CAPITOLO 1
INTRODUZIONE
In questo primo capitolo introduttivo presenteremo le tecnologie
utilizzate nel corso del lavoro di tesi. Si parlerà del contesto evolutivo, dal punto di vista socio-economico, che ha caratterizzato quest’ultimo decennio, e delle principali tecniche di analisi dei dati.
1.1- Business Intelligence
Nel mondo degli affari l’intelligenza sicuramente rimane un prerequisito fondamentale per il successo, ma nell’attuale contesto socio-economico non c’è più spazio per le antiche figure dei dirigenti aziendali che
verificavano personalmente i dati fondamentali e basavano il futuro solo sulle cifre del bilancio. L’impresa ha bisogno di un supporto informatico affinché posso prendere le decisioni migliori più in fretta, prima della concorrenza. Un aiuto, in questo senso, può essere dato dall’introduzione dell’intelligence.
L’intelligence è lo strumento in grado di produrre informazione utile, a partire dalla quale l’uomo potrà produrre conoscenza utilizzabile per lo sviluppo dell’azienda.
Se volessimo definire in modo preciso la Business Intelligence
potremmo considerarla come un insieme di modelli, metodi e strumenti in grado di raccogliere sistematicamente il patrimonio di dati prodotti pressoché quotidianamente dall’azienda, e aggregarli ed analizzarli, al fine di produrre informazione presentabile in forma semplice. Ovvero partire dai dati e dal loro significato nascosto e produrre informazione
utile e sfruttabile da tutti. Come notiamo facilmente, la chiave di tutto è il dato: sfruttato all’apparenza, viene memorizzato in grandi strutture dati (database, datawarehouse), ma nasconde ancora un enorme
potenziale. L’idea che è alla base della BI è quella di far esprimere ai dati un nuovo patrimonio informativo; gli sviluppatori di tale tecnologia amano prendere come riferimento a questo concetto una frase di
Voltaire, che sembra molto adeguata ad esprimere in maniera concisa la definizione di Business Intelligence, e che citiamo: “il vero viaggio di scoperta non consiste nel cercare nuove terre, ma nell’avere nuovi occhi”.
Ad esempio, l’analisi dello storico di un azienda porta ad osservare particolari relazioni logiche e matematiche tra alcuni dati, e osservando il presente è possibile cogliere analogie, che ci possono portare a
prevedere atteggiamenti futuri.
In termini aziendali, la Business Intelligence è vista come uno
strumento per trarre vantaggio competitivo a costi moderati, poiché generalmente i dati che vengono sfruttati vengono raccolti per scopi interni, e quindi non vi è costo aggiuntivo per la loro acquisizione. Ogni sistema di business intelligence ha un obiettivo preciso che deriva dalla “mission” e dagli obiettivi della gestione strategica di un'azienda.
Nella letteratura, la Business Intelligence viene considerata come il processo di trasformazione dei dati e delle informazioni in conoscenza, per tanto ci si può riferire loro come strumenti di supporto alle
decisioni, e i dati vengono trasformati e memorizzati solitamente in datawarehouse.
In pratica, la Business Intelligence rappresenta la nuova frontiera della crescita organizzativa aziendale. Permette ai collaboratori di un’azienda di accedere ai dati, analizzarli e condividerli all’interno
dell’organizzazione con i dipendenti e all’esterno con i clienti, i fornitori e i partner. Mentre i sistemi gestionali, o operazionali, si occupano principalmente di inserire e aggiornare i dati, lo scopo della Business Intelligence è di estrarre da questa “materia prima” tutte le
informazioni più o meno nascoste. Più le aziende producono informazioni, tanto più hanno bisogno di presentarle in maniera armonica, al fine di supportare i processi decisionali. L’esigenza di Business Intelligence, che investe l’impresa nel suo complesso, è
solitamente indirizzata alle funzioni di marketing, alle analisi finanziare e a coloro che gestiscono il servizio ai clienti, e a tutte le persone che, sulla base dei risultati delle analisi dei dati, possono poi prendere importanti decisioni di business. Un moderno sistema di Business Intelligence deve quindi aiutare l’azienda sia nell’effettuare analisi e controllo del business, sia nel prendere decisioni. Pertanto le sue caratteristiche principali saranno:
• Selezione delle informazioni e dei dati rilevanti per la gestione del business;
• Classificazione dei clienti per meglio comprendere le loro esigenze, e definire il loro valore in base alla potenzialità d’acquisto ed al fatturato realizzato;
• Verifica dell’andamento delle vendite e calcolo della redditività per prodotto, per canale, per cliente;
• Individuazione delle cause primarie che determinano scostamenti del budget;
• Individuazione delle cause primarie che determinano la defezione, totale o parziale, da parte dei clienti dell’azienda;
• Calcolo del valore dell’azienda, non solo in termini economici, ma anche in termini di risorse umane e risorse clientelari;
• Supporto al processo decisionale consentendo l’analisi quantitativa e qualitativa di scenari alternativi.
L’ulteriore evoluzione di tali sistemi è costituita da modelli predittivi, in grado non solo di analizzare il presente, ma di orientarsi verso il futuro. L’analisi comportamentale dei dati, soprattutto temporali, costituirà la base della predizione del verificarsi di eventi futuri. La pianificazione strategica da parte dell’azienda dovrà avvalersi anche di tali strumenti, in modo da poter prevenire eventi sgraditi, o comunque analizzare le cause di tali comportamenti.
1.2 Il CRM
Il Customer Relationship Management nasce con l'obiettivo di aiutare le aziende nella fidelizzazione dei clienti, col fine di realizzare nuove opportunità intervenendo dove il cliente ha necessità prevedibile e soddisfabili.
Fidelizzare il cliente significa conoscerlo, capire e prevederne i bisogni, capirne i tempi e rispondere alle sue segnalazioni.
Un cliente avrà forti motivazioni per restare fedele, se ravvisa nel fornitore una significativa attenzione alla sua identità.
Il CRM è lo strumento che consente la gestione delle relazioni con i clienti, col fine di averne sempre presente la situazione, prevederne le necessità ed in definitiva mantenere viva nel cliente, l'attenzione per l'azienda.
Non esiste un'esatta ed unica definizione di CRM, lo si può comunque considerare come un insieme di procedure organizzative, strumenti, archivi, dati e modelli comportamentali creato in un'azienda per gestire le relazioni con il cliente, il cui obiettivo primario è quello di migliorare il rapporto cliente-fornitore.
Il CRM si articola comunemente in 3 tipologie:
1. CRM operativo: soluzioni metodologiche e tecnologiche per automatizzare i processi di business che prevedono il contatto diretto con il cliente.
2. CRM analitico: procedure e strumenti per migliorare la
conoscenza del cliente attraverso l'estrazione di dati dal CRM operativo, la loro analisi e lo studio revisionale sui comportamenti dei clienti stessi.
3. CRM collaborativo: metodologie e tecnologie integrate con gli strumenti di comunicazione (telefono, fax, e-mail, ecc.) per gestire il contatto con il cliente.
L'errore più comune in cui ci si imbatte quando si parla di Customer Relationship Management è quello di equiparare tale concetto a quello
di un software. Il CRM non è una semplice questione di marketing né di sistemi informatici, ma riguarda l'azienda e la sua visione nel
complesso; il CRM è un concetto strettamente legato alla strategia, alla comunicazione, all'integrazione tra i processi aziendali, alle persone ed alla cultura, che pone il cliente al centro dell'attenzione sia nel caso del business-to-business sia in quello del business-to-consumer.
Le applicazioni CRM servono a tenersi in contatto con la clientela, a inserire le loro informazioni nel database e a fornire loro modalità per interagire in modo che tali interazioni possano essere registrate e analizzate.
1.3- Knowledge Discovery: il ciclo della scoperta della conoscenza
Riuscire a conferire il massimo valore ai dati ed all’informazione che si possiede diventa una delle priorità nell’odierno contesto aziendale. L’obiettivo primario è quindi quello di dedicare maggiore attenzione agli strumenti e ai metodi che possono dare supporto alle decisionifondamentali per il raggiungimento di risultati strategici d’impresa. L’evoluzione tecnologica dell’ultimo decennio ha prodotto un contesto sociale ed economico in continua evoluzione. Nello specifico, le aziende si trovano ad affrontare uno scenario altamente competitivo, in un mercato sempre più dinamico. D’altra parte la crescita tecnologica permette anche di avere un enorme potenziale per fronteggiare il mercato: non stiamo parlando solo dei dati, che ora è possibile
memorizzare in quantità esorbitanti, ma anche di strumenti in grado di esplorarli, di portare alla luce l’informazione. Molte delle informazioni
essenziali sono davanti ai nostri occhi, intrappolate nei dati; per
liberarle, il dato deve essere organizzato e strutturato, collocato in uno specifico contesto e dotato di significato, affinché assuma un valore tale da offrire un vantaggio competitivo per l’azienda.
Ad esempio le aziende in passato hanno speso molto per cercare di individuare i clienti più opportuni cui rivolgere particolari offerte, ricorrendo a volte anche a tecniche banali e costosissime (come
rivolgere tali offerte a tutti i clienti di cui si possedevano informazioni). La tecnologia ora permette, attraverso l’utilizzo di potenti algoritmi, l’individuazione degli elementi che interessano all’interno delle basi di dati.
