Capitolo 4
Una Metafora grafica per KDDML
Introduzione
Quando parliamo di metafora grafica, nel nostro caso, ci riferiamo sostanzialmente alle propietà di rappresentazione, manipolazione ed espressione di una query per un ambiente di Knowlewdge Dyscovery.
In questo capitolo saranno presentate le linee guida seguite per realizzare una metafora grafica per il linguaggio KDDML facendo particolare attenzione ai requisiti principali indicati in [TESI_2]. Un confronto diretto tra le metafora grafica realizzata e quella proposta sarà effettuata nel capitolo successivo nella sezione legata alle scelte implementative.
4.1 Requisiti della Metafora Grafica
La metafora grafica rappresenta la parte centrale su cui costruire l’intera interfaccia, e dovrebbe garantire ottima espressività e facilità d’uso.
In tal senso si può dire certamente che il grafo rappresenta un compromesso migliore tra usabilità e potere espressivo rispetto all’albero. Bisogna precisare però che occorrono dei meccanismi automatizzati per vincolare in qualche modo l’utente nell’inserimento degli operatori e nei collegamenti.
Una possibile soluzione può essere rappresentata, a questo proposito, dalla divisione dell’area di costruzione della query in fasi.
La compilazione di una query infatti, si può pensare come un vero e proprio processo di KD (vedi par. 1.7) cercando in qualche maniera di suddividere la query in categorie dipendenti dal task di DM da effettuare, come input, preprocessing,
learning, validation, e visualization, con la possibilità di inserire in ogni area solo gli operatori che fanno parte di una specifica classe.
Ciò, come accennato precedentemente, metterebbe in evidenza anche il processo a fasi tipico del KDD.
Numerose problematiche andrebbero comunque risolte, poiché non tutti gli utenti potrebbero aver bisogno delle medesime fasi. Inoltre l’output di una fase può appresentare l’input di una fase precedente, dato che il processo KDD è iterativo , vi è quindi la necessità di gestire anche cicli tra le fasi.
Da questa prima analisi emergono già alcuni requisiti fondamentali che l’interfaccia dovrebbe avere :
- Grafo come Metafora grafica;
- Organizzazione del flusso di costruzione della query seguendo le fasi tipiche del processo di KDD
- Controllo sugli operatori da inserire ad ogni passo
4.1.2 Analisi statica e meta-esecuzione
Come abbiamo visto nel primo capitolo si può dire che il processo di estrazione di conoscenza rappresenta un task “time-consuming”.
Molte volte infatti sarebbe utile scoprire eventuali errori prima di eseguire la query. In questo modo infatti si eviterebbe di eseguire task di data mining su grosse quantità di dati per poi non riuscire a ricavare alcun dato significativo a causa di inserimenti erronei di operatori o paramentri immessi durante la fase di organizzazione dello schema.
Infatti non è pensabile dover necessariamente eseguire la query per scoprire eventuali errori presenti, in quanto tali errori potrebbero presentarsi anche dopo lunghe attese, dovute a fasi corrette di preprocessing su enormi quantità di dati. Sarebbe quindi auspicabile, in una implementazione del sistema grafico, la possibilità di controllare eventuali errori rilevabili con una analisi statica basata sulla correttezza delle proprietà degli operatori note a priori e che quindi non necessitano di alcuna esecuzione per essere rilevate.
Sarebbe inoltre auspicabile riuscire a creare un meccanismo che incrementi le potenzialità offerte dalla sola analisi statica. A tal fine, si possono creare strumenti di meta-esecuzione.
La meta-esecuzione rappresenta la possibilità di concretizzare verifiche avanzate sulla correttezza della query. Attraverso questo meccanismo, è possibile attuare unaserie di controlli ottenibili tipicamente a run-time, senza dover mandare in esecuzione il processo, o per meglio dire senza manipolare i dati fisici.
Tali controlli devono quindi sfruttare una serie di “meta-informazioni” fornite dal sistema, sullo schema logico dei dati fisici dati) e dei modelli (meta-modelli), riguardanti la struttura dei dati.
Attraverso questo schema è possibile avere delle indicazioni sul numero e sul tipo degli attributi che appaiono nel seguito del file, e che rappresentano i dati fisici.
Per capire meglio facciamo un semplice esempio in cui la meta-esecuzione può evitare di eseguire inutilmente una query.
