2. LOCALIZZAZIONE IN AMBIENTI INDOOR
In questo capitolo sono riportati i risultati allo stato dell’arte più recenti presentati nella letteratura scientifica riguardo studi, sperimentazioni ed implementazioni di algoritmi atti alla localizzazione di Tag UHF RFID in ambienti indoor e dunque per range in lettura massimi di qualche metro. In particolare gli scenari di maggior interesse analizzati saranno tutti quelli conosciuti in letteratura sotto il nome di “smart shelves”, per i quali, scaffali per libri e vestiario, credenze o ripiani di frigorifero e naturalmente armadietti o cassetti per medicinali, ne sono validi esempi. Questi ultimi in particolare, come accennato nell’introduzione, saranno proprio lo scenario di misura studiato nei successivi capitoli.In particolare verrà trattata nello specifico la localizzazione per Tag passivi e verranno analizzati quegli algoritmi che, partendo dalla disponibilità dell’informazione RSSI (Received Signal Strength Indication), possano permettere la localizzazione di un Tag su una superficie bidimensionale. Ci preoccuperemo inoltre di Tag e Reader eterogenei, nonché delle problematiche riguardo il tipo di materiale coi quali sono realizzati i ripiani, scaffali, cassetti e gli oggetti da identificare.
Oltre ad articoli sperimentali, verranno inoltre riportate informazioni sulle soluzioni implementate dai produttori fino a questo momento.
2.1 Algoritmi di localizzazione
Sebbene l’obiettivo sia quello di analizzare algoritmi per Tag RFID passivi che utilizzino il parametro RSSI, un riepilogo generale sullo stato dell’arte nella localizzazione è utile per orientarsi nell’argomento e per evitare di escludere validi strumenti in previsione di sviluppi futuri.
2.1.1 Parametri per localizzazione
Al fine di localizzare un ricetrasmettitore di onde elettromagnetiche (target), sarà necessario acquisire ed elaborare uno o più parametri presenti nelle caratteristiche del segnale da esso trasmesso, che contengano informazioni utili all’implementazione di un algoritmo per la stima della posizione. Ne elenchiamo di seguito i principali [1].
ToA (Time of Arrival): è la misura del tempo che il segnale radio impiega a
percorrere la tratta di andata e ritorno tra trasmettitore e target. Tale parametro è linearmente proporzionale alla distanza “d” tra i due, la quale può essere stimata conoscendo la velocità di propagazione “v” dell’onda nel mezzo di trasmissione, in formule (2.1-2.2):
𝑇𝑇𝑇𝑇𝑇𝑇 = (2∗ 𝑑𝑑)𝑣𝑣 [𝑠𝑠] (2.1) 𝑑𝑑 = (𝑇𝑇𝑇𝑇𝑇𝑇 ∗ 𝑣𝑣)2 [𝑚𝑚] (2.2)
in cui la stima della distanza “d” verrà poi utilizzata negli algoritmi di localizzazione. Generalmente il ToA è un parametro estremamente preciso, ma la sua misura richiede un hardware piuttosto complesso (occorrono riferimenti temporali accurati che rendono il sistema costoso), e risente molto del multipath (cammini multipli) [10]-[11] che generano ToA diversi per uno stesso ricevitore.
TDoA (Time Differential of Arrival): simile al ToA per il fatto che anche il
TDoA è una misura di tempo: è la differenza tra il tempo che il segnale impiega a percorrere la tratta di andata e ritorno tra il target e due o più ricevitori spazialmente separati. Se indichiamo con “i” e “j” due generici ricevitori, possiamo esprimere la differenza tra i tempi di arrivo di i e j come (2.3):
𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑖𝑖,𝑗𝑗 = �𝑇𝑇𝑇𝑇𝑇𝑇𝑖𝑖− 𝑇𝑇𝑇𝑇𝑇𝑇𝑗𝑗� = �(2∗ 𝑑𝑑𝑣𝑣 𝑖𝑖)− �2 ∗ 𝑑𝑑𝑣𝑣 𝑗𝑗�� [𝑠𝑠] (2.3)
con di edj le distanze del Target dai ricevitori i e j rispettivamente.
Conoscendo tali valori di differenze reciproche tra almeno tre ricevitori è possibile stimare una posizione in 2D mediante algoritmi di laterazione [12]-[13]. TDoA presenta gli stessi difetti di multipath e di complessità hardware incontrati nel ToA, con costi
ancor più alti dovuti alla presenza di ricevitori multipli, ma come ToA è in grado di produrre stime generalmente molto accurate.
PoA (Phase of Arrival): è la misura della fase di arrivo di un segnale radio dopo
aver percorso la tratta di andata e ritorno tra trasmettitore e target, viene espressa mediante frazioni di lunghezza d’onda: il segnale trasmesso per la misura del PoA dovrebbe avvicinarsi il più possibile ad una sinusoide pura. Tale parametro può essere utilizzato negli stessi algoritmi che sfruttano ToA o TDoA. Seppur essendo un parametro con accuratezze ai livelli dei precedenti, soffre maggiormente del problema del multipath in ambienti indoor, in quanto richiede la presenza di un forte segnale in LoS (Line of Sight) per limitare errori in localizzazione.
AoA (Angle of Arrival): è la misura, mediante antenne direzionali, dell’angolo
di arrivo di un segnale proveniente dal target o in altre parole identifica la linea di direzione del Target (misurata in gradi rispetto al trasmettitore, in base ad un sistema di riferimento angolare). Viene utilizzato in algoritmi di triangolazione [13] e richiede un hardware costoso e complesso come la presenza di un array di antenne con linee di alimentazione indipendenti e risente molto del multipath e dello shadowing (cioè il mascheramento del segnale causato da ostacoli).
RSSI (Received Signal Strength Indication): viene riportata una discussione più
completa nei confronti dell’RSSI, dal momento che sarà il parametro utilizzato nei successivi esperimenti di localizzazione nel cassetto, presentati in questo lavoro di tesi. Come è noto, i segnali radio subiscono un’attenuazione in ampiezza [10] [15], (indicato con il termine Path Loss), in funzione della distanza percorsa nel mezzo trasmissivo ed l'RSSI è proprio legato all’"intensità" del segnale ricevuto dopo aver percorso la tratta andata e ritorno trasmettitore-target: è quindi possibile associare una distanza “d” ad ogni valore di RSSI e tali valori vengono dunque utilizzati negli algoritmi di localizzazione. Il grande vantaggio rispetto ai precedenti è quello di essere una caratteristica del segnale molto semplice da misurare, che richiede dunque un hardware elementare e dal basso costo, ma è anche quello che restituisce stime delle distanze meno accurate a causa della maggior sensibilità alle variazioni indesiderate dovute ad
Sì è fino ad ora parlato di "intensità" senza specificarne l’unità di misura per il fatto che non ne esiste una standardizzata per il parametro RSSI, bensì è necessario ogni volta specificarla per evitare ambiguità. Ci sono quattro unità di misura tipicamente utilizzate come alternative per rappresentare l’intensità del segnale ricevuto [16], anche se in ogni caso si tenga presente che potrebbero incontrarsi ulteriori definizioni di RSSI diverse da quelle che seguono, che andrebbero quindi analizzate caso per caso.
