Test e valutazioni sul modello ASSISTANT
In questo capitolo della tesi si cercherà di fornire una prima valutazione della portata del modello ASSISTANT. Il capitolo ha la seguente struttura: per prima cosa sarà descritto un piccolo esempio di applicazione parallela ad alte prestazioni, adattiva alle informazioni di contesto, successivamente saranno descritte le implementazioni ASSIST alternative dei moduli dell’esempio, ed infine si cercherà di emulare i meccanismi di adattività di ASSISTANT, dando una valutazione qualitativa del modello di programmazione.
6.1 Descrizione dell’applicazione parallela per la valutazione del modello
ASSISTANT
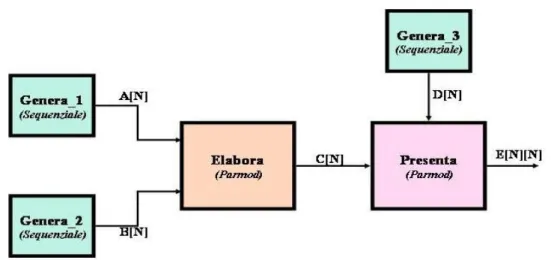
L’applicazione parallela che consideriamo, è un’applicazione didattica, in cui non entreremo nello specifico degli algoritmi sequenziali utilizzati né nell’ambito di utilizzo dell’applicazione. L’esempio potrebbe essere relativo alla gestione delle emergenze, per esempio per il calcolo di un modello previsionale per un’emergenza, oppure l’esecuzione parallela di un algoritmo di Data-Mining per il supporto alle decisioni. La figura 6.1 descrive la struttura dell’esempio:
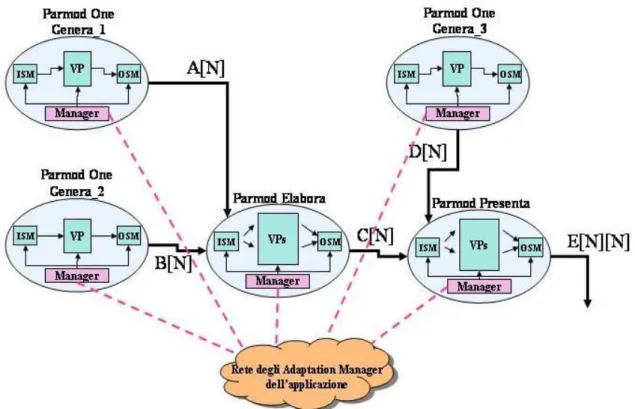
Figura 6.1: Schema dell’applicazione parallela per la valutazione di ASSISTANT.
Nell’applicazione abbiamo tre moduli sequenziali (PARMOD ONE) responsabili della generazione degli stream di input. I moduli sono Genera_1, Genera_2 e Genera_3 e hanno un funzionamento molto simile, ovvero producono uno stream di output di vettori, ciascuno di N interi, risultato di precedenti calcoli che omettiamo in questa sede. Il modulo Elabora necessita della presenza di un elemento in entrambi gli stream di ingresso per iniziare l’elaborazione. Una volta ricevuto un vettore A da Genera_1 e un vettore B da Genera_2, Elabora esegue la seguente operazione, per calcolare ciascun elemento del vettore C di output:
(
)
: [ ] : [ ], i C i F A i B
∀ = i=1, 2,...,N (1)
Il risultato del calcolo eseguito dal modulo Elabora è un vettore C di N interi, dove ogni intero è stato calcolato come indicato in (1). Lo stream di vettori C viene ricevuto dal modulo Presenta, che per iniziare l’elaborazione deve riceve un vettore da entrambi gli stream di ingresso, sia quello da Elabora sia quello da Genera_3. Presenta esegue un calcolo specifico, per ottenere dati i vettori C e D di input, una matrice quadrata E di dimensione NxN . Il calcolo eseguito è descritto dal frammento di pseudo-codice qui di seguito:
for i := 0 to N-1 do
for j := 0 to N-1 do (2) E[i][j] := G(C[i], D[j]);
producendo una matrice E che è il risultato dell’intera computazione, che viene inviato sullo stream di output. Per adesso ipotizziamo che la dimensione dei vettori e della matrice sia un valore N staticamente definito. Successivamente rimuoveremo questa opzione, individuando alcune alternative al valore che dinamicamente può assumere, e per quale motivazione.
6.2 Implementazione ASSIST dell’esempio
Nel paragrafo forniremo una prima implementazione dei moduli Elabora e Presenta, individuando implementazioni alternative degli stessi. Al fine di poter fornire una prima valutazione di ASSISTANT, posiamo limitarci ad identificare due alternative
implementazioni parallele, una task-parallel di tipo farm, l’atra data-parallel di tipo map per i due moduli paralleli.
6.2.1 Implementazione task-parallel del modulo Elabora
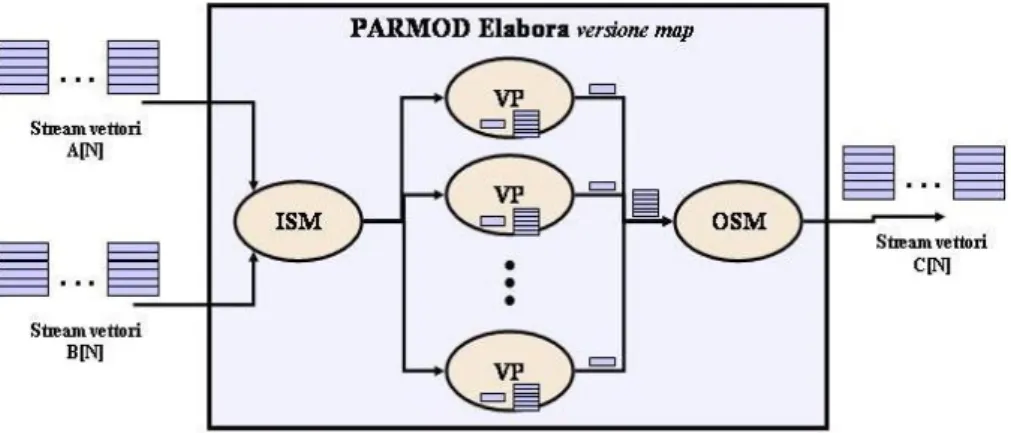
Nell’implementazione task-parallel, il PARMOD Elabora ha una topologia none, in cui ogni processore virtuale calcola completamente un vettore risultante C. Un VP riceve per intero un array A e un array B, ed esegue il calcolo di tutti gli elementi del vettore C, mediante l’uso della funzione sequenziale F. La figura 6.2 riassume lo schema del PARMOD Elabora versione farm:
Figura 6.2: Schema della versione farm del modulo Elabora.
Il codice ASSIST dell’implementazione è descritto in figura 6.3:
L’implementazione è caratterizzata da un PARMOD con topologia none, in cui ogni VP non ha associato alcuno stato replicato. La modalità di distribuzione prevede l’AND degli stream A e B, in modo che i dati vengano distribuiti ai VP solamente nel caso in cui sia presente un vettore in ciascuno stream di input del modulo Elabora. Ogni VP che riceve un vettore A e un vettore B di N interi, calcola sequenzialmente il vettore C in base alla formula indicata in (1), eseguendo N iterazioni della funzione F scritta in C++. Ogni vettore C prodotto, viene collezionato dalla sezione di output, che provvede ad inviarlo sullo stream di uscita dell’intero PARMOD.
6.2.2 Implementazione data-parallel del modulo Elabora
L’altra implementazione del modulo prevede una diversa forma di parallelismo e un diverso numero di VP, che eseguono un codice sequenziale alternativo. Il PARMOD in questo caso ha una topologia array, con N processori virtuali, dove ognuno di questi calcola in parallelo agli altri l’elemento corrispondente al proprio indice del vettore C, utilizzando l’elemento del vettore A con indice uguale a quello del VP. Ciascun virtual processor esegue un calcolo indipendente da quello degli altri, per cui siamo di fronte ad un’implementazione map, la cui struttura è descritta in figura 6.4:
Figura 6.4: Schema della versione map del modulo Elabora.