Consideriamo una query KDDML fatta in questo modo:
<?xml version="1.0" encoding="UTF-8"?> <KDDML_OBJECT>
<KDD_QUERY name="adult classify"> <TREE_CLASSIFY>
<TREE_MINER target_attribute="class"> <ARFF_LOADER arff_file_name="adult.arff"/>
<ALGORITHM algorithm_name="yadt"/> </TREE_MINER> <ARFF_LOADER arff_file_name="adult_test.arff"/> </TREE_CLASSIFY> </KDD_QUERY> </KDDML_OBJECT>
In questo caso l’esecuzione di questa semplice query potrebbe terminare inaspettatamente con un errore anche se da un punto di vista sintattico la query è stata formulata in maniera corretta.
Mettiamoci nella situazione in cui nel repository di KDDML (vedi capitolo 2) non sia presente la tabella adult_test.arff. L’esecuzione della query si arresterebbe dopo aver estratto un albero di classificazione da adult.arff .
Un altro motivo di possibile arresto della query è legato alla presenza o meno dell’attributo class nel file adult.arff. Questo rappresenta il caso più interessante. Infatti sarebbe di grande aiuto per l’utente avere un aiuto del genere da parte del sistema. Si potrebbe guidare l’utente nella compilazione del campo target_attribute in maniera tale da evitare eventuali errori a tempo di esecuzione. Bisogna precisare che per fare un’analisi di questo tipo non è necessario andare direttamente sui dati fisici ma basta conoscere (in questo caso) il modello dei dati associato al file .arff.
Un altro esempio tipico di errore rilevabile attraverso la meta-esecuzione, riguarda l’utilizzo dell’algoritmo ID3. Quest’ultimo prende in input solo con attributi nominali, e quindi, se utilizziamo come training set un insieme che prevede attributi di tipo numerico, il sistema solleva un’eccezione a run-time, quando si trova ad eseguire tale algoritmo.
Risulta evidente che, accedendo semplicemente ai meta-dati del training set, è possibile rilevare tale errore e presentarlo all’utente e in alcuni casi è possibile addirittura vincolare l’utente non permettendo di compilare dei campi in cui possono essere inseriti valori erronei.
andiamo ad eseguire la query e quindi a manipolare i dati fisici, cosa che è time-consuming, ma i controlli avvengono accedendo solo alle “meta-informazioni”, che devono comunque essere previste dal sistema.
Come è lecito attendersi, non tutti gli errori sono rilevabili attraverso la meta- esecuzione, altre procedure devono quindi essere garantite a tempo di esecuzione, per permettere il corretto svolgimento della query KDD.
Inoltre, i controlli a run-time riguardano in generale tutte quelle situazioni in cui le informazioni note staticamente, non sono sufficienti a garantire la correttezza della query.
Si possono identificare quindi vari modi per la rilevazione degli errori nella compilazione di una query:
- Analisi Statica - Meta-Esecuzione - Controlli a run-time
Si può quindi delineare un ulteriore requisito che l’interfaccia grafica per KDDML deve avere:
- guidare l’utente in una compilazione corretta della query.
Chiaramente questo rappresenta uno dei problemi di maggiore rilevanza poiché dovranno essere forniti strumenti per la validazione della query e la correzione di eventuali errori.
Per ciò che riguarda la validazione delle query si può dire che bisognerebbe evitare di eseguire una query non valida poiché l’interprete KDDML solleverebbe chiaramente una eccezione a run time.
Quello infatti che ci proponiamo in questo lavoro, è strettamente connesso con questo tipo di requisito poiché si parte dalla considerazione che l’utente finale non dovrebbe avere accesso a funzionalità che non può utilizzare.
verranno descritti in modo più esteso nel capitolo successivo.
4.1.3 Espansione del Sistema
Naturalmente, una caratteristica dei software in rapida evoluzione (come può essere il caso di quelli relativi al Data Mining), è la possibilità e la necessità di espandere il sistema.
Un requisito che reputiamo importante è la necessità di non dover andare a manipolare l’interfaccia grafica ogni volta che si intenda estendere il sistema. Per estensione nel nostro caso si può intendere introduzione di nuovi algoritmi, l’utilizzo di nuovi modelli e nuovi formati di sorgenti/destinazioni. L’obiettivo è quindi quello di costruire un’interfaccia che non sia realizzata staticamente, ma che svincolata dal nucleo funzionale del software, riesca ad aggiornarsi ogni volta che avviene un cambiamento nel sistema.
