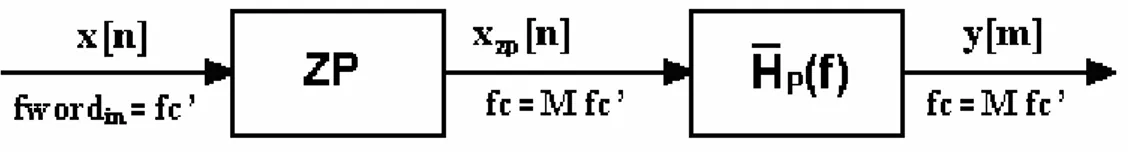Capitolo 2
Elaborazione di un segnale audio digitale
2.1 Architetture studiate
In questo capitolo vedremo in dettaglio come deve essere strutturato un amplificatore che lavora in modo digitale se vogliamo garantisca buone prestazioni dal punto di vista della distorsione del segnale di uscita e del rendimento. Lo schema più semplice tra quelli presi in esame prevede l’utilizzo di un segnale PWM a due livelli e di un’amplificazione in classe D.
Nome Tecnologia PWM Dead Time Reazione
AD digitale 2 livelli si -
AD1 mista 2 livelli no PEDEC analogico
AD2 digitale 2 livelli si DTC
AD3 digitale 3 livelli si -
Tabella 2.1: Caratteristiche delle architetture prese in esame
La altre due architetture con modulatore a due livelli sono state disegnate aggiungendo un controllo reazionato per limitare l’influenza dei disturbi introdotti dallo stadio di potenza; in particolare sono stati studiati due tipi diversi di controlli, uno analogico (PEDEC,[6]) ed uno digitale (Dead Time Compensator (DTC),[9]). A queste
architetture da studiare ne è stata infine aggiunta una quarta, che si rifà alla DDX brevettata dalla Apogee [1], caratterizzata dall’assenza di reazione e dall’utilizzo di un modulatore PWM a tre livelli.
Nello studio e nella progettazione dei quattro diversi tipi di amplificatori si ipotizza che essi ricevano in ingresso un segnale binario a 16 bit, nel quale ogni parola rappresenta senza segno l’ampiezza di un campione del segnale audio originario, campionato ad una frequenza di 44.1 kHz e supposto non negativo.
Per comodità abbiamo deciso di dare dei nomi alle diverse architetture presi in esame: AD, AD1, AD2 e AD3; le loro caratteristiche sono riassunte nella Tabella 2.1 e gli schemi a blocchi sono mostrati in Figura 2.1.
Figura 2.1: Schemi a blocchi delle architetture proposte
Dalla Figura 2.1 si vede chiaramente che tutte le architetture sono strutturate allo stesso modo fino al modulatore, mentre da quel punto in poi si distinguono a seconda della
modulazione e del tipo di controllo reazionato adoperato. In questo capitolo quindi, dopo una breve panoramica dei principali metodi di misurazione della qualità di un amplificatore audio, prenderemo in esame tutti i blocchi fino al modulatore compreso, in modo da capire che utilità hanno, come funzionano e come li abbiamo simulati in MATLAB.
2.2 Misura del segnale audio
Diciamo innanzitutto che sebbene le misure da noi utilizzate ci permettano di capire la bontà di un amplificatore rispetto ad un altro, non ci danno però un’idea esatta della qualitá di percezione del suono prodotto. Per sapere cioè con esattezza se e quanto il suono che esce da un amplificatore sia “migliore”di un altro per chi ascolta, sono stati sviluppati degli algoritmi che utilizzano particolari modelli psico-acustici [18], grazie ai quali è possibile stimare la qualitá percettiva dei suoni. Noi non tratteremo tali algoritmi, ma ci limiteremo ad utilizzare le classiche misure che servono anche per la valutazione della qualitá dei dispositivi audio. Vediamo le principali.
Spettro e Fast Fourier Transform (FFT)
La FFT trasforma un segnale dal dominio del tempo a quello della frequenza. Solitamente la FFT è utilizzata per ottenere lo spettro di un segnale dato, come ad esempio quello di uscita di un amplificatore.
Nel nostro caso la FFT è stata calcolata da MATLAB ed i valori cosí generati sono stati utilizzati per ottenere lo spettro in potenza del segnale di uscita, ossia per conoscere l’entità -espressa in Watt- delle componenti del segnale audio alle diverse frequenze.
Risposta in frequenza
La risposta in frequenza è misurata applicando in ingresso all’amplificatore un segnale di frequenza variabile e misurando l’ampiezza del segnale di uscita. in corrispondenza di
ogni valore di frequenza del segnale di ingresso; solitamente poi questi valori vengono riferiti a quello ottenuto a frequenza 1 kHz e sono quindi espressi in dB.
Dalla risposta in frequenza si ricava la larghezza di banda, che indica l’intervallo di frequenze in corrispondenza del quale si ha una risposta superiore a -3 dB.
Distorsione Armonica Totale (THD)
La THD (Total Harmonic Distortion) è data dall’espressione:
2 1 2 2 V V THD N i
∑
= (2.1)dove N è il numero di armoniche considerate e dipende ovviamente dalla banda di frequenza presa come riferimento. In pratica la THD è una stima dell’entità delle componenti spettrali indesiderate multiple della fondamentale, rispetto alla fondamentale stessa. La THD è un importante parametro per stabilire la bontà di un amplificatore in quanto è legata alle non linearità presenti all’interno dell’amplificatore stesso.
THD+Noise
Talvolta si misura il THD+N invece della semplice THD. In questo modo si include tra le componenti spettrali indesiderate non solo quelle a frequenza multipla della fondamentale (relative alla distorsione armonica), ma anche tutte le altre presenti nella banda di frequenza considerata.
Power Supply Rejection Ratio (PSRR)
La PSRR misura l’influenza che un’alimentazione mal regolata sull’ampiezza del segnale di uscita. Questo valore viene ottenuto dal rapporto (espresso in dB) tra l’ampiezza della perturbazione sovrapposta all’alimentazione e l’uscita dell’amplificatore.
2.3 Sovracampionamento
2.3.1 A cosa serve
Il sovracampionamento (oversampling) consiste nella generazione di un numero maggiore di campioni nell’unità di tempo a partire da quelli a disposizione, relativi ad una forma d’onda che è stata giá registrata in forma digitale. Come vedremo tra poco uno dei maggiori vantaggi che comporta il sovracampionamento di un segnale sta nell’ alleggerimento del disegno del filtro passa basso a valle dell’amplificatore audio, utilizzato per la ricostruzione del segnale. Un’altra importante ragione che spinge all’utilizzo del blocco di sovracampionamento è la possibilità di realizzare un Noise
Shaping (Par.2.5) efficace: aumentando la frequenza di campionamento infatti riusciamo
a distribuire come vogliamo la potenza del rumore generato dalla riduzione della profondità di bit, diminuendola in banda audio ed aumentandola tra questa e fC/2; questo permette di ridurre il numero di bit per campione lasciando quasi inalterato il rapporto segnale rumore. Come vedremo al Par.2.4 infine, una maggior frequenza di campionamento permette al cross-point deriver di effettuare con maggiore precisione la predistorsione del segnale digitale.
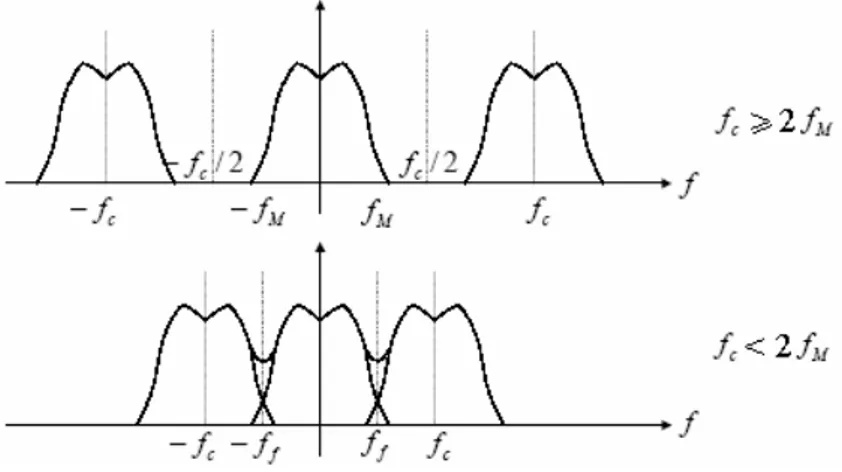
Figura 2.2: Spettro di un segnale sinusoidale di 1 kHz campionato a 44.1 kHz
Il segnale in ingresso all’amplificatore consiste in campioni audio digitali -cioè numeri- che entrano con la frequenza di 44.1 kHz, la stessa con la quale è stato campionato il segnale audio di partenza e con la quale sono stati registrati.