RSSI in mW (milliWatt): è probabilmente il modo più intuitivo per definire l’intensità e rappresenta la potenza ricevuta del segnale proveniente dal target, che si può identificare mediante l’equazione di Friis (generalizzata per scenari multipath mediante il parametro “n”) come (2.4):
𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅
𝑚𝑚𝑚𝑚= 𝑃𝑃
𝑟𝑟= 𝑃𝑃
𝑡𝑡�
𝐺𝐺4𝜋𝜋𝑑𝑑𝑡𝑡𝐺𝐺𝑟𝑟𝜆𝜆�
𝑛𝑛[𝑚𝑚𝑚𝑚]
(2.4) dove,Pr = Potenza Ricevuta (RSSI) [W], tipicamente convertita poi in [mW]
Pt = Potenza trasmessa, [W]
Gt,Gr = Guadagno dell’antenna trasmittente e ricevente
λ = Lunghezza d’onda del segnale [m]
d = lunghezza della tratta di andata e ritorno trasmettitore - target [m]
n = Costante di attenuazione: dipende dallo scenario ed in particolare dal tipo di
multipath in esso presente (n=2 in spazio libero)
RSSI in dBm (dBmilliWatt): la definizione è identica alla precedente, con l’unica differenza che tale valore di potenza viene espressa in dBm, in formule (2.5):
𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅
𝑑𝑑𝑑𝑑𝑚𝑚= 10 log
10�
1 [𝑚𝑚𝑚𝑚]𝑃𝑃𝑟𝑟[𝑚𝑚]� [𝑑𝑑𝑑𝑑𝑚𝑚]
(2.5) Path Loss [12]: L’RSSI può essere espresso mediante la 2.6 come l’inverso del fattore adimensionale Path Loss (il quale a sua volta è espresso in 2.7, comprensivo del percorso di andata e ritorno) e si definisce come l’attenuazione dovuta al percorso durante la propagazione nello spazio delle onde elettromagnetiche come si vede nella relazione 2.6:
𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅
𝑃𝑃𝑃𝑃=
𝑃𝑃𝑃𝑃𝑡𝑡 ℎ𝑃𝑃𝑇𝑇𝑠𝑠𝑠𝑠1= �
4𝜋𝜋𝑑𝑑𝜆𝜆�
𝑛𝑛 ∝ 𝑃𝑃𝑃𝑃𝑟𝑟 𝑡𝑡 [adimennsionale] (2.6)𝑃𝑃𝑃𝑃𝑡𝑡ℎ𝑃𝑃𝑇𝑇𝑠𝑠𝑠𝑠 = �
4𝜋𝜋𝑑𝑑𝜆𝜆�
𝑛𝑛 ∝ 𝑃𝑃𝑃𝑃𝑡𝑡 𝑟𝑟 [adimennsionale] (2.7)Inoltre esso dipende dallo scenario mediante il parametro “n” che ne caratterizza la legge di decadimento nello spazio ed è proporzionale al rapporto tra potenza trasmessa e potenza ricevuta come si può vedere dalle espressioni 2.8-2.9:
𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅
𝑃𝑃𝑃𝑃_𝑑𝑑𝑑𝑑= 10 𝑛𝑛 log
10�
4𝜋𝜋𝑑𝑑𝜆𝜆� = −10𝑛𝑛 log
10𝑑𝑑 + 𝐶𝐶(𝑛𝑛) [𝑑𝑑𝑑𝑑]
(2.8) in cui𝐶𝐶 = 10𝑛𝑛 log10�4𝜋𝜋𝜆𝜆� (2.9)
RSSI definito dallo standard IEEE 802.11 ed RSSI % [16]: lo standard IEEE 802.11 prevede un meccanismo mediante il quale l’intensità del segnale ricevuto (l’RSSI) acquisita dal ricevitore di una rete wireless, viene espressa tramite un numero intero adimensionale (un byte) variabile tipicamente nel range 0 - 255, o più in generale nel range 0 - RSSI_Max con RSSI_Max numero intero adimensionale che dipende dal produttore della rete wireless. In questo caso non si definisce un’unità di misura, in quanto tale parametro è definito dallo standard IEEE ma rimane comunque un numero arbitrario del produttore: il suo utilizzo è dunque rivolto unicamente ai circuiti ed al software del particolare trasmettitore che lo ha generato. Se ad esempio tale trasmettitore volesse inviare un pacchetto di dati sulla rete wireless, potrebbe implementare un "protocollo di anticollisione" interno che richieda di verificare se il canale sia libero (nessuno sta trasmettendo). Tale verifica può essere fatta mediante misura di questo RSSI numero intero, il quale, ad esempio, non deve superare un certo valore impostato come soglia di sicurezza (soglia trovata precedentemente in una misura di calibrazione preventiva), in modo da poter affermare che il canale non è occupato da altre trasmissioni. Infine l'RSSI può essere riportato anche in percentuale rispetto al valore di 100% dell’RSSI_Max per una maggiore facilità di comprensione.
2.1.2 Classificazione delle tecniche di localizzazione
Ogni algoritmo per RFID si basa sugli stessi principi della localizzazione indoor ampiamente noti e già applicati ad altre tecnologie, che in letteratura [17] [25] sono generalmente suddivisi in tre categorie nelle quali si sfruttano altrettanti principi di funzionamento eterogenei: Distance Estimation, Scene Analysis e Proximity.
Distance Estimation. Questa famiglia di algoritmi si basa sul calcolo di distanze
e ricorre alle proprietà dei triangoli per stimare la posizione di un target mediante triangolazione o trilaterazione [12]-[14].
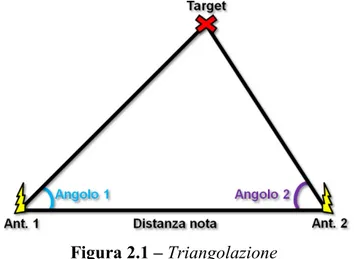
In particolare (figura 2.1) è possibile servirsi del principio della triangolazione mediante il quale, sfruttando la presenza di almeno due antenne direzionali poste in diversità spaziale [11], si misura l’angolo di incidenza dei segnali ricevuti dal target da due posizioni conosciute (AoA, Angle Of Arrival). Ovviamente il terzo angolo si ottiene per differenza dagli altri due e grazie al fatto che la conoscenza di tre angoli ed un lato permette di conoscere gli altri lati di un triangolo, mediante semplici calcoli trigonometrici si arriva alla localizzazione del target in 2D (3D con tre antenne).
Figura 2.1 – Triangolazione
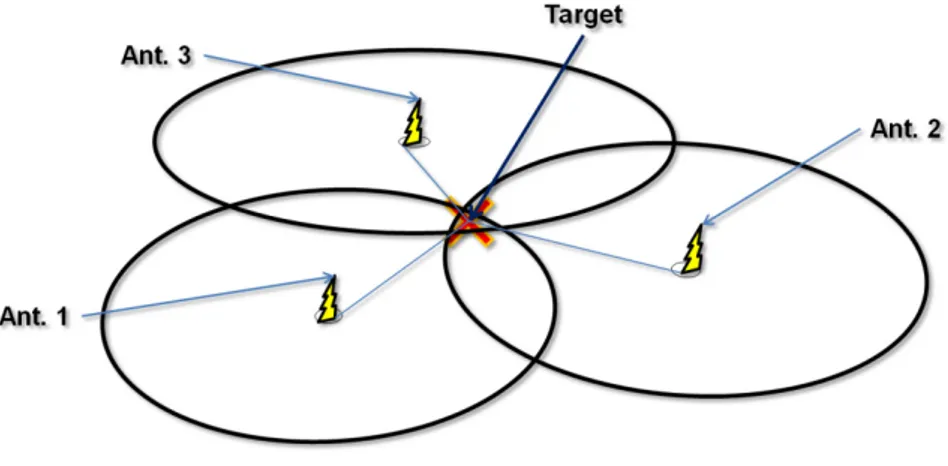
Per quanto riguarda invece il principio della trilaterazione [12] [14] sono necessarie almeno tre antenne per una localizzazione 2D (e quattro per il 3D): sfruttando uno dei parametri discussi nel precedente paragrafo, vale a dire RSSI, ToA, TDoA o PoA, si misurano le distanze di ogni antenna dal target. In questo modo ogni antenna supporrà
che il target si trovi in uno qualsiasi dei punti della circonferenza centrata sull’antenna stessa e di raggio pari alla distanza misurata (figura 2.2). Mettendo insieme le tre informazioni, cioè "intersecando" le tre circonferenze, si otterrà un punto, o meglio una zona di intersezione delle tre curve, nel quale sarà stimato il target.
Figura 2.2 - Trilaterazione
In generale quelle di Distance Estimation sono tecniche dalla bassa accuratezza e che risentono moltissimo dei problemi di multipath e shadowing [10]-[11]: con i metodi sopra esposti non si otterranno delle stime puntiformi della posizione del Target, ma piuttosto un intorno all’interno del quale esso sarà presente (questo aspetto è visibile in figura 2.2). Per ridurre questo errore, un metodo è quello di utilizzare un maggior numero di antenne per aumentare le informazioni a disposizione e calcolare la posizione del target effettuando una media, in base ad un criterio scelto, dei valori acquisiti.
Scene Analysis. Anche questa famiglia di algoritmi si basa sulle distanze
andando a considerare il confronto tra Target e Tag di riferimento. Infatti in questo tipo di configurazione vengono disposti nello scenario vari Tag in posizioni conosciute a priori, che verranno utilizzati come “ancore”(punti fissi): si noti comunque che in alternativa ai Tag si possono utilizzare anche antenne come riferimenti.
Il primo passo in questo caso consiste nell’acquisire una mappatura preventiva dello scenario grazie ai Tag o antenne di riferimento, dopodiché si può stimare la locazione di
distanza con quelli incogniti sarà inversamente proporzionale alle differenze di RSSI, ToA, TDoA, o PoA, mentre nel caso di antenne di riferimento la distanza sarà direttamente proporzionale ai livelli ricevuto del parametro utilizzato. L’algoritmo di questo genere più famoso per efficacia e semplicità è quello del k-NN (k-Nearest
Neighbor) [19]-[21], che analizzeremo ampiamente nell’ultimo capitolo.
Tipicamente, queste tecniche utilizzate in ambiente indoor, forniscono risultati molto più accurati delle precedenti triangolazioni e laterazioni e nel caso in cui si sfruttino Tag come riferimenti, hanno il vantaggio di utilizzare un numero di antenne inferiori, con ovvi benefici in termini di costi e complessità; viceversa, l’utilizzo di antenne rende l’algoritmo più resistente alle interferenze ed alle variazioni dello scenario di misura.
Proximity. Tale tecnica utilizza un elevato numero di antenne le quali vengono
disposte in modo consistente con lo scenario in questione, (ad esempio una griglia) e devono essere in numero sufficientemente elevato in modo da fornire una "copertura a celle" della zona (stesso principio della copertura a celle in una rete telefonica cellulare): in generale, la densità della disposizione delle antenne è direttamente proporzionale all’accuratezza del metodo.
La tecnica si basa sul parametro RSSI e sulla vicinanza (da qui il termine prossimità) del target Tag ad una delle varie antenne, le quali dunque funzionano da ancore. Quando infatti un Tag si trovasse nel range di lettura di una singola antenna, la sua posizione sarebbe stimata essere esattamente la stessa di quel ricevitore, se invece due o più antenne ricevessero un certo livello di segnale, allora il Tag sarebbe assunto trovarsi nella posizione dell’antenna che riceve il segnale RSSI più forte o alternativamente, nel secondo caso è possibile effettuare un "pesaggio" delle coordinate delle due antenne, utilizzando coefficienti proporzionali ai valori di RSSI, nel qual caso la tecnica tende ad assomigliare maggiormente a quelle di Scene Analysis.
