CAPITOLO 2
OTTIMIZZAZIONE ALGORITMICA
Nel capitolo precedente è stato presentato l’algoritmo Retinex così come è stato proposto dai ricercatori di Trieste. L’obiettivo di questo lavoro è quello di tradurre il codice proposto in linguaggio C, in una macchina implementabile su chip che sia in grado di espletare le stesse funzioni con la massima fedeltà possibile.
In ambito hardware, certe funzioni, soprattutto quelle lineari, non potranno essere realizzate in un circuito integrato. Sarà allora necessario effettuare delle semplificazioni, che potrebbero essere semplici linearizzazioni delle funzioni più complicate, oppure quantizzazioni non uniformi per mezzo di tabelle di numeri precalcolati, dette Look-Up-Table. Si capisce che tutte queste operazioni, volte a rendere realizzabili e meno pesanti alcuni dei calcoli, avranno come conseguenza la perdita, almeno in parte, di prestazioni sul risultato finale. Parallelamente alle operazioni di semplificazione degli operatori non lineari, saranno quindi effettuati dei test al fine di capire se ci stiamo allontanando troppo o no dalle prestazioni dell’algoritmo originale. Come strumenti saranno usati un parametro, il PSNR (rapporto segnale – rumore di picco), per dare dei raffronti oggettivi, e saranno mostrate anche le immagini intermedie e di uscita del sistema globale, al fine di
ottenere un’indagine visiva, che comunque è soggettiva, perché dipendente dall’opinione dell’osservatore. L’obiettivo finale di questo lavoro è ottenere un sistema digitale ottimo che sia il giusto compromesso tra: riproduzione fedele dell’algoritmo originale, costo, complessità e consumo di potenza.
Il materiale a disposizione per il progetto che si intende realizzare è costituito da: una descrizione precisa e fedele dell’algoritmo teorico tramite codice C, un set di tre immagini, una chiara, una scura e una con toni misti, che costituisce un campione rappresentativo delle possibili tipologie di immagine di cui si vorrebbe migliorare la qualità, delle sorgenti Matlab (load_image.m, display_image.m e save_image.m) che permettono di importare, visualizzare e salvare le immagini prima e dopo l’elaborazione. Il formato di tali immagini, infatti, è un particolare formato raster a 8 bit con intestazione ed è chiamato .img. I programmi Matlab, tramite degli stream, leggono all’interno del file, ne estraggono informazioni circa la dimensione e il punto di inizio dei campioni, e caricano in una matrice la serie di valori compresi tra 0 e 255 corrispondenti ai singoli pixel. Il valore 0 corrisponde al nero, e 255 al bianco, mentre i valori intermedi sono le codifiche dei toni di grigio. Sempre avvalendosi di Matlab, è possibile effettuare l’operazione inversa che crea un file .img a partire da una matrice di interi.
Figura 6. Set di tre immagini scelto come campione rappresentativo: swan.img, alpi.img, bedroom.img.
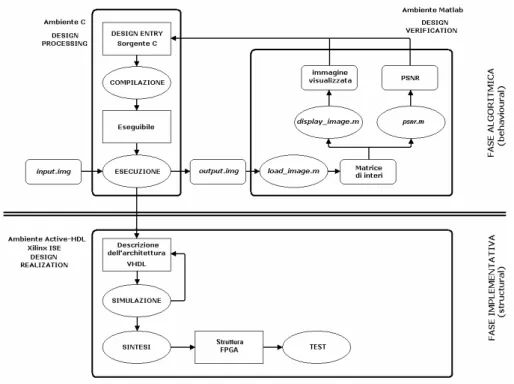
La descrizione dell’algoritmo viene fornita in ambiente C e allo stesso modo si descriverà l’algoritmo finale ottimizzato. Le simulazioni ed i test di controllo verranno eseguiti negli ambienti C e Matlab, e solo alla fine sarà realizzata una descrizione di tipo hardware per mezzo del linguaggio VHDL. La potenza e la flessibilità del C permettono, infatti, di eseguire simulazioni molto veloci, mentre in ambiente VHDL le stesse operazioni comporterebbero tempi di gran lunga superiori con la conseguenza di rallentare tutto lo sviluppo del progetto. In figura 7 è illustrato il flusso di progetto che verrà seguito in questo lavoro. I percorsi di retroazione rappresentano le modifiche che sono effettuate durante la fase di ottimizzazione del lavoro.
Figura 7. Flusso di progetto.
Risulta dunque evidente la divisione tra la fase algoritmica e la fase implementativa, ovvero la descrizione in VHDL con sintesi finale.
2.1 C
ONFRONTO TRA GLI ALGORITMI RET_
SOFT E RET_
HARDI ricercatori di Trieste ci hanno fornito due versioni dell’algoritmo Retinex, chiamate ret_soft.c e ret_hard.c La prima, software, è scritta in una forma puramente algoritmica e fa uso di operatori fortemente non lineari, ed è dunque
adatta per essere implementata su un processore in grado di svolgere qualsiasi calcolo. La seconda, hardware, è una versione semplificata che si rende adatta all’implementazione su circuiti integrati. Gli operatori non lineari sono stati sostituiti da operazioni di complessità inferiore come confronti per mezzo di comparatori con soglia ed altro. Ovviamente, la versione soft è migliore in termini di prestazioni. Vediamo adesso di mettere a confronto i due algoritmi per poter fare una scelta. Il calcolo della luminanza y(i,j) non è realizzato con lo stesso procedimento, e differisce soprattutto nel calcolo dei coefficienti So ed Sv.
Versione ret_soft_c:
Calcolo dei sensori di margine So(i,j) ed Sv(i,j):
So= 2 10 ( 1, ) 1 log ( 1, ) 1 k x n m x n m δ ⎡ ⎛ − + ⎞⎤ + ⎢ ⎜ + + ⎟⎥ ⎝ ⎠ ⎣ ⎦ Sv= 2 10 ( , 1) 1 log ( , 1) 1 k x n m x n m δ ⎡ ⎛ − + ⎞⎤ + ⎢ ⎜ + + ⎟⎥ ⎝ ⎠ ⎣ ⎦ Calcolo di y(i,j):
(
)
o v(
o v)
o v α y n-1,m S +y(n,m-1)S + S +S (1-α)+1 x(n,m) y(n,m)= S +S +1 ⎡ ⎤ ⎡ ⎤ ⎣ ⎦ ⎣ ⎦ (2.1)siamo di fronte a computazioni esatte dei vari coefficienti e dell’uscita del filtro. Versione ret_hard_c:
Calcolo dei sensori di margine So(i,j) ed Sv(i,j):
if (fabs((log10(x[i-1][j]+1)-log10(x[i+1][j]+1)))>=th) mo[i][j]=1; else mo[i][j]=0; if (fabs((log10(x[i][j-1]+1)-log10(x[i][j+1]+1)))>=th) mv[i][j]=1; else mv[i][j]=0;
Compaiono ancora dei termini logaritmici, ma anziché fare un calcolo esatto del coefficiente, il suo valore può essere 0 o 1 in seguito ad un confronto con la soglia K impostata dall’utente.
Calcolo di y(i,j): for (i=1; i<=dimx-2; i++) { for (j=1; j<=dimy-2; j++) {
fo=y[i-1][j]*(coeff_b)+y[i+1][j]*(1-coeff_b); fv=y[i][j-1]*(coeff_b)+y[i][j+1]*(1-coeff_b); ff=(fo+fv)/2;
if ((mo[i][j]==1) && (mv[i][j]==1)) y[i][j]=y[i][j]; if ((mo[i][j]==1) && (mv[i][j]==0)) y[i][j]=(int)fv; if ((mo[i][j]==0) && (mv[i][j]==1)) y[i][j]=(int)fo; if ((mo[i][j]==0) && (mv[i][j]==0)) y[i][j]=(int)ff; dove coeff_b corrisponde ad α .
Il calcolo dell’uscita di luminanza non è più visto come una funzione razionale, ma, calcolati i coefficienti Fo, Fv e definito Ff come la loro media equipesata, si
pone y(i,j) pari a se stessa se So ed Sv sono pari ad 1, altrimenti y(i,j) = Ff se So ed
Sv sono nulli. Infine y(i,j) assume i valori Fo ed Fv se, rispettivamente, So è nullo e
Sv vale 1 e viceversa. Dunque con un multiplexer ed alcune porte and si può
realizzare il calcolo del segnale di luminanza.
Fin qui la versione hard sembrerebbe la migliore, essendo più facile da implementare, ma un confronto di prestazioni tra i due algoritmi ha portato all’esclusione della versione ret_hard.c dato che si è dimostrata non efficiente per una delle tre immagini sorgente. Ecco cosa succede infatti nei tre casi impostando i parametri consigliati: nelle figure 8-11 riportiamo rispettivamente nella colonna di sinistra e nella colonna di destra le immagini di uscita ottenute con ret_soft.c e ret_hard.c
Figura 8. Immagine swan.img filtrata con Figura 9. Immagine swan.img filtrata con ret_soft. ret_hard.