Il problema di fondo quando si campiona il segnale audio è che lo spettro del segnale campionato è caratterizzato non solo dalle componenti in banda audio, che si estende da
0 a 20 kHz, ma anche da ripetizioni (alias) di questo spettro intorno alle frequenze multiple della frequenza di campionamento (Figura 2.2).
Indichiamo con fM la frequenza massima del segnale campionato, con fC la frequenza di campionamento e con fN la frequenza di Nyquist,che vale 2⋅fM; utilizzando una fC che non rispetti la disuguaglianza (Th.Shannon)
N M
C f f
f ≥ 2 =
si verifica una sovrapposizione delle alias (aliasing) e in questo modo lo spettro del segnale di partenza è perso per sempre e la deformazione dello spettro che si verifica puó essere vista come un ripiegamento (folding) dello spettro stesso alla frequenza fF=fC/2.
Figura 2.3: Spettro di un segnale campionato ad una frequenza di campionamento maggiore o minore della frequenza di Nyquist
In altre parole quindi perché un segnale campionato possa essere correttamente ricostruito è necessario in fase di registrazione prendere almeno due campioni per ciascun ciclo della forma d’onda originaria.
Nel nostro caso il segnale audio è stato campionato con una fC sufficiente (44.1 kHz) ad evitare il fenomeno dell’aliasing (essendo fM=20 kHz), ma se le copie dello spettro in banda audio non vengono efficacemente rimosse, interagiscono con le componenti audio presenti tra 0 e 20 kHz, creando distorsione di intermodulazione. Questo tipo di
distorsione non solo puó essere molto sgradevole da sentire, ma provoca surriscaldamento dei tweeters, dato che questi rispondono anche ai segnali ultrasonici. Essendo il segnale audio di banda 20 kHz al massimo, un filtro passa basso ideale (pendenza infinita) con una frequenza di taglio di tale valore mi permette di ricostruire correttamente il segnale di partenza, eliminando le alias.
Ovviamente però noi disponiamo di filtri a pendenza finita e quindi non riusciamo facilmente a tagliare da 20 kHz in poi il contenuto in frequenza del segnale campionato lasciando inalterato il segnale audio. Per ottenere una bassa distorsione del segnale di uscita vorremmo un’attenuazione di 0 dB fino a 20 kHz e di 90 dB per frequenze maggiori. Ottenere queste prestazioni da parte di un filtro passa basso analogico non è semplice, in quanto innanzitutto occorre che il filtro sia di ordine elevato, e poi che i componenti con cui è realizzato siano molto precisi. Anche in tal caso, comunque, un filtro con una risposta in ampiezza molto ripida in corrispondenza della frequenza di taglio, ha una risposta in fase poco lineare e quindi le componenti del segnale vengono sottoposte ad uno sfasamento non proporzionale alla frequenza, ossia avviene una distorsione di fase [22]. Vediamo brevemente questo cosa comporta.
Phase Shift
La fase è un ritardo temporale dipendente dalla frequenza (ϕ=ωt). Se tutte le componenti spettrali che compongono una forma d’onda audio (musica, ad esempio) sono ritardate della stessa quantità quando attraversano un dispositivo, si dice che tale dispositivo ha un comportamento in fase di tipo lineare, in quanto lo sfasamento introdotto per ognuna di loro è proporzionale alla frequenza. Un esempio potrebbe essere il ritardo digitale, che trasla nel tempo ogni componente del suono della stessa quantità.
L’orecchio umano in assenza di altri suoni come riferimento, non è sensibile a questo tipo di sfasamento; basti pensare che i segnali audio che escono da un lettore CD sono sempre ritardati durante l’elaborazione interna del segnale e la sua riproduzione, ma questo non ha alcun effetto sull’ informazione che noi percepiamo.
Con un segnale di riferimento, però, diventano udibili sia la presenza che l’entità di un ritardo temporale costante tra due onde sonore. Si immagini di ritardare un suono e di sovrapporlo a quello non ritardato; ritardi brevi provocano una cancellazione tra i due segnali dipendente dalla frequenza degli stessi, mentre un ritardo lungo provoca l’eco. Una dimostrazione di cancellazione tra due segnali si puó avere modificando i collegamenti sugli altoparlanti del nostro stereo: invertendo i segnali che arrivano su uno dei due, specie se stiamo riproducendo un segnale audio di tipo “mono” e a bassa frequenza, si riesce quasi a cancellare il suono complessivo prodotto.
Visto cosa succede nel caso di sfasamenti di ogni componente del segnale provocati da ritardi temporali costanti (t=(ϕ/ω)), resta da chiarire cosa accade se un segnale attraversa un dispositivo con risposta non lineare, in cui il ritardo di ogni componente dipende dalla frequenza. Consideriamo a questo proposito l’introduzione di uno sfasamento circa costante (phase shift) in un segnale audio; dato che ϕ ≈ costante e t=ϕ/ω, le componenti spettrali saranno ritardate di intervalli diversi tra loro. Cosa accade in questo caso? La risposta dipende dalla natura del segnale. L’orecchio umano con una forma d’onda statica - si pensi ad un segnale a dente di sega - è insensibile ad un cambiamento di fase costante delle sue componenti, cioè non si accorge se queste vengono sfasate tutte allo stesso modo. Su un oscilloscopio la seconda forma d’onda (sfasata) non appare come un’onda a dente di sega, ma nonostante ciò non siamo in grado di udirne la differenza con la prima.
Per forme d’onda di tipo dinamico (non stazionarie cioè) le cose vanno diversamente: si dimostra che ad esempio suoni brevi possono venire pesantemente danneggiati da un
phase shift. Suoni come “ding”, “pluck” o “tock” (ed in genere tutti i “transitori sonori”)
sono costituiti da molte componenti spettrali, tutte di breve durata; uno sfasamento non lineare modifica le loro relazioni temporali, trasformando ad esempio un “tock” in un “thwock”. Questa situazione è da evitare se vogliamo realizzare un buon amplificatore audio, in quanto la musica è da intendersi come una forma d’onda dinamica e quindi il
phase shift puó effettivamente degenerare il suono che udiamo. Stabilire in assoluto quale
sia l’entità di sfasamento accettabile non è possibile, ma sicuramente uno shift di fase di 1 grado ad esempio è tollerabile. In generale la regola da seguire è quella di minimizzare il phase shift quando possiamo.
Torniamo ora al filtro passa basso necessario alla ricostruzione del segnale audio. Dopo quanto detto dovrebbe essere chiaro che lavorare con un segnale campionato ad una frequenza poco maggiore di quella di Nyquist non solo comporta la necessità di utilizzare un filtro costoso, ma provoca la presenza di una distorsione di fase che non vogliamo.
Nel 1983 la Philips realizzò i primi lettori CD ad avere al loro interno un blocco di sovracampionamento. Intorno al 1986 molti altri costruttori di lettori CD utilizzarono la tecnica dell’oversampling per evitare di realizzare filtri di ricostruzione del segnale con pendenze elevate in corrispondenza della frequenza di taglio.
Sovracampionare un segnale digitale permette di generarne uno i cui campioni si presentano a frequenza multipla del segnale di ingresso e hanno ampiezza circa uguale a quella che avrebbero se fossero ottenuti direttamente dal segnale audio di partenza. Per capire perché una frequenza di campionamento maggiore risolva i problemi relativi ad una buona ricostruzione del segnale audio da parte del filtro di uscita, basti pensare che le repliche dello spettro del segnale audio si presentano ogni fC, dove con fC si indica la frequenza di campionamento. Se al momento della registrazione il segnale fosse campionato ad una frequenza ad esempio 8 volte maggiore di 44.1 kHz, la replica più vicina si sposterebbe (consideriamo fIN=20 kHz, che è il caso peggiore) da 24.1 kHz (=fC-fIN) a 332.8 kHz, permettendo l’utilizzo di un filtro passa basso con pendenza molto inferiore, che significa minor costo del filtro stesso e minore distorsione di fase. In particolare nel nostro caso, in cui si passa da fC=44.1 kHz a 352.8 kHz, la banda a disposizione per il filtraggio passa basso è pari prima a 2 kHz circa (fC/2 – fM), poi a quasi 158 kHz.
In realtà non c’è bisogno di campionare ad alta frequenza il segnale al momento della registrazione, ma come vedremo nel prossimo paragrafo grazie ai sovracampionatori si riesce a “convertire” la frequenza di campionamento di un segnale.
2.3.2 Principio di funzionamento del sovracampionatore
Lo scopo del sovracampionatore come abbiamo visto è quello di alterare lo spettro del segnale campionato per frequenze maggiori della banda audio. Il modo migliore per
farlo è quello di “trasformare” lo spettro di tale segnale, campionato a 44.1 kHz, in quello che avrebbe lo stesso segnale se fosse stato campionato ad una frequenza maggiore, che nel nostro caso è di 352.8 kHz.
