 373 417 376 A Dizionario A 376 [ 414 , 1 ] Contesto 417 414 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n
n i i i
fig. 3.12: if_icmplt 376, regola branch∉
Proseguiamo quindi con l’esecuzione del successore naturale: in questo caso l’istruzione 417 è ipd ed anche successore naturale. Si deve applicare la regola ipd≠0 perché restano rami da esaminare (infatti in testa al contesto c’è la coppia [414:if_icmplt, 1]). Viene aggiornato il frame del dizionario relativo all’ipd (facendo
il merge con l’out-frame corrente), viene decrementato il contatore della coppia in
testa al contesto e la verifica continua con il target (376) [fig. 3.13].
413 414 417 376 Dizionario A 376 [ 414 , 0 ] Contesto 417 A n n istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n n i i i A 414
CAPITOLO 3:SOLUZIONE PROPOSTA
Per ricominciare correttamente l’esecuzione è necessario caricare nel current in-frame il in-frame salvato nel dizionario per il target (il current in-in-frame è il in-frame
dell’istruzione che viene eseguita simbolicamente di volta in volta dall’interprete astratto). In questo caso particolare il frame da caricare è identico al current in-frame (vedi figura 3.14).
413 414 417 A 376 Dizionario A 376 [ 414 , 0 ] Contesto 417 A n n 376 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n
n i i i
fig. 3.14: Regola ipd≠0, parte 2 – carico il frame per ricominciare correttamente l’esecuzione L’esecuzione simbolica va avanti in modo standard fino al nuovo salto condizionato (385): anche questa volta si deve applicare la regola branch∉: l’istruzione viene eseguita simbolicamente, nel dizionario viene salvato il frame per il target (in
questo caso non devo salvare un null-frame per l’ipd (417) perché già esiste una entry del dizionario relativa all’istruzione 417) e nel contesto viene salvata la coppia [385:if_icmpne, 1] (vedi figura 3.15).
383 385 388 404 Dizionario A 376 [ 414 , 0 ] Contesto 417 A B 404 [ 385 , 1 ] istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n n i i i B 385
fig. 3.15: if_icmpne 376, regola branch∉
Per come è strutturato il grafo, a questo punto della verifica si è raggiunta la dimensione massima del dizionario per il blocco attuale: nel dizionario sono infatti memorizzati gli in-frames dei 2 targets (404, 376) e dell’ipd (417) dei due salti
CAPITOLO 3:SOLUZIONE PROPOSTA
La verifica continua anche questa volta con il successore naturale, cioè con l’istruzione 388: aload_0. Quando si giunge al suo ipd (417) viene di nuovo applicata la regola ipd≠0: viene aggiornato il frame dell’ipd nel dizionario,
decrementato il contatore della coppia in testa al contesto (quella cioè relativa al
salto condizionato 385), caricato nel current in-frame il frame del dizionario relativo
al prossimo ramo da verificare (404) e l’esecuzione continua quindi con quel ramo. Questo passo è illustrato in figura 3.16.
Dizionario A 376 [ 414 , 0 ] Contesto 404 B n n A 417 [ 385 , 0 ] 404 385 388 C 401 401 417 { lub(A,C)=A } B 404 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n
n i i i
fig. 3.16: Regola ipd≠0
Procedendo il processo si giunge di nuovo al salto condizionato 414: ce ne accorgiamo perché esiste ancora una coppia relativa a lui nel contesto: occorre fare
il merge dell’out-frame generato questa volta dall’esecuzione simbolica della 414
con il frame del suo target (salvato nel dizionario).
[ 414 , 0 ] Contesto [ 385 , 0 ] 404 385 388 401 417 414 Dizionario A 376 404 B A 417 D 414 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n n i i i 376
CAPITOLO 3:SOLUZIONE PROPOSTA
Possono accadere due cose: il frame non cambia (branch=) oppure il frame cambia
(branch≠). Se il frame non cambia si assume di aver già verificato la 414 e si salta
direttamente all’ipd della 385 (vedi figura 3.18).
