113
CAPITOLO 3
RISULTATI
114
Nel presente lavoro sono stati analizzati complessivamente 306 individui di cui 157 appartenenti alla specie Amphibalanus amphitrite e 149 a Styela plicata.
Gli individui di A. amphitrite analizzati hanno fornito sequenze della subunità I del gene mitocondriale Citocromo Ossidasi (COI) di 585 bp. Sono state ottenute 10 sequenze per i campioni di: Montecarlo, Genova, La Spezia sito 2, Olbia, Siracusa, Taranto, Ravenna e Porto Marghera, ed 11 sequenze per i porti di: La Spezia sito 1, Viareggio, Livorno, Portoferraio, Civitavecchia, Ancona e Trieste.
Per S. plicata le sequenze della COI ottenute sono risultate essere lunghe 613 bp. Sono state ottenute 10 sequenze per i campioni di: Montecarlo, Genova, La Spezia sito 1 e sito 2, Viareggio, Livorno, Portoferraio, Civitavecchia, Olbia, Taranto, Manfredonia, Ancona, Ravenna e Trieste e soltanto 9 sequenze per il campione di Siracusa.
3.1 COI in Amphibalanus amphitrite
3.1.1 Caratteristiche molecolari delle sequenze
Con l’ausilio del programma jModeltest (Posada & Crandall, 1998) è stato selezionato il modello di sostituzione nucleotidica che meglio soddisfa i nostri dati. Questo risulta essere TrN+I (Tamura & Nei, 1993) con le seguenti frequenze per ciascuna base nucleotidica: fA = 0.2860, fC = 0.1775, fG = 0.1622, fT = 0.3743. Dalle sequenze nucleotidiche (Appendice III) sono state ricavate con il programma DNAsp5 (Rozas et al., 2003) le sequenze aminoacidiche (Appendice IV) ed è stata rilevata la presenza di tre mutazioni non silenti. Alla posizione 130 in una sequenza del campione di Taranto un’Alanina risulta sostituita con una Treonina, alla posizione 134, in un individuo del campione di Ravenna, la Metionina viene sostituita da un’Isoleucina, ed infine sempre un’Isoleucina va a sostituire una Valina alla posizione 154 di una sequenza del campione di Viareggio.
3.1.2 Diversità genetica entro i campioni
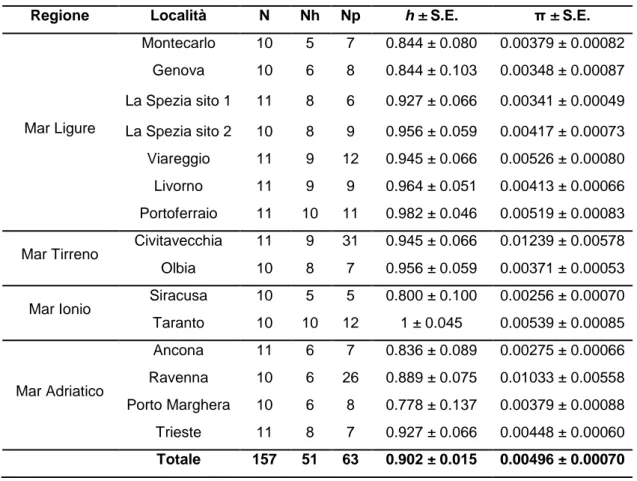
Nelle 157 sequenze analizzate abbiamo riscontrato la presenza di 51 aplotipi caratterizzati da 63 siti polimorfici (Tab. 3.1). In generale in tutti i siti
115
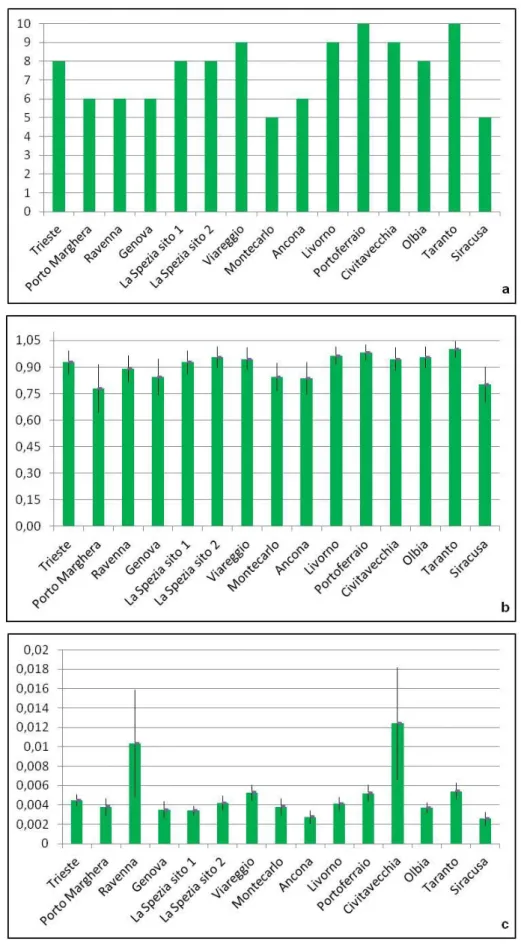
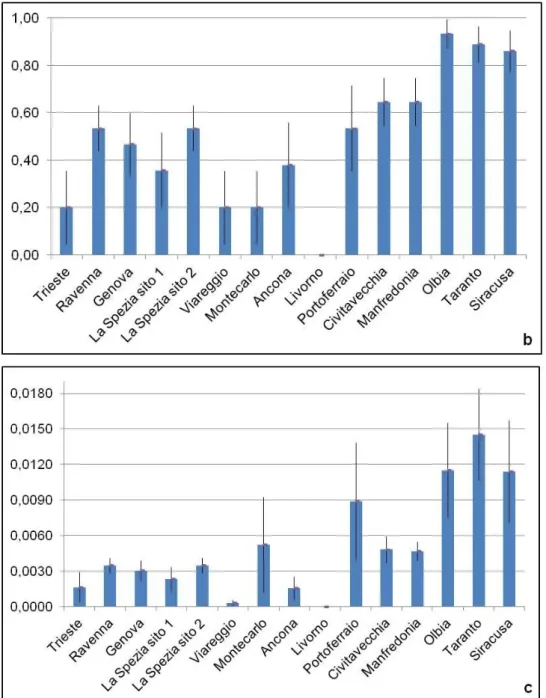
campionati è stato ritrovato un alto numero di aplotipi che và da un minimo di 5 ad un massimo di 10, mentre i porti con il maggior numero di siti polimorfici sono Civitavecchia, con 31 siti polimorfici, e Ravenna con 26 (Fig. 3.1). I porti in cui è presente il maggior numero di aplotipi, cioè 10, sono quelli di Portoferraio (10 aplotipi differenti su un totale di 11 sequenze analizzate) e Taranto (10 aplotipi differenti su un totale di 10 sequenze analizzate). La diversità aplotipica ha mostrato valori sempre elevati, il valore più alto è stato registrato nel porto di Taranto, h = 1, dove ogni individuo del campione è caratterizzato da un diverso aplotipo, mentre il valore più alto di diversità nucleotidica, π = 0.01239, è stato riscontrato nel porto di Civitavecchia. Il valore minimo di diversità aplotipica, h = 0.778, è relativo al campione di Porto Marghera, mentre quello della diversità nucleotidica π = 0.00256, si osserva nel porto di Siracusa.