Essendo il campionamento del segnale audio avvenuto in fase di registrazione, non disponiamo dei campioni “mancanti”, ossia non conosciamo quei valori del segnale di ingresso che avremmo potuto registrare campionando a 325.8 kHz. La funzione del sovracampionatore sarà quindi quella di stimare i valori che non abbiamo del segnale di partenza, in modo da emulare una frequenza di campionamento pari a quella desiderata. Il sovracampionamento [5],[13] è realizzato in due passi: prima si inserisce tra ogni coppia di campioni un certo numero di campioni nulli (zero-padding) e poi si fa passare questo segnale da un filtro digitale passa basso, chiamato filtro interpolatore:
Figura 2.4 : Schema a blocchi del sovracampionatore con interpolazione
Il blocco ZP che effettua lo zero-padding è quello che realizza l’aumento della velocità di campionamento. Dalla sequenza di ingresso x[n], avente frequenza fwordIN -che chiameremo ora fC’- viene infatti prodotta la sequenza di uscita xZP[m], avente frequenza fC = MּfC’. La generazione di questa nuova sequenza viene effettuata mediante un’operazione di riempimento con zeri, come mostrato in Figura 2.5 per M=4. L’aumento della frequenza di un fattore M viene cioè ottenuto mediante l’inserimento di M-1 campioni nulli tra ciascuna coppia di campioni consecutivi della sequenza originaria x[n].
Una volta effettuato lo zero-padding, c’è bisogno di un’operazione di interpolazione, capace di ricavare il valore che dovrebbero avere quei campioni che abbiamo inserito e
che per adesso hanno valore nullo.
Questa operazione viene effettuata per mezzo di un filtro passa basso e il motivo lo si capisce andando a vedere com’é fatto lo spettro del segnale a seguito dell’inserzione degli zeri.
In particolare, se andiamo a calcolare la trasformata di Fourier della sequenza sovracampionata xZP[m], riferita alla nuova frequenza fC = M· fC’, si ottiene:
[ ]
(
∑
+∞ −∞ = − = m ZP ZP f x m j mfT X ( ) exp 2π)
(2.2)dove T=1/fC. Se si osserva che xZP[m] è diversa da zero solo per m=Mּn (nel qual caso xZP[m]=x[n]) e che T=T’/M, l’espressione precedente diventa:
[ ]
∑
+∞ −∞ = = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛− = n ZP ZP M T Mnf j n x f X ( ) exp 2π ' x[ ]
n exp(
j2 nfT')
X(f) n ZP − =∑
+∞ −∞ = π (2.3) cioè le trasformate delle sequenze x[n] e xZP[m] sono identiche!Questo risultato non è assurdo; in realtà infatti le due trasformate XZP( f)eX( f)
presentano una differenza fondamentale: il periodo base di XZP( f) è l’intervallo [-1/2T,1/2T] che, rispetto al corrispondente periodo base [-1/2T’/1/2T’] di X( f), è M volte più grande. Ciò significa che elaborando xZP[m] con un filtro numerico, cioè con il secondo blocco di Figura 2.4, si possono modificare tutte le componenti spettrali appartenenti all’ intervallo [-M/2T’,M/2T’]. Se invece elaboriamo direttamente con un filtro numerico la sequenza originaria x[n] possiamo agire soltanto sulle sue componenti relative all’ intervallo [ -fC’/2, + fC’/2] (vedi parti evidenziate in rosso in Figura 2.5). Al blocco ZP si fa quindi seguire un filtro passa basso avente banda fC’/2 e guadagno in continua HP(0)pari a M. Questo guadagno è necessario in quanto il sovracampionamento distribuisce l’energia di ogni campione in ingresso su M campioni in uscita, attenuando di fatto ogni campione di un fattore M.
Il filtro interpolatore ha quindi il compito di cancellare alcune immagini presenti nello
spettro di XZP( f) relative al segnale originariamente campionato a 44.1 kHz , così da ottenere uno spettro teoricamente identico a quello che si sarebbe ottenuto campionando direttamente il segnale analogico x(t) di partenza con la frequenza di campionamento fC=352.8 kHz.
Figura 2.5 : Rappresentazione del processo di interpolazione nel tempo e in frequenza
Nel dominio del tempo, il filtro digitale passa basso riesce a ricavare i valori che effettivamente dovrebbero avere i campioni inseriti con lo zero-padding e per questa sua capacitá viene chiamato spesso “filtro interpolatore”.
La funzione di interpolazione la si puó vedere in dettaglio ragionando in termini analitici. Un primo metodo è il seguente: se indichiamo con hP[m] la risposta impulsiva del filtro HP( f), l’espressione del segnale sovracampionato y[m] è praticamente quella utilizzata tipicamente per riassumere l’elaborazione del segnale compiuta da un
interpolatore, ossia da un filtro passa basso utilizzato per la ricostruzione di un segnale
campionato:
∑
+∞ −∞ = = ⊗ − = ⊗ = n P P ZP m h m x n m Mn h m x m y[ ] [ ] [ ] [ ]δ[ ] [ ]∑
+∞ −∞ = − n P m Mn h n x[ ] [ ] (2.4) La funzione di interpolatore svolta dal filtro digitale del blocco di sovracampionamento appare ancora più chiaramente se andiamo ora a sostituire hP[m] (risposta impulsiva del filtro passa basso ideale avente banda 1/(2⋅M⋅T) e guadagno M) con la sua espressione:⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = M m c m hP[ ] sin (2.5)
da cui si trova che la sequenza y[m] in uscita al filtro vale
∑
+∞ −∞ = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = n M Mn m c n x m y[ ] [ ]sin (2.6)che ricorda la formula di interpolazione cardinale.
La sequenza y[m] è dunque una versione interpolata del segnale xZP[m], in cui i campioni nulli introdotti in fase di zero-padding vengono sostituiti da campioni interpolati che assicurano una maggiore “regolarità” del segnale sovracampionato.
2.3.3 Scelta del filtro interpolatore
La scelta del filtro interpolatore digitale è molto importante in quanto influenza notevolmente le prestazioni dell’amplificatore audio.
Come riferimento iniziale abbiamo preso, in accordo a quanto fatto in [19], le specifiche del filtro digitale di interpolazione interno al DAC UDA1320ATS della Philips Semiconductors [20] (vedi Tabella 2.2, dove nel nostro caso fS era pari a 44.1 kHz).
Specifications Frequency band Value (dB)
Pass-Band Ripple <0.45 fS 0.1
Stop-Band Attenuation >0.55 fS 50
Tabella 2.2: Specifiche del filtro di interpolazione
Il disegno del filtro è stato fatto sin dal principio con MATLAB: imponendo i valori della Tabella 2.2, con fpass=19.8 kHz e fstop=24.3 kHz, abbiamo ottenuto il minimo ordine per diversi tipi di filtri e quello di minor complessità è risultato essere il filtro IIR ellittico, per il quale N=7 (come riportato in [19]). La risposta in frequenza relativa ad ampiezza e fase è riportata in Figura 2.6.
Sebbene un filtro IIR abbia un basso costo di implementazione, ha il difetto di non avere una risposta in fase lineare e per questo produce il phase shift di cui abbiamo parlato al Par.2.3.1 a proposito del filtro di uscita. Per questa ragione il filtro dei blocchi di oversampling utilizzati in tecnologia digitale per applicazioni audio non sono di solito di tipo IIR, bensì di tipo FIR, in quanto questi ultimi sono caratterizzati da una risposta in fase molto più lineare. (si osservi come esempio Figura 2.6).
Figura 2.6 : Risposta in frequenza di un filtro IIR ellittico del 7°ordine (a) e di un filtro FIR di Hamming del 196° ordine
Il principale difetto dei filtri FIR è che a parità di prestazioni (vedi ad esempio quelle della Tabella 2.2), richiedono un ordine molto più elevato rispetto ai filtri IIR e di conseguenza un maggiore costo di implementazione, inteso come numero di prodotti per ogni campione ottenuto in uscita al filtro [19]. Per ovviare a questo problema solitamente si ricorre ad implementazioni di tipo polifase, che è una tecnica per scomporre un filtro unico in una catena di filtri in cascata, in modo da abbassare il costo complessivo. L’alternativa è diminuire l’ordine del filtro, sebbene ciò comporti
l’allargamento della cosiddetta “banda di transizione” (secondo una relazione di proporzionalità inversa), ossia della banda che separa la “pass-band” dalla “stop-band”. Nel caso del filtro di interpolazione in particolare questo si traduce in una peggiore attenuazione delle alias dello spettro del segnale di ingresso comprese tra la metà della frequenza di campionamento e la banda audio, con conseguente peggioramento della qualità del segnale di uscita all’amplificatore.
Abbiamo verificato che un filtro FIR di Hamming di ordine 196 e frequenza di taglio (a –6 dB) di 22.5 kHz (Figura 2.6) ha una risposta in frequenza confrontabile con quella del filtro IIR precedentemente considerato. Un filtro di tale ordine è molto costoso dal punto di vista dell’implementazione e pertanto abbiamo provato ad abbassarne il numero di coefficienti, allontanandoci così dalle specifiche della Tabella 2.2.
