C A P I T O L O
4
BCEL
Il BCEL (Byte Code Engineering Library) [BCEL98] è un insieme di APIs (Application Programming Interfaces) che consentono di leggere, creare e modificare il codice assemblato dei file class di Java. Utilizzando il BCEL abbiamo quindi a disposizione un toolkit per lavorare ad alto livello con il bytecode e non dobbiamo preoccuparci dei dettagli implementativi della compilazione o di implementare un parser. Come vedremo più in dettaglio in seguito, ad ogni file class viene associato un oggetto JavaClass che contiene tutte le strutture dati che caratterizzano un file class binario, come ad esempio la tabella dei simboli (nomi delle variabili, delle costanti, dei metodi,…), i diritti di accesso ad attributi e metodi, ed ovviamente le istruzioni dei metodi.Scritto da Markus Dahm [MarkusDahm], il BCEL è realizzato interamente in Java ed il codice sorgente è liberamente utilizzabile rispettando le condizioni delle licenze LGPL (GNU Less General Public License) e Apache; è stato inoltre utilizzato con successo in molti progetti, tra i quali compilatori, ottimizzatori, verificatori e analizzatori del bytecode. Il BCEL è composto da quattro packages:
- classfile: è il package che contiene il parser e le strutture dati per descrivere i vincoli strutturali di un file class;
- generic: è il package che consente di generare e modificare gli oggetti JavaClass;
- util: contiene classi di utilità varia, come ad esempio un viewer dei file class ed un tool per convertire i file class in formato HTML
- verifier: è il top-level del verificatore polivariante implementato da Enver Haase [EnverHaase]; espande e completa le APIs del BCEL.
CAPITOLO 4: BCEL
BCEL e JustIce costituiscono quindi uno strumento per analizzare, creare e modificare i file class binari di Java offrendone una visione object-oriented.
4.1 BCEL:
package classfile
Il package org.apache.bcel.classfile contiene il parser del bytecode offerto dal BCEL, contiene cioè tutti i metodi e attributi utili per leggere i file class. La struttura dati più importante del package è JavaClass: questa riflette esattamente le caratteristiche di un file class realizzato secondo le specifiche Java 2 [vmspecv2].
4.1.1 JavaClass
JavaClass si trova nel package org.apache.bcel.classfile.JavaClass ed è un componente statico del BCEL, viene utilizzato cioè solo per descrivere i vincoli strutturali di un file class, non per modificarlo. Un oggetto JavaClass contiene quindi tutti i metodi, attributi e riferimenti simbolici che descrivono un file class; tale oggetto può essere creato “manualmente” attraverso i tools forniti dal BCEL nel package generic, oppure ottenuto attraverso il ClassParser, che è un oggetto il grado di fare il parsing di un sorgente già compilato.
Questa è la struttura della classe JavaClass (riportiamo per comodità solo gli attributi ed i metodi di interesse):
public class JavaClass extends AccessFlags implements Cloneable, Node { private String file_name;
private String package_name;
private String source_file_name = "<Unknown>"; private String class_name;
private String superclass_name;
private int major, minor; // Compiler version private ConstantPool constant_pool; // Constant pool
private int[] interfaces; // implemented interfaces private String[] interface_names;
private Field[] fields; // Fields, i.e., variables of class private Method[] methods; // methods defined in the class private Attribute[] attributes; // attributes defined in the class ....
public void accept(Visitor v);
.... }
CAPITOLO 4: BCEL
Tutti i riferimenti simbolici sono contenuti nella tabella dei simboli (ConstantPool), che è un array di grandezza fissa che contiene le informazioni necessarie per risolvere al run-time i riferimenti simbolici delle classi; la tabella dei simboli è la struttura dati più estesa di un file class (oltre il 50% della dimensione di un file class viene occupata dalla sua codifica) e contiene in particolare anche le signatures dei metodi e degli attributi (variabili e costanti).
La signature è il nome utilizzato per individuare in modo univoco metodi e attributi di una determinata classe e viene specificata simbolicamente con una codifica compatta. Consideriamo ad esempio un metodo che restituisce un void e che ha come parametro una stringa String: la signature viene codificata come (Ljava.lang.String)V, vengono cioè specificati, per ogni metodo, il tipo dei parametri formali e il tipo restituito, mentre per gli attributi viene specificato, ovviamente, solo il tipo.
Due array, fields e methods, vengono utilizzati per descrivere le caratteristiche di attributi e metodi del file class; methods in particolare è della classe Method ed ha un attributo che ci interessa da vicino: l’array del codice del metodo. Tale attributo è una istanza della classe Code e contiene tutte le informazioni che caratterizzano il metodo, cioè la sequenza di istruzioni, la massima grandezza dello stack (max_stack), il numero massimo di variabili locali (max_locals), il numero di istruzioni (code_length) e la tabella delle eccezioni (exception_table).
