3
2D Preamble Searcher e
simulazioni numeriche
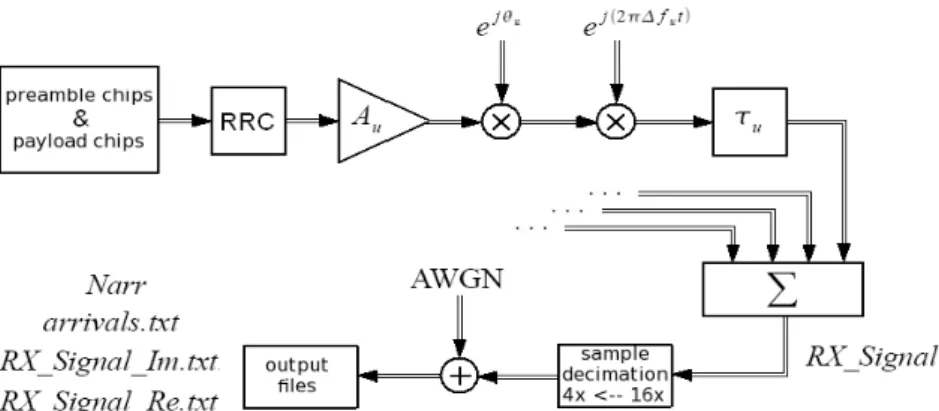
In questo Capitolo viene esposto il lavoro al calcolatore svolto nel laboratorio DSPCoLa utilizzando il linguaggio C/C++. Essenzialmente è suddiviso in due fasi. La prima fase riguarda la generazione dei segnali di test, che simulano il flusso di campioni provenienti dalla conversione A\D nel front-end di ricezione del Gateway E-SSA. La seconda fase riguarda lo sviluppo del 2D Preamble Searcher in cui vengono messi a punto i valori e i parametri ricavati sia analiticamente che sperimentalmente. La seconda fase si chiude con l'implementazione software dell'algoritmo NCPDI, utilizzato come confronto per le prestazioni. Generatore di segnale e rivelatore di preambolo sono due programmi indipendenti che condividono solo alcuni file di dati. In questo modo è possibile lanciare diversi rivelatori usando lo stesso segnale di test, o lo stesso rivelatore su di un set di segnali diversi.
3.1 Generatore di segnale
Il sorgente C/C++ del generatore è costituito da alcuni moduli, fra cui il file global.h che permette di impostare alcuni parametri come l'intensità degli arrivi, la presenza o meno dell'offset di frequenza e su quale range, e il roll-off dell'impulso. I
Ad ogni lancio dell'eseguibile viene simulato e salvato su file l'equivalente di poco più di un secondo di segnale (1.09052 s) E-SSA like. Deve essere precisato che il segnale creato non è una replica fedele del segnale previsto per E-SSA ma una versione leggermente semplificata, tuttavia è verosimile che le prestazioni ricavate non si discostino dallo scenario caratteristico E-SSA.
E' stato scelto di generare internamente un numero di campioni più elevato del necessario, in modo da simulare realisticamente la condizione di non perfetto allineamento temporale fra codice in arrivo e codice locale. Per l'esattezza vengono generati internamente 64 M campioni, mentre ne vengono effettivamente salvati in uscita solo 16 M. E' infatti previsto che il rivelatore di preambolo lavori ad una frequenza di 4/Tc, cioè 15.36 Msamples/s.
3.1.1 Generazione delle variabili aleatorie
Per la simulazione è fondamentale la creazione di variabili aleatorie aventi le distribuzioni desiderate e che appaiano il più possibile come valori casuali. Dal momento che tutte le densità di probabilità possono essere ottenute a partire da quella uniforme, l'unico punto critico riguarda la scelta di una buon generatore di numeri casuali distribuiti uniformemente tra 0 e 1 e del tutto incorrelati fra un lancio e i successivi.
Nella libreria standard stdlib.h è presente rand( ) che restituisce un intero casuale fra 0 e il valore prefissato RAND_MAX, quindi la generazione potrebbe basarsi su di essa convertendo i numeri da interi a reali sull'intervallo [0,1]. Tale funzione non è tuttavia ben implementata e presenta diversi lati negativi che riguardano il periodo di ripetizione e la correlazione della sequenza prodotta. Per la generazione è stata perciò utilizzata la funzione ran0( ) tratta da “Numerical Recipes in C” [16] , che prende in ingresso un puntatore a intero e restituisce numeri reali fra 0 ed 1 (0 escluso). La funzione si basa sul generatore Minimal Standard di Park e Miller e, pur trattandosi di poche righe di codice, è estremamente più affidabile della rand( ).
Per ogni valore estratto con ran0( ), viene calcolato il valore della variabile di interesse con le operazioni riassunte in Tab. 3.1, in cui la notazione usata è la stessa del Capitolo 1. In particolare, la variabile esponenziale viene generata col metodo della trasformazione inversa, mentre la variabile gaussiana con il metodo della composizione di due variabili uniformi.
Tab. 3.1 – Generazione delle variabili casuali di interesse, a partire dalla funzione ran0(). Variabile Funzione usata Operazioni principali
Δfu - ran0(jseed)*2*f_offset_MAX - f_offset_MAX
θu - ran0(jseed)*2*PI - PI
τu- τu-1 ddpexp(LAMBDA, jseed) -log(ran0(jseed))/LAMBDA
noise sample Gaussian(0,sigma2,jseed) un = ran0(jseed); ln = (un < 1) ? log(un) : 0.0; arg = 2.0*PI*ran0(jseed); return(cos(arg)*sqrt(sigma2)*sqrt(-2.0*ln));
Au2 Lognormal(0, 9, jseed) n1 = Gaussian(0, sigma2, jseed); return ( pow(10.0, n1/10.0) );
dm(u) ComputeRandomChip(jseed) 2* (unsigned int) (2*ran0(jseed))-1;
In molte prove la generazione della Au2 viene omessa perché fissata
semplicemente ad 1. Per la variabile τu deve invece essere fatta una precisazione: la
simulazione è a tempo discreto, mentre la variabile creata come da tabella è un valore continuo. Il valore effettivamente impiegato viene allora ottenuto con l'arrotondamento al campione più vicino:
poiss_rounded = (int) floor(poiss/SAMPLE_TIME + 0.5);
Qualora vi sia l'utilità di porsi in condizioni ideali di assenza di chip-level collision, è sufficiente sommare nella riga un valore costante, per esempio 32 (corrispondente a due intervalli di chip).