A tale scopo l’interfaccia grafica deve essere pensata in modo tale da slegarsi completamente dal nucleo sottostante nel senso che operatori, parametri, algoritmi e modelli devono essere caricati dinamicamente in modo indipendente dal loro numero e tipo, ma allo stesso tempo deve garantire di catturare in maniera corretta eventuali modifiche ad operatori o attributi.
Anche per questo aspetto si rimandiamo maggiori dettagli al capitolo successivo.
4.1.4 Salvataggio del Query Flow
In maniera molto generica si può dire che un requisito fondamentale in qualsiasi applicazione che prevede l’elaborazione di documenti, che siano
documenti di testo, immagini o , come nel nostro caso query grafiche, è sicuramente il salvataggio parziale del modello che si sta elaborando.
Anche nel nostro caso si capisce subito che questo rappresenta un requisito fondamentale per la nostra interfaccia.
E’ auspicabile quindi che a partire da una query grafica si possa salvare il l’intero flusso di lavoro che rispecchia il processo di Knowledge Discovery. In questa maniera l’utente può ricaricare la query precedentemente salvata e modificare e/o eseguire la query.
Naturalmente si deve fornire la possibilità di salvare anche query parziali che perciò non possono essere validate.
Chiaramente si deve pensare ad uno standard per il salvataggio della query e per la memorizzazione di informazioni prettamente grafiche.
A tale proposito possiamo dire che è necessario valutare la possibilità di utilizzare un formato leggibile anche al di fuori della sola interfaccia, come XML, oppure utilizzare un formato proprietario.
Il salvataggio di un knowledge flow perciò rappresenta un requisito fondamentale per la realizzazione di tale tool e per l’utente è sicuramente una funzionalità di primaria importanza.
I dettagli relativi alle modalità di realizzazione verranno mostrati nel capitolo seguente.
4.1.5 Parametri
Quando si considera la formulazione di una query, un dettaglio che sicuramente non può essere scartato è quello relativo all’immissione dei parametri.
Infatti dal nostro punto di vista, in qualche modo, pensiamo che l’utente del sistema debba essere guidato, oltre che nella stesura della query, anche nell’inserimento dei parametri per gli operatori.
semplice ed immediato per agevolare l’utente finale in questo compito.
Queste caratteristiche chiaramente possono influire sulle potenzialità e sull’usabilità che l’interfaccia grafica può offrire.
L’utente che si trova a “settare” i parametri per un determinato operatore si deve trovare di fronte una interfaccia ben organizzata che vincoli in maniera netta la possibilità, da parte di chi compila la query, di immettere dei paramentri errati.
Ciò va a tutto vantaggio della validazione della query, infatti se si cerca di direzionare la compilazione della query verso una modalità più vincolante si riesce chiaramente ad essere più diretti e anche se può sembrare strano l’utente da questa rigidità riceve innumerevoli vantaggi. Vogliamo sottolineare come sia necessario guidare l’immissione dei parametri obbligatori. Infatti controlli di questo tipo possono evitare un controllo di correttezza dei parametri al momento della validazione della query.
Questo discorso si lega irrimediabilmente anche all’espandibilità del sistema. Infatti, se supponiamo che il livello dell’interfaccia grafica non debba mai essere modificato, dobbiamo garantire, da parte della struttura sottostante, una serie di informazioni che permettano all’interfaccia di capire quali sono i parametri obbligatori, quelli opzionali con i relativi valori di default, e quali sono ad esempio i range di valori da visualizzare.
Quindi, abbiamo segnalato come requisito fondamentale dell’interfaccia grafica, l’immissione guidata dei parametri degli operatori .
4.1.6 Vincoli grafici
Da un punto di vista dell’organizzazione grafica della query ci sono molti punti su cui riflettere.
(descritti nel capitolo 3), tenendo in considerazione la libertà che lasciano all’utente circa la disposizione degli operatori nell’ambiente grafico.
Per quello che riguarda Yale, si può notare che il sistema gestisce completamente la disposizione degli operatori nell’albero. Questo è piuttosto naturale dato che la Gui di Yale utilizza una metafora grafica ad albero e di conseguenza , proprio per sua natura non permette una grande libertà di immissione degli operatori. Infatti per poter aggiungere un operatore all’albero bisogna necessariamente selezionare il nodo padre e inserire il successivo operatore che verrà visualizzato come figlio del nodo attuale. Questo tipo di rappresentazione, come discusso in precedenza permette una visione gerarchica della query , ma presenta in ogni caso dei punti di debolezza.
Un utente più esigente vorrebbe in qualche modo interagire con il sistema in maniera più diretta contemporaneamente più potente.
