Risultati delle Simulazioni
IV.1 INTRODUZIONE
La tecnica predistorsiva descritta nei capitoli precedenti, così come il sistema MC-CDMA e il generatore di traffico, sono stati implementati usando il linguaggio di programmazione C++ e hanno prodotto i risultati che saranno mostrati nel corso di quest’ultimo capitolo. Le prestazioni del sistema, verranno descritte utilizzando principalmente il diagramma IQ dei simboli in ingresso al decisore, la velocità di convergenza dell’algoritmo (in termini di valor assoluto dell’errore al variare del tempo) e la BER in funzione del rapporto segnale rumore. Verranno confrontate da principio le prestazioni del sistema MC-CDMA senza predistorsore nel caso di una costellazione 16 QAM, con quelle ottenute con predistorsore utilizzando tre diverse complessità.
Si analizzeranno poi delle simulazioni ottenute per una costellazione 4 QAM con valori di complessità corrispondenti alla 16 QAM e in base alle osservazioni su questi modelli si presenterà una soluzione alternativa per risolvere le problematiche incontrate. Le simulazioni sono state effettuate con un carico di lavoro che corrisponde allo scenario alto così come descritto nel Capitolo II e per diverse allocazioni. È stata considerata un
solo tipo di non linearità, l’amplificatore SSPA con modello di Rapp. Si rileveranno i passaggi fondamentali nella lettura dei grafici, e per ogni risultato, verranno forniti i parametri di ingresso al simulatore.
IV.2 PREDISTORSORE CON COSTELLAZIONE 16 QAM
Le simulazioni presentate in questo paragrafo sono state ottenute fornendo al programma i seguenti parametri d’ingresso, Fig. IV.1:
Tipo di modulazione utilizzata 16-QAM
Numero Utenti (Nu) 256
Numero di sottoblocchi di simboli di informazione (Ns) 1
Fattore di Spreading (L) 256
Numero di campioni per chip (NcIc) 8
Durata del filtro di trasmissione (Dur) 20
Roll-Off 0.125
Lunghezza prefisso ciclico 64
Fig. IV.1 – Parametri d’ingresso per costellazione 16 QAM
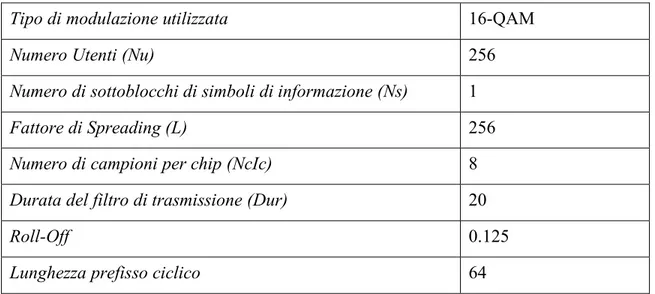
Per quanto riguarda l’allocazione dei codici, questa è guidata da file e il carico corrisponde al profilo di traffico alto. La prima simulazione è stata eseguita senza il predistorsore di simboli, per esaminare le prestazioni base di un sistema MC-CDMA, i risultati possono essere esaminati in Fig, IV.2:
10-5 10-4 10-3 10-2 10-1 BER 16 14 12 10 8 6 4 2 0 Eb/N0 (dB) Legenda - BER Teorica - BER Media
16 QAM Senza Predistorsore
Fig. IV.2 – Prestazioni MC-CDMA per 16 QAM senza predistorsore
La curva di BER del risultato in rosso rappresenta il valor medio delle BER assunte da ciascun canale attivo durante la simulazione, in nero invece si riporta il valore della curva teorica di BER di una costellazione 16 QAM. Come si vede la BER media del sistema, sebbene l’allocazione dei codici sia guidata in modo da ridurre la cross-correlazione tra i vari codici delle sequanze di spreading, non è sufficiente per consentire un uso del sistema MC-CDMA privo di un sistema di predistorsione che riduca l’effetto della non linearità introdotta dall’ HPA.