4.1.2 Design Patterns
Tutti gli oggetti della classe JavaClass sono caratterizzati dal metodo accept(Visitor v) che consente ad oggetti derivati dalla classe Visitor di compiere delle operazioni (esecuzione simbolica, controllo vincoli, ...) sui vari componenti dei file class con la tecnica dei design patterns [DesignPatterns]: l’obiettivo di un design pattern è quello di separare la struttura dell’oggetto dall’operazione compiuta su di esso, in modo da poter cambiare l’algoritmo eseguito dall’operazione senza dover specificare ogni volta il tipo particolare di classe a cui appartiene l’oggetto passato come parametro. Ad esempio per verificare i vincoli strutturali di una istruzione e per eseguirla simbolicamente si invoca sempre lo
CAPITOLO 4: BCEL
stesso metodo dell’istruzione, il metodo accept(Visitor v), passando come parametro nel primo caso un oggetto della classe InstContraintVisitor, ed uno della classe ExecutionVisitor nel secondo.
4.2 BCEL:
package generic
Il package generic fornisce classi utili per essere svincolati dai dettagli implementativi del bytecode durante la trasformazione dinamica dei file class.
Esaminiamo ora le principali classi che consentono di “generare” le strutture dati caratteristiche dei file class (ovvero degli oggetti JavaClass):
• il tipo di un oggetto viene definito attraverso la classe Type, in questo modo si è svincolati dai dettagli della sintassi delle signatures: ogni tipo rispetta ovviamente tutti i vincoli sintattici e semantici delle specifiche del linguaggio Java e per i tipi più utilizzati la classe Type offre inoltre delle costanti predefinite, ad esempio Type.VOID, Type.STRING.
• la classe ConstantPoolGen implementa la tabella dei simboli (constant pool) ed offre metodi utili per aggiungere nuovi riferimenti simbolici; allo stesso modo la classe ClassGen fornisce una interfaccia utile per aggiungere metodi e attributi ad un file class.
• gli attributi vengono implementati con oggetti della classe FieldGen, mentre i metodi con la classe MethodGen. Per ogni oggetto MethodGen è possibile specificare manualmente la dimensione massima dello stack ed il massimo numero di variabili locali attraverso setMaxLocals() e setMaxStack().
• ogni oggetto che fa riferimento a istruzioni nel bytecode viene detto targeter di istruzioni: i targeters sono caratterizzati dal fatto di non “puntare” direttamente le istruzioni, ma di accedere a queste attraverso degli handles, chiamati appunto InstructionHandles, che specificano, tra le altre cose, la posizione dell’istruzione nel bytecode ed individuano gli handles della istruzione precedente e successiva (nel bytecode). Gli InstructionHandles vengono quindi utilizzati per ottenere un livello di astrazione maggiore e semplificare la vita ai programmatori: le istruzioni vere e proprie infatti consistono solamente di un tag, ovvero il loro opcode, e di due interi che ne specificano la dimensione
CAPITOLO 4: BCEL
in bytes e l’offset nel bytecode: gli InstructionHandles rendono molto semplici le operazioni di lettura, modifica, cancellazione e inserimento di istruzioni (e quindi facilitano anche la costruzione del control-flow graph), supportano la tecnica dei design patterns, implementano il metodo toString() per un più facile output del formato mnemonico dell’istruzione, ed implementano i metodi getInstruction() e getPosition() per restituire l’istruzione vera e propria e la sua posizione nel bytecode, rispettivamente. Il metodo getInstruction() in particolare risulta utile per poter “esaminare” l’istruzione e capire, ad esempio, a quale famiglia appartiene, cioè se è un salto condizionato, una ret, una istruzione aritmetica, e così via. Una gerarchia (incompleta) dei tipi delle istruzioni è quella proposta qui di seguito:
#opcode #lenght Instruction #target #index #position BranchInstruction ReturnInstruction IfInstruction Select TABLESWITCH LOOKUPSWITCH IFEQ IF_ICMPNE IFNULL +getType() #index CPInstruction JsrInstruction StackInstruction LoadInstruction ArrayInstruction ArithmeticInstruction INSTANCEOF NEW +getName() FieldOrMethod +getFieldType() FieldInstruction +getArgumentTypes() InvokeInstruction
CAPITOLO 4: BCEL
• il package fornisce anche strumenti per la creazione di “nuove” istruzioni: ad esempio è possibile creare delle istruzioni utili per il debug ed inserirle quindi nel bytecode, oppure sperimentare nuove istruzioni per una eventuale evoluzione della Java Virtual Machine. In particolare per semplificare la creazione delle istruzioni il package mette a disposizione la classe InstructionFactory e l’interfaccia CompoundInstruction che forniscono metodi per creare varie istruzioni tipate e modelli per la traduzione di istruzioni “virtuali”. Per istruzioni virtuali si intendono delle istruzioni che non esistono realmente nel bytecode, una sorta di “istruzioni generalizzate”: ad esempio una istruzione “virtuale” switch può essere utilizzata come modello per indicare le due istruzioni “reali” lookupswitch e tableswitch del bytecode.
• quando viene trasformato il bytecode, per ottimizzazioni o per semplice analisi del codice, è utile avere strumenti per effettuare la ricerca di determinati patterns. La classe FindPattern è stata studiata proprio per offrire questa possibilità: il metodo search() consente infatti di cercare determinate configurazioni di codice attraverso delle espressioni regolari. Per maggiori dettagli fare riferimento alla documentazione del BCEL [BCEL98].