Tab. 3.1: Stime di diversità genetica in A. amphitrite. N = numero di individui; Nh = numero di
aplotipi, Np = numero di siti polimorfici, h = diversità aplotipica e π = diversità nucleotidica, S.E. = errore standard.
Regione Località N Nh Np h ± S.E. π ± S.E.
Mar Ligure Montecarlo 10 5 7 0.844 ± 0.080 0.00379 ± 0.00082 Genova 10 6 8 0.844 ± 0.103 0.00348 ± 0.00087 La Spezia sito 1 11 8 6 0.927 ± 0.066 0.00341 ± 0.00049 La Spezia sito 2 10 8 9 0.956 ± 0.059 0.00417 ± 0.00073 Viareggio 11 9 12 0.945 ± 0.066 0.00526 ± 0.00080 Livorno 11 9 9 0.964 ± 0.051 0.00413 ± 0.00066 Portoferraio 11 10 11 0.982 ± 0.046 0.00519 ± 0.00083 Mar Tirreno Civitavecchia 11 9 31 0.945 ± 0.066 0.01239 ± 0.00578 Olbia 10 8 7 0.956 ± 0.059 0.00371 ± 0.00053 Mar Ionio Siracusa 10 5 5 0.800 ± 0.100 0.00256 ± 0.00070 Taranto 10 10 12 1 ± 0.045 0.00539 ± 0.00085 Mar Adriatico Ancona 11 6 7 0.836 ± 0.089 0.00275 ± 0.00066 Ravenna 10 6 26 0.889 ± 0.075 0.01033 ± 0.00558 Porto Marghera 10 6 8 0.778 ± 0.137 0.00379 ± 0.00088 Trieste 11 8 7 0.927 ± 0.066 0.00448 ± 0.00060 Totale 157 51 63 0.902 ± 0.015 0.00496 ± 0.00070
116
Fig. 3.1: Istogrammi dei valori di a) numero degli aplotipi, b) diversità aplotipica (± errore
standard) e c) diversità nucleotidica (± errore standard), di A. amphitrite in ciascun porto considerato.
117
3.1.3 Diversità genetica tra i campioni
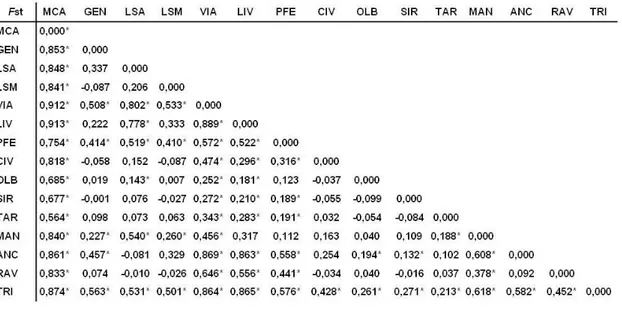
L’indice di fissazione (FST) mostra valori (Tab. 3.2) che variano da un massimo di FST = 0.104 per la coppia Siracusa-Trieste, ad un minimo di FST = 0.002 per la coppia Montecarlo-Ancona. Inoltre 73 coppie di valori risultano negativi e possono quindi essere interpretati come valori 0, indicando totale omogeneità fra coppie di campioni. Non sono stati riscontrati valori significativi di FST.
Tab. 3.2: Indice di fissazione FST per ogni coppia di siti campionati. MCA = Montecarlo; GEN = Genova; LSA = La Spezia sito 1; LSM = La Spezia sito 2; VIA = Viareggio; LIV = Livorno; PFE = Portoferraio; CIV = Civitavecchia; OLB = Olbia; SIR = Siracusa; TAR = Taranto; ANC = Ancona; RAV = Ravenna; VEN = Porto Marghera; TRI = Trieste e TOT = totale.
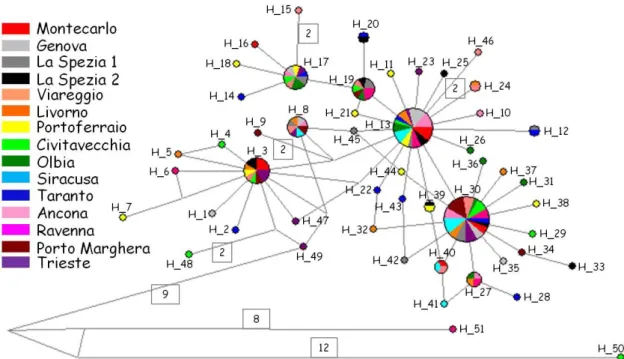
Al fine di identificare le relazioni esistenti tra i vari aplotipi è stato costruito un network con l’algoritmo Median-Joining. La Figura 3.2 mostra i 51 aplotipi trovati analizzando i campioni di A. amphitrite, di essi 39 sono privati e vengono elencati in Tabella 3.3 insieme al porto a cui appartengono. Altri 6 aplotipi sono rari, di questi 4 sono rappresentati da due soli individui: H12 (La Spezia sito 1 e Taranto), H20 (La Spezia sito 2 e Taranto), H24 (Viareggio e Livorno), H39 (La Spezia sito 2 e Portoferraio). Gli altri 2 aplotipi rari sono H27 (presente in un individuo da Livorno, Olbia, Ancona e Ravenna) e H40 (presente in un individuo da Montecarlo, Viareggio e Siracusa). I restanti 6 aplotipi sono condivisi da un gran numero di individui provenienti da molti dei siti analizzati.