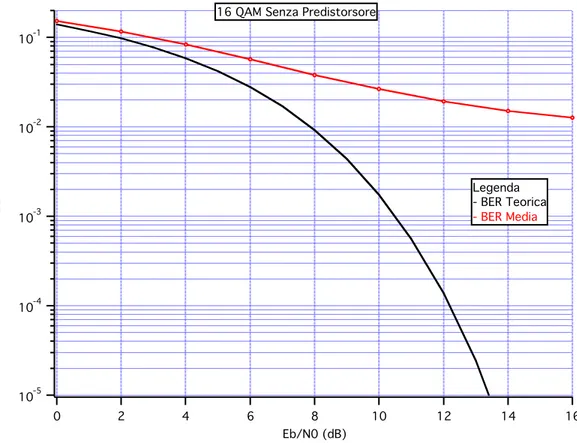
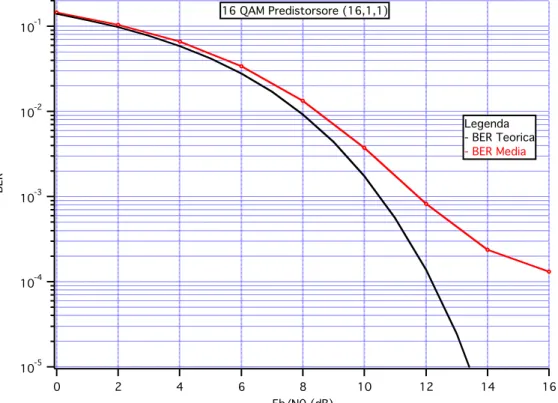
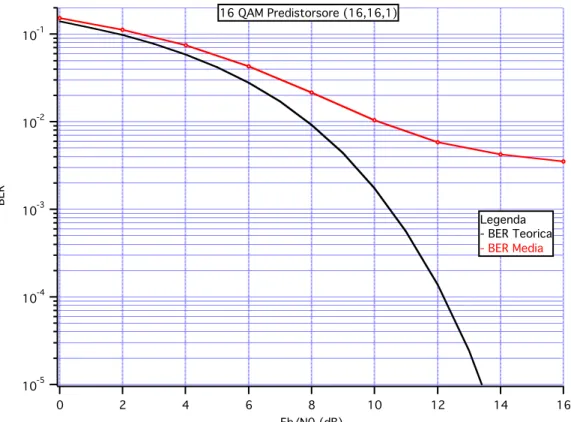
Si considerino adesso i risultati ottenuti sullo stesso sistema, con la stessa costellazione, ma con l’uso di una tecnica predistorsiva, con tre complessità diverse, Fig. IV.3-5:
10-5 10-4 10-3 10-2 10-1 BER 16 14 12 10 8 6 4 2 0 Eb/N0 (dB) Legenda - BER Teorica - BER media 16 QAM Predistorsore (1,1,1)
Fig. IV.3 – Prestazioni MC-CDMA per 16 QAM con predistorsore (1,1,1)
10-5 10-4 10-3 10-2 10-1 BER 16 14 12 10 8 6 4 2 0 Eb/N0 (dB) Legenda - BER Teorica - BER Media 16 QAM Predistorsore (16,1,1)
10-5 10-4 10-3 10-2 10-1 BER 16 14 12 10 8 6 4 2 0 Eb/N0 (dB) Legenda - BER Teorica - BER Media 16 QAM Predistorsore (16,16,1)
Fig. IV.5 – Prestazioni MC-CDMA per 16 QAM con predistorsore (16,16,1)
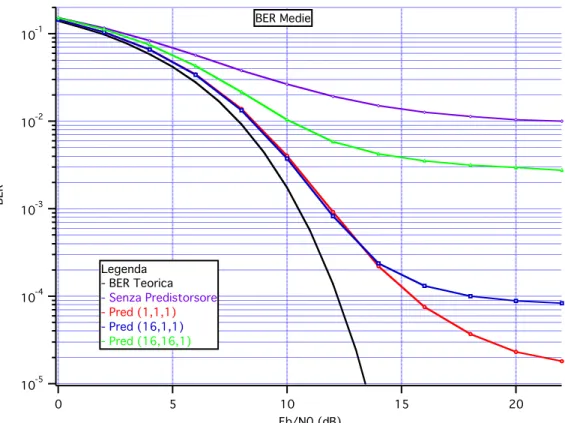
I risultati a complessità (1,1,1) e (16,1,1) rappresentano un netto miglioramento nelle prestazioni: si consideri che ad un valore di BER pari a 10!3 corrisponde una BER che dista dal valore teorico circa 2 dB nel primo caso e circa 1.5 dB nel secondo; inoltre i risultati vengono presentati a partire da una condizione iniziale di utenti pari a zero, pertanto l’evoluzione si riferisce ad un transitorio, tali valori di prestazioni rappresentano una dimostrazione dell’efficacia della tecnica predistorsiva nel caso critico di cella inizialmente scarica; invece nel caso a complessità più elevata (16,16,1) si trova un floor e l’andamento è più simile al caso senza predistorsione (seppur migliore).