In letteratura questo concetto è espresso con il termine KD,
Knowledge Discovery, ossia scoperta della conoscenza. In realtà in letteratura si precisa che la Knowledge Discovery è una scoperta non guidata della conoscenza, precisando la caratteristica fondamentale di questo tipo di analisi: la mancanza di ipotesi. In questo modo è
possibile ottenere informazioni insperate, sebbene di indubbia utilità. L’analisi del dettaglio degli scontrini di un supermercato ha portato, ad esempio, alla conclusione che i consumatori di pannolini acquistano anche birra. L’utilizzo commerciale di questa informazione sarà poi compito del responsabile delle decisioni. Analogamente, l’utilizzo di Knowledge Discovery può essere rivolto all’analisi dello storico dei dati al fine di individuare implicazioni logiche tra i dati, e quindi la
individuare particolari periodicità che possono contribuire a dare maggior senso a determinati eventi, come il calo di vendite di un
prodotto in un determinato periodo dell’anno, o ancora determinare le caratteristiche di un cliente.
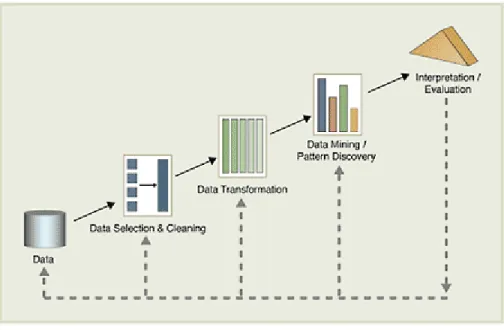
In figura è rappresentato l’intero processo di Knowledge Discovery
Figura 1 : il ciclo di KD
Osserviamo un po’ in dettaglio le fasi dell’intero processo.
In primo luogo avverrà una selezione dei dati di interesse: ci
focalizziamo solo su di un sottoinsieme di essi, che rappresentano i dati interessanti al nostro problema. Con tutta probabilità il database, o datawarehouse, conterrà diverse informazioni, che per il nostro caso di studio risulterebbero inutili; tanto vale scartali subito. Nel caso di una catena di ipermercati e supermercati, se il nostro interesse di analisi si concentra sull’analisi della defezione del cliente, saranno prese in
considerazione le tabelle relative ai clienti, ai prodotti e agli scontrini, ma sicuramente non ci serviranno quelle relative ai dipendenti o ai vari negozi della catena.
Una successiva fase di preprocessing servirà a mantenere in memoria solo una parte dei dati selezionati: infatti viene analizzato il contenuto delle tabelle selezionate, ponendo attenzione sulla popolazione dei diversi attributi. Si tratta di una fase importante di collaborazione tra programmatore e programmi: viene analizzata la ‘popolazione’ degli attributi delle tabelle selezionate. Alcuni attributi risulteranno essere inutili alla nostra analisi, o per il loro significato, o per i valori che
assumono. Infatti un attributo per lo più nullo (parliamo dell’ordine del 95%) difficilmente potrà essere utilizzato, come anche un attributo che assume lo stesso valore con percentuali altissime. Al termine di questa fase saranno stati prodotti dei riassunti cartacei con la specifica di ciascun attributo:sarà evidenziato, oltre al significato, anche la densità (percentuale di valori non nulli) e la popolazione (valori che l’attributo potrà assumere).
Il passo successivo prevede la trasformazione dei dati: si possono definire nuovi dati a partire da quelli già esistenti, mediante
aggregazioni o operazioni logiche e matematiche, oppure convertendo i tipi. Questa fase inoltre garantirà la consistenza dei dati che
provengono da fonti diverse. Alcuni dati andranno sicuramente bene così, altri invece, per avere significato nell’analisi, dovranno essere modificati, o, meglio, ne saranno creati degli altri a partire da quelli originali. Tecnicamente tutto ciò può avvenire mediante cambi di tipo, calcoli matematici e logici, aggregazioni su un valore. Ad esempio,
alcune date possono essere rappresentate come stringhe, o addirittura in formato differente a seconda delle fonti:può capitare che alcune tabelle le rappresentino in formato “julian”, altre in altro formato o addirittura in stringhe; per poterle confrontare fra loro sarebbe
opportuno perlomeno averle tutte in un formato standard. Altri attributi invece sono calcolati ex novo, partendo dal valore degli attributi
presenti: ad esempio la Coop definisce la fedeltà del cliente in base al numero di spese effettuate nell’arco di un periodo di tempo di quattro mesi, per tanto se vogliamo avere un attributo “fedeltà” bisognerà calcolarlo a partire dagli attributi che rivelano il numero di spese
effettuate e il periodo in questione. Infine, alcuni attributi necessitano di essere calcolati come aggregati di altri. Ad esempio, il database di UniCoop memorizza ogni singola riga di ogni singolo scontrino emesso, quindi per ricostruire l’importo di una spesa effettuata bisognerà
aggregare per numero cliente e data di emissione dello scontrino.
La fase di Data Mining vera e propria si trova a lavorare quindi su dati già abbastanza puliti e trasformati. Si tratta della fase principale di tutto il processo di Knowledge Discovery, soprattutto per il suo
risultato: infatti al termine di questa fase saranno prodotti i pattern, strumenti utilizzabili dall’utente finale.
Infine i risultati saranno interpretati e analizzati, al fine di valutare la qualità del processo. L’intero processo non è strettamente sequenziale, nel senso che spesso da un sotto-processo si ha la necessità di
1.4- Il Data Mining
Chiaramente la fase di Data Mining merita un discorso particolare, sia per la sua importanza, sia per la sua complicatezza. In questa fase l’intelligenza artificiale e il potere delle macchine devono riscontrare anche intuitività ed esperienza dello sviluppatore, al fine di non incombere troppe volte in falsi risultati.
Data mining, letteralmente, vuol dire estrazione di dati. Come in miniera, per portare alla luce l’informazione bisogna scavare, e il processo di data mining offre gli strumenti più adatti a questo genere di lavoro. In letteratura le definizioni che si trovano sono molteplici, di seguito se ne riporteranno solo alcune, per chiarire meglio il concetto a chi non ha coniato la sua personalissima definizione:
Il data mining è la non banale estrazione di informazione implicita, precedentemente sconosciuta e potenzialmente utile, attraverso l’utilizzo di differenti approcci tecnici (Matheus)
Il data mining consiste nell’uso di tecniche statistiche da utilizzare con i database aziendali per scoprire modelli e relazioni che possono essere impiegati in un contesto di business
Il data mining è una combinazioni di potenti tecniche che aiutano a ridurre i costi e i rischi come anche ad aumentare le entrare, estraendo informazione dai dati disponibili
Il concetto comune a queste ed altre definizioni, è che il data mining è un insieme di strumenti, tecniche, metodologie, con l’obiettivo
estrapolare informazione. È un processo di estrazione della
conoscenza. L’ambito di applicazione risulta così essere il più vario possibile, spostandoci anche dai settori puramente aziendali, potendo il data mining studiare le correlazioni tra dati anche in ambita medico, o biologico. Lo scopo finale del data mining è quello di fornire uno
strumento finale, utilizzabile da tutti. Per ottenere ciò è opportuno definire dipendenze logiche tra i dati. Nel caso di grandi aziende la quantità di dati a disposizione è enorme, per tanto può risultare semplice osservare particolari dipendenze fra i dati. Ad esempio, può risultare utile scoprire come il valore di un attributo dipenda dal valore di un altro. In alcuni casi si tratta di informazioni banali, ma a volte risultano vere anche alcune relazioni controintuitive. Chiaramente i risultati variano a seconda della soglia di precisione che voglio
ottenere, ad esempio potrei decidere di accettare anche relazioni valide non sempre, ma almeno nella maggior parte dei casi (scelgo ad
esempio una soglia del 70 %), potrei ottenere implicazioni sbagliate o casuali, anche se, lavorando su grandi data base, non dovrebbe
accadere. Ma l’aspetto più interessante è quello di considerare dati ricavati, a partire chiaramente da dati esistenti, modificati per assecondare le richieste dell’applicazione. Ad esempio si possono
considerare valori aggregati (sommatorie di valori relativi ad un singolo cliente), ma anche valori creati a partire da altri (banalmente, l’età a partire dalla data di nascita), o valori calcolati matematicamente (medie aritmetiche, ma anche identificatori di serie temporali). In questo caso sarebbe molto interessante scoprire, ad esempio, che un determinato trend di acquisti porti alla defezione di un cliente, oppure che un’età compresa tra i 40 e i 50 anni porti all’acquisto di beni più
costosi. L’obiettivo finale sarà quello di avere una tabella generale, ossia un insieme di attributi che definiscono l’oggetto dell’analisi, che viene chiamato in gergo “Tabellone”, altrimenti definito, più
tecnicamente, input dell’analisi. Nel caso dell’analisi dell’abbandono del cliente fatta per UniCoop, avremo un “Tabellone” di attributi che
definiscono il cliente: attributi già esistenti nel database originale, attributi calcolati, aggregati globali, parametri che definiscono serie temporali (nel nostro caso coefficienti di regressione lineare che identificano l’andamento temporale del numero di spese effettuate). Inoltre ci saranno uno o più attributi, le cosiddette variabili target, che identificheranno il comportamento futuro del cliente. Nel caso
dell’analisi dell’abbandono, tali variabili mi diranno se il cliente
continuerà nel prossimo futuro a fare la spesa presso la Coop oppure cesserà o diminuirà drasticamente la sua attività. L’obiettivo finale sarà quello di costruire un modello predittivo: infatti, dopo aver studiato le relazioni tra attributi del “tabellone” e le variabili target nello storico dei dati, queste ultime dovranno essere calcolate, con la maggiore accuratezza possibile, nel presente, al fine di prevedere
l’atteggiamento futuro del cliente.