[ 414 , 0 ] Contesto [ 385 , 0 ] 404 385 388 401 417 414 Dizionario A 376 404 B A 417 D 414 A 417 { lub(D,A)=A } istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
*La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n n i i i 376
fig. 3.18: Regola branch=
Se invece il frame cambia bisogna eseguire di nuovo la 414. Per eseguire
nuovamente la 414 si compie un “rewind” dell’interprete astratto: vengono tolte dal
contesto le coppie [385:if_icmpne, 0] e [414:if_icmplt, 0], vengono tolti dal
dizionario i frames dei due targets e dell’ipd, e la verifica riprende di nuovo dal salto
condizionato 414, con la regola branch∉, questa volta però con il nuovo frame,
quello cioè che ha prodotto un cambiamento nel dizionario. Questo passo è illustrato in figura 3.19. istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n n i i i [ 414 , 0 ] Contesto [ 385 , 0 ] 404 385 388 401 417 376 Dizionario A 376 404 B A 417 D 414 { lub(D,A)=D } (411) D 376 417 [ 414 , 1 ] 414
CAPITOLO 3:SOLUZIONE PROPOSTA
Supponiamo di trovarci nel caso in cui si debba applicare la regola branch=
(operando sui tipi, che sono in numero finito, i frames possono cambiare un numero
limitato di volte, in base all’operatore lub(..)): la prossima istruzione è quindi l’ipd
417. Questa volta la regola da applicare è ipd=0 perché nel contesto il contatore per
l’istruzione 385 vale 0: eliminiamo quindi dal dizionario il frame relativo al target
404 e dal contesto la coppia [385:if_icmpne, 0]: il salto condizionato 385 viene
chiuso. 404 385 388 401 417 414 376 A 417 [ 414 , 0 ] Contesto [ 385 , 0 ] Dizionario A 376 404 B A 417 A 376 A 417 [ 414 , 0 ] istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n
n i i i
fig. 3.20: Regola ipd0 (I): chiusura del salto condizionato 385
L’ipd non può comunque ancora essere eseguito perché è necessario prima
verificare anche l’altro salto condizionato: questo può esser fatto subito perché anche la 414 ha il contatore a 0, cioè tutti i suoi rami sono stati verificati. Si procede quindi con l’eliminazione dal dizionario del frame del target (376) e dell’ipd
(417), e con l’eliminazione della coppia [414:if_icmplt, 0] dal contesto: anche il
salto condizionato 414 è chiuso ed il dizionario è di nuovo vuoto (vedi figura 3.21).
404 385 388 401 417 414 376 A 417 [ 414 , 0 ] Contesto Dizionario A 376 A 417 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n* *La lettera ne specifica il contenuto; se non
presente il frame è vuoto (null-frame) n
n i i i
CAPITOLO 3:SOLUZIONE PROPOSTA
3.6 Dizionario
senza
frames duplicati
Consideriamo il seguente codice, tratto dal metodo processCompleteUpdate(...) del JavaCard kit (file JavaPurse.class):
... switch (buffer[TLV_OFFSET]) { case MASTER_PIN_UPDATE: updatePIN(apdu, masterPIN); setIsPersonalized(); break; case USER_PIN_UPDATE: updatePIN(apdu, userPIN); break; case EXP_DATE_UPDATE: updateParameterValue(apdu, ExpDate); break; case PURSE_ID_UPDATE: updateParameterValue(apdu, ID_Purse); break; case MAX_BAL_UPDATE: updateBalanceValue(apdu, OFFSET_BAL_MAX); break; case MAX_M_UPDATE: updateBalanceValue(apdu, OFFSET_AMOUNT_MAX); break; case VERSION_UPDATE: updateParametersFile(apdu); break; case LOYALTY1_UPDATE: updateLoyaltyProgram(apdu, (byte)0); break; case LOYALTY2_UPDATE: updateLoyaltyProgram(apdu, (byte)1); break; case LOYALTY3_UPDATE: updateLoyaltyProgram(apdu, (byte)2); break; case LOYALTY4_UPDATE: updateLoyaltyProgram(apdu, (byte)3); break; default: ISOException.throwIt(ISO7816.SW_FUNC_NOT_SUPPORTED); } ...
Il bytecode generato dal compilatore Java è:
...
97: tableswitch[170](67) -> {164, 180, 192, ..., 269} IPD = 284: load_0 164: aload_0[42](1) 165: aload_1[43](1) 166: aload_0[42](1) 167: getfield[180](3) 22 170: invokespecial[183](3) 62 173: aload_0[42](1) 174: invokespecial[183](3) 63 177: goto[167](3) -> 284: aload_0 180: aload_0[42](1) 181: aload_1[43](1)
CAPITOLO 3:SOLUZIONE PROPOSTA 182: aload_0[42](1) 183: getfield[180](3) 23 186: invokespecial[183](3) 62 189: goto[167](3) -> 284: aload_0 ... 281: invokestatic[184](3) 39 284: aload_0[42](1) 285: getfield[180](3) 19 ...
ed il control-flow graph associato è mostrato in figura 3.22.