Le precedenti osservazioni possono essere meglio comprese se si analizza la Fig. IV.6 che presenta le curve delle varie casistiche sovrapposte su un unico grafico:
10-5 10-4 10-3 10-2 10-1 BER 20 15 10 5 0 Eb/N0 (dB) Legenda - BER Teorica - Senza Predistorsore - Pred (1,1,1) - Pred (16,1,1) - Pred (16,16,1) BER Medie
Fig. IV.6 – Confronto BER Medie per 16 QAM
Con la tecnica di predistorsione, in ogni caso si guadagna rispetto ad un sistema non predistorto, il guadagno è maggiore a complessità inferiore rispetto ad una complessità superiore, come mai succede questo?
Aumentando la complessità del sistema, ci si aspetta che i fenomeni di warping e clustering diminuiscano e ci si avvicini verso una situazione in cui la dispersione dei simboli intorno alla costellazione nominale, si aggiri all’interno della soglia prefissata. Questo si verifica solo nei casi in cui l’algoritmo abbia tempi di convergenza abbastanza piccoli, ossia nei casi a complessità inferiore: in questo senso la migliore prestazione si ottiene proprio in corrispondenza del predistorsore (1,1,1); l’effetto di warping (ossia la traslazione del baricentro del cluster rispetto al punto nominale della costellazione) viene compensato, mentre rimane l’effetto di clustering che con una bassa complessità resta abbastanza evidente: questo si può vedere considerando le singole realizzazioni di ogni canale, la loro distribuzione si concentra in regioni più ampie rispetto al valor medio, al diminuire della complessità. Pertanto a complessità minori, il valor medio migliora, ma ci
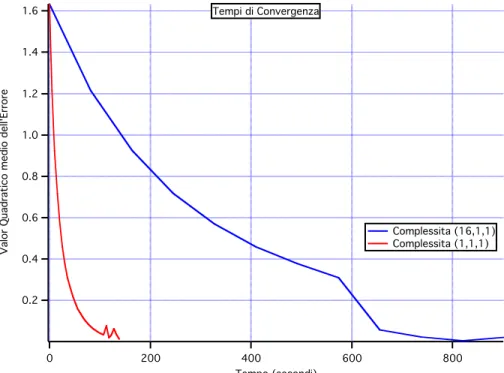
sono canali che vanno molto bene e canali che vanno molto male, invece al crescere della complessità il valor medio peggiora ma c’è una maggiore uniformità nei singoli canali. In conclusione gli effetti di warping e clustering si fanno più intensi nei casi in cui l’algoritmo di compensazione abbia tempi di convergenza alti: nel caso (16,16,1) il numero di simboli che viene trasmesso è lo stesso rispetto ai casi con complessità inferiori, ma il numero di equazioni iterative che devono essere aggiornate ad ogni ciclo è diverso; nel caso a complessità (1,1,1) le equazioni iterative sono solo 16, nel caso (16,1,1) sono 16*16= 256 e nel caso (16,16,1) sono 16*16*16=4096, pertanto la durata di un ciclo completo di aggiornamento delle equazioni iterative cresce al crescere della complessità, il risultato è che la velocità di convergenza dell’algoritmo si allunga e il traffico variabile cambia le impostazioni della cella ancor prima che essa arrivi ad una situazione di stabilità: l’algoritmo non ce la fa ad inseguire le variazioni del sistema. Questo può essere confermato dalla Fig. IV.7 in cui sono rappresentati i tempi di convergenza nei casi a complessità (1,1,1) e (16,1,1): si nota che l’error quadratico medio tende a zero molto più velocemente nel caso a complessità inferiore per i motivi sopra esposti. 1.6 1.4 1.2 1.0 0.8 0.6 0.4 0.2
Valor Quadratico medio dell'Errore
800 600 400 200 0 Tempo (secondi) Tempi di Convergenza Complessita (16,1,1) Complessita (1,1,1)
IV.3 PREDISTORSORE CON COSTELLAZIONE 4 QAM