Ovviamente lo svantaggio sia economico che di ingombro nell’utilizzare “N” antenne Reader anziché “N” Tag di riferimento è evidente nel caso in cui i Tag fossero passivi, ma d’altra parte è sicuramente la tecnica più semplice tra quelle qui discusse ed è probabilmente quella più resistente ad interferenze come multipath e shadowing, mentre la sua accuratezza (ma anche il costo di implementazione) si può gestire, dal momento
che dipende dall’ampiezza delle celle in range e dunque dal numero di antenne impiegate.
In base a quanto detto fino a questo punto, si riporta di seguito una tabella contenente gli algoritmi per RFID maggiormente trattati ed impiegati in letteratura [17]-[19] che si basano sulle tecniche appena discusse (Spot_ON e Landmarc sono tra le tecniche maggiormente citate in letteratura).
Nome
algoritmo Tecnica riferimento Tag di target Tag Tipologia Dimensione
Spot_on RSSI - Laterazione No Attivo 3-D
Saw-id TOA - Laterazione No Passivo 2-D
Lpm TDOA - Laterazione No Attivo 2-D
Rsp AOA - No Passivo 2-D
Landmarc [3] k-NN / RSSI Sì Attivo 2-D
Vire k-NN / RSSI Sì Attivo 2-D
Simplex k-NN / RSSI Sì Attivo 3-D
Jin et al. k-NN / RSSI Sì Attivo 2-D
R-lim Read Rate, Moving No Passivo 2-D
Tabella 2.1: Algoritmi di localizzazione RFID
Le caratteristiche decisionali riguardo la scelta di un algoritmo sono essenzialmente le seguenti:
parametro utilizzato (RSSI, ToA, TDoA, PoA, AoA, etc.); tecnica di localizzazione (triangolazioni, k-NN etc.); presenza o assenza di Tag di riferimento;
tipologia di funzionamento dei Tag: attiva passiva.
2.2 Algoritmi per Tag passivi, basati sulla potenza
Come affermato in precedenza, in questa fase vengono analizzati nello specifico gli algoritmi di localizzazione RFID e mirati all’utilizzo dell’informazione RSSI ricevuto dai Tag, o in maniera più generale, quegli algoritmi basati sulla potenza, dal momento che si prende in considerazione anche un nuovo parametro caratteristico nell’RFID, il
Read Rate, strettamente correlato alla potenza ricevuta e dunque all’RSSI. La scelta di
fondare questa ricerca su parametri proporzionali alla potenza ricevuta è giustificata dalla loro semplicità di applicazione ad algoritmi di localizzazione ed alla economicità degli apparati hardware coinvolti, i quali non richiedono complessi circuiti di sincronismo temporale o di fase, o particolari antenne per le stime degli angoli di ricezione. Naturalmente, quelli basati sulla potenza sono anche parametri meno accurati di quelli, ad esempio, basati sulle temporizzazioni (ToA etc.), ma sono stati comunque scelti proprio per i notevoli vantaggi appena citati. Inoltre per questi tipi di algoritmi è stato preferito utilizzare dei Tag passivi UHF.
Per quanto riguarda la scelta di sistemi funzionanti alle frequenze UHF piuttosto che LF o HF, i vantaggi sono stati ampiamente discussi nel primo capitolo ed essenzialmente sono una maggiore velocità di trasmissione dei dati, la portata in distanza maggiore a parità di potenza erogata (maggior efficienza energetica), la possibilità di utilizzare antenne di piccole dimensioni (Tag piccoli) ed infine le migliori proprietà di riflessione delle onde elettromagnetiche, fondamentale per permettere il funzionamento dei Tag passivi in backscattering. L’unico grande svantaggio che si riscontra nelle frequenze UHF è il drastico calo di prestazioni in presenza di materiali elettromagneticamente assorbenti, come liquidi o il corpo umano.
La scelta invece di Tag passivi piuttosto che Tag attivi, ricade sulle loro dimensioni ridotte, il loro costo estremamente basso e la non dipendenza da una fonte energetica interna (batteria, pannelli solari etc.). Si capisce come tutte queste caratteristiche siano necessarie in scenari di localizzazione per smart shelves, dove i Tag vengono disposti a breve distanza l’uno dall’altro in numero decisamente elevato: si pensi ad esempio all’applicazione di etichette per ogni medicinale in un cassetto per farmacie.
Come ultima considerazione, utile per comprendere quello che verrà discusso nei paragrafi successivi, sono le metodologie su come effettuare l’acquisizione del parametro di interesse (RSSI o Read rate) in funzione della distanza tra Tag e Reader. Dunque si possono individuare due modi:
1. è possibile acquisire una curva di valori RSSI (o Read Rate) in funzione della distanza, per vari step, ottenendo quindi un vettore di dati;
2. in alternativa si può pensare di acquisire una serie di curve caratteristiche del parametro RSSI (o Read Rate) in funzione della distanza e della potenza utilizzata in trasmissione (entrambe variabili a step) ottenendo così una matrice di dati.
2.2.1 RSSI e Tag passivi
La più ardua sfida incontrata in questo lavoro deriva dal fatto che nella letteratura più classica e generica esaminata in precedenza (si veda tabella 2.1) il parametro RSSI è largamente adoperato con Tag attivi, essenzialmente per i livelli potenza maggiori e più stabili che sono in grado di ritrasmettere e dunque facilmente rilevabili ed affetti da minori problemi di rumore o interferenza.
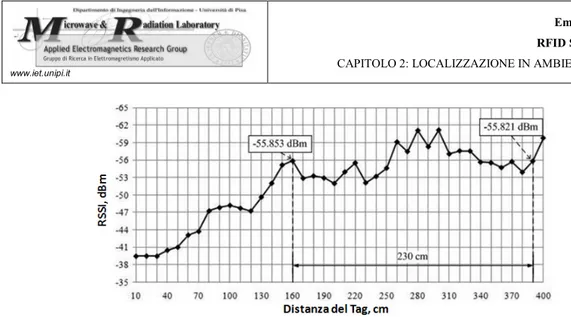
I Tag passivi, i quali rispondono con livelli di potenza inferiori e meno stabili (backscattering), vengono utilizzati maggiormente in algoritmi basati su temporizzazioni, fase o direzione di arrivo. Dal momento che stiamo trattando problematiche indoor, anche il multipath rappresenta un problema consistente e di grande rilievo: a causa di questo si sperimentano infatti ambiguità tra i valori di RSSI e le distanze associate [20] [22]. Dalla misura sperimentale riportata in figura 2.3 a pagina seguente si apprende come a due distanze anche molto diverse tra loro, può corrispondere un valore di RSSI molto simile. Sebbene sia un inconveniente che caratterizza tutti i sistemi RFID, tale problematica è maggiormente accentuata nei Tag passivi a causa proprio delle basse potenze di backscattering. Si noti infine come il fenomeno risulti molto marcato soprattutto all’aumentare della distanza.
Figura 2.3: Misura sperimentale di RSSI vs distanza su Tag passivo
Un altro problema che si sperimenta con i Tag passivi (quelli attivi non ne sono affetti) riguarda il fatto che Tag della stessa marca, modello e a parità di condizioni (distanza, potenza trasmessa dal Reader, etc.) non rispondono in generale con livelli di potenza (backscattering) uguali[20]: ciò comporta che, in presenza di due Tag passivi vicini tra loro, l’intensità del segnale di ritorno al Reader potrebbe essere anche molto diversa e dunque questa caratteristica rende ancora più difficoltosa la stima utilizzando RSSI. In figura 2.4 si riporta una misura sperimentale che mostra questo comportamento: sono stati misurati 5 Tag e i valori ottenuti sono stati normalizzati al livello di potenza ricevuta (mW) dal Tag #1, ed espressi infine in percentuale (Tag #1 è pari al 100%). Da notare che Tag dello stesso tipo possono rispondere con livelli anche molto diversi: in questo esempio con 5 UPM Raflatac Rafsec G2 si passa dal 92% al 118% circa, ma per altri modelli di Tag l’effetto può essere anche maggiore.
Figura 2.4: - % RSSI ricevuto a parità di condizioni, 5 Tag passivi “UPM Raflatac
Dalle considerazioni fatte fino a questo punto risulta quindi chiaro come, senza l’impiego di algoritmi ben studiati, la tecnica RSSI con Tag RFID in generale e con Tag passivi in particolare abbia una limitazione nell’accuratezza delle stime anche se i vantaggi della semplicità rendono appetibile l'utilizzo di tale parametro. A differenza del passato, ad oggi la maggior parte dei Reader moderni sono in grado di fornire l’indicazione RSSI come parametro di uscita dal software di gestione. In commercio si trovano dunque svariati modelli di Reader che implementano tale funzione, ne sono validi esempi gli ultimi modelli di Alien Technology come ALR-9900-EMA, gli Speedway Reader Family di Impinj o il Caen Rfid A528: quest’ultimo modello in particolare sarà quello utilizzato nelle fasi di misure in questo lavoro di tesi. Si ricordi che l’indicatore RSSI non ha un’unità di misura standard, bensì è un parametro relativo che varia da produttore a produttore e spesso anche da Reader diversi dello stesso produttore, dunque non sono generalmente confrontabili l’uno con l’altro, a meno di effettuare delle conversioni in un’unità di misura comune. Invece nei Reader più economici oppure meno recenti di quelli accennati spesso non forniscono direttamente in uscita il parametro RSSI, come accade ad esempio nel modello precedente di Alien Technology, ALR-9800: si presenta di seguito una possibile tecnica di acquisizione dell’RSSI, definita come "attenuazione a step della potenza trasmessa"[12], da adottare esclusivamente in questi casi dal momento che, tale procedura ha lo svantaggio di essere molto lenta ed elaborata.