1.4.1 Principali tecniche di Data Mining
Come abbiamo già accennato nei paragrafi precedenti, il Data Mining è un insieme di tecniche con l’obiettivo di estrarre le regolarità presenti nel database. Osserveremo ora quali sono le principali tecniche
1.4.2 Regole Associative
Prima di presentare questa tecnica sarà opportuno fare un breve discorso sulla terminologia utilizzata. Si definisce “item” un singolo elemento del database; una “transazione” è un insieme di item congiunti, ad esempio gli item acquistati insieme in un carrello della spesa. Una regola associativa si presenterà nella forma X => Y, con X e Y item; significa, cioè, che chi compra X comprerà anche Y. Ogni regola ha associata anche due valori che la qualificano: il “supporto” e la “confidenza”. Facciamo un esempio: sia D un insieme di transazioni, e {A,B,C},{A,C,D},{A,B,D,E} e {E,F} le sue transazioni. Sia A => B una regola associativa; se l’insieme di item {A,B} compare su 2 transazioni su 4. Il suo supporto rappresenta proprio questa percentuale, e sarà 2 su 4, ossia del 50%. Notiamo inoltre che A compare in 3 transazioni, mentre {A,B} solo in due. La confidenza misura su quante transazioni in cui compare A compaia anche B, e cioè 2 su 3, ossia il 66%. Se ad esempio volessimo calcolare supporto e confidenza della regola inversa, B => A, noteremo che tale regola ha supporto del 50% e confidenza del 100%.
1.4.3- Il Clustering
La tecnica del Clustering consiste nel determinare un partizionamento naturale di un insieme di dati in k cluster, insiemi che devono avere due caratteristiche fondamentali:
• Similitudine tra oggetti dello stesso cluster
Ovvero, l’obiettivo è massimizzare la similarità intra-cluster e minimizzare la similarità inter-cluster.
Tra gli algoritmi utilizzati per la clusterizzazione, uno dei più famosi in letteratura è l’algoritmo K-Means. Il suo funzionamento prevede
inizialmente la scelta del parametro K, ossia il numero di cluster
desiderati, da parte dell’utente. Successivamente l’algoritmo genera K centri casuali, e in base alla distanza tra gli elementi e i centri, questi ultimi vengono ricalcolati, fino ad ottenere la partizione desiderata. In questo modo non è detto che sia generata la configurazione ottima, ma tecniche di supporto sulla scelta iniziale dei centri e sulla ripetizione dell’algoritmo consentono di ottenere i risultati desidrati.
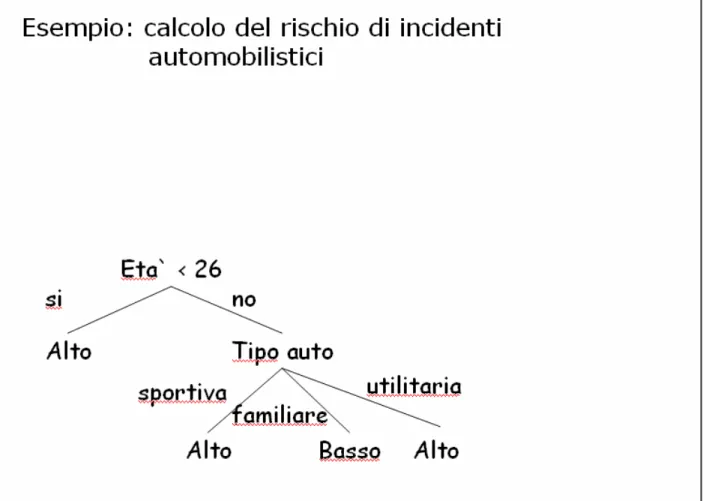
1.4.4- La Classificazione
Le classificazioni sono forse la più comune tecnica applicata ad analisi di Data Mining.
Questa tecnica prevede la costruzione di un modello descrivendo un insieme predeterminato di classi e concetti. Tale modello viene
“appreso” analizzando tuple e attributi di una parte del database, e viene espresso in forma di regole di classificazione e formule
matematiche. In sostanza, viene costruito in modello in grado di stabilire il valore, o l’intervallo di valori, che un attributo non noto dovrebbe avere.
l’albero di decisione, per i seguenti aspetti:
• L’estrazione di questi modelli è tipicamente più veloce rispetto gli altri metodi
• Il modello estratto è più facile da interpretare tramite le regole di classificazione
• I modelli in questione possono facilmente essere convertiti in interrogazioni SQL per interrogare la base di dati
Una volta che è stato sviluppato il modello, esso viene usato in modo predittivo per classificare dei nuovi record nelle stesse predefinite classi. Per esempio, un classificatore capace di identificare i rischi di prestito, può essere usato per aiutare nella decisione se concedere o meno un prestito ad un cliente. Di norma l’output predetto da un
classificatore è categorico, cioè può assumere pochi valori (“Si” o “No”, oppure “alto”, “medio” o “basso”).
Figura 2 : esempio di classificazione
Una volta realizzato un modello decisionale (ad esempio un albero decisionale) bisognerà valutare la sua bontà come modello predittivo, analizzando il suo funzionamento: per fare questo, prediremo dei valori che sono già in nostro possesso, in modo da poterne confrontare il
1.5- Il progetto “BICOOP”
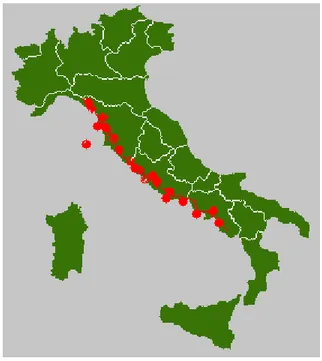
Il lavoro di tesi svolto fa parte di un più ampio progetto commissionato da Coop, o per la precisione da UniCoop Tirreno, che comprende molti negozi in buona parte della costa tirrenica.
Figura 3 : distribuzione dei negozi UniCoop Tirreno
Coop sta per Cooperativa di Consumatori.
L’intera “filosofia” Coop è regolata dai principi solidi delle cooperative: alla base dell’imprenditorialità ci sono i valori originari della
cooperazione, pertanto l’attenzione principale è volta verso le persone, i clienti, i loro bisogni, piuttosto che esclusivamente sul loro potere d’acquisto.
UniCoop Tirreno distingue le filiali in due grosse sottocategorie: avremo negozi di tipo Ipermercati e negozi di tipo Supermercati. La
differenza sostanziale consiste nell’immagazzinamento dei dati, che vanno a popolare, nella base di dati originale, tabelle differenti.
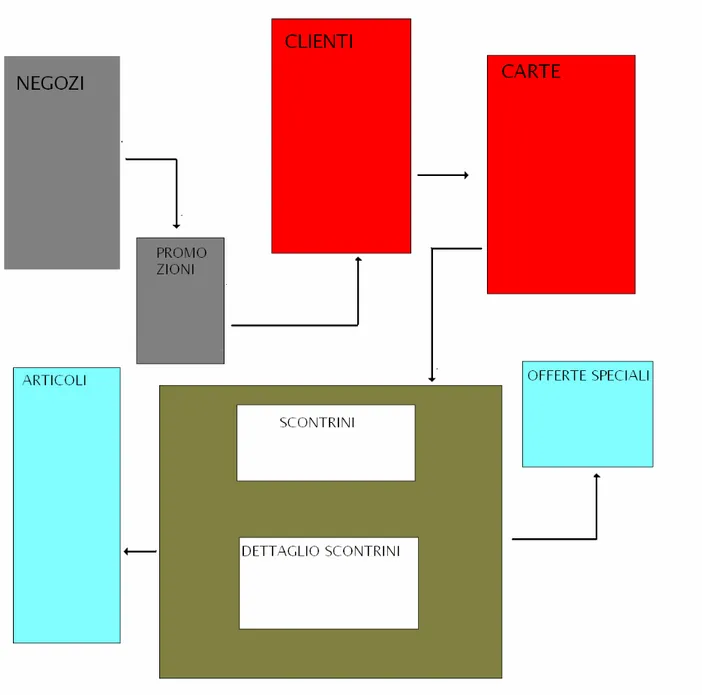
UniCoop Tirreno raccoglie i suoi dati in un database, il cui schema generico riportiamo nella figura seguente.
Figura 4 : schema riassuntivo del database UniCoop Tirreno
Alcune tabelle possiamo definirle atemporali,nel senso che raccolgono informazioni globali, che vengono aggiornate nel tempo. Nel dettaglio, queste sono:
• Tabella di descrizione dei negozi
• Tabella di descrizione dei movimenti delle promozioni e relativi dettagli.
• Tabella di descrizione (soprattutto anagrafica) dei clienti soci Coop.
• Tabella relativa ai soci prestatori
• Tabella delle professioni
• Tabella dei titoli di studio
• Tabella descrittiva delle carte socio
• Tabella relativa alle sole carte socio prestampate
• Tabella relativa alle sole carte socio nazionali
• Tabella contente le informazioni relative all’attivazione del salvatempo
• Tabella dei livelli bonus-malus relativi allo strumento salvatempo
• Tabelle di descrizione delle offerte speciali
• Tabelle di descrizione nel dettaglio delle promozioni
• Tabella degli articoli
• Tabella di descrizioni dettagliate relative agli articoli
• Tabelle di categorizzazione degli articoli, che sono divisi in settori, reparti, categorie e sottocategorie.
