CAPITOLO II
Generatore di Traffico
Per il sistema MC-CDMA
II.1 Introduzione
Nel presente capitolo saranno analizzati gli aspetti del generatore di traffico per il sistema MC-CDMA di cui si era in precedenza accennato. Il sistema MC-CDMA deve essere provvisto di un generatore di traffico che simuli il comportamento di una cella di un sistema cellulare e dunque, l’ingresso e l’uscita degli utenti. In particolare saranno descritte le caratteristiche del generatore di traffico, il tipo di traffico che deve generare, alcune funzioni aggiuntive del programma che saranno utili nei capitoli successivi, come ad esempio, l’assegnazione di codici secondo leggi ben precise; inoltre analizzeremo il programma in modo esaustivo per spiegare secondo quali leggi statistiche e matematiche si può simulare un modello di traffico che si avvicini abbastanza al traffico reale che caratterizza una base station di un sistema radiomobile ; in ultima analisi verranno forniti i risultati delle simulazioni.
Il sistema di trasmissione MC-CDMA prevede un numero di portanti pari a L, il suo fattore di spreading. Ovviamente tali portanti non saranno attive dal primo istante in cui si inizia ad osservare il sistema, tutt’altro: dove non sarà detto diversamente, si ipotizzerà che il sistema all’inizio sia scarico e che gli utenti entrino a poco a poco secondo determinate leggi statistiche.
Capitolo II
37
II.2 Caratterizzazione statistica del Generatore di
Traffico
Per focalizzare il problema, si immagini di trovarsi all’interno di un sistema di comunicazione cellulare: uno dei primi obiettivi che ci si pone è quello di fornire dei margini per la valutazione delle performance e per il dimensionamento di una cella di un sistema di questo tipo.
Molteplici studi sono stati effettuati in questo campo [6],[8],[9], prendendo in considerazione sistemi cellulari con diversi scenari di traffico e con un determinato numero di celle; tuttavia, proprio in base a questi studi, possono essere tracciate delle caratteristiche comuni che costituiranno la base su cui è stata implementata la presente trattazione.
I modelli che vengono usati per rappresentare i sistemi CDMA sono le catene di Markov di tipo M/M/k/k e le M/M/∞. In tali casi la capacità del sistema è o fissa o infinita.
Si consideri la tratta downlink di un sistema come quello descritto in precedenza e si supponga che questa introduca le problematiche più limitanti, dal punto di vista delle prestazioni: sotto queste ipotesi, si verifica un blocco del sistema ogniqualvolta la totalità degli utenti all’interno della cella considerata e delle altre celle vicine, introduce una densità di interferenza che supera di una certa soglia il valore del livello di rumore.
In tali casi la capacità del sistema non è né fissa né infinita: pertanto i modelli di Markov prima citati non sono caratteristici di questo tipo di struttura.
Si consideri allora l’interferenza modellabile come un processo gaussiano, in accordo al teorema del limite centrale nel caso di molti utenti attivi.
È necessario trovare un modello per descrivere la MAI (Multiple Access Interference) del sistema MC-CDMA dopodichè si assumerà che la capacità del sistema sia limitata dalla MAI stessa.
Si focalizzi l’attenzione su un’unica cella del sistema multicellulare che utilizza lo schema del MC-CDMA, la base station è collocata al centro della cella.
Capitolo II
38 La base station è equipaggiata con un’antenna omnidirezionale in grado di lavorare su due gamme di frequenze diverse per quanto riguarda le due direzioni di propagazione del segnale (uplink e downlink).
Come già accennato, ci si concentrerà adesso sulla sola tratta in downlink che è quella che in generale limita le prestazioni di questo tipo di sistemi.
Con queste ipotesi fatte, s’ignori in prima analisi il rumore gaussiano introdotto dal canale AWGN e si assuma che il rapporto segnale-rumore sia da imputare unicamente al rapporto segnale-interferenza.
Le chiamate degli utenti hanno una distribuzione degli arrivi che può essere descritta da un processo di Poisson con densità di probabilità data da:
P su!" in
( )
n = j#$ =% &Tframe
(
)
jj! & exp '% &T
(
frame)
j= 0,1,....(N ! 1) (2.2.1)In cui il primo membro rappresenta la probabilità che all’istante n il numero di arrivi sia pari a j (con j che può assumere un valore compreso tra 0 e N-1), in seguito si supporrà che il numero massimo di arrivi contemporanei non può essere superiore a 6 (N=7).
Nella formula (2.2.1) compare ! che rappresenta il tasso d’arrivo delle chiamate nella cella (espresso in arrivi al secondo o Erlang) e Tframe rappresenta la durata di un
blocco OFDM.
Nella presente trattazione il problema dell’hand-off verrà trattato in maniera semplificata: se una cella lavora già al massimo delle sue capacità, non può ovviamente offrire un servizio ad utenti che si aggiungono, pertanto tali utenti sono instradati nelle celle vicine.
Per questo tipo di chiamate, sarebbe necessario prevedere un secondo modello statistico che descriva la probabilità che si verifichi l’hand-off e il modo in cui dovrebbero essere trattate le chiamate che ne derivano.