3.1.2 Schema a blocchi
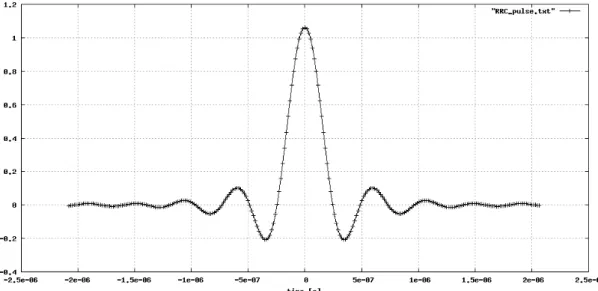
ciclo di generazione dei pacchetti. Viene innanzitutto creato l'impulso di trasmissione con roll-off α pari a 0.22 e troncato a 8 code, facendo uso delle funzioni ad-hoc RRC e BuildTrasmittingPulse (file RRC_pulse.txt in uscita). In particolare nella funzione RRC viene implementato, per comodità di visualizzazione su plot, un impulso
TcgTt che non ha più energia unitaria ma assume un'ampiezza all'incircaunitaria in t=0 (Fig. 3.1). Dato che l'espressione analitica dell'impulso assume forme indeterminate quando t→0 e t→Tc/4α, è opportuno isolare nel calcolo questi due
valori critici: gTt =4 1− se ∣t∣ (3.1) gTt =
cos
4 1−
− 2 cos
4 1
se∣
t− Tc 4 ∣
(3.2) dove ε è un valore di guardia impostato su 10-12.Successivamente viene letto il file preamble_chips.txt che contiene la sequenza complessa prevista in E-SSA per il preambolo, e tramite ciclo for viene costruito e salvato il segnale di preambolo associando un impulso di trasmissione a ciascun chip complesso (preamble_signal.txt). Infine viene inizializzato il seme (seed) che servirà a
generare tutte le variabili casuali necessarie: seed = (int) time(NULL); jseed = &seed;
Questo comando garantisce che il seme sia diverso ad ogni avvio del programma, poiché la funzione time(NULL) restituisce un valore che rappresenta l'orario attuale del sistema. Naturalmente è necessaria l'inclusione della libreria time.h nell'unità di compilazione.
La successiva fase di generazione, schematizzata a blocchi in Fig. 3.2, è costituita dalle seguenti operazioni eseguite ripetutamente tramite ciclo while:
• generazione di un nuovo intertempo τu- τu-1 di arrivo
• incremento del contatore degli arrivi Narr
• creazione di Npl chip di payload tramite doppia esecuzione di
Compute_random_chip, una per la parte reale del chip e una per quella immaginaria. Il numero impostato è Npl = 307200.
• generazione della forma d'onda dell'u-esimo pacchetto • estrazione dei valori casuali Au, θu, Δfu
• applicazione delle variabili al pacchetto creato e inserimento sul segnale complesso RX_Signal costruito finora
• aggiunta di una riga su arrivals.txt che riporta τu, Au, θu, Δfu
L'uscita dal ciclo avviene non appena un nuovo valore τu creato, sommato alla durata
di un pacchetto, supera la durata del segnale che si desidera generare. A quel punto viene salvato in uscita il numero Narr, e i file dati RX_Signal_Re.txt e
RX_Signal_Im.txt. Durante la scrittura avviene la decimazione dei campioni: dei 16 campioni per chip ne vengono salvati solo 4, per un totale di 16 M (16777216) valori complessi.
3.1.3 AWGN
Il blocco AWGN è un sottoprogramma che può essere fatto eseguire o meno, dal momento che le prestazioni di E-SSA sono limitate dal livello di MAI e non dal rumore termico. Il modulo consiste nella semplice aggiunta di rumore gaussiano a media nulla e varianza sigma2 sulle parti reali e immaginarie dei campioni del segnale, prima della scrittura dei file RX_Signal_Re.txt e RX_Signal_Im.txt.
Il parametro richiesto in ingresso è il valore SNR=Ec/N0 quando Au=1, dove Ec
è l'energia media ricevuta per chip a RF. Applicando l'impulso RRC del precedente paragrafo e ricordando che i chip di sequenza sono modellabili come IID, si ha:
Ec=1 2RC0= 1 22 Tc=TcN0= Tc SNR (3.3)
Essendo poi la simulazione a tempo discreto con quattro campioni per chip, deve essere impostato un valore di varianza N0' scalato dell'intervallo di campionamento:
N0'= N0 Tc 4 = 4 SNR (3.4)
che è proprio il valore sigma2 da inserire nella funzione Gaussian( ) della tabella 3.1.
3.1.4 Accorgimenti per la condizione di regime
La generazione interna dei campioni deve iniziare prima di t=0 e finire dopo t=1.09052 s. Se così non fosse otterremmo in uscita un segnale che presenta dei
transitori all'inizio e alla fine, perché in vicinanza dei due estremi il numero medio di pacchetti sovrapposti risulterebbe più basso, causando una variazione della MAI e quindi falsificando le probabilità PFA e PMD cercate. Chiaramente in E-SSA vi saranno
variazioni nell'intensità media degli arrivi e il rivelatore dovrà adattarsi automaticamente, tuttavia per fare un confronto con le curve teoriche ricavate nel Cap.2 è necessario riportarsi ad una situazione di regime.
L'intervallo di tempo minimo con cui è opportuno far partire in anticipo e terminare in ritardo la generazione è pari alla durata di un pacchetto. I segnali di test utilizzati sono stati generati con un intervallo di guardia pari a due pacchetti all'inizio e due alla fine. I file salvati in uscita e la lista degli arrivi contengono ovviamente solo la parte utile.
3.2 Implementazione del 2D Preamble Searcher
Questo paragrafo mostra in dettaglio l'implementazione software della ricerca bidimensionale di preambolo, introdotta alla fine del Capitolo 2. Il programma elabora campioni complessi con oversampling pari a 4, e viene proposto come alternativa alla tecnica NCPDI attualmente prevista in E-SSA.
Il codice sorgente è costituito da alcuni moduli oltre al main.cc. In particolare, utilities.cc contiene delle funzioni utili, molte delle quali scritte ad-hoc, mentre in global.h è possibile modificare i parametri di lavoro come lo spazio di offset di frequenza da ricercare, la soglia per il Threshold Crossing e la lunghezza delle FFT, che da ora in poi sarà sempre indicata con N. I numerosi calcoli sui numeri complessi sono anche qui facilitati dalla libreria complex.h.