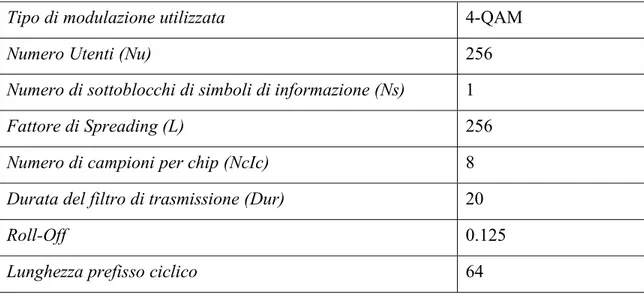
Le simulazioni presentate in questo paragrafo sono state ottenute fornendo al programma i seguenti parametri d’ingresso, Fig. IV.8:
Tipo di modulazione utilizzata 4-QAM
Numero Utenti (Nu) 256
Numero di sottoblocchi di simboli di informazione (Ns) 1
Fattore di Spreading (L) 256
Numero di campioni per chip (NcIc) 8
Durata del filtro di trasmissione (Dur) 20
Roll-Off 0.125
Lunghezza prefisso ciclico 64
Fig. IV.8 – Parametri d’ingresso per costellazione 4 QAM
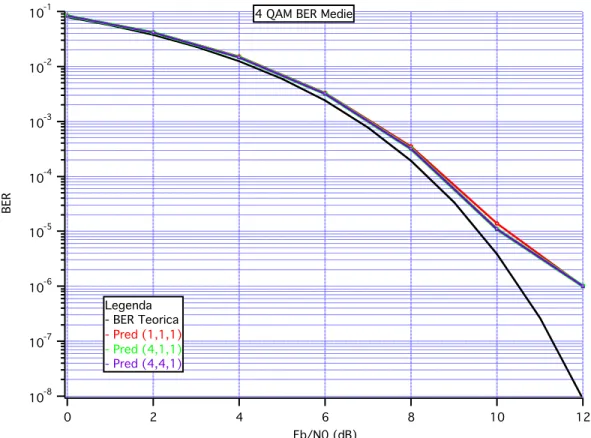
Le impostazioni sono le medesime del paragrafo IV.2 ad eccezione della costellazione che in questo caso è una 4 QAM. Si concentrerà l’interesse sulle simulazioni corrispondenti rispetto al caso precedente e dunque il predistorsore verrà usato a complessità (1,1,1) (4,1,1) e (4,4,1), nella Fig. IV.9 sono rappresentati i risultati delle simulazioni sotto forma di BER medie:
10-8 10-7 10-6 10-5 10-4 10-3 10-2 10-1 BER 12 10 8 6 4 2 0 Eb/N0 (dB) Legenda - BER Teorica - Pred (1,1,1) - Pred (4,1,1) - Pred (4,4,1)
4 QAM BER Medie
Fig. IV.9 – Confronto BER Medie per 4 QAM
In questo caso le curve si trovano abbastanza sovrapposte: essendo la costellazione più piccola di un fattore 4 anche le complessità corrispondenti si riducono di molto infatti nel caso (1,1,1) le equazioni iterative saranno 16, nel caso (4,1,1) saranno 16*4=64 e nel caso (4,4,1) saranno 16*4*4=256 pertanto a livello di complessità di calcolo non si supera il caso (16,1,1) che già di per sé forniva risultati accettabili di BER.
Tuttavia si vuol trovare un tipo di simulatore che concentri gli aspetti positivi di una complessità elevata (la riduzione del clustering) insieme agli aspetti positivi di una complessità bassa (riduzione del warping con tempi di convergenza piuttosto bassi), il tutto cercando di ridurre l’onere di calcolo nel caso delle equazioni iterative.
Per considerare tutti questi aspetti nasce una nuova versione del sistema di trasmissione con un nuovo algoritmo che è stato chiamato Versione Fast.
IV.4 ALGORITMO FAST
L’algoritmo fast nasce dall’esigenza di ottenere un sistema giù snello dal punto di vista computazionale e che allo stesso tempo superi i problemi presentati dalla versione base dello stesso algoritmo; le idee che stanno alla base di questo nuovo procedimento sono sostanzialmente tre:
1) Considerando l’uso di modulazioni M-QAM, si può sfruttare la simmetria tipica di questa costellazione per ridurre di un fattore 4 la complessità delle equazioni iterative: i simboli che devono essere predistorti, vengono riportati tutti nel primo quadrante, il predistorsore tratta una costellazione estesa che risulta ridotta di un fattore 4, predistorce il simbolo e solo dopo che il simbolo è stato predistorto, viene contro-ruotato per essere riportato al suo quadrante iniziale. Ovviamente, la riduzione di un fattore 4, da una parte riduce la complessità computazionale dell’algoritmo ma dall’altra esclude completamente tutte quelle modulazioni che non godono della proprietà di simmetria rispetto ai quadranti dell’asse cartesiano (la PSK ad esempio, che invece era prevista nella versione base dell’algoritmo).