Per quanto riguarda i nostri scopi, considerare le priorità di chiamate derivanti da hand-off sarebbe una complicazione che in ogni modo non fornirebbe informazioni utili alle misure, pertanto le chiamate che derivano da hand-off saranno trattate come se fossero delle semplici chiamate: chiamate nuove e chiamate trasferite da un’altra
Capitolo II
39 cella hanno lo stesso livello di priorità, o meglio, l’hand-off non ha nessuna priorità rispetto ad una chiamata semplice.
I tempi di durata delle chiamate vengono modellizzati con una variabile con distribuzione esponenziale negativa data da:
fT
( )
t =µm! exp("µmt) con T = 1 µmDove T rappresenta il tempo medio di permanenza di un utente nella rete.
In base al modello appena esposto si può dire che un utente che entra nella cella o completa il suo servizio in un tempo medio pari a T oppure esegue un hand-off, in tal caso il suo valore di permanenza nella cella sarà un certo Th tale che:
Th < T
ma come è distribuita Th?
Si chiami TN il tempo che una certa chiamata impiega in una cella, TN sarà distribuita
esponenzialmente allo stesso modo di T pertanto:
Th = min T,T
[
N]
e di conseguenza:fTh
( )
t =(
µN +µm)
! exp "#$(
µN +µm)
!t%&invece la probabilità che una chiamata abbia bisogno di un hand-off è:
Pr T
{
N < T}
=µN
µN +µm
Capitolo II
40 Eseguito il primo hand-off dopo un tempo ! , la chiamata potrebbe terminare nella nuova cella oppure aver bisogno di un secondo hand-off; coerentemente con quanto visto prima, questo secondo tempo di permanenza può essere così espresso:
Th2 = min T#$
(
m!")
,Th%&inoltre, la distribuzione di questo tempo di permanenza risulta:
fT
h 2 =
(
µh +µm)
! exp "#$(
µh +µm)
!t%&e la probabilità che si verifichi un secondo hand-off è:
Pr T
{
h2 < (Tm!" )}
=µh
µh +µm
= H2
dalle considerazioni appena enunciate si può estrapolare il tempo medio di permanenza di un utente in una cella; indicando con ! la porzione di arrivi in una cella dovuti a hand-off (!H) rispetto alla totalità degli arrivi (!), si può scrivere:
! = "H
"
infine il tempo medio di permanenza nella cella ha una distribuzione esponenziale negativa con valor medio dato da:
E T
{ }
a = 1 µa =! " E T{ }
h2 + (1#! )" E T{ }
h ossia: E T{ }
a = 1 µa = ! µh+µm + 1"! µN +µmCapitolo II
41 inoltre dovremo calcolare il tasso di arrivo come la somma delle chiamate nuove più quelle dovute a hand-off :
! = !N +!H
definendo adesso BN la probabilità di blocco di una chiamata e assumendo che le
chiamate di entrambi i tipi vengano bloccate con la stessa probabilità avremo che:
!= 1+
(
1" BN)
# H1 1" 1" B(
N)
# H2 $ %& ' () * + , , -. / /#!Nper cui alla fine il sistema MC-CDMA che si va a studiare avrà dei tassi di arrivo poissoniani ! e dei valori medi dei tempi di servizio Ta come quelli appena calcolati.
II.3 Bounds per le performance di rete di un sistema
cellulare
Scopo del presente paragrafo è fornire dei margini per le prestazioni e il dimensionamento di una rete mobile. L’obiettivo non è quello di fornire un modello che rappresenti il traffico in modo realistico, bensì stabilire dei limiti nella distribuzione e nel comportamento degli utenti entro i quali la rete possa lavorare. Si farà uso di un modello conservativo caratterizzato da una coda M/M/k-type e di un modello ottimistico definito da una coda M/M/k/k-type.
Capitolo II
42 Nelle precedenti definizioni con M/M s’intende la markovianità dei processi d’arrivo e della distribuzione dei tempi di servizio, questa proprietà è garantita dalle caratteristiche statistiche descritte nel paragrafo II.2.
Modello M/M/k/k-type
Questo tipo di modello assume che la cella abbia le caratteristiche di una coda M/M/k/k-type. Ogni nuova chiamata nella cella, cercherà come prima opzione un canale vuoto. Nel caso non vi siano posti liberi, l’utente viene rifiutato e non compare più nel sistema. In questo modello non si prevede che l’utente possa provare di nuovo a chiamare, lo stesso avviene per le chiamate derivate da hand-off. Nella notazione utilizzata la prima k rappresenta il numero di serventi, la seconda k il numero di utenti in coda, infine con type si indica la disciplina di coda. Questo modello risulta troppo ottimistico, pertanto se ne seguirà uno più conservativo.
Modello M/M/k-type
Non è realistico pensare che un utente che si veda rifiutato un servizio, non tenti di chiamare una seconda volta, pertanto nel modello M/M/k-type si prevede che gli utenti rifiutati continuino nella loro richiesta di servizio finché non ottengono un canale libero. In questo modello si realizza una sorta di fila d’attesa nel sistema: gli utenti che vedono rifiutato il servizio tentano all’infinito di conquistare un canale libero, si ricrea uno stato fittizio secondo il quale l’utente che richiama viene fatto attendere finchè non si libera il primo canale, come in una sorta di “fila d’attesa infinita”.
