LA STRATEGIA DI OTTIMIZZAZIONE
1.1 Considerazioni preliminari sul tempo di esecuzione dell’EMvironment3.0
L’EMvironment3.0 è il software sviluppato dal Microwave and Radiation Laboratory della Facoltà di Ingegneria dell’Università di Pisa per l’analisi della propagazione elettromagnetica in ambienti misti indoor/outdoor. Il linguaggio di programmazione usato è il FORTRAN 95.
L’EMvironment3.0 per frequenze superiori ai 300MHz adotta una modellizzazione a raggi delle onde elettromagnetiche. Dato uno scenario 3D e l’ordine dei contributi scelto dall’utente, il solutore geometrico del software individua, per ogni coppia trasmettitore-ricevitore, tutti i raggi che connettono il punto in cui è posta l’antenna trasmittente al punto di osservazione attraverso un metodo deterministico inverso che prende il nome di ray-tracing e fa uso dell’image method [1].
Per ordine dei contributi c si intenderà d’ora in avanti il numero massimo delle interazioni che i raggi possono avere con gli oggetti presenti all’interno dello scenario. Le interazioni corrispondono ai fenomeni propagativi che possono verificarsi all’interfaccia tra due mezzi: riflessione, trasmissione e diffrazione su uno spigolo. Ad esempio, scegliere un ordine di contributi pari a 2 significa imporre al software di trovare i seguenti raggi: diretto, singolarmente e doppiamente riflessi, singolarmente e doppiamente trasmessi, singolarmente diffratti1, riflessi/trasmessi e
viceversa, riflessi/diffratti e viceversa, trasmessi/difratti e viceversa.
Ogni raggio trovato viene sottoposto ad alcuni controlli preliminari (ad esempio si verifica che il punto di interazione appartenga alla piastra su cui l’interazione è avvenuta). Se l’esito dei controlli è positivo, ogni singola tratta del raggio individuato viene immediatamente sottoposto ai visibility test, un insieme di operazioni geometriche standard più o meno complesse che consistono nel calcolo dei punti di intersezione tra rette e piani, la verifica dell’appartenenza di un punto ad un poligono, il calcolo di distanze ed altre ancora. Questi test, applicati ad ogni oggetto dello
1
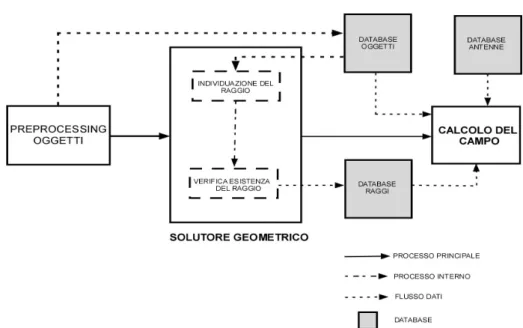
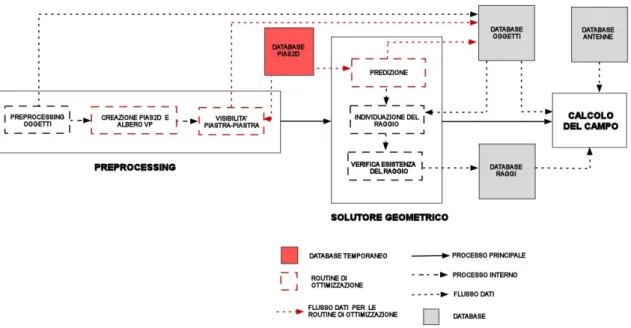
scenario, stabiliscono l’esistenza del raggio, ovvero verificano che il raggio individuato non sia ostacolato da nessuno di essi. Se l’esito del test è positivo, ovvero se il raggio esiste, il suo path viene memorizzato in un apposito database e grazie ad esso, alla conoscenza del diagramma d’irradiazione dell’antenna trasmittente e delle caratteristiche elettro-fisiche degli oggetti su cui si sono verificate le interazioni (registrati in altri due appositi database) viene calcolato il campo elettromagnetico nel punto di osservazione. L’operazione di calcolo del campo viene eseguita dopo che il solutore geometrico ha trovato tutti i raggi esistenti. La fig.1.1 mostra lo schema del processo.
Figura 1.1 – Schema a blocchi del solutore geometrico ed elettromagnetico dell’EMvironment3.0
Il tempo di esecuzione del software, a meno di quello impiegato dal preprocessing degli oggetti, sarà quindi dato dalla somma dei singoli tempi di esecuzione del solutore geometrico e del solutore elettromagnetico. Mentre il secondo è una funzione lineare del numero di path trovati e di c, il primo è una funzione non lineare di c e del numero di trasmettitori, ricevitori e piastre2 presenti all’interno dello
scenario. Statisticamente si trova inoltre che oltre il 99% del tempo di esecuzione è dovuto al solutore geometrico e che ben il 90% è dovuto ai visibility test e al calcolo
2
Gli oggetti presenti all’interno dello scenario sono infatti scomposti in piastre, ovvero poligoni che costituiscono le 2-facce dell’oggetto. L’insieme delle piastre associate ad un oggetto non è altro che il 2-scheletro di un n-politopo (dove n è appunto il numero delle piastre). Per le definizioni si veda l’Appendice.
dei punti immagine [4]. Data la maggior complessità dei visibility test, la maggior parte di tale percentuale è imputabile a quest’ultimi. E’ quindi evidente che se si vuole ottimizzare il tempo di esecuzione, si dovrà agire su di essi.
L’EMvironment3.0 implementa un algoritmo ricorsivo come core del solutore geometrico per eliminare la ridondanza dovuta al continuo ricalcolo dei punti immagine3. Per capire come esso lavori, si prenda il seguente esempio.
Supponiamo di avere uno scenario composto da un trasmettitore, un ricevitore e un numero N di piastre pari a 3, con c uguale a 2; limitiamoci al caso delle riflessioni. Per ogni coppia tramettitore-ricevitore, il software fa un ciclo su tutte le piastre dello scenario, e quindi il ciclo avrà N loop. Al primo loop trova l’immagine del trasmettitore rispetto alla piastra di indice 1; traccia il raggio e lo invia ai visibility test per controllare l’esistenza del raggio singolarmente riflesso. Fatto questo, entra in ricorsione (prima ricorsione) , dando origine ad un nuovo ciclo di altri 3 loop. Questa volta sarà calcolata l’immagine del punto immagine, trovato precedentemente, rispetto alla piastra corrente del loop della prima ricorsione. Naturalmente il primo di questi loop sarà saltato in quanto non ha senso fisicamente (non possono esserci due riflessioni consecutive sulla stessa piastra), mentre sarà trovato il punto immagine relativo alla piastra 2. Viene quindi tracciato il raggio e viene inviato al visibility test. Concluso questo, si passa alla piastra 3 ripetendo gli stessi passaggi; in questo modo si evita di ricalcolare ogni volta lo stesso punto immagine rispetto alla piastra 1. Finito il ciclo, il programma esce dalla prima ricorsione, passa al loop successivo, relativo alla piastra 2, e ripete il processo ricorsivo.