In Figura 3.2 si può inoltre notare la presenza di due aplogruppi: uno che comprende gli aplotipi da H1 a H49, al quale afferiscono la gran parte dei
118
campioni, ed uno che presenta due individui caratterizzati dagli aplotipi H50 e H51, che sono separati dagli aplotipi del primo gruppo rispettivamente per 21 e 17 mutazioni.
Fig. 3.2: Network degli aplotipi riscontrati in A. amphitrite.
Tab. 3.3: Aplotipi della COI rilevati in A. amphitrite nei 15 campioni analizzati. MCA =
Montecarlo; GEN = Genova; LSA = La Spezia sito 1; LSM = La Spezia sito 2; VIA = Viareggio; LIV = Livorno; PFE = Portoferraio; CIV = Civitavecchia; OLB = Olbia; SIR = Siracusa; TAR = Taranto; ANC = Ancona; RAV = Ravenna; VEN = Porto Marghera; TRI = Trieste e TOT = totale. MCA GEN LSA LSM VIA LIV PFE CIV OLB SIR TAR ANC RAV VEN TRI TOT
H1 1 1 H2 1 1 H3 3 2 1 1 1 1 1 2 12 H4 1 1 H5 1 1 H6 1 1 H7 1 1 H8 1 1 1 1 1 1 1 1 8 H9 1 1 H10 1 1 H11 1 1 H12 1 1 2 H13 3 4 1 2 2 2 1 2 3 1 4 2 1 28 H14 1 1 H15 1 1
119
MCA GEN LSA LSM VIA LIV PFE CIV OLB SIR TAR ANC RAV VEN TRI TOT
H16 1 1 H17 1 1 1 1 1 2 1 1 1 10 H18 1 1 H19 2 1 1 1 1 2 1 9 H20 1 1 2 H21 1 1 H22 1 1 H23 1 1 H24 1 1 2 H25 1 1 H26 1 1 H27 1 1 1 1 4 H28 1 1 H29 1 1 H30 2 2 3 1 3 2 3 1 4 1 3 3 5 3 36 H31 1 1 H32 1 1 H33 1 1 H34 1 1 H35 1 1 H36 1 1 H37 1 1 H38 1 1 H39 1 1 2 H40 1 1 1 3 H41 1 1 H42 1 1 H43 1 1 H44 1 1 H45 1 1 H46 1 1 H47 1 1 H48 1 1 H49 1 1 H50 1 1 H51 1 1 TOT 10 10 11 10 11 11 11 11 10 10 10 11 10 10 11 157
Utilizzando la statistica Bayesiana sono stati costruiti due alberi filogenetici basati su tutte e 157 le sequenze di A. amphitrite e due diversi
120
outgroup. Questi alberi ci hanno permesso di indagare due tipi di relazioni: quella tra i diversi aplotipi di A. amphitrite e quella tra A. amphitrite e gli outgroup.
Nel primo caso (Fig. 3.3a) sono state usate come outgroup due sequenze di Balanus glandula ricavate da GenBank (numeri di accesso: HM029141.1 e HM029137.1). L’albero così ottenuto mostra un unico nodo significativo (100%), che raggruppa tutti gli aplotipi di A. amphitrite in un unico clade monofiletico, separato dalle 2 sequenze outgroup. Essendo però le sequenze di B. glandula molto più brevi delle nostre (386 bp in B. glandula contro le 585 bp del nostro studio), si crea un artefatto per il quale non è più possibile distinguere i nostri aplotipi gli uni dagli altri, essi infatti si riducono da 51 a 36. Questo dipende dal fatto che il programma MrBayes ver. 3.1.2 (Huelsenbeck & Ronquist, 2001; Ronquist & Huelsenbeck, 2003) analizza soltanto la parte di sequenza comune a tutti i campioni e perciò tralascia le mutazioni presenti nelle sequenze di A. amphitrite relative alle parti in cui esse non coincidono con quelle di B. glandula, ciò determina una riduzione degli aplotipi di A. amphitrite.
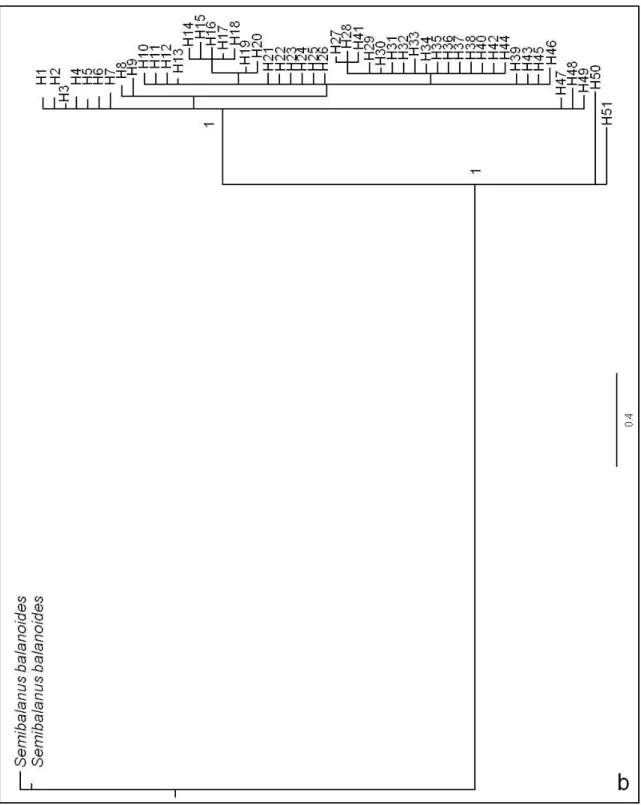
Per ovviare al problema sopra riportato è stato costruito un secondo albero filogenetico (Fig. 3.3b) in cui sono state utilizzate come outgroup due sequenze di Semibalanus balanoides anch’esse ricavate da GenBank (numeri di accesso: HM377485.1 e HM377487.1) e di lunghezza (658 bp) maggiore di quelle da noi impiegate (585 bp). Si può vedere come gli aplotipi di A. amphitrite anche in questo caso si discostino dai due outgroup rappresentati dalle due sequenze di Semibalanus balanoides inclusi nelle analisi. Infatti, solo 2 dei 9 nodi rappresentati in figura mostrano una probabilità a posteriori ≥ al 95%, indicando così l’affidabilità del nodo rappresentato. Questi risultano essere i nodi che comprendono tutti i campioni di Amphibalanus amphitrite (100%), ed i 2 aplotipi H50 e H51 (100%). Inoltre essendo le due sequenze outgroup più lunghe rispetto a quelle utilizzate in precedenza i nostri aplotipi non si accorpano fra di loro.