Figura 10. Immagine bedroom.img filtrata con Figura 11. Immagine bedroom.img
ret_soft. filtrata con ret_hard.
Dall’indagine visiva possiamo concludere che la versione ret_hard non riesce a trattare correttamente alcune immagini, in particolare quelle ricche di toni scuri. La causa di questo problema risiede nel troncamento a numeri interi dei risultati intermedi del calcolo di y(i,j). Scegliamo comunque di implementare la versione ret_soft.c in modo da ottenere un’ulteriore versione semplificata a partire da quella algoritmica. La versione hard, di fatto, comporta pochi sforzi per la sua realizzazione e dunque non si presenta particolarmente interessante.
2.2 M
ETODOLOGIE DI OTTIMIZZAZIONEDopo aver scelto l’algoritmo base tra i due a disposizione, è giunto il momento di parlare delle tecniche di semplificazione e ottimizzazione delle operazioni necessarie per il calcolo della luminanza. Più avanti sarà definita un’architettura che sarà in seguito descritta in linguaggio hardware VHDL. L’espressione analitica della funzione di trasferimento del filtro (2.1) può essere scritta in forma semplificata, se definiamo i coefficienti fo ed fv come:
( 1, ) (1 ) ( , ) ( , 1) (1 ) ( , ) fo y i j y i j fv y i j y i j α α α α = − + − = − + − (2.2) ottenendo così: ( , ) ( , ) 1 So fo Sv fv y i j y i j So Sv + + = + + (2.3)
Sono dunque presenti, per ora, moltiplicatori e sommatori. Supponiamo per il momento che il blocco finale sia un semplice divisore per calcolare y(i,j) come rapporto tra 2 valori.
Per quanto riguarda il calcolo della riflettanza, essendo definita come rapporto tra immagine originale ed uscita di luminanza, il progetto consisterà nell’implementazione di un divisore dedicato.
Tornando al calcolo della luminanza, vedremo se e come sia possibile semplificare le operazioni necessarie per il calcolo dei coefficienti So, Sv, Fo e Fv.
I coefficienti con apice ‘o’ sono relativi alla direzione orizzontale, mentre quelli con apice ‘v’ si riferiscono alla direzione verticale di scansione. Dato che a livello di algoritmo, i calcoli nel caso di coefficienti omonimi orizzontali e verticali (per esempio: So ed Sv) sono identici e cambiano solo gli argomenti, in
realtà si tratta di progettare soltanto due blocchi che potranno essere poi replicati nel caso si scelga un’architettura parallela. Per quanto riguarda sommatori e moltiplicatori, per la loro implementazione si veda il cap. 4, riguardante le scelte architetturali.
La prima fase del lavoro di ottimizzazione algoritmica consisterà nello studiare la programmabilità del sistema. I vari coefficienti S ed F richiedono l’impostazione di alcuni valori programmabili. Esistono però dei valori predefiniti che sono stati consigliati dai ricercatori di Trieste. Ci chiediamo dunque se è necessario mantenere costanti tali valori o se vale la pena poter impostarne qualcuno dall’esterno. La possibilità di variare alcuni parametri ha degli aspetti positivi e negativi: se da un lato infatti, all’aumentare della programmabilità sarebbe possibile ottenere vari tipi di prestazioni e modalità d’utilizzo, dall’altro un elevato numero di valori da impostare potrebbe rendere difficile l’utilizzo del sistema da parte dell’utente, si otterrebbe cioè un sistema poco user friendly. Per il calcolo della luminanza y(i,j) i parametri da impostare sono tre: K, α, e Nc (Numero di cicli di scansione). K è una soglia che interviene nel calcolo dei coefficienti S: So = 2 10 ( 1, ) 1 log ( 1, ) 1 k x n m x n m δ ⎡ ⎛ − + ⎞⎤ + ⎢ ⎜ + + ⎟⎥ ⎝ ⎠ ⎣ ⎦ Sv = 2 10 ( , 1) 1 log ( , 1) 1 k x n m x n m δ ⎡ ⎛ − + ⎞⎤ + ⎢ ⎜ + + ⎟⎥ ⎝ ⎠ ⎣ ⎦
α è invece argomento dei coefficienti F e regola la banda del filtro RRF. Più è alto e minore è la banda. Al crescere di α aumenta dunque l’effetto passa basso. Come possiamo vedere nell’espressione analitica dei coefficienti F, al crescere di α viene dato maggior peso ai pixel vicini, a scapito del pixel centrale. Il caso α = 1 non è ammesso. ( 1, ) (1 ) ( , ) ( , 1) (1 ) ( , ) fo y i j y i j fv y i j y i j α α α α = − + − = − + −
La fase di studio della programmabilità del sistema consisterà dunque nel verificare cosa succede nel caso in cui venga variato uno dei parametri, tenendo fermi gli altri ai valori predefiniti, che sono K = 0.01 ; α = 0.750 e Nc = 4. Una volta decisi alcuni valori interessanti, il passo successivo consisterà nella semplificazione degli operatori non lineari presenti nel calcolo dei coefficienti.
Successivamente il sistema semplificato sarà descritto in una nuova versione dell’algoritmo ret_soft.c, fedele alle scelte architetturali appena fatte. Grazie al nuovo codice sarà possibile effettuare le simulazioni in ambiente C con i vantaggi già elencati. In questa fase saranno lasciate invariate, rispetto all’algoritmo teorico, tutte quelle parti che non interessano questo lavoro, ovvero i blocchi dedicati all’elaborazione del segnale di luminanza, riflettanza, ed il moltiplicatore per la ricostruzione finale dell’immagine.
Nell’ideare un’architettura plausibile per i blocchi di calcolo S e F, la prima scelta è stata quella di eliminare la presenza di operatori non lineari come logaritmi e potenze. Queste operazioni sono state linearizzate seguendo due possibili approcci: l’approssimazione lineare e l’approccio a Look-Up Table. Nel primo caso si tratta di approssimare una funzione con una serie di spezzate; nel secondo, presa una certa funzione, si cerca di quantizzarla con valori costanti per mezzo di una caratteristica a scala. La look-up-table è preferibile da un punto di vista di risorse richieste, dato che i valori della funzione approssimante vengono semplicemente letti in una ROM opportunamente programmata. L’interpolazione lineare richiede invece un’architettura un po’ più complessa. Dovendo calcolare l’equazione di una retta sarà necessaria la presenza di un moltiplicatore oltreché di
un sommatore per la quota. D’altro canto si tratta di un calcolo più preciso, specialmente se il passo di quantizzazione della look-up-table non è troppo fine.
Cercheremo di applicare entrambe le tecniche e sceglieremo quella più soddisfacente. Lo scopo finale è realizzare un trade-off tra prestazioni e risorse richieste sul chip. Nel caso di approccio Lut (look-up-table ) sarà necessario anche uno studio statistico delle immagini campione per decidere sul tipo di campionamento da effettuare. Di solito, infatti, nel realizzare una Lut, è conveniente operare una quantizzazione a distribuzione non uniforme delle soglie, perché statisticamente esisteranno delle zone nel dominio della funzione per cui è più probabile che si debba calcolare la funzione stessa, ed altre zone meno importanti. Dallo studio statistico e da uno studio di funzione sarà chiaro quali saranno le zone che meritano una maggiore concentrazione di valori campionati.
Definiamo adesso il parametro che ci consentirà di dare dei risultati oggettivi alle nostre analisi. Si tratta del già menzionato PSNR ( Rapporto segnale – rumore di picco). In simboli:
PSNR = 10log10 25522
MSE dove MSE
2 =
(
)
2 1 1 1 ( , ) *( , ) M N i j I i j I i j M N = = − ⋅∑∑
(2.4)MSE = Mean Square Error ; M= dimensione verticale matrice; N= dimensione orizzontale matrice
I(i,j) = immagine originale ; I*(i,j) = immagine filtrata.
MSE è l’errore quadratico medio valutato pixel a pixel tra le due immagini che si vogliono confrontare, che può al massimo valere 255 nel caso estremo in cui si confrontino un’immagine tutta bianca con una tutta nera.
In questo caso il PSNR vale 0 dB, mentre nel caso di immagini identiche MSE vale 0 e il PSNR diverge all’infinito. Per poter calcolare agevolmente questo parametro, è stata descritta in ambiente Matlab la funzione psnr.m (cfr. appendice), che, date due immagini sotto forma di matrice di interi, controlla che la loro dimensione sia uguale, ne calcola il valore quadratico medio ed infine il PSNR.
Le immagini che verranno messe a confronto sono le uscite elaborate dall’algoritmo soft originale e da quello modificato a parità di parametri impostati.
Quando non specificato diversamente, per uscite intendiamo le uscite del sistema globale, dove i blocchi a valle del divisore di riflettanza saranno considerati ideali, come già anticipato.
Dunque come termine di confronto per il calcolo del PSNR sarà considerato l’algoritmo ret_soft.c., se non diversamente indicato.