2) Come punto di riferimento per l’algoritmo di predistorsione si prende la complessità che garantisce valori medi migliori, ossia la (1,1,1), pertanto la velocità di convergenza dell’algoritmo è garantita: si raggiunge in tempi buoni una condizione secondo la quale gli M cluster della costellazione M QAM si trovano entro soglia.
3) Laddove sia possibile e le condizioni di traffico lo permettano, una volta che si è risolto il problema della convergenza, si va ad agire sul clustering. Questa procedura si realizza prevedendo un sistema di predistorsione a marce: quelle che nella versione base dell’algoritmo venivano chiamate “complessità” ed erano scelte all’inizio e non potevano essere cambiate durante una simulazione, in
questa nuova versione Fast, sono compresenti e possono essere cambiate qualora si realizzino le condizioni adatte: quando un utente entra, la priorità del sistema deve essere quella di farlo convergere in un tempo breve (il minore possibile) verso il valore nominale della costellazione (e questo è garantito dal punto 2), una volta che si sia raggiunta tale condizione, l’algoritmo prevede il passaggio di complessità: una volta compensato l’effetto di warping, ci si occupa di quello di clustering, si aumenta la marcia, si passa alla complessità immediatamente superiore.
Che cosa succede praticamente? L’utente che entra viene trattato come se fosse in presenza di un predistorsore (1,1,1) in questo modo il baricentro del cluster viene portato a coincidere con il valore nominale della costellazione; a questo punto si possono verificare due eventi: o entra un nuovo utente pertanto questo viene trattato secondo il solito sistema oppure non entra nessuno, in tal caso il sistema ha la possibilità di affinare la sua compensazione del clustering: il cluster relativo ad un punto viene spezzato in quattro sotto-cluster e ciascuno di essi viene fatto di nuovo convergere al punto nominale, in pratica si realizza il cambiamento di complessità da (1,1,1) a (4,1,1).
Il procedimento prosegue e laddove ce ne sia la possibilità passa ad un’ulteriore complessità (16,1,1) e così via fino alla complessità massima (16,16,16).
C’è un ultimo fattore da prendere in considerazione: se l’allocazione è guidata, i tempi di convergenza in media sono migliori, laddove invece l’allocazione non sia guidata ma random, talvolta gli interferenti possono portare il sistema in condizioni critiche per cui si raggiunge la zona di saturazione dell’amplificatore: in tal caso il predistorsore continua ad aumentare la potenza d’ingresso dei simboli senza tuttavia riuscire a compensare la distorsione: iterando più volte tale processo, si può arrivare a dei valori di potenza troppo elevati per certi utenti e tali valori elevati potrebbero danneggiare utenti vicini che invece hanno valori di potenza più ragionevoli.
Per questo motivo è necessario dotare questo sistema di un meccanismo di controllo che mantenga la potenza a livelli accettabili: il meccanismo di controllo che si è pensato di attuare per l’algoritmo Fast prevede un numero di cicli massimi per ciascuna marcia,
possono in realtà non esserlo) e si incrementa la marcia alla complessità immediatamente successiva. Infine le marcie sono disposte secondo una tabella, dalla meno complessa alla maggiore complessità, tramite una griglia si possono decidere quali marcie utilizzare e quali merce saltare.
IV.5 RISULTATI DELLE SIMULAZIONI CON ALGORITMO
FAST
Nel presente capitolo verranno mostrati i risultati delle simulazioni con l’algoritmo fast. Nel caso dell’algoritmo fast le simulazioni sono state eseguite per una costellazione 16 QAM nel caso di IBO=3 e IBO=4; i risultati vengono espressi anche in questo caso in termini di BER.