Applicando un segnale di ingresso di 1 kHz ed utilizzando un filtro FIR di ordine 32 con frequenza di taglio a –6 dB di 25 kHz (Figura 2.7) abbiamo ottenuto risultati addirittura leggermente migliori dal punto di vista della distorsione del segnale di uscita, sebbene questa tendenza si invertisse per frequenze maggiori di 5 kHz. Dato che l’orecchio umano è particolarmente sensibile alle medie frequenze e dato che in ogni caso le variazioni sarebbero state difficilmente percepibili (non superavano il 10%), abbiamo deciso di utilizzare il filtro FIR di ordine 32 per il blocco di sovracampionamento. Vediamo brevemente che coefficienti abbiamo usato.
Coefficienti del filtro di interpolazione
Una volta impostate le caratteristiche di un filtro digitale, come abbiamo visto MATLAB ne fornisce automaticamente il modello, in cui ogni coefficiente è espresso di default in forma normalizzata con 20 cifre decimali. Logicamente in fase di sintesi non è ragionevole utilizzare coefficienti con una tale precisione, in quanto sarebbero necessari registri anche di 70 bit! Per questa ragione, con segnale di ingresso di 1 kHz, abbiamo ridotto gradualmente il numero di cifre decimali su cui era espresso ogni coefficiente fino a quando la modifica da noi apportata non ha provocato una variazione della THD del segnale di uscita pari al 10%. Siamo così arrivati ad esprimere i coefficienti con 4 cifre decimali (ossia con 12 bit): togliere un ulteriore cifra avrebbe significato portare a
zero 8 dei 33 coefficienti, con conseguente allargamento della banda di transizione e quindi notevole perdita di prestazioni.
Figura 2.7: Risposta in frequenza del filtro FIR di ordine 32 utilizzato nel modello Simulink del blocco di sovracampionamento
In tutte le simulazioni che abbiamo fatto per analizzare le diverse architetture di amplificatori audio abbiamo utilizzato per il modello del blocco di sovracampionamento il filtro di interpolazione appena descritto, ossia un Hamming Window FIR di ordine 32, frequenza di taglio (a –3 dB) di circa 18.2 kHz e coefficienti (normalizzati) espressi con 4 cifre decimali. Per uno studio dettagliato del problema del “bit bounded” si veda [27].
2.4 Modulazioni PWM e Predistorsione
Nel descrivere l’utilità del sovracampionamento abbiamo parlato della ricostruzione del segnale audio da parte del filtro passa basso a valle dell’amplificatore senza però considerare che nel nostro caso il filtro di uscita ha a che fare con un segnale PWM, il cui spettro è molto più complicato di quello che abbiamo trattato fino ad ora. Sebbene il principio di fondo resti invariato, vediamo ora in dettaglio com’è fatto lo spettro di un segnale modulato ad impulsi, in modo da capire anche a che cosa serve il blocco che abbiamo chiamato “cross-point deriver”.
Lo spettro di un segnale modulato ad impulsi dipende fortemente dal tipo di modulazione utilizzata per generarlo.
In un tipico amplificatore in classe D il segnale PWM viene generato confrontando (tramite un comparatore) il segnale di ingresso (modulante) con un’onda (portante) triangolare (si parla in tal caso di Double-Sided PWM) o a dente di sega (si parla allora di
Trailing-Edge PWM) di frequenza molto più elevata e ampiezza dello stesso ordine di
grandezza; nel caso il segnale di ingresso sia digitale, come abbiamo visto al Cap.1 tipicamente prima viene convertito in forma analogica e poi viene utilizzato per generare il segnale PWM.
Figura 2.8 : Generazione convenzionale di un segnale NPWM di tipo Trailing-Edge
La modulazione appena descritta è definita “Natural PWM”, dato che gli impulsi del segnale di uscita al modulatore hanno una durata che rappresenta gli istanti in cui il segnale d’ingresso attraversa in modo “naturale” la forma d’onda utilizzata per il confronto. Un altro modo per generare il segnale PWM è quello di far durare gli impulsi un tempo proporzionale al valore assunto dal segnale di ingresso in istanti intervallati tra loro di una quantità costante; in questo secondo caso si parla di “Uniform PWM” (Figura 2.9).
Figura 2.9: Uniform e Natural PWM (Trailing-Edge)
Negli amplificatori che stiamo studiando il segnale di ingresso è di tipo digitale e ogni parola (PCM a 16 bit) corrisponde al valore di un campione prelevato dal segnale audio originario. Essendo il campionamento in fase di registrazione eseguito ad istanti ugualmente intervallati tra loro, si capisce come mandando il segnale PCM in ingresso direttamente al modulatore avremmo senz’altro una modulazione UPWM (Figura 2.10).
Figura 2.10: Realizzazione e diagramma temporale di una UPWM Trailing-Edge
Per capire meglio come stanno le cose, basti pensare che introducendo nel modulatore analogico di Figura 2.8 un blocco capace di campionare ad intervalli regolari e quantizzare il segnale di ingresso (vedi “Zero Order Hold and Amplitude Quantizer” in Figura 2.10), in pratica ci mettiamo nelle stesse condizioni in cui si troverebbe il modulatore utilizzato negli amplificatori audio digitali se ricevesse direttamente il segnale PCM.
Purtroppo i due segnali NPWM e UPWM (Trailing-Edge) confrontati fin’ora hanno degli spettri abbastanza diversi; in particolare vedremo come quello del segnale UPWM comporti una distorsione decisamente maggiore. Nelle considerazioni che seguiranno faremo sempre riferimento a modulazioni di tipo “Trailing-Edge”, ossia ottenute dall’utilizzo di un segnale portante a dente di sega.
2.4.1 Confronto tra NPWM e UPWM
Definendo fs la frequenza del segnale sorgente, supposto sinusoidale e descritto per semplicità dalla legge M⋅cos(ωSt), e fC quella dell’onda a dente di sega utilizzata in circuiti analogici per ottenere il segnale NPWM, la serie di Fourier è [12]:
( )
+∑
∞(
)
−∑
∞(
) (
−)
+ + = 1 1 0 sin 2 sin cos 2 ) ( m t m k m M m J m t m t M k t F c c s NS π ω π π π ω ω(
)
∑ ∑
∞ = ±∞ ± = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − − − 1 1 2 2 sin m s c n n k m t n t m m M m Jn ω ω π π π π (2.7) Il primo termine k è la componente continua del segnale PWM di uscita e non comporta alcun problema; il secondo termine rappresenta il segnale di ingresso modulante; il terzo termine ed il quarto sono relativi alla portante e alle sue armoniche; l’ultimo termine rappresenta i prodotti di intermodulazione tra il segnale modulante e le sue armoniche e la portante e le sue armoniche.In altre parole lo spettro del segnale NPWM (Figura 2.11) comprende il segnale modulante in banda base, la frequenza di campionamento e le sue armoniche e delle
bande laterali formate dal prodotto tra il segnale audio e tutte le armoniche della frequenza di campionamento.
Figura 2.11: Spettro del segnale NPWM
Dal momento che le bande laterali della frequenza di campionamento (che è anche la frequenza di switching) hanno estensione teoricamente illimitata, le componenti indesiderate raggiungono la banda audio, provocando cosí distorsione non-armonica del segnale audio. Andando ad analizzare l’entità delle bande laterali suddette e la velocità con cui si attenuano, si vede che l’ampiezza delle componenti di distorsione è proporzionale al valore assunto dalla funzione di Bessel (vedi (2.7)) e quindi scegliendo una frequenza di campionamento sufficientemente grande le componenti che entrano nella banda audio sono trascurabili; in particolare considerando un segnale modulante puramente sinusoidale si ha che quando la frequenza di switching è almeno 10 volte più grande della frequenza del segnale di ingresso, la distorsione dovuta alle bande laterali della frequenza di campionamento è inferiore a -144 dB. Considerando che la banda audio si estende fino a 20 kHz, una frequenza di campionamento di 200 kHz produce una distorsione delle bande laterali non rilevabile dall’orecchio umano.