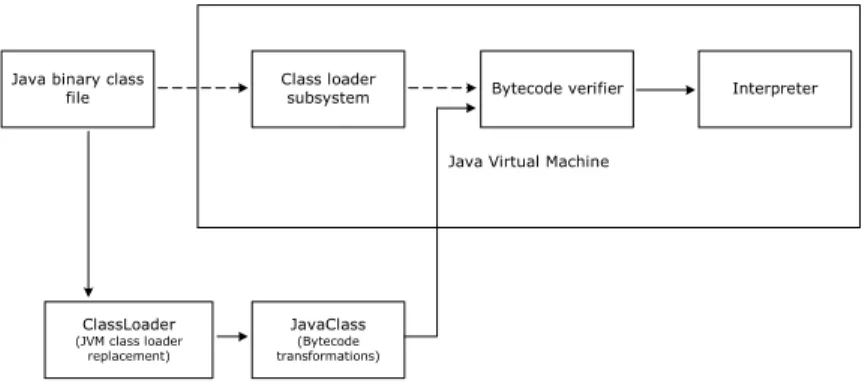
• un’altra interessante possibilità offerta dalle APIs del BCEL è quella di intercettare il caricamento di un file class da parte della JVM attraverso un oggetto ClassLoader. Caricare il bytecode prima della JVM consente di applicare delle trasformazioni al bytecode per sperimentare, ad esempio, strategie di verifica alternative oppure evoluzioni delle APIs della JVM [JavaCoreReflection], vedi figura 4.2.
Java Virtual Machine Java binary class
file
Class loader
subsystem Bytecode verifier Interpreter
JavaClass (Bytecode transformations) ClassLoader (JVM class loader replacement)
CAPITOLO 4: BCEL
4.3 BCEL:
package util
Il package contiene un insieme di classi che forniscono strumenti utili per visualizzare il bytecode e dei buoni esempi per capire come funziona il BCEL. Le classi più interessanti sono:
• BCELifier: questa classe consente di generare un possibile sorgente .java che può aver generato il bytecode del file class che viene passato come argomento. • Class2HTML: legge un file class e lo converte in formato HTML.
• InstructionFinder: è un tool per cercare un determinato pattern, cioè una determinata sequenza di istruzioni specificata attraverso una espressione regolare, all’interno del bytecode.
4.4 BCEL: package verifier (JustIce)
Il package org.apache.bcel.verifier costituisce il top level del JustIce. JustIce è un verificatore di file class implementato da Enver Haase nel 2001: effettua una verifica polivariante del bytecode seguendo le linee guida espresse nelle specifiche Java 2 della Sun [vmspecv2]. La verifica polivariante è un particolare tipo di analisi che risulta “necessaria” quando il bytecode contiene delle subroutines: le subroutines sono la traduzione degli statemets finally del codice Java e vengono in genere utilizzate verso la “fine del codice” per compiere operazioni di “chiusura”, ad esempio chiusura di file aperti o di connessioni TCP; la verifica delle subroutines rende complicata la verifica strutturale ed ha reso necessaria una implementazione particolare del dizionario: più avanti in questo stesso capitolo si parlerà in modo più approfondito del problema della verifica delle subroutines, dei “consigli” della Sun per la loro verifica e delle strutture dati utilizzate dal JustIce per effettuare correttamente la data-flow analysis.
Nel package sono state implementate 5 classi con un main(String[]): una è il main del verificatore vero e proprio (Verifier), le altre sono esempi che chiariscono il funzionamento del JustIce e che consentono di confrontarne i risultati con la versione del verificatore (Sun, Microsoft,...) installata sulla macchina host.
CAPITOLO 4: BCEL
Il JustIce associa ad ogni file class un oggetto Verifier. Per effettuare i vari passi della verifica il Verifier crea istanze di PassVerifier: ogni passo della verifica ha quindi un oggetto che lo identifica che è in grado eseguire una parte dell’algoritmo e di lanciare messaggi per segnalare successo o fallimento del processo. Le classi che effettuano i controlli statici sul file class si trovano nel package statics mentre quelle per fare i controlli strutturali si trovano nel package structurals. Il package exec contiene classi per la gestione dei messaggi di eccezione, cioè violazione di qualche vincolo da parte del bytecode esaminato, lanciati durante la verifica.
4.4.1 JustIce: package statics
Tutte le classi necessarie per verificare i vincoli statici di un file class sono contenute in questo package: sono quindi presenti le classi per i primi passi della verifica (Pass1Verifier, Pass2Verifier, Pass3aVerifier), le strutture dati per rappresentare le variabili locali (nome e tipo contenuto di ognuna di loro) ed alcune altre classi utili per la rappresentazione dei tipi di dati Long e Double, questi infatti hanno una occupazione di memoria doppia rispetto agli altri tipi di dati quindi devono essere gestiti in modo particolare (occuperanno 2 variabili locali: la “parte bassa” sarà memorizzata nella variabile ri e la “parte alta” in ri+1).
Le verifiche statiche non creano difficoltà evidenti quindi non verranno analizzate in dettaglio: viene proposta solo una veloce analisi dei controlli effettuati nei primi 3 passi del JustIce.
Pass1Verifier controlla i vincoli statici indicati nel primo passo delle specifiche Java 2, controlla cioè che il file class che sta per essere caricato dal loader della JVM non contenga evidenti problemi di integrità.
Pass2Verifier effettua il passo 2 delle specifiche della Sun: controlla l’integrità del contenuto della tabella dei simboli, la correttezza della gerarchia delle classi, la validità dei nomi e dei descrittori utilizzati, effettua cioè tutti i controlli che è possibile fare senza guardare le istruzioni del bytecode.