Consideriamo dunque l’algoritmo ret_soft come target da avvicinare il più possibile. La specifica minima da rispettare in termini di PSNR è il valore 30 dB, valore tipicamente considerato come soddisfacente da chi studia sistemi di elaborazione delle immagini. Cercheremo dunque di ottenere, in questa fase, PSNR sempre ben superiori a questo limite per due motivi: i blocchi a valle sono considerati ideali e pensando ad una loro implementazione semplificata, ci sarà un ulteriore calo del PSNR; secondariamente, dobbiamo tener presente che al momento della descrizione e simulazione in VHDL, sicuramente i valori del PSNR saranno destinati a calare ancora di qualche dB per via di ulteriori perdite nel passaggio da C a hardware. Cercheremo dunque prestazioni in termini di PSNR vicine ai 40 dB.
Accosteremo alla stima oggettiva data dal PSNR, la stima soggettiva dell’ispezione visiva poiché il fine ultimo del sistema è ottenere immagini che dunque devono essere osservate, ed anche perché in alcuni casi il PSNR da solo potrebbe indurre ad errori di valutazione. Per esempio, nel caso in cui ci sia un problema localizzato in certo frame, come potrebbe essere una piccola area completamente nera, la stima del PSNR essendo una media, probabilmente darebbe un risultato accettabile non mostrando l’anomalia, ma grazie all’ispezione visiva il problema è ben presto evidenziato. Nemmeno l’ispezione visiva da sola è sufficiente: si pensi al caso di due immagini simili, da dover confrontare. Non sapendo quale scegliere, il PSNR delle due rispetto all’immagine di riferimento ci aiuterà nella scelta. Utilizzeremo contemporaneamente i due metodi di confronto, soggettivo ed oggettivo.
2.3 A
NALISI DEL GRADO DI PROGRAMMABILITÀ DEL SISTEMAUna volta lanciato l’eseguibile ret_soft.exe, dopo aver immesso il nome del frame che si desidera elaborare, vengono chiesti, in sequenza, i valori di alcuni parametri. Quelli che interessano il presente lavoro dedicato al filtro RRF ed al calcolo dell’uscita di riflettanza sono: K, α, e Nc.
Abbiamo già detto che esistono dei valori predefiniti per i parametri, ma ciascuno di questi può essere variato nel proprio range. L’alterazione di alcuni o di tutti i valori può far funzionare il sistema in modo ad esempio da risparmiare potenza, od ottenere diverse prestazioni. È necessario dunque, stabilire il grado di programmabilità del sistema, vale a dire cercare di capire se esistono parametri il cui valore non può essere cambiato o se ce ne sono altri per cui merita definire alcuni valori limite, comunque non più di due o tre, in modo da non rendere troppo difficile l’impiego del sistema per l’utente. Per raggiungere tale obiettivo sono stati effettuati dei test in cui è stato variato il valore di uno dei parametri, fissando gli altri ai loro valori ottimi. Visionando poi le immagini di uscita del filtro RRF si sono tratte delle conclusioni su ciascun parametro. Nei prossimi paragrafi si riportano tutti i procedimenti seguiti.
2.3.1 Ruolo del parametro K
L’obiettivo è indagare sull’effetto del parametro K sull’intero sistema e studiarne il range ottimo di variazione. K non ha particolari campi di esistenza, si sa che è un valore di soglia positivo, quindi, almeno teoricamente, potrebbe assumere qualunque valore maggiore di zero. Il valore K modula la selettività del filtro RRF, dato che all’aumentare del parametro i coefficienti So ed Sv assumono valori
significativi più facilmente.
Vediamo l’effetto visivo della variazione di K, iniziando da K = 0.01 ed aumentandolo ogni volta di un fattore 10. Gli altri parametri assumono i relativi valori consigliati. Riportiamo alcune immagini ottenute per valori molto diversi del fattore K.
Figura 12. Immagine swan.img filtrata con Figura 13. Immagine swan.img filtrata con ret_soft e K=0.01 ret_soft e K=100
Figura 14. Immagine alpi.img filtrata con Figura 15. Immagine swan.img filtrata con ret_soft e K=0.01 ret_soft e K=0.1
Figura 16. Immagine bedrooom.img filtrata con Figura 17. Immagine swan.img filtrata ret_soft e K=0.01 con ret_soft e K=0.1
L’ispezione visiva non evidenzia grandi differenze, nemmeno se si confrontano i casi con K=0.01 e K=100. L’immagine è sempre sufficientemente chiara, anche nei dettagli. Ci sono comunque delle differenze, riscontrabili conoscendo il ruolo del fattore K. Esso è il numeratore dei coefficienti So e Sv,
sensori dei contorni lungo le direzioni orizzontale e verticale. Aumentando K, succede lo stesso per So e Sv ed il risultato sarà una perdita nella definizione dei
contorni, perché ci saranno sempre più valori delle matrici So e Sv che assumono il
valori alti, tipici del bianco. Vediamo nelle figure 18-21 cosa succede sulle le immagini dei dettagli mo2 al variare di K, per l’immagine sorgente swan.img:
Figura 18. Maschera orizzontale per swan.img Figura 19. Maschera orizzontale per swan.img filtrata con ret_soft e K=0.01 filtrata con ret_soft e K=0.03
Figura 20. Maschera orizzontale per swan.img Figura 21. Maschera orizzontale per swan.img filtrata con ret_soft e K=0.09 filtrata con ret_soft e K=0.1
Con k=0.01 (valore consigliato) i contorni degli oggetti nell’immagine sono ben definiti. Con k=0.03 si sono persi dei dettagli con k=0.1 abbiamo addirittura una schermata bianca, poiché i pixel sono quasi tutti a 255, dunque bianchi.
In teoria i contorni sono stati persi, ma le immagini di uscita sono in ogni modo soddisfacenti. C’è stata comunque una perdita di prestazioni: osservando nuovamente le figure 12 e 13 e seguendo il contorno del cigno, si può notare che se K assume un valore grande, i contorni sono più sfumati rispetto al caso con K=0.01. Lì l’effetto si nota maggiormente perché c’è la separazione tra il soggetto della foto ed il paesaggio. Sempre nel caso di swan.img, lungo il confine cigno – vegetazione se K è basso c’è un ottimo dettaglio e la vegetazione sembra toccare il cigno, com’è nella realtà, viceversa se K è alto si nota una striscia quasi nera che avvolge il cigno, la vegetazione sembra essere staccata dal soggetto. Questo è proprio dovuto alla perdita di sensibilità nei confronti dei margini.
Anche nelle altre immagini sorgente si verifica questo fenomeno, seppur in modo molto meno evidente.
2.3.2 Ruolo del parametro Alfa
Come fatto in precedenza per K, ora l’obiettivo è studiare il ruolo del coefficiente di ricorsione α nel nostro sistema, sempre allo scopo di semplificarne la programmabilità e l’implementazione.
In questa fase viene variato il valore di α, mentre per tutti gli altri parametri sono assunti i relativi valori consigliati, quindi si analizzano le conseguenze di questo procedimento sulle immagini di uscita finale ed intermedie del sistema, motivando le differenze che si verificano caso per caso.
La variazione del parametro α nell’algoritmo soft è poco evidente nelle immagini di uscita, almeno finché siamo lontani dal valore ottimo 0.75 e ciò è confermato anche da un’indagine sul valore che assumono i vari pixel. Le differenze aumentano anche, visivamente, quando ci si allontana a partire dal valore ottimo. In particolare, si nota che se aumentiamo α, l’immagine sembra essere più ricca di dettagli, le sfumature del corpo del cigno assumono toni più vivi (vedi figura 24 a pagina 45). Tale effetto di miglioramento del dettaglio cessa
di presentarsi se α si avvicina al valore massimo 1, valore “pericoloso” per come è definito l’algoritmo. Si nota che l’immagine di uscita diviene prima più luminosa (vedi figura 25 a pag. 46), perdendo molti dettagli, poi, quando α supera il limite massimo, diviene improvvisamente nera. Per capire perché tutto ciò avviene, è necessario osservare, al variare di α, l’uscita del filtro, ovvero il segnale luminanza. Come già spiegato, α rappresenta il peso dei pixel immediatamente vicini a quello attualmente processato, nel calcolo della stima di luminanza. In pratica, più α è grande, più aumenta l’effetto passa basso del filtraggio. Infatti, se i pixel vicini sono più importanti, il peso del pixel centrale, essendo moltiplicato per (1-α) andrà diminuendo e l’effetto visivo sarà quello di avere un’immagine un po’ più sfumata, dunque con minor dettaglio, perché le componenti ad alta frequenza sono reiettate dal filtro.