Per quanto riguarda la UPWM le cose non sono cosí semplici. L’espressione della serie di Fourier di un segnale UPWM è [12]:
(
) ( )
+ − + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − =∑
∞∑
∞ m t m M m J n k n t m n M n Jn k t F c c s s c s c s US π ω π π ω ω π ω ω πω ω ω π sin 1 2 2 sin ) ( 1 0 1(
)
(
)
(
)
∑ ∑
∞ = ∞ ± ± = ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − + + ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ + − 1 1 2 2 sin m n c s c c s c c s c n k t n m n m M n m Jn π ω π ω ω ω π ω ω ω π ω ω (2.8) Il primo termine k è la componente continua, il secondo termine corrisponde al segnale modulante di ingresso e le sue armoniche; il terzo e l’ultimo termine sono simili a quelli del segnale NPWM e scegliendo una frequenza di campionamento sufficientemente elevata comportano una distorsione non-armonica trascurabile. Nel caso considerato, in cui il segnale di ingresso è sinusoidale, lo spettro del segnale UPWM è quello di Figura 2.12. Si deduce che mentre un segnale NPWM è caratterizzato teoricamente da un’assenza di distorsione armonica, in quanto non sono presenti armoniche del segnale di ordine superiore al primo, in un segnale UPWM è presente un’elevata THD, dell’ordine del 2%, e per molte applicazioni- comprese quelle degli amplificatori audio- tale livello di distorsione non è accettabile.Figura 2.12 : Spettro del segnale UPWM
Riepilogando, un segnale NPWM ha il pregio, rispetto a quello UPWM, di non avere componenti armoniche del segnale audio; inoltre (ma questo vale per entrambi i tipi di segnali PWM considerati) nella banda 0-20 kHz la distorsione non-armonica è trascurabile se la frequenza di campionamento utilizzata è, come nel nostro caso, 352.8 kHz.
La presenza di componenti armoniche in banda audio nel segnale UPWM comporta necessariamente una distorsione più elevata del segnale di uscita, in quanto la ricostruzione del segnale audio viene fatta per mezzo di un filtro passa basso che idealmente taglia le componenti spettrali a frequenza maggiore di 20 kHz, ma lascia invariato tutto ció che si trova a frequenze minori, comprese le armoniche del segnale utile. Tutto questo fa capire la ragione per cui si vorrebbe che all’interno di un amplificatore digitale audio il modulatore generasse un segnale NPWM.
2.4.2 Pseudo-Natural PWM
Negli ultimi dieci anni sono stati fatti molti sforzi per superare i difetti della UPWM, in modo da minimizzare l’effetto di distorsione provocato dalle componenti armoniche del segnale di ingresso in banda audio.
Le prime pubblicazioni presentavano architetture corrette dal punto di vista concettuale, ma irrealizzabili nella pratica a causa dell’eccessiva frequenza di clock del modulatore, che doveva raggiungere le decine di GHz [15]. L’introduzione di un blocco di sovracampionamento e di un Noise Shaper permisero di diminuire la frequenza del modulatore a decine di MHz, ma la distorsione dovuta alle componenti armoniche del segnale audio era ancora presente. Soltanto l’introduzione di un “cross-point deriver” ha migliorato le prestazioni degli amplificatori audio digitali, in grado cosí di raggiungere non solo un rendimento superiore al 90% ma anche una distorsione del segnale di uscita inferiore allo 0.05%. Lo scopo del “cross-point deriver” è quello di elaborare il segnale digitale sovracampionato in modo da ottenere in uscita al modulatore un segnale che sia il più possibile somigliante al NPWM , sia dal punto di vista temporale che spettrale; questo segnale è chiamato per ovvie ragioni Pseudo-Natural PWM (PNPWM) [3]. Le difficoltà che incontriamo a generare un segnale NPWM con il modulatore digitale
dipendono come già spiegato dalla natura del segnale che riceve in ingresso il modulatore stesso: le parole PCM sono la codifica digitale dei campioni del segnale audio sorgente; dato che quei campioni sono stati estratti in modo uniformemente distribuito nel tempo, mon si può che ottenere una ottenendo quindi una UPWM.
Per ottenere una modulazione diversa in uscita al modulatore l’unico modo è modificare il valore delle parole PCM a 16 bit, in modo da ottenere un segnale che “emuli” la NPWM. Lo scopo del “cross-point deriver” è proprio quello di utilizzare due o più campioni consecutivi del segnale digitale di ingresso per stimare il valore del segnale audio di partenza in un istante intermedio tra due consecutivi di campionamento. Confrontando quindi il valore cosí ottenuto con la rampa digitale creata internamente al modulatore, si riesce ad ottenere un segnale modulato ad impulsi che somigli a quello NPWM desiderato, ossia “Pseudo-NPWM”. Il grado di somiglianza tra il segnale PNPWM e quello NPWM dipende dalla complessitá dell’algoritmo utilizzato per stimare l’andamento della onda sonora originaria.
Il cross-point deriver quindi non fa altro che modificare (predistorcere) il segnale PCM in modo da limitare la distorsione armonica nel segnale PWM generato dal modulatore digitale.
La Pseudo-Natural PWM è stata introdotta da J.M.Goldberg e M.B.Sandler [3] intorno agli anni ‘90. L’idea di base è quella di riuscire a calcolare l’istante di tempo in corrispondenza del quale il segnale audio di partenza attraverserebbe l’onda a dente di sega che avremmo usato operando in modo analogico per generare un segnale NPWM. Conoscere tale istante “di attraversamento” in modo esatto sarebbe possibile se avessimo a disposizione il segnale analogico di partenza, mentre noi disponiamo soltanto dei campioni PCM. Come giá accennato quello di cui c’è bisogno è appunto una ricostruzione del segnale analogico a partire dai suoi campioni ed un modo pratico per farla è utilizzare un’approssimazione polinomiale di ordine n.
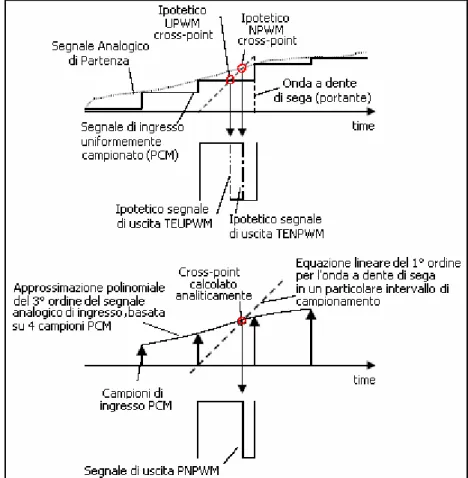
Per capire in cosa consiste effettivamente la PNPWM supponiamo (vedi Figura 2.13) di conoscere l’andamento del segnale originario e di confrontare lui e la sua versione “a gradini” con l’onda portante che utilizzerebbe un modulatore analogico: possiamo distinguere due istanti particolari o “cross-point”, uno relativo all’attraversamento del segnale a dente di sega da parte del segnale discontinuo (UPWM cross-point) e l’altro
relativo all’attraversamento della stessa onda portante da parte stavolta del segnale analogico sorgente (NPWM cross-point).
Il procedimento che mi permette di ottenere la PNPWM consiste nello stimare l’andamento del segnale audio nell’intorno dell’“UPWM cross-point”, cosí da conoscere approssimativamente l’“NPWM cross-point”; da quello è possibile quindi ricavare (essendo nota la funzione a dente di sega, scelta da noi) il valore (da mandare al modulatore) assunto dal segnale originario in quell’istante.
Figura 2.13: Generazione del segnale PNPWM (approssimazione polinomiale di ordine 3)
Vediamo in dettaglio come vanno le cose se vogliamo utilizzare un’approssimazione polinomiale del primo ordine, che permette di stimare il valore di ogni parola da mandare al modulatore utilizzando 2 soli campioni PCM.
Poniamo l’attenzione su una coppia di istanti di campionamento del segnale di ingresso, t0 e t1, in corrispondenza dei quali il segnale vale rispettivamente in0 e in1. La distanza tra
t0 e t1 è dunque pari al periodo dell’onda a dente di sega, che in Figura 2.14 è rappresentata sovrapposta al segnale analogico di partenza:
Figura 2.14 : Approssimazione del primo ordine del cross-point
In assenza del “cross-point deriver”, al modulatore digitale PWM arriverebbero le parole PCM relative ai valori in0 e in1 quantizzati e di conseguenza si otterrebbe un segnale UPWM, dato che t0 e t1 sono due generici istanti di campionamento adiacenti.
Per ottenere una NPWM, relativamente al periodo rappresentato in Figura 2.14, occorre mandare in ingresso al modulatore una stima di in(tα), che è proprio il valore assunto dal segnale di ingresso nell’istante di attraversamento dell’onda triangolare. Avendo a disposizione solo i valori in0 e in1, quello che si può fare è stimare il valore suddetto, che però non sarà mai noto con esattezza.
Il modo più semplice e immediato per conoscere approssimativamente tα è unire con una retta i campioni in0 e in1 e calcolare l’istante in cui tale retta si incontra con la rampa del segnale a dente di sega; tale problema porta a conoscere t2, utilizzato come stima dell’istante tα. Questa stima sarà tanto più precisa quanto maggiore è la frequenza dell’onda a dente di sega rispetto a quella del segnale di ingresso, ossia quanto più grande è il rapporto di campionamento; ecco allora che sovracampionare il segnale PCM aiuta anche ad ottenere migliori risultati da parte del cross-point deriver.
Quella che abbiamo appena considerato è comunque un’approssimazione del 1º ordine del segnale compreso tra t0 e t1 e com’è facilmente intuibile la stima di in(tα) non è molto precisa.