L’utilità di considerare questo tipo di sistemi sta nel fatto che le code M/M/k possono essere trattate analiticamente, perciò si è soliti considerare il sistema cellulare come una rete di code in cui ciascuna cella è rappresentata da una coda di questo tipo. La k nella notazione indica il numero di serventi, il fatto che non si indichi il numero di utenti che la coda prevede significa che tale valore è infinito, infine anche qui type indica la disciplina di coda.
Capitolo II
43 Per completezza bisogna dire che questo modello viene a sua volta sdoppiato in due casi che prendono il nome di M/M/k – QCH (Queued Call Hand-Over) e di M/M/k – W/O QCH (Without Queued Call Hand-Over). I due modelli considerano un ulteriore parametro libero, ossia se gli utenti in “fila d’attesa” possano o meno effettuare un hand-off dalla loro condizione e trovare un servizio in una cella vicina, prima che nella cella dove si trovano nell’istante in questione. Per non complicare ulteriormente la trattazione utilizzeremo sistemi che non prevedono questa ulteriore possibilità e, solo per questi, enunceremo un’analisi sul modello di Jackson che condurrà a delle considerazioni importanti per attribuire ai parametri del traffico dei valori veri e propri.
Si consideri adesso un sistema costituito da code di tipo M/M/k, la suddetta rete di Jackson, e si definiscano i seguenti parametri:
PT
( )
i = probabilità di blocco della cella i!i = tasso di arrivo nella cella i
^
P
ij = probabilità che un utente entrato in i esegua hand-off su jinoltre si può scrivere che:
^
P
ij = 1 mi ^µ
i ! Pijdove Pij rappresenta la probabilità di transizione ad un passo (tali probabilità si
possono disporre in una matrice N*N in cui ciascun valore rappresenta la probabilità di transizione da una cella a un’altra vicina, la somma su una riga di tali probabilità vale 1).
Capitolo II 44 ^
µ
i =µi+ 1 midove µi sono i reciproci dei tempi medi di servizio esponenziali, mentre mi sono i
reciproci dei tempi medi di hand-off. Inoltre : ^
P
exit( )
i = µi ^µ
indica la probabilità di uscita dalla cella i senza effettuare hand-off , infine:
^
!
i =!i+ ^!
j "P
^ji i# j$
per ognuna delle N celle
rappresenta gli arrivi totali nella cella i, dovuti al generatore di traffico e alle chiamate che hanno subito hand-off.
Fatte queste premesse, si considererà adesso un traffico simmetrico, cioè uguale per ogni cella per cui:
!i =! µi =µ mi = m !i ( 2.3.1 )
ricordando la condizione per cui il modello M/M/k rimane stabile:
! = "
k#µ < 1 (2.3.2)
si può dimostrare che la probabilità di blocco in questo caso è data dalla Formula C di Erlang.
Capitolo II 45 ^
!
=!
^ i ^µ
=µ
^ isenza perdere di generalità si consideri un’unica cella con i seguenti valori caratteristici:
!, µ, m, Pij = 1
6 dove inoltre N=6, per questa cella si può dire che:
^
!
= ^"
k# ^µ
si dimostrerà che ! = ^!
: ^!
= ^"
k# ^µ
= ^"
k# µ + 1 m $ %& '() = " ^ k # m mµ + 1 $ %& ' () inoltre: ^!
=!+ 6!^" 1 m µ+ 1 m # $ % % % & ' ( ( ( "1 6 =!+ !^ mµ+ 1= ! µ mµ+ 1 m # $% &'( e infine: ^!
= " µ# mµ+ 1 m $ %& '()# 1 k# m mµ+ 1 $ %& ' () = " k#µ =! dopodiché essendo ! = ^Capitolo II
46 Dopo aver visto la caratterizzazione statistica del sistema e i parametri che entrano in gioco, forniremo adesso dei valori numerici per la trattazione di tali sistemi, valori che andremo ad utilizzare all’interno delle nostre simulazioni.
Si considereranno tre tipi di traffico in ingresso: Real Time, Streaming e Data, le caratteristiche statistiche sono le medesime per ogni tipo di traffico, quello che cambieranno saranno i valori numerici dei parametri.
I valori che sono forniti concordano con [10],[19]: Intervallo di segnalazione=Tchip= 50 nsec;
Tblocco= Tchip*(L+prefisso)=50nsec*(256+64)=16msec; 180sec RT T = 180sec S T = 60sec D T = ;
Dove con Tchip si indica la durata di un chip, ossia di un simbolo di codice, invece con Tblocco si indica la durata di un blocco OFDM, le T rappresentano i valor medi dei tempi esponenziali di servizio per i tre tipi di traffico.