Il massimo dettaglio nelle immagini di luminanza si ottiene per α = 0, in quanto il filtraggio passa-basso non ha luogo e le componenti ad alta frequenza passano indisturbate. In pratica, al diminuire della banda del filtro ( e quindi all’aumentare di α) si ottiene una migliore stima della luminanza, perché si eliminano componenti ad alta frequenza che competono alla riflettanza. Il risultato concreto è quindi una migliore stima della luminanza quando α si avvicina ad 1, e conseguentemente, dato che la riflettanza è ricavata per mezzo di un rapporto con la luminanza al denominatore, se la stima della luminanza è migliore, ne gioverà anche quella della riflettanza. Aumentando sempre più α le immagini di luminanza sono sempre più sfumate. Quando α si avvicina ad 1 l’immagine di luminanza è uniformemente grigia. Si sono persi quasi tutti i dettagli. Se poi si supera il limite α = 1 l’immagine prima assume dei toni casuali, poi diviene improvvisamente nera, e ciò è dovuto al fatto che, per come l’algoritmo è stato ideato, il parametro di ricorsività non può superare il valore 1. Quest’ultimo fatto spiega anche perché il segnale di uscita sia completamente nero se α >1. In definitiva, è meglio non abbassare troppo il valore di α, pena una stima della luminanza a bassa qualità, con conseguente perdita di dettagli nell’immagine di uscita. Lo stesso valore consigliato, pari a 0.75, è vicino al valore massimo possibile per α, e questo giustifica i ragionamenti fin qui condotti. Per il nostro
sistema, possiamo scegliere di poter variare α tra 0.50 e 0.90 per rendere conto del trade-off necessario tra qualità delle immagini e complessità del filtro da realizzare, che aumenta se richiediamo un maggiore effetto passa basso, dato che la banda del filtro diviene più stretta.
Seguono, nelle figure 22-28 alcune immagini ottenute per diversi valori di α.
Figura 22. Immagine di uscita di swan.img Figura 23. Immagine di luminanza di swan.img elaborata con ret_soft e α = 0. elaborata con ret_soft e α = 0.
Figura 24. Swan.img: immagini di uscita, luminanza e riflettanza ottenute con l’algoritmo ret_soft per diversi valori di α.
Per bassi valori di α. si ottengono immagini con poco dettaglio, invece se α = 0.90 l’immagine di uscita presenta una maggiore qualità, in quanto sono
Vediamo cosa succede, in figura 25, impostando α pari al suo valore limite: 1.
Figura 25. Swan.img: immagini di uscita, luminanza e riflettanza ottenute con l’algoritmo ret_soft ponendo α = 1.0
Le immagini sono alterate a causa della perdita in prestazioni della stima di luminanza. Se α supera il limite consentito, il sistema restituisce delle immagini completamente nere, perchè fallisce nella stima della luminanza.
Vediamo anche i casi delle altre immagini sorgente:
Figura 26. Alpi.img: immagini di uscita ottenute da ret_soft nei casi α = 0.60 e α = 0.75.
Figura 27. Alpi.img: immagini di uscita ottenuta da ret_soft ponendo α = 0.90
Anche partendo da un’immagine ricca di toni bianchi, le migliori prestazioni si ottengono spingendo α vicino al suo limite massimo. Notare in particolare i dettagli sulla manica dell’alpinista in primo piano e la neve in primo piano in basso a destra, e poi la neve sullo sfondo.
Figura 28. Bedroom.img: immagini di uscita ottenute con l’algoritmo ret_soft nei casi α = 0.60, α = 0.75 e α = 0.90.
Con quest’ultima immagine è ancora più evidente il miglioramento del risultato che si può ottenere aumentando il valore di α: con α = 0.60 alcuni dettagli sarebbero addirittura invisibili, rispetto al caso con α ≥ 0.75. Notare i dettagli della coperta in primo piano, luce della abajour, il pavimento della stanza ed il paesaggio esterno in figura 28.
Attraverso i tre casi di immagini sorgente visti, possiamo concludere che si potrebbe utilizzare un valore di α grande nel caso si desiderino immagini molto dettagliate, mentre per ottenere l’immagini con dettagli minori, sono sufficienti valori di α più modesti. Non si verifica particolare dipendenza dei risultati dalle caratteristiche dell’ immagine acquisita, in altre parole l’algoritmo è ben robusto rispetto all’ingresso.
2.3.3 Ruolo del parametro Nc (Numero di Cicli)
L’algoritmo Retinex presenta problemi di rumore di fase, in seguito al filtraggio dei pixel effettuato con le maschere. Quello che si verifica infatti, in seguito ad un processo di mascheratura di un frame, è una leggera instabilità della fase delle immagini, vale a dire che l’immagine viene leggermente spostata in uno dei quattro versi possibili sulle direzioni orizzontale e verticale.
Ciò si può notare effettuando un’animazione delle immagini di luminanza ottenute con scelte diverse del numero di cicli. Questo problema può essere risolto mediando su quattro versi di scansione, ed effettuando quindi quattro iterazioni. Si ottiene un filtraggio del rumore di fase. Sono stati analizzati gli effetti collaterali dei cicli di iterazione del Filtro Ricorsivo Razionale (RRF), andando a studiare i risultati ottenuti, rispettivamente, con 1,2,3,4 iterazioni di filtraggio, impiegando le solite tre immagini sorgente, la prima con toni misti, la seconda con prevalenza di toni chiari, infine la terza con prevalenza di toni scuri.
Di seguito vengono presentate le immagini di uscita per bedroom.img nei casi di una e di quattro scansioni al fine di poter evidenziare meglio le eventuali differenze.
Figura 29. Bedroom.img: immagini di uscita, ottenute con l’algoritmo ret_soft nel caso di 1 scansione con filtro RRF e poi nel caso di 4 scansioni.
Diamo un’occhiata agli effetti della variazione del numero di cicli sull’uscita di luminanza, verificando che l’aumento delle scansioni rende più forte l’effetto passa-basso del filtro. La luminanza relativa alle 4 passate sarà più sfumata di quella relativa ad una sola scansione.
Figura 30. Swan.img, Alpi.img, Bedroom.img: immagini di luminanza, ottenute con l’algoritmo ret_soft nel caso di 1 scansione con filtro RRF e poi nel caso di 4 scansioni.
In ogni caso l’effetto visivo è un discreto aumento del dettaglio sull’immagine di uscita. Questo può essere giustificato avendo osservato cosa succede alle immagini di luminanza, dunque immediatamente all’uscita del filtro, all’aumentare dei cicli.
Al ciclo 1 l’immagine è ben definita, aumentando i cicli l’immagine diviene maggiormente sfumata e quindi viene enfatizzato l’effetto passa-basso rispetto a tutte le quattro direzioni possibili, in modo che non ne esista una privilegiata nel filtraggio dei pixel con la maschera, con conseguente miglioramento della stima della luminanza. Ci si riconduce quindi a ciò che avveniva all’aumentare di α, ovvero una migliore stima della luminanza ed una altrettanto migliore estrapolazione della riflettanza, con il risultato di un aumento del dettaglio nell’immagine finale.
Conviene sempre effettuare quattro iterazioni di filtraggio, in modo da eliminare il rumore di fase, ed aumentare il dettaglio dell’immagine di uscita.
2.3.4 Riepilogo dei test: definizione della programmabilità Variazione parametro k :
Immagini di soddisfacente qualità per ogni valore di k. Effetti collaterali:
• perdita del dettaglio lungo i contorni del soggetto all’aumentare di K. Questo è proprio dovuto alla perdita di sensibilità dei sensori di margine. • i dettagli della vegetazione sono più definiti con K basso, mentre se K è
alto si perdono dei dettagli.
• Le maschere mo e mv, perdono molti dettagli per K > 0.05
Le differenze più grandi si hanno al passaggio di K da 0.01 a 0.02, invece per step successivi, sempre di ampiezza 0.01, le differenze sono meno evidenti.
Dato che la variazione del parametro K non influisce molto sulle immagini di uscita, fissiamo il parametro K al suo valore ottimo 0.01. Abbiamo eliminato una variabile, e questa è la prima grande semplificazione per il nostro sistema.
Variazione parametro α:
α regola i dettagli sull’immagine di uscita. All’aumentare di α aumentano i dettagli, dunque potremmo utilizzare α come parametro regolatore della definizione delle immagini di uscita, ad esempio:
α = 0.90 se si richiedono dettagli molto spinti. α = 0.75 per dettagli medi.
α = 0.5 per una minore definizione.
Variazione parametro Nc (numero di cicli di iterazione):
La versione Soft dell’algoritmo Retinex risente molto poco delle caratteristiche dell’immagine sorgente, funziona bene in ogni caso. Conviene sempre effettuare quattro iterazioni di filtraggio, in modo da eliminare il rumore di fase, ed aumentare il dettaglio dell’immagine di uscita.
Nel caso in cui si voglia ridurre i tempi ed i costi di elaborazione, si può porre il parametro Nc al valore 2, ottenendo un filtraggio almeno parziale del rumore di fase. Per contro l’immagine di uscita perde in prestazioni perché è diminuito l’effetto passa-basso del filtro RRF.
2.4.
L
INEARIZZAZIONE DEGLI OPERATORI NON-
LINEARI 2.4.1 Calcolo dei coefficienti So ed SvCome sappiamo i coefficienti So e Sv, detti Sensori di margine orizzontale e
verticale, servono per determinare la presenza di bordi tra un oggetto ed un altro in una certa immagine che stiamo studiando.