Pass3aVerifier compie tutti gli ultimi controlli statici necessari prima di cominciare la data-flow analysis [vmpecv2 4.9.1, Pass 3] ed i controlli del passo 4 delle specifiche della Sun [vmpecv2 4.9.1, Pass 4]. Il passo 4 viene effettuato ora
CAPITOLO 4: BCEL
perché contiene controlli che vengono effettuati al run-time ed il JustIce, non facendo parte della JVM installata sul sistema, non potrebbe quindi effettuarli. Comunque il passo 4 è un passo “virtuale”, cioè ritarda semplicemente dei controlli (che potevano esser fatti nel passo 3) per ragioni di efficienza (i primi 3 passi della Sun infatti non richiedono il caricamento dell’intero file class) quindi “anticipare” questi controlli non va contro le specifiche e comunque non crea problemi.
4.4.2 JustIce: package structurals
Come accennato in precedenza, il JustIce non compie una verifica seguendo “alla lettera” le specifiche Java 2 perché queste vogliono solo rappresentare delle linee guida e non sono quindi espresse in modo rigoroso ed alle volte possono essere soggette a interpretazione: l’autore ha quindi scelto di restare quanto più fedele era possibile a quelle specifiche ma di implementare il JustIce osservando anche il funzionamento di altri verificatori ed inoltre, dove ritenute lacunose, le specifiche della Sun sono state “completate” (in particolare verrà proposta una definizione “chiara” di subroutine).
Partiamo proprio con l’analisi della verifica delle subroutines perché il JustIce effettura una analisi polivariante ed è quindi necessario capire quali informazioni occorre memorizzare per comprendere a fondo le motivazioni che hanno spinto all’utilizzo di determinate strutture dati.
4.4.2.1 Verifica delle subroutines secondo la Sun
Le subroutines solo la traduzione nel bytecode del blocco finally, spieghiamo quindi ora come funziona, almeno a grandi linee, la gestione delle eccezioni in Java: quando un metodo può potenzialmente lanciare eccezioni (ad esempio la Integer.readLine(), legge un intero dallo stdin e può lanciare una NumberFormatException) va messo in un blocco try in modo da avere a disposizione un meccanismo per cui vada in esecuzione un handler (exception handler) che gestisca correttamente la situazione di errore. Ogni handler viene
CAPITOLO 4: BCEL
definito all’interno di un blocco catch ed è associato al tipo di eccezione specificato dal catch. Capitano situazioni in cui è necessario compiere determinate operazioni sia che vengano lanciate eccezioni, sia che non vengano lanciate: per evitare ripetizioni di statements ed inutile complessità nel codice sorgente è stato appunto ideato il blocco finally, cioè il compilatore garantisce che tutte le istruzioni contenute nel blocco finally vengano eseguite dopo il try o try-catch.
Per implementare il blocco finally il compilatore della Sun utilizza un meccanismo simile a quello dei gestori delle eccezioni: attraverso l’uso di due istruzioni particolari, jsr (jump subroutine) e ret (return from subroutine), il codice della subroutine diventa “condivisibile” perché la chiamata a quel codice è parametrizzata. La chiamata è parametrizzata perché la jsr, ogni volta che viene invocata, salva sullo stack l’indirizzo di ritorno e salta al codice di inizio della subroutine: l’indirizzo di ritorno (returnAddress) è un tipo particolare di dato che può essere prelevato da un registro solo con l’istruzione ret. Quindi in questo modo si riesce a rendere comune un blocco di codice a più flussi di esecuzione del grafo.
Sono molti i modi con cui si può arrivare al codice di una subroutine: dopo l’ultima istruzione del blocco try se non vengono lanciate eccezioni, dopo l’ultima istruzione di un blocco catch, o in seguito ad una eccezione lanciata proprio dal gestore di una eccezione. Come si intuisce quindi la struttura del grafo in presenza delle subroutines diventa più complessa, e questo porta ad un incremento della complessità anche del processo di verifica del bytecode.
Le subroutines devono rispettare determinati vincoli strutturali [vmspecv2 4.8.2]:
• il codice della subroutine può avere al massimo una ret;
• la catena delle jsr deve essere strutturata in modo da non provocare chiamate ricorsive tra le subroutines;
• un particolare indirizzo di ritorno può essere utilizzato al massimo una volta.
La Sun propone delle idee per effettuare una verifica polivariante [vmspecv2 4.9.6]:
• ogni istruzione deve tener traccia della lista di targets della jsr per raggiungere una determinata istruzione; spesso questa lista contiene una sola istruzione
CAPITOLO 4: BCEL
perché avere più jsr annidate vuol dire avere più blocchi finally annidati, e questa è una cosa statisticamente poco probabile nei codici sorgenti.
• per ogni istruzione eseguita dopo la jsr viene tenuta traccia, con un vettore di bit, quali sono le variabili modificare dalla subroutine: in questo modo è possibile propagare correttamente i tipi in seguito al raggiungimento l’istruzione ret.
La verifica polivariante è necessaria per propagare correttamente i tipi delle variabili locali dopo l’esecuzione di una ret: proponiamo ora un esempio che dovrebbe chiarire la natura del problema. L’esempio è lo stesso proposto da Enver Haase nell’articolo sul JustIce [JustIce, pag 40]:
0: iconst 0 ; carica la costante intera 0 nello stack...