Se vogliamo calcolare il numero di raggi che potenzialmente possono essere trovati, schematizziamo il processo attraverso un semplice gioco. Supponiamo di avere un dado ad N facce, ognuna contrassegnata da un valore n, con n=1,2,….N, e di poterlo
3
La soluzione ricorsiva implementata nell’ EMvironment3.0 rispetto alla versione 2.0 già da sola ha migliorato i tempi di esecuzione del solutore geometrico eliminando la ridondanza relativa al calcolo dei punti immagine: alcune semplici prove dimostrano che il guadagno cresce notevolmente al crescere di c e di N. Ad esempio, per c=2 il rapporto 2.0
3.0
T
T tra il tempo di esecuzione dei due software (T2.0 tempo di escuzione della versione 2.0, T3.0quella
della versione 3.0) aumenta di un fattore 1 ogni 150 piastre. Per c=3 il rapporto incrementa molto più rapidamente divenendo non proporzionale
lanciare c volte. Il numero delle combinazioni possibili sarà dato da c
P = N ; ma a
noi non interessano tutte le combinazioni, bensì soltanto quelle nelle quali non siano presenti almeno due cifre consecutive uguali. Il numero di tali combinazioni sarà dato da
P
li=
N N
(
−
1)
c−1: questa cifra descrive il limite superiore – sottostimato perché abbiamo considerato solo le riflessioni – del numero di raggi che il solutore geometrico trova, e quindi di cicli di visibility test che il software può potenzialmente eseguire per ogni coppia trasmettitore-ricevitore e per un determinato c. Il numero totale di raggi per ognuna delle suddette coppie sarà dato da:1 1
(
1)
c i l iP
N N
− ==
∑
−
(1) lP varia quindi con (O Nc). Tuttavia, la gran parte di questi raggi sarà inevitabilmente scartata dopo i test di visibilità. Il numero di questi ultimi per raggio a sua volta è una funzione non lineare delle piastre presenti nello scenario e di c. Infatti c determina il numero massimo di tratte da cui un singolo path può essere composto, essendo questo pari a (c+1). Per ogni singola tratta, viene fatto un ciclo su tutte le N
piastre dello scenario per verificare che nessuna di esse la intralci. Il numero di test di visibilità per raggio è quindi Pv =N c( + , con c fissato: 1) Pv varia con ( )O N . Moltiplicando il numero di raggi per il numero di visibility test per raggio, otteniamo
2 1 1 ( 1) ( 1) c i i P N N − i =
=
∑
− + che è il limite superiore del numero complessivo di test di visibilità per ogni coppia trasmettitore-ricevitore. Considerando anche queste ultime, si trova il numero di visibility test sulla singola piastra che possono essere potenzialmente svolti nel corso del processing:2 1 1
(
1) (
1)
c i T R iP
N N
N
N
−i
==
∑
−
+
(2)dove N è il numero di piastre presenti nello scenario, NT quello dei trasmettitori, C
Quindi il tempo di esecuzione relativo al solutore geometrico – misurato in base alle operazioni standard che costituiscono il visibility test - varia in un range che progredisce con:
1
(
c)
O N
+ (3)Si verifica immediatamente che il limite superiore raggiunge l’ordine delle decine di migliaia di miliardi per un ricevitore e un trasmettitore, con N=1000 e c=3. Questo ordine aumenta ulteriormente di un fattore 3
10 per ogni incremento di c. All’aumentare di N le cose vanno notevolmente peggio: raddoppiando le piastre, per c=3, il limite superiore raggiunge un ordine di 14
10 ; per ogni incremento di c, esso aumenta di un fattore 4
10 . E’ anche evidente che qualsiasi algoritmo di ottimizzazione ha un solo grado di libertà poiché, come vedremo più dettagliatamente, può agire soltanto su N, essendo NT,NC e c scelti dall’utente.
Le strategie di ottimizzazione usate fino ad ora, come lo Space Volumetric Partitioning (SVP) [5], introdotte prima dell’implementazione del core ricorsivo4, cercavano di
ridurre il numero Pv diminuendo in esso, e solo in esso, il contributo relativo ad N;
tuttavia esse non scalfiscono affatto il numero Pl , che è quello che ha
indubbiamente peso maggiore per il tempo di esecuzione al crescere di c e di N. Una corretta strategia di ottimizzazione del software non può quindi prescindere dall’operare anche su di esso.
1.2 La selezione delle piastre per le interazioni: back/face culling e criterio PVS
L’ EMvironment3.0 implementa dei semplici stratagemmi per diminuire N in Pl,
andando ad operare una selezione delle piastre che possono supportare le interazioni. E’ tuttavia importante sottolineare che tale selezione è valida soltanto per le riflessioni e le trasmissioni; allo stato attuale, infatti, l’EMvironment3.0 non implementa nessun algoritmo per la scelta degli spigoli diffrattivi sul percorso del
4
Questo miglioramento non ha cambiato il numero complessivo di raggi che potenzialmente possono essere trovati: l
raggio. Come si vedrà più avanti, infatti, mentre è facile determinare alcune semplici regole valide per i raggi riflessi o trasmessi, la teoria di Keller, usata per la modellazione della diffrazione, introduce un’indeterminazione sulla direzione del raggio dopo che sia stato diffratto da uno spigolo. In altre parole, se un raggio riflesso rimane nel semispazio positivo indotto dalla piastra (si veda oltre) su cui avviene l’interazione e un raggio trasmesso passa invece da quello positivo a quello negativo (o viceversa), tali affermazioni non valgono per un raggio diffratto. Tuttavia il fatto che l’EMvironment3.0 supporti una sola diffrazione per raggio rende accettabile l’assenza di un algoritmo capace di determinare gli spigoli diffrattivi; inoltre, per quanto non sia possibile affrontare direttamente il problema della selezione degli spigoli con l’algoritmo che si andrà a descrivere, è pur sempre vero che esso può essere “aggirato” conoscendo le interazioni del raggio che contiene la diffrazione, come sarà brevemente spiegato nel Capitolo 5.
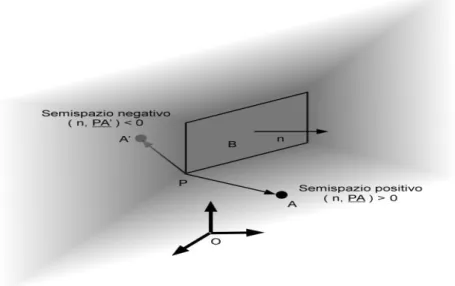
Come si diceva, per selezionare le piastra nella fase di processing vengono creati degli array che registrano le relazioni di visibilità tra tutte le coppie costituite dal trasmettitore (o ricevitore) sotto esame e una piastra (visibilità punto-piastra); similmente, durante il preprocessing viene creata una matrice per memorizzare le relazioni di visibilità anche tra tutte le coppie di piastre (visibilità piastra-piastra). La relazione di visibilità presa in considerazione è il cosidetto back/face culling : per il caso punto-piastra, un punto A è definito visibile da una piastra B se e soltanto se è contenuto nel semispazio positivo (poliedro) indotto dal piano di supporto che contiene la piastra B; parimenti, nel caso piastra-piastra, una piastra A’ è definita visibile da una piastra B se e soltanto se è contenuta parzialmente o totalmente nel semispazio positivo (poliedro) indotto dal piano di supporto che contiene la piastra B. In entrambi i casi, se la relazione è verificata, si dice che la piastra B vede il punto A (o la piastra A’). Nel caso punto-piastra, la relazione è simmetrica, mentre non lo è per il caso piastra-piastra.