Adesso considereremo in accordo a [ ] un Throughput aggregato e in base a questo calcoleremo i corrispettivi valori dei tassi d’arrivo nei tre casi:
[6.2,6.8,7.2]
10 ! =
da cui derivano tre scenari a seconda del valore del Throughput
( )
! che si sceglie:SCENARIO con BASSO TRAFFICO , ! = 106.2
SCENARIO a TRAFFICO MEDIO, ! =106.8
SCENARIO a TRAFFICO ALTO, ! =107.2
In base a questi valori di Throughput, calcoleremo i tassi di arrivo, supponendo che i tipi di traffico siano equamente ripartiti, ciascuno con le caratteristiche statistiche precedentemente descritte e ciascuno con i valori statistici appena enunciati.
Capitolo II
47 Inoltre dovremo considerare la tratta d’interesse (downlink) e la percentuale di traffico che mediamente si trova in questa tratta: per i nostri scopi supporremo che il traffico realtime sia equamente distribuito tra uplink e downlink, lo streaming invece si troverà per il 70% in downlink, infine il traffico dati coprirà l’80% in downlink. Le velocità di trasmissione sono riferite a [progetto primo]:
SCENARIO MEDIO 6.8 1 3 33% 33% 10 1 sec % 0.04017sec 144 10 180 2 sec RT downlink RT bit kbit v T ! " # $ %&') (* % = % = % = % % # $% ' ( ) * 6.8 1 3 33% 33% 10 7 sec % 0.0211sec 384 10 180 10 sec S downlink S bit kbit v T ! " # $ %&') (* % = % = % = % % # $% ' ( ) * 6.8 1 3 33% 33% 10 8 sec % 0.0723sec 384 10 60 10 sec D downlink D bit kbit v T ! " # $ %&') (* % = % = % = % % # $% ' ( ) *
Nello stesso modo troveremo:
SCENARIO ALTO 1 0.1009sec RT ! = " 1 0.0530sec S ! = " 1 0.1816sec D ! = "
Capitolo II 48 SCENARIO BASSO 1 0.0100sec RT ! = " 1 0.0053sec S ! = " 1 0.0182sec D ! = "
Si noti che tutti questi valori verificano la condizione di stabilità ( 2.3.2 ).
II.4 Descrizione del Generatore di Traffico
I programmi che implementano il generatore di traffico sono due (la versione base e una sua variante) e sono abbastanza simili tra di loro, si descriverà in maniera esaustiva solo il primo, mentre ci si limiterà a descrivere le differenze con l’altro. I parametri su cui si può agire, dal file d’ingresso sono i seguenti:
Tblocco RT T S T D T RT ! S ! D ! L Numero di Portanti Tipo di Allocazione
Capitolo II
49 Questi parametri devono essere inseriti nel file d’ingresso, uno per riga, in questo ordine. Il significato dei simboli è coerente con quanto spiegato in precedenza, ci soffermeremo solo sul Numero di Portanti (che sarà utile solo nella variante del programma) e sul Tipo di Allocazione. Ad ogni utente che entra nel sistema, deve essere assegnato uno degli L codici disponibili, ogni codice deve essere assegnato solo una volta, in base ad una precisa legge. Il Tipo di Allocazione descrive questa legge, il programma implementa due tipi di legge a seconda che si assegni a questo parametro il valore 0 o il valore 1:
0= i codici vengono assegnati in modo random,
1= i codici vengono assegnati secondo un algoritmo di allocazione, letti da file. Il programma inizia con la lettura del file d’ingresso, i valori sopra citati vengono caricati in apposite memorie, dopodichè nel caso di allocazione guidata si procede a caricare in un vettore i codici contenuti nel file dell’allocazione guidata, il vettore prende il nome di CODE[L] e ha dimensione L.
Subito dopo si hanno le inizializzazioni delle memorie dinamiche: il vettore
UTENTI[i], con i che va da 0 a Nu-1 e con Nu=L, assume valori 1 o 0 a seconda che
l’utente i-esimo sia o meno attivo; nel caso che l’utente sia attivo, a questo deve essere assegnato uno degli L codici disponibili, il codice che viene assegnato è indicato da EXIT[i], inoltre il vettore AUX[EXIT[i]] dice se i codici contenuti in
CODE[i] sono già stati usati per un utente (1) oppure no (0). All’arrivo di un utente
deve essere assegnato un codice, ma anche un valore di durata del suo servizio, questo valore è assegnato con proprietà statistiche ben precise (che saranno analizzate a breve), per ora ci si limiti a considerare che viene assegnata una durata per ciascuna chiamata e tale durata viene memorizzata nel vettore DURATA[i]. Tutte le memorie dinamiche appena descritte vengono inizializzate in maniera coerente col fatto che il numero di utenti iniziali attivi nella cella è nullo:
su_prec=0;
di conseguenza il vettore UTENTI avrà tutti zero, cosi come AUX e DURATA, invece per EXIT si è scelto un valore iniziale pari a L, poiché lo 0 corrisponde a un valore di codice effettivo (i valori di codice con L=256 vanno infatti da 0 a 255). Finite le inizializzazioni, il programma entra nel suo ciclo principale. Per capire meglio come agisce questo blocco si faccia riferimento alla Fig. II.1; un giro
Capitolo II
50 completo di questo blocco, realizza la generazione d’utenti in un istante n, l’aggiornamento ad ogni istante è realizzato dalla seguente formula:
su _ attuale(n)= su _ prec(n) + suIN _ RT (n) + suIN _ S(n) + suIN _ D(n) ! suOUT (n)
ovvero sia, il numero di utenti attivi all’uscita del ciclo all’istante n è pari al numero di utenti presenti al passo immediatamente precedente (su_prec) più quelli che sono stati generati all’istante n (divisi per tipo di traffico Real Time, Streaming e Data) meno quelli che hanno finito il loro servizio durante lo stesso istante.