L'esecuzione del programma consiste in tre fasi: preparazione, ricerca 2D, misura di PFA e PMD. Solo la fase centrale è quella che effettivamente interessa per un
possibile impiego real-time. La prima fase è infatti un'inizializzazione, mentre l'ultima è necessaria per valutare le prestazioni.
che ricoprono le trasformazioni di Fourier, il sottoparagrafo che segue mostra come sono state calcolate le FFT in modo efficiente.
3.2.1 FFTW3: una libreria per il calcolo efficiente delle FFT
FFTW è una libreria contenente veloci routine in C per il calcolo della trasformata discreta di Fourier (DFT) in una o più dimensioni, su array di dimensioni arbitrarie, composti sia da numeri reali che complessi. FFTW è un software libero sviluppato da Matteo Frigo e Steven Johnson del MIT, e il pacchetto sorgente è scaricabile da [17] con licenza GNU GPL. I benchmarks effettuati su molti tipi di piattaforme di calcolo hanno dimostrato la superiorità di FFTW rispetto ad altri pacchetti open-source disponibili oggi per il calcolo delle FFT, e hanno evidenziato la competitività nei confronti dei pacchetti proprietari (e molto costosi). La prima versione risale al 1999, e oggi è disponibile la 3.2.2. Informazioni dettagliate possono essere trovate in [18].
FFTW è ottimizzata per lavorare su tipi di dati double (8 byte) e float (4 byte). In questa tesi, FFTW è usata con numeri complessi le cui parti reale e immaginaria sono rappresentate inizialmente su double e successivamente viene valutato il passaggio a singola precisione. Per l'utilizzo è necessario includere <fftw3.h> e aggiungere il comando -lfftw3 durante la compilazione.
L'estrema velocità viene raggiunta attraverso un'accurata ottimizzazione degli algoritmi utilizzati e l'impiego di istruzioni specifiche per i vari tipi di processori. Per questo motivo è richiesta la dichiarazione e la costruzione di un plan:
fftw_plan p;
fftw_complex *in, *out;
in = (fftw_complex*) fftw_malloc(sizeof(fftw_complex)*N); out = (fftw_complex*) fftw_malloc(sizeof(fftw_complex)*N); p = fftw_plan_dft_1d(N, in, out, -1, FFTW_ESTIMATE);
ad-hoc con la funzione fftw_malloc. Il plan è una struttura dati che contiene le informazioni su come eseguire la FFT e richiede la lunghezza N della FFT, i puntatori in e out ad array di complessi, la direzione della trasformata (–1=FFT, +1=IFFT), e il metodo per la scelta degli algoritmi. In molti casi FFTW_ESTIMATE è sufficiente, ma se sono richieste numerose trasformate dello stesso tipo è preferibile utilizzare FFTW_MEASURE che costruisce il miglior plan possibile. Nel nostro caso questa seconda modalità rende molto più lunga l'inizializzazione, ma fa risparmiare un tempo notevole nell'esecuzione della rivelazione (arriva quasi a dimezzare il tempo richiesto per ciascuna trasformata), e quindi è stato scelto di usarla. L'esecuzione della trasformata viene lanciata con il comando:
fftw_execute(p);
il cui risultato è contenuto nell'array out. Se è necessario eseguire un'altra trasformata, è possibile riutilizzare lo stesso plan, ovviamente dopo aver riscritto l'array in con il nuovo vettore dati. Quando il plan e gli array non servono più, si può liberare memoria RAM con i comandi:
fftw_destroy_plan(p);
fftw_free(in); fftw_free(out);
E' utile infine evidenziare un paio di aspetti. Il primo è che FFTW calcola una DFT/IDFT non normalizzata:
DFT
{
x [n]}
=X [k ]=∑
n=0 N −1 x [n ]e−j 2 N n k , 0≤k ≤ N −1 (3.5) IDFT{
X [ k ]}=x [n]=∑
k=0 N −1 X [k ]ej 2 N n k , 0≤n≤N −1 (3.6)Il secondo aspetto, osservabile dalla prima formula, è che la frequenza nulla si trova in out[0] cioè non è al centro del vettore di output.
3.2.2 Preparazione alla rivelazione
• lettura di RX_Signal_Re.txt, RX_Signal_Im.txt e memorizzazione su array di complessi
• lettura di preamble_signal.txt e calcolo della trasformata complessa coniugata P*[k] attraverso FFT, dopo zero-padding del preambolo fino ad N
• calcolo del numero intero K e preparazione dell'eventuale finestra (si veda 3.2.6)
• lettura di arrivals.txt e preparazione della lista degli arrivi effettivamente rilevabili. Il loro numero viene memorizzato in arr_num. A seconda del numero N utilizzato, non sempre vengono elaborati tutti i 16 MSamples.
3.2.3 Rivelazione 2D: schema a blocchi
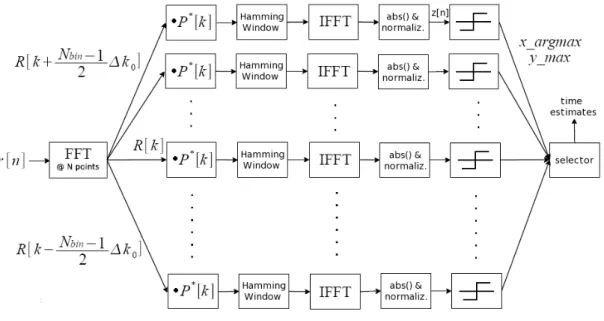
La Fig. 3.3 mostra sotto forma di blocchi le operazioni eseguite in fase di rivelazione. Viene qui descritto sommariamente l'algoritmo, mentre nei sottoparagrafi che seguono sono mostrate più in dettaglio alcune delle operazioni e delle scelte fatte.
Il segnale ricevuto viene suddiviso in blocchi di N campioni, e ciascun vettore
r[n] viene portato nel dominio delle frequenze ottenendo R[k]. La suddivisione non è netta ma richiede un overlap (si veda 3.2.4). Una batteria di Nbin moltiplicatori
provvede a moltiplicare la versione complessa coniugata della trasformata del preambolo P*[k] per una versione di R[k] a campioni permutati ciclicamente, in modo
da compensare un certo offset di frequenza diverso da ramo a ramo (si veda 3.2.5). Su ogni ramo viene applicata l'eventuale finestratura, e poi la IFFT. Dopo l'estrazione del modulo, su ciascun vettore z[n] di reali non negativi viene applicata la normalizzazione, e poi la soglia fissa. L'ultimo blocco provvede a filtrare e restituire la lista ordinata dei candidati arrivi.
