6
Capitolo 1
Resource Management
Questo capitolo introduce il concetto di Griglia Computazionale (Computational Grid) ed illustra l’architettura che la descrive, dando una breve descrizione dei livelli che la compongono. Inoltre, sarà trattato uno degli aspetti fondamentali della griglia, il Resource Management.
In seguito sarà data una spiegazione di cosa si intende per una generica risorsa in un ambiente Grid, verranno illustrati gli strumenti utilizzati per rappresentarla ed i mappings esistenti tra di essi. Inoltre, è descritta la struttura che un Resource Management ha in un ambiente Grid, le problematiche che si incontrano in un tale ambiente e le soluzioni esistenti per risolverle.
7
1.1 Griglie Computazionali
La popolarità di Internet e la disponibilità di potenti elaboratori e di reti ad elevate prestazioni stanno cambiando il modo con il quale oggi vengono usati i calcolatori. Infatti, oggi è possibile organizzare una vasta gamma di risorse computazionali e di dispositivi distribuiti geograficamente, come un’unica risorsa computazionale. Tale insieme viene comunemente indicato con i termini Griglia Computazionale (Computational Grid) o, semplicemente, Griglia (Grid).
La Griglia è un’infrastruttura hardware e software che fornisce accessi “dependable” (sicuri ed affidabili), “consistent” (con un’interfaccia uniforme per accedere a risorse computazionali di tipo diverso), “pervasive” (possibilità di accedere alle risorse computazionali da qualsiasi posto di lavoro nella Griglia). Essa rappresenta un insieme coordinato di risorse geograficamente distribuite e condivise in maniera dinamica da utenti appartenenti ad organizzazioni virtuali (VO), che sono collezioni dinamiche di individui, di istituzioni e di risorse che definiscono chiaramente e accuratamente:
• che cosa è condiviso;
• a chi è permesso condividere;
• le condizioni sotto cui occorre la condivisione [1].
Inoltre, la Griglia è caratterizzata da un insieme di servizi (middleware) che includono: autenticazione, sicurezza, autorizzazione, naming, scheduling e meccanismi per l’esecuzione remota. Tali servizi hanno il compito di rendere uniforme l’interfaccia verso i diversi gestori locali della griglia stessa.
L’uso della Griglia Computazionale permette di ottimizzare l’utilizzo delle risorse computazionali, offrendo un più diffuso accesso alle risorse stesse, di richiedere risorse “on demand”, di interagire con grandi banche dati e di avere un migliore sfruttamento degli elaboratori disponibili, collegando insieme risorse di calcolo, dispositivi di memorizzazione e strumenti specializzati. La realizzazione di una Griglia richiede lo sviluppo e il dispiegamento di altri servizi oltre a quelli
8 sopra menzionati, che riguardano la gestione delle risorse, la configurazione di una griglia ed i meccanismi di accounting dell’utilizzo delle risorse.
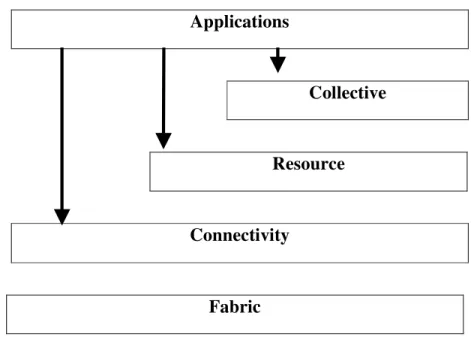
L’architettura di una Griglia viene strutturata a livelli (Figura 1.1) in cui distinguiamo i livelli: Fabric, Connectivity, Resource, Collective ed Application [1]. Il livello Fabric consiste di tutte le risorse globalmente distribuite che sono accessibili da qualsiasi posto nella rete Internet. Queste risorse potrebbero essere computers, servizi di memorizzazione, database e speciali strumenti scientifici come, ad esempio, un radio telescopio. Il livello Connectivity definisce l’insieme dei protocolli di Comunicazione e Autenticazione richiesti per le transazioni di rete specifiche per la Griglia. I protocolli di Comunicazione abilitano lo scambio dei dati tra le risorse del livello Fabric, mentre i protocolli di Autenticazione permettono di verificare l’identità degli utenti e delle risorse tramite meccanismi sicuri crittograficamente, come il single sign on, delegation, integration, user-based trust relationships. Il livello Resource utilizza i protocolli di comunicazione del livello Connectivity per definire protocolli, API e SDK che si occupino della sicurezza nella negoziazione, dell’instanziamento, del monitoraggio, del controllo e del pagamento delle operazioni effettuate su singole risorse computazionali. Le implementazioni di questi protocolli invocano le funzioni a livello Fabric per accedere e controllare le risorse locali. Inoltre, tali protocolli sono utilizzati solo su singole risorse computazionali, mentre i risultati delle operazioni eseguite su insiemi di risorse distribuite vengono trattati a livello successivo, il livello Connectivity. A livello Resource si distinguono due classi di protocolli:
• Protocolli d’Informazione, utilizzati per ottenere informazioni
riguardanti la struttura e lo stato delle risorse;
• Protocolli di gestione, utilizzati per negoziare l’accesso alle risorse
condivise.