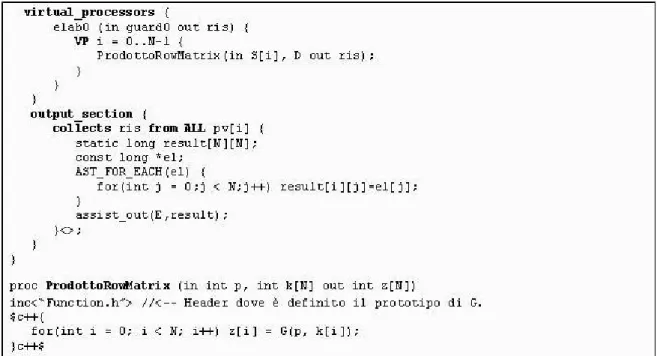
Oltre ad utilizzare un elemento del vettore A, ogni VP utilizza per intero il vettore B, in modo che ogni processore virtuale esegua il calcolo indipendente dell’elemento corrispondente al proprio indice del vettore risultante C, mediante la computazione della funzione sequenziale F. Nella figura 6.5 viene mostrato il codice ASSIST dell’implementazione data-parallel del modulo:
Figura 6.5: Implementazione map del modulo Elabora.
Del PARMOD Elabora abbiamo fornito due implementazioni che comunque mantengono la stessa interfaccia del modulo. Nel caso task-parallel ogni singolo processore virtuale esegue il calcolo di C per intero, sequenzialmente, dati i vettori A e B di input, e quindi viene parallelizzato il processo di calcolo di diversi vettori C tra di loro. Nell’implementazione data-parallel invece, è stato parallelizzato il processo di calcolo dei singoli elementi dei vettori C. In questo caso ogni processore virtuale, tanti quanti sono gli elementi di C, calcola l’elemento corrispondente utilizzando per intero il vettore B e un solo elemento del vettore A. Le due implementazioni alternative hanno alcune caratteristiche differenti, che rientrano nel noto confronto tra farm e map [55] e che valgono il linea generale:
1. Nel caso in cui la grana di calcolo di F sia medio-fine, il farm ottiene buoni risultati con grado di parallelismo inferiore rispetto al caso data-parallel.
2. La forma map è un tipico paradigma adatto a grane di calcolo più grosse, quindi nel nostro esempio con la funzione sequenziale F con tempi medi di elaborazioni significativi.
3. La forma farm è in grado di per sé di bilanciare il carico tra gli worker (processi VPM del PARMOD), operando con una distribuzione su domanda. Mentre nel caso della map, il bilanciamento dipende dalla varianza del tempo medio di elaborazione della funzione sequenziale F. Tanto è maggiore la varianza, tanto più la map presenterà possibili sbilanciamenti del carico in media.
4. la soluzione map può essere preferibile in tutti quei casi in cui i nodi di elaborazione, su cui viene eseguito il calcolo, abbiano vincoli particolarmente stringenti sulla memoria disponibile, nel caso di vettori con dimensione considerevole.
Dal punto di vista del tempo di completamento del modulo Elabora, le due distinte implementazioni non hanno grosse differenze in generale, mentre gli aspetti cruciali sono relativi:
1. All’utilizzo di memoria.
2. Alla realizzazione della scatter del vettore A.
Nel primo caso si può osservare che nell’implementazione task-parallel, ogni processore virtuale ha la necessità di mantenere per intero in memoria il vettore A, il vettore B e il vettore del risultato C. In tutto ogni singolo processore virtuale deve lavorare con 3* N valori interi. Nel caso invece della map, ogni processore virtuale utilizza il vettore B per intero, un elemento del vettore A e produce un elemento del vettore finale C, per un totale di N + interi. La differenza in termini di costanti moltiplicative, può essere 2 importante nel caso in cui N sia un parametro estremamente elevato, nell’ordine di migliai di interi. E’ quindi possibile pensare di utilizzare le due distinte implementazioni del modulo parallelo, in relazione alla tipologia di nodi su cui sono eseguiti i processi VPM del PARMOD. Per esempio, nel caso in cui il modulo sia eseguito su nodi mobili e pervasivi, con una limitata capacità sia di memoria principale che di ulteriori dispositivi di memorizzazione di massa per la memoria virtuale (come accade per i PDA), può essere preferita l’esecuzione di una map, altrimenti l’esecuzione di un farm che bilancia il carico con maggiori garanzie.
Per quanto riguarda il secondo caso invece, un aspetto importante nella realizzazione map è come è implementata la scatter, ovvero il processo di distribuzione degli elementi
dei vettori A ai VP. Supponendo di avere N Virtual Processor, partizionati tra K processi Virtual Processor Manager (worker), le diverse implementazioni della scatter possono avere le seguenti performance [55]:
( )
2 log scatter send scatter send N T K T K N T K T K = ⋅ = ⋅ Nel primo caso si assume che la scatter venga fatta linearmente, mediante una sequenza di spedizioni, mentre nel secondo caso utilizzando un albero binario, che comporta un numero di spedizioni logaritmico sul numero di worker. Il valore Tsend indica, in relazione all’architettura, il tempo medio per l’esecuzione di una primitiva di comunicazione, in funzione del numero di parole. Nella versione map la scatter può rappresentare un collo di bottiglia, se vale la relazione (con implementazione lineare):
send F N N K T T K K ⋅ > ⋅
Con TF tempo medio di elaborazione di un elemento del vettore C da parte di un VP.
ovvero se il tempo si servizio della scatter è maggiore del tempo di servizio di un generico worker della map. Occorre quindi dimensionare le partizioni, e quindi il numero di worker, in modo da evitare questa situazione. Il calcolo sul grado di parallelismo ottimale può essere eseguito dall’Adaptation Manager di ogni PARMOD ASSISTANT, che è a conoscenza del modello dei costi e della definizione della funzione Tsend in relazione all’architettura correntemente usata. Nel capitolo, ci limiteremo comunque a considerare l’utilizzo di memoria come sola discriminante, tra la versione farm e la versione map.
6.2.3 Implementazione task-parallel del modulo Presenta
Similmente a quanto abbiamo già considerato per il modulo Elabora, descriviamo adesso le due distinte implementazioni per il modulo parallelo Presenta, responsabile della
realizzazione dello stream finale di output dell’intera applicazione parallela. Anche in questo caso consideriamo, per semplicità, le implementazioni farm e map del modulo. Nel caso dell’implementazione farm, ogni VP del modulo Presenta esegue il calcolo sequenziale dell’intera matrice E NxN risultante. In questa situazione quindi i vettori C e D, ricevuti rispettivamente dai moduli Elabora e Genera_3, vengono distribuiti su domanda ai VP, che provvedono ad eseguire il calcolo della matrice risultante E, in base all’algoritmo indicato in (2). La figura 6.6 descrive la struttura del PARMOD:
Figura 6.6: Schema della versione farm del modulo Presenta.
Il codice ASSIST dell’implementazione farm è mostrato nella figura 6.7 qui di seguito:
Figura 6.7: Implementazione farm del modulo Presenta.
Quindi in questa situazione, ogni processore virtuale esegue il calcolo per intero della matrice E finale, utilizzando un intero vettore C e un intero vettore D. In questo modo la
seguente forma di parallelismo consente di parallelizzare il calcolo di diverse matrici E, tra di loro.
6.2.4 Implementazione data-parallel del modulo Presenta
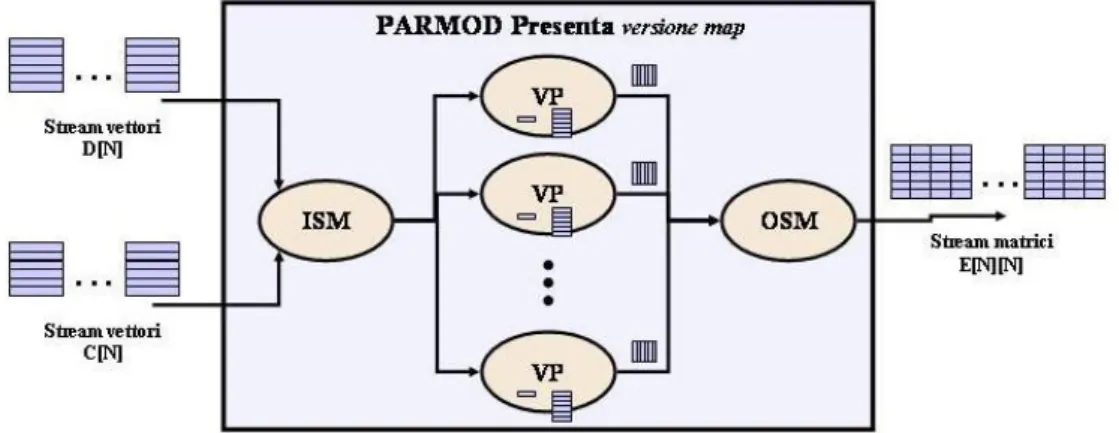
L’implementazione alternativa del modulo Presenta consiste in una map con N processori virtuali, a ciascuno dei quali viene associata una riga della matrice E finale e il suo calcolo indipendente. Per ogni coppia di vettori C e D ricevuti, viene eseguita la scatter del primo vettore verso i corrispondenti VP, mentre del secondo vettore viene fatta una broadcast. In questo modo ogni VP è in grado di produrre una sola riga della matrice finale, che viene ricomposta nella sezione di output. La figura 6.8 mostra la modalità di distribuzione e collezione, di questa versione implementativa:
Figura 6.8: Schema della versione map del modulo Presenta.