Si osservi che in Figura 2.14 i valori della rampa e dei campioni sono normalizzati rispetto alla dinamica della rampa stessa: questo non comporta alcuna limitazione nel ragionamento fatto, dato che a noi interessa confrontare il segnale di ingresso col segnale a dente di sega ed il risultato di tale confronto (che fornisce la larghezza degli impulsi del segnale PWM) non cambia normalizzando le ampiezze di entrambi i segnali; in altre parole, si verifica facilmente che se si genera un segnale PWM dal confronto del segnale di ingresso (ad esempio sinusoidale) con uno a dente di sega, una volta fissata la frequenza di entrambe le onde la larghezza degli impulsi non dipende dalla loro ampiezza in termini assoluti, ma dipende solo dalla relazione che esiste tra le ampiezze dei due segnali in termini relativi.
Per quanto riguarda l’asse dei tempi, anch’essa è normalizzata rispetto al periodo di campionamento; questo ci permette di considerare la rampa del segnale a dente di sega come funzione cw(t)=t. Il risultato delle normalizzazioni suddette è che in1, in0 e t2 variano tra –0.5 a +0.5. E’ giusto chiedersi se anche la normalizzazione dell’asse dei tempi sia lecita oppure no; più avanti, nella descrizione del modulatore PWM, vedremo che la situazione analogica normalizzata che stiamo ora considerando è esattamente equivalente a quella che effettivamente si verifica nel nostro caso in fase di modulazione. Riprendiamo dalla Figura 2.14; la retta tra in0 e in1 ha equazione:
) ( 5 . 0 ) ( ) ( ˆ1 t in1 in0 t in1 in0 n i = − + + (2.9)
Definendo poi f(t)=cw(t)- in(t), con f(t=tα) =0, si ha
) ( ˆ ) ( ) ( ˆ 1 1 t cwt in t f = − ove fˆ1 (t = t2)=0 (2.10)
Ecco quindi che il problema di calcolo dell’istante di attraversamento tα (cross-point) è diventato un problema di calcolo della radice. La soluzione dell’ equazione (2.10) è:
(
)
0 1 0 1 2 1 5 . 0 in in in in t + − + = (2.11) 41Con un’onda a dente di sega a frequenza sufficientemente elevata, t2 è una stima accettabile di tα;essendo poi cw(t)=t, vale anche che t2=in(t2) e t2 risulta quindi essere una stima anche del valore (normalizzato) di in(tα).
Come si osserva dalla (2.11) questo modo di ragionare, seppure semplice, comporta la necessità di implementare delle divisioni, che in genere si preferisce evitare a causa del loro costo elevato dal punto di vista della sintesi. Inoltre gli studi [3] relativi a questo tipo di ricostruzione del segnale di ingresso a partire dai campioni PCM hanno accertato che l’approssimazione del primo ordine non è in grado di garantire una qualità di 16 bit. Per raggiungere tali livelli di linearità dovremmo utilizzare una stima del segnale audio almeno del terzo ordine, che utilizzerebbe anche in-1 e in2 e fornirebbe quindi risultati più precisi, ma comporterebbe anche un notevole aumento della complessità del cross-point deriver (il numero di operazioni per campione passerebbe infatti da 3 addizioni, 2 moltiplicazioni e una inversione a circa 14 addizioni, 5 moltiplicazioni e una inversione [3]) .
Volendo realizzare architetture di amplificazione a basso costo di implementazione, abbiamo studiato un altro tipo di “pre-distorsione” del segnale di ingresso, un po’ differente da quella proposta da Goldberg e Sandler ma comunque molto interessante.
2.4.3 δC-PWM
Qualche anno fa Bah-Hwee Gwee propose [4] il “δC-PWM sampling process”, un nuovo metodo di elaborazione dei dati PCM in grado in teoria di permettere al modulatore di generare un segnale PWM affetto da un livello di distorsione armonica accettabile (intorno allo 0.2 %). L’efficacia di questa procedura fu accertata in fase di progetto per un amplificatore in classe D con un segnale di ingresso a frequenza 48 kHz e nessun blocco di sovracampionamento; la nostra speranza era che fosse efficace anche in presenza di un segnale PCM sovracampionato.
Per maggiore chiarezza la Figura 2.15 mette a confronto la NPWM, la UPWM, la PNPWM e la δCPWM (“δ-Compensated PWM”). Con la linea rossa abbiamo indicato la retta che unisce due campioni consecutivi del segnale di ingresso; tale retta è la inˆ t( )
di Figura 2.14, ossia quella considerata al paragrafo precedente per fare una stima del primo ordine di in(tα).
Le considerazioni che stanno alla base del δC-PWM process sono tutte di tipo geometrico e si riferiscono anche in questo caso ad una situazione normalizzata, senza per questo perdere in generalità.
Indichiamo con SNS il valoredel segnale di ingresso nell’istante indicato finora con tαe con S1’ la sua stima, si ha:
S1' S= 1+δ (valori normalizzati) (2.12)
Andiamo a vedere come si puó stimare δ.
Se consideriamo l’intervallo AC e l’ampiezza λ, e l’intervallo AE con α, ho due triangoli simili e quindi posso scrivere λ/α = AC/AE. Approssimando poi λ con δ, si ha che
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ≈ ⇒ ≈ AE AC AE AC δ α α δ (2.13) Ragionando ancora con i triangoli simili, si puó scrivere anche:
S AB S AE AE AB 1 1 1 1 ⇒ = = (2.14) S AD S AE AE AD 1 1 2 2 ⇒ = = (2.15)
Facendo il rapporto tra le due relazioni appena ricavate si ottiene che AB/AD = S1/S2, ottenibile anche osservando i triangoli simili FAB e FJH.
L’ultimo passaggio infine è quello fondamentale e consiste in un’approssimazione:
AC = AB+AD ≈ AC 2 ) ( ' (2.16) 43
Figura 2.15: Modulazioni PWM a confronto
Sostituendo nella (2.13) si ha:
2 ) )( ( 2 ) ( S2 S1 S2 S1 AE AD AB AE AC = − + ⋅ + = ≈α α δ (2.17) e quindi 2 ) )( ( ' 2 1 2 1 1 1 S S S S S S = + − + (2.18)
Una volta calcolato S1’ utilizzando S1 e S2, questo va a sostituire S1; quindi S2 e S3
saranno utilizzati dal cross-point deriver per calcolare S2’, che andrà a sostituire S2 ,e così via.
A questo punto è interessante osservare che se nella (2.11) andiamo a considerare che in1 e in0 sono molto simili tra loro, l’equazione puó essere riscritta come
(
)(
)
(
)(
)
2 2 ) ( 1 5 . 0 ' 1 1 0 1 0 1 0 0 1 1 0 in in in in in in in in in in in ≅ + + − = + + − + (2.19)Sostituendo in0 e in1 con S1 e S2, la somiglianza tra la (2.18) e la (2.19) è evidente.
Dopo quanto visto sulla PNPWM, questo ci ha fatto supporre che effettivamente la δC-PWM generata dal modulatore potesse essere affetta da una distorsione armonica minore della UPWM anche con un segnale di ingresso sovracampionato. Inoltre con questa tecnica l’unica divisione da implementare è realizzabile con un semplice shift verso destra.
2.4.4 Realizzazione del cross-point deriver
Deciso l’algoritmo da utilizzare per la predistorsione del segnale PCM, occorre fare alcune precisazioni prima di vedere la sintesi circuitale del blocco in questione.
Le considerazioni fatte riguardo alla modulazione δC-PWM sono relative a segnali di partenza analogici ed inoltre il segnale portante, quello di ingresso e l’asse dei tempi sono normalizzati; c’è però da chiedersi cosa accade nel nostro caso, dove il segnale di ingresso è discreto e rappresentato in parole PCM da 16 bit.
Per quanto riguarda l’utilizzo dei segnali con ampiezza normalizzata, al momento della realizzazione si tratterà di introdurre uno shift verso destra a valle del moltiplicatore che implementa il prodotto tra (S2-S1) e (S2+S1)/2, in modo da “normalizzare” δ che cosí potrà essere espresso non più su 32 bit ma semplicemente su 16.
Una precisazione importante va fatta sui segni: la (2.18) è corretta solo se considero parole PCM relative a valori non negativi: in tal caso δ può assumere valori positivi o negativi a seconda se il segnale di ingresso è crescente o decrescente, ma in uscita al cross-point deriver avremo sempre un risultato corretto. In caso invece che il segnale di
ingresso assuma anche valori negativi, non solo occorrerebbe calcolare Si’ in base al segno del segnale di ingresso, ma avremmo comunque complicazioni nel realizzare il modulatore: il contatore al suo interno che realizza il segnale a dente di sega ha in uscita numeri unsigned e sono questi che vengono poi confrontati coi campioni PCM.