Possiamo altresì definire macro categorie che definiscono i settori di appartenenza delle suddette tabelle (nella figura soprastante definite da colori diverse). Avremo quindi le seguenti categorie:
• Tabelle relative ai clienti_socii
• Tabelle relative alle carte socio
• Tabelle relative alle promozioni sui prodotti
• Tabelle relative agli articoli in vendita
• Tabelle relative alle offerte speciali in vigore al momento della vendita di un determinato articolo
Inoltre abbiamo a disposizione tutti i dettagli relativi agli scontrini
emessi ai titolari di carte socio. Per ogni giorno siamo in possesso delle seguenti tabelle:
• Testate_Scontrini_yyyymmdd
• Dettaglio_Scontrini_yyyymmdd (solo canale SUPER)
• Dettaglio_Sacchetti_yyyymmdd (solo canale SUPER)
• Dettaglio_Sacchetti_yyyymmdd_I (solo canale IPER)
Le tabelle Dettaglio_Scontrini e Iva_Sontrini sono assolutamente identiche; la differenza è che la prima è utilizzata presso le filiali del canale SUPER mentre la seconda in quelle del canale IPER. Stessa discorso per le tabelle Dettaglio_Sacchetti, usata nel canale SUPER, e Dettaglio_Sacchetti_I, usata nei negozi IPER.
I valori yyyymmdd che seguono le tabelle rappresentano il formato della data relativa agli scontrini che vogliamo considerare, nel modello anno, mese, giorno. Se ad esempio siamo interessati al giorno 22 dicembre 2005 al posto di yyyymmdd ci sarà 20051222.
La prima tabella raccoglie la corrispondenza tra il codice della carta che ha effettuato la spesa (e quindi del cliente) e il codice dello scontrino emesso. Successivamente c’è differenza a seconda si tratti del canale SUPER o del canale IPER. Nel primo caso dobbiamo considerare le tabelle Dettaglio_Scontrini e Dettaglio_Sacchetti; la prima contiene il dettaglio delle spese effettuate, cioè i vari prodotti acquistati, il loro prezzo, l’eventuale offerta speciale attiva al momento dell’acquisto. Dettaglio_Sacchetti invece si riferisce esclusivamente all’acquisto di determinati prodotti, che Coop considera appartenenti alla categoria dei sacchetti, o del fresco. Fanno parte di tale insieme la carne, il pesce, i prodotti ortofrutticoli, i prodotti gastronomici, la pasticceria. Questa distinzione è essenziale per la Coop, che considera
importantissimo che un cliente acquisti anche questo genere di prodotti.
Il caso del canale IPER è simmetrico, la tabella Iva_Scontrini è
sostanzialmente sostitutiva di Dettaglio_Scontrini, idem per i sacchetti.
L’obiettivo finale consiste nel raggiungimento di due distinti progetti:
BI.1) il Disegno e la realizzazione del data warehouse dei soci di UniCoop Tirreno
BI.2) il Disegno e la sperimentazione di soluzioni avanzate di CRM (Customer Relationship Management) basate su analisi
previsionale di data mining.
Per quanto riguarda il secondo progetto, la piattaforma di Business Intelligence (BI) sarà dotata, sulla base del DW dei Soci Coop, di soluzioni avanzate per il CRM e la gestione del socio basate su modelli di analisi previsionale che saranno costruiti mediante tecniche di Data Mining a partire dai dati presenti nel DW stesso. I due sottoprogetti da sviluppare sono:
• L’analisi previsionale dell’effetto delle promozioni sulle vendite (sia del prodotto in promozione che dei prodotti concorrenti)
• La predizione dell’abbandono dei soci.
Il lavoro descritto di seguito riguarda la realizzazione di un modello predittivo in grado di ipotizzare il comportamento futuro del cliente in termini di fedeltà: si potrà parlare di analisi dell’abbandono, o della defezione, del cliente. Si tratterà di realizzare uno studio di fattibilità
del componente e una serie di prove per verificarne il funzionamento. Il lavoro si concentrerà su un sotto insieme di filiali appartenenti al
gruppo UniCoop Tirreno, e precisamente i negozi del territorio di Livorno.
1.5.1- Il sottoprogetto di analisi dell’abbandono
Nel recente passato, nei comuni anche medio grandi, vigeva la cultura del negozietto di alimentari. La clientela era pressoché sempre la
solita, e i negozianti instauravano un rapporto confidenziale con
ciascun cliente. Conoscevano la composizione del nucleo famigliare, e le sue variazioni, nel bene e nel male, sapevano venire in contro alle loro necessità (ad esempio portando loro la spesa a casa), in alcuni casi potevano permettersi di fare offerte speciali al momento (<<oggi c’è del pesce freschissimo!!!>>). Insomma istauravano relazioni
umane, con l’obiettivo di mantenere con il cliente un rapporto di reciproca soddisfazione, e quindi di fedeltà dello stesso.
Il progresso ha investito anche questa cultura, i piccoli negozi di
alimentari hanno dovuto cedere il passo alla grande distribuzione, che offre innumerevoli vantaggi: prezzi competitivi, offerte vantaggiose, parcheggi, possibilità di trovare tutto o quasi quello che serve. Tutto questo a scapito della conoscenza del cliente. Per conoscere il cliente, ora, bisogna avere i suoi dati, tutti quelli che è possibile recuperare, con l’intento di ricreare il vecchio rapporto di fiducia.
Interessa sapere il grado di soddisfacimento di ciascun cliente, e così cercare di minimizzare quanto più possibile il rischio di abbandono di quest’ultimo.
Un cliente che si trova bene in un’impresa rappresenta un capitale enorme per questa, innanzi tutto perché un cliente fedele tende nel tempo a incrementare la sua frequenza di acquisto, e ad avere probabilmente propensione ad aggiungere nuove voci di acquisto a quelle originarie. Inoltre una clientela soddisfatta tende a fare buona pubblicità e quindi aiuta a trovare nuovi clienti a costi di acquisizione molto bassi.
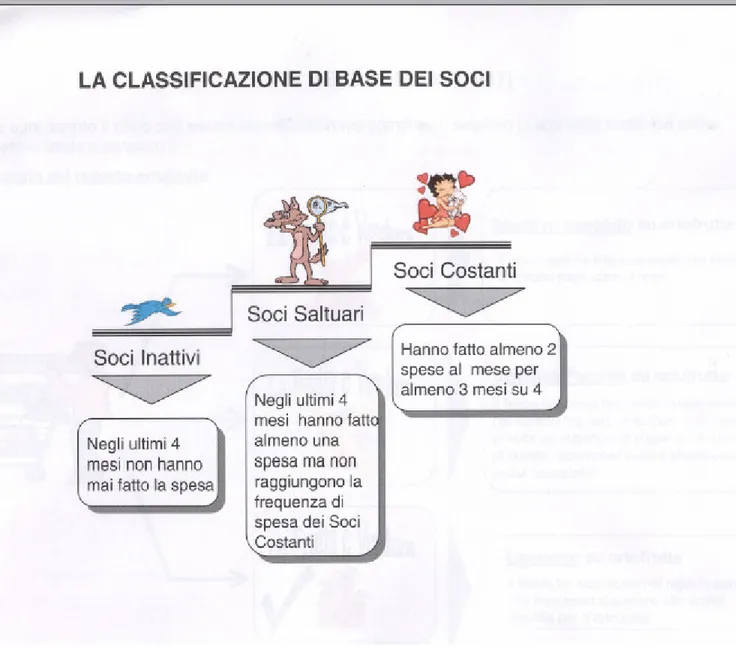
Coop considera la soddisfazione del cliente in termini di fedeltà, distinguendo i soci in tre categorie, e più precisamente:
• sono soci costanti coloro che hanno fatto almeno 2 spese al mese per almeno 3 mesi su 4;
• sono soci saltuari coloro che non rientrano nella prima categoria, ma hanno comunque effettuato almeno una spesa negli ultimi 4 mesi;
• sono soci inattivi coloro che non hanno effettuato spese negli ultimi 4 mesi.
Figura 5 : classificazione di base dei soci
Come è evidente, la Coop si avvale di una finestra logico-temporale di 4 mesi, per cui qualsiasi nostra decisione deve comportare una finestra temporale di dimensione almeno quadrimestrale.
Inoltre si noti che la fedeltà del cliente dipende solo dalla frequenza, in termini di spese effettuate, e non dalla portata economica di
quest’ultime. All’azienda interessa quante volte il cliente fa la spesa, non se spende tanto o poco.
L’interesse si estende inoltre anche su quali prodotti il cliente acquista, con considerazioni particolari sui prodotti appartenenti alla categoria del fresco: un cliente che acquisti all’interno del circuito Coop della carne, o del pesce, rappresenta senza dubbio un segnale di fedeltà e soddisfazione da parte di chi compra. Per tanto le analisi che andranno fatte saranno orientate non solo sulla frequenza globale, ma anche su quella settoriale, relativa all’acquisto generale nei reparti del fresco, ma anche relativa a determinati prodotti, come ad esempio proprio il pesce.
CAPITOLO 2
PREPROCESSING
In questo capitolo vedremo in dettaglio come viene svolta la fase preliminare di preprocessing, un’analisi qualitativa sui dati grezzi.
2.1- Data Profiling
Come già accennato in precedenza, prima di effettuare il vero e proprio
Data Mining bisognerà preparare i dati su cui lavorare: bisognerà
depurarli delle informazioni che potrebbero forviare le analisi, cercando di considerare quanto più possibile i soli dati utili. Ma per fare questo è necessario in un certo senso censire i dati, avere una quanto meglio accurata analisi sul loro significato reale e sul loro contenuto:
bisognerà “conoscere” i dati quanto più possibile.
In effetti noi lavoriamo su qualcosa che non è stato scritto da noi, in un campo che non è proprio di nostra competenza: si possono presentare subito problemi di incomprensione, dovuti al semplice fatto che due persone distinte, che si occupano di settori diversi, difficilmente interpreteranno lo stesso problema nello stesso modo, come non attribuiranno lo stesso significato ad alcuni termini, in pratica non adotteranno mai lo stesso "linguaggio".