284 234 242 180 164 192 204 216 225 251 260 269 278 239 248 189 177 201 213 222 231 257 266 275 281 97
fig. 3.22: switch a 12 vie
Siamo quindi in presenza di uno switch a 12 vie (11 targets e un successore
naturale): se il codice fosse solo quello riportato l’algoritmo standard memorizzerebbe nel dizionario 11 entries, una per ogni target, mentre l’algoritmo
basato sull’ipd ne memorizzerebbe 12, una per ogni target ed una per l’ipd.
La cosa che più stupisce è che un metodo così semplice riesca a mettere in crisi entrambi gli algoritmi di verifica: gli switch fanno infatti crescere a dismisura il
numero di entries del dizionario. Analizziamo più in dettaglio come si comporta
CAPITOLO 3:SOLUZIONE PROPOSTA
risolverlo: quando si giunge all’istruzione 97 (tableswitch) si applica la regola
branch∉, cioè di salva un frame per ogni target, un null-frame per l’ipd, si aggiunge
al contesto la coppia [97:tableswitch, 11] e si procede con la verifica del successore
naturale. Questo passo è illustrato in figura 3.23.
234 242 180 164 192 204 216 225 251 260 269 278 97 Dizionario [ 97 , 11 ] Contesto 284 A 234 A 180 A 242 A 192 A 251 A 204 A 260 A 216 A 269 A 225 A 278 A 97 A out-frame dell'istruzione n A in-frame dell'istruzione n*
*La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n n istruzioni verificate istruzioni da verificare istruzione corrente i i i
fig. 3.23: Regola branch∉
Per 12 volte l’ipd (284) viene raggiunto: le prime 11 si applica la regola ipd≠0, come
mostrato in figura 3.24. 234 242 180 164 192 204 216 225 251 260 269 278 97 Dizionario [ 97 , 2 ] Contesto B 284 A 234 A 180 A 242 A 192 A 251 A 204 A 260 A 216 A 269 A 225 A 278 284 239 248 189 177 201 213 222 231 257 266 275 281
CAPITOLO 3:SOLUZIONE PROPOSTA
L’ultima volta invece la ipd=0 e si dealloca tutto il dizionario e la coppia [97:tableswitch, 0] dal contesto (vedi figura 3.25).
234 242 180 164 192 204 216 225 251 260 269 278 97 Dizionario Contesto B 284 A 234 A 180 A 242 A 192 A 251 A 204 A 260 A 216 A 269 A 225 A 278 284 239 248 189 177 201 213 222 231 257 266 275 281 [ 97 , 0 ]
fig. 3.25: Regola ipd=0
Ciò che risulta evidente è che i frames salvati nel dizionario non sono mai stati
modificati durante l’esecuzione simbolica delle istruzioni dei rami, a parte quello dell’ipd: le entries dei targets sono servite solo per salvare gli in-frames per poter
ricominciare correttamente la verifica di ogni ramo. Il “reale” contenuto di tali
entries altro non è che l’out-frame del salto condizionato, salviamo cioè 11 volte la
stessa identica informazione nel dizionario. Salvare in-frames diversi per diversi targets è una cosa che in generale occorre fare perché a-priori non è possibile
sapere se durante l’intero processo di verifica tali frames restano identici: ad
esempio un target dello switch potrebbe essere anche target di una istruzione di
salto, ad esempio di una istruzione if, di un altro ramo dello switch e questo
CAPITOLO 3:SOLUZIONE PROPOSTA 22 4 6 { lub(A,C)=C } 9 Dizionario A 14 22 C 14 12 A 4 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
*La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n n i i i 8 C 9
fig. 3.26: L’in-frame di un target può cambiare durante la data-flow analysis
Ciò che possiamo sicuramente affermare è però che subito dopo l’esecuzione dello
switch tutti gli in-frames dei targets sono identici; quindi è sufficiente memorizzare
un solo frame nel dizionario, e farlo “puntare” da più istruzioni: in questo modo se
eventualmente durante la data-flow analysis il frame di uno o più targets dovesse
cambiare siamo in grado di tenerne conto.