Per questa ragione la scelta della metafora grafica è caduta sul modello a grafo. Anche in questo caso però bisogna menzionare alcuni difetti di una rappresentazione di questo tipo legato soprattutto a problemi di chiarezza e visibilità della query stessa.
Se consideriamo i sistemi WEKA ed ORANGE (analizzati brevemente nel capitolo precedente) si possono notare alcuni difetti nella visualizzazione della query.
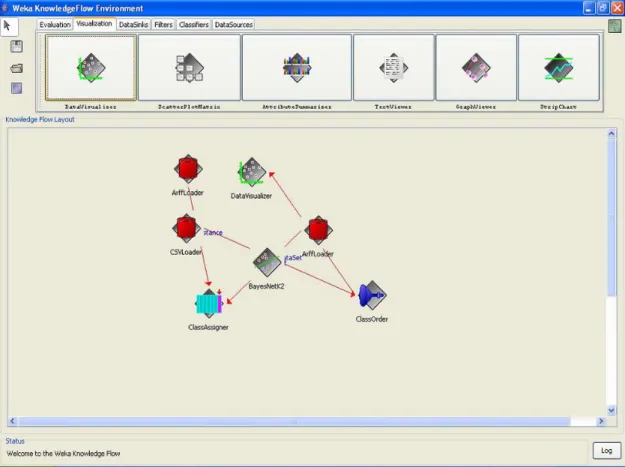
Con Weka Knowledge Flow infatti (vedi figura 20) è possibile creare un intreccio tale di operatori e collegamenti da perdere di vista completamente lo schema che si sta cercando di elaborare.
Questo in parte è dovuto anche al fatto che è possibile inserire prima tutti gli operatori e poi in seguito creare i collegamenti tra di essi.
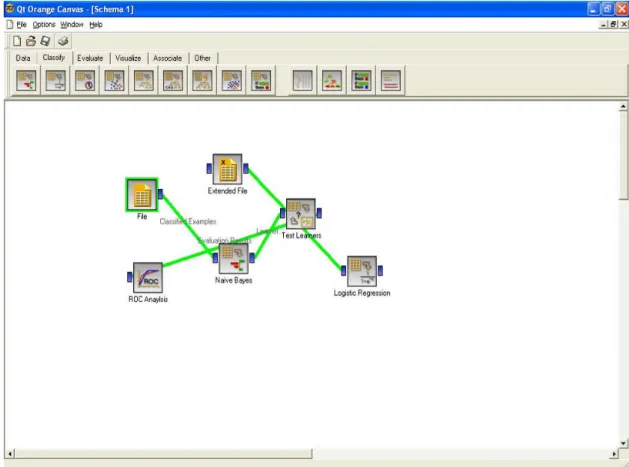
Per ORANGE vale lo stesso discorso. Anche in questo caso infatti è possibile creare degli intrecci complessi sul canvas, anche se c’è da dire che quest’ultimo tool limita in parte il posizionamento degli oggetti grafici colorando di rosso il contorno dell’icona nel caso in cui si voglia tentare di sovrapporre due o più oggetti grafici o inserire l’operatore in una certa posizione (figura 21).
Figura 20 : WEKA Knowledge Flow
Le linee guida che abbiamo seguito nella realizzazione dell’interfaccia grafica vera e propria chiaramente tengono in considerazione queste osservazioni e, come accade molte volte, siamo giunti ad un compromesso tra facilità di utilizzo e possibilità di manipolare graficamente la query da parte dell’utente. Anche in questo caso si può dire che il requisito individuato rappresenta il fatto di vincolare l’utente a spostare gli operatori del grafo e lasciare completamente al sistema la possibilità di inserire dei collegamenti tranne in alcuni casi particolari che discuteremo nel capitolo successivo.
figura 21 : Orange canvas
4.2 Verso un modello formale di rappresentazione
Come abbiamo discusso nel capitolo precedente, e con le osservazioni fatte nel corso di questo capitolo, la necessità di un’interazione uomo-macchina semplice e’ diventata cruciale per una grande varietà di applicazioni. Per raggiungere una migliore interazione, sono state proposte nuove categorie di linguaggi (linguaggi visivi), basato sul vasto utilizzo di meccanismi grafici ed “iconici”.