Naturalmente, per poter classificare un semispazio come positivo o negativo il piano di supporto che li induce entrambi deve presentare una orientazione intrinseca data dalla normale della piastra. Il semispazio positivo (sottospazio ‘above’) indotto dal piano sarà quello i cui punti verificano la seguente condizione: il prodotto scalare tra il vettore che va da un vertice della piastra al punto e la normale del piano è positivo; i
punti appartenenti al semispazio negativo (sottospazio ‘below’) saranno quelli che daranno risultato negativo al medesimo prodotto scalare5. Intuitivamente, si può dire
che il semispazio positivo è costituito da tutti quei punti che stanno “davanti” alla piastra, quello negativo dai punti che stanno “dietro” ad essa.
Figura 1.2 – determinazione dell’appertenenza di un punto al semispazio positivo o negativo
indotto da una piastra
Durante il preprocessing, viene allocata e inizializzata nel database degli oggetti la matrice IPS (Intelligent Plate Storage) di dimensioni NxN. Ogni elemento della matrice può assumere i soli valori 1 e 0; se IPS(i,j)=1, la piastra i vede la piastra j, se IPS(i,j)=0 la piastra i non vede la piastra j; tale matrice sarà naturalmente con diagonale nulla. La verifica, per ogni coppia di piastre di indice i e j, viene fatta con un ciclo su tutti i vertici della piastra j. Appena si trova un prodotto scalare - come definito precedentemente – positivo, l’elemento IPS(i,j) viene posto ad uno e si esce dal ciclo. Il tempo di esecuzione dell’algoritmo che crea IPS varia entro 2
( ) O N . La pseudo-codifica in FORTRAN 95 è riportata oltre.
Similmente durante il processing per il trasmettitore (tx) sotto esame viene allocato (sempre nel database degli oggetti) il vettore MULTI_PRIMO, di dimensione N; come nel caso precedente, se MULTI_PRIMO(i)=1 tx vede la piastra i, se MULTI_PRIMO(i)=0 tx è invisibile rispetto alla piastra i. Allo stesso modo, viene
5
creato il vettore MULTI_ULTIMO per il ricevitore (rx) sotto esame. Entrambi i vettori vengono inizializzati in un tempo ( )O N .
L’uso di questi vettori e della matrice IPS gioca un ruolo fondamentale per diminuire P , determinando preliminarmente quali sono le piastre che l potenzialmente possono supportare le interazioni del raggio e quindi operando una selezione di esse: in altre parole, si agisce su N in P prendendone un l sottoinsieme. Si faccia infatti riferimento alla fig 1.3 e all’esempio riportato nel paragrafo precedente. Figura 1.3 IPS=0 DO i=1, N DO j=1, N IF (i=j) THEN CONTINUE ELSE DO m=1 a #vertici di j dot_product=0 PAjm =calcola_vettore(vert(i,1), vert(j,m)) dot_product(ni, PAjm) IF (dot_product>0) THEN IPS(i,j)=1 EXIT END IF END DO END IF END DO END DO
Il software inizia il ciclo sulle piastre; questa volta calcolerà il punto immagine soltanto rispetto alle piastre di indice i per cui MULTI_PRIMO(i)=1, in quanto è fisicamente impossibile che ci sia una riflessione su piastre che non rispettano questa condizione6: in questo modo ci siamo assicurati un notevole risparmio di tempo
poichè il software non entrerà in ricorsione nei loop 2 e 3, né potrà trovare un raggio singolarmente riflesso sulle piastre 2 e 3. Calcolato il punto immagine del tx rispetto alla piastra 1, si traccia il raggio che viene inviato ai visibility test; quindi il programma entra in ricorsione per cercare la seconda riflessione. Questa volta durante il ciclo sulle piastre dovrà selezionare soltanto quelle di indice j per cui IPS(j,1)=1, in quanto le altre non possono dare riflessione. Di conseguenza vengono saltati i loop 1 e 3 e si calcola il nuovo punto immagine soltanto rispetto alla piastra 2. In questo modo abbiamo ottenuto Pl = anziché 2 Pl = come ci saremmo dovuti aspettare. 9
Condizioni simili vengono applicate anche nel caso della trasmissione. L’uso del back/face culling si traduce in un indubbio risparmio sul tempo di esecuzione del solutore geometrico; tuttavia questo guadagno è difficilmente quantificabile dipendendo dalla posizione relativa delle piastre e da quella dei tx ed rx. In conclusione, il piccolo onere computazionale causato dall’implementazione del back/face culling è un costo accettabile per il guadagno che potenzialmente può dare. Tuttavia, per N e c molto grandi, anche essa si dimostra inefficace.
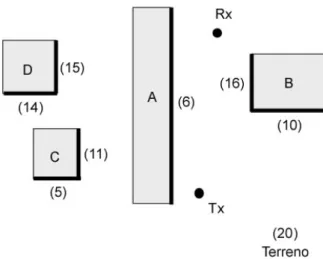
Si prenda infatti in considerazione la fig. 1.4, dove tutte le piastre hanno normale esterna. Supponiamo per semplicità che gli oggetti A, B, C e D abbiano tutti la stessa altezza e che quella di rx e tx sia inferiore. Intuitivamente possiamo dire che se esiste un raggio singolarmente o doppiamente riflesso esso può interagire soltanto con il terreno e con una piastra rispettivamente di A e di B, perché le altre non possono contribuire e quelle appartenenti a C e D non sono “visibili” – come defineremo meglio tra poco - dai punti di osservazione. Tuttavia il back/face culling classifica come visibili dal tx molte più piastre rispetto a quelle che effettivamente origineranno dei raggi utili al calcolo del campo elettromagnetico: abbiamo 8 piastre (quelle marcate
6
Infatti tutti gli oggetti all’interno dello scenario sono politopi, di conseguenza per ogni piastra A che non vede un punto P ce n’è almeno un'altra B, appartenente al medesimo oggetto, che lo vede e che impedisce la riflessione su A di un raggio proveniente dal semispazio negativo della piastra A; lo stesso vale per il caso piastra-piastra. Si può quindi affermare che la riflessione su una piastra possa avvenire soltanto se il raggio proviene dal suo semispazio positivo.
in figura più il terreno) rispetto alle 3 che vorremmo. Nella figura, tra parentesi sono indicate le piastre visibili da ogni piastra visibile dal tx. All’aumentare di N, il numero delle piastre “indesiderabili” aumenta notevolmente, facendo crescere Pl . La
relazione di visibilità stabilita dal back/face culling si presenta quindi come un criterio debole di selezione per le piastre.
Figura 1.4 – In neretto le piastre marcate con il back/face culling come
visibili dal trasmettitore; tra parentesi il numero di piastre visibili (sempre secondo il back/face culling) da ogni piastra marcata.