122
Fig. 3.3: Alberi basati sulla statistica Bayesiana delle relazioni filogenetiche esistenti tra gli
individui campionati e i due outgroup scelti. I numeri riportati sui rami rappresentano le probabilità a posteriori della veridicità di ciascun nodo; a) albero che include Balanus glandula come outgroup; b) albero che include Semibalanus balanoides come outgroup.
123
Per l’approfondimento dello studio della struttura genetica di Amphibalanus amphitrite è stato utilizzato un test di assegnazione basato sulla statistica Bayesiana. Il test ha messo in evidenza la presenza di 3 cluster genetici, che in Fig. 3.4 sono rappresentati da 3 colori diversi: giallo, celeste e marrone. Ogni riga del grafico rappresenta un individuo e le percentuali dei diversi colori la probabilità di appartenenza di ogni individuo ad un determinato cluster, nel caso in cui la probabilità di appartenenza ad un cluster sia inferiore a P = 0.05 l’assegnazione dell’individuo ad un cluster è incerta. Tutti gli individui eccetto 2 risultano assegnati ai cluster genetici di appartenenza con valori di probabilità compresi fra 0.6 < P < 1, mentre 2 individui, uno appartenente al campione di La Spezia (sito 1) ed uno al sito di Portoferraio, hanno assegnazione incerta (P < 0.05). Il cluster giallo è quello più diffuso, ad esso appartengono la maggior pare degli individui analizzati in tutti i siti. Anche il cluster celeste è presente in tutti i porti, fatta eccezione per il porto di Olbia, anche se con un numero nettamente inferiore di individui rispetto al cluster giallo. Infine 2 soli individui appartengono al cluster marrone e sono provenienti uno da Civitavecchia ed uno da Ravenna.
124
Fig. 3.4: Rappresentazione grafica dei risultati ottenuti con il test Bayesiano di assegnazione,
ogni singola riga rappresenta un individuo, mentre i 3 colori corrispondono ai 3 cluster individuati. Le percentuali dei colori rappresentano la probabilità che l'individuo appartenga al cluster identificato da quel colore. Con il simbolo * si mettono in evidenza gli individui la cui assegnazione è incerta (P<0.05). Mentre dai grafici a torta si può vedere la percentuale di appartenenza ai 3 cluster di tutti gli individui di una data località.
125
Per determinare come la variabilità genetica sia ripartita nei diversi livelli gerarchici è stata utilizzata l’analisi della varianza molecolare (AMOVA, Analysis of MOlecular VAriance) utilizzando l’intero dataset senza alcuna strutturazione, oppure considerando il livello gerarchico “per bacini” (Tab. 3.4) in cui i campioni vengono divisi fra i quattro bacini dei mari italiani (bacino ligure, bacino tirrenico, bacino ionico e bacino adriatico). Analizzando l’intero dataset senza alcuna strutturazione si nota che la varianza molecolare è totalmente attribuita (101.09%) al livello “entro porti”. In presenza della strutturazione “per bacini” la varianza viene nuovamente attribuita per intero al livello “entro porti” (101.16%). Inoltre, la varianza attribuita al livello "tra porti" nella prima analisi, ed ai livelli ”tra regioni” e “tra porti entro regioni” nella seconda, assumono valori negativi per motivi stocastici e, analogamente a quanto accade per i valori negativi di FST, devono essere interpretati come pari a 0.
Tab. 3.4: Risultati delle analisi della varianza molecolare (AMOVA) per i frammenti della COI di
A. amphitrite. Con il simbolo * si mettono in evidenza i valori risultati significativi (P<0.05) e con
** quelli altamente significativi (P<0.01).
Per verificare la presenza di isolamento da distanza (IBD, Isolation By Distance), è stato applicato un test di Mantel tra i valori di FST (Tab. 3.2), e quelli delle distanze nautiche minime per ciascuna coppia di campioni espressa in miglia nautiche (Tab. 3.5). È stato ottenuto un valore del coefficiente di Mantel pari a Z = -596.2459 con un valore di probabilità, P = 0.5227, che evidenzia l’assenza di isolamento da distanza (Fig. 3.5).
126
Tab. 3.5: Distanze nautiche minime tra le coppie di porti esaminati espresse in miglia marine.
MCA = Montecarlo; GEN = Genova; LSA = La Spezia sito 1; LSM = La Spezia sito 2; VIA = Viareggio; LIV = Livorno; PFE = Portoferraio; CIV = Civitavecchia; OLB = Olbia; SIR = Siracusa; TAR = Taranto; ANC = Ancona; RAV = Ravenna; VEN = Porto Marghera; TRI = Trieste.