Il livello Collective fornisce i servizi utilizzati per la gestione e la condivisione delle risorse come Directory service, Co-Allocation, Scheduling, Brokering,
9 Monitoring e Diagnostics, Data Replications. Infine, al livello più alto, troviamo il livello Applicazioni (Applications), chiamato così perché contiene le applicazioni utente che operano all’interno delle VO [2,10].
In questa architettura il Resource Management è trasversale ai livelli Connectivity, Resource e Collective, i quali forniscono gli strumenti adatti per l’uso, la gestione, la condivisione e il monitoraggio delle risorse nell’ambiente Grid.
Nel seguito di questo capitolo, per la descrizione del Resource Management per le Griglie Computazionali, considereremo il sistema Globus Toolkit 2.0, che è divenuto oramai uno standard de facto per l’implementazione e la gestione di griglie computazionali. Globus fornisce un’infrastruttura software che abilita le applicazioni a gestire le risorse di calcolo eterogenee e distribuite. L’insieme degli strumenti (toolkit) forniti da Globus consistono di un insieme di componenti che implementano i servizi base, come la sicurezza, l’individuazione delle risorse, il resource management e le comunicazioni. Architetturalmente Globus è costruito a livelli in cui i servizi globali, collocati al livello superiore, sono costruiti sulla base del nucleo dei servizi essenziali del livello inferiore. L’insieme degli strumenti di Globus è indipendente dal progetto Globus stesso e per questo un’applicazione può sfruttare le funzionalità che esso fornisce, come il resource management o l’infrastruttura di informazione, senza usare le librerie di comunicazione di Globus. Tale toolkit fornisce [10]:
• Grid Security Infrastructure (GSI); • GridFTP;
• Globus Resource Allocation Manager (GRAM); • Metacomputing Directory Service (MDS-2); • Global Access to Secondary Storage (GASS); • Catalogo dei dati e gestione delle repliche;
10 Applications Collective Resource Connectivity Fabric
Figura 1.1: Schema architetturale di una griglia computazionale.
1.2 Resource Management
Il Resource Management costituisce un’importante componente di una griglia computazionale e il suo scopo principale è di schedulare efficientemente le richieste delle applicazioni sulle risorse utilizzabili.
Il progetto di un Resource Management per Grid deve tenere conto di aspetti quali: site autonomy, heterogeneous substrate, policy extensibility, co-allocation ed online control dei task.
1 Il site autonomy riferisce il fatto che le risorse sono tipicamente possedute e gestite da differenti organizzazioni in differenti domini amministrativi.
2 Il heterogeneous substrate deriva dal site autonomy e riferisce il fatto che differenti siti possono usare differenti sistemi di resource management locali.
11 3 La policy extensibility nasce dal fatto che le applicazioni sono ottenute
da un ampio insieme di domini amministrativi, ognuno con le loro esigenze gestionali. Una soluzione di resource management deve supportare lo sviluppo di nuove strutture di gestione per domini specifici senza che venga richiesta alcuna modifica al codice utilizzato dai siti che lo utilizzano.
4 Il co-allocation deriva dal fatto che alcune applicazioni effettuano richieste per una risorsa che possono essere soddisfatte solo usando simultaneamente risorse di siti distinti. Il site autonomy e la possibilità di fallimento durante l’allocazione delle risorse introducono la necessità di meccanismi specializzati per l’allocazione di risorse multiple, l’instanziamento della computazione su queste risorse ed il monitoraggio e la gestione di tali computazioni.