REAL TIME STREAM DATA USCITA REMOVE CODE CODE CODE CODE su_prec suIN_RT suIN_S suIN_D suOUT su_attuale
Fig. II.1- Schema del Generatore di Traffico
In figura ciascun blocco esegue un’operazione ben precisa, la cooperazione dei vari blocchi realizza un ciclo completo del generatore e sviluppa le sue funzionalità. Ogni blocco è caratterizzato da un colore, blocchi dello stesso colore realizzano la stessa operazione, ma per valori d’ingresso diversi.
Capitolo II
51 Il generatore, ad ogni suo ciclo, deve contare quanti utenti vengono generati per ogni tipo di traffico previsto, quanti utenti escono complessivamente, inoltre per ogni utente arrivato deve assegnare un codice tra quelli disponibili e per ogni utente uscito deve liberare il codice corrispondente che si è reso di nuovo disponibile in conseguenza della fine del servizio di tale utente.
Si analizza ora il funzionamento di ciascun blocco, nello stesso ordine seguito dal programma.
Il blocco REAL TIME riceve in ingresso il valore di su_prec=0 , inizializza cont=6 (il numero massimo di utenti che possono entrare in un istante) e predispone una memoria dinamica PsuIN_RT[cont+1] inizializzata a zero.
A questo punto si calcola la probabilità che entrino p utenti con p che va da 0 a 6, mediante la formula (2.2.1):
P su!" in
( )
n = j#$ =% &Tframe
(
)
jj! & exp '% &T
(
frame)
per j=0,….,6 (2.2.1)ovviamente la probabilità che entri un utente è maggiore di quella per due utenti, così come quella per due utenti sarà maggiore rispetto a quella per tre utenti, e così via… e comunque ciascuna probabilità sarà inferiore a 1.
Adesso si genera un numero casuale compreso tra 0 e 1, che nel programma viene chiamato numero1 ; in base al confronto tra numero1 e i valori delle probabilità calcolate in PsuIN_RT[cont+1], si determina il numero di utenti di traffico REAL TIME arrivati all’istante n.
Gli utenti arrivati devono essere accolti, all’inizio la cella è completamente scarica, dunque tutti gli utenti che arrivano vengono anche accolti, ma man mano che il generatore va avanti, si potrebbe riempire, per questo è necessario predisporre un controllo per l’allocazione degli utenti, si contano dunque i posti liberi come:
PL=Nu-su_prec;
Se il numero di posti liberi è maggiore o uguale al numero di utenti arrivati, si allocano tutti gli utenti arrivati, altrimenti se ne allocano solo un numero pari ai posti ancora disponibili e si scartano gli altri, tale numero è espresso da suIN_RT.
Capitolo II
52 Si passa a riempire il vettore UTENTI[i], per ciascun utente accolto i, si setta un 1. Ad ogni utente allocato viene inoltre assegnato un valore di DURATA[i] del servizio, tale valore viene assegnato mediante la formula []:
log(1 ) RT U X T ! = !
Dove U è una variabile aleatoria uniformemente distribuita, generata del programma e nominata numero3 , dopodiché su di essa si esegue una trasformazione in variabile esponenzialmente distribuita con valor medio del tempo di servizio pari a T ; tale RT variabile nel programma si chiama expo:
U=numero3 Expo= X
Tale valore di expo è il valore che assume anche il vettore DURATA[i] al posto corrispondente all’utente i che è stato appena generato.
A questo punto il lavoro del blocco REAL TIME è concluso e si passa al blocco CODE, che si occupa di assegnare un codice a ciascun utente allocato dal blocco precedente.
L’allocazione avviene in due modi diversi a seconda del valore di tipo contenuto nel file d’ingresso.
Allocazione Random
Per ogni utente i appena allocato si genera un valore di probabilità compreso tra 0 e L-1 che si chiama numnum, si controlla che il valore AUX[numnum] corrispondente al numero appena generato sia nullo e in caso affermativo si assegna tale valore di codice nel posto del vettore EXIT[i] corrispondente all’utente in considerazione e si pone il valore AUX[numnum]=0, in modo che all’iterazione successiva non possa essere assegnato ad un altro utente; nel caso in cui AUX[numnum]=1 si procede a generare un nuovo valore compreso tra 0 e L-1, finché non se ne trovi uno libero.
Capitolo II
53 Allocazione Guidata
In questo caso, per ogni utente i appena allocato si va a scorrere il vettore AUX[j] finché non si trova il primo valore di j per cui AUX è nullo (in questo modo si alloca in maniera ordinata dal primo all’ultimo codice, secondo l’ordine descritto da CODE) a questo punto si pone:
EXIT[i]=CODE[j]; AUX[j]=1 ;
In questo modo, ad ogni utente viene assegnato il primo codice disponibile dal file di allocazione guidata, e si rende non più disponibile tale codice per le successive allocazioni.