Con PVS (Potentially Visible Set), concetto introdotto nel 1990 da Airey et al.[3], si intende l’insieme degli oggetti “visibili” da un punto o da una regione di spazio. La relazione di visibilità introdotta è più simile a quella che cerchiamo: un oggetto (una piastra nel nostro caso) o un punto A sono visibili da un punto (o una regione di spazio) B se e solo esiste almeno un raggio diretto non occluso che connette il punto (o un punto sulla superficie dell’oggetto) A al punto (o al punto appartenente alla regione di spazio) B. Se questa condizione è valida si può affermare che B vede A; la relazione questa volta è simmetrica sia per il caso punto-piastra che per quello piastra-piastra. Una piastra j potrà quindi essere classificata rispetto ad una piastra i (o al punto di vista) come “completamente invisibile” o “parzialmente o completamente visibile”. Soltanto le seconde potranno supportare l’interazione di un raggio proveniente dalla piastra i (o dal punto di vista).
Grazie alla definizione di questi nuovi attributi, il criterio PVS si dimostra molto più forte rispetto al back/face culling nell’operare una selezione delle piastre. Applichiamolo al caso precedente: come mostra la figura 1.5, questa volta come visibili dal tx vengono scelte soltanto 4 piastre (le 3 marcate più il terreno). Quindi
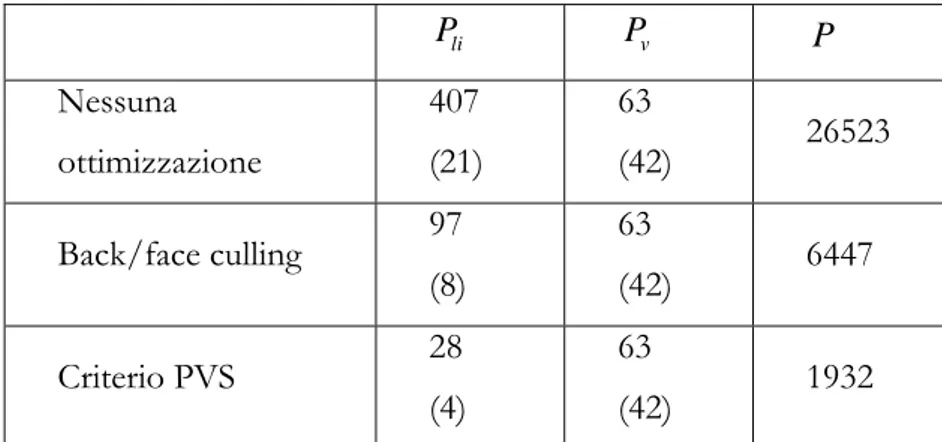
per N=21 (5 piastre per edificio più il terreno), c=2, NT=1, NR=1 avremo i valori
riportati nella tabella 1; in essa è presentato il numero di raggi, sia doppiamente riflessi che singolarmente riflessi (tra parentesi), che si possono ottenere. Come si può vedere dalle Equazioni (1)-(2), con il PVS in questo particolare caso il guadagno su P è del 70% rispetto al back/face culling. Nel caso peggiore, con il PVS si può raggiungere P=6447. li P Pv P Nessuna ottimizzazione 407 (21) 63 (42) 26523 Back/face culling 97 (8) 63 (42) 6447 Criterio PVS 28 (4) 63 (42) 1932
Tabella 1 – confronto tra il numero di visibility test che si ottengono per lo scenario di
figura 1.4 con il back/face culling e il criterio PVS.
Si dimostra infatti facilmente che l’insieme delle piastre visibili secondo il criterio PVS è un sottoinsieme di quelle visibili secondo il back/face culling.
Figura 1.5 – in neretto la piastre marcate con il criterio PVS come
visibili dal trasmettitore; tra parentesi il numero di piastre visibili (sempre secondo il criterio PVS) da ogni piastra marcata.
Inoltre in scenari urbani densamente edificati e in quelli indoor, è ragionevole aspettarsi che l’insieme di piastre visibili da un punto A o (da una piastra A’) non vari molto al crescere del numero N delle piastre poiché la visibilità tipicamente è
impedita da pochi grandi ostacoli posti nelle vicinanze di A (A’), ovvero pochi grandi ostacoli impediscono tutti i raggi che possono propagarsi da A (A’). Questo significa che il PVS potenzialmente può operare una selezione delle piastre tale da diminuire drasticamente il numero Pl di cicli di test di visibilità .
D’ora in avanti quindi, dove non diversamente specificato, intenderemo la visibilità secondo il criterio PVS. Di seguito riporteremo una descrizione d’insieme della soluzione adottata per implementarlo.
1.3 Descrizione generale dell’algoritmo di ottimizzazione
Per quanto più forte, l’implementazione del criterio PVS si dimostra più complicata di quella necessaria per il back/face culling, in quanto la verifica della visibilità tra un punto (una piastra) e una piastra viene fatta studiando complessivamente l’intero insieme di raggi che può propagarsi da un punto (una piastra) ad un’altra piastra. L’algoritmo di ottimizzazione rientra quindi in quella categoria delle tecniche di accelerazione che sostituiscono al singolo raggio una entità generale di cui il raggio individuale è il caso speciale [6]. Esso inoltre non può prescindere dal tenere in debito conto tutti gli oggetti presenti nello scenario – a differenza del back/face culling, dove viene studiata la singola coppia punto(piastra)-piastra. Sotto questo punto di vista, un algoritmo simile in qualche modo implementa già una grossa parte delle funzioni richieste dai visibility test; poiché l’algoritmo lavorerà principalmente nel preprocessing, si può dire che ivi sarà spostata la gran parte dei test di visibilità, riducendo quelli nel processing vero e proprio all’indispensabile.
L’algoritmo andrà a leggere dagli array MULTI_PRIMO, MULTI_ULTIMO e dalla matrice IPS e li riscriverà durante la sua esecuzione concordemente con il criterio PVS, in modo che ad esempio IPS(i,j)=1 significhi che “la piastra j è parzialmente o completamente visibile da quella i”, ovvero esiste almeno un raggio che può propagarsi dalla piastra i alla j – la matrice riscritta risulterà simmetrica. Similmente sarà fatto per gli altri due vettori. Al termine dell’algoritmo, le piastre visibili (da un punto o da un’altra piastra) risulteranno un sottoinsieme di quelle marcate dal back/face culling, riducendo Pl. L’algoritmo dovrà essere diviso in due parti: una
computo delle relazioni di visibilità tra i punti di osservazione (tx ed rx) e le piastre; essendo legata a tx ed rx, essa deve essere eseguita ogni qualvolta se ne cambi la posizione. In questo senso, la predizione descrive le relazioni di visibilità della parte “mobile” dello scenario; essa inoltre concerne la visibilità punto-piastra (visibilità da un punto [7]). L’array MULTI_PRIMO (MULTI_ULTIMO) dovrà quindi essere riscritto ogni volta che si cambi la pisizione del tx (rx). Come si vedrà nel capitolo successivo, la soluzione scelta è l’algoritmo Shadow Volume Binary Space Partitioning (SVBSP). L’insieme delle relazioni di visibilità piastra-piastra (visibilità da un poligono [7]) concerne invece la parte “fissa” dello scenario, in quanto non cambia al variare della posizione di tx e rx. La matrice IPS può quindi essere riscritta una sola volta, e il risultato salvato su apposito file per simulazioni successive in cui l’unica parte dello scenario a cambiare è la posizione dei punti di osservazione. In questo modo si eviterà la ridondanza dovuta alla nuova computazione delle stesse relazioni. L’algoritmo scelto per questa parte è una versione modificata del Line Space Partitioning (LSP).