Nella simulazione delle diverse architetture e nella successiva sintesi abbiamo quindi fatto l’ipotesi di utilizzare numeri senza segno; questa non è una grossa limitazione, se si pensa che nel caso avessimo a che fare con segnali digitali a 16 bit con segno sarebbe sufficiente sommare ad essi il numero binario corrispondente a 215; in questo modo otterremmo valori in ingresso al cross-point deriver di valore compreso tra 0 e 216-1, come desiderato.
Figura 2.16: Schema a blocchi del cross-point deriver
Lo schema a blocchi del circuito che implementa la (2.18) è mostrato in Figura 2.16. Si osservi che se in ingresso si hanno i campioni PCM a 16 bit con frequenza fword=8⋅fwordIN, i campioni in uscita sono ancora espressi su 16 bit e hanno la stessa frequenza. Il circuito di predistorsione infatti non fa altro che utilizzare le coppie consecutive di campioni per stimare i valori intermedi utili al fine di realizzare una modulazione che emuli la NPWM.
Come precedentemente accennato, nel modello Simulink del cross-point deriver è stato necessario introdurre uno shift di 16 posizioni verso destra a valle del moltiplicatore, in modo da normalizzare δ che risulta così espresso su 16 bit.
2.4.5 Prestazioni del cross-point deriver
In fase di simulazione abbiamo inizialmente verificato l’utilità del processo di predistorsione δC-PWM in condizioni operative simili a quelle per cui era stato progettato, ossia quando in ingresso all’amplificatore veniva inviato un segnale con frequenza 1 kHz e frequenza di campionamento pari a 44.1 kHz. Utilizzando un modulatore a due livelli, la THD% relativa alle prime dieci armoniche del segnale di ingresso è scesa da valori superiori al 2.5% fino allo 0.6% circa. Purtroppo lo stesso miglioramento non si è verificato né con una PWM tri-state e la frequenza di campionamento invariata, né con una fC otto volte maggiore (352.8 kHz) ed una PWM a due livelli. L’aspetto interessante dei risultati che abbiamo ottenuto dopo diverse simulazioni è che non solo il processo di distorsione non migliorava affatto i livelli di THD, ma in alcuni casi addirittura li peggiorava.
Alla luce di questi dati e non desiderando aumentare ulteriormente il costo di implementazione della parte digitale, abbiamo deciso di escludere il cross-point deriver con δC-PWM dalla catena di elaborazione del segnale digitale, mettendo così a confronto senza di esso le quattro architetture prese in esame.
Figura 2.17: Spettro del segnale di uscita di AD3 con fc=352.8 kHz e senza predistorsione (a) e di AD con fc=44.1 kHz e con predistorsione (b) (THD% relativa alle prime 10 armoniche)
Un’ultima precisazione va fatta a proposito dell’utilizzo di una frequenza di campionamento pari a 44.1 kHz: sebbene in tal caso la THD migliori notevolmente con la predistorsione del segnale PCM, rimane il problema della presenza di componenti spettrali di notevole entità al di sopra dei 20 kHz (vedi Figura 2.17(b)) che, come già spiegato in precedenza (Par.2.3.1), provoca degenerazione del segnale audio; questa è la ragione per cui a parità di THD è comunque preferibile utilizzare una frequenza di campionamento più elevata senza introdurre alcuna predistorsione piuttosto che ricorrere ad un cross-point deriver con un segnale non sovracampionato (vedi ad esempio Figura 2.17(a)).
2.5 Noise Shaping
Supponendo di mandare il segnale di uscita del cross-point deriver direttamente al modulatore, occorrerebbe utilizzare per quest’ultimo una frequenza di clock eccessiva per una realizzazione a basso costo dell’amplificatore. La ragione è che una parola PCM di 16 bit può assumere 216 configurazioni diverse, alle quali in fase di modulazione dovrebbero corrispondere altrettante diverse durate degli impulsi del segnale PWM. Essendo la frequenza con cui si presentano i campioni PCM pari a fword=8⋅fwordIN (con fwordIN=44.1 kHz), il clock necessario al modulatore sarebbe 8⋅fwordIN⋅216, ossia 23.1 GHz. Un clock così elevato non è facilmente realizzabile, senza considerare poi che a parità periodo di switching le minime variazioni che il modulatore riuscirebbe ad imporre sulla durata degli impulsi (≈ 40 ps) non sarebbero riproducibili dai transistori di potenza, che tipicamente hanno tempi di commutazione dell’ordine di decine di ns. Per queste ragioni si presenta la necessità di esprimere il segnale PCM con parole aventi un numero di bit inferiore.
Un semplice troncamento delle parole PCM non risolverebbe il problema in quanto il rumore di quantizzazione così introdotto sarebbe inaccettabile: la potenza di rumore sarebbe distribuita su tutto lo spettro fino a fword/2 coinvolgendo anche la banda audio, provocando così degenerazione del segnale analogamente a come farebbe il rumore bianco.
Esiste una tecnica in grado di diminuire il numero di bit di una parola PCM senza compromettere il SNR in banda audio ed è quella del “noise shaping”. Con essa viene introdotta complessivamente circa la stessa potenza di rumore che nel caso del troncamento suggerito precedentemente, con la differenza che ora la densità spettrale di rumore non è costante su tutto lo spettro, ma si può fare in modo che sia bassa in banda audio e alta al di fuori (Figura 2.18).
Figura 2.18 : Rumore di quantizzazione con troncamento o noise shaping
Questa tecnica è possibile solo se c’è una sufficiente banda di frequenze ove “ridirezionare” la potenza di rumore e nel nostro caso tale intervallo esiste: dal momento che il segnale PCM di ingresso è stato sovracampionato, la banda ove la potenza di rumore può essere deviata è quella tra la massima frequenza del segnale audio (20 kHz ) e 176.4 kHz ((8⋅fwordIN)/2).
2.5.1 Realizzazione
La tecnica del noise shaping è realizzata in pratica per mezzo di un modulatore Σ∆ a 8 bit (Figura 2.19), in cui H(z) è un filtro FIR di ordine N.
Figura 2.19 : Schema a blocchi del Noise Shaper
Abbiamo indicato con x[n] il segnale PCM a 16 bit sovracampionato che arriva dal cross-point deriver con la frequenza di 8⋅fwordIN (352.8 kHz), con eRQ[n] l’errore di riquantizzazione e con eNS[n] l’errore presente in uscita al Noise Shaper; X(z), Y(z),Erq(z) e Ens(z) sono le rispettive Z-trasformate.
Come si vede in Figura 2.19, ogni singolo campione a 16 bit viene “troncato” per mezzo di un quantizzatore e l’errore cosí generato viene mandato allo “shaping filter” H(z) per poi essere sommato al nuovo campione PCM in ingresso.
Per la scelta del Noise Shaper bisogna tener conto di diversi fattori [21]:
• La massima frequenza di clock utilizzabile con la tecnologia adoperata, con particolare riferimento ai contatori del modulatore PWM. Nel nostro caso abbiamo ipotizzato di poter arrivare senza problemi a frequenze di 120 MHz.
• Il SNR desiderato in banda audio; per un amplificatore di qualità tale valore deve essere quello corrispondente ad un segnale a 16 bit, ossia 96 dB, in modo che la diminuzione del numero di bit ottenuta col Noise Shaper non comporti alcun degrado del segnale. Ciò è possibile solo se si utilizza un sovracampionamento sufficientemente elevato, ma questa esigenza purtroppo si scontra con il desiderio di realizzare un amplificatore con elevata efficienza, che diminuisce se la frequenza di switching dei transistori dello stadio di potenza è eccessiva. Un compromesso è raggiunto utilizzando una frequenza di sovracampionamento pari a 352.8 kHz. • Il rumore di quantizzazione accettabile fuori dalla banda audio, che deve essere in
genere il più basso possibile per evitare di introdurre eccessiva distorsione sul segnale di uscita.
Per capire come la presenza del rumore al di fuori della banda audio influenzi la qualità del segnale in uscita all’amplificatore occorre aver chiaro il fatto che la modulazione PWM è un processo non lineare, capace (come già visto al Par.2.4.1) di provocare distorsione del segnale in banda audio. Ne segue che se il segnale di ingresso viene “noise-shaped” prima di effettuare la modulazione PWM (com’è ovvio che sia), le componenti spettrali relative al rumore prodotto dallo stesso Noise-Shaper possono subire anch’essa distorsione a seguito della modulazione [3]. Questo processo è analogo alla “distorsione per intermodulazione” studiata al corso di Teoria dei Segnali, in cui le componenti spettrali “n⋅fs” di elevata frequenza e grande ampiezza (fs è la frequenza del
segnale modulante) “ripiegano” in bassa frequenza perché “intermodulano” con la frequenza portante. Questo fenomeno può comportare la presenza in banda base di rilevanti componenti di errore; per la precisione ciò accade quando⏐fC+n⋅fs⏐ <fb ed in particolare quindi quando la frequenza di campionamento non è sufficientemente maggiore della frequenza fs del segnale di ingresso. Lo stesso fenomeno accade ora per le componenti di rumore in alta frequenza generate dal Noise Shaper, che possono venire folded back in banda audio a causa del processo di modulazione. Ne segue che maggiore è la potenza di rumore in uscita al Noise Shaper, maggiore è il problema di ripiegamento delle componenti spettrali di rumore all’interno della banda audio.