Profiling, ossia attribuire il giusto significato ai termini, studiare l'utilità reale dei dati presenti, che dipende non solo dal significato e dall'importanza attribuita da chi li utilizza realmente, ma anche dalla loro densità, cioè dalla quantità di valori interessanti di cui disponiamo.
Ad esempio, nelle tabelle del database ritenute interessanti, diversi attributi, si rivelavano essere poco utili ai fini dell'analisi, o perchè utilizzati in contesti diversi (ad esempio utilizzati solo con i fornitori, e quindi di scarso interesse nell'analisi dell'abbandono di un cliente), o perchè scarsamente utilizzati, e quindi spesso caratterizzati dal valore null, o da un unico valore che per tanto non consentiva distinzioni. La fase di Data Profiling necessita di una collaborazione con il personale specializzato di UniCoop Tirreno, che conosce bene il signicato degli attributi presenti, ma anche del valore che essi possano assumere e di una buona intuizione dell’informatico, e del sostegno di strumenti statistici in grado di definire la densità degli attributi di una tabella.
Di seguito riportiamo un esempio di Data Profiling, ottenuto analizzando la tabella delle Carte.
I record della tabella della Carte sono identificati da un codice che chiameremo numero di carta. Gli attributi maggiormente rilevanti sono:
• il negozio presso cui è stata attivata
• le date, di emissione, di consegna, di generazione, di modifica, di ritiro, ecc…
• codici che identificano le autorizzazioni dei clienti ad utilizzare il servizio di prelievo cash, e i relativi utilizzi di tale servizio
• l’eventuale smarrimento
• l’eventuale blocco, o disabilitazione temporanea, con tutte le informazioni relative.
• Informazioni relative al personale che ha emesso la carta
• Informazioni anagrafiche del cliente possessore della carta
• Eventuale numero di conto del cliente
• Informazioni aggiuntive
Di tali attributi, siamo in grado di sapere quanti valori diversi possono assumere e quali, in che misura sono popolati, ossia la percentuale di valori “null” che ogni attributo assume.
Esistono infatti attributi con percentuali di valori nulli molto alte, ben sopra il 90%. Tali attributi, risulterebbe difficile considerarli per analisi accurate, e spesso vengono volutamente tralasciati. Discorso identico per la percentuale di valori distinti: se un attributo vale sempre ‘5’, sarebbe un’inutile perdita di tempo considerarlo. Questo tipo di analisi preliminare serve per poter tracciare uno schema riassuntivo per le tabelle d’interesse.
2.2- Data Understanding
La fase di Data Understanding completa la precedente fase di
Profiling: obiettivo finale sarà la creazione di un report documentativo delle tabelle che abbiamo preso in esame per il problema
dell’abbandono del cliente. Ricordiamo che esse sono, per la parte statica:
• Tabelle relative ai clienti_socii
• Tabelle relative alle carte socio
• Tabelle relative alle promozioni sui prodotti
• Tabelle relative agli articoli in vendita
• Tabelle relative alle offerte speciali in vigore al momento della vendita di un determinato articolo
In particolare, la nostra analisi verterà sul cliente, e sul suo utilizzo della carta socio. Saremo inoltre interessati a conoscere la tipologia del cliente, studiando ad esempio il suo comportamento nel circuito Coop: potrebbe essere interessante sapere se ad esempio ha attivato o no il salvatempo. Esamineremo con maggior interesse le tabelle:
• Carte
• Attivazione_salvatempo
Esse sono le tabelle che racchiudono tutte le informazioni relative al cliente, ai suoi dati anagrafici e ai dati relativi alla carta a lui intestata. In particolare, Attivazione_Salvatempo contiene una traccia delle carte, e quindi dei clienti, che hanno attivato il “salvatempo”, uno strumento utilizzabile nei negozi Coop per calcolare da soli l’importo della spesa che si sta facendo. Sono apparecchi in grado di leggere il codice a barre dei prodotti, e stampare uno scontrino relativo agli acquisti fatti.
L’ulteriore idea è quella di considerare le spese pesate, analizzando le condizioni in cui viene effettuata ciascuna spesa, osservando le offerte speciali attive sui prodotti acquistati. Aggiungeremo alle tabelle sopra citate anche le seguenti:
• Articoli
• Tabella delle Offerte Speciali
La prima è una descrizione degli articoli acquistabili, divisi in settori, reparti, categorie e sottocategorie. La tabella delle offerte speciali, invece, contiene le informazioni relative alle diverse offerte speciali praticate. Queste tue tabelle permettono di risalire, dai dettagli degli scontrini, alle particolari condizioni di acquisto di un prodotto, ossia posso conoscere l’offerta speciale in vigore al momento di un
particolare acquisto. Esempi di offerte speciali sono il “3X2”, oppure l’offerta “p.50”, che offre cinquanta punti (per le tessere di raccolta
punti per i premi) con l’acquisto di un determinato articolo.
Tutto questo non significa che tralasceremo le altre tabelle, ma che orientativamente il nostro interesse si focalizzerà su queste, e su queste in particolare sarà opportuno applicarsi per ottenere un report completo e soddisfacente.
Il report finale si presenta come l’elenco delle tabelle, descritte dai loro attributi. Ad ogni singolo attributo sarà associato un breve commento che ne ricorderà il significato, e saranno elencati, quando possibile, i valori da esso assunti. Infine, per ciascun valore, sarà descritto il significato.
CAPITOLO 3
PROGETTAZIONE DEL DATA MINING
Questo capitolo ha l’obiettivo di introdurre gli aspetti fondamentali che riguardano il data mining: saranno introdotti gli indici e saranno
presentati i principali obiettivi dell’analisi.
3.1- Approccio Generale
Da un punto di vista strettamente tecnico, il nostro studio si
concentrerà su alcune tabelle del database Coop. In particolare, siamo interessati a tracciare da un lato un profilo sociale del socio, tenendo conto del suo grado di utilizzo del sistema Coop (ad esempio un segnale incoraggiante potrebbe essere l’utilizzo del salvatempo),
dall’altro vogliamo avere delle serie temporali che identifichino il trend di acquisti di ciascun cliente. Fondamentalmente siamo interessati ad effettuare lo studio e le relative analisi esclusivamente sul numero di spese effettuate dal cliente, e ad analizzare come possibili defezioni a medio o lungo termine tutti quei comportamenti che descrivono un decremento significativo della frequenza. Tuttavia esempi di vita reale fanno supporre che tale atteggiamento si riveli semplicistico e poco esaustivo.
Si pensi ad esempio ad una determinata promozione che offra un
bonus del 10% di sconto, su una qualsiasi spesa effettuata nel mese di settembre, per tutti coloro che effettueranno almeno otto spese nel
mese di agosto. Com’è logico pensare, moltissimi soci effettueranno otto o più spese nel mese di agosto, probabilmente solo per ottenere lo sconto. Per tanto un analisi fatta esclusivamente sulle frequenze
denoterebbe per tutti coloro che abitualmente fanno meno spese durante un mese, un picco, seguito inevitabilmente da un ritorno alla”normalità”. Sarebbe per tanto giusto dare anche una stima
“pesata” delle frequenze, cosi da effettuare analisi sia sulla frequenza reale del cliente sia su quella “costruita”. Per agire in questo modo, andiamo a controllare in che condizioni (con quali offerte speciali in corso) viene effettuata una spesa, per poi attribuire un valore ad essa.
Un secondo esempio potrebbe essere quello di colui che, ottenuto il buono sconto del 10%, effettua una spesa molto consistente. Se era solito comprare un chilo di pasta, potrebbe succedere che ne compri cinque chili, pensando magari che la pasta non scade subito e costa il 10% in meno. Ne conseguirebbe quindi che, per tutto il mese, non abbia bisogno di andare tante volte a fare la spesa quanto gli occorreva di solito. Per tanto, un decremento della frequenza potrebbe essere giustificato da un incremento della singola spesa, come se quella spesa valesse per due. Sembra logico quindi analizzare anche il trend degli importi spesi, in modo da poter, in alcuni casi, giustificare un
decremento della frequenza con un aumento dell’importo speso.
Per tanto, l’idea è di usare una triplice classificazione del cliente, in termini non solo di frequenza, ma anche di frequenza pesata e volume di spesa.
L’applicazione finale consisterà in un modello in grado di effettuare previsioni riguardo l’andamento futuro del cliente, indicando in maniera adeguata la soddisfazione del cliente o il suo rischio di abbandono, sia in termini generali, sia ristretto ai soli acquisti nel settore del fresco, sia relativo ai singoli prodotti acquistati. In questo modo si potrà intervenire come meglio si crede per evitare tali defezioni
3.2- La rilevazione degli indici
Come già accennato in precedenza, per ottenere un’analisi ottimale bisognerà trasformare, almeno in parte i dati: l’idea è quella che non bastino i soli attributi, così come ci sono stati presentati; ne serviranno degli altri, da costruire a partire dagli originali. Per ottenere un modello predittivo che identifichi il rischio di abbandono di un cliente, bisognerà costruire una serie di attributi intorno al cliente. Dal valore di tali
attributi dipenderà il fattore di rischio della defezione. Innanzi tutto, una premessa: anche se consideriamo logicamente tutto incentrato sul cliente, praticamente lavoreremo sulle carte, e sul loro codice
identificativo: questo non cambia nulla dal punto di vista teorico, perché tra cliente e carta c’è una corrispondenza biunivoca;
semplicemente favorisce le analisi dal punto di vista pratico.
Tornando al discorso precedente, dobbiamo fare in modo di avere, per ciascun cliente, una serie di attributi che lo definiscano: si parlerà di indici o indicatori.
saranno costruiti come operazioni logiche e matematiche tra attributi originali, altri infine saranno considerati invece su base temporale.