Il codice è costituito da due grandi cicli for: quello esterno seleziona la parte di segnale ricevuto da elaborare, quello interno passa in rassegna gli Nbinrami che sono
stati fissati. Terminata l'elaborazione di un blocco r[n], si passa al successivo. La simulazione elabora l'equivalente di un secondo di segnale, ma è facilmente adattabile ad uno scenario real-time in cui i campioni non provengono da un file di dati ma dal convertitore ADC.
3.2.4 Dimensionamento FFT/IFFT e overlap
Nel Capitolo 2 (par.2.1.1) è stata mostrata la necessità di eseguire la correlazione fra l'inviluppo complesso del segnale ricevuto e l'intero preambolo, nel caso ideale di rivelatore a tempo continuo e assenza di offset di frequenza. Il 2DPS software lavora a tempo discreto, quindi è necessario eseguire la correlazione lineare a tempo discreto fra il blocco di segnale r[n] di N campioni, e il preambolo noto p[n]:
crp[m]=
∑
n=−∞∞
r [n] p*[n−m] . (3.7)
Tale correlazione avrebbe un'estensione di (N+4Npr –1) campioni, se con Npr si indica
il numero di chip che costituiscono il preambolo e se trascuriamo le code RRC. Gli aspetti da risolvere sono adesso due: fissare in modo opportuno la lunghezza N, e trovare un modo efficiente per calcolare la correlazione lineare, possibilmente
sfruttando la velocità della FFT.
La lunghezza N dovrà necessariamente soddisfare le seguenti due condizioni: N ≥4 Npr e N =2i . (3.8)
La prima assicura che si correli sull'intera lunghezza di preambolo, mentre la seconda ottimizza le FFT poiché rende la complessità di calcolo di ciascuna trasformata proporzionale a (N/2)log2N moltiplicazioni complesse.
Per quanto riguarda il secondo aspetto, non è possibile calcolare una correlazione lineare con una semplice moltiplicazione nel dominio trasformato DFT, al contrario di quanto avviene per i segnali a tempo continuo. Tale proprietà torna però a verificarsi quando si consideri la correlazione circolare, così definita:
crp[m]=
∑
n=0 N −1
r [n] p*[n−m] (3.9)
dove il vettore del preambolo è stato implicitamente riempito con degli zeri fino a N, e le sequenze sono state periodicizzate con periodo N. L'uscita è ancora una sequenza periodica e andando ad effettuare la DFT della crp[m] si ha:
DFT
{
crp[m]}
=∑
m=0 N −1{
∑
n=0 N −1 r [n] p*[n−m]}
e−j 2N mk=∑
n=0 N −1 r [n ]{
∑
m=0 N −1 p*[n−m]e−j 2N mk}
effettuando ora il cambio di variabile m'=m-n, sfruttando poi la ripetitività della sequenza p [−m' ] e infine applicando la proprietà:
DFT
{
p*[−m ' ]}
=P* [k ] (3.11) si trova che∑
n=0 N −1 r [n ]∑
m '=−n N −1−n p*[−m' ]e−j 2 N m ' nk=∑
n=0 N −1 r [n]e−j 2N nk⋅∑
m '=0 N −1 p*[−m' ]e−j 2 N m' k = = R[ k ]⋅P* [k ] (3.12)La correlazione circolare può essere allora calcolata moltiplicando uno spettro per il complesso coniugato dell'altro, e antitrasformando mediante IFFT.
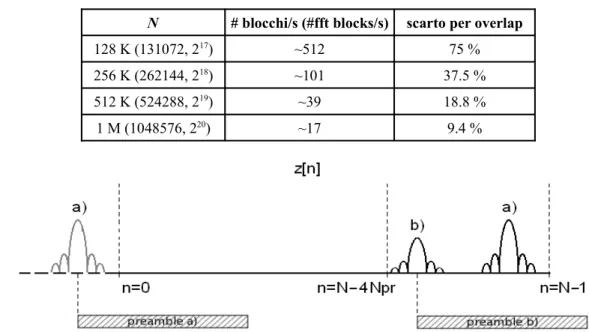
A questo punto è necessario introdurre un overlap, perché solo una porzione del vettore ricavato corrisponde alla correlazione lineare che intendevamo fare inizialmente. Tale porzione è esattamente pari ai primi (N– 4Npr+1) campioni, mentre
gli ultimi (4Npr –1) devono essere scartati. Il blocco r[n] che sarà elaborato
successivamente partirà dalla parte scartata, in modo da assicurare una osservazione continua del segnale. Si noti che se non venisse applicato alcun overlap, avremmo due effetti dannosi causati dalla correlazione ciclica:
• Un preambolo che fosse iniziato poco prima del primo elemento r[0], verrebbe correlato parzialmente (solo la sua parte finale) con la grave conseguenza della comparsa di un certo picco di correlazione “fantasma” da qualche parte dopo la posizione (N– 4Npr);
• Un preambolo che cominciasse poco dopo la posizione (N–4Npr), non verrebbe
correlato completamente poiché dovrebbe idealmente terminare all'inizio di r[n], cosa che non è possibile e dunque darebbe un picco di correlazione più basso.
In Fig. 3.4 sono mostrati questi due effetti, da cui la necessità dell'overlap. In Tab. 2.2 sono invece elencati alcuni possibili valori di N che soddisfano le condizioni 3.8, il numero di blocchi in cui va suddiviso il segnale corrispondente a circa 1 s, e la percentuale di scarto di ciascun blocco elaborato dovuta all'overlap.
Tab. 2.2 – Scelta della lunghezza N delle FFT.
N # blocchi/s (#fft blocks/s) scarto per overlap
128 K (131072, 217) ~512 75 %
256 K (262144, 218) ~101 37.5 %
512 K (524288, 219) ~39 18.8 %
1 M (1048576, 220) ~17 9.4 %
Fig. 3.4 - Effetti della correlazione circolare. Il preambolo a) è in anticipo,
La scelta di un particolare N incide sul numero di FFT da effettuare al secondo, e quindi sul costo computazionale. Una lunghezza di 128 K è chiaramente svantaggiosa, mentre sono più opportune lunghezze come 256 K e 512 K. Va evidenziato che sebbene in hardware le FFT solitamente non vadano oltre gli 8 K, in software questo parametro è invece molto più flessibile. Nel Capitolo 4 viene valutato il costo dell'algoritmo dal punto di vista delle FFT.