In questo caso ognuno degli N processori virtuali si limita ad eseguire il calcolo di una sola riga della matrice risultante (quella con indice corrispondente al VP che la calcola). Quindi mentre nella versione farm viene parallelizzato il processo di calcolo tra matrici E di output, nella versione map viene parallelizzato il processo di calcolo di una matrice e dei suoi elementi. La figura 6.9 mostra il codice ASSIST dell’implementazione.
Figura 6.9: Implementazione map del modulo Presenta.
Anche per questo secondo modulo parallelo valgono le considerazioni sul confronto map/farm, che sono già state fatte per il modulo Elabora. Per quanto riguarda l’occupazione di memoria da parte dei VP, le considerazioni precedenti sono più che mai valide in questo caso, dove avendo a che fare con matrici il problema della memoria ha un ordine di grandezza superiore, rispetto al caso precedente. Nella versione farm infatti, ogni processore virtuale opera su due vettori di N interi, e produce una matrice di N2 interi. Il numero di elementi su cui opera ogni VP è quindi 2
2N+N nel caso task-parallel. Nel caso data-parallel invece, ogni VP della map opera sull’intero vettore D, e su un elemento del vettore C, producendo una riga di N interi di risultato, per un totale di 2N +1 elementi, che rappresenta una riduzione significativa, con N nell’ordine di migliaia di interi. In questo modo quindi, l’implementazione map di Presenta può essere preferita in tutti quei contesti in cui l’esecuzione dei processi del modulo parallelo, debba avvenire su nodi di elaborazione con piccole capacità di memorizzazione, come nodi mobili e pervasivi, che per esempio sono gli unici disponibili in una situazione d’emergenza.
6.3 Applicazione del modello ASSISTANT all’esempio
In questo paragrafo descriveremo l’utilizzo del modello ASSISTANT per l’esempio di applicazione che abbiamo descritto. L’obiettivo è quello di descrivere come i manager dei
PARMOD riconfigurino i loro moduli paralleli, a seguito di eventi ambientali e di monitoraggio delle prestazioni, e come i manager siano in grado di comunicare tra di loro in modo da coordinare il processo di adattività globale, che coinvolga l’intera applicazione in esame.
Un primo modo per iniziare è renderci conto dello schema dell’applicazione, introducendo il modello ASSISTANT. In questo caso, ogni PARMOD dell’applicazione è formato dai quattro elementi primitivi del modello: l’input section, l’output section, l’insieme dei processori virtuali e il manager dell’adattività. In termini di processi individuiamo l’Input Section Manager e l’Output Section Manager, per la gestione della distribuzione degli input e collezione degli output, i processi VPM (Virtual Processor Manager), ciascuno responsabile dell’esecuzione di una partizione dei VP del PARMOD, e il manager dell’adattività, eventualmente realizzato anche da più processi cooperanti. La figura 6.10 descrive questo schema, evidenziando l’interconnessione tra i manager dei moduli dell’applicazione:
Figura 6.10: Applicazione parallela strutturata con il modello ASSISTANT.
Come è già stato spiegato, il manager dell’adattività di un PARMOD ha la possibilità di riconfigurare il modulo, in base alla ricezione di un evento esterno, che per esempio può essere: un evento che segnala una modifica delle prestazioni del modulo parallelo, oppure un evento relazionato al contesto ambientale. Il manager viene programmato dall’utente
dell’applicazione parallela mediante le regole della sua politica di adattività, che specificano per ogni evento le riconfigurazioni che devono essere compiute reattivamente sul PARMOD, senza interromperlo, ma tra l’esecuzione di computazioni indipendenti (esempio tra due item successivi degli stream di input, come è stato già spiegato nel quinto capitolo). Nel seguito analizzeremo, prima il processo di adattività locale di ogni modulo parallelo, poi cercheremo di descrivere il processo di adattività globale dell’applicazione, e le interazioni conseguenti tra gli Adaptation Manager dei moduli.
6.3.1 L’adattività locale dei singoli PARMOD
Nel paragrafo saranno presentate le politiche di adattività locali dei moduli paralleli Elabora e Presenta dell’applicazione, per la valutazione di ASSISTANT.
1) Adattività locale del modulo Elabora
Nel caso del modulo Elabora, possiamo considerare la seguente struttura ASSISTANT del modulo, e l’interazione con l’interfacce e i servizi esterni di contesto descritta nella figura 6.11:
Figura 6.11: Modulo parallelo ASSISTANT Elabora.
L’Adaptation Manager di Elabora esegue i processi di riconfigurazione delle funzioni e delle prestazioni, sul modulo parallelo. Come esemplificazione abbiamo introdotto per il modulo parallelo due alternative funzionali, una che utilizza il paradigma farm, l’altra la forma di parallelismo data-parallel map. Il passaggio da una forma all’altra, a seguito di un
evento esterno, comporta la necessità di eseguire le seguenti operazioni di riconfigurazione sui processi del PARMOD:
1. Il cambiamento della topologia, nel primo caso none mentre nel secondo caso array.
2. Il cambiamento del numero di VP, nel primo caso a VP anonimi, nel secondo N. 3. Il cambiamento delle politiche di distribuzione dell’ISM. Nel primo caso la politica
è on demand per entrambi i vettori A e B, nel secondo caso è una scatter del vettore A e una broadcast ai VP del vettore B.
4. Il cambiamento delle politiche di collezione dell’OSM. Nel primo caso una semplice collezione dei dati dei VP, nel secondo una raccolta (gather) dei risultati ricevuti dai VP e la ricomposizione del vettore finale C.
5. La modifica del codice sequenziale eseguito da ciascun VP. Nel primo caso ogni VP esegue la funzione con nome “IteraF”, nel secondo caso “EseguiF”.
6. La modifica dello stato dei VP. Nel primo caso non c’è stato, i VP sono solo entità funzionali, nel secondo ogni VP utilizza un elemento del vettore S di N interi, suddiviso (scatter) tra gli N processori virtuali.
Queste sono le sei operazioni compiute dal manager, per il passaggio fra le due forme di parallelismo. La scelta di cambiare la forma di parallelismo del modulo Elabora, può dipendere da un evento esterno, ricevuto tramite le interfacce di contesto. Come abbiamo visto, l’evento esterno può essere relativo alla tipologia di nodi di elaborazione su cui sono correntemente eseguiti i processi VPM del PARMOD, e la loro capacità in termini di memoria. L’alternativa map rispetto all’alternativa farm può essere preferibile in tutte quelle situazioni in cui, a causa del valore di N molto grande, la richiesta di memoria principale da parte dei processi VPM può essere troppo elevata per la disponibilità dei nodi su cui sono eseguiti realmente. In particolar modo, quindi, la scelta tra map e farm può dipendere dal tipo di nodi su cui i processi del modulo parallelo sono eseguiti correntemente.
Nel caso di situazioni di emergenza, se il processi VPM del PARMOD vengono assegnati dal manager su nodi con scarsa capacità di memoria, può essere necessario modificare l’implementazione del modulo, sostituendo alla corrente implementazione farm, l’implementazione map che abbiamo descritto. Oppure, se l’alternativa funzionale adottata correntemente è la map, può essere necessario riutilizzare la forma farm, non
appena nella Pervasive Grid tornino disponibili nodi di elaborazione con capacità sufficienti .