Per entrambi gli algoritmi useremo uno scenario 2.5D. Per scenario 2.5D si intende una manipolazione dello scenario 3D originale, dal quale vengono estratte le informazioni 2D relative al piano x-y; la singola terza dimensione viene presa in considerazione soltanto laddove siano verificate alcune condizioni in 2D. Questo approccio da origine ad una soluzione conservativa, poichè l’insieme delle soluzioni in 3D è un sottoinsieme di quelle in 2.5D. Ciò significa nel nostro particolare caso che alcune piastre saranno classificate come visibili quando non lo sono, tuttavia non potrà avvenire il contrario.
Introduciamo inoltre un’ipotesi di lavoro: che le piastre siano in grande maggioranza poligoni rettangolari ortogonali al terreno7. Di conseguenza andremo a lavorare soltanto su
di esse, lasciando immutate le relazioni di visibilità relative alle piastre che non rispettano questa condizione. Questa ipotesi e lo scenario 2.5D diminuiscono l’onere computazionale degli algoritmi e trasformano il problema della visibilità da un
7
poligono in quello di visibilità da un segmento [7] più facile da eseguire. Tutte le piastre prescelte possono infatti essere descritte dal loro solo top-edge (spigolo superiore) [8]. Nel dettaglio, l’algoritmo di ottimizzazione esegue 3 passi successivi:
• alloca e inizializza durante il preprocessing un database delle piastre (PIAS2D) che contenga le sole informazioni utili per lo scenario 2.5D. Dopo l’allocazione dell’array PIAS2D, viene creato l’albero BSP Visibility Priority (VP); entrambi il database e l’albero verranno utilizzati nei successivi due passi;
• durante il preprocessing computa la visibilità piastra-piastra in modo da riscrivere la matrice IPS;
• durante il processing esegue la fase di predizione per i punti di osservazione correnti, in modo da riscrivere MULTI_PRIMO e MULTI_ULTIMO.
Una volta terminata l’esecuzione del solutore geometrico, viene deallocata pias2d e cancellato l’albero VP per liberare memoria non più sfruttata. La fig 1.6 schematizza quanto detto.
Figura 1.6 - Schema a blocchi del solutore geometrico ed elettromagnetico dell’EMvironment3.0 con l’algoritmo di
ottimizzazione
Va infine precisato che l’algoritmo allo stato attuale lavora soltanto negli scenari outdoor, dove le uniche interazioni accettate sono la riflessione e la diffrazione. Per
quanto esso sia implementabile anche per scenari indoor, si è scelto di testarlo su ambienti che consentissero di sviluppare un codice relativamente semplice.
1.4 L’array PIAS2D
Per velocizzare l’accesso alle informazioni utili per lavorare in ambiente 2.5D si è scelto di creare un apposito array di strutture [9] in grado di memorizzare i dati eleborati provenienti dalla parte del database degli oggetti (l’array PIAS) che registra i dati geometrici delle piastre. Questa soluzione permette di eliminare la ridondanza che si avrebbe nell’andare a calcolare le informazioni di cui sopra ogni volta che siano richieste: esse infatti non sono immediatamente disponibili nell’array PIAS. L’allocazione e l’inizializzazione di PIAS2D, di dimensione n pari al numero di piastre che rispettano l’ipotesi di lavoro, viene fatta nel preprocessing del programma dalla routine CREA2D. La memoria richiesta per l’allocazione di ogni elemento dell’array può variare a seconda dei processori da 68 a 136 byte, quindi la minima memoria richiesta per PIAS2D durante l’intera esecuzione del preprocessing e del solutore geometrico, in aggiunta a quella già usata dalla versione non ottimizzata dell’EMvironment3.0, è pari a (n x 212) byte; la massima sarà naturalmente il doppio. Assumendo ad esempio n=5000, la memoria richiesta varia tra 0.32Mbyte e 0.64Mbyte.
La struttura scelta come elemento dell’array prevede infatti dei campi REAL per memorizzare l’altezza della piastra, le coordinate degli estremi e del centro del suo top edge, la proiezione della sua normale sul piano x-y, i tre coefficienti dell’equazione esplicita della retta passante per il top edge oltre a un campo LOGICAL e due campi INTEGER, l’uno per l’indice della piastra e l’altro per la variabile ‘sp’ che registra l’evento spanned. Per evento spanned si intende l’ “attraversamento” di una piastra da parte della retta di riferimento (cfr. Cap. 2 e 3). ‘sp’ tipicamente può assumere 4 valori (2, 1, 0, -1); gli attributi associati ad ognuno di questi valori cambiano nei due step di predizione e visibilità piastra-piastra, e saranno quindi descritti successivamente. In ogni elemento è infine presente una matrice REAL di rango 2 e dimensione 2, di nome ‘vertexspan’, che sarà utilizzata nella determinazione della visibilità piastra-piastra.
Il funzionamento della routine è molto semplice: innanzi tutto viene fatto un ciclo sulle piastre dello scenario per contare il numero di quelle che rispettano l’ipotesi di lavoro. Viene quindi allocato PIAS2D e lanciato un nuovo ciclo (quindi con N loop) per inizializzarlo. Per ogni loop di indice i si verifica che la piastra sotto esame (di indice i) rispetti l’ipotesi di lavoro; se la condizione non è verificata, si passa alla piastra successiva. Se la condizione è verificata, si assegna all’elemento corrente di PIAS2D innanzi tutto la proiezione della normale della piastra sul piano x-y; quindi attraverso un unico ciclo sui vertici della piastra se ne calcola altezza e coordinate degli estremi e del centro del top edge. L’altezza è posta pari alla terza coordinata (coordinata z) del vertice che risulta averla massima; similmente vengono trovate le 4 variabili che corrispondono al minimo e al massimo rispettivamente lungo x ed y della piastra. Queste quattro variabili, assieme alla conoscenza della normale permettono di assegnare anche le coordinate degli estremi del top edge e, una volta conosciuti questi, del centro di esso. I coefficienti dell’equazione esplicita della retta passante per il top edge vengono calcolati ed assegnati durante il computo dela visibilità piastra-piastra. Finito il ciclo sulle piastre, non ci sono altre operazioni da eseguire per l’inizializzazione di PIAS2D e la routine passa a creare l’albero VP. Quanto detto fino ad adesso è riportato nel diagramma di flusso 1.
1.5 L’albero Visibility Priority (VP)
1.5.1 Gli alberi Binary Space Partitioning (BSP)
Introdotti nel 1969 da Schumacker et al [10], gli alberi BSP sono entità geometriche nelle quali degli iperpiani sono usati ricorsivamente per suddividere uno spazio di dimensione D in modo da creare un insieme di celle disgiunte ancora di dimensione D. Ognuna di queste celle può quindi essere marcata come “interna” o “esterna” all’insieme o ad un sottoinsieme degli iperpiani che la hanno determinata.