Potremmo distinguerli, per semplicità, in attributi fissi, o indicatori “base”, e attributi temporali.
3.2.1- Gli indicatori “base”
Le prime informazioni che risultano essere importanti sono quelle relative al solo cliente, indipendentemente da quante spese effettua. Possiamo parlare di una denotazione del cliente all’interno di UniCoop Tirreno. Consideriamo per tanto innanzitutto la vita del cliente come socio: utilizzeremo due attributi che ci dicono da quanto tempo il nostro cliente è socio, espresso in mesi e in anni.
Vogliamo inoltre anche tener traccia della data del suo ultimo
movimento, che sarà considerato come la data più recente tra diversi attributi di tipo data presenti nel database originale. L’ultimo
movimento del cliente non sempre coincide con l’ultima spesa effettuata, perché consideriamo come movimenti anche i prelievi monetari dagli sportelli dedicati, oppure il ritiro di duplicati carta o
simili. Un’assenza del cliente per un periodo lungo di tempo può a volte essere giustificata da, ad esempio, lo smarrimento della carta.
Infine cerchiamo di tracciare un ulteriore profilo del cliente:
consideriamo un nuovo attributo, “affidabilità”, calcolato in base al comportamento del cliente nel sistema. Più precisamente, un cliente che ha attivato il salvatempo, probabilmente è un cliente che è solito
fare le sue spese alla Coop; cosi come un cliente che usufruisce del servizio di prelievo cash, è un cliente che si recherà spesso nei pressi della struttura per il prelievo, e quindi probabilmente al supermercato. Questi ed altri parametri, tra cui la vita del socio (da quanto tempo il cliente è socio) saranno pesati, ossia alla relativa attivazione di un servizio saranno attribuiti dei punti. La loro somma costituisce il valore del parametro dell’affidabilità. Consideriamo anche valori negativi, ad esempio di quei soci che risiedono lontani dalle sedi di UniCoop
Tirreno: è il caso di coloro che sono diventati soci presso le sedi di UniCoop Firenze.
L’Affidabilità è per tanto calcolata come segue:
(0.01)*VitaDelSocio (in settimane) +
2.5 (Se Attivo) +
1.5 (Se attivato il salvatempo) +
2.5 (Se in possesso della Tessera sconto) +
1 (Se autorizzato ai Prelievi Cash) –
5 (Se socio presso UniCoop Firenze) –
5 (Se inserito nella Black List)
Riassumendo, gli indicatori che potremmo definire fissi sono:
• VitaSocioMM
• Data_Ultimo_Movimento
• Affidabilità
3.2.2- Gli indicatori temporali
La seconda categoria di indici invece è calcolata dinamicamente su una finestra temporale di almeno quattro mesi.
Il fulcro della nostra analisi sarà concentrato sulla fedeltà del cliente, come definito dalla stessa UniCoop Tirreno, sarà considerato costante il cliente che effettuerà almeno due spese al mese per almeno tre mesi su quattro. Il cliente saltuario, invece, si limita ad effettuarne una sola negli ultimi quattro mesi. Il cliente inattivo, infine, nessuna. Tale
discorso deve valere anche per le spese effettuate nei soli reparti del fresco (pane, carne, pesce, ortofrutta, gastronomia, pasticceria) e nei singoli sotto-reparti (noi consideriamo, come espressamente richiesto dai responsabili UniCoop Tirreno, la fedeltà nel reparto del pesce). Avremo cosi tre attributi fedeltà: fedeltà, fedeltàSacchetti e fedeltàPesce.
Inoltre sarà opportuno andare a vedere più nel dettaglio il comportamento del cliente nel periodo in questione.
La nostra analisi, per quanto espressamente richiesto da Coop, si baserà innanzitutto sull'analisi della frequenza, ossia del numero di
spese effettuate da parte di un cliente-socio presso una qualsiasi filiale della catena super o iper. Analogamente interessa anche effettuare analisi statistico-temporali su quello che viene acquistato dal cliente, ponendo particolare attenzione su quello che Coop definisce reparto del fresco, cioè una serie di prodotti, dalla carne al pesce, all'ortofrutta, che definiscono in particolar modo la "fedeltà" del nostro socio.
Abbastanza correlato all'analisi della frequenza poniamo lo studio del venduto, ossia la spesa economica sostenuta per ogni accesso alla
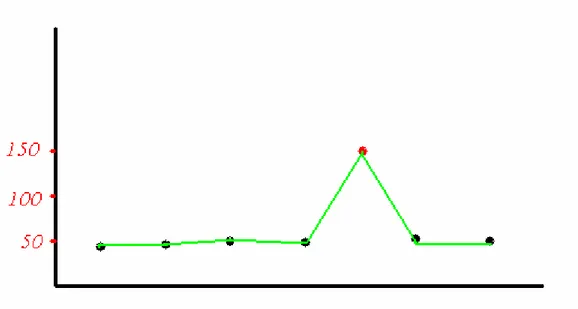
catena Coop. Per evitare un inquinamento dei dati, in quest'ultimo caso non viene tenuto conto dei valori di outlaier, ossia di quei valori che potrebbero falsare l'andamento dei valori di spesa. Per spiegare meglio questo concetto proviamo ad immaginare il caso di un cliente normale, che di media effettua una spesa alla settimana, acquistando più o
meno i soliti articoli. Ipotizziamo che spenda, settimanalmente, quindi ad ogni spesa, 50 euro. Se un giorno il nostro cliente decide di
acquistare un costoso apparecchio elettronico, e sceglie di comprarlo proprio alla Coop, la sua spesa effettuata quel giorno sarà molto più elevata delle precedenti. Supponiamo acquisti un forno a microonde e lo paga 100 euro. Quando andiamo ad analizzare la serie temporale (per esempio su base settimanale) avremo un andamento simile a quello rappresentato in figura (sicuramente una versione semplicistica, ma il concetto è evidente).
Figura 6 : serie temporale con outlaier
Come notiamo dalla figura, ad un certo punto (esattamente dopo la quinta settimana) notiamo un decremento netto della spesa effettata dal nostro cliente, chiaramente dovuto al fatto che l'acquisto del
microonde è stato un acquisto non ripetibile, e quindi è ovvio che ci sia questa decrescita del grafico. L'eliminazione degli outlaier, cioè ad esempio l'eliminazione di tutti quei beni che costano più di 50 euro, mi consente di avere un andamento del venduto più realistico, come nella figura sotto.
Figura 7 : serie temporale dopo eliminazione degli outlaier
Questo accorgimento ci consente in fase di analisi di evitare di considerare casi simili come casi di defezione, o comunque di diminuzione del grado di affidabilità di un cliente.
Un ulteriore accorgimento è stato preso anche nei confronti delle
frequenze: la fedeltà di un cliente è associata (tra l'altro) al numero di spese effettuate, quindi una diminuzione di esse significherebbe una diminuzione della fedeltà del socio. Ma anche in questo caso ci sono degli scenari che sconvolgono, o anche semplicemente alterano, quella che in condizioni standard sarebbe stata la frequenza reale. Tipico il caso di una promozione che offriva il 10% di sconto su una spesa qualsiasi se nel mese precedente erano state fatte 8 spese. Anche chi di norma effettuava meno accessi, in condizioni del genere ha preferito recarsi più spesso a fare la spesa, ma nei mesi successivi è ritornato alla normalità. Anche questo possiamo vederlo come un caso di
outlayer. Inoltre è normale che in determinate circostanze, o, meglio, con determinate offerte sui prodotti, un cliente sia più o meno
invogliato ad andare a fare la spesa, magari anche solo per pochi prodotti. Nasce quindi l'idea di effettuare una "pesatura" della
frequenza: un cliente che fa x spese avrà una frequenza pari ad x, ma è possibile il caso in cui il cliente faccia un numero di spese maggiori del solito, condizionato da determinate promozioni; in tal caso,
considerando ogni spesa come pesata, attribuendo cioè ad ogni spesa un valore compreso tra 0.7 e 1, avremo un ulteriore valore da
confrontare. Ogni acquisto di un prodotto in offerta ha un valore, tipicamente minore di uno, mentre l'acquisto di un prodotto non in offerta vale uno. La media di questi valori fornisce la frequenza pesata di quella spesa.
Chiaramente la "pesatura" dipende dal tipo di offerta presente. Ad esempio, l'offerta del 3X2 è molto comune, un acquisto viene
considerato poco di meno del reale (0.90) mentre le offerte 1+1, o quelle che garantiscono molti punti aggiuntivi per la raccolta premi, modificano molto la frequenza pesata (fino a 0.70). Facendo la media di questi valori si ottiene la frequenza relativa a quella spesa. Ad esempio, se un cliente acquista solo prodotti in offerta, magari molto conveniente, la sua spesa avrà la frequenza reale uguale ad uno, ma quella relativa, o "pesata", uguale a 0.85. In questo modo, per
analizzare l’andamento della frequenza relativo ad un socio,
considereremo non solo il numero reale di spese effettuate, ma anche questa nuova grandezza, la frequenza “pesata”. Ad esempio,
ipotizziamo che il signor Rossi faccia di media 5 spese al mese, e che compri quello che gli serve, lasciandosi poco influenzare dalle offerte speciali. Ma un mese ci sono diverse promozioni che gli interessano,
per tanto si recherà più volte a fare la spesa, diciamo altre 3 volte. Successivamente tornerà ad effettuare il solito numero di spese. La sua frequenza, dopo il picco avuto un mese, scenderà abbastanza
vertiginosamente. Diminuirà da 8 (nel mese delle promozioni che gli interessavano) a 5. In realtà il suo atteggiamento non è cambiato, il signor Rossi ha avuto solamente un picco di frequenza in un mese, giustificato dal fatto che erano in vigore delle offerte che gli
interessavano particolarmente. La frequenza pesata potrebbe rimediare a questo problema. Infatti, attribuendo alle 3 spese effettuate un
valore più basso, la loro somma non denoterà una discesa drammatica come nel caso delle frequenze reali. In un certo senso, spianeremo il picco.