Figura 6.12: Possibile politica di adattività del manager di Elabora.
La figura 6.12 mostra un possibile frammento della politica di adattività del modulo Elabora. La sintassi usata è da intendersi in forma completamente informale e solo prototipale. Nelle regole della politica di adattività del manager, vengono definiti gli eventi di contesto a cui questo è interessato. In questo caso sono:
1. low_memory_availability: quando l’evento si verifica, indica che almeno un processo VPM del PARMOD è eseguito su un nodo di elaborazione con una corrente capacità di memoria principale, inferiore al limite necessario per l’esecuzione efficiente della modalità farm, in base al valore di N. Il limite viene calcolato utilizzando una funzione Space, che dipende dalla dimensione dei vettori N di input. L’evento viene verificato mediante l’interazione tra l’Adaptation Manager e un servizio esterno di contesto (VPMs_Stats_Service), responsabile di fornire le indicazioni sullo stato (esempio sulla memoria principale disponibile ed utilizzata) dei nodi su cui sono correntemente mappati i processi.
2. only_low_memory_node_presence: quando l’evento si verifica, indica l’assenza nell’ambiente di nodi di elaborazione con disponibilità di memoria principale sufficiente all’esecuzione della modalità farm. L’evento viene verificato mediante l’interazione tra l’Adaptation Manager e un servizio di Resource Discovery esterno, che viene contattato come una qualsiasi altra interfaccia di contesto.
3. normal_memory_availability: quando l’evento si verifica, indica che tutti i processi VPM sono eseguiti su nodi con capacità di memoria principale sufficiente all’esecuzione della modalità farm. Anche in questo caso la presenza dell’evento viene rilevata dall’Adaptation Manager, mediante l’interazione con un servizio di contesto VPMs_Stats_Service, che assumiamo sia disponibile.
Il significato delle regole è da intendersi che, finché persiste un evento di contesto, il PARMOD adotta uno specifico comportamento (implementazione), quando l’evento non è più verificato, viene innescato un processo di riconfigurazione per modificare il comportamento in base alle regole di politica. Le ultime due regole della figura 6.12 quindi, sono applicate solo quando Elabora è entrato nella modalità map, ed indicano quando è possibile tornare alla modalità di default farm. Le prime due regole sono invece applicate solo quando il modulo è in modalità farm, ed indicano quando è necessario modificare la forma di parallelismo. L’attuazione della politica di adattività del PARMOD, richiede l’interazione da parte del manager con le interfacce di contesto esterne, che in questo caso possono essere:
o VPMs_Stats_Service: servizio di contesto che fornisce misurazioni in tempo reale sulla memoria principale disponibile ed utilizzabile dei nodi su cui sono attualmente mappati i processi VPM del modulo parallelo.
o ResourceDiscoveryService: servizio per la scoperta dinamica delle risorse della Pervasive Grid disponibili, con determinate caratteristiche sulla capacità di elaborazione e memoria principale.
Supponiamo che il PARMOD inizialmente utilizzi la modalità farm. Dalle politiche si evince come il manager modifichi l’implementazione del PARMOD, in modo che:
1. Se esiste un VPM che viene eseguito su un nodo con capacità di memoria principale insufficiente, il manager verifica la presenza di altri nodi di elaborazione idonei, e nel caso esistano, esegue una migrazione del VPM su uno di questi. Se possibile quindi, il manager mantiene l’implementazione farm, che garantisce un miglior bilanciamento del carico tra i processi Virtual Processor Manager.
2. Se nel caso precedente, non esiste invece un nodo con capacità sufficienti, il manager decide di modificare la forma di parallelismo eseguendo la forma di parallelismo data-parallel, che consente di ridurre le richieste in termini di memoria principale necessaria per l’esecuzione dei VPM.
L’implementazione map viene mantenuta fintanto esistono le condizioni d’emergenza, per cui sono disponibili solo nodi mobili con piccole capacità di memorizzazione (esempio PDA a disposizione degli utenti). Nel caso la condizione d’emergenza venga meno, e venga ripristinata la normale connettività dei dispositivi dell’ambiente, possono tornare disponibili nodi d’elaborazione con capacità maggiori, per esempio nodi di un cluster connesso ai nodi d’interfaccia (per riferirci all’esempio di applicazione pervasiva proposto nel terzo e quarto capitolo). In questo caso il manager deve modificare la forma di parallelismo, tornando alla modalità farm che è preferibile.
Nel nostro esempio quindi, l’Adaptation Manager del modulo Elabora è in grado di modificare l’implementazione del PARMOD, passando da un’implementazione farm ad una map, e viceversa, in relazione alla capacità di memoria principale dei nodi su cui sono eseguiti i processi VPM del modulo, ed in relazione alla disponibilità nella griglia di altri nodi idonei. Se possibile, viene eseguita la modalità task-parallel, altrimenti in una situazione d’emergenza (connettività scarsa e presenza solo di piccoli nodi pervasivi), viene usata la modalità data-parallel finché l’emergenza persiste.
Il manager è anche in grado di modificare dinamicamente il grado di parallelismo del modulo Elabora, modificando il numero e il mapping sui nodi dei processi VPM, eseguendo le seguenti operazioni:
o Aggiunta o rimozione di un processo VPM modificando il mapping VP-VPM.
o Migrazione di un processo VPM su un nodo. Questa operazione può essere necessaria se un nodo, su cui era eseguito un VPM, non è più raggiungibile ed utilizzabile.
Il manager può modificare dinamicamente il grado di parallelismo (numero dei VPM) del modulo, in base al valore medio del tempo d’interarrivo sui suoi stream di input. In questo modo il manager, utilizzando il proprio modello dei costi, deve avere la possibilità di determinare se il modulo è o meno un collo di bottiglia dell’applicazione. Nel caso lo
sia, può aumentare il grado di parallelismo, al fine di migliorare il tempo di servizio, rimuovendo se possibile il collo di bottiglia. Se non lo è, può invece diminuire il grado di parallelismo eccessivo, per migliorare l’efficienza relativa del modulo parallelo.
2) Adattività locale del modulo Presenta
Similmente a quanto abbiamo visto per il modulo Elabora, anche il modulo Presenta ha una struttura analoga al precedente modulo parallelo, come mostrato in figura 6.13:
Figura 6.13: Modulo parallelo ASSISTANT Presenta.
Anche in questo caso individuiamo l’Adaptation Manager del modulo Presenta, che si occupa d’implementare l’adattività, sia delle funzioni che delle prestazioni del PARMOD. Per l’adattività delle funzioni Presenta prevede due distinte implementazioni, anche in questo caso una farm o una map. Normalmente il modulo utilizza la versione task-parallel, e la riconfigurazione della forma di parallelismo può dipendere dalle tipologie di nodi disponibili e dalla loro capacità di memoria principale. Nel caso di passaggio dalla forma farm alla map, vengono effettuate dal manager le seguenti operazioni:
1. Un cambiamento della topologia del PARMOD, nel primo caso none mentre nel secondo array.
2. Una cambiamento del numero di VP, nel primo caso VP anonimi nel secondo N. 3. Una cambiamento delle politiche di distribuzione nell’ISM. Nel primo caso la
politica è on demand, per entrambi i vettori C e D, nel secondo caso è una scatter del vettore C e una broadcast ai VP del vettore D.
4. Un cambiamento delle politiche di collezione dell’OSM. Nel primo caso una semplice collezione dei risultati dei VP, nel secondo una collezione (gather) delle righe ricevute dai VP, e la ricomposizione della matrice finale E.
5. Viene modificato il codice sequenziale eseguito da ciascun VP. Nel primo caso ogni VP esegue la funzione sequenziale con nome “CalcoloMatrice”, nel secondo caso, invece, la funzione sequenziale “ProdottoRowMatrix”.
6. Viene modificato lo stato dei VP. Nel primo caso non c’è stato, i VP sono solo entità funzionali. Nel secondo caso, invece, ogni VP utilizza un elemento del vettore S di N interi, suddiviso (scatter) tra gli N processori virtuali.
Come nel caso precedente, la politica di adattività del modulo Presenta può essere definita in modo analogo al modulo Elabora, come abbiamo già visto nella figura 6.12.