Tali coefficienti assumono i valori massimi nelle aree uniformi, al limite si raggiunge il valore 1000 se k=0.01 e δ = 0.00001, mentre se i valori dei pixel sotto esame differiscono in modo sostanziale, i valori di So e Sv decrescono molto
rapidamente tendendo a 0. Ricordiamo le espressioni analitiche di So e Sv:
So = 2 10 ( 1, ) 1 log ( 1, ) 1 k x n m x n m δ ⎡ ⎛ − + ⎞⎤ + ⎢ ⎜ + + ⎟⎥ ⎝ ⎠ ⎣ ⎦ Sv = 2 10 ( , 1) 1 log ( , 1) 1 k x n m x n m δ ⎡ ⎛ − + ⎞⎤ + ⎢ ⎜ + + ⎟⎥ ⎝ ⎠ ⎣ ⎦
k è un parametro che ci consente di cambiare il valore massimo assunto da So ed
Sv, mentre δ è una costante che evita il caso di denominatore nullo, ed è stata
fissata al valore 0.00001
La notazione (x n−1, )m indica che stiamo considerando il pixel che si trova immediatamente a sinistra rispetto a quello al centro della maschera, lungo la direzione orizzontale.
La notazione ( ,x n m− indica invece il pixel che si trova al di sopra di quello 1) posto al centro della maschera, in direzione verticale.
Cerchiamo ora di rappresentare graficamente gli andamenti di So ed Sv al
variare dell’argomento, il rapporto ( 1, ) 1 ( 1, ) 1 x n m x n m
⎛ − + ⎞
⎜ + + ⎟
⎝ ⎠, che chiamiamo per
casi ambigui quali 0 0 o
0
∞ che manderebbero in crisi in sistema. Ecco spiegata la presenza della costante +1 nel numeratore e nel denominatore dell’argomento del logaritmo. Detto questo, X potrà assumere valori nell’intervallo [1/256 ; 256 ] (1/256 = 0.00390625) con passo di 1/256 poiché i pixel possono variare tra 0 e 255, dove 0 corrisponde al nero, mentre 255 è la codifica del bianco.
Dato che una rappresentazione in doppia scala lineare su tutto l’intervallo di variazione di X sarebbe difficilmente interpretabile a causa della diversità di passo tra scala verticale ed orizzontale, si preferisce una rappresentazione in doppia scala logaritmica, ed in aggiunta una rappresentazione in scala lineare ristretta all’intervallo X ∈[0.9 ; 1.1], riportate in figura 31.
Possiamo subito evidenziare un comportamento molto selettivo del sensore, che restituisce un valore pari a 1000 se X=1, dunque se i pixel adiacenti hanno lo stesso valore, mentre appena i pixel cominciano a differire, la funzione decade molto velocemente verso valori prossimi allo zero.
Figura 31. Grafico delle funzioni So ed Sv in doppia scala logaritmica e sua restrizione in scala
lineare per X compreso tra 0.9 e 1.1
So ed Sv assumono il loro valore massimo con andamento molto ripido. Se infatti
immaginiamo di approssimare l’andamento della funzione per X ∈[0.95 ; 1] con una retta, calcolando la derivata si troverebbe
(
)
(
)
1000 19.754 1 0.95 − − = 980.246 0.05 = 19604.92, una pendenza estremamente grande.Allontanandoci dal valore che rende nullo il log, la funzione tende molto velocemente a zero. La cosa veramente importante da rilevare è la simmetria rispetto all’ asse X=1. Questa proprietà della funzione può essere sfruttata nella linearizzazione di So ed Sv: si potrebbe interpolare una sola parte del grafico,
ricavando l’altra per simmetria, oppure, ancora più intelligentemente, si potrebbe fare in modo da ricadere sempre su un lato della funzione, ad esempio quello per cui X >1. Gli argomenti di So ed Sv sono due pixel di cui si vorrebbe calcolare il
rapporto ed altre operazioni successive: sarà sufficiente, prima del rapporto ordinare i pixel in modo da avere un risultato sempre maggiore o minore di 1. Supponendo di voler percorrere la prima alternativa, bisognerà leggere i valori dei due pixel, stabilire quale sia il maggiore, ed eventualmente riordinarli in modo da ottenere un rapporto maggiore di uno. Ci troveremo così sicuramente nella parte destra del grafico. Giustifichiamo ora in simboli i ragionamenti fatti per sfruttare la simmetria della funzione So – Sv:
1
1
(log logX log )X X
−
= = − e quindi ( log )2 (log )2
X X
− =
dove con 1
X indichiamo l’inversione dei pixel. Vediamo infine cosa succede al variare di K:
Figura 32. Andamento di So, Sv nel caso in cui K = 0.05
La soglia K modula il valore massimo della curva So – Sv, ad esempio ponendo
K= 0.05 il sensore raggiunge il valore 5000. Questo non cambia di molto i risultati nel calcolo della luminanza, dato che l’espressione analitica di y(i,j) prevede So ed
Sv sia al numeratore che al denominatore, ma comporta comunque la perdita di
inevitabilmente anche l’intervallo di X per cui il sensore assume valori molto più grandi di 1 verrà espanso. Per convincerci di ciò, possiamo notare come nel caso di k=0.05, già per X=0.98 il sensore valga 500, mentre se k=0.01 per avere So =500, bisogna prendere un valore di X situato tra 0.99 e 1. In pratica,
aumentando K, i sensori riducono la loro selettività.
2.4.2 Indagine Statistica delle immagini
L’obiettivo del procedimento che segue è capire quanti sono, statisticamente, i casi in cui si cade nell’intorno del massimo della funzione So, Sv di cui abbiamo
visto l’andamento. L’argomento fondamentale della funzione è il rapporto ( , 1) 1 ( , 1) 1 x n m x n m ⎛ − + ⎞ ⎜ + + ⎟ ⎝ ⎠ per Sv, e ( 1, ) 1 ( 1, ) 1 x n m x n m ⎛ − + ⎞ ⎜ + + ⎟ ⎝ ⎠ per So.
Ciò significa che, centrato un certo pixel, nel primo caso si dovrà calcolare il rapporto tra il valore del pixel immediatamente superiore a quello considerato, ed il valore del primo pixel che si trova immediatamente al di sotto.
Le notazioni di Matlab e dell’algoritmo scritto in codice C sono diverse.
Per Matlab, il primo indice è di riga, il secondo di colonna, si segue dunque la notazione matriciale classica. Nel codice C++ ret_soft, il primo indice è di colonna, il secondo di riga. Manteniamo al momento queste convenzioni.
Come già fatto in precedenza, chiamiamo X l’argomento del logaritmo, per semplicità di notazione.
Sfrutteremo la simmetria degli andamenti di So ed Sv, considerando solo la parte
per X > 1, a destra del massimo.
Per effettuare i test sono state preparate delle funzioni in ambiente Matlab i cui nomi sono Test1...5.m. A partire dalla matrice dell’immagine sorgente, vengono calcolate due nuove matrici, chiamate statv e stath contenenti i valori dell’argomento del logaritmo per So ed Sv. Queste matrici sono salvate e dunque
rese disponibili per un’eventuale ispezione. Statv e stath, sono costruite, rispettivamente, effettuando delle scansioni raster per colonna, e per riga dell’immagine sorgente. A tal proposito dobbiamo osservare che esse, immaginando di partire da immagini sottoforma di matrici di dimensione N x N,
avranno dimensione (N-2) x (N-2) e ciò può essere facilmente compreso se ricordiamo che nel calcolo dell’ argomento X, dato un pixel, si deve considerare il precedente ed il successivo lungo una direzione, orizzontale o verticale. Si deve però evitare di uscire dai confini della matrice nei due versi che giacciono su ogni direzione, dunque entrambe le dimensioni devono essere diminuite di due unità. La stessa affermazione si può giustificare ricorrendo al concetto di filtraggio delle immagini con maschere 3 x 3 ed immaginando quali siano i possibili spostamenti della maschera all’interno della matrice dell’immagine.
Illustriamo ora i test statistici effettuati:
nella prima prova, chiamata TEST1, l’intervallo [1 ; 256] è stato suddiviso in 8 sotto intervalli della stessa ampiezza, per vedere come si distribuiscono i valori delle matrici stath e statv. Successivamente range di valori di X sempre più ristretti sono stati suddivisi in ulteriori 8 sotto intervalli equispaziati. Si arriva così fino al Test5 in cui è l’intervallo [1 ; 1.1 ] ad essere sezionato. L’ultima prova, Test6, è stata dedicata al calcolo statistico dei valori di picco, quelli per cui X = 1.
Test1
L’intervallo [1 ; 256] di ampiezza 255, viene suddiviso in 8 intervalli equispaziati di ampiezza 255/8 = 31.875 delimitati dai valori: 1 ; 32.875 ; 64.75 ; 96.925 ; 128.5 ; 160.375 ; 192.25 ; 224.125 ; 256
Nei diagrammi che seguono, figure 33 e 34, nell’asse delle ascisse sono riportati gli intervalli di quantizzazione del relativo test. In ordinata è riportata la percentuale dei valori che appartengono a ciascun intervallo.