1: istore 0 ; ...e poi la salva nel registro r0
2: jsr 11 ; salta al codice della subroutine
5: fconst 0.0 ; carica la costante float 0.0 nello stack...
6: fstore 0 ; ...e poi la salva nel registro r0
7: jsr 11 ; salta di nuovo al codice della subroutine
10: return ; fine del metodo
11: astore 1 ; inizio subroutine: salva indirizzo di ritorno in r1
12: nop ; NOP
13: ret 1 ; fine subroutine: torna all’indirizzo specificato in r1
Il grafo relativo a questo codice è riportato in figura 4.3.
START 0 1 5 END 11 12 2 13 6 7 10 (jsr 11) (jsr 11) (ret 1) (astore 1)
fig. 4.3: Grafo di flusso con una subroutine
Siamo in presenza di due chiamate alla subroutine: prima della 2: jsr 11 il registro r0 contiene un tipo intero, mentre prima della 7: jsr 11 contiene un float;
CAPITOLO 4: BCEL
se non fossimo in presenza di una subroutine il r0 verrebbe marcato come
inutilizzabile perché int e float non hanno un supertipo comune, invece un verificatore polivariante in questo caso deve marcare r0 come inutilizzabile solo
all’interno del corpo della subroutine (il codice delle subroutine è sempre lo stesso per le diverse chiamate quindi r0 non può contenere una volta un int e l’altra un
float ed essere utilizzato in lettura dalla subroutine) ed in più, se la subroutine non ne modifica il contenuto, quando si giunge alla ret r0 deve contenere il tipo che
aveva prima della jsr: in questo modo è possibile ottenere una corretta propagazione dei tipi.
In definitiva quindi le difficoltà nella verifica delle subroutines sono legate ai seguenti fattori:
• il merge che viene effettuato tra la jsr ed il suo successore porta ad una propagazione esatta del tipo “all’interno” della subroutine ma ad una propagazione inesatta dopo la ret; il problema è fondamentalmente legato al fatto di memorizzare il frame del target della jsr;
• il bytecode non è strutturato: non è possibile capire sempre esattamente qual è il codice di una subroutine [fig 4.4];
• il bytecode può esser scritto e modificato “a mano”, esiste quindi del bytecode valido che però non può essere generato da nessun codice sorgente [fig 4.5].
0: jsr 5 3: nop 4: return 5: astore_2 6: iconst_0 7: iload_1 8: if_icmpeq -> 3 10: ret 2
fig. 4.4: Il bytecode non è strutturato: quali sono le istruzioni della subroutine? La nop fa parte della subroutine?
CAPITOLO 4: BCEL 0: jsr 4 3: return 4: dup 5: astore_2 6: pop 7: ret 2
fig. 4.5: Bytecode corretto che nessun compilatore “standard” produce a partire da un sorgente java. Questo codice supera la verifica effettuata dal verificatore della Sun, è invece rigettato dal JustIce.
4.4.2.2 Verifica delle subroutines proposta nel JustIce
Il JustIce impone dei vincoli strutturali chiari e determinati per le subroutines: questi vincoli portano però a rigettare una certa percentuale, anche se minima, di metodi con codice valido.
Definizione “precisa” di subroutine proposta nel JustIce:
• ogni istruzione del metodo fa parte al massimo di una sola subroutine: se non appartiene a nessuna subroutine diremo che appartiene al top-level del metodo; • la prima istruzione di una subroutine è sempre una astore_N che memorizza il
returnAddress salvato in testa allo stack nella variabile locale rN;
• le subroutines terminano sempre con una ret: per ogni jsr esiste quindi sempre una ed una sola ret associata;
• le subroutines non sono protette da alcun gestore delle eccezioni;
• nessuna istruzione della subroutine può essere il target di un gestore delle eccezioni;
• se una subroutine s1 (supponiamo che cominci con astore_1) è annidata in un’altra subroutine s0 (supponiamo che cominci con astore_0), la s1 non può utilizzare il returnAddress della variabile r0.
CAPITOLO 4: BCEL 0: jsr 4 3: return 4: dup 5: astore_2 6: astore_3 7: iconst_0 8: iload_1 9: if_icmpeq -> 11 11: ret 2 12: ret 3
fig. 4.6: Codice non valido: istanza del return address utilizzata più volte
Imponendo questi vincoli abbiamo la sicurezza di avere subroutines “correttamente annidate” e quindi strutture “particolari” del grafo di flusso dovute a bytecode non prodotto da un compilatore “standard” non passano la verifica.
Quindi, a parte le “precisazioni” sul termine subroutine, il JustIce segue le indicazioni della Sun per quanto riguarda la verifica.
CAPITOLO 4: BCEL
4.4.2.3 JustIce: il control-flow graph
Ogni metodo da verificare è caratterizzato da un control-flow graph e questo viene rappresentato da una istanza della classe ControlFlowGraph:
public class ControlFlowGraph{
private class InstructionContextImpl implements InstructionContext{ ...