Supponiamo infatti di avere uno spazio tridimensionale r e di scegliere un piano h per dividerlo; in questo modo operiamo una partizione binaria su r che origina due nuove regioni r+ = ∩ e rr h+ −= ∩ , dove hr h− + e h− sono rispettivamente i semispazi aperti positivo e negativo di h. Ognuno di questi due semispazi può a sua volta essere diviso, e così via, in modo da produrre un albero binario. Un albero BSP è quindi un insieme gerarchico di regioni di uno spazio euclideo di
dimensione D che presentano una relazione di parentela “genitore-figlio”. Il processo di costruzione dell’albero usa un solo operatore locale, la partizione binaria; il partizionatore binario di una regione R di dimensione D è qualsiasi sottoinsieme di R di dimensione D-1 che divide R in due regioni disgiunte di modo che qualsiasi percorso da un punto dell’una ad un punto dell’altra debba intercettare il partizionatore. Quest’ultimo è composto da un iperpiano, da un sub-iperpiano che è l’intersezione dell’sub-iperpiano con la regione partizionata r, e dai suoi due semispazi. Nel caso 3D, ad esempio, il partizionatore sarà composto da un piano e da una retta; nel caso 2D, avremo una retta e un punto.
Gli alberi BSP si prestano molto bene ad essere implementati con strutture gerarchiche come gli alberi binari. Ad ogni nodo vengono associate le informazioni relative ad un partizionatore binario h; in questo modo ad ogni nodo corrisponderà una regione di spazio r divisa dal corrispondente partizionatore: il sottoalbero sinistro sarà relativo alla regione r+ = ∩r h+, quello destro alla regione r− = ∩ , dove r h− ancora una volta h+ e h− sono rispettivamente i semispazi aperti positivo e negativo indotti da h. Naturalmente la radice dell’albero corrisponderà all’intero spazio originario.
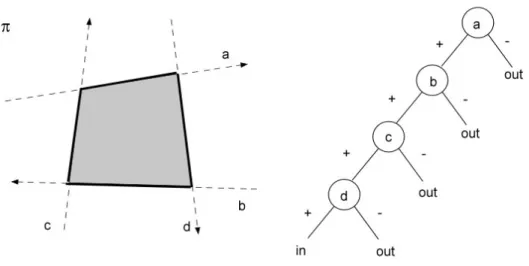
Figura 1.7 – poligono (a sinistra) e sua rappresentazione attraverso albero BSP (a destra)
Gli alberi BSP sono estremamente efficaci nel descrivere poliedri [10]. Si prenda come esempio la figura 1.7, dove è mostrato un semplice poligono e il relativo albero BSP. La retta a suddivide il piano π in due semipiani, l’uno positivo l’altro negativo; la retta b a sua volta divide il semipiano positivo in altri due semipiani, e così
rispettivamente fanno c e d. Tutte le rette sono orientate in modo che l’interno del poligono giaccia sempre nel semipiano positivo da esse indotto: così la cella associata alla foglia più a sinistra coincide proprio con la superficie interna del poligono; quelle associate alle foglie a destra descrivono invece regioni di spazio esterne al poligono. La classificazione delle foglie in “interne” ed “esterne” rende possibile eseguire operazioni insiemistiche (unione, intersezione, differenza) sui poliedri manipolando gli alberi BSP che li descrivono [12]. Come vedremo, questa caratteristica si rivelerà estremamente importante.
1.5.2 Scopo di VP
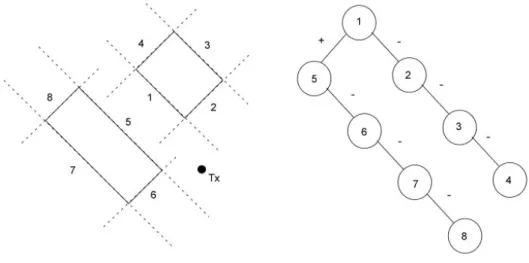
L’algoritmo di ottimizzazione, sia durante la predizione che nel computo della visibilità piastra-piastra, necessita di determinare l’ordine nel quale verranno processate le piastre secondo la priorità di visibilità front-to-back rispetto ad un punto di riferimento; cioè, dato un punto di riferimento (punto di vista), le piastre devono essere processate da quella più vicina a quella più lontana rispetto a tale punto, secondo il cosiddetto algoritmo del pittore. Gli alberi BSP si rivelano estremamente efficienti nel determinare tale ordine [13]; supponiamo infatti di confrontare la posizione del punto di vista rispetto alla radice dell’albero che descrive lo scenario. Possono verificarsi due possibilità: che il punto si trovi nella regione positiva indotta dal partizionatore della radice, o in quella negativa. Chiameremo il “lato” del nodo sul quale è locato il punto di vista “lato contenente”, e “altro lato” l’opposto. L’ordine con il quale l’albero deve essere visitato è quindi: a) “lato contenente”, b) nodo e c) l’ “altro lato”. Infatti sappiamo che se il punto di vista è in uno dei due semispazi, per esempio h+, determinati dal partizionatore h, nessun oggetto che giace nell’altro semispazio può essere più vicino al punto di vista rispetto al partizionatore stesso o a uno qualunque degli oggetti che giacciono in h+. Visitando ricorsivamente ogni nodo dell’albero secondo l’ordine stabilito, si riesce quindi ad ordinare le piastre secondo il tipo di priorità scelta. Con riferimento alla figura 1.8, dove tutte le piastre presentano normale esterna, si consideri infatti il seguente esempio.
La posizione del Tx viene confrontata con il partizionatore della radice dell’albero: poiché si trova nel semispazio positivo della piastra 1, il Tx viene passato al sottoalbero positivo; viene quindi confrontato con il partizionatore del nuovo nodo
(piastra 5), rispetto al quale si trova ancora nel semispazio positivo. Tuttavia non esiste il sottoalbero positivo di questo nodo, per cui la prima piastra ad essere inseita in lista è la 5. Il Tx viene quindi passato al sottoalbero negativo, con lo stesso procedimento: vengono immesse in lista nell’ordine le piastre 6, 8 e 7. Terminata la scansione del sottoalbero positivo della radice, si inserisce la piastra 1 e si passa ad analizzare il sottoalbero negativo: vengono immesse nell’ordine le piastre 2, 4 e 3. Alla fine del processo avremo ottenuto la sequenza di piastre 5-6-8-7-1-2-4-3.
Figura 1.8 – Semplice scenario e sua rappresentazione attraverso albero BSP
Tuttavia, l’inevitabile inaccuratezza dovuta alla finitezza del floating point può generare degli errori nei vari passi che conducono alla costruzione dell’albero: esso non viene realizzato come ci aspetteremmo. Alcune semplici prove dimostrano che questo indesiderabile fenomeno ha maggiore probabilità di presentarsi al crescere del numero delle piastre. Ciò naturalmente si ripercuote sull’ordinamento front-to-back, generando errori in sede di determinazione del raggio. Di conseguenza si è scelto di affiancare al tipo di scansione dell’albero descritto poco fa un ulteriore ordinamento basato sulla distanza crescente dal punto di osservazione, concordemente con l’algoritmo del pittore; la distanza dal punto di osservazione è definita come quella tra tale punto e il centro della piastra. Quindi in prima istanza le piastre da aggiungere alla lista da processare vengono selezionate secondo la priorità front-to-back; una volta effettuata la selezione, viene creato un nuovo elemento che contiene l’indice, le coordinate dei vertici e la distanza della piastra; tale elemento viene inserito in lista nella posizione determinata dalla sua distanza.