Le Fig. IV.10-13 rappresentano le curve di BER per varie realizzazioni:
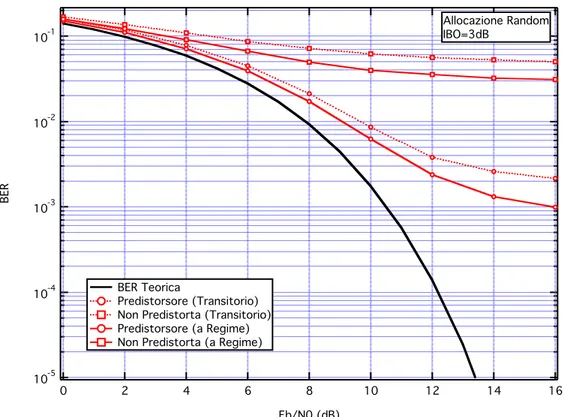
10-5 10-4 10-3 10-2 10-1 BER 16 14 12 10 8 6 4 2 0 Eb/N0 (dB) BER Teorica Predistorsore (Transitorio) Non Predistorta (Transitorio) Predistorsore (a Regime) Non Predistorta (a Regime)
Allocazione Random IBO=3dB
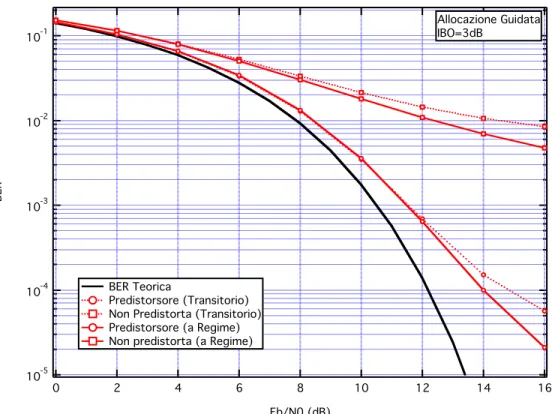
10-5 10-4 10-3 10-2 10-1 BER 16 14 12 10 8 6 4 2 0 Eb/N0 (dB) BER Teorica Predistorsore (Transitorio) Non Predistorta (Transitorio) Predistorsore (a Regime) Non predistorta (a Regime)
Allocazione Guidata IBO=3dB
Fig. IV.11 – Allocazione Guidata IBO=3 dB
10-5 10-4 10-3 10-2 10-1 BER 16 14 12 10 8 6 4 2 0 Eb/N0 (dB) BER Teorica Predistorsore (Guidata) Predistorsore (Random) Non Predistorta (Random) Non Predistorta (Giudata)
Transitorio IBO=3dB
10-5 10-4 10-3 10-2 10-1 BER 16 14 12 10 8 6 4 2 0 Eb/N0 (dB) BER Teorica Predistorsore (Random) Predistorsore (Guidata) Non Predistorta (Random) Non Predistorta (Guidata)
A Regime IBO=3dB
Fig. IV.13 – regime IBO=3dB
Osservando le curve di BER si può notare che senza predistorsore l’allocazione Guidata va meglio rispetto alla Random (sia in Transitorio che a Regime), pertanto solo con il metodo di allocazione che minimizza la cross-correlazione dei codici delle sequenze di spreading si può ottenere un miglioramento delle prestazioni. La situazione migliora ulteriormente se si aggiunge la tecnica di predistorsione con algoritmo fast; infine, i metodi che garantiscono le prestazioni migliori sono quelli che utilizzano sia l’allocazione guidata che la predistorsione, in tal caso, ad esempio, si riesce ad ottenere un valore di BER di 10!3 con valori di rapporto segnale-rumore che si distaccano di circa
1.5 dB dal valore di BER Teorica, questo significa che si riesce ad ottenere buone prestazioni (si trasmette sbagliando a decidere un simbolo su 1000) utilizzando un Eb/N0 di solo 1.5 dB superiore rispetto al caso teorico.