Per l’adattività delle prestazioni anche il manager del modulo Presenta può occuparsi di variare dinamicamente il grado di parallelismo del modulo. Può essere necessario aumentare il grado di parallelismo (numero di processi VPM), nel caso in cui il tempo di interarrivo al modulo diminuisca in media, e quindi sia necessario rimuovere il collo di bottiglia che eventualmente può manifestarsi su Presenta. Al contrario, può anche essere necessario diminuirlo, nel caso in cui il tempo d’interarrivo al modulo aumenti in media, e quindi Presenta sia inutilmente parallelo e sia necessario migliorarne l’efficienza relativa.
L’analisi dei parametri prestazionali (tempi d’interarrivo, di servizio, bande di elaborazione, etc…) può essere effettuato da un servizio adibito all’analisi delle prestazioni del modulo parallelo. Tale servizio può essere visto come un servizio esterno di contesto al manager, come lo sono le altre interfacce di contesto, servizi di sistema, servizi di Resource Discovery, etc…
A livello di implementazione può essere utile realizzare il servizio di monitoraggio delle prestazioni del PARMOD, come parte integrante dello stesso, come mostrato in figura 6.14. Per esempio può essere comodo considerare un servizio di monitoring del tempo d’interarrivo implementato nel processo Input Section Manager, ed interrogabile mediante apposita interfaccia non funzionale da parte dell’Adaptation Manager del PARMOD ASSISTANT:
6.3.2 Adattività globale dell’applicazione e cooperazione tra gli Adaptation Manager
In questo paragrafo cerchiamo di descrivere il processo complessivo di adattività dell’intera applicazione parallela. Ogni PARMOD dell’applicazione è un’entità indipendente, in grado mediante il proprio Adaptation Manager di riconfigurare le proprie funzioni e di modificare il proprio grado di parallelismo in relazione alle prestazioni e al modello dei costi utilizzato. Nel caso di applicazioni strutturate da più moduli, si rende necessaria la comunicazione tra manager, per realizzare politiche di adattività più complesse, che coinvolgano diversi moduli di elaborazione. Come abbiamo già descritto nel capitolo cinque, la comunicazione tra manager è richiesta in generale per due principali motivazioni:
1. Ogni manager è in grado di comunicare con un certo numero di servizi/interfacce di contesto, più o meno intelligenti. Le interfacce possono essere sensori, adattatori di sensori, servizi di scoperta delle risorse, servizi di monitoraggio delle prestazioni, etc… Può essere necessario, per un manager, acquisire informazioni che sono prodotte da servizi che non sono a lui direttamente connessi, ma che sono connessi ad altri manager (sia per motivi di locazione che per motivi di utilità). In questo caso è essenziale una rete di manager, e la loro comunicazione per la distribuzione del contesto (caso di contesto partizionato).
2. I manager sono in grado di comunicare tra di loro, per realizzare delle politiche di adattività coordinate tra i vari moduli dell’applicazione.
Principalmente in questo paragrafo ci occuperemo del secondo punto, ovvero di come le politiche di adattività possano effettivamente coordinare l’adattività di più PARMOD,
provocando riconfigurazioni globali. Il processo di adattività globale dell’applicazione può essere realizzato per due distinti fini:
1. per le prestazioni: le prestazioni dell’intera applicazione parallela, in termini di tempo di servizio totale e di banda d’elaborazione, dipendono dai tempi di servizio di tutti i singoli moduli dell’applicazione stessa.
2. per le funzioni: le situazioni ambientali in cui si trovano i processi di un PARMOD, possono richiedere riconfigurazioni delle funzioni che coinvolgono più moduli dell’applicazione parallela.
Per quanto riguarda le prestazioni, il processo di adattività dei manager si limita a modificare il grado di parallelismo dei moduli paralleli, utilizzando un noto modello dei costi, con il fine di massimizzare banda ed efficienza relativa dell’applicazione, rimuovendo là dove sia possibile i colli di bottiglia. Questo processo viene eseguito in parte localmente ai moduli e ai loro manager, come mostrato in figura 6.15:
Figura 6.15: Verifica delle performance locali di un modulo parallelo.
Ovvero, se il modulo parallelo M è un collo di bottiglia (Ts > Ta), il suo Adaptation Manager, in base al valore del tempo medio d’interarrivo al PARMOD (Ta), può incrementare il grado di parallelismo e quindi ridurre il tempo medio di servizio del modulo parallelo (Ts), nel caso in cui i nodi a disposizione e la forma di parallelizzazione lo consenta. Questo processo modifica il tempo d’interpartenza del PARMOD (Tp), e può comportare riconfigurazioni simili del grado di parallelismo dei moduli a cui sono destinati gli stream di output di M, in quanto viene modificato il loro tempo medio d’interarrivo. Il manager può inoltre ridurre il grado di parallelismo, nel caso in cui il tempo d’interarrivo (Ta) risulti superiore al tempo di servizio attuale (Ts) del modulo parallelo, rendendo Ts tanto più uguale a Ta se possibile, migliorando così l’efficienza relativa.
Figura 6.16: Comunicazione tra manager per adattare i gradi di parallelismo.
Supponiamo che M2 sia un collo di bottiglia, quindi vale la relazione che il suo tempo medio di servizio è maggiore del suo tempo medio d’interarrivo (Ts2 > Ta2), e supponiamo che non sia possibile parallelizzare ulteriormente M2 (per esempio per insufficienza di nodi di elaborazione). In questo caso, il manager di M2 può indicare al manager di M1 di ridurre appropriatamente il suo tempo di servizio (Ts1) e quindi di interpartenza Tp1. Ovviamente queste operazioni compiute tra manager necessitano che sia noto il modello dei costi, per eseguire le riconfigurazioni del grado di parallelismo. Il caso particolare dell’applicazione di esempio è riportato nella figura 6.17:
Figura 6.17: Adattività delle performance tra manager.
Supponiamo che il modulo Presenta sia l’unico collo di bottiglia (Ts−pres>Tp elab− ) dell’intera applicazione, e non sia possibile parallelizzarlo ulteriormente. In questo caso il manager di Presenta può comunicare con il manager di Elabora per chiedergli (se questo non è collo di bottiglia ovvero se Ts elab− <Ta elab− ) di ridurre il suo grado di parallelismo, al fine di migliorare l’efficienza relativa complessiva dell’applicazione di esempio. Interessante, invece, è il processo di comunicazione tra manager per l’adattività globale delle funzioni. Nel nostro particolare caso, il fattore discriminante per la scelta della forma implementativa è la disponibilità di memoria
principale dei nodi d’elaborazione su cui vengono eseguiti i processi VPM del PARMOD. Si tratta comunque di una caso specifico, in generale l’evento che determina la preferenza di una implementazione alternativa rispetto ad un’altra può essere un evento di contesto di natura anche differente, e non sempre connesso alla memoria.
Nell’applicazione di esempio, di norma viene preferita la forma task-parallel, mentre in situazioni di emergenza, in cui il PARMOD deve essere eseguito su piccoli nodi pervasivi, il manager può scegliere una forma data-parallel, che riduce la richiesta di memoria principale dei processi VPM. Possiamo immaginare che i moduli Elabora e Presenta, mediante i loro manager, siano in grado ulteriormente d’interagire con i moduli che producono i tre stream di input (A, B e D), per modificare dinamicamente la dimensione dei vettori di input. Consideriamo per semplicità di individuare tre valori possibili della dimensione degli input prodotti dai moduli Genera_*:
{
1, 2, 3}
N = N N N N1≪ N2≪ N3
Possiamo definire un altro evento contestuale che interessa la politica di adattività dei moduli Elabora e Presenta, e che indica la presenza di un evento in cui tutti i nodi di elaborazione disponibili hanno una capacità di memoria insufficiente per l’elaborazione, sia nel caso task-parallel che data-parallel. La politica di adattività locale dei moduli può essere estesa in modo informale come segue in figura 6.18 :
Figura 6.18: Estensione delle politiche di adattività di Elabora e Presenta.
Nell’esempio indicato sopra, viene definito un nuovo evento contestuale che prende nome di high_emergency_situation. Il verificarsi dell’evento, indica che tutti i nodi d’elaborazione disponibili sulla Pervasive Grid, per l’esecuzione dei processi di un PARMOD, sono nodi con una capacità di memoria principale insufficiente per l’elaborazione, sia della modalità task-parallel che data-parallel, con il dimensionamento corrente dei dati di input (parametro N). La funzione minimumSpace, determina la quantità minima di memoria principale necessaria all’esecuzione, efficiente, del processo VPM, in relazione al parametro N attuale. In questo caso la presenza dell’evento ambientale può richiedere che venga riconfigurata completamente l’applicazione. Può essere richiesto di modificare la dimensione degli stream A, B e D e di conseguenza degli stream C e E. Le richieste richiedono la comunicazione tra i manager dei moduli, come indicato nelle politiche di adattività.