Si supponga di trovarsi in uno scenario molto semplice, caratterizzato dalla presenza di un Tag posto ad una certa distanza da un Reader, il cui software di controllo deve almeno provvedere la possibilità di trasmettere a vari livelli di potenza selezionabili, ovvero permetta di diminuire a step successivi l’attenuazione del segnale trasmesso. Sotto queste ipotesi si effettuano interrogazioni del Tag al variare di questo parametro, per una distanza Tag – Reader fissata, in dettaglio:
1) fissando la distanza, si procede all’interrogazione del Tag sotto esame iniziando con un’attenuazione di 0dB (massima potenza trasmessa dal Reader). Nel caso in cui non si riceva alcuna risposta dal Tag ,verrà annotato un valore nullo di RSSI (indice di un
Target molto distante) e la procedura termina. Altrimenti, se è stata ricevuta una risposta comprensibile, si avanza al passo successivo.
2) L’interrogazione del Tag viene ripetuta per incrementi costanti del livello di attenuazione, ad esempio 2dB, 4dB, 8dB e così via. La dimensione dello step utilizzato, in questo esempio 2dB, influisce ovviamente sulla precisione della misura e sulla velocità della stessa.
A partire da un certo livello di attenuazione (dipendente dalla distanza) il Tag cesserà di rispondere: tale livello di attenuazione al quale ciò accade, ad esempio 50dB, fornisce un indicazione della potenza necessaria all’interrogazione del Tag, che è linearmente proporzionale alla distanza ed al valore dell’RSSI, il quale può dunque essere memorizzato come RSSI=50dB, o alternativamente come valore adimensionale pari a 50.
3) Se l’attenuazione del Reader raggiungesse il valore massimo (ad esempio 150dB) ed il Tag continuasse ancora a rispondere, l’RSSI sarebbe annotato come massimo (RSSI =150dB o 150 adimensionale), indice di un Tag molto vicino.
2.2.2 Tag Read Rate
Per mezzo di un Reader RFID si può ripetutamente interrogare Tag all’interno di una certa finestra temporale, con una velocità di lettura che tipicamente raggiunge valori dell’ordine di una acquisizione al secondo: in questo modo si può estrarre un nuovo parametro, di solito espresso in percentuale, che caratterizza il numero di letture avvenute con successo, vale a dire l’efficienza di lettura (ovvero il "Read Rate" di un Tag funzione della distanza) [23]-[24]. Infatti si mostra sperimentalmente che, utilizzando una potenza in trasmissione prefissata, quando un Tag si trovi sufficientemente vicino al Reader, esso restituisce il 100% di letture con successo ma nel momento in cui si allontani tale Tag, si riscontra un calo di efficienza in lettura in funzione della distanza. In modo duale, fissando la distanza del Tag, ci sarà un certo
livello di potenza minima del Reader in grado di leggere con una efficienza (o Read rate) del 100%, ma nel momento in cui si provi a diminuire tale potenza, l’efficienza diminuirà a sua volta in funzione della potenza del Reader.
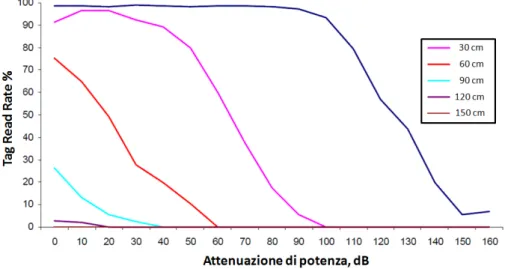
E’ possibile quindi pensare di utilizzare tale parametro come alternativa all’RSSI, dal momento che, come quest’ultimo, dipende strettamente dalla potenza. In letteratura [24] inoltre si riscontra quanto il Read Rate sia un parametro molto robusto nel confronti del multipath e grazie a misure sperimentali [23] è stato riscontrato inoltre che tale efficienza è una funzione decrescente con la distanza e con la potenza in maniera accurata, come mostra figura 2.5 in cui sono riportate delle curve caratteristiche per un Tag a differenti distanze: percentuale di risposte positive (Read Rate) in funzione della potenza trasmessa dal Reader.
Figura 2.5 – Read Rate in funzione della potenza trasmessa, misurata per varie distanze
Si constata inoltre [23] che il parametro qui discusso è precisamente "riproducibile": ripetendo l’esperimento di acquisizione per più volte a parità di condizioni, si scopre che le caratteristiche di Figura 2.5 vengono rigenerate accuratamente, dunque ognuna di quelle curve identifica univocamente la distanza alla quale è stata acquisita. Infine dal grafico si può intuire che ridurre eccessivamente lo step in distanza, in questo caso imposto a circa 30cm, renderebbe le curve poco distinguibili l’una dall’altra (aspetto
verificabile ad esempio calcolando il vettore differenza tra i dati di due curve). Questa considerazione pone ovviamente un limite alla accuratezza ottenibile, che nel caso di questo esempio vale circa 30cm.
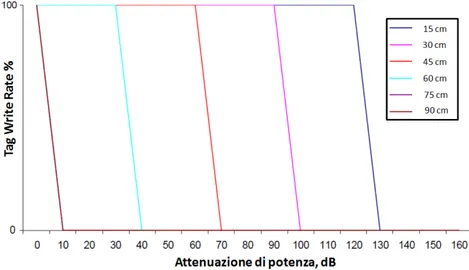
Tutte le considerazioni fatte fino ad ora riguardo l’efficienza in lettura di un Tag, possono ripetersi nel caso in cui si consideri la funzione di scrittura (programmazione) di un Tag da parte di un Reader. In questo caso il parametro equivalente prende il nome di "Write Rate": se ne riporta un grafico delle caratteristiche in figura 2.6. dal quale si possono estrarre le seguenti considerazioni:
la portata in scrittura di un sistema RFID è inferiore (circa la metà)
le curve caratteristiche del Write Rate risultano essere lineari a tratti: ciò comporta un miglioramento dell’accuratezza nelle misure a causa delle differenze tra le curve più nette.
il Write Rate induce ad una nuova idea di sviluppo: è possibile pensare di programmare i Tag a distanza per inserire l’identificativo necessario all’applicazione e nello stesso momento aggiungere nella memoria del chip il valore della distanza, la quale sarebbe stimata direttamente durante il processo di scrittura stesso.
Figura 2.6 – Write Rate in funzione della potenza trasmessa, misurata per varie
2.2.3 Metodi di calibrazione
La calibrazione del set-up di misura è un passaggio preventivo alla localizzazione con il quale si ottiene una legge matematica (modello) o, alternativamente, un database di dati RSSI o Read Rate in funzione della distanza, associato allo scenario analizzato: in questo modo, ogni volta che viene acquisito un valore di RSSI o di Read Rate, sarà possibile associare direttamente tale dato ad un valore di distanza sfruttando il modello oppure il database, senza bisogno di andarla a misurare. Si tenga presente che esistono anche algoritmi di localizzazione che non hanno bisogno di calibrazione: in questa sezione si discutono dunque due tecniche e un terzo metodo che non richiede invece la calibrazione preventiva.
Tecnica 1: calibrazione con creazione di database [23]-[24]
Uno degli aspetti fondamentali di questa tecnica di calibrazione consiste nel fatto che non viene assunto nessun modello dello scenario con formule teoriche che tengano conto del Path Loss, del multipath etc. le quali non potrebbero mai rappresentare in maniera estremamente precisa la realtà. Senza supporre niente in partenza dunque, il comportamento dello scenario viene invece interpretato sperimentalmente effettuando "misure sul campo" di RSSI (o Read Rate) da Tag posti a distanze conosciute, in modo tale da creare un database di misure (vettore o matrice, a seconda che si vari soltanto la distanza oppure anche la potenza), all’interno del quale ogni valore (oppure ogni curva caratteristica come avveniva in 2.2.2) è associato ad una particolare distanza. Nella fase successiva di acquisizione del parametro, l’associazione sarà effettuata dunque per confronto dei dati misurati con quelli presenti in database. Si supponga quindi di avere un Tag ad una certa distanza incognita per il quale sia stato acquisito il valore di RSSI o Read Rate (oppure il vettore di valori a distanza fissa ma a potenza variabile, a seconda di quale metodo di acquisizione si utilizzi, potenza fissa o variabile). Tale dato o vettore di dati verrà confrontato con quelli presenti in database: nel caso di dato singolo, esso sarà associato direttamente al valore più vicino presente in database in termini di
differenza minima, il quale poi fornirà il valore di distanza corrispondente; mentre nel caso di vettore di dati, si confronterà tale vettore mediante minimizzazione della distanza euclidea dai vettori di dati memorizzati in database.
Di seguito si riportano i passaggi da eseguire per la creazione del database: come si vede, nel caso
in cui si tenga la potenza in trasmissione fissa o variabile, la tecnica è leggermente differente:
1. vari Tag passivi vengono posti a distanze conosciute “xi” dal Reader: le posizioni
scelte ed il numero di Tag in questa fase influisce sulla precisione del database che verrà creato;
2. il Reader, eventualmente per ogni livello di potenza, altrimenti ad un unico livello
fisso, interroga ogni Tag;
3. il Reader raccoglie il dato di RSSI2 o Read Rate per ogni Tag ed eventualmente per
ogni livello di potenza;
4. nel caso in cui si sia tenuta la potenza fissa, tali valori raccolti forniranno un' unica
curva di valori RSSI in funzione della distanza. Oppure, nel caso in cui si sia variata la potenza, tali valori raccolti forniranno un database di curve caratteristiche per un Tag a differenti distanze: RSSI in funzione della potenza trasmessa dal Reader (tecnica più lenta ma teoricamente più accurata).