I risultati vengono confermati e migliorati se si utilizza un IBO un po’ più favorevole; le
Fig. IV.14-17 descrivono l’andamento delle simulazioni corrispondenti ai casi precedenti
10-7 10-6 10-5 10-4 10-3 10-2 10-1 BER 15 10 5 0 Eb/N0 (dB) BER Teorica Predistorsore (a Regime) Non Predistorta (a Regime) Predistorsore (in Transitorio) Non Predistorta (in Transitorio)
Allocazione Random IBO = 4 dB
Fig. IV.14 – Random IBO=4 dB
10-7 10-6 10-5 10-4 10-3 10-2 10-1 BER 15 10 5 0 Eb/N0 (dB) BER Teorica Predistorsore (A Regime) Non Predistorta (A Regime) Predistorsore (in Transitorio) Non Predistorta (in Transitorio)
Allocazione Guidata IBO = 4 dB
10-7 10-6 10-5 10-4 10-3 10-2 10-1 BER 15 10 5 0 Eb/N0 (dB) BER Teorica Predistorsore (Random) Predistorsore (Guidata) Non Predistorta (Random) Non Predistorta (Guidata)
Transitorio IBO = 4 dB
Fig. IV.16 – Transitorio IBO= 4dB
10-7 10-6 10-5 10-4 10-3 10-2 10-1 BER 15 10 5 0 Eb/N0 (dB) BER Teorica Predistorsore (Random) Predistorsore (Guidata) Non Predistorta (Random) Non predistorta (Guidata)
A Regime IBO = 4 dB
Si nota che in questo caso che si riescono ad ottenere prestazioni uguali alle precedenti ad IBO=3 dB con meno di 1 dB di differenza rispetto al caso teorico.
Si analizza ora l’effetto di warping: . 2.8 2.6 2.4 2.2 2.0 1.8 1.6 1.4 1.2 1.0 0.8 0.6 0.4 0.2 0.0 V al or M ed io d el l'E rr or e 12.0 11.0 10.0 9.0 8.0 7.0 6.0 5.0 4.0 3.0 2.0 1.0 0.0 x103 Errore Medio Primo utente Secondo utente Terzo utente Quarto utente Tempo di Convergenza (in Transitorio)
Fig. IV.18 – Analisi dell’errore nel transitorio
La Fig. IV.18 descrive l’andamento del valore assoluto di ErrMod al variare del tempo (espresso in millisecondi) durante la trasmissione del primo milione di simboli in una cella in fase di transitorio: in nero si rappresenta il valor medio di tutti gli utenti attivi, in rosso il primo utente che entra, in blu il secondo, in verde il terzo e in giallo il quarto. Si nota che l’algoritmo ha tempi di convergenza buoni: il primo utente che entra, pur essendo da solo, riesce ad arrivare ad una condizione sotto soglia in meno di 1 millisecondo dopodichè a causa dell’alto PAPR si mette ad oscillare intorno ad un valor medio. In conseguenza dell’ingresso del secondo utente si ha un miglioramento che porta il valor medio dell’errore ancora più vicino a zero, l’ingresso del secondo utente con un codice scelto in modo da minimizzare la cross-correlazione delle sequenze di spreading
L’ingresso del terzo utente fa rilevare una momentanea crescita dell’errore che viene prontamente compensata riportando il sistema alla complessità minima, che garantisce tempi di convergenza brevi. Lo stesso avviene con l’ingresso del quarto utente.
Si analizza adesso lo stesso tipo di grafico per una cella nello stadio di Regime: Fig.
IV.19. 0.6 0.5 0.4 0.3 0.2 0.1 0.0
Valor Medio dell'Errore
30x103 25 20 15 10 5 0 tempo (msec)
Fig. IV.19 - Analisi dell’errore a regime
Anche nel caso a regime si può notare come l’algoritmo faccia tendere velocemente a zero il valore assoluto del modulo dell’errore: in figura si nota il valor medio in nero mentre le barre verticali in verde notificano l’ingresso o l’uscita di un utente; si vede che in conseguenza dell’ingresso o dell’uscita di un utente l’errore tende a salire inizialmente per poi stabilizzarsi in breve tempo nei passi successivi, questo significa che si sta compensando l’effetto di warping e quello di clustering.
Infine in Fig. IV.20-25 si possono apprezzare i miglioramenti apportati alla costellazione predistorta con il variare delle marce: i Diagrammi IQ mostrano i cluster dei simboli ricevuti; si vede come nelle prime marce i simboli siano affetti da warping e da
clustering, aumentando la complessità il warping viene presto compensato mentre il clustering permane; aumentando ancora fino alle complessità massime si ha una sensibile diminuzione anche dell’effetto di clustering.
Si è pertanto raggiunto lo scopo che ci si era prefissati nel confrontare le prestazioni tra la versione base e quella fast, ossia garantire le prestazioni della complessità minima del base andando ad agire, dove possibile, anche sul clustering.