1.5.3 Implementazione di VP
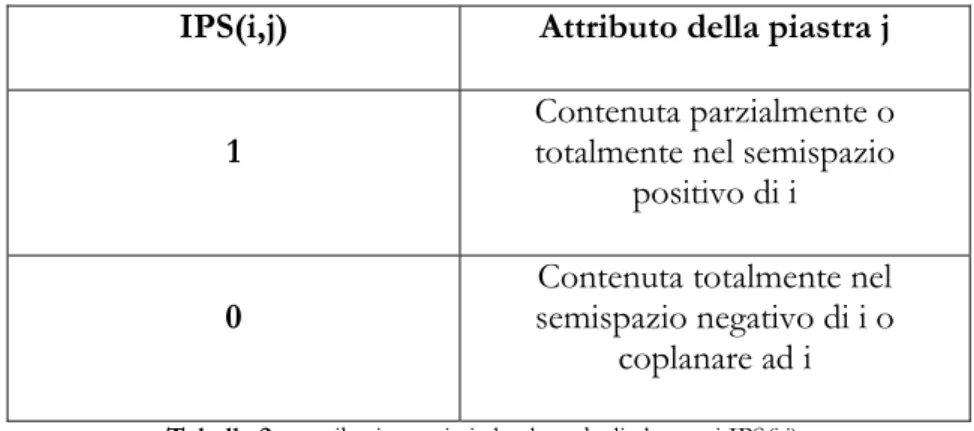
Determinare questo ordine implica di conseguenza costruire l’albero BSP che descrive lo scenario; tale albero verrà chiamato nel seguito Visibility Priority (VP). Il partizionatore di ogni nodo dell’albero sarà l’iperpiano di supporto (la retta, nell’approccio 2.5D) passante per una piastra (il suo top edge). Le piastre usate saranno naturalmente le n che rispettano l’ipotesi di lavoro. La struttura di ogni nodo è molto semplice, essendo formata da un campo INTEGER che registra l’indice della piastra, da 4 campi REAL per memorizzarne i vertici e da due puntatori, rispettivamente al sottoalbero positivo e a quello negativo. Non sono necessarie altre informazioni poiché tutte quelle relative all’appartenenza di una piastra j ad uno dei due semispazi indotti da quella i, utilizzate per la costruzione dell’albero, sono memorizzate in una matrice simile a IPS. Si è detto infatti che ogni elemento di IPS può assumere due valori, il cui significato è riportato nella Tabella 2.
IPS(i,j) Attributo della piastra j 1 Contenuta parzialmente o totalmente nel semispazio
positivo di i
0 semispazio negativo di i o Contenuta totalmente nel coplanare ad i
Tabella 2 – attributi associati al valore degli elementi IPS(i,j)
Possiamo pensare di costruire una matrice simile i cui elementi possano assumere valori che combinati con quelli di IPS esprimano per ogni piastra j uno degli attributi che ci serviranno nella costruzione di VP: “contenuta totalmente nel semispazio positivo di i”, “contenuta totalmente nel semispazio negativo di i”, “appartenente ad entrambi i semispazi di i”, “coplanare ad i”. Questa nuova matrice di dimensione NxN, chiamata Total Intelligent Plate Storage (TIPS), sarà allocata prima della costruzione di VP e deallocata al termine del preprocessing. Inizialmente TIPS verrà inizializzata in modo che gli attributi associati ai suoi valori siano complementari a quelli di IPS. La pseudo-codifica del codice che inizializza TIPS è riportata più oltre.
In questo modo TIPS(i,j) può assumere i valori -2 (“j è coplanare ad i”), 0 (“j è contenuta totalmente nel semispazio positivo di i” ) e 1 (“j è contenuta totalmente o parzialmente nel semispazio negativo di i”). Sottraendo TIPS da IPS e memorizzando il risultato in TIPS, si ottengono gli attributi cercati, riportati nella Tabella 3.
La creazione di TIPS evita la ridondanza che si avrebbe nell’andare a computare ogni volta le relazioni necessarie alla costruzione di VP e alla determinazione della visibilità piastra-piastra.
La costruzione di alberi binari come VP deve far fronte a due opposte esigenze. Da un lato infatti essi devono essere ben bilanciati, ovvero ogni ramo dell’albero deve avere all’incirca lo stesso numero di nodi: ciò diminuisce notevolmente il tempo per la ricerca di un valore registrato nell’albero [9]. Supponiamo infatti di avere 32.767 valori in una lista; mediamente, per trovare il valore cercato se ne dovranno scandire 16.384. Per contro, tutti i valori possono essere memorizzati in un albero binario di soli 15 livelli, così che il numero massimo di scansioni necessarie per la ricerca sia proprio 15. Nel nostro caso, fare questo significa scegliere come partizionatore di
TIPS=0 DO i=1, N DO j=1, N IF (i=j) THEN CONTINUE ELSE cont=0 DO m=1 a #vertici di j dot_product=0 PAjm =calcola_vettore(vert(i,1), vert(j,m)) dot_product(ni, PAjm) IF (dot_product<0) THEN TIPS(i,j)=1 EXIT
ELSE IF (dot_product=0) THEN cont=cont+1 ENDIF END DO IF (cont=#vertici di j) THEN TIPS(i,j)=-2 ENDIF END IF END DO END DO
ogni spazio la piastra che all’incirca ha lo stesso numero di piastre nei suoi due semispazi. Dall’altro lato, per quel che riguarda gli alberi BSP, si deve fare in modo che ogni partizionatore divida il minor numero possibile di oggetti (piastre) nello scenario, poiché questo oggetto andrà “replicato” in modo da essere presente in entrambi i semispazi; ciò equivale a dire che ogni oggetto partizionato da origine a due nodi, aumentando la dimensione dell’albero. Per evitare ciò, si dovrebbe scegliere come partizionatore la piastra che ha tutte le altre piastre in uno solo dei suoi due semispazi.
TIPS(i,j) Attributo della piastra j
2 Coplanare ad i
1 Contenuta totalmente nel
semispazio positivo di i
0 Appartenente ad entrambi i
semispazi di i
-1 Contenuta totalmente nel
semispazio negativo di i
Tabella 3 – attributi associati al valore degli elementi TIPS(i,j)
La soluzione scelta è quindi un compromesso tra queste due esigenze. In prima istanza si da la priorità a quelle piastre che dividono una regione di spazio in due semispazi contenenti all’incirca lo stesso numero di piastre. In seconda istanza, si privilegiano quelle che partizionano il minor numero possibile di piastre. Si prenda come esempio la figura 1.8: le piastre 3 e 4 presentano lo stesso numero di piastre in entrambi i loro semispazi; tuttavia la piastra 4 da origine ad eventi “splitted”, mentre la 3 a nessuna: quindi viene selezionata quest’ultima. Per evento “splitted” si intende il
partizionamento di un oggetto in due parti per opera di un piano o di una retta; il verificarsi di uno di questi eventi obbliga a “replicare” la piastra in due nodi, in questo particolare caso ognuno contenente le coordinate degli estremi del segmento che giace nel relativo semispazio.