Tecnica 2: Calibrazione con modello di Path Loss [10] [12]
Tale calibrazione è utilizzabile solo con il parametro RSSI, in quanto i modelli di Path Loss sono sempre funzioni di potenza (e non di Read Rate) al variare della distanza. A differenza della tecnica sopra discussa, in questo caso prima di qualunque misura si assume un modello teorico di Path Loss, funzione della distanza, per lo scenario in questione: un modello riconosciuto in letteratura come tra i più accurati per ambienti
2Se RSSI non fosse direttamente disponibile al Reader si dovrebbe utilizzare necessariamente la tecnica di
attenuazione a step discussa in 2.2.1, in quel caso si potrebbe ottenere solo una singola curva di RSSI in funzione della distanza.
multipath indoor è chiamato "Log-Distance" [10] [12], del quale se ne riporta la formula di definizione espressa nella 2.9:
𝑃𝑃𝑃𝑃𝑑𝑑𝑑𝑑 = 𝑃𝑃𝑃𝑃0 𝑑𝑑𝑑𝑑 + 10𝑛𝑛 log10(𝑑𝑑) [𝑑𝑑𝑑𝑑] , (2.9)
dove “𝑃𝑃𝑃𝑃𝑑𝑑𝑑𝑑” è il Path Loss (misurato in dB) e
d
è la distanza tra Reader e Tag(variabile).
Ricordando infine che una delle possibili definizioni per il parametro RSSI corrisponde proprio all’inverso (in scala lineare) del Path Loss, si può scrivere (2.10):
𝑃𝑃𝑃𝑃𝑑𝑑𝑑𝑑 = −𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑑𝑑𝑑𝑑 (2.10)
Nella 2.9 si noti la presenza di due parametri incogniti: la costante “𝑃𝑃𝑃𝑃0 𝑑𝑑𝑑𝑑” ed il
parametro “n” (che caratterizza il livello di multipath). Lo scopo della calibrazione è proprio quello di ricavare questi due parametri, in modo da ottenere una relazione di Path Los che corrisponderà esattamente alla curva di calibrazione cercata: RSSI in funzione della distanza. Per ricavare dunque i due parametri incogniti, vari Tag passivi vengono posti nell’ambiente di misura in posizioni “
d”
differenti e conosciute: tramite interrogazione di questi Tag si acquisiscono vari valori di RSSI per diverse distanze d1,d2….dn, che possono essere inserite nel modello come segue (2.11-2.13):
−𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑑𝑑𝑑𝑑1 = 𝑃𝑃𝑃𝑃0 𝑑𝑑𝑑𝑑 + 10𝑛𝑛 log10(𝑑𝑑1) (2.11)
−𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑑𝑑𝑑𝑑2 = 𝑃𝑃𝑃𝑃0 𝑑𝑑𝑑𝑑 + 10𝑛𝑛 log10(𝑑𝑑2) (2.12)
[…]
−𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑑𝑑𝑑𝑑𝑛𝑛 = 𝑃𝑃𝑃𝑃0 𝑑𝑑𝑑𝑑 + 10𝑛𝑛 log10(𝑑𝑑𝑛𝑛) (2.13)
Mettendo a sistema queste equazioni del modello (una equazione per ogni distanza) si ottengono le calibrazioni dei valori incogniti (𝑃𝑃𝑃𝑃0 𝑑𝑑𝑑𝑑 ed n): naturalmente sarebbero
sufficienti due equazioni in quanto le incognite sono soltanto due, ma sfruttandone un numero maggiore, ad esempio una decina, si può ottenere un dato più preciso, tramite medie quadratiche nel sistema sovradimensionato. Una volta conosciuti i parametri incogniti del modello, avremo ottenuto la curva di Path Loss (o in maniera equivalente di RSSI),calibrata sullo scenario e da utilizzare in fase di misura.
Tecnica 3: confronto diretto
Un modo alternativo alla calibrazione preventiva per associare un valore di RSSI o di Read Rate ad una distanza è quello di confrontare direttamente il valore del parametro ricevuto dal Tag incognito con quello ottenuto da vari Tag di riferimento presenti nello scenario a distanze conosciute a priori: la distanza associata del Tag incognito sarà quella del Tag di riferimento che risponde con il livello più vicino al parametro RSSI. Si sostituisce dunque il database con i Tag di riferimento, i quali contengono le stesse informazioni. Questa terza tecnica sulla quale si basa ad esempio k-NN (k-Nearest Neighbor) è estremamente interessante in quanto la calibrazione non è più necessaria e soprattutto in un unico passaggio si ottiene direttamente la localizzazione di un Tag.
2.2.4 Prestazioni dei Tag passivi in base all’orientazione
Un altro fattore estremamente importante quando si parla di localizzazione basata sulla potenza per sistemi RFID è l’orientazione assunta dai Tag nello scenario di misura, in quanto strettamente correlata ai livelli di potenza di backscattering. Per un buon funzionamento in tutte le condizioni possibili i Tag RFID dovrebbero avere un comportamento invariante rispetto all’orientamento assunto, ma intuitivamente si comprende come il livello di intensità della potenza ricevuta da un Reader dipenda anche da questo fattore. Quindi potrebbe accadere che Tag a distanze simili rispondano con valori di RSSI o Read Rate anche molto diversi tra loro a causa dell’orientazione assunta e questo naturalmente renderebbe l’associazione con la distanza estremamente complicata.
Per questo motivo è necessario fare un'analisi di alcuni risultati scientifici riguardo al comportamento dei Tag passivi al variare della loro orientazione, aspetto critico nelle applicazioni reali, in quanto può essere impossibile conoscere a priori come verranno posizionati i Tag e in ogni caso è importante capire quale sia il modo migliore di disporli sul campo e soprattutto quanto ciò influisca o meno sul buon funzionamento del sistema.
In letteratura si possono trovare sia risultati di misure effettuate in un ambiente eletrromagneticamente isolato ( ad esempio in camera anecoica) che misure ottenute in scenari reali in modo tale anche da capire quanto gli agenti esterni influiscano sulla misura. Un esempio di test effettuato in camera anecoica è esposto in [26] in cui però viene utilizzato come parametro di confronto la variazione dell' Error Rate % (definito come “100% − 𝑅𝑅𝑅𝑅𝑃𝑃𝑑𝑑 𝑅𝑅𝑃𝑃𝑡𝑡𝑅𝑅%”) in funzione del grado di orientazione per più modelli di Tag, il tutto al variare della orientazione dei Tag ruotati lungo i due assi orizzontale e verticale. Il risultato è visibile in figura 2.7, nella quale l’asse circolare rappresenta l’orientazione [gradi], mentre l’asse verticale rappresenta l’attenuazione [dBm] richiesta per ottenere un Error Rate del 50%.
Figura 2.7 - Andamento dell’Error Rate con l’orientazione per 4 tipi di Tag
I Tag passivi testati sono i seguenti: Tag_A: prototipo non specificato Tag_B: Avery Dennison AD-610 Tag_C: Alien Technology AL-9338-02 Tag_D: Avery Dennison AD-410
Come ci si poteva immaginare la leggibilità dei Tag varia in maniera molto significativa con l’orientazione che diventa quindi un parametro da tenere in forte considerazione, si nota infatti che solamente due di esse (in questo esempio 0° e 180°) forniscono buoni
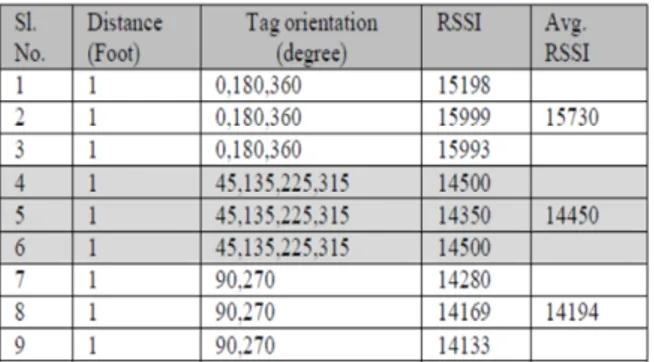
risultati. Al variare del modello di Tag invece si nota che le curve vengono traslate in potenza continuando ad avere però gli stessi andamenti con l’orientazione. Un esempio invece di misura di scenario realistico è esposto in [24] in cui viene stavolta preso come parametro l'RSSI3 su di un unico Tag, un UPM Raflatac.
Il Tag è stato posto a distanza fissa e misurato il suo valore di RSSI per tre diverse orientazioni, dove 0° corrisponde ad un posizionamento dell’antenna del Tag in adattamento di polarizzazione con quella del Reader. In figura 2.8 e tabella 2.2 si presentano i risultati dai quali si riscontra un calo drastico dell’RSSI ricevuto (rappresentato qui come numero adimensionale) all’allontanarsi dalla condizione di adattamento in polarizzazione.
Tabella 2.2 – RSSI al variare dell’orientazione di un Tag passivo
Figura 2.8 – RSSI al variare dell’orientazione di un Tag passivo
3Si tenga presente che anche l'RSSI, così come il Read Rate è un parametro direttamente proporzionale
2.3 Descrizione degli algoritmi
Dopo aver ampiamente discusso i parametri di un sistema RFID basati sulla potenza, passiamo alla descrizione degli algoritmi per localizzazione di Tag passivi che sfruttano RSSI o Read Rate. Nel seguito vengono illustrate quattro tecniche per la localizzazione in due dimensioni, 2-D (estendibili al 3-D o anche adottabili al più semplice 1-D) specificatamente pensate per l’implementazione in Smart Shelves (scaffali, cassetti etc.) o in altri tipi di scenari indoor. Tali tecniche si basano tutte sulla presenza di Tag di riferimento o alternativamente di antenne Reader multiple utilizzate come "ancore" (riferimenti).