Figura 33. Istogramma di scansione verticale Figura 34. Istogramma di scansione orizzontale ottenuto da swan.img nel Test1. ottenuto da swan.img nel Test1.
I diagrammi di scansione verticale ed orizzontale hanno fornito, in ogni caso, distribuzioni statistiche analoghe, pertanto da qui in avanti si eviterà di fare distinzione.
Stesso discorso per gli istogrammi ottenuti da immagini diverse. I risultati del test evidenziano che, in ogni caso, quasi tutti i valori cadono nel primo intervallo. E’ necessario partire da un intervallo più ristretto dei valori di X.
Test2
Dato che quasi tutti i pixel cadono nel primo intervallo, procedendo per bisezione, come seconda iterazione del test, suddividiamo il primo intervallo, da 1 a 31.875 , in ulteriori 8 intervalli equispaziati di ampiezza 30.875/8 = 3.859 e delimitati dai valori 1 ; 4.859 ; 8.718 ; 12.577 ; 16.436 ; 20.295 ; 24.154 ; 28.013 ; 31.875 Come conseguenza di questa scelta, i valori delle matrici statv e stath maggiori di 31.875 saranno persi. Indichiamo dunque anche questo dato, destinato ad aumentare man mano che si procede per bisezione.
Dobbiamo dunque modificare la condizione nelle righe if della funzione Matlab, che diventano:
if (stat(i,j) <( 1+ (3.859.*k))) || (stat(i,j) > (1+3.859.*(k+1))) dove con stat si intende sia statv che stath
Vediamo i risultati ottenuti nei consueti istogrammi:
Figura 35. Istogramma di scansione verticale
ottenuto da bedroom.img nel Test2. Valori di statv persi : 0 %
Anche in questo caso il primo intervallo, da 1 a 4.859, comprende la quasi totalità dei valori. Il numeri valori di X persi è trascurabile, dunque non sussiste alcun problema in quel senso. Suddividiamo ulteriormente il primo intervallo in altri 8 valori nel Test3.
Test3
L’intervallo da 1 a 4.859 di ampiezza 3.859 è suddiviso in 8 intervalli da 3.859/8 = 0.482, ed i valori di frontiera degli intervalli sono: 1 ; 1.482 ; 1.964 ; 2.446 ; 2.928 ; 3.410 ; 3.892 ; 4.374 ; 4.859
Le righe if vengono aggiornate:
if (stath(i,j) <( 1+ (0.482*k))) || (stath(i,j) > (1+0.482.*(k+1)))
Figura 36. Istogramma di scansione verticale
ottenuto da swan.img nel Test3. Valori di statv persi: 0.84 %
Gran parte dei valori cadono nei primi 4 intervalli, dunque tra 1 e 3. Nel test successivo assumeremo questi limiti per l’intervallo da analizzare.
Test4
Suddividiamo dunque l’intervallo [1 ; 3] in 8 intervalli di ampiezza 2 / 8 = 0.25, delimitati dai valori: 1 ; 1.25 ; 1.50 ; 1.75 ; 2.00 ; 2.25 ; 2.50 ; 2.75 ; 3
Al solito, aggiorniamo le righe if della funzione Matlab: if (stath(i,j) <( 1+ (0.25.*k))) || (stath(i,j) > (1+0.25.*(k+1)))
Figura 37. Istogramma di scansione verticale
ottenuto da swan.img nel Test4. Valori di statv persi: 7.49 %
Il primo sotto intervallo è ancora troppo popolato rispetto agli altri per trarre delle conclusioni, anche se le distribuzioni cominciano ad essere uniformi.
Procediamo comunque con il Test5. Test5
Proviamo a sezionare l’intervallo [1 ; 1.1 ], che si trova attorno al picco della funzione So, Sv.
Suddividiamo dunque questo intervallo in 8 intervalli da 0.1/8 = 0.0125
I valori di frontiera degli intervalli sono: 1 ; 1.0125 ; 1.0250 ; 1.0375 ; 1.05 ; 1.0625 ; 1.075 ; 1.0875 ; 1.1
Aggiornata come fatto in precedenza la funzione Matlab, ed eseguita, i risultati sono i seguenti:
Figura 38. Istogramma di scansione orizzontale ottenuto da alpi.img nel Test5. Valori di statv persi: 25.49 %
Con quest’ultima iterazione del test abbiamo ottenuto risultati importanti: le percentuali di popolazione dei vari sotto intervalli sono finalmente confrontabili. Concludiamo che in 2 casi su 3 il sotto intervallo [1.00 ; 1.01] è molto più popolato dei successivi. Gli altri sotto intervalli presentano percentuali minori e molto simili tra di loro. Purtroppo il quantitativo dei valori persi è rilevante: oscilla tra il 23 % ed il 65 % circa. Questi valori sono però molto vicini allo zero, quindi si può pensare di trascurarli. Successivamente verificheremo la validità di questa ipotesi.
Test6
Come ultimo test verifichiamo quale sia la percentuale dei valori esattamente pari ad 1 nelle matrici statv e stath, per trovare quante volte i parametri So ed Sv
assumono i loro valori di picco.
Immagine sorgente statv stath
Swan.img 7.11 % 7.82 %
Bedroom.img 32.01 % 34.69 %
Alpi.img 4.81 % 5.39 %
Tabella 2. Percentuali di valori di picco riscontrati nella scansione verticale ed orizzontale, per le tre immagini.
Dalla tabella si evince che nel caso di immagini scure come bedroom.img, i valori pari ad 1 sono considerevoli. In una ipotetica look-up table sarà conveniente riservare una locazione per il valore di picco di So ed Sv.
In definitiva, la maggior parte dei valori di X cade nell’intervallo [1 ; 1.1], salvo qualche caso particolare. Sempre pensando di costruire una look-up table per approssimare l’andamento di So, Sv, partiremo dalle statistiche ricavate dai
Test 4 e 5, accettando di perdere alcuni valori di X. Tuttavia quest’ultimo aspetto potrebbe essere un vantaggio per diminuire la complessità circuitale del sistema e per risparmiare in termini di tempo di computazione.
2.4.3 Linearizzazione delle funzioni So e Sv
Dopo aver effettuato lo studio statistico sulle immagini sorgente, cerchiamo un’approssimazione per le funzioni So ed Sv, in modo da poter realizzare
un’architettura hardware semplificata. Lo scopo principale è ora quello di sostituire i logaritmi con andamenti più regolari.
La prima idea è quella di effettuare una linearizzazione a tratti della funzione da approssimare. Successivamente sarà implementata invece una look-up-table. In seguito a considerazioni su prestazioni e risorse richieste sul chip sarà scelta la migliore tra le due alternative. In ogni caso i risultati degli studi statistici ci saranno di aiuto.
Consideriamo i risultati del test statistico Test4, per le tre immagini sorgente. Abbiamo già osservato che scansioni orizzontali e verticali forniscono distribuzioni analoghe.
L’ intervallo partizionato è [1 ; 3] ; in questa restrizione della funzione cadono rispettivamente, per le tre immagini di prova, il 92.51 %, l’ 82.79 %, il 94.65 % di tutti i valori delle matrici stath. Questi dati sembrano autorizzarci a scegliere proprio questo intervallo per la quantizzazione, e di supporre So, Sv nulli quando
X assume valori esterni ad [1 ; 3]. Gli 8 sotto intervalli hanno ampiezza (2 / 8) = 0.25, delimitati dai valori: 1 ; 1.25 ; 1.50 ; 1.75 ; 2.00 ; 2.25 ; 2.50 ; 2.75 ; 3.
Come si evince dai diagrammi a barre (figura 37), gran parte dei valori di X cadono nel primo sotto intervallo, ovvero per X ∈[1.00 ; 1.25], poi le percentuali decadono molto rapidamente. Allora dovremo effettuare un’interpolazione molto spinta quando X ∈[1.00 ; 1.25] mentre sarà sufficiente un’approssimazione meno fine per X > 1.25.
Prima di tutto, cerchiamo di scoprire come il taglio di alcuni valori di X possa influire sulle immagini di uscita, per verificare l’ipotesi fatta precedentemente sulla base dei risultati del test statistico Test4. Consideriamo per ora soltanto i valori del primo sotto intervallo di Test1, eliminiamo dunque i casi X > = 32, in cui So, Sv vengono posti a 0. Il calcolo dei valori dei coefficienti So ed Sv è
effettuato con il metodo ottimo, quello proposto dal programma ret_soft.exe. Prendiamo l’algoritmo Retinex originale e creiamone alcune versioni alternative
che scartino i valori di X maggiori di 32, 128 e 180. Presa un’immagine, la elaboriamo con l’algoritmo originale ottenendo l’immagine di riferimento per il calcolo del PSNR e la elaboriamo anche con gli algoritmi modificati ottenendo nuove immagini. A questo punto è possibile verificare gli effetti del taglio su X. Riportiamo i risultati delle prove nella tabella 3.