2.5.2 Rumore nel Noise Shaper
Passiamo ad analizzare in dettaglio il comportamento del Noise Shaper relativamente al rumore, in modo da capire che scelte dobbiamo fare per garantire che il segnale di uscita non risulti eccessivamente distorto.
Facendo riferimento alla Figura 2.19, indichiamo con X’(z) la Z-trasformata del segnale in ingresso al quantizzatore e cerchiamo di trovare l’espressione del segnale di uscita. Si ha: ) ( ) ( ) (z X z Ens z Y = + (2.20) e definendo ) ( ) ( ) ( z Erq z Ens z G = (2.21) possiamo scrivere Y(z)= X(z)+G(z)⋅Erq(z) (2.22)
L’ espressione di G(z) si ricava dalle relazioni:
)) ( ) ( ( ) ( ' ) ( ) ( ' ) ( ) ( ) ( ) ( ) ( ' z Ens z X z X z Y z X z Erq z H z Erq z X z X + − = − = ⋅ + = (2.23)
che mi forniscono il rapporto tra Ens(z) e Erq(z):
⇒ − = − ( )) ( ) 1 )( (z H z Ens z Erq ( ) 1 ) ( ) ( ) ( = =H z − z Erq z Ens z G (2.24)
Sostituendo l’ espressione di G(z) nella (2.22) si ottiene infine ) ( ) 1 ) ( ( ) ( ) (z X z H z Erq z Y = + − ⋅ (2.25)
La prima osservazione da fare una volta ricavata l’ espressione che lega Y(z) con H(z) è che il filtro digitale non può eliminare tutto il rumore dovuto alla riquantizzazione [7]. Affinché il sistema sia realizzabile infatti deve essere causale, ossia occorre che al numeratore di H(z) ci siano solo potenze di ‘z’ negative, in modo da garantire la
presenza di almeno un ritardo nell’anello di feedback; questo comporta l’impossibilità di usare H(z) pari a 1.
Sostituendo poi ej θ (dove θ=ωT e, ω=2πf) a z per ottenere lo spettro del segnale di uscita, si ottiene ) 1 ) ( )( ( ) ( ) ( jθ = jθ + jθ jθ − e H e Erq e X e Y (2.26)
Dall’espressione ottenuta si vede che il filtro H cambia lo spettro dell’errore di riquantizzazione tramite la funzione ( ( jθ)−1) ma non modifica il segnale.
e H
Ora si capisce quindi la ragione per cui per caratterizzare un Noise Shaper si fornisce sempre la G(z), meglio conosciuta come Noise Transfer Function (NTF): dipende infatti da lei il modo con cui la potenza di rumore viene ridistribuita nell’intervallo di frequenze compreso tra la continua e la metà della frequenza di campionamento.
2.5.3 Progetto del filtro di shaping
Come abbiamo appena visto dallo studio analitico del Noise Shaper H(z) ha il compito di modificare lo spettro dell’errore di riquantizzazione eRQ, dandogli la forma più opportuna affinché il segnale PCM non subisca un deterioramento a causa della
riduzione del numero di bit che rappresentano i singoli campioni; per questa sua funzione H(z) viene chiamato filtro di “shaping”.
In fase di progetto per minimizzare il rumore in banda audio avremmo dovuto ricorrere ad una procedura numerica di ottimizzazione per la scelta dei coefficienti di H(z), ma uno studio cosí approfondito del Noise Shaper andava oltre gli scopi di questa tesi. Abbiamo invece preferito un approccio più semplice e più comunemente usato, che consiste nel realizzare una NTF del tipo:
N
z z
G( )=−(1− −1) (2.27)
Noto il legame tra G(z) e H(z) (2.24), il filtro digitale da utilizzare è un filtro FIR di ordine N a coefficienti interi:
N
z z
H( )=1−(1− −1) (2.28)
Per quanto riguarda la scelta dell’ordine del filtro, intuitivamente sembrerebbe che N maggiore garantisca risultati migliori, ma non è sempre così. Come già accennato, in fase di progettazione di un Noise Shaper è importante la valutazione non solo del rumore presente in banda audio, ma anche al di fuori di essa.
Andiamo nuovamente a sostituire z con ej θ e facciamo alcune considerazioni. Definiamo K il guadagno di potenza di rumore, ossia il rapporto
2 2 e n K σ σ = (2.29) ove σn e σe sono le densità spettrali di potenza relative rispettivamente a eNS e eRQ. Per conoscerne il valore, basta integrare in frequenza il termine (H(z)-1):
= − = +
∫
− θ π π π θ d e H K ( j ) 12 2 1 θ π π π θ θ d e H e H j j∫
+ − + ( ) ( ) 2 1 1 * (2.30)Otteniamo così una prima importante conclusione, ossia che la potenza totale di rumore
non può mai essere ridotta dal Noise Shaper, dato che il termine sotto integrale non può mai essere negativo.
Sviluppiamo ancora l’espressione di K; nel caso di un filtro FIR con p coefficienti, H(z) può essere riscritta come
∑
(2.31) = − = N p p pz b z H 1 ) ( e quindi, dopo qualche passaggio, si ottiene
∑
(2.32) = + = N p p b K 1 2 1Il guadagno di potenza di rumore risulta così essere dipendente semplicemente dai coefficienti del filtro digitale ed in particolare una maggiore lunghezza della risposta impulsiva del filtro comporta un aumento del guadagno di potenza di rumore. Questa è la conferma del fatto che un progetto inadeguato del Noise Shaper potrebbe provocare un livello della potenza di rumore alle alte frequenze abbastanza grande da causare, dopo la modulazione, un aumento della distorsione del segnale di uscita, come descritto all’inizio di questo paragrafo. In altre parole, se cerchiamo di esercitare un maggiore controllo sulla manipolazione dello spettro del rumore di quantizzazione, il rapporto segnale rumore dell’amplificatore viene degradato.
Occorre quindi trovare un compromesso tra il vantaggio di avere un filtro di ordine elevato e lo svantaggio che comporta l’aumento di K, perché non ha senso avere una enorme attenuazione di rumore in banda audio se poi il segnale di uscita risulterà distorto a causa della grande potenza di rumore provocata dal Noise Shaper al di fuori della banda audio stessa.
Basandoci su prove sperimentali [2],[3],[7] abbiamo scelto un filtro di shaping (e una NTF) del quinto ordine; considerando che la frequenza di sovracampionamento fC, che è anche quella con la quale si presentano le parole PCM (fword) in ingresso al Noise Shaper, vale 352.8 kHz, si hanno le seguenti risposte in frequenza:
Figura 2.20: Risposte in frequenza della NTF (a) e del filtro di shaping (b) per N=5
2.5.4 Posizione del Noise Shaper
Una della maggiori limitazioni dei segnali sottoposti a Noise-Shaping [7] è che sono estremamente “fragili”, nel senso che è molto facile annullare completamente tutti i benefici acquisiti dal punto di vista della densità spettrale di potenza di rumore in banda audio. Un esempio può essere quello di applicare un’amplificazione al segnale che esce dal Noise Shaper: questa semplice operazione, svolta in ambiente digitale, può risultare estremamente dannosa, in quanto può contenere implicitamente un procedimento di quantizzazione il cui rumore associato può facilmente dominare il rumore in banda audio presente nel segnale noise-shaped. Il risultato di quanto appena detto lo si vede in Figura 2.21:
Figura 2.21: Spettro dopo l’amplificazione di un segnale noise-shaped
Come si può facilmente constatare, il vantaggio acquisito in banda audio col Noise Shaper è andato completamente perso (potenza di rumore equamente distribuita fino a 15 kHz) e come se non bastasse l’eccesso di rumore in alta frequenza tipico di un segnale sottoposto a Noise-Shaping è rimasto!
Per evitare che accadano fenomeni come quello appena descritto e per essere quindi certi di beneficiare del Noise Shaper, è assolutamente necessario inserirlo come ultimo blocco di elaborazione del segnale di ingresso, ossia immediatamente prima del modulatore. Questa è una ragione per la quale il cross-point deriver precede il Noise Shaper nelle architetture di amplificazione di segnali audio da noi prese in considerazione; l’altra ragione è che la presenza di rumore in alta frequenza che caratterizza un segnale dopo l’ operazione di shaping non permetterebbe [3] un’ efficace stima del cross-point.
2.6 Modultore PWM a due livelli
Una volta ridotto il numero di bit dei campioni PCM, ora espressi su 8 bit grazie al Noise Shaper, essi vengono utilizzati per generare il segnale PWM.
Le parole binarie in ingresso al modulatore per comodità le tratteremo come numeri interi senza segno di valore Nword compreso tra 0 e 255.
Figura 2.8: Generazione convenzionale di un segnale NPWM