5 Il problema dello online control scaturisce dalla negoziazione che può essere invocata per adattare le richieste dell’applicazione all’utilizzabilità della singola risorsa, particolarmente in presenza di applicazioni adattive che generano richieste dinamiche con conseguente variabilità nell’uso delle risorse.
Non esistono sistemi resource management che risolvono efficientemente le cinque problematiche sopra esposte [7].
Un sistema di Resource Management deve fornire dei meccanismi di controllo delle autorizzazioni e di monitoring. I primi vengono utilizzati per determinare se una richiesta per una risorsa può essere soddisfatta, mentre i secondi vengono utilizzati per assicurare che esiste il “contratto” per l’utilizzo di una risorsa, tra il sistema di gestione delle risorse e l’applicazione richiedente. Il Resource Management adotta delle politiche di Accrediting, Reclamation, Allocation e naming delle risorse. L’accrediting viene utilizzato per individuare le risorse utilizzabili per i jobs, che sono delle entità che eseguono le applicazioni di rete nell’ambiente Griglia. Reclamation viene utilizzato per recuperare le
12 risorse rilasciate dai job che hanno terminato la loro esecuzione. Allocation permette di allocare le risorse ai jobs. Il naming delle risorse è fatto attraverso uno o più namespaces che identificano unicamente le risorse presenti all’interno di una Griglia.
Infine, per garantire un utilizzo sicuro delle risorse, un sistema di gestione delle risorse può adottare diversi metodi, uno tra questi prevede l’utilizzo (e l’interazione con esso) di un security manager che autentica ed autorizza tutte le richieste per una risorsa, utilizzando le credenziali fornite dal job; l’integrità di tali credenziali verrà accertata dal security manager che gestirà, inoltre, la lista delle autorizzazioni. Per lo scambio di informazioni tra il sistema di gestione delle risorse ed il security manager viene utilizzato un canale sicuro che si assume sia una parte dell’infrastruttura della Griglia sottostante [4].
1.3 Resource in un ambiente Griglia
Le risorse in un ambiente Grid sono fornite dal livello Fabric dell’architettura Grid e l’accesso condiviso ad esse è mediato tramite l’utilizzo di specifici protocolli.
Una risorsa può essere un’entità locale, come un sistema di file distribuito, un cluster o un insieme di computer distribuiti. Inoltre è caratterizzata da informazioni di tipo statico (OS, software, numero di nodi, ecc.) e/o dinamiche (CPU load, network load, ecc). Le risorse potrebbero implementare meccanismi di richiesta che permettono la scoperta della loro struttura, del loro stato e delle loro capacità da un lato, ed dei meccanismi di gestione che forniscano controlli riguardo la qualità del servizio dall’altro. In base alle loro caratteristiche computazionali tali risorse si distinguono in:
• Risorse Computazionali: sono meccanismi richiesti per lanciare i
programmi e per monitorare e controllare l’esecuzione dei processi risultanti. Le funzioni di richiesta sono necessarie per determinare le caratteristiche hardware e software e le informazioni sullo stato della
13 risorsa, quali ad esempio il carico corrente e lo stato della coda, nel caso di risorse gestite da un sistema di scheduling.
• Risorse di Memorizzazione: sono meccanismi richiesti per scrivere e
leggere file. In questo contesto sono utili dei meccanismi di gestione che controllino le risorse allocate per il trasferimento di dati (spazio disco, capacità di memorizzazione del disco, ampiezza di banda di rete, CPU, ecc.). Anche in questo caso, come per le risorse computazionali, sono necessarie funzioni di richiesta che permettono di determinare le caratteristiche hardware e software e le informazioni attinenti alla risorsa, come lo spazio disco utilizzabile e l’occupazione di banda durante il trasferimento dei dati.
• Risorse di Rete: sono meccanismi di gestione che forniscono il
controllo sulle risorse allocate. Le funzioni di richiesta potrebbero essere fornite per determinare le caratteristiche e il carico della rete [2].
1.3.1 Rappresentazione di una Risorsa
Le risorse in una Griglia possono essere rappresentate in vari modi. Introduciamo il Lightweight directory access protocol, LDAP [11], considerato lo standard per la rappresentazione dell’informazione in una Griglia.
In generale, le directory sono usate per registrare le informazioni che saranno rese accessibili a chi (utente o risorsa) ne richieda l’utilizzo. Nelle Griglie computazionali ad ogni directory è associato un servizio, chiamato Directory service, che indica quale directory può essere acceduta attraverso un protocollo di rete. I servizi “directory service” includono meccanismi di replicazione e distribuzione dei dati.