Range di X Swan.img (dB) Bedroom.img (dB) Alpi.img (dB)
[1.00 ; 32.00] ∞ 102.34 29.29
[1.00 ; 128.00] ∞ 102.34 29.29
[1.00 ; 180.00] ∞ 102.34 69.94
Tabella 3. Qualità delle immagini ottenute al variare del range considerato per X.
Dalla tabella si evince che alpi.img risente moltissimo del taglio dei valori di X > 32, mentre le altre due immagini sono in pratica identiche a quelle ottenute con l’algoritmo originale, questo perché, come visto nel Test1, swan.img e bedroom.img non hanno valori di X>32 mentre in alpi.img esistono valori di X anche molto alti, a causa della presenza nella foto, di aree chiare a contrasto
con aree scure.
Le prestazioni non migliorano finché non raggiungiamo il range [1.00 ; 180.00] ; in tal caso il taglio di alcuni valori di X non comporta particolari
perdite in qualità dell’immagine di uscita.
Dunque per trattare qualsiasi tipo di immagine, è necessario comprendere valori di X almeno fino a 180.
Chiarito questo problema, cerchiamo di capire quanto l’interpolazione lineare deve essere fine per ottenere certe prestazioni. Focalizziamo l’attenzione sui valori di So, Sv più critici, quelli vicini al massimo delle funzioni. Ricordiamo quindi i
risultati del test statistico Test5 (figura 38), in cui è l’intervallo [1.00 ; 1.10] ad essere ulteriormente spezzettato.
Questa volta i valori di frontiera degli intervalli sono:
1 ; 1.0125 ; 1.0250 ; 1.0375 ; 1.05 ; 1.0625 ; 1.075 ; 1.0875 ; 1.1
Proviamo ora a fare una prima modifica all’algoritmo ret_soft.exe, approssimando le suddette funzioni con il metodo dell’interpolazione lineare. Consideriamo quindi delle spezzate a pendenza diversa su vari intervalli.
Sono state realizzate diverse approssimazioni, al variare del numero delle spezzate approssimanti, nel range di X definito prima. I risultati sono riassunti nella tabella 4.
Algoritmo
approssimato Swan.img (dB) Bedroom.img (dB) Alpi.img (dB)
Ret_soft_6 37.49 44.73 31.83
Ret_soft_7 37.47 44.75 43.37
Ret_soft_11 38.71 45.11 45.67
Tabella 4. Prestazioni raggiunte con varie soluzioni di interpolazione lineare.
I risultati forniti da Ret_soft_7 sono accettabili, il guadagno offerto dall’approccio ad 11 spezzate è di poco superiore, e non vale la pena di implementarlo. dunque consideriamo questa come soluzione accettabile al momento. Saranno possibili poi opportune ottimizzazioni.
Cerchiamo adesso di approssimare So ed Sv per mezzo di una Look-up-table.
2.4.4 Approssimazione di So e Sv con look-up table
Un altro possibile approccio molto diffuso per approssimare una funzione è quello della look-up table. La funzione da approssimare viene quantizzata, dunque divisa in sotto intervalli nei quali il valore assunto è costante. Questi valori vengono poi memorizzati in una Rom (Read Only Memory) e potranno essere letti indirizzando opportunamente la memoria. Chiaramente la scelta dell’indirizzo da leggere, ed in definitiva del valore approssimante la funzione, sarà legata all’argomento che deve essere elaborato.
Questa possibilità si propone come possibile alternativa a quella già realizzata per mezzo dell’interpolazione lineare. Dunque cercheremo di raggiungere prestazioni almeno pari a quelle ottenute dall’approssimazione a spezzate, e sceglieremo infine la soluzione migliore in base a ragionamenti sul trade-off costo-prestazioni. A parità di prestazioni, l’approccio LUT è preferibile rispetto al caso dell’interpolazione lineare che richiede moltiplicatori e comparatori per effettuare i calcoli approssimati, e dunque un’architettura più complicata. Un altro
aspetto da sottolineare è la maggiore velocità del sistema a LUT, poiché in sostanza non si deve effettuare alcun calcolo, ma si devono soltanto prelevare valori da una memoria.
Sono state realizzate diverse Lut, posizionando le soglie in base a quanto ottenuto dai test statistici. Per ogni Lut implementata, è stata creata una nuova versione dell’algoritmo Retinex, con nomi del tipo ret_soft_lut_numero_soglie. Ad esempio:
Ret_soft_lut_9
X= 1 y=1000 X ∈[ 1.00 ; 1.01] ⇒ 1000 348.75 674.375 2 y= + = X ∈] 1.01 ; 1.05] ⇒ 348.75 217.9 283.325 2 y= + = X ∈] 1.05 ; 1.20] ⇒ 217.9 1.59 109.745 2 y= + = X ∈] 1.20 ; 1.75] ⇒ 1.59 0.17 0.88 2 y= + = X ∈] 1.75 ; 3.00] ⇒ 0.17 0.04 0.105 2 y= + = X ∈] 3.00 ; 60.00] ⇒ 0.0439 0.0032 0.02355 2 y= + = X ∈] 60.00 ; 120.00] ⇒ 0.0032 0.0023 0.00275 2 y= + = X ∈]120.00 ; 180.00] ⇒ 0.0023 0.0020 0.00215 2 y= + =In tabella 5 riportiamo risultati in termini di PSNR, confrontati con il caso dell’interpolazione lineare :
Algoritmo approssimato
Swan.img (dB) Bedroom.img (dB) Alpi.img (dB)
Ret_soft_7 37.47 44.75 43.37
Ret_soft_lut_9 31.17 27.88 26.93
Differenza di
prestazioni: - 6.30 - 16.87 - 16.44 Tabella 5. Confronto in termini di prestazioni tra interpolazione lineare e quantizzazione di So ed
Siamo molto lontani dalle prestazioni ottenute con l’interpolazione lineare, dunque è necessario aumentare gli intervalli di quantizzazione, e quindi la dimensione della Rom. Gli intervalli dovranno essere molto fitti vicino al valore di picco della funzione, perché lì la derivata è molto grande e, statisticamente, in molti casi l’argomento del logaritmo cade in questa zona del grafico. Allontanandoci dal valore X = 1, la quantizzazione diverrà sempre più rilassata, sia perché la derivata della funzione decresce notevolmente, sia perché la concentrazione di valori di X statisticamente decresce.
Vengono dunque proposte due versioni della look up table, chiamate lut_low e lut_high, la prima a 25 livelli di quantizzazione, che è in grado di ottenere delle prestazioni molto vicine al caso dell’ interpolazione lineare e la seconda, ottimizzata a 32 livelli di quantizzazione, considerando il fatto che di solito le ROM hanno un numero di locazioni pari ad una potenza del 2. Queste sono le prestazioni raggiunte applicando le lut al posto del calcolo esatto: il confronto è effettuato anche rispetto a Retsoft7, sempre in termini di Rapporto Segnale Rumore di Picco.
Algoritmo
approssimato Swan.img (dB) Bedroom.img (dB) Alpi.img (dB)
Ret_soft_7 37.47 44.75 43.37
Retsoft_lut_low 38.01 47.93 46.22
Differenza di
prestazioni: + 0.54 + 3.18 + 2.85 Tabella 6. Confronto tra l’algoritmo di interpolazione lineare e Lut Low.
Algoritmo
approssimato Swan.img (dB) Bedroom.img (dB) Alpi.img (dB)
Ret_soft_7 37.47 44.75 43.37
Retsoft_lut_high 38.84 51.42 46.56
Differenza di
prestazioni: + 1.37 + 6.67 + 3.19 Tabella 7. Confronto tra l’algoritmo di interpolazione lineare e Lut High.
Il posizionamento delle soglie ed i valori approssimanti sono riassunti nelle tabelle seguenti.
Lut Low Lut High
Tabelle 8-9. Soglie e valori della Lut Low a 25 livelli e della Lut High a 32 livelli.
A conferma dei dati in tabella, si veda il grafico presente nella prossima pagina, in figura 39, in cui si mettono a confronto gli approcci a spezzata ed a lut per l’approssimazione dei coefficienti S.
Sono state rappresentate le prestazioni raggiunte, valutate in PSNR, in funzione del numero di costanti di approssimazione di cui è composta la Lut, e confrontate con la migliore approssimazione lineare realizzata.