127
3.2 COI in Styela plicata
3.2.1 Caratteristiche molecolari delle sequenze
Come in A. amphitrite anche per Styela plicata è stato selezionato il modello di sostituzione nucleotidica che meglio soddisfa i nostri dati. Questo è risultato essere HKY (Hasegawa et al., 1985) con le seguenti frequenze per ciascuna base nucleotidica: fA = 0.2154, fC = 0.1638, fG = 0.2136, fT = 0.4073.
Dallo studio delle sequenze aminoacidiche (Appendice VI) ricavate a partire dalle sequenze nucleotidiche (Appendice V) si è rilevata la presenza di 3 mutazioni non silenti. In particolare, in 81 sequenze ripartite fra tutti i campioni, eccetto quello di Montecarlo, gli aminoacidi alle posizioni 50 e 190, della sequenza aminoacidica, mutano da Isoleucina a Leucina. In 14 individui, comprendenti 9 individui del campione di Montecarlo, 1 di Portoferraio, 1 di Olbia, 1 di Siracusa e 2 di Taranto, troviamo un’altra mutazione non silente, Valina al posto di Isoleucina, alla posizione 93.
3.2.2 Diversità genetica entro i campioni
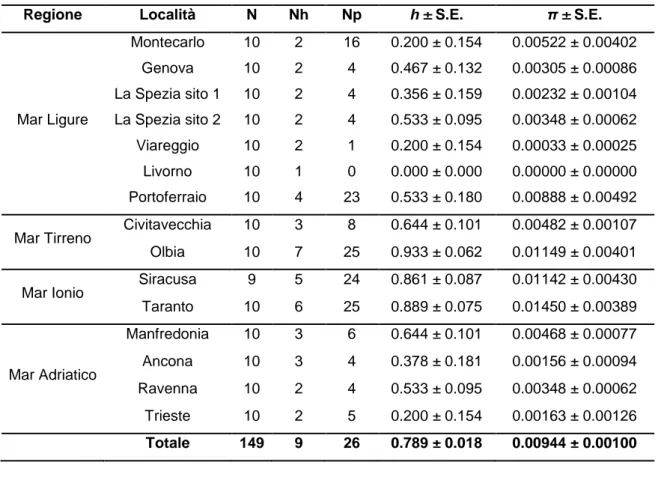
Nelle 149 sequenze analizzate abbiamo riscontrato la presenza di 9 aplotipi caratterizzati da 26 siti polimorfici (Tab. 3.6). Il porto in cui è presente il maggior numero di aplotipi è quello di Olbia in cui sono stati rilevati 7 dei 9 aplotipi trovati. La diversità aplotipica ha mostrato il valore più alto nel porto di Olbia, h = 0.933, mentre il valore più alto di diversità nucleotidica, π = 0.01450, è stato registrato nel porto di Taranto. I valori minimi per entrambi gli indici sono uguali a zero e caratterizzano il porto di Livorno, in cui le 10 sequenze analizzate corrispondono ad un unico aplotipo.
Oltre ad Olbia, i campioni con il maggior numero di aplotipi sono, in ordine decrescente, Taranto, Siracusa e Portoferraio, essi sono anche i porti in cui si riscontra la presenza di un maggiore numero di siti polimorfici (Fig. 3.6).
128
Tab. 3.6: Stime di diversità genica in S. plicata. N = numero di individui; Nh = numero di
aplotipi, Np = numero di siti polimorfici, h = diversità aplotipica e π = diversità nucleotidica, S.E. = errore standard.
Regione Località N Nh Np h ± S.E. π ± S.E.
Mar Ligure Montecarlo 10 2 16 0.200 ± 0.154 0.00522 ± 0.00402 Genova 10 2 4 0.467 ± 0.132 0.00305 ± 0.00086 La Spezia sito 1 10 2 4 0.356 ± 0.159 0.00232 ± 0.00104 La Spezia sito 2 10 2 4 0.533 ± 0.095 0.00348 ± 0.00062 Viareggio 10 2 1 0.200 ± 0.154 0.00033 ± 0.00025 Livorno 10 1 0 0.000 ± 0.000 0.00000 ± 0.00000 Portoferraio 10 4 23 0.533 ± 0.180 0.00888 ± 0.00492 Mar Tirreno Civitavecchia 10 3 8 0.644 ± 0.101 0.00482 ± 0.00107 Olbia 10 7 25 0.933 ± 0.062 0.01149 ± 0.00401 Mar Ionio Siracusa 9 5 24 0.861 ± 0.087 0.01142 ± 0.00430 Taranto 10 6 25 0.889 ± 0.075 0.01450 ± 0.00389 Mar Adriatico Manfredonia 10 3 6 0.644 ± 0.101 0.00468 ± 0.00077 Ancona 10 3 4 0.378 ± 0.181 0.00156 ± 0.00094 Ravenna 10 2 4 0.533 ± 0.095 0.00348 ± 0.00062 Trieste 10 2 5 0.200 ± 0.154 0.00163 ± 0.00126 Totale 149 9 26 0.789 ± 0.018 0.00944 ± 0.00100
129
Fig. 3.6: Istogrammi dei valori di a) numero degli aplotipi, b) diversità aplotipica (± errore
standard) e c) diversità nucleotidica (± errore standard), per ciascun porto considerato.