Noi in questo lavoro siamo interessati in una sottoclasse particolare dei linguaggi visivi, denominata “Linguaggi di Querying Visuali” (VQL), sviluppati
nel corso degli anni passati soprattutto nell’ambito database. I VQL principalmente sono basati sull'idea di applicazione di nuovi meccanismi di interazione, basati “sul paradigma di manipolazione diretta”, delle informazioni (dati) rappresentate visivamente. Sono stati proposti vari VQL, ma soltanto alcuni di loro sono forniti di una definizione formale.
In questa parte del lavoro di tesi miriamo a fornire una semantica statica proponendo un modello grafico di dati, il “graph model”, in cui la rappresentazione visiva fa parte del modello in se, e un insieme minimo di primitive grafiche, attraverso le quali gli operatori di querying possono essere espressi.
I sistemi di querying visuali (VQS) possono essere definiti come sistemi di querying essenzialmente basati sull'uso di rappresentazioni visive per descrivere il dominio di interesse e per esprimere le richieste ad un sistema, che esso sia una base di dati o un motore di Knowledge Discovery (come nel nostro caso).
I VQS includono sia un linguaggio per esprimere le query in una forma visiva, sia una varietà di funzionalità per facilitare l'interazione uomo-macchina. I VQS sono orientati verso un'ampia gamma di utenti anche con limitate abilità tecniche che generalmente ignorano la struttura interna del linguaggio su cui il VQS si appoggia. Durante gli anni scorsi, sono stati proposti molti VQS che adottano una gamma di rappresentazioni e di strategie visive di interazione differenti. Sulla base degli elementi visivi adottati, si distinguono VQL “a grafici” ed “iconici”, cioè, linguaggi basati rispettivamente sul vasto uso degli schemi e di icone. Possiamo concludere quindi che, come detto in precedenza, tipicamente, i linguaggi iconici hanno una più alta carica metaforica rispetto a quelle grafiche. Tuttavia i linguaggi grafici sono più adatti per essere formalizzati, dato che possono essere rappresentati con una struttura
matematica precisa (cioè, il grafo) su cui gli schemi sono basati.
Per superare questo tipo di problema, una possibile soluzione è unificare il modello di dati e la relativa rappresentazione grafica, applicando direttamente su esso gli operatori grafici (come la selezione dei nodi e disegno dei collegamenti) che hanno una propria semantica. Infatti, poichè stiamo parlando di KDD che è un processo ben definito e suddiviso in fasi ben delineate, siamo capaci di dare all’intero processo una rappresentazione grafica semplice in cui operatori e collegamenti possono essere facilmente rappresentati con nodi ed archi.
L'idea di base è nella definizione di un insieme minimo di primitive grafiche, attraverso le quali possono essere definiti precisamente meccanismi visivi di interazione più complessi.
A partire da queste considerazioni, proponiamo un insieme minimo di primitive grafiche basate su un modello grafico, denominate proprio graph model. Le caratteristiche principali del graph model e delle primitive grafiche sono:
a) il graph model permette di definire il processo di querying su un motore per KDD con una tripla <G , C, m>, dove il G è una struttura a grafo non orientato, C è un insieme di vincoli, ed m una funzione, denominata funzione filtro, che verra’ descritta meglio in seguito;
b) la semantica delle primitive grafiche è espressa anche in termini di trasformazioni, in modo che nella valutazione di una query, a partire da una tripla iniziale che rappresenta una query vuota, viene prodotta una tripla finale, che rappresenta
le informazioni richieste. Le primitive grafiche del linguaggio hanno semplicemente due funzionamenti di base: la selezione di un nodo e la rappresentazione di un arco etichettato.
Chiamiamo il nostro modello per la sottomissione di query KDDMLGraph. Allora espandendo la definizione precedente di graph model si può dire che un KDDMLGraph è una tupla G = <N,E,LN ,LA ,fN,fA> definito come segue :
N = N-In ∪ N-central ∪ N-out; N-in sono i nodi del grafo che rappresentano gli operatori attraverso i quali si può fornire un input al sistema(caricare dei modelli, delle tabelle o connessioni con database remoti). I nodi N-out sono quelli che rappresentano gli operatori di output (operatori per scrivere dei risultati su un database o su un file arff). I nodi intermedi rappresentano tutti gli altri operatori (preprocessing, data Mining ecc.).
E ⊆ N × N; è l’insieme dei collegamenti tra i nodi.
LN e’ l’insieme delle etichette dei nodi; le etichette di partenza sono rappresentate dal nome dell’operatore.
LA è l’insieme delle etichette degli archi; queste etichette rappresentano il tipo di output dell’operatore.