Nella rappresentazione LDAP è necessario elencare due fondamentali entità: information provider distribuiti e gli aggregate directory services. Un information provider fornisce l’accesso ad informazioni dinamiche e dettagliate riguardanti le risorse Grid; è strutturato secondo un servizio che utilizza due
14 protocolli: il Grid Resource Information Protocol (GRIP) [5], che è usato per accedere le informazioni riguardanti le risorse e il Grid Resource Registration Protocol (GRRP) [5], che è usato per notificare agli aggregate directory services l’utilizzabilità di queste informazioni. Un aggregate directory service usa il GRIP e il GRRP per ottenere informazioni (da un insieme di information provider) riguardanti un insieme di risorse e per rispondere successivamente alle richieste che fanno riferimento alle risorse medesime.
La rappresentazione dei dati e le API (Application Protocol Interface), definite dallo LDAP directory service, sono adottate dal Metacomputing Directory Service (MDS) [19], utilizzato nell’ambiente Grid per fornire un’interfaccia uniforme a diverse sorgenti di informazione.
Nella rappresentazione MDS l’informazione riguardante le risorse è organizzata in collezioni chiamate entry. L’informazione riguardante una entry è rappresentata da uno o più attributi, ognuno consistente di un nome ed un corrispondente valore. Ad ogni entry MDS è associata una object class che definisce gli attributi ad esso associati ed i tipi di dato ed i valori che tali attributi possono assumere. Inoltre, ogni entry é identificata con un nome unico chiamato distinguished name. Per semplificare il processo di individuazione di una entry nello MDS, queste ultime sono organizzate secondo un “names space” gerarchico strutturato ad albero chiamato Directory Information Tree (DIT) [6]. Il distinguished name è costruito specificando le entry sul percorso che va dalla radice del DIT alla entry che è stata selezionata. Ogni componente nel percorso che forma il distinguished name deve identificare una specifica entry del DIT.
Il Metacomputing Directory Service include una struttura standard di information provider configurabile, chiamata Grid Resource Information Service (GRIS) [5]. Il GRIS autentica e analizza le richieste entranti di tipo GRIP e le invia successivamente a uno o più information provider “locali” secondo il tipo dell’informazione scelta nella richiesta. Inoltre, è implementato come un backend che comunica con un information provider attraverso un API. Oltre al GRIS,
15 MDS fornisce un’altra struttura utilizzata per la costruzione di una aggregate directory, chiamata Grid Index Information Services (GIIS) [5], che accetta i messaggi GRRP da altre istanze GIIS ed unisce tutte queste sorgenti di informazione in uno spazio di informazione unificato. Esso fornisce un mezzo di lavoro insieme ai servizi GRIS arbitrari per fornire un’immagine coerente del sistema che può essere esplorata o cercata da un’applicazione Grid. Le risorse dell’information provider usano il protocollo push1 per aggiornare il GRIS,
mentre le informazioni mantenute nel GIIS sono aggiornate con il protocollo pull2.
Il secondo metodo che prendiamo in considerazione per la rappresentazione delle risorse è l’eXtesible Markup Language (XML) [20]. Quest’ultimo viene utilizzato per rappresentare le risorse Grid come dei servizi, cioè la risorsa viene rappresentata prendendo in considerazione le sue caratteristiche più importanti che diventeranno gli attributi del servizio. Una volta che i servizi Grid sono definiti, la loro rappresentazione, gestione e monitoraggio sono delegati ai Web Services [13]. Il termine Web Services significa che le applicazioni distribuite saranno assemblate da una rete di servizi software nello stesso modo in cui i siti web sono assemblati da una rete di pagine HTML. I Web services sono stati progettati per fornire un’interfaccia alle applicazioni costruite usando piattaforme orientate agli oggetti come .NET, COM, J2EE. Tecnicamente i Web Services sono delle applicazioni che usano i protocolli XML e Web-based. Logicamente i Web Services rappresentano dei servizi che possono essere acceduti da qualsiasi piattaforma usando un linguaggio comune. Tale linguaggio è XML, che viene utilizzato da alcune specifiche quali il Simple Object Access Protocol (SOAP), il Web Service Description Language (WSDL), il WS-Inspection e Universal
1 Protocollo push: i dati vengono inviati dal mittente (client o server) al destinatario
(server).