}
private final MethodGen method_gen;
private final Subroutines subroutines;
private final ExceptionHandlers exceptionhandlers;
private Hashtable instructionContexts;
public ControlFlowGraph(MethodGen method_gen);
public InstructionContext contextOf(InstructionHandle inst);
public InstructionContext[] getSuccessors();
... }
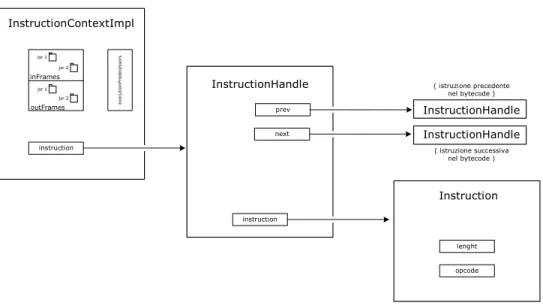
Nel JustIce l’insieme di informazioni che caratterizzano una istruzione viene chiamato contesto dell’istruzione: fanno parte del contesto quindi l’istruzione ed il suo frame, i suoi successori, eventuali bit per il tagging e la lista delle jsr effettuate fino a quel momento. Una implementazione dell’interfaccia InstructionContext costituisce quindi il candidato ideale per la realizzazione del grafo di flusso (vedi figura 4.7).
CAPITOLO 4: BCEL InstructionContextImpl InstructionHandle Instruction ex ec ut io nP re d e ce ss or s jsr 1 jsr 2 jsr 1 jsr 2 inFrames outFrames instruction instruction prev next InstructionHandle InstructionHandle lenght opcode ( istruzione precedente nel bytecode ) ( istruzione successiva nel bytecode )
fig. 4.7: Relazione tra nodi del control-flow graph (InstructionContextImpl), InstructionHandles, Instruction
Per recuperare un nodo del grafo si utilizza il metodo contextOf(...) che ha come parametro l’InstructionHandle dell’istruzione richiesta.
L’interfaccia InstructionContext offre 5 metodi per un facile accesso a tutte le funzionalità necessarie per compiere una data-flow analyis come quella indicata nelle specifiche Java 2:
• execute(...): esegue simbolicamente una istruzione, verrà descritta più in dettaglio tra breve;
• getSuccessors(): restituisce un vettore di InstructionContext(s), cioè di nodi del grafo: contiene il successore naturale e tutti gli eventuali targets dell’istruzione; può lanciare eccezioni, in particolare questo avviene se il metodo viene invocato su istruzioni ret: questa scelta è stata fatta perché i vincoli strutturali imposti sulle subroutines devono essere accuratamente valutati e, potendo cambiare da implementazione a implementazione, è bene farli con metodi ad-hoc; bisogna tener presente infatti che il successore di una ret è contenuto nel registro specificato come parametro, ad esempio r0 se l’istruzione
CAPITOLO 4: BCEL
ricostruire la catena di esecuzione (execution chain) per poter controllare se la coppia jsr-ret è valida.
• getExceptionHandlers(): restituisce tutti i gestori di eccezioni che proteggono l’istruzione. Gli ExceptionHandlers sono potenziali successori delle istruzioni da loro protette: questa informazione è contenuta nella tabella delle eccezioni quindi, per evitare ripetizioni che potrebbero potenzialmente appesantire molto la struttura del grafo e per gestire meglio il problema di eventuali chiamate ricorsive tra gli handlers, i rami del grafo che vanno da una istruzione ai suoi handlers vengono creati al volo ogni volta che la data-flow analysis raggiunge il nodo;
• getOutFrame(...): restituisce l’out-frame ottenuto attraverso l’esecuzione simbolica dell’istruzione;
• getInstruction(): restituisce l’InstructionHandle dell’istruzione associata al nodo del grafo.
La classe InstructionContextImpl viene implementata come classe privata del ControlFlowGraph quindi dall’esterno è possibile utilizzare solo i metodi forniti dall’interfaccia InstructionContext: questo va bene, perché solo i metodi del ControlFlowGraph devono gestire determinati aspetti della struttura dei nodi (ad esempio il caching dei successori o la lista delle jsr effettuate fino a quel momento).
CAPITOLO 4: BCEL
Esaminiamo la classe InstructionContextImpl:
private class InstructionContextImpl implements InstructionContext{
private InstructionHandle instruction;
private HashMap inFrames;
private HashMap outFrames;
private ArrayList executionPredecessors;
private boolean mergeInFrames(Frame inFrame) ;
private InstructionContextImpl lastExecutionJSR() ;
public boolean execute(...) ;
public Frame getOutFrame(Arraylist execChain) ;
public ExceptionHandler[] getExceptionHandlers() ;
public InstructionHandle getInstruction() ;
public InstructionContext[] getSuccessors() ; ...
}
A differenza di altre implementazioni, in cui viene memorizzato solo l’in-frame dei targets, il JustIce memorizza due frames (in-frame e out-frame) per ogni istruzione e per tutta la durata della data-flow analysis. Memorizzare il frame per ogni istruzione è stato fatto per seguire fedelmente le specifiche Java 2 della verifica, mentre il fatto di memorizzare in-frame e out-frame è probabilmente solo legato al fatto che in questo modo il codice del metodo che implementa la data-flow analysis (anticipiamo fin da ora che è la circulationPump(...) implementata nella classe Pass3bVerifier) viene leggermente semplificato e ottimizzato.