La tecnica che è stata implementata è nota anche, nel campo del filtraggio FIR software attraverso FFT corte, col nome di overlap-save method.
3.2.5 Bin Doppler
Come visto nel Capitolo 2 (par. 2.1.2) la presenza di un offset di frequenza nei pacchetti in arrivo comporta un abbassamento del picco. L'alternativa alla NCPDI è quella di tentare di compensare a monte l'offset in modo che lo scarto di frequenza netto residuo sia abbastanza inferiore al valore critico di 156.2 Hz.
Lo scopo di far passare il vettore R[k] attraverso Nbin rami in parallelo è
proprio quello di annullare un certo offset, diverso da ramo a ramo. Una volta che r[n] è stato portato in frequenza, possiamo ottenere molto facilmente l'obiettivo. Applichiamo per esempio una traslazione di k0 campioni e manteniamo la periodicità:
RP[k ] = R[k −k0] , RP[k ]=RP[k N ] . (3.13)
Si tratta cioè di effettuare una permutazione ciclica sul vettore R[k] : se k0>0 i valori
in {0, 1, ..., N–k0–1} vengono rispettivamente spostati nelle posizioni {k0, k0+1, ...,
N–1}, mentre i valori in {N–k0, N–k0+1, ..., N–1} vengono spostati nelle posizioni {0,
1, ..., k0–1}. Calcolando la IDFT che ne risulta:
rP[n]=
∑
k =0 N −1 R [k −k0]ej 2 N n k = k '=k −k0 k '=−k∑
0 N −1− k0 R[ k ' ]ej 2 N k ' k0 =ej 2 N n k0 r [n] (3.14) si trova che permutare lo spettro R[k] di k0 posti corrisponde nel tempo al segnale r[n]moltiplicato per l'oscillazione complessa di frequenza normalizzata k0/N.
Msamples/s, la frequenza non normalizzata è
fk0=fsk0
N . (3.15)
Se k0<0 la conclusione è la stessa, cambia solo il modo in cui vanno spostati i
campioni.
Nel 2DPS il vettore R[k] viene traslato con Nbin diversi valori di k0, e inviato ai
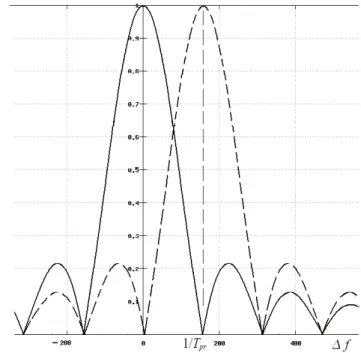
rami. Su un certo ramo viene annullato l'offset di quei pacchetti che presentavano shift di Δf=–fk0 permettendone così la rivelazione. Pacchetti che presentavano shift vicini a quello sono rilevabili grazie al lieve abbassamento del picco di correlazione che, a differenza di quanto visto in 2.1.2, adesso segue l'andamento:
A EPsinc fTPR , f= f f k0 . (3.16)
Adesso si tratta di fissare i valori Nbin e k0 da impiegare. Più il numero di bin è
elevato e più gli offset sono compensati in modo fine e maggiore è la richiesta di risorse di calcolo. Ovviamente il caso limite Nbin=1 e k0 nullo corrisponde al semplice
correlatore completo già trattato in 2.1.2. Un compromesso per fissare il numero di bin è quello di far sì che in corrispondenza del nullo di correlazione di uno di essi sul bin
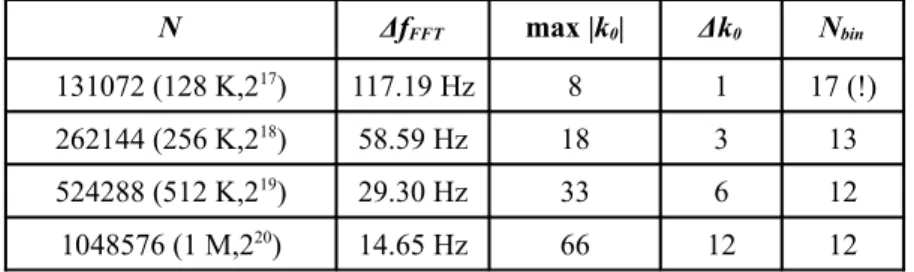
adiacente compaia il picco massimo (Fig. 3.5), ottenendo così 13 bin. Lavorando con le FFT, tuttavia, l'asse delle frequenze è a valori discreti e il numero di scelte che possiamo fare è limitato. La minima frequenza fk0 si ha quando k0=1, e dato che essa
corrisponde anche alla risoluzione in frequenza della FFT, viene indicata con ΔfFFT. In
Tab. 2.3 sono mostrati i valori al variare di N del minimo offset compensabile, dello spostamento massimo |k0| per coprire in modo simmetrico l'intervallo di interesse fra
-1 KHz e +-1 KHz, e del Δk0 fra i rami da impostare per avere 12 o 13 bin.
Tab. 2.3 – Relazione fra la lunghezza N e la scelta dei bin.
N ΔfFFT max |k0| Δk0 Nbin
131072 (128 K,217) 117.19 Hz 8 1 17 (!)
262144 (256 K,218) 58.59 Hz 18 3 13
524288 (512 K,219) 29.30 Hz 33 6 12
1048576 (1 M,220) 14.65 Hz 66 12 12
Si può notare che la lunghezza 128 K non consente una sufficiente risoluzione in frequenza, ed ancora una volta appare svantaggioso applicarla. Nelle Figg. 3.6, 3.7 e 3.8 che seguono sono mostrati i casi rispettivamente di 12, 23 e 67 bin, ottenuti componendo le uscite dei rami, nell'intorno di un picco di correlazione.
La prima funzione scritta per il 2DPS è stata:
void offset_comp(double complex *R_fft,int delta_k);
che per ogni chiamata esegue la permutazione ciclica in avanti di Δk0 posti sul vettore
R[k]. La rivelazione parte infatti dal più grande k0 negativo, ovvero inizia col cercare i
Fig. 3.7 - Composizione delle uscite, con Nbin=23.
pacchetti giunti con gli offset positivi più elevati.