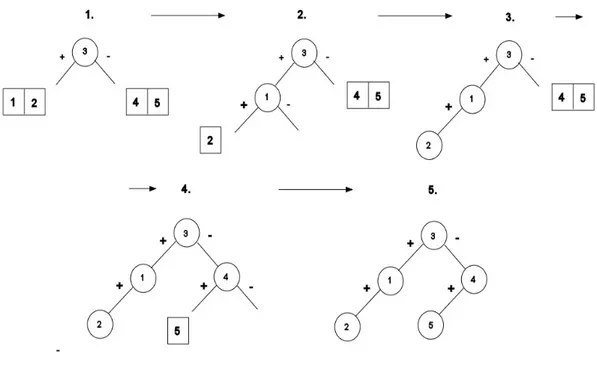
Figura 1.10 –Processo di costruzione dell’albero BSP relativo alla fig. 1.9
Per meglio comprendere come funzioni la costruzione di VP, si consideri ancora la fig. 1.9; si è detto che il primo piano ad essere selezionato come partizionatore è quello di supporto alla piastra 3: le piastre 1 e 2 formeranno il suo sottoalbero positivo, quelle 4 e 5 il sottoalbero negativo. Scelta la radice (o in generale un nuovo nodo) il processo va replicato per ogni sottospazio dei due indotti: per quello positivo come nuovo partizionatore possiamo scegliere indifferentemente il piano di supporto della piastra 1 o della 2 (entrambe hanno una piastra in uno dei relativi
sottospazi e non danno luogo a nessun evento “splitted”); per quello negativo allo stesso modo avremo la piastra 4 o 5. Il processo viene replicato fino a che non resta al massimo una piastra in ogni sottospazio. La fig. 1.10 riporta la costruzione dell’albero relativo al semplice scenario di fig. 1.9.
E’ importante notare che se avessimo scelto come radice dell’albero la piastra 4, avremmo avuto più nodi in quanto il “frammento” af della 3 e quello ce della 2 avrebbero originato due nuovi nodi da inserire nel sottoalbero negativo, mentre quelli fb e eb allo stesso modo avrebbero dovuto essere inseriti nel sottoalbero positivo.
In [13] è riportata le formula generale per calcolare il numero massimo fD( )n di volumi (celle) di uno spazio D-dimensionale che possono essere create con n piani di dimensione D-1 (partizionatori). 0
( )
D D in
f
n
i
=⎛ ⎞
=
⎜ ⎟
⎝ ⎠
∑
(4) Il numero massimo di nodi dell’albero BSP è pari a 2 ( )fD n . Nel nostro caso, talenumero sarà:
2
2
n
N
=
n
+ +
n
(5)Quindi l’albero VP richiederà da un minimo di (n x 18) byte ad un massimo di
2
( (n + +n 2) 36)x byte. Come si è visto nell’algoritmo di costruzione dell’albero, si
sono ridotti al minimo sia la memoria necessaria per ogni nodo sia gli eventi di tipo “splitted” che portano alla duplicazione dei nodi. Questa scelta si rivela corretta se pensiamo che per n=5000, la memoria richiesta per registrare VP va da 0.09 Mbyte ad un massimo nominale di 858.48 Mbyte nel caso peggiore. Il limite superiore come è evidente cresce con 2
( )
O n , quello inferiore con ( )O n .Una volta creata TIPS e scelta la regola di selezione delle piastre, l’albero VP è costruito ricorsivamente: selezionata come partizionatore una piastra tra le k possibili organizzate in una lista (la struttura dei nodi è la stessa di quelli dell’albero VP), le restanti k-1
vengono ripartite tra i due semispazi individuati e quindi organizzate in due nuove liste. Per ogni semispazio viene scelta una nuova piastra, che da origine ad altri due regioni e conseguentemente a due nuove liste di piastre. Il processo termina quando non ci sono più piastre da inserire nell’albero. La pseudo-codifica è riportata di seguito.
La subroutine che costruisce l’albero prende il nome di MAKEVP. La condizione di uscita dalla ricorsione è contenuta nella pseudo-routine “inserisci_nodo”: oltre ad inserire il nodo k nell’albero, esso verifica anche che la lista delle piastre non sia formata da questo solo nodo, nel qual caso il controllo è restituito alla routine chiamante.
RECURSIVE SUBROUTINE makevp (lp: lista_piastre, na: nodo_albero) k=scelta_piastra(lp)
CALL estrazione(k, lp) CALL inserisci_nodo(k, na) NULLIFY(pos_list, neg_list)
! pos_list è la lista delle piastre che giacciono nel semispazio positivo, ! neg_list quella delle piastre del semispazio negativo
DO i=1 alla dimensione di lp n=confonta(k,i) SELECT CASE(n) CASE(2) IF (norm_est(i)=norm_est(k)) THEN CALL add(pos_list, k) ELSE CALL add(neg_list, k) ENDIF CASE(1) CALL add(pos_list, k) CASE(0)
! k+ e k- sono i segmenti del top edge della piastra appartenenti rispettivamente ! al semipiano positivo e negativo indotti dal partizionatore
CALL dividi_piastra(k, k+, k-) CALL add(pos_list, k+) CALL add(neg_list, k-) CASE(-1) CALL add(neg_list, k) END SELECT END DO
IF (ASSOCIATED(pos_list)) CALL makevp(pos_list, na%pos) IF (ASSOCIATED(neg_list)) CALL makevp(neg_list, na%neg) END SUBROUTINE
L’argomento del costrutto SELECT CASE è proprio il valore registrato in TIPS(k,i). Nel caso in cui le piastre siano coplanari, si è scelto di assegnare la piastra i al semispazio positivo di k se le loro normali sono uguali, al semispazio negativo se sono opposte.
La procedura che contiene tutte le routine necessarie alla creazione di VP prende il nome di CREA_VPTREE. Il suo funzionamento è riportato nel diagramma di flusso 2.
Di seguito viene riportata anche la pseudo-codifica della routine FRONT_TO_BACK che crea la lista ordinata secondo l’algoritmo del pittore delle piastre da elaborare nelle successive due fasi. Gli elementi di questa lista contengono le informazioni sulla piastra da processare: l’indice, le coordinate degli estremi del top edge o del suo frammento, la distanza dal punto di osservazione.
Questa procedura rimane sostanzialmente invariata nella fase di predizione e nella determinazione della visibilità piastra-piastra; l’unica differenza tra queste due fasi, come vedremo, sarà nelle pseudo-routine “pos_side”, che determina la posizione del punto di vista rispetto alla piastra, e nella routine “display” che contiene i controlli per la selezione della piastra.
RECURSIVE SUBROUTINE front_to_back(eye: punto di vista, t: nodo corrente di VP) ! “nodo_lista” è l’elemento inizializzato con le informazioni sulla piastra se essa risulta ! soddisfare le condizioni richieste dalla procedura “display”
! “testa” è il puntatore alla lista nella quale va inserita “nodo_lista” IF (.NOT.(ASSOCIATED(t))) RETURN
IF (pos_side(t, eye)) THEN
CALL front_to_back(eye, t%pos) CALL display(t, nodo_lista)
CALL ordina_lista(testa, nodo_lista) CALL front_to_back(eye, t%neg) ELSE
CALL front_to_back(eye, t%neg) CALL display(t, nodo_lista)
CALL ordina_lista(testa, nodo_lista) CALL front_to_back(eye, t%pos) END IF