In-frame e out-frame di ogni istruzione sono in realtà due tabelle, in particolare due HashMap, perché per effettuare correttamente una analisi polivariante è necessario selezionare il frame giusto: il tipo delle variabili locali cambia (potenzialmente) a seconda della diversa sequenza di subroutines eseguite. Nelle specifiche della Sun, infatti, viene consigliato di salvare la sequenza delle jsr effettuate: nel JustIce è sufficiente salvare quale è stata l’ultima subroutine eseguita perché, grazie ai vincoli imposti [par.4.4.2.2, JustIce pag.37], ogni volta che si incontra una ret c’è sempre una jsr associata e tutte le coppie jsr-ret sono sempre correttamente annidate. Quindi, la chiave utilizzata per l’HashMap è
CAPITOLO 4: BCEL
l’ultima subroutine eseguita: se non ne è stata eseguita nessuna vuol dire che siamo al top-level e la chiave utilizzata in questo caso è null.
Il vettore executionPredecessors memorizza la sequenza delle istruzioni che sono state eseguite simbolicamente dall’interprete astratto fino a quel momento: è utile per un output verboso, ad esempio per visualizzare la sequenza di esecuzione che ha prodotto il fallimento della verifica di un metodo, e per i controlli strutturali da effettare sulle subroutines.
Il metodo mergeInFrames(Frame inFrame) effettua il merge come descritto nelle specifiche Java 2: il merge viene fatto tra l’out-frame dell’istruzione corrente e l’in-frame dei successori [vmspecv2 4.9.2, 4° passo della data-flow analysis]. In realtà il JustIce è stato implementato “dal punto di vista del successore”: l’istruzione che viene eseguita non è la corrente ma il successore; questo sarà più chiaro tra poco, quando descriveremo in dettaglio la data-flow analysis [cap 4.4.2.4]. Implementare la data-flow analysis dal punto di vista del successore implica effettuare il ciclo descritto nelle specifiche Java 2 [vmspecv2 4.9.2] cominciando dal terzo punto altro che dal primo: questo non comporta comunque problemi, anzi, per come è strutturato il JustIce è una ottimizzazione a livello di tempo di esecuzione. Quindi il metodo mergeInFrames(...) viene ogni volta applicato ai successori ed ha come parametro l’out-frame dell’istruzione attuale (che costituisce appunto il nuovo in-frame dei successori): l’in-frame da modificare è quello dei successori e non occorre passarlo come parametro perché è memorizzato nel nodo del grafo (HashMap InFrames) e quindi il metodo può andare direttamente a modificarlo (se il merge lo fa cambiare).
L’out-frame dell’istruzione attuale viene recuperato attraverso il metodo getOutFrame(ArrayList execChain): siccome l’out-frame dell’istruzione corrente viene generato dal ciclo precedente della data-flow analysis (per i motivi su menzionati) bisogna anche controllare che questo sia stato fatto correttamente quindi, probabilmente per non complicare troppo il codice della circulationPump(...), è stato scelto di implementare un metodo dedicato per recuperare l’out-frame.
Il metodo execute(...) compie l’esecuzione simbolica dell’istruzione: ha come parametri il nuovo in-frame dell’istruzione (cioè l’out-frame del predecessore), la lista di esecuzione (execPreds) delle istruzioni e due oggetti
CAPITOLO 4: BCEL
derivati dalla classe Visitor per effettuare il controllo dei vincoli strutturali e l’esecuzione simbolica con la tecnica dei design patterns [par. 4.1.2.1]. Il metodo restituisce un booleano: restituisce true se il changed bit [vmpec2 4.9.2] vale true, cioè se l’istruzione deve essere eseguita perché il suo in-frame è cambiato, false altrimenti. Prima di eseguire simbolicamente l’istruzione vengono fatti i controlli strutturali invocando il metodo accept(...) dell’istruzione passando come parametro un oggetto della classe InstConstraintVisitor: se i vincoli non vengono rispettati la verifica fallisce e viene lanciata una eccezione StructuralCodeConstraintException. L’esecuzione simbolica viene effettuata invocando il metodo accept(...) dell’istruzione passando come parametro un oggetto ExecutionVisitor. Alla fine della execute(...) viene sempre aggiornata la tabella degli out-frame dell’istruzione.
CAPITOLO 4: BCEL
4.4.2.4 JustIce: la data-flow analysis
La classe Pass3bVerifier esegue i controlli strutturali sui file class. Esaminiamo la struttura della classe:
public final class Pass3bVerifier extends PassVerifier{
private static final class InstructionContextQueue{...}
private int method_no;
private void circulationPump(...);
public VerificationResult do_verify();
public int getMethodNo();
... }
Solo due metodi sono pubblici: uno è utile per conoscere il numero del metodo su cui si sta effettuando la verifica (getMethodNo()) e l’altro serve per lanciare il passo della verifica (do_verify()).
Per effettuare la data-flow analysis è necessario avere una coda in cui porre le istruzioni da verificare: la coda è stata implementata con la classe InstructionContextQueue:
private static final class InstructionContextQueue{
private Vector ics;
private Vector ecs;
public void add(...);
public int size();
public void remove(...);
public boolean isEmpty();
public InstructionContext getIC(int i);
public ArrayList getEC(int i); }
Nella coda istruzioni (ovvero nella worklist) vengono messi direttamente i nodi del grafo, in modo da non dover chiamare ogni volta il metodo contextOf(...) per ottenere, partendo dall’InstructionHandle, i successori del nodo da esaminare: il vettore ics (instruction contexts) contiene quindi tutte le istruzioni da eseguire simbolicamente, ovvero tutte quelle che hanno il changed-bit che vale true.