3.2.6 Finestratura
Nonostante la sequenza di preambolo prevista per E-SSA abbia una autocorrelazione molto buona questo non è più rigorosamente vero quando si osserva la autocorrelazione del corrispondente segnale costruito con gli impulsi RRC (Fig. 2.6). Sono presenti infatti alcuni lobi laterali, dei quali il primo è il più dannoso. Fintantoché è valida l'ipotesi di perfect power control tale lobo non dà problemi perché è semplice fissare una soglia che rimane al di sopra di esso, su ciascun ramo del 2DPS. Nel caso più realistico di dispersione in potenza dei pacchetti, un picco con ampiezza elevata fa invece superare la soglia per due o tre volte, causando false acquisizioni, per via di tali lobi laterali. La stima dell'arrivo differisce infatti per più di un chip dal vero τu, con il risultato che aumenta la PFA. Alzando la soglia si ha invece
un effetto opposto, ovvero i pacchetti con potenza bassa vengono perduti e aumenta la PMD.
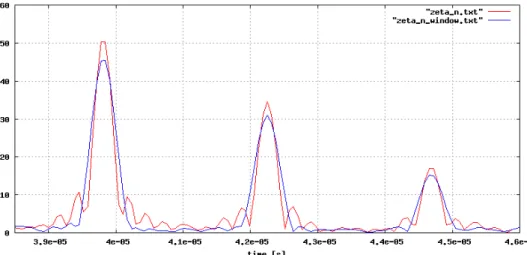
La situazione ideale sarebbe quella di osservare un singolo lobo per ciascun arrivo. E' possibile avvicinarsi a ciò inserendo una finestratura prima di ciascuna IFFT. Se solitamente la finestratura viene eseguita su di un segnale nel tempo e serve a rendere più leggibile il suo spettro, l'utilizzo che ne viene fatto qui è esattamente l'opposto, essa cioè migliora la forma del picco nel dominio del tempo. Dai test effettuati con vari tipi di finestre, quella più adatta è risultata essere la Hamming [19].
Il primo passo è fissare il numero intero K di campioni da finestrare: K = (int) ceil((1+ROLLOFF)*FFT_Lenght/(OVERSAMPLING*2));
K è il numero di campioni della FFT corrispondenti all'estensione della banda teorica del segnale portato in banda base, ovvero è l'arrotondamento a intero di:
K ≃1 2 TC
1
fFFT (3.17)
FFTW3 la frequenza nulla non è al centro ma all'estrema sinistra dell'array: for (index=0; index<2*K; index++) {
Window[index] = 0.54 + 0.46*cos(2*PI*index/(2*K -1)); }
Prima di ciascuna IFFT, i primi K e gli ultimi K campioni vengono pesati con la finestra, mentre gli altri forzati a 0 (Fig. 3.9) Il risultato che si ottiene è che aumenta molto la dinamica delle ampiezze di picco rilevabili correttamente. Lo svantaggio è che i picchi sono leggermente più bassi, quindi si ha una leggera perdita di prestazioni per i pacchetti più deboli. Inoltre il lobo principale di correlazione diviene largo circa tre intervalli di chip anzichè due, perciò ci si espone maggiormente alla collisione fra pacchetti. In Fig. 3.10 è possibile vedere un confronto fra segnale finestrato e non.
La necessità o meno della finestratura dipenderà da quanto E-SSA sarà in grado di limitare la dispersione in potenza degli utenti. L'impiego della finestra introduce inoltre una complessità trascurabile. Ad esempio nel caso di N=256K si è visto che il tempo di calcolo incrementa di circa il 2.5% per ciascun blocco su ciascun ramo.
3.2.7 Normalizzazione e ricerca degli arrivi
La normalizzazione, applicata separatamente su ciascun ramo e su ciascun blocco, consente l'applicazione di una soglia fissa per l'algoritmo di Threshold Crossing.
Dopo la IFFT viene ricavato il modulo con la funzione cabs( ), oppure il modulo quadro e riempito il vettore z[n]. Di esso viene valutato il valore efficace, senza includere l'overlap, con la funzione:
double Veff_value(double *zeta_t_block,int useful_length);
che somma i quadrati dei (N–4Npr+1) campioni utili e divide per il loro numero. Si
può velocizzare questa fase stimando il valore efficace su un subset di essi, ed anche calcolarlo solo su di un ramo e utilizzare lo stesso valore negli altri. I campioni di z[n] vengono tutti divisi per Veff e si entra nel ciclo di ricerca degli arrivi, eseguita su
ciascun ramo. Quando l'elaborazione su un blocco di segnale r[n] è completata, viene prelevato il blocco successivo. La ricerca è costituita da un ciclo esterno while che attraverso l'indice index1 scorre tutti i valori dell'array e controlla il superamento della soglia, che deve essere fissata a seconda del compromesso PFA/PMD desiderato. Quando
viene trovato un valore sopra soglia si entra in un sottociclo while il cui scopo è quello di trovare il punto di massimo locale del lobo di correlazione, usando l'indice index2 (Fig. 3.11). Una volta fissata la coppia (x_argmax,y_max) vengono eseguiti i comandi:
flag=check_if_present(x_argmax,y_max,num_detection,arr_found); if (flag == 0) {num_detection++;}
index1 = index1 + index2 + hop; che eseguono le operazioni:
• check_if_present( ) verifica se il tempo x_argmax è già presente nell'array bidimensionale arr_found, contenente gli arrivi netti trovati finora e le rispettive altezze.
• se viene trovato un tempo già memorizzato che presenta uno scarto inferiore a md (“minimum distance”), si confronta l'altezza y_max con quella già presente: se è superiore allora si aggiorna la posizione dell'array con la nuova coppia, altrimenti no. In pratica il ramo che presenta il picco più alto viene considerato come quello più affidabile per la stima del tempo. In ogni caso la funzione restituisce flag=1. Valori di tempo opportuni per md sono quelli corrispondenti a 1 o 3 campioni.
• se non viene trovato un tempo simile a x_argmax, la nuova coppia è dichiarata come nuovo arrivo e salvata in nuovo posto di arr_found. La funzione restituisce flag=0, e viene incrementato num_detection che conta il numero di arrivi netti trovati e serve a riempire correttamente arr_found.
• index1 viene incrementato del valore (index2+hop), in modo che il segnale torni sotto soglia e possa partire la ricerca del picco successivo. Sono stati applicati valori di hop intorno a 3 aumentati a 6 in presenza di finestratura. La ricerca dei picchi nel blocco termina quando index1 ha superato la posizione utile (N–4Npr). L'utilità di lavorare su vettori z[n] di lunghezza “abbondante” N si spiega
con il fatto che aiuta il riconoscimento di quei lobi presenti in vicinanza di z[0] e di z[useful_length -1]. I primi hanno infatti parte del lobo che compare ripiegata in fondo al vettore, e dunque è necessario un accorgimento per rilevarli, mentre i secondi vengono riconosciuti normalmente grazie al fatto che non vengono tagliati.