16 Description Discovery and Integration (UDDI) [3,12,13]. Usando un documento XML creato sotto forma di un messaggio, un programma invia una richiesta ad un web service attraverso la rete e riceve una risposta, che può avere anche la forma di un documento XML. I Web services standard definiscono il formato del messaggio, specificano l’interfaccia a cui il messaggio è inviato, descrivono le convenzioni per mappare i contenuti del messaggio dentro e fuori i programmi che implementano il servizio e definiscono i meccanismi per pubblicare e per individuare le interfacce Web services.
SOAP è un protocollo di comunicazione basato su XML che consente anche di definire chiamate RPC (Remote Procedure Call). Lo standard SOAP definisce come rappresentare i dati di un programma in XML o effettuare chiamate da remoto. Il WSDL è un documento XML che descrive cosa un web service può fare, dove risiede e come invocarlo. Il WS-Inspection comprende un semplice linguaggio XML e le relative convenzioni per individuare le descrizioni di un servizio pubblicato da un service provider. UDDI è la specifica che consente di registrare i propri servizi Web e, permette inoltre di individuare tali servizi interrogandolo tramite messaggi SOAP. UDDI può essere paragonato alle “pagine gialle” classiche in cui si cerca un provider che offra un determinato servizio e, una volta trovato, si possono leggere le informazioni sugli altri servizi offerti dal provider e richiedere i dettagli implementativi di ciascun servizio.
Il terzo metodo che prendiamo in considerazione per rappresentare le risorse è
il CIM [9], Common Information Model. CIM è un modello di rappresentazione
dell’informazione usato nelle reti per contenere e condividere definizioni standardizzate per tutti gli oggetti gestiti. Usa tecniche proprie del paradigma orientato agli oggetti e sostituisce un insieme di associazioni e di classi con delle proprietà, che forniscono una struttura concettuale conosciuta, dentro cui è possibile organizzare l’informazione riguardante l’ambiente gestito.
17 Il CIM consiste di un definition language, che descrive le varie tecniche e costrutti usati per modellare le risorse ed utilizza un insieme di schemi (modelli) che descrivono come le specifiche risorse sono rappresentate.
Il CIM è strutturato in tre livelli distinti:
• Core Model: è un insieme di classi, associazioni e proprietà che
fornisce un vocabolario base per analizzare e descrivere i sistemi gestiti.
• Common Model: permette di catturare informazioni che sono comuni a
particolari aree di gestione, ma al tempo stesso indipendenti da una particolare tecnologia o implementazione. Le aree comuni sono sistemi, applicazioni, databases, reti, servizi. Il modello dell’informazione è abbastanza specifico per fornire una base per lo sviluppo delle applicazioni di gestione. Il Core model, insieme con il Common model, costituiscono il CIM Schema.
• Extension Schema: sono un insieme di classi aggiunte al Common
Model che rappresentano oggetti gestiti che hanno alcune caratteristiche dipendenti dalla particolare tecnologia. Queste classi si applicano ad ambienti quali i sistemi operativi UNIX, Microsoft Windows, ecc.
Nel contesto CIM sino ad ora illustrato vengono utilizzati i termini “classe” e “schema”. Una classe è una collezione di istanze che supportano le stesse proprietà e gli stessi metodi. Uno schema è un namespace di proprietà per un insieme di classi. Gli schemi sono usati per l’amministrazione e il naming della classe. I nomi delle classi devono essere unici all’interno degli schemi riconosciuti. Riguardo alla rappresentazione delle risorse, il CIM si basa sul Resource Description Framework (RDF). Lo RDF contiene tre componenti che sono: il modello dei dati, la sintassi e lo schema. Il modello dei dati è una vista semplice e generale dell’informazione e perciò relativamente facile da utilizzare
18 su altri modelli. La sintassi può essere usata per decodificare l’informazione e lo schema può essere usato per descriverla.
Nel modello RDF è necessario identificare una risorsa e per farlo viene utilizzato l’Uniform Resource Identifier (URI). La tripla <risorsa, proprietà, valore> è l’unità atomica dell’informazione RDF ed è detta stato. La proprietà è una caratteristica della risorsa ed è descritta da un valore. Il valore di uno stato invece, può essere una lettera, una stringa, oppure un’altra risorsa e, in tal caso, gli stati formano gli archi di un grafo.