Da un punto di vista strettamente tecnico, la nostra attenzione si sofferma sulle seguenti tabelle:
• Tabella dei soci
• Tabella delle offerte speciali
• Tabella delle carte
La prima ci fornisce i dettagli anagrafici del cliente, e i dettagli relativi alla sua "vita" nella Coop. Cioè è possibile risalire alla data in cui ha fatto domanda per diventare socio Coop, e quindi ricavare da quanto tempo è socio, e così via. La seconda tabella raccoglie le informazioni relative alle offerte speciali: risulta molto utile sapere in che
promozione.
Esistono differenti classi di promozioni presenti nel database, ne riportiamo quelle più significative: Offerte 3X2: includono anche le meno note 4X3, 5X4 e cosi via. Ad esse sarà associato un peso poco incisivo, compreso tra 0.9 e 0.95, in quanto si tratta di offerte
abbastanza abituali.
Offerte punti: sono offerte speciali che offrono con alcuni prodotti un certo numero di punti per la raccolta premi. A volte sono aggiunti anche ulteriori punti aggiuntivi. Quest'offerta in particolari condizioni risulta essere molto vantaggiosa, talmente tanto da giustificare qualche accesso in più da parte di un cliente (ci sono a volte offerta di 100
punti in più, magari fino a esaurimento scorte o per un periodo di tempo limitato). Queste offerte potrebbero influenzare l’andamento solito della frequenza di un cliente, per tanto gli si attribuirà un peso più incisivo, tipicamente tra 0.7 a 0.9, a seconda dei punti offerti.
Offerte sconto: comprendono sia gli sconti in euro (1euro, 50 cent, -2euro) sia quelli percentuali (per esempio 30%). Anche in questo caso, il peso associato varia in base allo sconto effettuato. Prodotti acquistati al 50% o superiori, o con 2 euro di sconti, avranno un peso di 0.7, a scalare fino ad un valore di 0.9.
risulta condizionare molto il numero di spese effettuate da un cliente. Per tanto sarà attribuito un peso di 0.75.
Infine, la tabella delle carte contiene informazioni molto utili, che
possono in un certo senso identificare il cliente: ad esempio, la tabella contiene diversi attributi di tipo data che contengono le informazioni relative alla data di ultimo utilizzo della carta da parte del socio. In un certo senso vanno a costituire un check point, un punto temporale in cui abbiamo avuto l'ultima segnalazione di questo cliente.
Per quanto riguarda l'analisi delle serie temporali ci concentreremo sull’analisi di tre tabelle giornaliere:
•Tabella delle testate degli scontrini
•Tabella di dettaglio scontrino
•Tabella di dettaglio del settore del fresco
Esistono tre tabelle per ogni giorno per ogni negozio.
La tabella testata scontrino racchiude le associazioni tra numero di carta e codice dello scontrino emesso. Risulta per tanto possibile associare un cliente (associato a una carta) a tutti gli scontrini e alle relative spese effettuate.
duplicati, quindi per avere un identificativo univoco dello scontrino si deve fare affidamento sulla coppia di attibuti data e codice scontrino.
Ad uno scontrino (o meglio a una coppia data, codice scontrino) sono associati nelle tabelle dettaglio scontrino e dettaglio sacchetti, le informazioni relative ai prodotti acquistati. Quindi per ogni prodotto acquistato ho traccia del costo dell'articolo e delle condizioni
promozionali in cui è stato acquistato. Aggregando per periodi di tempo qualsiasi, posso per tanto ottenere, per ogni cliente, quante volte ha fatto la spesa (frequenza), in che condizioni promozionali ha comprato (frequenza pesata), quanto ha speso (Volume Spesa).
Abbiamo per tanto creato nuovi indici, che possiamo definire temporali:
• Fedeltà • Fedeltà Sacchetti • Fedeltà Pesce • Frequenza • Frequenza Sacchetti • Frequenza Pesce • Spesa Totale • Frequenza Pesata
I primi tre indicatori sono su base quadrimestrale, in quanto i valori di fedeltà sono calcolati in base agli ultimi quattro mesi di attività di un
socio. Gli altri indici si riferiscono invece ad un periodo settimanale.
Tuttavia bisognerà in qualche modo riassumere il comportamento di tali serie settimanali in un unico valore, relativo a tutto il quadrimestre, o, genericamente, a tutta la finestra temporale di interesse. Occorre un valore che rappresenti l’andamento della frequenza nel tempo, che informi se tale valore è aumentato o diminuito nel periodo interessato; se ipotizziamo di riassumere tutti i valori delle frequenze con una retta, ci interessa sapere la pendenza di tale retta.
3.2.3- La regressione lineare
Uno dei principali obiettivi dell’analisi statistica è lo studio dell’associazione tra diverse variabili.
Una retta di regressione riassume la relazione tra due variabili, ma in una direzione specifica: quando una delle variabili (la variabile
esplicativa, o indipendente) aiuta a spiegare o prevedere l’altra (la variabile risposta, o dipendente).
Noi ci riferiremo al caso meno complesso di regressione lineare semplice, cioè al caso in cui sia stata rilevata una sola variabile esplicativa X e la relazione tra Y e X sia lineare. A noi interessa conoscere l’andamento della serie temporale dei nostri dati: se
pensiamo ad una rappresentazione continua dei nostri dati attraverso una retta, vogliamo conoscerne la pendenza, che ci descriva quindi un andamento positivo (crescita) o negativo (decrescita) dei valori che ci
interessa analizzare. Volendo considerare la retta di regressione lineare come rappresentazione continua, ci interessa conoscere il valore del coefficiente angolare, che formalmente può essere calcolato con la seguente formula:
sia ‘n’ la cardinalità delle osservazioni X, e x1…xi i rispettivi valori, vale lo stesso per Y. Siano inoltre xm e ym i valori medi delle osservazioni.
nel caso di utilizzo, ci interessa il coefficiente di regressione lineare relativo alle frequenze di spese effettuate e di spese effettuate nei reparti del fresco.
Avremo due coefficienti diversi, uno relativo agli scontrini ed uno relativo ai sacchetti, con la settimana (1 per prima settimana e via dicendo) intesa come variabile esplicativa e le frequenze intese come variabili risposta.
• coeffRegLin
• coeffRegLin_Sacchetti
che rappresentano il valore del coefficiente di regressione lineare delle rette di interpolazione relative alle frequenze di spesa, e alle frequenze nei soli reparti del fresco.
Riassumendo, abbiamo identificato una serie di attributi di interesse che descrivono il cliente (socio) di UniCoop Tirreno. Tali attributi
definiscono il cliente sia nel contesto globale Coop, sia, relativamente a un periodo specifico, nel solo contesto di acquirente. In quest’ultimo caso, il cliente sarà definito mediante tre gradi di fedeltà: ci interesserà sapere se il suo comportamento, in base alla definizione data da
UniCoop Tirreno, sarà quello di cliente Costante, Saltuario o Inattivo, il tutto relativo non solo al contesto generale ma ai sotto-contesti del “fresco” e del pesce. Infine saranno riportati, per ciascun cliente, i parametri relativi al periodo selezionato, in termini di frequenza (in primis) e di spesa totale e frequenza pesata. Riepilogando, gli attributi trovati e accostati a ciascun cliente sono:
• Fedeltà
• Fedeltà_Sacchetti
• Frequenza • Frequenza_Sacchetti • Frequenza_Pesce • Spesa_totale • Frequenza* • coeffRegLin • coeffRegLin_Sacchetti
3.3- Estrazione dei modelli di data mining
Per concludere la fase di progettazione del data mining è opportuno compiere uno studio di fattibilità. In particolare, utilizzando lo
strumento Clementine, distribuito da SPSS, sono stati costruiti dei modelli, con lo scopo di realizzare dei prototipi per l’analisi degli attributi del database, che in futuro saranno utilizzati nella
sperimentazione vera e propria. I modelli in questione rappresentano graficamente un flusso di informazioni, da una sorgente dei dati (un database) a un output (una tabella, un database, uno strumento di analisi…), passando per diversi nodi, che rappresentano operazioni fatte sul flusso, dalle semplici select SQL alle operazioni di tipizzazione o di aggregazione.
cliente. Lo scenario originario ci offre, per quanto riguarda la granularità degli scontrini, una finestra temporale giornaliera, dal giorno 1/10/2005 al giorno 12/09/2006. Disponiamo inoltre di tutte le tabelle del database Coop. Durante il percorso che porterà all’ottenere tutti gli attributi che caratterizzano il cliente, passeremo
inevitabilmente attraverso modelli intermedi di supporto e utilità. Di seguito saranno riportati alcuni schemi che hanno contribuito
significativamente allo studio della fattibilità e alla preparazione dei dati.
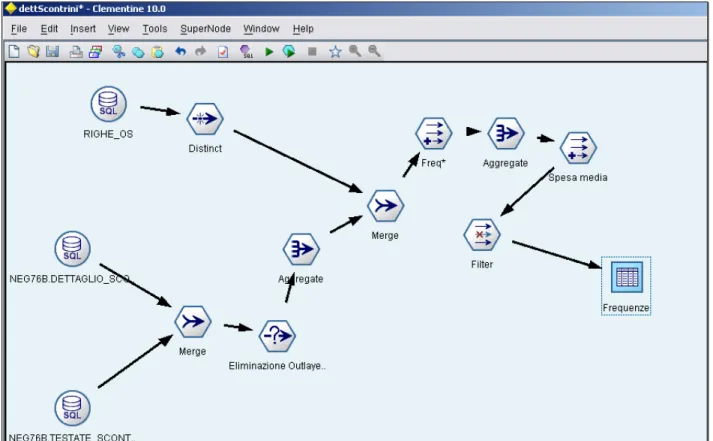
Il primo schema è dettScontrini, come suggerisce il nome si tratta di un’analisi in dettaglio degli scontrini emessi in un certo periodo di tempo.