X ∈ Valore LUT 1 1000 ] 1.0000 ; 1.0005] 998 ] 1.0005 ; 1.0010] 988.4 ] 1.0010 ; 1.0015] 971 ] 1.0015 ; 1.0030] 907.5 ] 1.0030 ; 1.0040] 812 ] 1.0040 ; 1.0060] 683 ] 1.0060 ; 1.0080] 526 ] 1.0080 ; 1.0100] 402 ] 1.0100 ; 1.0120] 310 ] 1.0120 ; 1.0140] 243 ] 1.0140 ; 1.0160] 195 ] 1.0160 ; 1.0180] 159 ] 1.0180 ; 1.0230] 118 ] 1.0230 ; 1.0360] 67 ] 1.0360 ; 1.0520] 30 ] 1.0520 ; 1.0750] 15 ] 1.0750 ; 1.1200] 7 ] 1.1200 ; 1.2000] 4.5 ] 1.2000 ; 1.5000] 0.95 ] 1.5000 ; 1.7500] 0.27 ] 1.7500 ; 3.0000] 0.105 ] 3.0000 ; 60.0000] 0.0214 ] 60.0000 120.0000] 0.00255 ]120.0000 ;180.0000] 0.00215 X ∈ Valore LUT 1 1000 ] 1.0000 ; 1.0005] 998 ] 1.0005 ; 1.0010] 988.4 ] 1.0010 ; 1.0015] 971 ] 1.0015 ; 1.0030] 907.5 ] 1.0030 ; 1.0040] 812 ] 1.0040 ; 1.0045] 746.75 ] 1.0045 ; 1.0050] 702.5 ] 1.0050 ; 1.0055] 659.3 ] 1.0055 ; 1.0060] 617.5 ] 1.0060 ; 1.0080] 526 ] 1.0080 ; 1.0100] 402 ] 1.0100 ; 1.0120] 310 ] 1.0120 ; 1.0140] 243 ] 1.0140 ; 1.0160] 195 ] 1.0160 ; 1.0180] 159 ] 1.0180 ; 1.0230] 118 ] 1.0230 ; 1.0290] 77 ] 1.0290 ; 1.0360] 50 ] 1.0360 ; 1.0520] 30 ] 1.0520 ; 1.0750] 15 ] 1.0750 ; 1.1200] 7 ] 1.1200 ; 1.2000] 4.5 ] 1.2000 ; 1.3000] 1.325 ] 1.3000 ; 1.4000] 0.620 ] 1.4000 ; 1.5000] 0.390 ] 1.5000 ; 1.6000] 0.280 ] 1.6000 ; 1.7500] 0.205 ] 1.7500 ; 3.0000] 0.105 ] 3.0000 ; 60.0000] 0.0214 ] 60.0000 120.0000] 0.00255 ]120.0000 ;180.0000] 0.00215
Come si vede, una lut a 24 locazioni consente di raggiungere la performance ottenuta con7 spezzate.
Confronto tra approccio lineare e a Lut per il calcolo di So e Sv
30 31 32 33 34 35 36 37 38 39 40 10 12 14 16 18 20 22 24 26 28 30
Dimensione Lut (Num. Locazioni)
PS
N
R
Interpolazione lineare a 7 spezzate
Approccio a Lut vs. numero di locazioni
Figura 39. Confronto di prestazioni tra approccio a spezzata e Lut per il calcolo dei coefficienti S.
Scegliamo di implementare le funzioni So e Sv attraverso la LUT a 32 livelli di
quantizzazione, in quanto, oltre ad ottenere dei benefici in termini di semplicità di architettura, le prestazioni sono superiori al caso di interpolazione lineare.
2.4.5 Calcolo dei coefficienti Fo ed Fv
Il calcolo dei coefficienti F, come si evince dalle loro espressioni analitiche, prevede solo operazioni di moltiplicazione e somma, pertanto non è necessario alcun procedimento di linearizzazione.
( 1, ) (1 ) ( , ) ( , 1) (1 ) ( , ) fo y i j y i j fv y i j y i j α α α α = − + − = − + −
2.4.6 Ottimizzazione del calcolo della luminanza
L’espressione di y(i,j) prevede il calcolo di un quoziente tra due termini abbastanza semplici, che prevedono operazioni come prodotti e somme.
Vogliamo però evitare di dover sintetizzare su FPGA un vero e proprio divisore poiché tale componente richiederebbe uno spreco di risorse logiche. Di solito si cerca di aggirare qualsiasi operazione di divisione o con uno shift di bit o con un approccio a Lut.
Supponiamo di voler seguire proprio questa strada. Se ricordiamo l’espressione (2.3) di y(i,j) e la riscriviamo nella nuova forma (2.5):
( , ) ( , ) 1 So fo Sv fv y i j y i j So Sv + + = + + 1 [ ( , )] 1 So fo Sv fv y i j So Sv = + + ⋅ + + (2.5)
adesso è possibile concepire y(i,j) non più come un quoziente, ma come un prodotto tra due fattori, di cui il secondo può essere calcolato con una Lut dedicata, mentre il primo lo realizziamo mediante blocchi come moltiplicatori e sommatori.
L’obiettivo di questo paragrafo è, quindi, l’implementazione di una memoria che contenga dei valori precalcolati per il termine (So + Sv + 1)-1.
Si tratta di realizzare una quantizzazione della nota funzione 1/M, dove M corrisponde ovviamente a (So + Sv + 1). Da simulazioni realizzate in ambiente C
si è visto che il passo di quantizzazione (QP) deve essere molto piccolo per ottenere risultati soddisfacenti. Si è scelta inizialmente una quantizzazione uniforme.
Per calcolare il PSNR in questo caso sono state messe a confronto le immagini elaborate da ret_soft e quelle che provengono da una nuova versione dell’algoritmo comprendente tutte le modifiche fin qui effettuate. Riportiamo i risultati ottenuti nella tabella 9a, nella prossima pagina, in termini di PSNR sulle singole immagini e come valore medio.
QP Prestazioni Medie (dB) Swan.img (dB) Bedroom.img (dB) Alpi.img (dB) 10 15.88 15.00 17.57 15.06 8 16.47 15.67 18.31 15.43 5 17.90 17.66 19.61 16.43 2 19.47 18.42 20.33 19.68 1 25.77 24.40 27.30 25.62 0.5 30.56 31.19 30.49 30.01 0.3 33.57 33.28 32.99 34.45 0.1 40.47 40.73 41.54 39.16
Tabella 9a. PSNR al variare della quantizzazione uniforme per il calcolo di (So + Sv +1)-1.
Si ottengono risultati interessanti se l’intervallo di quantizzazione è minore od uguale a 0.5, volendo un PSNR superiore mediamente a 30 dB.
Osservando i valori che So ed Sv possono assumere (tabella 9) e tenendo
presenti i risultati dei test statistici sulle immagini campione, possiamo affermare che una quantizzazione a passo molto ridotto costituirebbe uno spreco, dato che è necessaria solo per un range ristretto dei valori dei coefficienti S.
E’ possibile quindi operare una quantizzazione non uniforme, con QP più grande per valori alti di So ed Sv ed un passo di quantizzazione più piccolo
altrimenti. Ciò consentirà anche di risparmiare sulle dimensioni della Lut da implementare. Ad esempio se scegliamo QP costante e pari a 0.5 avremo bisogno di 2001 / 0.5 = 4002 costanti per approssimare 1/M, dove 2001 è il massimo valore assumibile da M.
I valori riportati in tabella 9 sono interi se maggiori di uno, altrimenti è presente una parte frazionaria. E’ allora lecito pensare di assumere un QP pari ad 1 per grandi valori della somma So + Sv e tornare a considerare le cifre dopo la
virgola al di sotto di un certo limite per la somma dei coefficienti S.
Sempre dai test statistici avevamo visto che le distribuzioni di So ed Sv sono
distinguere tra coefficiente orizzontale e verticale. Ragionevolmente, converrà assumere un QP unitario quando il termine 2 S +1 sarà maggiore di 10. A quel punto, calcolare l’inverso di 10 o di 10.1 non sarà molto diverso.
Definiamo quindi due zone a passo di quantizzazione diverso: d1 e d2. Sono state provate varie alternative, al variare di d1, d2 e dei relativi QP e sono stati valutati anche gli intervalli totali di approssimazione, che corrisponderanno alla dimensione in termini di locazioni di memoria, della Lut che si vuole realizzare. I risultati di tali prove sono riportati nella tabella 9b.
QP1 QP2 Numero intervalli Prestazioni Medie (dB) Swan.img (dB) Bedroom.img (dB) Alpi.img (dB) 0.1 0.5 4072 36.71 39.68 34.76 35.68 0.01 0.5 4882 37.42 39.22 35.64 37.39 0.1 1 2081 32.69 37.44 30.06 30.58 (a)0.1 1 2171 35.65 39.08 34.21 33.65 (b)0.1 1 2441 39.46 40.49 39.13 38.76 (c)0.1 1 2891 40.31 40.71 40.53 39.69 0.1 0.1 4002 40.47 40.73 41.54 39.16
Tabella 9b. PSNR ottenuti con varie alternativa di quantizzazione non uniforme. (a): d1 = 20; (b): d1 = 50; (c): d1 = 100.
La scelta definitiva è quella indicata con (b), poiché permette di ottenere prestazioni molto buone con una richiesta ragionevole in termini di dimensione della Look-Up-Table. Dunque d1 = 50 e QP1 = 0.1 ; d2 = 1951 e QP2 = 1.
Una volta letto il valore di (So + Sv + 1)-1, operazione che richiederà un solo ciclo
di clock dato che si deve leggere il dato in una memoria, sarà possibile calcolare il pixel di luminanza come un prodotto anziché come un quoziente.
Per problemi relativi al dimensionamento di questa Lut e per il resto del sistema, si rimanda al prossimo capitolo.