Per sfruttare al meglio i vantaggi offerti dal CIM e quelli offerti da LDAP e da XML sono stati realizzati dei mapping in cui si ha la “fusione” di due di questi tre strumenti. Rispetto ai tre modelli sopra citati i mapping conosciuti sono CIM-to-LDAP e CIM-to-XML. Il primo è stato realizzato per: fornire informazioni basate su LDAP attraverso il CIM; usare il modello CIM per la gestione delle directory e per il controllo dell’infrastruttura; pubblicare informazioni basate su CIM in una directory [17]. Il secondo è stato realizzato per sfruttare la capacità di XML di esprimere i dati strutturati e per utilizzare la validazione integrata degli stessi su Web. Il mapping CIM-to-XML è nato con l’obiettivo di creare una grammatica XML scritta in DTD (Document Type Definition) [20], che sarà poi usata per rappresentare sia le dichiarazioni degli oggetti CIM (Classi, Istanze, Qualifiers), sia i messaggi CIM che saranno utilizzati (incapsulati) dai vari protocolli di rete come ad esempio HTTP [18].
1.4 Struttura di un Resource Management
Il Resource Management è una parte centrale della piattaforma di elaborazione Grid. La sua funzione base è accettare le richieste di elaborazione da macchine all’interno della Griglia e di assegnare ad una richiesta una specifica macchina in modo che l’utente possa accedere alle risorse di calcolo.
19 All’inizio del capitolo sono state elencate alcune problematiche del resource management in un ambiente Grid, che sono: il site autonomy, lo heterogeneous substrate, la policy extensibility, la co-allocation e lo online control. Non esistono, attualmente, sistemi che risolvono tutte queste problematiche, infatti alcuni sistemi batch queuing supportano la co-allocation, ma non il site autonomy e la policy extensibility; Condor [15] supporta il site autonomy, ma non la co-allocation o lo online control; Legion [14] e Gallop [16] risolvono lo online control e la policy extensibility, ma non le problematiche di co-allocation o di heterogeneous substrate.
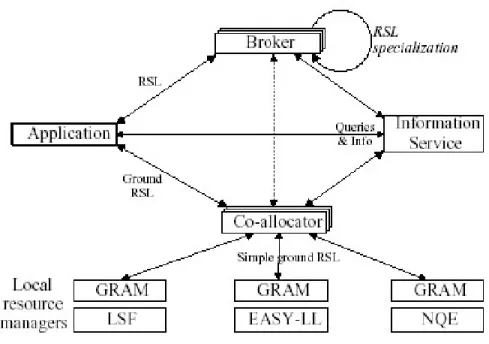
Per risolvere queste problematiche è stata sviluppata, nel contesto del progetto Globus, un’architettura per la gestione delle risorse, schematizzata in Figura 1.2. Questa risolve le problematiche del site autonomy e dello heterogeneous substrate, introducendo delle entità chiamate resource managers che forniscono un’interfaccia verso i diversi meccanismi di sicurezza, le politiche e gli strumenti per il resource management locale. Per lo online control e la policy extensibility è stato definito un resource specification language (RSL) [7], che supporta la negoziazione tra differenti componenti di un resource management e viene introdotto il resource brokers per gestire il mapping delle richieste di un’applicazione ad alto livello nelle richieste agli scheduler locali. Infine, per risolvere la problematica della co-allocation, nell’architettura vengono definite varie strategie di allocation che sono incapsulate nel resource co-allocators.
20
Figura 1.2: Architettura del resource management in Globus.
Come si può vedere in Figura 1.2, lo RSL è usato per comunicare le richieste di risorse ai vari componenti. I resource broker ricevono in input le specifiche RSL ad alto livello e le trasformano in richieste specializzate per i vari componenti del sistema di allocazione delle risorse attraverso un processo chiamato specialization. Le trasformazioni effettuate dai resource broker generano una specifica in cui le locazioni delle risorse richieste sono completamente specificate. Ad esempio, una di queste richieste specializzate, detta round request è passata al componente co-allocator, il quale è responsabile di coordinare l’allocazione e la gestione delle risorse possedute da differenti siti.
L’information service è responsabile principalmente di fornire un accesso efficiente e pervasivo all’informazione riguardante l’utilizzabilità e la capacità delle risorse nel momento in cui vengono richieste. Questa informazione è usata per individuare le risorse con specifiche caratteristiche, per identificare il resource manager associato con una risorsa e per determinare le proprietà di tale
21 risorsa. In questa architettura, l’information service è costituito dal Metacomputing Directory Service (MDS).