Le funzioni di “labeling” sono definte come segue : fN : N → L1;
fA : E → L2
Volendo passare (solo per facilità di descrizione) ad un modello di grafo in cui non vi sono le definizioni delle funzioni fN ed fA , si può riformulare il KDDMLGraph come :
G = <N × O, E> in cui:
N ={op-1,…..,op-n } e’ l’insieme di operatori
L = {out-1,….out-n} e’ l’insieme dei tipi di output che possono essere tabelle , modelli, ecc.
E ⊆ (N × L) ∪ (L × N ) e’ l’insieme degli archi.
Abbiamo cambiato rappresentazione solo per far notare meglio il concetto di flow-diagram nel senso che dando una definizione di L, si può percepire come se tra un operatore ed un altro vi sia un vero e proprio flusso di dati (in questo caso tabelle o modelli) proprio come avviene nel processo KDD.
Ridefiniamo i nodi di input come l’insieme :
S = {in ∈ L | (n , in) ∉ E, ∀n ∈ N}. Questi nodi possono rappresentare un input esterno per il graph-flow (o per un sottografo del KDDMLGraph). Gli operatori con tali caratteristiche nella realizzazione dell’interfaccia grafica sono stati raggruppati nella fase DATA LOADER .
I nodi cosiddetti di “output” sono l’insieme :
T = {out ∈ L | (out , n) ∉ E, ∀n ∈ N}. Essi rappresentano l’output del flow-graph e sono quelli a cui si fa riferimento nel progetto software come DATA WRITING.
Considerando questa notazione si possono definire gli Input (parametri) e gli Output per ogni operatore in maniera immediata:
I(n) = {in ∈ L | (in , n) ∈ E}. O(n) = {out ∈ L | (n , out) ∈ E}.
Quindi in maniera simile se si considera B ⊆ N come un sottoinsieme degli operatori, I(B) e O(B) possono essere definiti come :
I(B) = {in ∈ L | in ∈ I(b) per b ∈ B}. O(B) = {out ∈ L | out ∈ O(b) per b ∈ B }.
Facendo riferimento ad una serie di vincoli, come descritto in precedenza si puo’ dire che questo grafo di flusso nel modello formale deve soddisfare alcune condizioni :
(1). |I(n)| > 0 ∀n ∈ N ∩ S.
(2). |O(n)| > 0 ∀n ∈ N ∩ T.
Il punto (2) è valido se non si considera la possibilità di effettuare una meta-esecuzione della query. In ogni modo nel capitolo suuccessivo questo punto verrà considerato in maniera più approfondita.
seguente:
connect : n × c → N’; definita per n ∈ N , c ⊆ C , N’ ⊂ N.
Ricordiamo dalla definizione precedente che C indica l’insieme dei possibili vincoli sugli operatori. La funzione connect infatti, dato un operatore e un insieme di vincoli restituisce un sottoinsieme di operatori N’ che rappresentano un possibile collegamento tra n e v ∈ N’.
Più formalmente si può dire che dato un nodo n ∈ N con una serie di vincoli c ∈ C, allora v ∈ N’ può essere un nodo collegato a n se connect(n,v) ≠ ∅ .
A questo punto definiamo per il nostro caso specifico l’insieme dei vincoli. Consideriamo come molt(n) ∀ n ∈ N il numero di archi entranti che n può avere; ciò corrisponde al numero di parametri dell’operatore a cui il nodo si riferisce.
Indichiamo inoltre con type_in(wi) ∀ w ∈ N e ∀ i ∈ molt(w) il tipo dell’i-esimo parametro di input e con type_out(w) il tipo di output del nodo w.
Allora dati due nodi (operatori) n,v ∈ N si dice che n può essere collegato a v (e non viceversa), se valgono |I(v)| > 0 e |O(n)| > 0 , e ∃ i ∈ molt(v) tale che type_in(vi) = type_out(n).
Nella regola precedente abbiamo sottolineato il termine può, poichè questa regola è valida solo se non sono collegati già molt(v) elementi al nodo v.
Hv = {x ∈ connect(x,v) | ∃ (x , I(v) ) ∈ E } per v ∈ N
Si può a questo punto aggiungere una condizione alla regola precedente riformulandola nel modo seguente:
Def. Dati due nodi (operatori) n,v ∈ N si dice che n può essere collegato a v (e non viceversa), se valgono |I(v)| > 0 e |O(n)| > 0 , e ∃ i ∈ molt(v) tale che type_in(vi) = type_out(n) ed n ∈ R dove R = connect(n,v) \ Hv.