3.2.3 Diversità genetica tra i campioni
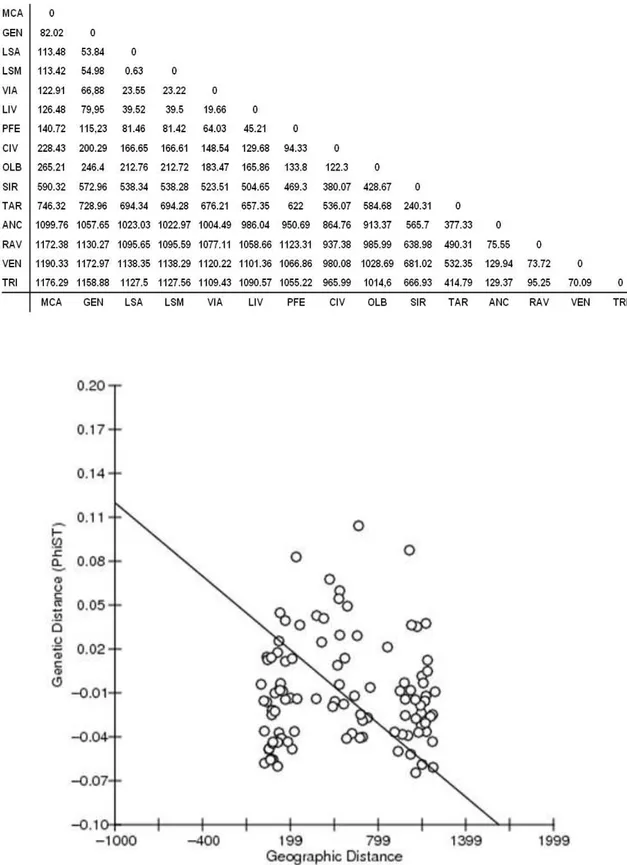
L’indice di fissazione (FST), rappresentato nella Tabella 3.7, è stato calcolato per ciascuna coppia delle località campionate. I valori negativi presenti possono essere interpretati come pari a 0. I valori risultanti dall’analisi variano da un massimo di FST = 0.913 per la coppia Montecarlo-Portoferraio, ad un minimo di FST = 0.007 per la coppia Olbia-La Spezia (sito 2). Inoltre, 13 coppie di valori risultano negative e possono quindi essere interpretate come 0.
Si può inoltre notare come parecchi FST risultino significativi sebbene siano di valore molto diverso: infatti fra questi si và da un massimo di 0.913 per
130
la coppia Montecarlo-Portoferraio, ad un minimo di 0.132 per la coppia Siracusa-Ancona.
Tab. 3.7: Indice di fissazione FST per ogni coppia di località, con il simbolo * si mettono in evidenza i valori risultati significativi (P<0.05). MCA = Montecarlo; GEN = Genova; LSA = La Spezia sito 1; LSM = La Spezia sito 2; VIA = Viareggio; LIV = Livorno; PFE = Portoferraio; CIV = Civitavecchia; OLB = Olbia; SIR = Siracusa; TAR = Taranto; MAN = Manfredonia; ANC = Ancona; RAV = Ravenna; TRI = Trieste.
Come in A. amphitrite le relazioni esistenti fra i vari aplotipi sono state identificate tramite la costruzione di un network con l’algoritmo Median-Joining. La Figura 3.7 mostra i 9 aplotipi trovati analizzando i campioni di S. plicata, di cui 2 privati: H5 appartenente a Portoferraio e H6 esclusivo del campione di Olbia. Altri 2 aplotipi risultano rari: H1 presente nel sito di Trieste, con 9 individui, ed in quello di Taranto con un unico individuo, H7 presente in 1 individuo del campione di Olbia ed in 1 di quello di Ravenna.
I restanti 5 aplotipi sono condivisi da campioni provenienti da molti dei siti analizzati. Va inoltre notato che tutti gli individui del campione di Livorno fanno parte dell’aplotipo H3, 9 individui di Viareggio e 9 di Montecarlo sono raggruppati rispettivamente nell’aplotipo H2 e nell’aplotipo H9. Mentre nell’aplotipo H4 sono raggruppati 7 individui del campione di Portoferraio.
Da Figura 3.7 si può inoltre notare la presenza di due aplogruppi separati fra loro da 16 mutazioni: uno che comprende gli aplotipi da H1 a H8, in cui sono compresi la gran parte dei campioni, ed uno che è rappresentato dagli individui presenti nell’aplotipo H9.
131
132
La distribuzione degli individui all’interno degli aplotipi è ben rappresentata in Tabella 3.8.
Tab. 3.8: Aplotipi della COI rilevati in S. plicata nei 15 campioni analizzati. MCA = Montecarlo;
GEN = Genova; LSA = La Spezia sito 1; LSM = La Spezia sito 2; VIA = Viareggio; LIV = Livorno; PFE = Portoferraio; CIV = Civitavecchia; OLB = Olbia; SIR = Siracusa; TAR = Taranto; ANC = Ancona; RAV = Ravenna; VEN = Porto Marghera; TRI = Trieste e TOT = totale.
MCA GEN LSA LSM VIA LIV PFE CIV OLB SIR TAR MAN ANC RAV TRI TOT
H1 1 9 10 H2 9 2 2 1 1 1 16 H3 7 2 6 1 10 1 5 2 2 2 5 1 4 48 H4 7 1 2 1 1 4 16 H5 1 1 H6 1 1 H7 1 1 2 H8 1 3 8 4 4 1 3 3 8 6 41 H9 9 1 1 1 2 14 TOT 10 10 10 10 10 10 10 10 10 9 10 10 10 10 10 149
L’albero filogenetico basato sulla statistica Bayesiana, è stato costruito utilizzando tutte e 149 le sequenze (Fig. 3.8); questa analisi ci ha permesso di identificare diversi tipi di relazioni: la prima tra i diversi aplotipi, l’altra tra gli aplotipi e le due sequenze di Styela clava ricavate da GenBank (numeri di accesso: HQ730800.1 e HQ730805.1) utilizzate come outgroup. Si può notare come gli aplotipi di Styela plicata si discostino dai due outgroup, rappresentati dalle due sequenze di Styela clava, inclusi nelle analisi. Infatti solo 2 dei 5 nodi rappresentati in Figura 3.8 mostrano avere una probabilità a posteriori ≥ al 95%, indicando così l’attendibilità del nodo rappresentato. Questi risultano essere i nodi che comprendono tutti i campioni di Styela plicata (100%), ed i 2 aplotipi H3 e H4 (97%), mentre i restanti due nodi non risultano attendibili a causa dei valori di probabilità a posteriori troppo bassi.
133
Fig. 3.8: Albero basato sulla statistica Bayesiana delle relazioni filogenetiche esistenti tra gli
individui campionati e i due outgroup scelti. I numeri riportati sui rami rappresentano le probabilità a posteriori della veridicità di ciascun nodo.