A questo punto il compito del blocco CODE è esaurito e si passa al blocco STREAM e DATA che eseguono le stesse operazioni viste con REAL TIME e forniscono i valori di suIN_S e suIN_D, anche se con caratteristiche statistiche diverse di caso in caso. Ciascun blocco fornisce dunque il numero di utenti allocati, riempie le relative memorie e passa i propri dati ai rispettivi blocchi CODE che provvedono ad allocare i codici liberi agli utenti appena generati.
Si arriva al blocco USCITA: questo blocco verifica i valori assunti dal vettore
DURATA che saranno nulli per gli utenti inattivi e diversi da zero per gli utenti attivi.
Ad ogni ciclo questo esegue la seguente operazione per tutti gli utenti:
if(UTENTI[i]==1) { DURATA[i]=DURATA[i]-Tblocco; if (DURATA[i]<=0) { PsuOUT[i]=1; } } else PsuOUT[i]=0;
Capitolo II
54 ovvero, per ogni utente attivo si decrementa il valore di DURATA di un unità di tempo (un ciclo ha come unità temporale il valore di un Tblocco), se, in conseguenza di decrementi successivi, il valore di DURATA[i] per un utente i raggiunge un valore minore o uguale a zero, si assume che tale utente i abbia esaurito il suo servizio dentro la cella ed esca. In tal caso la memoria dinamica PsuOUT[i] registra questo fatto settando ad 1 il posto occupato dall’utente i che ha appena terminato il servizio. Il controllo viene eseguito su tutti gli utenti attivi, poiché quelli inattivi, non essendo presenti non possono neanche terminare il servizio.
A questo punto non si fa altro che contare quanti valori sono stati settati ad 1 durante un ciclo e in questo modo si ottiene il valore finale di su_OUT.
Si arriva al blocco REMOVE CODE: tutti gli utenti che abbandonano la cella liberano i codici che tenevano occupati, pertanto in conseguenza dell’uscita dell’utente i verranno riportate le memorie dinamiche ai valori iniziali, ossia UTENTI[i] e
DURATA[i] vengono riportate a zero EXIT[i] viene riportato a L e AUX[EXIT[i]] a
zero, in questo modo i codici sono di nuovo disponibili per essere allocati in cicli successivi.
Infine il generatore esegue l’operazione:
su _ attuale(n)= su _ prec(n) + suIN _ RT (n) + suIN _ S(n) + suIN _ D(n) ! suOUT (n)
che fornisce il numero di utenti attivi all’uscita del ciclo.
Prima della chiusura del ciclo si setta il parametro su_prec=su_attuale in modo che al ciclo successivo si riparta dal numero effettivo di utenti presenti .
Il programma fornisce un file d’uscita “FlussoTraffico.txt” che prevede una prima colonna che riporta i cicli in funzione del tempo trascorso (n*Tblocco), tre colonne con gli arrivi per ciascun tipo di traffico, una colonna delle uscite e il totale degli utenti attualizzato, inoltre accanto all’ultima colonna, tra parentesi quadre compaiono i codici assegnati in corrispondenza di ciascun utente attivo.
Questo è il funzionamento della versione base del programma che implementa il generatore di traffico, esiste un’altra versione di questo programma.
La variante prevede un ulteriore parametro libero costituito dal numero di sottoportanti: la versione base assume che dato L fattore di spreading, le portanti
Capitolo II
55 siano automaticamente L, nella variante invece si suppone che L e il numero di portanti (anzi in questo caso sottoportanti) possa essere diverso, ad esempio:
se L=256 e si suppone di lavorare con 16 sottoportanti, ciascuna sottoportante avrà un valore di codice compreso tra 0 e (L/16)-1 (attenzione che il numero di sottoportanti deve essere comunque un sottomultiplo di L).
L’allocazione può essere eseguita a riempimento di portante oppure a “round-robing”, ovvero riempiendo prima i codici 0 di ciascuna sottoportante poi tutti i codici 1 poi i 2 e cosi via, tuttavia non considereremo più questa variante e analizzeremo la versione base che serve maggiormente ai nostri scopi.
II.5 Risultati delle simulazioni con i Generatori di
Traffico
A conclusione di questo capitolo sono presentati i risultati di alcune simulazioni. Si analizzerà il file “FlussoTraffico.txt” del simulatore prima dal punto di vista degli utenti e in seguito dal punto di vista dei codici, concluderemo le analisi con la dimostrazione effettiva che i tempi di servizio sono distribuiti esponenzialmente per ciascun tipo di traffico e con i valor medi desiderati.
Le simulazioni sono state eseguite per 500000 mila cicli del generatore; per le considerazioni che saranno fatte e soprattutto per l’esperienza e il confronto con simulazioni precedenti, tale valore sembra un buon compromesso tra l’attendibilità dei risultati e la durata delle simulazioni.
Inoltre poiché in seguito, quando si andrà ad integrare il generatore con il sistema MC-CDMA, sarà necessario rallentare il generatore per consentire all’algoritmo di predistorsione di convergere, considereremo un valore di Tblocco incrementato di un fattore 1000.