E’ da tenere presente il fatto che in alcuni casi potrebbe essere sufficiente una localizzazione 1-D ed in base all’applicazione, da valutare caso per caso, potrebbero essere sufficienti le conoscenze analizzate fino a questo momento (paragrafo 2.3), le quali permettono già una stima della distanza in funzione del valore del parametro acquisito (vedi le calibrazioni), in modo più semplice e rapido. E’ comunque da aggiungere che l’utilizzo di uno degli algoritmi di seguito discussi, quasi certamente apporta accuratezze migliori anche nel caso di stime in un'unica dimensione e spesso rende la calibrazione un procedura evitabile.
2.3.1 Laterazione su Tag di riferimento
Quella che segue può catalogarsi come tecnica mista di Distance Estimation e Scene Analysis, per il fatto che si basa sull’idea della laterazione [12] [14], dunque appartenente alla prima famiglia di algoritmi, ma che sfrutta anche la presenza di Tag di riferimento, tipici della seconda famiglia, ed infine si noterà di seguito che questa tecnica ha bisogno inoltre di una calibrazione preventiva.
L'idea che sta alla base della laterazione è che conoscendo le distanze da (almeno) tre punti di riferimento, che in questo caso sono i tre Tag di riferimento, si può identificare univocamente la posizione incognita. Bisogna considerare che, sebbene possano
teoricamente risultare sufficienti le distanze da tre punti per una localizzazione in due dimensioni (trilaterazione), l’utilizzo di un maggior numero di riferimenti (multilaterazione) è sempre preferibile per aumentare l’accuratezza dei risultati. Questo aspetto viene mostrato schematicamente in figura 2.9: nell’immagine (a) abbiamo la stima della posizione di un Target rappresentata dall’area in giallo, utilizzando tre riferimenti (antenne o Tag), mentre nell’immagine (b) è stato introdotto in posizione strategica un quarto riferimento, la cui circonferenza, intersecandosi con le altre provoca la riduzione dell’area di stima del Tag (ancora in giallo).
(a) (b)
Figura 2.9 – Laterazione al variare del numero di riferimenti utilizzati
Come abbiamo dunque intuito, uno degli aspetti più interessanti (ereditato dall’algoritmo per Tag attivi, Landmarc [19]), è che la localizzazione dei Tag è effettuata misurando la distanza da “K” Tag di riferimento, piuttosto che da “K” antenne Reader (come avveniva in 2.1.2), che risulterebbe molto più costoso, oltre che ingombrante.
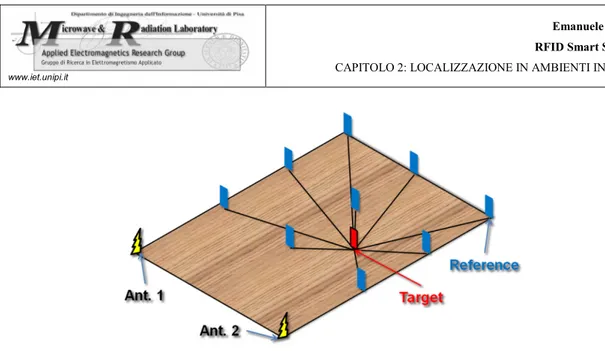
Entrando nei dettagli [12] del metodo dunque, viene disposta nello scenario una griglia di Tag di riferimento (identificati in blu all’interno di figura 2.10 a pagina seguente), le cui posizioni note sono utilizzate per determinare la posizione del Tag incognito (rosso, in figura 2.10 a pagina seguente): per i calcoli delle distanze sono necessarie e sufficienti due antenne poste in prossimità della griglia e distanziate di un certo step.
Figura 2.10 - Localizzazione del Tag incognito mediante multi-laterazione
La figura 2.11 mostra la geometria e nelle 2.14-2.15 vengono espresse le formule trigonometriche implicate nella misura delle “K” distanze “𝑇𝑇𝑖𝑖” tra l’unico Tag incognito
dell’esempio ed il Tag di riferimento i-esimo. Riguardo alle due antenne A0 ed A1 non è necessario conoscerne le coordinate, bensì solamente la distanza relativa.
𝑇𝑇𝑖𝑖 = ��𝑑𝑑𝑖𝑖1�2+ |𝑑𝑑𝑡𝑡1|2− 2�𝑑𝑑𝑖𝑖1�|𝑑𝑑𝑡𝑡1| cos(𝜙𝜙𝑖𝑖− 𝜃𝜃) (2.14)
𝜙𝜙𝑖𝑖 = cos−1�|𝑑𝑑12|2+ �𝑑𝑑𝑖𝑖1�2− �𝑑𝑑𝑖𝑖2�2/2|𝑑𝑑12|�𝑑𝑑𝑖𝑖1�� (2.15)
Sfruttando uno dei parametri discussi, vale a dire RSSI oppure Read Rate, inizialmente è necessaria l’esecuzione di una preventiva calibrazione, come quella mediante modello di Path Loss oppure mediante database, con i Tag di riferimento già posizionati in modo strategico. Dopodiché le due antenne A0 ed A1, interrogando lo scenario, acquisiranno l’RSSI (o Read Rate) dal Tag incognito e, grazie al database della calibrazione, si risalirà al valore della distanze “𝑑𝑑𝑡𝑡𝑇𝑇0, 𝑑𝑑𝑡𝑡𝑇𝑇1” dal Tag incognito“t”. Le distanze “𝑑𝑑𝑖𝑖𝑇𝑇0, 𝑑𝑑𝑖𝑖𝑇𝑇1” delle
antenne A0 ed A1 da tutti i Tag di riferimento“i” sono conosciute a priori, quindi, conoscendo anche la distanza”𝑑𝑑12” tra le due antenne e utilizzando i calcoli
trigonometrici mediante le formule 2.14-2.15 si arriva a trovare le distanze “𝑇𝑇𝑖𝑖” del Tag
incognito da ognuno dei Tag di riferimento.
Una volta note le distanze “𝑇𝑇𝑖𝑖”, l’ultimo passaggio del metodo consiste, sfruttando la
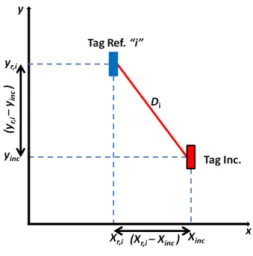
laterazione ed un sistema di riferimento cartesiano, nel risalire alle coordinate della posizione del Tag, tramite un sistema di equazioni: le “K” equazioni che permettono di fare ciò sono semplici relazioni pitagoriche sulle coordinate dei Tag e sono espressi nella 2.16 (vedi figura 2.12):
�𝑥𝑥𝑟𝑟,𝑖𝑖− 𝑥𝑥𝑖𝑖𝑛𝑛𝑖𝑖�2+ �𝑦𝑦𝑟𝑟,𝑖𝑖 − 𝑦𝑦𝑖𝑖𝑛𝑛𝑖𝑖�2 = 𝑇𝑇𝑖𝑖2 (2.16)
in cui �𝑥𝑥𝑟𝑟,𝑖𝑖 ; 𝑦𝑦𝑟𝑟,𝑖𝑖� sono le coordinate (conosciute) del reference Tag i-esimo, mentre
(𝑥𝑥𝑖𝑖𝑛𝑛𝑖𝑖 ; 𝑦𝑦𝑖𝑖𝑛𝑛𝑖𝑖) sono le coordinate del Tag incognito (vedi figura 2.12).
Figura 2.12 - Calcolo delle coordinate del Tag incognito mediante riferimento
Come abbiamo già accennato, in un algoritmo di laterazione in 2-D, avere più di tre coordinate di riferimento conosciute e dunque più di tre equazioni, porta ad un sistema sovradimensionato, il che si riflette in una maggior informazione sullo scenario utile a migliorare l’accuratezza della stima finale: per risolvere il sistema sovradimensionato è possibile effettuare delle medie quadratiche sul sistema di equazioni [12]. In figura 2.13 si riportano gli errori di misura e dunque il livello di accuratezza di questa tecnica, utilizzando 9 Tag di riferimento[12]: per distanze fino a 1-1.5m dalle antenne del Reader si sperimentano errori di misura medi dell’ordine di 30-35cm, per distanze superiori, vale a dire da 1.5 a 2.5 metri, l’errore sale decisamente arrivando a medie di circa 70cm.
Figura 2.13 – Vista 3-D dell’errore di misura in funzione della distanza dalle antenne
2.3.2 Tecnica delle interferenze
E’ interessante notare che la seguente tecnica di localizzazione è stata ideata [22] per applicazioni di tipo smart shelf (figura 2.14) e pensata ad una possibile implementazione in uno scenario come può essere quello di una biblioteca o di un magazzino. Il sistema quindi è stato testato all’interno di un mobile a ripiani.
Figura 2.14 – Schema di principio per una Smart Shelf
Passando alla descrizione del principio di funzionamento, si parta col dire che questa tecnica rientra nella famiglia degli algoritmi di Scene Analysis, non richiede una calibrazione preventiva e sfrutta Tag di riferimento che devono essere disposti nello scenario in maniera abbastanza densa, ad esempio lungo gli scaffali di un mobile, insieme ovviamente ad i Tag incogniti; si serve poi di un’unica antenna posizionata all’esterno del mobile ad una distanza adeguata (in Far Field) che permetta di leggere tutti i Tag presenti nello scenario (figura 2.14).