Completata la ricerca su tutti i rami e tutti i blocchi, da arr_found viene prelevata la lista dei tempi di arrivo list_found e riordinata con l'algoritmo Quicksort. La rilevazione degli arrivi a questo punto termina con la scrittura del file arrivals_found.txt.
Avendo a disposizione il numero di arrivi num_detection rivelati al secondo (pari a circa il numero di arrivi veri, in condizioni di funzionamento corretto), è possibile fissare una soglia secondo il criterio CFAR, in modo che l'algoritmo si adatti automaticamente ai cambiamenti tenendo costante PFA.
3.2.8 Misura sperimentale delle prestazioni
L'ultima fase dell'esecuzione stima le prestazioni ottenute affidandosi alla Legge dei Grandi Numeri. PFA e PMD vengono calcolate come frequenze relative,
ricordando che nel Capitolo 2 il tempo era stato idealmente suddiviso in celle H0 e H1
PFA=Pr
{
H1| H0
}
≈# detections
# H0cells , PMD=Pr
{
H0| H1}
≈# arrival free cells
# H1cells (3.18) La stima diviene abbastanza affidabile, e quindi il punto individuato sulla ROC è corretto, solo se osserviamo almeno qualche decina di eventi.
La funzione:
double P_FA(double *arrivals, double *list_found, int arr_num, int num_detection);
per ogni elemento list_found[i] cerca il suo corrispettivo nella lista degli arrivi veri, con una tolleranza d'errore impostabile, per esempio, a 1 o 2 campioni (che equivale ad uno scarto concesso di Tc/4 o Tc/2). Se l'arrivo non viene trovato, si incrementa il
contatore dei falsi allarmi e si passa a controllare list_found[i+1]. Terminato l'ultimo controllo su list_found[num_detection - 1] , mostra su schermo il totale dei falsi allarmi, scrive il file false_alarms.txt, calcola il valore EFAR e poi la PFA, dividendo
per il corretto numero di celle H0 ricavato così:
# H0cells=# fft blocks⋅ N −4 N pr1/4 (3.19)
Similmente, la funzione:
double P_MD(double *arrivals, double *list_found, int arr_num, int num_detection);
per ogni elemento arrivals[i] cerca il suo corrispettivo nella lista degli arrivi trovati con una tolleranza d'errore identica al caso precedente. Se non viene trovato, incrementa il contatore dei mancati avvistamenti e passa a controllare arrivals[i+1]. Terminato l'ultimo controllo su arrivals[arr_num - 1] , stampa su schermo il totale dei mancati avvistamenti, scrive il file missed_detections.txt e calcola PMD, andando a
dividere per il numero di celle:
3.3 Alcune ottimizzazioni
Dopo le prime versioni del rivelatore, sono stati inseriti alcuni miglioramenti sia per quanto riguarda la precisione della stima che il tempo di calcolo. In questo paragrafo vengono presentati i più importanti.
I tempi di calcolo da qui in avanti vengono valutati inserendo un comando prima e alcuni dopo la parte di codice in esame:
start=clock(); . . . . . end=clock();
exec_time=((double)(end-start))/CLOCKS_PER_SEC; printf("%.8f\n", exec_time);
La funzione clock( ) fa parte della libreria time.h, in cui tra l'altro viene specificata la macro CLOCKS_PER_SEC.
3.3.1 Interpolazione parabolica
Il picco che viene trovato può, anche in condizioni ottimali di assenza di rumore e interferenza, differire di 1/8 di chip rispetto al tempo vero di arrivo τu. La
causa di ciò risiede nel tempo di campionamento, fisso a Tc/4.
Un miglioramento della stima del tempo di arrivo, con pochi calcoli aggiuntivi, può essere ottenuto approssimando con una parabola il lobo principale della funzione di autocorrelazione del preambolo. La parabola è espressa nella forma:
f t= f pC⋅t−p2 (3.21)
dove τp è l'ascissa corrispondente al max della parabola, e sarà la nuova stima del
tempo di arrivo. C è un opportuno coefficiente negativo, visto che la curva è rivolta verso il basso. Per la costruzione della parabola è necessario innanzitutto individuare i tre istanti di tempo t1, t2 e t3 entro cui cade il picco di correlazione (che equivale al
seguente sistema per ricavare le tre incognite τp, f(τp) e C (Fig. 3.12):
{
f pC⋅t1−p2=f t1 f pC⋅t2−p2=f t2 f pC⋅t3−p2=f t3(3.22)
Dal momento che noi siamo interessati al solo valore τp e il campionamento è regolare
con intervallo Tc/4, manipolando il sistema è facile verificare che si può calcolare
direttamente: p=t2Tc 8 f t1−f t3 f t1−2 f t2f t3 (3.23)
L'unica aggiunta da inserire nel 2DPS è perciò quella di utilizzare una matrice arr_found a quattro righe: le prime due salvano (x_argmax,y2_max) come prima, mentre le altre due salvano le altezze y1_max e y3_max del campione che precede e che segue.
L'interpolazione non viene fatta per ogni picco trovato, ma solo al termine della ricerca sui rami e solo sul candidato che presenta l'ampiezza più elevata rispetto agli altri rami. Per questo la richiesta aggiuntiva di calcolo è assolutamente trascurabile. Nel Capitolo 4 viene valutato tramite simulazione il miglioramento ottenuto in termini di Root Mean Square Error.
3.3.2 Discriminazione degli arrivi nel dominio della frequenza
L'osservazione dei plot nella doppia dimensione tempo-frequenza, suggerisce l'idea di poter tentare di risolvere due preamboli che siano sovrapposti nel tempo (cioè in chip collision) ma non lo siano sufficientemente in frequenza. Per distinguerli con successo la loro distanza in frequenza deve essere superiore al doppio di 1/Tpr, cioè poco più di
300 Hz, in modo che i lobi principali delle zero-delay Ambiguity function (par. 2.1.2) non siano sovrapposti. In questo caso, la dispersione in frequenza a causa del Doppler appare come una risorsa utile anziché come un effetto dannoso (Fig. 3.13).