Gestire un dizionario con una politica del genere è leggermente più complesso ma può portare grandi vantaggi per quanto riguarda l’occupazione in memoria: ad esempio verificando il metodo processCompleteUpdate(...) con tale strategia la dimensione massima del dizionario sarebbe stata pari ad 1 perché il
frame dell’ipd, quando viene creato “realmente” applicando la regola ipd≠0, risulta
essere identico a quello dei targets (il null-frame iniziale dell’ipd non viene
“realmente” allocato).
Questa gestione del dizionario può essere ovviamente utilizzata con successo anche nella verifica standard: tenendo conto del fatto che il codice delle
applets, in particolare quello della Java Cards, è “piccolo” si può osservare infatti
che i frames sono molte volte identici. Il principio è simile a quello utilizzato nelle
cache, cioè è possibile notare una sorta di località spaziale e temporale nella tipologia di operazioni effettuate in prossimità delle diramazioni e ricongiungimenti dei rami del control-flow graph. Con l’algoritmo di verifica basato sull’ipd la località
delle operazioni viene accentuata perché la data-flow analysis procede “a blocchi”
ed appena si esce da un blocco tutti i frames (non più necessari) vengono
CAPITOLO 3:SOLUZIONE PROPOSTA
3.7 Analisi critica dei risultati
Alla base della inefficienza, in termini di occupazione in memoria, dell’algoritmo standard di verifica c’è l’allocazione statica del dizionario all’inizio della data-flow analysis dei metodi. L’algoritmo di verifica basato sull’ipd è appunto studiato per
ottimizzare questo aspetto. Memorizzare un frame per ogni target di un salto
condizionato e per l’ipd potrebbe sembrare che porti ad un incremento delle
dimensioni del dizionario, rispetto alla verifica standard. In realtà questo avviene solo per pochissimi casi, in particolare solo per metodi particolarmente semplici, si pensi ad esempio al bytecode del paragrafo precedente, ed il problema può
comunque esser facilmente risolto utilizzando una politica di allocazione che eviti
frames duplicati. La struttura che caratterizza i metodi in cui si hanno maggiori
vantaggi per l’algoritmo basato sull’ipd è una struttura a blocchi: ogni volta che un
blocco viene “chiuso” il dizionario diminuisce di dimensione. Tale situazione è mostrata in figura 3.27. START 0 2 END 5 6 9 12 22 23 25 26 29 Numero massimo di entries nel dizionario 2 1 0 3 4 (goto 12) (goto 29)
Verificatore basato sull'ipd Verificatore standard
fig. 3.27: Numero di entries nel dizionario durante la verifica
I maggiori svantaggi rispetto all’algoritmo standard sono nel tempo di verifica. Le principali cause del maggiore tempo di verifica sono legate a due fattori:
1. deallocazione delle entries dal dizionario; 2. verifica di un “numero maggiore” di istruzioni.
CAPITOLO 3:SOLUZIONE PROPOSTA
Il primo svantaggio era quasi ovvio: basta però implementare una politica di allocazione “furba” in cui vengano evitati duplicati nel dizionario per ottenere delle performance molto vicine a quelle del verificatore standard: le entries nel dizionario
vengono drasticamente ridotte, quindi vengono risparmiate molte scritture, che sono operazioni più lente rispetto alle letture.
Il secondo problema invece è anche quello che in realtà potrebbe far aumentare maggiormente il tempo di verifica. Consideriamo ad esempio un grafo così strutturato: due salti condizionati consecutivi e disgiunti; supponiamo che un ramo del secondo salto condizionato contenga un salto all’indietro, su un target del
salto condizionato precedente (vedi figura 3.28).
START 0 2 END 5 6 9 12 22 23 25 26 29
fig. 3.28: Ripetizione di istruzioni a causa della deallocazione del dizionario
In questo caso verifichiamo due volte le stesse istruzioni perché abbiamo deallocato dal dizionario l’entry del target quando il primo salto condizionato è stato chiuso:
abbiamo cioè perso l’informazione che specificava se e come era stato verificato il
target e le istruzioni seguenti. In questo caso particolare il verificatore basato
sull’ipd verifica di nuovo tutte le istruzioni fino al secondo salto condizionato. Con il
verificatore standard avremmo invece “potenzialmente” potuto evitarlo: se infatti il
frame con cui si arriva la seconda volta ha nei registri dei tipi “più lontani
dall’Object” (in termini di gerarchia dei tipi) rispetto alla prima volta, la verifica non
sarebbe stata necessaria.
Il tempo di verifica non inficia la validità dell’approccio perché la verifica dell’applet è eseguita una sola volta al momento dell’installazione su carta: l’applet