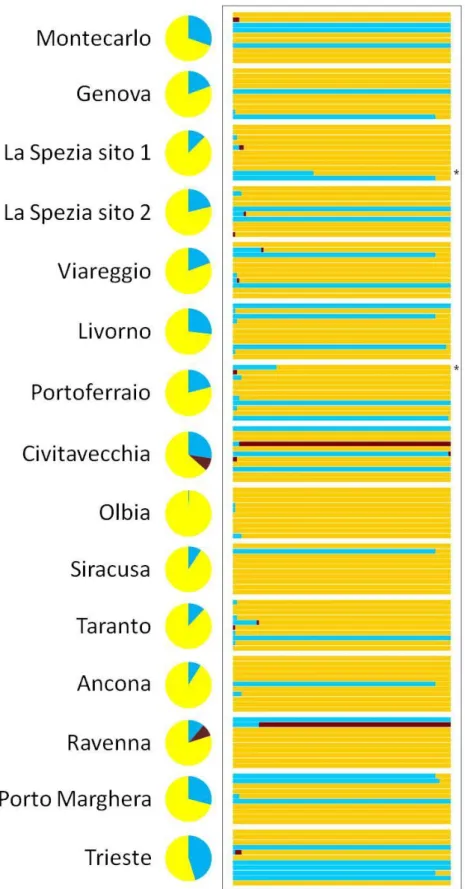
Per approfondire lo studio della struttura genetica di S. plicata è stato utilizzato un test di assegnazione basato sulla statistica Bayesiana. Il test ha individuato la presenza di 5 cluster genetici, che in Fig. 3.9 sono rappresentati da 5 colori diversi. Ogni riga del grafico rappresenta un individuo e le percentuali dei diversi colori la probabilità di appartenenza di ogni individuo ad un determinato cluster; nel caso in cui la probabilità di appartenenza ad un cluster sia inferiore a P = 0.05, l’assegnazione dell’individuo ad un cluster è incerta. Tutti gli individui tranne 1 risultano assegnati con valori di probabilità compresi fra 0.2 < P < 1 ai cluster genetici di appartenenza, mentre un individuo appartenente al campione di Portoferraio ha un’assegnazione incerta.
Il cluster giallo è rappresentato quasi totalmente da individui del campione di Montecarlo, mentre quello arancione è predominante nel campione di Trieste. Il cluster rosa rappresenta la quasi totalità degli individui di Portoferraio ed è diffuso nei campioni del Mar Tirreno, del Mar Ionio e del sud del Mare Adriatico. I cluster maggiormente rappresentati sono il blu ed il celeste, il primo rappresenta la totalità degli individui dei campioni di Viareggio e Livorno e la gran parte di quelli di Genova e La Spezia (sito 2) ed inoltre è presente in tutti gli altri campioni fatta eccezione per quello di Montecarlo. Il secondo cluster, invece, è predominante nei campioni di La Spezia (sito 1),
134
Ravenna ed Ancona ed inoltre è diffuso nel Mar Tirreno, nel Mar Ionio ed in altri tre campioni del Mar Ligure.
Fig. 3.9: Rappresentazione grafica dei risultati ottenuti con il test Bayesiano di assegnazione,
ogni singola riga rappresenta un individuo, mentre i 5 colori corrispondono ai 5 cluster individuati. Le percentuali dei colori rappresentano la probabilità che l'individuo appartenga al cluster identificato da quel colore. Con il simbolo * si mettono in evidenza gli individui la cui assegnazione è dubbia (P<0,05). Mentre dai grafici a torta si può vedere la percentuale di appartenenza ad ognuno dei 5 cluster degli individui di ciascuna località campionata.
135
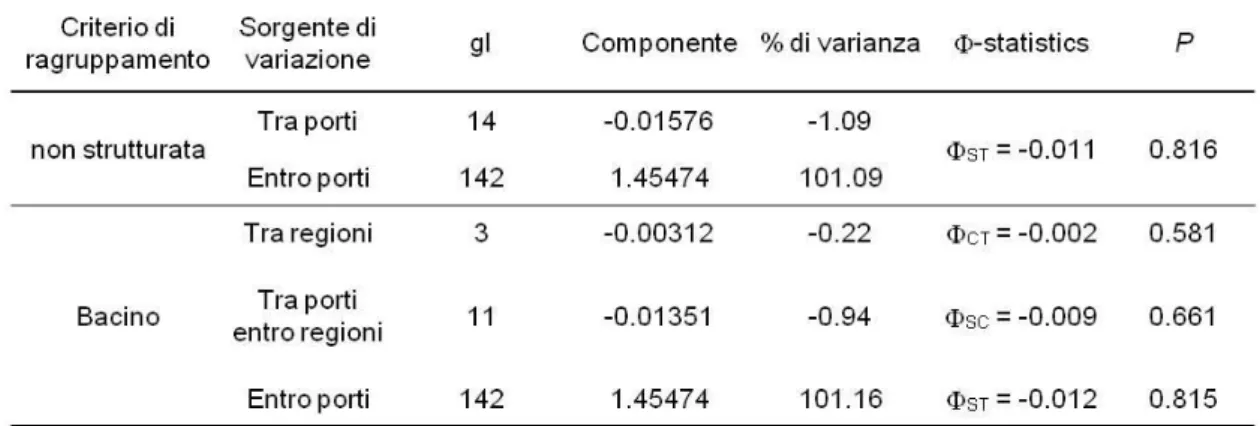
Per determinare come sia ripartita la variabilità genetica è stata utilizzata l’AMOVA, utilizzando l’intero dataset senza alcuna strutturazione, oppure imponendo una strutturazione per bacini (Tab. 3.9). Analizzando l’intero dataset senza alcuna strutturazione imposta si nota che una notevole percentuale di varianza molecolare (52.21%) è assegnata al livello “entro porti”. Imponendo la strutturazione “per bacini” la varianza viene ripartita in modo quasi uguale fra i livelli “tra porti entro regioni” (59.11%) ed “entro porti” (54.14%). Inoltre la varianza attribuita al livello "tra regioni", in quest'ultima ipotesi, assume valore negativo per motivi stocastici e, analogamente a quanto accade per i valori negativi di FST, può essere interpretata come pari a 0.