Nonostante non sia garantita la decodifica con successo di uno o entrambi i pacchetti, il fatto di riconoscerli distinti è utile poiché se l'ampiezza di uno dei due supera di molto l'ampiezza dell'altro la decodifica del primo potrebbe andare a buon fine. Successivamente il ciclo di SIC cancellerebbe il primo pacchetto dal segnale, e quindi con una seconda passata potrebbe avere successo anche la decodifica del secondo pacchetto.
Nel programma deve essere inserita una nuova riga in arr_found dove si indica il numero del ramo su cui è stato trovato il picco di correlazione. La funzione check_if_present( ) deve essere poi modificata in modo che, dopo aver controllato lo scarto di tempo fra un picco trovato e un picco già memorizzato, confronti anche lo scarto frequenziale, in termini di bin. Se tale scarto è uguale o superiore a un certo numero, per esempio 2 nel caso a 13 bin, allora si conclude che si tratta di un arrivo diverso da quello già salvato.
La memorizzazione del numero di ramo rappresenta anche una stima grossolana dell'offset di frequenza con cui giunge un pacchetto, che può essere sfruttata dai circuiti di recupero di frequenza del ricevitore.
3.3.3 Compensazione Doppler ad array fissi
La permutazione del vettore R[k] eseguita dalla funzione offset_comp( ), in realtà può essere evitata semplicemente andando a moltiplicare gli elementi opportuni dei vettori R[k] e P*[k]. In Fig. 3.14 è mostrato a titolo d'esempio il caso k
0=+2.
Nel codice, al posto della funzione è stato perciò inserito un if che distingue i tre casi di k0 positivo, negativo, nullo ed esegue le corrette moltiplicazioni complesse
per riempire l'array in2. In questo modo non è necessaria alcuna modifica sul vettore R[k], nè memoria aggiuntiva per il salvataggio delle sue versioni traslate. Il risparmio di tempo che si ottiene per l'esplorazione di un bin è intorno al 10%.
Fig. 3.13 - Chip-level collision che in frequenza risulta separata.
3.3.4 Rappresentazione in doppia e singola precisione
2DPS è stato inizialmente scritto usando la rappresentazione in double dei numeri complessi, cioè 8 byte per rappresentare la parte reale e altrettanti per quella immaginaria. E' stato poi verificato che il passaggio a singola precisione (float) non solo non mostra perdite apprezzabili delle prestazioni, ma rende il calcolo molto più rapido. Ad esempio, si è visto che l'esecuzione di una singola IFFT a 256 K in float richiede circa il 20% in meno di tempo (21.58 ms contro 26.73 ms).
Allo scopo di lavorare in float devono essere impiegate le apposite funzioni FFTW: fftwf_malloc( ), fftwf_plan_dft_1d( ), fftwf_execute( ) e collegamento con -lfftw3f.
3.4 Implementazione del NCPDI Preamble Searcher
L'implementazione del rivelatore NCPDI si basa anch'essa su un intenso utilizzo di FFTW per effettuare velocemente le correlazioni, facendo ancora attenzione all'overlap necessario. L'esecuzione del programma è di nuovo suddivisa nelle tre fasi di preparazione, rivelazione, e stima delle prestazioni.
Come spiegato in 2.2.2, è stato scelto di eseguire 24 correlazioni parziali, e di conseguenza è necessario operare con trasformate di dimensione N=8 K in modo che, al netto dell'overlap, si copra tutto il preambolo:
N −4 NprM 1
⋅M 4 Npr conNpr=24576
N =8192 , M =24 (3.24)
L'overlap risulterebbe di (4 K -1) ma per comodità è stato fissato a 4 K, in modo che dopo ciascuna IFFT vadano scartati esattamente metà campioni.
Durante l'inizializzazione il preambolo viene suddiviso in M parti e, dopo l'aggiunta di zero-padding fino a 8 K, vengono calcolate le rispettive trasformate P(m)[k]. Di queste ne viene presa la versione complessa coniugata, che viene salvata
sulla corrispondente riga nell'array di complessi avente dimensioni [M,8192].
La fase di rivelazione è costituita da un for che di volta in volta seleziona una porzione di r[n] di dimensione N. Dal vettore nel tempo si passa a R[k], sul quale vengono eseguite le seguenti operazioni per M volte:
• moltiplicazione per P(m)*[k]
• eventuale finestratura Hamming
• IFFT, eliminazione dei 4 K campioni di overlap, ed estrazione del | |2
• somma del contributo appena ottenuto in modulo quadro sulle corrette posizioni dell'array output_NCPDI, in modo che i picchi ottenuti all'uscita dei correlatori parziali si sommino coerentemente.
In questo modo la R[k] viene calcolata solo una volta, ma bisogna fare attenzione a dove vanno ogni volta sommati i nuovi contributi. In Fig. 3.14 è schematizzato questo algoritmo con riferimento alle operazioni nel tempo e al caso semplificato M=3.
Terminata l'elaborazione dei 16 M campioni di test, si procede con la normalizzazione dei valori in output_NCPDI, basata di nuovo sul valore efficace. Le combinazioni che possono essere scelte sono diverse:
• Veff calcolato su tutti gli elementi dell'array
• Veff calcolato su blocchi più piccoli (per esempio 256 K) e normalizzato
indipendentemente su ciascun blocco.
• Veff stimato solo su di un subset di campioni e normalizzazione applicata su
blocchi più grandi.
La scelta di un certo tipo piuttosto che di un altro non incide apprezzabilmente sulla ROC finale che possiamo ottenere. Per il confronto diretto con 2DPS, è tuttavia preferibile effettuare la normalizzazione su blocchi delle stesse dimensioni di quelli che vengono impostati in 2DPS.
Terminata la normalizzazione, comincia la ricerca degli arrivi. Questa viene eseguita come in 2DPS, con la differenza che adesso ogni picco che viene trovato è immediatamente dichiarato come arrivo. Dalla ricerca vengono esclusi i due brevi transitori all'inizio e alla fine dell'array output_NCPDI, durante i quali non sono stati
sommati tutti gli M contributi.
L'ultima fase è il calcolo delle PFA e PMD e la scrittura in uscita del file
output_NCPDI.txt, che consente la visualizzazione su plot.
Anche per la NCPDI continuano a valere le considerazioni sulla finestratura prima di ciascuna IFFT, l'interpolazione parabolica e il passaggio a rappresentazione in float. Infatti, nonostante la ricombinazione dei risultati parziali sia diversa da quanto previsto per il 2DPS, si continua ad avere il problema dei lobi laterali. I picchi che si vedono hanno ancora un lobo principale largo 2 volte il tempo di chip, e alcuni lobi laterali.