Per esempio, se viene rilevato che nessun nodo d’elaborazione su cui possono essere eseguiti i processi VPM di Presenta, ha capacità di memoria sufficienti all’esecuzione dei processi del modulo, in questo caso l’Adaptation Manager di Presenta richiede a tutti gli altri moduli dell’applicazione di riconfigurarsi, per utilizzare una dimensione dei dati di input inferiore. Ovviamente la modifica della dimensione dei dati porta gli Adaptation Manager dei moduli ad eseguire operazioni di riconfigurazione, tra cui:
1. Il numero di processori virtuali.
2. Le politiche di distribuzione, che hanno a che fare con una dimensione dei dati di input diversa e una distribuzione verso un diverso numero di VP.
3. Le politiche di collezione che hanno a che fare con una dimensione dei dati di output diversa, e da un diverso numero di VP.
4. In presenza di stato partizionato, nel caso di implementazione data-parallel, il vettore S distribuito tra i VP deve avere una dimensione diversa e distribuito verso un numero di VP differente.
Queste sono le riconfigurazioni che devono essere eseguite da ogni manager dei moduli dell’applicazione. Al termine dell’intero processo globale di adattività, l’applicazione deve riprendere a funzionare, con il valore alternativo della dimensione degli input N.
6.4 Sperimentazioni ed emulazioni del modello ASSISTANT
Nella parte restante del capitolo analizzeremo le sperimentazioni del modello ASSISTANT, che sono state compiute durante la tesi. Le prove e le valutazioni sono state effettuate utilizzando la versione attuale di ASSIST (1.3), con l’obiettivo di emulare alcuni dei meccanismi di adattività descritti nella tesi. L’implementazione completa del modello ASSISTANT richiederebbe una reingegnerizzazione completa di ASSIST e della libreria ASSISTLIB che ne rappresenta il cuore del supporto. I test eseguiti, invece, cercano di emulare alcuni comportamenti di adattività, utilizzando gli strumenti e i limiti della versione attuale, in modo da avere dei prototipi a breve termine che ci consentano di poter determinare l’utilità e l’applicabilità del modello proposto.
6.4.1 Prima emulazione di ASSISTANT sull’applicazione parallela di questo capitolo
Una prima realizzazione del PARMOD ASSISTANT è stata fornita utilizzando gli strumenti e i meccanismi messi a disposizione con la versione attuale di ASSIST, in modo da avere un prototipo funzionante nel breve termine, che faccia alcune delle operazioni del manager individuate nel quinto capitolo. Questo primo test propone delle limitazioni importanti, che verranno analizzate nel seguito.
La prima implementazione del modulo adattivo è descritta nella figura 6.19 seguente:
L’emulazione del PARMOD ASSISTANT consiste in tre classi di moduli ASSIST standard, che realizzano alcune parti delle funzionalità descritte nel capitolo quinto:
1. Switcher: è un PARMOD ONE che si occupa di realizzare parte delle funzionalità dell’ISM del PARMOD ASSISTANT e dell’Adaptation Manager.
2. Un insieme di PARMOD (one e/o paralleli) che realizzano le alternative funzionali del PARMOD ASSISTANT. Solo un’alternativa è utilizzata in un certo istante, quella correntemente attivata dallo Switcher.
3. Raccoglitore: un PARMOD ONE eventualmente presente, per raccogliere i dati ricevuti dal PARMOD che in quel momento esegue il calcolo, ed inviare i risultati sugli stream di output del modulo ASSISTANT.
In questa implementazione, gli stream di ingresso e di uscita del modulo ASSISTANT sono rispettivamente gli stream di ingresso allo Switcher e di uscita dal Raccoglitore. Le funzionalità del modulo Switcher sono particolarmente critiche e possono essere così riassunte:
1. Il modulo riceve i dati dagli stream di input e provvede a trasmetterli al PARMOD responsabile della loro elaborazione. Tra i PARMOD presenti, i dati vengono trasmessi ad uno solo di questi, ovvero il modulo che in quel momento realizza l’alternativa funzionale attiva.
2. Il modulo Switcher riceve degli eventi esterni di contesto, e mediante questi decide di modificare l’attuale alternativa funzionale utilizzata per l’elaborazione. Il modulo è infatti responsabile di inoltrare i dati di input al PARMOD, che correntemente realizza le funzionalità. A seguito di un evento, lo Switcher può decidere di inoltrare gli input a un diverso PARMOD, per realizzare un’implementazione differente delle operazioni offerte dal modulo adattivo.
Per capire meglio, riprendiamo l’esempio dell’applicazione parallela adattiva esposto in questo capitolo. Come abbiamo visto, i moduli Elabora e Presenta prevedono due alternative funzionali, una task-parallel (FARM) e una data-parallel (MAP). Nel caso del
modulo Elabora (per il modulo Presenta le considerazioni sono speculari), questo è strutturato in un PARMOD ONE (lo Switcher), che realizza parte delle funzionalità dell’Adaptation Manager del modulo ASSISTANT, e in due PARMOD che realizzano rispettivamente l’implementazione task-parallel e data-parallel, per la produzione dei vettori C. Il modulo Switcher riceve gli elementi dagli stream A e B, e decide in base all’implementazione correntemente attiva se inoltrarli al PARMOD farm o al PARMOD map. I due PARMOD hanno la stessa interfaccia, sia di ingresso che di uscita, in questo caso cioè entrambe le implementazioni necessitano di due stream di ingresso, con tipo array di N interi, e producono uno stream di uscita, di tipo array di N interi. Per gli output non è necessario, in questo caso, eseguire delle post-elaborazioni, per cui non è presente il modulo Raccogli.
Lo Switcher riceve inoltre uno stream di eventi da interfacce di contesto esterne. Nel test eseguito, le funzionalità dell’Adaptation Manager per la gestione dei dati di contesto sono state ridotte all’osso, e vengono simulate con la ricezione periodica di un evento, implementato come uno stream di valori interi, dove viene associato al valore 0 il significato di eseguire la modalità farm e al valore 1 il significato di eseguire la modalità map. Quindi, una volta ricevuto il valore 0, lo Switcher inoltra gli array A e B di input al PARMOD farm, finché non riceve un valore 1 dallo stream degli eventi, in questo caso inizia ad inoltrare gli array di input al PARMOD map e viceversa. Il valore numerico ricevuto può essere interpretato come la necessità di migrare i processi VPM del modulo su piccoli nodi mobili. Questo può comportare, tra gli altri aspetti, la necessità di utilizzare un’implementazione dei moduli che richieda una minore occupazione di memoria principale, come un’implementazione data-parallel, in cui le strutture dati sono partizionate tra diversi nodi di elaborazione e non replicate, come nel caso task-parallel. In termini dell’emulazione proposta i due moduli sono descritti in figura 6.20:
Figura 6.20: Prima emulazione dei PARMOD ASSISTANT Elabora e Presenta.
La figura 6.21 riassume invece l’architettura complessiva dell’applicazione parallela:
Figura 6.21: Architettura complessiva della prima emulazione.
Nella figura emerge come i PARMOD ASSISTANT Elabora e Presenta siano stati emulati come indicato nella figura 6.20, inoltre sono presenti i seguenti moduli sequenziali aggiuntivi:
1. Modulo Stampa: PARMOD ONE che scrive le matrici E ricevute da Presenta su un file “FileMatrici.txt,” di output dell’applicazione.
2. Moduli EnvController1 e EnvController2: moduli sequenziali puri, che producono ciascuno uno stream di interi, corrispondenti agli eventi per modificare il comportamento di Elabora e Presenta, dalla modalità farm alla modalità map e viceversa. In pratica questi moduli emulano le interfacce di contesto.
Il codice ASSIST di quest’implementazione è descritto in modo completo nell’Appendice A della tesi. Questa prima emulazione ha i seguenti limiti:
1. Le alternative funzionali devono essere previste tutte staticamente a tempo di compilazione. Ogni alternativa funzionale è un PARMOD ASSIST standard, collegato al modulo Switcher.