CAPITOLO 4: BCEL
Il vettore ecs (execution chains) contiene la sequenza di istruzioni che è stato necessario eseguire per arrivare ad un determinato nodo del grafo: ogni nodo della coda ics è quindi associato ad una execution chain della ecs. La classe fornisce ovviamente tutti i metodi necessari per aggiungere (add(...)) e rimuovere (remove(...)) elementi alla worklist, per conoscerne la dimensione (size()) o sapere se è vuota (isEmpty()) e per restituire elementi delle due code (getIC() e getEC()). La workList è privata perché solo la circulationPump(...) deve poterla modificare.
La circulationPump(...) è il metodo che compie da data-flow analysis: lanciato dalla do_verify(), ha come parametri il control-flow graph su cui deve operare, il primo nodo del grafo (start) ed il suo in-frame (vanillaFrame) e due oggetti derivati dalla classe Visitor necessari per compiere le verifiche strutturali (icv, instruction constraint visitor) e l’esecuzione simbolica (ev, execution visitor). Il control-flow graph ed il vanillaFrame vengono creati dalla do_verify(): basta infatti guardare la signature del metodo per capire quali variabili locali inizializzare e con quale tipo inizializzarle. Lo stack inizialmente è vuoto. La massima dimensione dello stack ed il massimo numero di variabili locali sono due attributi del campo Code di ogni metodo.
Analizziamo ora il funzionamento della circulationPump(...): la prima istruzione del metodo ha il changed-bit che vale true quindi viene eseguita simbolicamente (per generare e quindi salvare il suo out-frame nell’InstructionContext della prima istruzione) e messa nella worklist. Per eseguire simbolicamente una istruzione si invoca il metodo execute(...)1. A
questo punto comincia il ciclo descritto nelle specifiche Java 2: l’istruzione viene prelevata dalla worklist e vengono calcolati i successori. L’istruzione attuale (in questo caso la prima del metodo) è già stata eseguita quindi ne conosciamo l’out-frame, è possibile allora invocare direttamente il metodo execute(...) per i successori: penserà quel metodo a fare prima il merge tra l’out-frame attuale (cioè nuovo in-frame del successore) ed il vecchio in-frame del successore (se non esistesse un vecchio in-frame il merge ovviamente non viene effettuato e si utilizza
1
Nel JustIce eseguire una istruzione vuol dire fare il merge tra l’out-frame del predecessore e l’in-frame dell’istruzione su cui viene invocata la execute(...), fare controlli strutturali e simulare l’effetto su variabili locali e stack dell’istruzione se l’in-frame cambia in seguito al merge, aggiornare l’out-frame dell’istruzione.
CAPITOLO 4: BCEL
direttamente il nuovo in-frame per fare controlli strutturali ed esecuzione simbolica). Se il merge produce un cambiamento nell’in-frame del nodo allora la execute(...) restituisce true (naturalmente si assume che il controllo dei vincoli strutturali sia stato superato con successo: in caso contrario sarebbe stata lanciata una eccezione e la verifica sarebbe fallita).
Quindi una versione semplificata della circulationPump(...) è la seguente:
private void circulationPump( ControlFlowGraph cfg, InstructionContext start,
Frame vanillaFrame, InstConstraintVisitor icv, ExecutionVisitor ev ){
InstructionContextQueue icq = new InstructionContextQueue();
start.execute(vanillaFrame, new ArrayList(), icv, ev);
icq.add(start, new ArrayList());
while(!icq.isEmpty()){ InstructionContext u;
ArrayList ec = getEC();
ArrayList newchain = (ArrayList) (ec.clone()); u = icq.getIC(r);
icq.remove(r);
InstructionContext[] succs = u.getSuccessors(); for(int s=0; s<succs.length; s++){
InstructionContext v = succs[s];
if(v.execute(u.getOutFrame(oldchain), newchain, icv, ev)){ icq.add(v, (ArrayList) newchain.clone());
} }
} }
La circulationPump(...) effettua in realtà anche altre operazioni: in particolare prima di eseguire una istruzione controlla se l’istruzione in questione è una ret: in tal caso effettua prima dei controlli strutturali per verificare il corretto annidamento delle subroutines e poi calcola il successore della ret ed effettua il merge in modo polivariante. Inoltre c’è anche un ciclo che controlla se l’istruzione è protetta da qualche gestore delle eccezioni: in tal caso mette tra i possibili successori anche le prime istruzioni dei gestori, cioè invoca il metodo execute(...) sulla loro prima istruzione (effettua quindi merge, controlli strutturali ed esecuzione simbolica) e se questo metodo restituisce true (ovvero se l’in-frame della prima
CAPITOLO 4: BCEL
istruzione del gestore di eccezioni cambia in seguito al merge) allora l’istruzione viene messa nella worklist (ics).
La circulationPump(...) prevede inoltre due modalità di funzionamento: normale e debug. Le due modalità differiscono per il modo in cui le istruzioni vengono prelevate dalla worklist: nella modalità normale vengono prelevate casualmente, nella modalità debug in modo sequenziale.