-3 -2 -1 0 1 2 3 Quadratura -3 -2 -1 0 1 2 3 Fase
Simboli Ricevuti (Prima Marcia)
Fig. IV.20 – Diagramma IQ Prima Marcia
-3 -2 -1 0 1 2 3 Quadratura 3 2 1 0 -1 -2 -3 Fase
Simboli Ricevuti (Seconda Marcia)
-3 -2 -1 0 1 2 3 Quadratura 3 2 1 0 -1 -2 -3 Fase
Simboli Ricevuti (Terza Marcia)
Fig. IV.22 – Diagramma IQ Terza Marcia
3 2 1 0 -1 -2 -3 Quadratura 3 2 1 0 -1 -2 -3 Fase
Simboli Ricevuti (Quarta Marcia)
-3 -2 -1 0 1 2 3 Quadratura -3 -2 -1 0 1 2 3 Fase
Simboli Ricevuti (Quinta Marcia)
Fig. IV.24 – Diagramma IQ Quinta Marcia
-3 -2 -1 0 1 2 3 Quadratura 3 2 1 0 -1 -2 -3 Fase
Simboli Ricevuti (Sesta Marcia)
IV.6 CONCLUSIONI
Nella presente trattazione sono state analizzate e valutate le prestazioni per due differenti tecniche predistorsive (la versione base e la versione fast) pensate per compensare le non-linearità introdotte nei sistemi MC-CDMA da parte degli amplificatori di potenza, in condizioni critiche di carichi di traffico.
In ogni caso le prestazioni hanno dimostrato che si ha un netto miglioramento dei valori di probabilità di errore sui bit: sia che si usi la tecnica base, sia che si usi la versione fast; inoltre, l’allocazione dei codici è una variante non trascurabile nella valutazione delle prestazioni: si vede infatti che l’allocazione guidata dei codici rappresenta in ogni circostanza un miglioramento rispetto al caso in cui i codici vengano assegnati in maniera casuale (a parità di tecnica predistorsiva).
Inoltre mentre nella versione base dell’algoritmo di predistorsione, all’aumentare della complessità diminuisce la velocità di convergenza, l’algoritmo fast è stato pensato soprattutto per ovviare a tale inconveniente; pertanto la versione base riesce a compensare lo warping solo se utilizzata a bassa complessità, la verisone fast invece non solo migliora le prestazioni medie del sistema (pertanto compensa il fenomeno di warping in modo se non uguale, migliore) ma riesce ad andare ad agire anche sull’effetto di clustering laddove ve ne sia la possibilità (con il sistema “a marce”).
Tutte le simulazioni sono state eseguite concordemente al caso peggiore ossia si è previsto un profilo di traffico alto che cambiasse le impostazioni della cella nella maniera più critica possibile e anche in tal caso l’algoritmo fast ha presentato dei tempi di convergenza validi ed una discreta dinamicità nel conformarsi volta per volta al nuovo stato della cella.
Inoltre si è studiato il comportamento della cella in due situazioni tipiche di traffico: quella a regime e quella in transitorio; la situazione a regime serve per descrivere la cella durante il suo normale funzionamento, ossia si è previsto che la cella fosse carica al 12.5% delle sue capacità e si è dimostrato che i risultati così ottenuti, in presenza di un traffico variabile sono concordi ai risultati ottenuti nei casi di traffico statico (ossia in cui gli utenti sono presenti in un certo numero dall’inizio alla fine della finestra temporale
entro la quale si osserva la cella, senza possibilità di entrare od uscire). Si è sottoposto la cella ad un caso ancora più critico: uno stato di transitorio in cui la cella inizialmente è scarica e gli utenti compaiono di volta in volta fino a riempirla, anche in queste circostanze, particolarmente sfavorevoli soprattutto per quanto riguarda il valore del PAPR che, come si è visto, diminuisce all’aumentare degli utenti, si riescono ad ottenere prestazioni soddisfacenti anche se ovviamente peggiori rispetto al caso a regime, anche laddove il traffico sia intenso.
Infine si è potuto notare l’indipendenza della tecnica di predistorsione da quella di allocazione guidata delle risorse: entrambe rappresentano un miglioramento rispetto ai rispettivi casi senza predistorsione e con allocazione random, in particolare però le migliori prestazioni si sono ottenute integrando entrambe le strategie.
Infine i risultati sono stati comprovati a differenti valori di IBO e anche in essi si può trovare una coerenza: le prestazioni, a parità di tecnica, migliorano sensibilmente all’aumentare dell’IBO, e ciò è ovvio in quanto l’aumento dell’IBO implica una maggiore lontananza dalla zona di saturazione dell’amplificatore di potenza, pertanto i simboli subiscono distorsioni minori e si ottengono migliori prestazioni.