2. Tutti i PARMOD che realizzano le diverse alternative devono avere le stesse interfacce di input/output, ovvero lo stesso tipo/numero di stream di input e output.
3. Essendo ogni alternativa funzionale un PARMOD ASSIST a sé stante, questo comporta un elevato numero di processi sempre attivi, anche se una sola alternativa funzionale è utilizzata in un certo arco di tempo.
4. Lo switcher necessita di un numero di stream in uscita pari al numero di stream di input al PARMOD ASSISTANT, per il numero di alternative funzionali staticamente individuate.
5. Il manager è emulato da un PARMOD ONE che effettua lo “switching” dei dati di input ricevuti, inviandoli al giusto PARMOD che implementa l’attuale alternativa funzionale attiva. In modo particolare lo Switcher esegue sia compiti propri del manager, come scegliere la forma di parallelismo, ma anche distribuire i dati ai processori virtuali che fanno il calcolo.
6. L’emulazione del manager è un modulo ASSIST visibile allo stesso livello degli altri moduli dell’applicazione parallela, e direttamente programmato dall’utente, come per il resto dell’applicazione. In futuro, l’obiettivo sarà quello di poter definire un PARMOD ASSISTANT con una sintassi specifica, che consenta di definire le alternative funzionali e le politiche di adattività, e che nasconda nel supporto di ASSISTANT, invisibile all’utente, come avviene il meccanismo di “switching” tra le diverse implementazioni.
7. Le alternative funzionali devono operare su uno stato diverso o comunque replicato su di esse. Lo stato associato ad un’alternativa funzionale non può essere utilizzato
nell’altra alternativa, a meno che non si preveda meccanismi specifici, come l’utilizzo di una memoria comune condivisa tra i PARMOD (non necessaria nell’emulazione dell’applicazione, dove le alternative non necessitano di stato comune), oppure tecniche di checkpoint dello stato, da cui sia possibile ripristinare la computazione indipendentemente dall’implementazione utilizzata.
8. In quest’emulazione, le politiche di adattività dei manager di Elabora e Presenta sono implementate staticamente nel codice del modulo Switcher. Riferendoci allo peseudo-codice con cui abbiamo definito le politiche nei capitoli precedenti, abbiamo le seguenti regole:
NEW EVENT Necessità_Esecuzione_Farm
CONDITION “ricevo da EnvController1 un segnale di valore 0”; NEW EVENT Necessità_Esecuzione_Map
CONDITION “ricevo da EnvController1 un segnale di valore 1”; ON Necessità_Esecuzione_Farm
DO BEHAVIOUR “utilizza l’alternativa funzionale Elabora_Farm”; ON Necessità_Esecuzione_Map
DO BEHAVIOUR “utilizza l’alternativa funzionale Elabora_Map”;
Non è prevista nell’emulazione la possibilità di modificare a tempo d’esecuzione le politiche di adattività, che sono “cablate” nel codice sequenziale dei moduli Switcher, sia di Elabora che di Presenta.
Quindi la riconfigurazione delle funzioni viene emulata “giocando” sugli stream di uscita del modulo Switcher, come mostrato in figura 6.22 nel caso del modulo Elabora.
Figura 6.22: Implementazione mediante stream multipli delle riconfigurazioni delle funzioni del modulo Elabora.
dove il “routing” degli input sugli stream A1 e B1 attiva l’elaborazione farm, mentre su A2 e B2 quella map. Per quanto riguarda le riconfigurazioni delle prestazioni, invece, il
PARMOD ASSISTANT deve avere la capacità di modificare il numero e il mapping dei processi VPM. Questo viene emulato mediante l’utilizzo dei meccanismi di riconfigurazione dinamica, che sono stati descritti nel paragrafo 5.2 del quinto capitolo.
ASSIST già possiede la possibilità di effettuare delle riconfigurazioni dinamiche, in realtà limitate alla sola modifica del numero di VPM. Questa limitazione ha suggerito la necessità di modificare il modello di programmazione, in modo da prevedere meccanismi di adattività più complessi, che non interessino solo il grado di parallelismo, ma anche la dipendenza dal contesto ambientale (Context Awareness). Nell’emulazione, comunque, i meccanismi di variazione dei VPM già implementati sono utilizzati direttamente dal modulo Switcher, che emulando il manager del PARMOD ASSISTANT deve avere, non solo la possibilità di modificare l’implementazione utilizzata, ma di modificare dinamicamente il grado di parallelismo.
I meccanismi per la riconfigurazione del numero di VPM prevedono la presenza di una entità che coordina l’intera applicazione (Application Manager), a cui può essere richiesto, mediante uno specifico protocollo, di eseguire operazioni di aggiunta, rimozione e migrazione dei processi VPM (vedi paragrafo 5.2) dei moduli paralleli. L’interazione con quest’entità avviene mediante l’utilizzo di un programma DCClient, che consente all’utente, da riga di comando, di richiedere la modifica del grado di parallelismo di un PARMOD dell’applicazione.
Figura 6.23: Prima emulazione dell’applicazione con realizzazione sia delle riconfigurazioni delle funzioni che delle performance.
Nel caso del modello ASSISTANT, invece, è l’Adaptation Manager di ogni singolo PARMOD che è in grado di modificare il grado di parallelismo del proprio modulo, in base ai dati sul monitoring delle prestazioni ed utilizzando un noto modello dei costi. L’emulazione in questo senso consiste nel consentire al modulo Switcher di agire da DCClient, interagendo con il gestore della dinamicità di ASSIST per modificare il numero di VPM dei PARMOD dell’applicazione.
La prima emulazione è stata eseguita sul cluster “Pianosa”, presso il Dipartimento di Informatica dell’Università di Pisa, un cluster di 34 workstation Pentium III a 800 Mhz con 1 GB di RAM, su cui sono stati eseguiti i processi dell’applicazione con la struttura indicata in figura 6.23. Il test consiste nell’esecuzione dell’applicazione, con dimensione dei vettori N pari a 5000 interi, in modo che la matrice E assuma l’occupazione in memoria virtuale di circa 95 MB. La grana del calcolo dei processi viene simulata mediante l’esecuzione di procedure di attesa (sleep(2)). I processi sono eseguiti, ciascuno
su un nodo diverso del cluster, caricando l’intera loro memoria virtuale sulla memoria principale fisica del nodo dove sono stati assegnati. Utilizzando per le prove un’architettura distribuita, in cui ciascun nodo d’elaborazione ha la sua memoria principale privata rispetto alle altre, le considerazioni che sono state fatte sull’occupazione di memoria, tra le implementazioni farm e map, rimangono valide in questo contesto.
L’esecuzione inizia con Elabora e Presenta eseguiti nella modalità di default, ovvero task-parallel e ciascuno con cinque processi VPM attivi. Durante l’elaborazione viene simulato l’evento di migrazione dei processi VPM di Presenta, su nodi d’elaborazione mobili e pervasivi, con una disponibilità limitata sia di memoria principale, che di dispositivi di memorizzazione di massa per la memoria virtuale (come per esempio accade per un PDA), che determina la necessità di modificare l’implementazione del PARMOD da farm a map. Alla ricezione di tale evento, i processi VPM vengono migrati su altri nodi (nella simulazione comunque nodi del cluster), e viene modificata la forma d’implementazione utilizzata passando alla map. Successivamente, viene simulato un ulteriore evento, che determina la necessità di modificare il grado di parallelismo del modulo Presenta, passando da cinque VPM a dieci VPM. Questo può essere necessario, sia per aumentare il tempo di servizio di Presenta, sia per limitare ulteriormente la dimensione della memoria virtuale dei suoi processi, in quanto la matrice E e gli altri dati vengono suddivisi tra un maggior numero di processi, che eseguono l’elaborazione.
La figura 6.24 mostra la dimensione della memoria virtuale dei processi VPM di Presenta, con le diverse alternative funzionali e il diverso grado di parallelismo:
Figura 6.24: Dimensionamento della memoria virtuale dei processi VPM del PARMOD Presenta.