La localizzazione è basata sull’interferenza che nuovi Tag incogniti inseriti nello scenario, oppure presenti e spostati in altre posizioni, producono sui Tag di riferimento, interferenza basata sulla variazione del parametro RSSI: un pesante limite di questo
algoritmo di localizzazione è il fatto che possa stimare la posizione di Tag che vengano inseriti, oppure spostati, all’interno dello scenario, ma non è in grado di localizzare Tag che vi si trovavano già in precedenza . Comunque questa tecnica delle interferenze permette di ottenere precisioni di localizzazione che, in uno scenario tipico come quello descritto, possono arrivare anche a soli 10cm di errore [22].
Il funzionamento si può suddividere in tre fasi A, B e C.
A - Fase iniziale. Si supponga di aver posizionato sia tutti i Tag di riferimento
che quelli incogniti: il sistema interroga tutti i Tag nello scenario acquisendone i valori RSSI, eseguendo poi un ciclo di interrogazioni ad intervalli di tempo regolari e tenendo in memoria la lista di tutti (e solo) gli RSSI al ciclo precedente ed al ciclo attuale.
B - Rilevamento delle interferenze e selezione del gruppo di Tag. Si immagini
che ad un certo punto un nuovo Tag incognito venga inserito nello scenario, oppure che un Tag incognito già presente venga spostato in una locazione differente: durante il ciclo di interrogazioni successivo, si apprenderà che gli RSSI dei Tag di riferimento avranno subito delle variazioni a causa dell’interferenza dovuta alla modifica della scena (anche quelli incogniti, ma l’algoritmo non ne è interessato). Sfruttando questo fenomeno, l’algoritmo seleziona i Tag di riferimento più "utili" che verranno poi considerati per stimare le coordinate del Tag inserito o spostato, dovuto al fatto che questi saranno quelli che avranno subito il maggior livello di interferenza in valore assoluto, ovvero riassumendo in quattro punti:
1) si calcolano i valori assoluti “𝐸𝐸𝑖𝑖𝑛𝑛” delle differenze tra RSSI attuali ed RSSI al
ciclo precedente, per ogni Tag di riferimento i-esimo (2.17): 𝐸𝐸𝑖𝑖𝑛𝑛 = �𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅
𝑖𝑖𝑛𝑛 − 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑛𝑛−1� (2.17)
dove “n” è il riferimento del ciclo n-esimo. 2) Si calcola una soglia come espresso dalla 2.18:
𝑃𝑃
𝑛𝑛=
1𝐾𝐾
∑
𝐾𝐾𝑖𝑖=1𝐸𝐸
𝑖𝑖𝑛𝑛(2.18)
in cui “K” è il numero totale dei Tag di riferimento (i=1….K).
La soglia “𝑃𝑃𝑛𝑛” rappresenta la media delle variazioni di RSSI da tutti i Tag di
fornire un valore minimo di variazione RSSI oltre al quale si parla di interferenza: in questo modo, se tutti i Tag subissero contemporaneamente una brusca variazione di RSSI dovuta a fenomeni globali come ad esempio una variazione di temperatura, tali modifiche non sarebbero erroneamente considerate dall’algoritmo come interferenze dovute all’inserzione di un nuovo Tag.
3) Si confronta ogni differenza “𝐸𝐸𝑖𝑖𝑛𝑛” con la soglia “
𝑃𝑃
𝑛𝑛”.
4) A questo punto si identificano tre casi:
- nel primo se il sistema rileva una variazione di interferenza da qualche Tag di riferimento superiore alla soglia “
𝑃𝑃
𝑛𝑛”
e se riscontra un incremento del numero di Tag, deciderà che è presente un nuovo Tag nello scenario. Parte dunque una fase di "raggruppamento" dei Tag di riferimento in cui il sistema seleziona solo quelli in cui la variazione “𝐸𝐸𝑖𝑖𝑛𝑛” è maggiore della soglia “𝑃𝑃
𝑛𝑛”
. Il sistema è migliorabilecon un’ulteriore tecnica di raffinamento [20] [22]dove si considerano solamente Tag fisicamente vicini l’uno all’altro: se un Tag isolato produce un grande valore di interferenza, non viene comunque considerato, in quanto lontano dal gruppo (è un problema che si presenta a causa del multipath, vedi figura 2.3).
- Nel secondo caso invece se il sistema rileva una variazione di interferenza da qualche Tag di riferimento superiore alla soglia “
𝑃𝑃
𝑛𝑛”
, ma trova un numero invariato di Tag nello scenario, decide che un Tag è stato riposizionato nell’area di interrogazione: come prima cosa dunque viene identificato il Tag incognito riposizionato come quello che ha subito la più forte variazione di RSSI dal ciclo precedente. Poi, a differenza del caso 1, saranno presenti due gruppi di Tag di riferimento che avranno subito interferenze maggiori: quelli vicini alla vecchia posizione e quelli vicini alla nuova posizione del Tag spostato: per il calcolo delle coordinate si utilizzeranno solamente quelli vicini alla nuova posizione, i quali saranno identificati come quelli del gruppo che mediamente hanno subito maggior interferenza.- Infine nell'ultimo caso il sistema si accorge che un Tag è stato tolto dallo scenario quando non lo rileva.
C - Fase della Localizzazione. Arrivati a questo punto, le coordinate del Tag
incognito vengono stimate calcolando una media pesata di quelle dei Tag di riferimento selezionati in base all’algoritmo analizzato nella fase B. Se si suppone di aver selezionato al passo precedente un gruppo di “G” Tag di riferimento: le coordinate di questi Tag selezionati verranno considerate tutte, ma ognuna sarà pesata in base al livello di interferenza che i Tag hanno subito.
Per tenere conto di questo, viene calcolato un fattore di pesaggio “
𝑝𝑝
𝑠𝑠𝑛𝑛”
per ogni Tag s-esimo del gruppo espresso nella 2.19:𝑝𝑝
𝑠𝑠𝑛𝑛=
𝐸𝐸𝑠𝑠𝑛𝑛
∑𝐺𝐺𝑗𝑗=1𝐸𝐸𝑗𝑗𝑛𝑛 (2.19) dove:
n è l'indice del ciclo n-esimo.
g è il numero totale di Tag di riferimento selezionati dai K, per il calcolo delle
coordinate.
s è l' indice fisso del Tag di riferimento del quale stiamo calcolando il peso 𝑝𝑝𝑠𝑠𝑛𝑛.
j è l'indice mobile dei Tag di riferimento selezionati ( j=1…G).
i è l'indice mobile (non è in formula) di tutti i K Tag di riferimento ( i=1…K).
Tale fattore di pesaggio sarà maggiore per i Tag che hanno subito maggior interferenza 𝐸𝐸𝑠𝑠𝑛𝑛, dopodiché si calcolano le coordinate incognite (𝑅𝑅𝑥𝑥, 𝑅𝑅𝑦𝑦) grazie alla nota
formula della media pesata(2.20):
(𝑅𝑅𝑥𝑥, 𝑅𝑅𝑦𝑦) = ∑𝐺𝐺𝑠𝑠=1𝑝𝑝𝑠𝑠𝑛𝑛(𝑥𝑥𝑠𝑠, 𝑦𝑦𝑠𝑠) (2.20)
in cui (𝑥𝑥𝑠𝑠, 𝑦𝑦𝑠𝑠) sono le coordinate conosciute dei Tag di riferimento s-esimi (dove ora
s=1…G)
Accuratezza del metodo delle interferenze. Di seguito si riporta un’immagine
(figura 2.15) del set-up di misura utilizzato in un esempio di applicazione [22] di questa tecnica, mentre in figura 2.16 (a pagina seguente) si riporta un grafico, riferito allo stesso scenario, in cui si notano l'effetto delle variazioni che subisce il parametro RSSI proveniente dai Tag di riferimento durante l’inserimento nello scaffale di nuovi Tag; le label T1…T9 si riferiscono proprio ad i nuovi Tag di volta in volta inseriti.
Figura 2.15 – Set-up di misura di un esempio di Smart Shelf basata sulle interferenze
Figura 2.16 –Misure di interferenza sull’RSSI, durante l’inserimento di nuovi Tag
(T1…T9)
2.3.3 L-VIRT (Localization - VIrtual Reference Tag)
Questa tecnica di localizzazione [25], la quale si cataloga esattamente all’interno della famiglia degli algoritmi Proximity, è basata sulla dislocazione di antenne Reader dalla posizione e dal read range noti, le quali serviranno da ancore per le stime delle coordinate e come si vede in seguito, la densità del loro collocamento influisce drasticamente sulle prestazioni dell’algoritmo. Fa uso inoltre di Tag di riferimento
“virtuali” che verranno descritti successivamente. Tra quelle analizzate fino ad ora probabilmente L-VIRT è la tecnica più semplice e veloce sia da un punto di vista computazionale che pratico nell'’installazione e che oltretutto produce ottimi risultati con costi ridotti. Si capirà che è un algoritmo facilmente concepibile per localizzazione in scenari come stanze o grandi magazzini, ma sicuramente può adattarsi anche ad una smart shelf.
Il metodo necessita di varie antenne Reader che vengono disposte nello scenario ad intervalli regolari in posizioni strategiche, ad esempio ai quattro angoli di una stanza di medie dimensioni, assicurandosi che la loro copertura sia tale da permettere ad un Tag incognito disposto nello scenario di rientrare sempre nel range di lettura di almeno un’antenna Reader: i Reader possono avere range differenti oppure identici, non è un vincolo restrittivo del metodo, è importante in ogni caso che siano range di copertura fissi. Non è richiesta nessuna calibrazione, se escludiamo la misurazione preventiva del range di lettura delle antenne, i quali da ora in poi verranno supposti coincidenti per ogni Reader solo per una questione di chiarezza nell’esposizione.