Capitolo II
56 Pertanto le simulazioni che seguono, descrivono la dinamica del traffico dentro una cella durante un tempo pari a :
(Tblocco*1000)*Numero_Cicli=8000secondi
Per rendere più leggibile il file, i dati in esso contenuti verranno presentati in forma grafica, sul grafico troveremo in ascisse il valore del tempo (secondi) e in ordinate il numero di utenti presenti dentro la cella ad ogni istante considerato; infine questo tipo di grafico sarà presentato per i tre scenari di traffico alto , medio e basso, secondo i valori visti al paragrafo II.3.
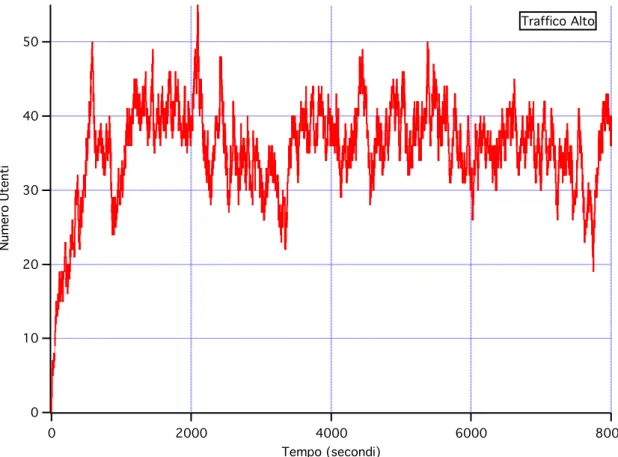
50 40 30 20 10 0 Numero Utenti 8000 6000 4000 2000 0 Tempo (secondi) Traffico Alto
Capitolo II 57 25 20 15 10 5 0 Numero Utenti 8000 6000 4000 2000 0 Tempo (secondi) Traffico Medio
Fig. II.3 – Simulazione con Traffico Medio
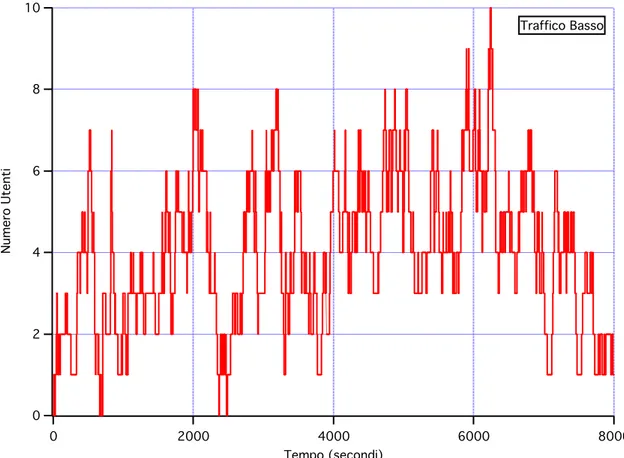
Dal confronto tra i grafici di Fig. II.2, II.3 e II.4 si può notare che l’andamento degli utenti nei tre scenari ha caratteristiche comuni, ad esempio si parte da un numero di utenti comune, si ha una prima fase di crescita veloce degli utenti, dopodichè si raggiunge un andamento medio che oscilla intorno ad un valore proporzionale al tipo di traffico che abbiamo scelto: con lo scenario alto ci troviamo ad un numero medio di utenti che si aggira intorno a 40, con il traffico medio ci si stabilizza intorno ai 15-20, mentre nel caso di scenario basso siamo intorno ai 4-6 utenti; ovviamente il fenomeno è più evidente nel caso di scenario alto poiché si ha un numero complessivo di arrivi maggiore rispetto agli altri casi.
Capitolo II 58 10 8 6 4 2 0 Numero Utenti 8000 6000 4000 2000 0 Tempo (secondi) Traffico Basso
Fig. II.4 – Simulazione con Traffico Basso
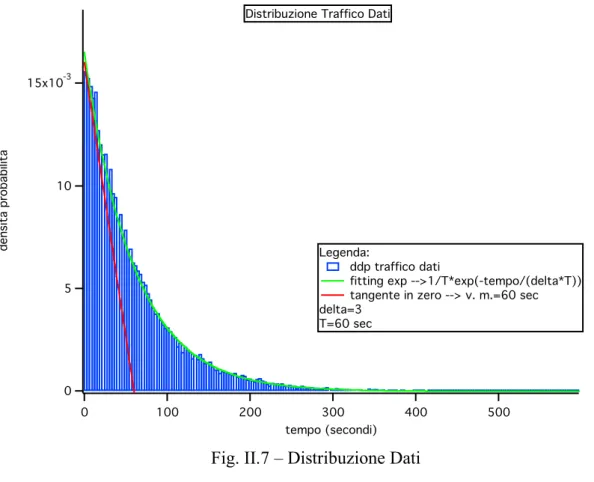
Si procede a dimostrare adesso che i tempi di servizio attribuiti agli utenti sono effettivamente esponenziali e con il valor medio voluto (ossia 180 secondi per il traffico real time e streaming e 60 secondi per quelli dati). cosi
Gli istogrammi di Fig. II.5, II.6 e II.7 sono stati ottenuti considerando ogni valore di durata generato per ogni utente di ciascun tipo (Real Time, Streaming e Data).