Nel caso di Presenta, in modalità farm ogni VP opera su N2+2Nvalori interi. Essendo la versione farm un PARMOD con topologia none, il mapping tra VP e processi VPM è eseguito uno ad uno, di conseguenza ogni VPM esegue il codice di un solo processore virtuale. Il dimensionamento della memoria virtuale con 5000 interi e poco superiore ai 100 MB per processo. Nel caso map invece, ognuno degli N VP calcola una riga della matrice finale, e opera su 2N +1 valori interi. L’assegnamento dei VP ai processi VPM viene fatto equamente, da parte del supporto di ASSIST, in questo modo ogni VPM opera
su
(
2N 1)
N K+ interi, dove K indica il numero di processi VPM attualmente impiegato. Questi valori teorici sono stati riscontrati sperimentalmente con i risultati del test, mostrati in figura 6.24.
Nella figura 6.25 vengono mostrati i risultati dello stesso test, in relazione al tempo medio di servizio del modulo Presenta, che rappresenta il collo di bottiglia dell’intera applicazione. Il tempo medio d’elaborazione di una intera matrice è stato simulato mediante l’esecuzione di una sleep, con tempo di attesa di 120 secondi. In questo modo
l’esecuzione della scatter (in questo caso implementata linearmente), è del tutto trascurabile.
Figura 6.25: Tempo di servizio medio di Presenta durante il primo test eseguito.
La prima rilevazione mostra il riferimento del caso di un solo processo VPM, che comporta un tempo di servizio medio di 129.64 secondi, ovvero il tempo medio di calcolo di una matrice E, più il tempo necessario alla trasmissione della stessa (95 MB), su una rete con banda di 100 Mb/s (rete d’interconnessione ethernet del cluster Pianosa). Praticamente nell’architettura utilizzata per i test, gran parte della tempo di comunicazione non viene sovrapposto al calcolo. Supponiamo poi che venga impostato un contratto di QoS, che imponga all’Adaptation Manager di Presenta di dimensionare il tempo di servizio, in modo che non superi 30 secondi a matrice. Con la conoscenza del modello dei costi, il manager aumenta il grado di parallelismo (esempio cinque VPM), in modo da raggiungere un tempo di servizio medio conforme al contratto, di 26.68 secondi. Successivamente viene simulato l’evento d’emergenza, che comporta la riconfigurazione delle funzioni passando alla map con cinque VPM. In questo caso il manager verifica che il nuovo tempo di servizio medio di 49.08 secondi, deve essere ridimensionato per rispettare il contratto, aumentando il grado di parallelismo. Nel caso di dieci VPM, il tempo di servizio assume il valore medio di 29.42 secondi, conforme nuovamente al contratto di QoS.
6.4.2 Seconda emulazione di ASSISTANT sull’applicazione parallela di questo capitolo
La seconda emulazione dell’applicazione ASSISTANT rappresenta un’evoluzione del modo di procedere precedente, che maggiormente si avvicina al modello di adattività esposto nel quinto capitolo. La figura 6.25 descrive la struttura della seconda emulazione dei moduli paralleli Elabora e Presenta:
Figura 6.26: Seconda emulazione dei PARMOD ASSISTANT Elabora e Presenta.
L’emulazione sfrutta la generalità del costrutto PARMOD di ASSIST, per poter realizzare un modulo parallelo con due distinte modalità di attivazione, una task-parallel e l’altra data-parallel. Le implementazioni alternative sono sempre attivate dallo Switcher, in relazione agli stream su cui il PARMOD riceve i dati di input. Nel caso di Elabora, se gli input vengono ricevuti sugli stream A1 e B1, i processori virtuali elaborano i risultati in modo farm, altrimenti se riceve su A2 e B2, gli stessi VP elaborano in modalità map. Tutto questo è possibile sfruttando il fatto che in ASSIST è possibile associare politiche di distribuzione diverse in base agli stream su cui si riceve, e di conseguenza far eseguire così agli stessi VP, codice diverso, in base alla guardia che è stata attivata nella distribuzione.
La figura 6.26 mostra il codice di questa emulazione del PARMOD Elabora (per Presenta l’implementazione è del tutto riconducibile). Dal codice si evince come siano
presenti due modalità di distribuzione dei vettori A e B, in relazione al fatto che si riceva dagli stream A1 e B1 o da A2 B2. Inoltre, a seconda che venga attivata la prima o la seconda guardia, i VP eseguono due distinte funzioni sequenziali, CalcoloVettore nel caso farm e CalcoloElementoVettore nella map. Per quanto riguarda la politica di collezione dell’OSM, abbiamo due tipi di collezioni, una nel caso si riceva da uno stream interno “ris”, su cui i processori virtuali in modalità map scrivono gli elementi calcolati del vettore C, oppure semplicemente collezionare il vettore C calcolato, ed inviarlo sullo stream di output nel caso farm.
Figura 6.27: Codice ASSIST della seconda emulazione del PARMOD Elabora.
La seguente emulazione, rispetto alla precedente, è certamente più affine al modello originale ASSISTANT di PARMOD adattivo, in quanto ha le seguenti caratteristiche:
1. Esistono due unici PARMOD ASSIST nell’applicazione, uno per Elabora e uno per Presenta, di conseguenza non abbiamo una replicazione di processi VPM per le diverse alternative funzionali. I VP dei processi VPM sono in grado, a tempo d’esecuzione, di alternarsi dalla forma map alla forma farm e viceversa, come previsto nel modello ASSISTANT originale, descritto nel quinto capitolo.
2. Essendo sia Elabora che Presenta formati ciascuno da un unico PARMOD, nel caso ci sia la necessità di mantenere uno stato nel passaggio da un’alternativa funzionale ad un’altra, questo sarebbe molto più semplice da realizzare che nell’emulazione precedente, senza ricorrere per questo scopo a meccanismi come la memoria condivisa tra PARMOD o tecniche di checkpointing dello stato, ma utilizzando gli attributi all’interno del modulo parallelo secondo una logica consistente.
La seconda emulazione consente, quindi, una maggiore “vicinanza” al modello finale, ma ancora con le limitazioni imposte dall’attuale supporto di ASSIST:
1. Le diverse distribuzioni sono associate a diversi stream da cui si riceve. Questa soluzione è valida solo nel caso di poche alternative funzionali e quando queste sono tutte note staticamente. Nel modello ASSISTANT finale, il manager deve modificare a tempo d’esecuzione il codice eseguito dall’ISM per le distribuzioni, in base alle regole di politica e al tipo di implementazione da attivare.
2. Stessi aspetti del primo punto riferiti alle modalità di collezione dell’OSM.
3. Nell’emulazione le alternative sono sempre definite staticamente. Non è possibile con l’attuale supporto prevedere a tempo d’esecuzione la possibilità di adottare implementazioni nuove (mediante plug-in) e quindi nuove funzioni sequenziali da far eseguire ai processori virtuali.
Anche in questa seconda emulazione, il modulo Switcher sia di Elabora che di Presenta, emulando le funzionalità dell’Adaptation Manager ASSISTANT, ha la possibilità di modificare il grado di parallelismo del modulo parallelo, interagendo mediante DCClient con il manager dell’applicazione (vedi riconfigurazione dinamica in ASSIST paragrafo 5.2). Il codice della seconda emulazione è riportato nell’appendice B della tesi, mentre i risultati dei test sono presentati in figura 6.28.
Figura 6.28: Tempo di servizio medio di Presenta durante il secondo test eseguito.
Il test analizza il solo modulo Presenta, che rappresenta il fattore determinante per le prestazioni dell’intera applicazione. Nella prova, Presenta viene inizialmente eseguito con modalità farm con cinque processi VPM. In questo caso il tempo di servizio medio è circa 26.68 secondi per matrice. A seguito di una riconfigurazione delle funzioni, resa necessaria da un cambiamento del contesto, viene simulato il mapping dei VPM su nodi mobili (nell’emulazione comunque nodi del cluster), e viene modificata la forma di parallelismo passando ad una map, mantenendo lo stesso grado di parallelismo. In questo caso il tempo medio di servizio di Presenta viene valutato sui 48.91 secondi a matrice, e rende necessario, per mantenere il contratto di QoS precedentemente stabilito, di aumentare il grado di parallelismo, passando per esempio a dieci VPM. In questo modo il tempo di servizio medio assume il valore di circa 29.47 secondi, nuovamente conforme al contratto di performance stabilito. Si può notare, inoltre, come a parità di numero di VPM e di tipologia di implementazione utilizzata (farm o map), i moduli nelle due distinte emulazioni abbiano un tempo di servizio medio estremamente simile.