Nel livello più basso dell’architettura del resource management troviamo i resource managers locali la cui implementazione è chiamata Globus Resource Allocation Management (GRAM) [7]. Ogni singolo GRAM è usato per:
1. elaborare le specifiche RSL che rappresentano le richieste per la risorsa, rifiutando la richiesta o creando un processo (“job”) per la sua gestione;
2. abilitare il monitoraggio remoto e la gestione dei jobs creati per soddisfare una richiesta;
3. aggiornare periodicamente lo MDS information service con informazioni riguardanti l’utilizzabilità e le capacità delle risorse che vengono monitorate.
Il GRAM è usato come interfaccia tra un ambiente metacomputing e un’entità autonoma abile a creare processi, come un computer parallelo o un Condor pool. Questo significa che un resource manager non ha bisogno di coincidere con un singolo host, ma piuttosto con un servizio che agisce per conto di una o più risorse computazionali.
La specifica di una risorsa passata ad un GRAM è assunta essere ground, cioè essere sufficientemente concreta in modo che il GRAM può identificare le risorse locali che la soddisfano senza ulteriori interazioni con l’entità che ha generato la richiesta. Una particolare implementazione GRAM può ottenere questo obiettivo schedulando le risorse o, più comunemente, “mappando” la specifica di una risorsa in una richiesta per alcuni meccanismi di allocazione delle risorse locali (es. Condor, EASY, Fork, LoadLeveler, LSF, NQE).
In breve, il funzionamento di un GRAM è il seguente: un GRAM prende una richiesta come input, l’autentica utilizzando il Globus Security Infrastrutture (GSI) e se la richiesta è stata accettata la sottomette agli schedulers locali per individuare la risorsa e creare un job a cui è associato un “job handle”. Il
22 processo richiedente può usare il job handle per monitorare e controllare lo stato della computazione creata.
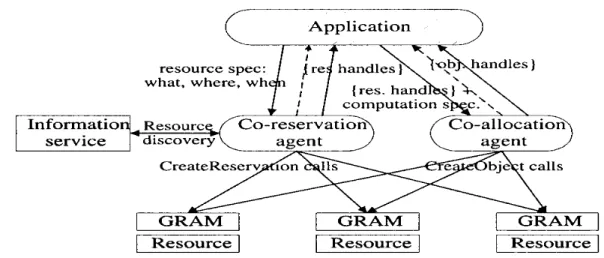
Questa architettura ha influenzato fortemente il successivo progetto per il resource management, ovvero il Globus Architecture for Reservation and Allocation (GARA) [8] in Globus. Il GARA, infatti, estende l’architettura resource management precedente in due modi principali: introduce un generico resource object, che include i flussi di rete, i blocchi di memoria, i blocchi disco e altre entità come i processi; introduce un’entità (classe) nell’architettura resource management detta reservation. Un generico resource object può essere creato invocando l’operazione “Create Object”, la cui chiamata restituisce un object handle che può essere usato per monitorare e controllare la risorsa. Per quanto riguarda reservation, invece, il GARA divide l’incarico di creazione di un resource object in due fasi: reservation ed allocation. Nella fase di reservation avviene la creazione di una reservation e questo assicura che la successiva richiesta di allocazione avrà successo. Nella fase di allocazione viene restituito il “reservation handle” che può essere usato per monitorare e controllare lo stato della reservation e può, inoltre, essere passato alla successiva chiamata “Create Object” per associare tale object alla reservation. Per creare una reservation viene utilizzata una operazione “Create Reservation” generica, che interagisce con i resource management locali per assicurare che la quantità e la qualità delle risorse richieste sarà utilizzabile al tempo di inizio richiesto e rimarrà utilizzabile per la durata desiderata. Come illustrato in Figura 1.3 il GARA introduce una nuova entità chiamata co-reservation agent che ha il compito di scoprire una collezione di risorse che può soddisfare l’insieme delle richieste di QoS (quality of service) per un’applicazione end-to-end. Quindi, una chiamata ad un co-reservation agent specifica richieste di QoS e ritorna un insieme di co-reservation handle, che può essere successivamente passato ad un co-allocation agent. Rispetto alla precedente architettura, in GARA il co-allocation agent ha il
23 compito più semplice di allocare un insieme di risorse, dato un reservation handle generato da un co-reservation agent [8].