Ciascun valore di DURATA viene diviso per un delta (nel caso presente delta=3) e poi se ne fa la parte intera; in base al valore cosi trovato, si va ad incrementare di uno l’intervallo corrispondente, implementando cosi il calcolo della densità di probabilità della distribuzione dei tempi di servizio. Fittando l’istogramma si nota che la curva che si ottiene è effettivamente un’esponenziale, inoltre tracciando la tangente alla curva nel punto zero si nota che il punto d’incontro della tangente con l’asse x coincide con il valor medio della distribuzione e tale valore è esattamente quello pronosticato, ossia 180, 180 e 60.
Capitolo II 59 5x10-3 4 3 2 1 densita probabilita 500 400 300 200 100 0 tempo(secondi) Legenda:
ddp traffico Real Time
fitting exp --> 1/T*exp(-tempo/(delta*T)) tangente in zero --> v.m.=180 sec delta=3
T=180 sec Distribuzione Traffico Real Time
Fig. II.5 – Distribuzione Real Time
5x10-3 4 3 2 1 densita probabilita 500 400 300 200 100 0 tempo (secondi) Legenda: ddp traffico streaming
fitting exp --> 1/T*exp(-tempo/(delta*T)) tangente in zero --> v.m.=180 sec delta=3
T=180 sec Distribuzione Traffico Streaming
Capitolo II 60 15x10-3 10 5 0 densita probabilita 500 400 300 200 100 0 tempo (secondi) Legenda: ddp traffico dati
fitting exp -->1/T*exp(-tempo/(delta*T)) tangente in zero --> v. m.=60 sec delta=3
T=60 sec Distribuzione Traffico Dati
Fig. II.7 – Distribuzione Dati
Infine resta da analizzare come avviene l’assegnamento del codice nei casi di allocazione guidata e random, per capire meglio riportiamo una parte del file “FlussoTraffico.txt”.
In Fig. II.8 si osserva l’allocazione random: all’istante 10.752 si verifica l’ingresso di un utente di tipo DATA a cui viene assegnato il codice 203.
Fig. II.8 – FlussoTraffico Random
L’effetto dell’allocazione casuale è più evidente se si considera l’uscita di un utente e il successivo ingresso di un altro, come si note osservando la Fig. II.9:
10.720000 5 0 0 0 0 [ 155 58 204 145 127 ]
10.736000 5 0 0 0 0 [ 155 58 204 145 127 ]
10.752000 6 0 0 1 0 [ 155 58 204 145 127 203 ]
10.768000 6 0 0 0 0 [ 155 58 204 145 127 203 ]
Capitolo II
61
Fig. II.9 – Flusso Traffico Random 2
In questo caso si può notare che all’istante 35.744 si verifica l’uscita di un utente con conseguente rimozione del codice corrispettivo (in questo caso il 24) alcuni cicli dopo si vede che a 37.824 secondi si ha l’ingresso di un nuovo utente e l’associazione di un codice: si noti che il codice assegnato viene scelto a caso (90) : è diverso dal precedente.
Il contrario avviene se si consulta lo stesso file ottenuto nel caso di allocazione guidata, cfr. Fig. II.10:
Fig. II.10 – Flusso Traffico Guidato
35.712000 8 0 0 0 0 [ 155 172 204 153 127 224 84 24 ] 35.728000 8 0 0 0 0 [ 155 172 204 153 127 224 84 24 ] 35.744000 7 0 0 0 1 [ 155 172 204 153 127 224 84 ] 35.760000 7 0 0 0 0 [ 155 172 204 153 127 224 84 ] . . . . 37.792000 7 0 0 0 0 [ 155 172 204 153 127 224 84 ] 37.808000 7 0 0 0 0 [ 155 172 204 153 127 224 84 ] 37.824000 8 0 0 1 0 [ 155 172 204 153 127 224 84 90 ] 37.840000 8 0 0 0 0 [ 155 172 204 153 127 224 84 90 ] 29.888000 7 0 0 0 0 [ 255 254 95 170 210 181 78 ] 29.904000 7 0 0 0 0 [ 255 254 95 170 210 181 78 ] 29.920000 6 0 0 0 1 [ 255 254 95 170 181 78 ] 29.936000 6 0 0 0 0 [ 255 254 95 170 181 78 ] . . . 33.568000 6 0 0 0 0 [ 255 254 95 170 181 78 ] 33.584000 6 0 0 0 0 [ 255 254 95 170 181 78 ] 33.600000 7 0 1 0 0 [ 255 254 95 170 210 181 78 ] 33.616000 7 0 0 0 0 [ 255 254 95 170 210 181 78 ]
Capitolo II
62 In questo caso si vede che all’istante 29.92 viene deallocato il codice 210 e all’istante 33.6 viene riallocato lo stesso codice, questo perché i codici non sono più allocati in maniera casuale, ma seguono un preciso ordine.