Tab. 3.9: Risultati delle analisi della varianza molecolare (AMOVA) per i frammenti della COI di
S. plicata. Con il simbolo * si mettono in evidenza i valori risultati significativi (P<0.05) e con **
quelli altamente significativi (P<0.01).
Per verificare la presenza di isolamento da distanza (IBD, Isolation By Distance) è stato applicato un test di Mantel tra i valori di FST (Tab. 3.7) e quelli delle distanze nautiche minime per ciascuna coppia di campioni espressa in miglia nautiche (Tab. 3.10). È stato ottenuto un valore del coefficiente di Mantel pari a Z = 20090.9252, con un valore di probabilità P = 0.6280, che evidenzia l’assenza di isolamento da distanza (Fig. 3.10).
136
Tab. 3.10: Distanze nautiche minime tra coppie di porti (miglia nautiche). MCA = Montecarlo;
GEN = Genova; LSA = La Spezia sito 1; LSM = La Spezia sito 2; VIA = Viareggio; LIV = Livorno; PFE = Portoferraio; CIV = Civitavecchia; OLB = Olbia; SIR = Siracusa; TAR = Taranto; ANC = Ancona; RAV = Ravenna; VEN = Porto Marghera; TRI = Trieste.
137
3.3 Confronto dei risultati di Styela plicata con studi pregressi
I risultati ottenuti per S. plicata nel presente lavoro sono stati confrontati con quelli ottenuti con lo stesso marcatore molecolare (COI) in due studi precedenti, che presentano un disegno di campionamento su scala spaziale assai più ampia (de Barros et al., 2009 e Pineda et al., 2011) (Fig. 3.11).
Fig. 3.11: Nella mappa sono messi in evidenza i porti campionati nei tre studi presi in esame. In
rosso quelli dello studio di de Barros et al. (2009), in verde quelli di Pineda et al. (2011) ed in bianco, nell’ingrandimento, quelli del presente studio. Il campione in giallo è comune agli studi di de Barros et al. (2009) e di Pineda et al. (2011).
Per confrontare i tre studi è stato costruito un network degli aplotipi con l’algoritmo Median-Joining contenente in totale 568 sequenze, tale da consentire il confronto fra i dati ottenuti nel presente lavoro e quelli ricavati da de Barros et al. (2009) e Pineda et al. (2011).
La Figura 3.12 mostra i 23 aplotipi a cui appartengono le sequenze analizzate: per facilitare la comprensione del network è stato attribuito un diverso colore a ciascun bacino di provenienza dei campioni. Dei 23 aplotipi trovati 14 risultano essere privati: H3, H4 e H13 appartengono a campioni dell’Oceano Pacifico; H7 è esclusivo del Mar Mediterraneo; H9, H10, H12, H17, H18, H19, H20, H21, H22 e H23 sono presenti solamente nell’Oceano
138
Atlantico. Dei restanti aplotipi quattro (H1, H11, H14 e H16) sono presenti in tutti i bacini mentre ciascuno degli altri cinque si osserva solo in 2 dei 4 bacini campionati.
Dei 23 aplotipi complessivamente rilevati dai tre studi, 22 erano già stati osservati da Pineda et al. (2011), mentre H7 è un nuovo aplotipo rappresentato da 1 individuo del nostro campione di Portoferraio. Inoltre, anche in questo network, come in quello basato sui nostri dati (Fig. 3.7) ed in quello di Pineda et al. (2011), si può notare la presenza di 2 aplogruppi, uno comprendente gli aplotipi che vanno da H1 ad H15 ed il secondo che contiene i rimanenti 8 aplotipi. Tali aplogruppi sono separati da 14 mutazioni e corrispondono a quelli del network di Figura 3.7 e di Pineda et al. (2011).
Fig. 3.12: Network complessivo degli aplotipi riscontrati in S. plicata in tre studi: presente
lavoro, de Barros et al. (2009) e Pineda et al. (2011).
L’intero dataset è stato quindi sottoposto ad un test di assegnazione basato sulla statistica Bayesiana. Il test ha individuato la presenza di 7 cluster genetici che in Figura 3.13 sono rappresentati da 7 colori diversi. Ogni riga del grafico rappresenta un individuo e le percentuali dei diversi colori la probabilità di appartenenza di ogni individuo ad un determinato cluster. Tutti gli individui risultano assegnati con valori di probabilità compresi fra 0.08 < P < 1 ai cluster genetici di appartenenza. Si può notare come il cluster giallo, che in Figura 3.10 era rappresentato quasi totalmente da individui del campione di Montecarlo, adesso includa campioni provenienti dall’Oceano Atlantico (San Fernando, North Carolina e Florianòpolis), dall’Oceano Pacifico (California, Manly e
139
Misaki) e dall’Oceano Indiano (Port Elizabeth). Il cluster arancione, al quale in Figura 3.10 appartengono solamente i campioni di Trieste, comprende ora: Arenis de Mar e Javea, 2 campioni provenienti dal Mar Mediterraneo; Ferrol nell’Oceano Atlantico; Knysna (Sud Africa) nell’Oceano Indiano; Sakushima Island ed Hong Kong nell’Oceano Pacifico. Il cluster rosa, che in Figura 3.10 includeva quasi esclusivamente campioni di Portoferraio, ora include anche una parte degli organismi di Manfredonia, di Javea (Mediterraneo) e di Knysna (Sud Africa). Infine il cluster blu, che corrisponde a quello del medesimo colore in Figura 3.10, è rappresentato quasi esclusivamente da campioni Mediterranei dello studio corrente.
140
Fig. 3.13: Rappresentazione grafica dei risultati ottenuti con il test Bayesiano di assegnazione:
ogni singola riga rappresenta un individuo mentre i 7 colori corrispondono ai 7 cluster individuati analizzando contemporaneamente tre studi: presente lavoro, de Barros et al. (2009) e Pineda et al. (2011).