Figura 8 : modelli clementine - dettaglio scontrini
In figura mostriamo un esempio semplificato del modello: a sinistra, i nodi tondi rappresentano i nodi di input, mentre la tabella “Frequenze”, evidenziata sulla destra, rappresenta l’output. Per maggiori dettagli, in appendice sarà riportata una descrizione completa del modello.
La tabella delle testate degli scontrini fornisce la correlazione tra carta (e quindi cliente) e scontrino; la tabella dei dettagli degli scontrini fornisce le informazioni riguardo il dettaglio dello scontrino, cioè cosa ha acquistato e in quali condizioni di offerta. Infine la tabella delle
offerte speciali (Righe_OS) fornisce le informazioni dettagliate riguardo la promozione attiva al momento della vendita e mi permette di
calcolare un attributo derivato, Valore, che mi fornisce una "pesatura" della spesa effettuata e quindi della frequenza. Da un punto di vista
puramente tecnico, le tabelle sono tutte sottoposte ad una “filter”, un vero e proprio filtro, che permette di eliminare dal contesto gli attributi inutilizzati, mentre, nei casi in cui un attributo che verrà utilizzato per aggregazioni presenta valori nulli, è necessaria una selezione che elimini appunto questi valori, che possono essere fonte di problemi in fase di elaborazione. Inoltre è presente un ulteriore select che funge da eliminatore degli outlier così che valori poco interessanti e ingannevoli possano essere eliminati dall'analisi.
Negli scontrini il campo che identifica l’offerta in corso al momento dell’acquisto di un singolo articolo può avere valore ”null”: in tal caso tale valore verrà sostituito con un valore convenzionale che non
disturbi l'elaborazione. Infine con due diversi processi di aggregazione vengono create due tabelle che contengono le informazioni che ci
servono. La prima è un’”aggregazione” su data,scontrino e codice della carta, e rappresenta una singola spesa effettuata (identificata appunto dalla terna di attributi citati) e visualizza l'importo della spesa e la
frequenza relativa associata a quella spesa (da 0.70 a 1).
La seconda aggregazione è sulle carte, cioè per ogni cliente, per un dato periodo di tempo, viene fatta una valutazione globale, che comprende numero di spese fatte (frequenza) e frequenza relativa, spesa totale e spesa media.
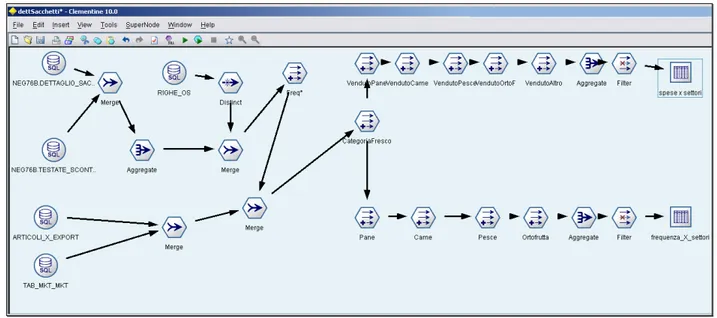
Il secondo schema, dettSacchetti, analizza invece i sacchetti, ossia pone attenzione sull’ acquisto dei prodotti appartenenti alla categoria del "fresco".
Figura 9 : modelli clementine - dettaglio sacchetti
Rispetto il precedente schema, abbiamo utilizzato la tabella dei dettagli dei sacchetti del fresco, e le tabelle degli articoli e della suddivisione degli articoli (in settori, reparti, categorie e sottocategorie), che ci
servono per risalire a partire dal codice articolo presente sullo scontrino a che prodotto si riferisce. A noi interessano quelli che fanno parte del settore del fresco, e più in particolare distinguiamo tra pane (e simili), pesce, carne e ortofrutta.
Elaboriamo due tabelle differenti, che ci consentono di visualizzare al meglio le informazioni di interesse.
La prima, denominata "spese x settori", fornisce per ogni cliente in un periodo di tempo indicato quanto ha speso nei reparti del fresco
(attributo Spesa Totale) e in particolare quanto nei vari reparti.
La seconda, di rilevante importanza, è la tabella "frequenza x settori", che ci consente di analizzare l'andamento di ogni cliente, in termini di spese effettuate nei reparti del fresco, e in particolare in ciascuno di
essi. Ci consente quindi di analizzare, come richiesto da Coop, gli
acquisti (in numero, non in valore) di ogni cliente in ciascun reparto del fresco che intendiamo analizzare.
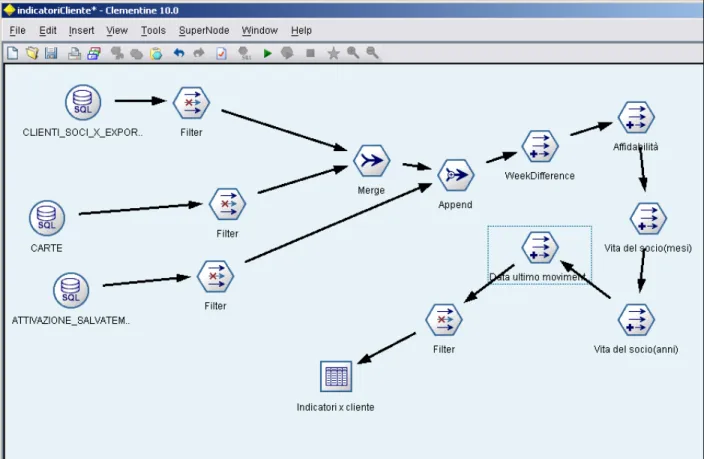
Un terzo modello, IndicatoriCliente, è in grado di calcolare, per ogni cliente, gli attributi a-temporali che lo definiscono.
Figura 10 : modelli clementine – indici “statici” per cliente
Si tratta di parametri che mi definiscono quanto il socio in questione utilizzi il sistema Coop, attraverso lo studio del periodo di tempo da quando è socio e sfruttando le informazioni relative all'attivazione o meno dello strumento del salvatempo o altro ancora; gli attributi ricavati rappresentano l'affidabilità, cosi come descritta nel paragrafo relativo agli indici, la data dell'ultimo movimento effettuato all'interno
di Coop, e la vita del socio, espressa in mesi e anni. Il modello in
questione è rappresentato da una “join” a tre livelli, ossia un unione di tabelle, che combina le tre tabelle di interesse della base di dati ,e, nello specifico, si tratta della tabella dei clienti-soci, quella delle carte e quella della attivazioni del salvatempo. La tabella risultante ci fornisce in conclusione, per ogni cliente (in realtà per ogni carta, ma ogni carta è associata a un solo cliente), i parametri di interesse.
Successivamente sono stati costruiti schemi per simulare la creazione di una tabella contenente tutti gli attributi d’interesse per singolo socio.
Bisogna quindi anche generare i coefficienti di regressione lineare che ci interessano: per fare ciò, una parte del modello si occupa, partendo dal dettaglio settimanale delle spese fatte da ciascun cliente, di
calcolare il valore del coefficiente per quanto riguarda la serie delle frequenze e la serie delle frequenze limitate ai soli reparti del fresco.
La formula in questione è:
dove m è il coefficiente che ci interessa calcolare.
Per quanto riguarda gli altri attributi, utilizzeremo alcuni di quelli introdotti nei precedenti schemi. Il risultato finale sarà la creazione di una Tabella Finale.
3.4- Preparazione del database
Una volta ultimata la fase di preprocessing bisognerà procedere al mining vero e proprio, volto alla creazione di un modello predittivo. La nostra ipotesi è quella di considerare gli scontrini, e quindi tutte le informazioni relative, su base settimanale, perché sembrerebbe essere la giusta via di mezzo tra un soddisfacente dettaglio e un numero
ragionevole di tabelle da utilizzare. Inoltre conviene considerare ogni mese composto esattamente di quattro settimane, in questo modo ogni mese sarà di uguale dimensione (in numero di giorni). La prima azione da compiere è aggregare settimanalmente gli scontrini. Noi abbiamo tutti i dettagli con granularità giornaliera, per ciascun negozio. Nella fase di sperimentazione sono stati selezionati solo una piccola parte dei negozi di UniCoop Tirreno, e precisamente cinque negozi, sul territorio di Livorno, avendo cura di scegliere almeno un negozio di tipo IPER e uno di tipo SUPER. I negozi in questione portano il nome (sigla) di NEG01, NEG02, NEG03, NEG05 e NEG07, di cui quattro negozi
“SUPER” e un “IPER”. Per aggregare settimanalmente è stato utilizzato lo strumento “Design Center” di Oracle, in grado di realizzare, in
maniera semi-automatica, tali aggregati. Alla fine, abbiamo tabelle che contengono i dettagli relativi a un intera settimana, rappresentati, nel nome, dalla data del giorno sabato di tale settimana. Inoltre si è
scontrini e ai soli sacchetti del fresco; tale scelta ottimizza le prestazioni di elaborazione, in quanto le due tabelle hanno utilizzi differenti.

![Elisa Gregori, Le comiche smorfie. Avramiotti contro Chateaubriand : [recensione]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)