L’approccio di misura si basa su due principi, il primo dei quali è quello dei vincoli di connettività correlati al read range: si supponga che un’antenna Reader sia in grado di leggere un Tag” T”, questo sta a significare che “T” si trova nel suo range di lettura (è un vincolo inclusivo); viceversa, se un Reader non riesce a leggere un Tag, questo implica che tale Tag si trova al di fuori del range di lettura (vincolo esclusivo). E’ chiaro che questo approccio è strettamente correlato al parametro RSSI restituito dai Tag, anche se qui è sufficiente analizzare il comportamento di lettura / non lettura, senza andare a misurare il livello (in Watt, dBm etc.) dell’RSSI.
Il secondo principio che viene sfruttato è quello dei Tag di riferimento virtuali: si effettua una discretizzazione dello spazio, simulando una griglia di Tag di riferimento: non è necessario installare nessun Tag reale, ma si immagina che in ogni punto della griglia virtuale ci sia un Tag dalle coordinate note.
Dunque si analizzi la figura 2.17 a pagina seguente in cui si suppone di trovarsi in un ambiente 2D con quattro Reader ed in presenza di un unico Tag incognito inserito nello
Figura 2.17 – Esempio di vicoli inclusivi ed esclusivi applicati a Tag virtuali in 2D
(a) I Reader #1 #2 e #4 possono leggere il Tag incognito e ne identificano la zona di appartenenza mediante l’intersezione dei tre cerchi individuando il range in lettura (vincoli inclusivi).
(b) Si sfrutta anche l’informazione del Reader #3 il quale, non leggendo il Tag incognito, fornisce un vincolo esclusivo che mediante intersezione, riduce l’area della zona di appartenenza.
(c) E’ mostrata la zona di localizzazione del Tag ottenuta sfruttando le informazioni di connettività inclusiva (a) ed esclusiva (b) dalle varie antenne.
(d) Utilizzando lettori mobili in aggiunta a quelli fissi è possibile ridurre ulteriormente la regione di incertezza[25]
Una volta nota la regione di appartenenza del Tag incognito, visibile in figura 2.17-c, al suo interno saranno contenuti vari Tag virtuali, vale a dire vari punti della griglia dalle posizioni note.
Di conseguenza, l’ultimo passaggio consiste nel calcolare la media delle coordinate di tutti questi Tag virtuali, ottenendo la stima delle coordinate dal Tag incognito che sarà quindi localizzato nel baricentro della zona individuata.
Accuratezza del metodo. Si riportano di seguito alcuni risultati sperimentali
[25] di accuratezza dell’algoritmo al variare del distanziamento e dunque del numero totale o densità delle antenne Reader.
A causa dello scenario multipath le zone di read range delle antenne non disegneranno in realtà cerchi perfetti (2D): infatti, a causa delle riflessioni può accadere che un punto all’interno del teorico cerchio che individua il range, non venga raggiunto dall’antenna e viceversa può accadere che un punto esterno a tale cerchio sia invece coperto dal fascio dell’antenna; di conseguenza, per tenere conto di questi fenomeni è stato introdotto un modello di Path Loss a comportamento gaussiano, Log-Distance (lo stesso già incontrato nella tecnica di calibrazione con modello), il quale modellerà la forma delle celle in range al variare del un parametro di deviazione standard “σ”[25] che, come mostrato in tabella 2.3, dipende dallo scenario in cui ci troviamo.
σ
Scenario
0 Ideale
1 Spazio Libero
5 Mediamente ostruito
10 Densamente ostruito
Tabella 2.3 - Valori assunti dal parametro “σ” nel modello di Path Loss Log-Distance
Figura 2.18 - Accuratezza delle misure di stima delle coordinate di un Tag (L-VIRT)
In scenari poco ostruiti, caratterizzati cioè da un basso livello di interferenze multipath e dunque da un σ piccolo, i risultati sono migliori come era logico aspettarsi. Nel caso
σ =1, l’errore di stima, al variare della spaziatura tra le antenne, rientra nel range da 15 a
125cm: il consistente incremento dell’errore a partire da 4m di spaziatura deriva dal fatto che tale valore è il read range medio dei Reader utilizzati in questo particolare esperimento. L’aumento dell’errore poi va di pari passo con l’incremento dei valori di σ, vale a dire del peggioramento dell’interferenza multipath, che deformando i cerchi di range delle antenne, altera il corretto funzionamento dell’algoritmo.
2.3.4 k-NN (k-Nearest Neighbor): cenni
La tecnica di localizzazione del k-NN[19]-[21] è già stata accennata in precedenza, ed anch’essa rientra nella famiglia degli algoritmi di Scene Analisys; infatti è fondata su Tag di riferimento ed in particolare sul confronto dell’RSSI o del Read Rate tra i Tag di riferimento stessi ed i Tag incogniti; inoltre non richiede calibrazioni. Ne rimandiamo ulteriormente la descrizione dettagliata che sarà analizzata nei particolari all’interno dei capitoli riguardanti la fase delle misure, dal momento che k-NN è l’algoritmo selezionato per l’implementazione del "cassetto intelligente".
2.3.5 Analisi delle tecniche discusse: vantaggi e svantaggi
E’ possibile, a questo punto, riepilogare sinteticamente le tecniche discusse, con lo scopo di effettuare un confronto dei vantaggi e degli svantaggi per quanto riguarda i costi, la complessità, l’accuratezza ed il livello di utilità pratica in scenari di smart shelves. Per un’esposizione più schematica indicheremo le tecniche come di seguito:
Tecnica 1: Laterazione su Tag di riferimento Tecnica 2: Interferenze
Tecnica 3: L-VIRT
Tecnica 4: k-NN (anche se non ancora descritta nel dettaglio, la riportiamo nel confronto)
Analisi dei costi. Le tecniche 1, 2, 4 sono caratterizzate da costi simili ed
abbastanza contenuti per il fatto che utilizzano Tag di riferimento passivi ed un unico Reader connesso ad una o al massimo due antenne: all’aumentare delle dimensioni dello scenario è sufficiente incrementare il numero dei Tag di riferimento inseriti, dal costo estremamente basso, oltre che la potenza in trasmissione (pochi milliWatt). La tecnica 3 è più onerosa dal momento che necessita della dislocazione di molte antenne, le quali, anche se di tipo economico fanno purtroppo incrementare il costo (numero di connessioni maggiori) ed il numero di Reader: si consideri anche che all’aumentare delle dimensioni dello scenario è necessario incrementare il numero di tali antenne in maniera adeguata alla densità necessaria.
Analisi della complessità. La tecnica 1 (laterazione) è molto complessa per i
seguenti motivi:
è necessaria una calibrazione preventiva;
è necessario trovare la giusta dislocazione dei Tag di riferimento, mediante test per individuarne il numero e le posizioni che minimizzano gli errori di misura; i calcoli matematici necessari sono estremamente elaborati.
La tecnica 2 (Interferenze) ha gli stessi problemi della precedente riguardo la dislocazione dei Tag di riferimento, ma un grande vantaggio è che non è necessaria una
calibrazione preventiva del sistema, il che si traduce in maggior velocità delle misure. Inoltre i calcoli matematici coinvolti sono più semplici. L’identificazione di un nuovo Tag viene eseguita velocemente, ma è da tenere presente che si può inserire o spostare solo un Tag per volta, quindi, pensando alla catalogazione di libri in una biblioteca ha una inizializzazione di database con tempi lunghi: si potrebbe pensare ad una tecnica preventiva per l’inizializzazione.
La tecnica 3 (L-VIRT) è sicuramente la più semplice ed agevole delle tre: non ha Tag di riferimento, il che si traduce in una bassissima complessità di installazione e manutenzione del sistema e la localizzazione risulta estremamente veloce. Inoltre non necessita la misura di parametri come RSSI essendo sufficiente capire se si riceve o meno risposta da un Tag. I calcoli coinvolti nella localizzazione sono i più semplici fino ad ora analizzati.
La tecnica 4 (k-NN) ha gli stessi problemi logistici di 1 e 2 riguardo la dislocazione dei Tag di riferimento, ma come la tecnica 2 non necessita di una calibrazione preventiva. I calcoli matematici coinvolti sono più agevoli e semplici, ai livelli di tecnica 3 e dunque k-NN è preferibile sicuramente alla tecnica 1.
Analisi di accuratezza. Non è semplice, senza prima effettuare dei test a parità
di condizioni, affermare quale tecnica sia la più accurata in termini errore nella stima delle coordinate: in questa fase è solamente possibile riportare i livelli di errore riscontrati nei vari documenti tecnici in letteratura [12] [19]-[22] [25]. Nella tecnica 1 sono dell'ordine di 30cm per distanze fino a 2 metri, dopo di ciò il livello aumenta drasticamente per distanze maggiori. Nella tecnica 2 le accuratezze sono migliori, si arriva anche a 10cm di errore per distanze di circa 2m. In base al tipo di materiale "taggato", l’errore sale a circa 20cm nel caso di, ad esempio, uno scatolone contenente bottiglie d’acqua. Nella tecnica 3 la precisione dipende fortemente dal numero di antenne e Reader utilizzati, dunque è poco confrontabile: gli errori possono variare dai 10cm ad 1metro e anche oltre. Infine nella tecnica 4 gli errori sono dell’ordine di 30cm per distanza fino a 3 mentre risente in maniera minore rispetto alle altre tecniche della presenza di materiali diversi interferenti in vicinanza del Tag.