5. CLUSTERIZZAZIONE FEATURES E CREAZIONE MAPPA
5.1 Premessa
In questo capitolo, viene affrontato il problema della clusterizzazione delle features estratte dalla coppia di frames stereo che hanno una corrispondenza destra-sinistra. Gli algoritmi proposti in questo capitolo, sono stati testati utilizzando il SIFT come algoritmo per estrarre le features (capitolo 3) e le corrispondenze sono state trovate tramite l’algoritmo di paragrafo 3.3. Ciò non toglie che gli algoritmi di questo capitolo possano avere un modulo a monte diverso dal SIFT: basta un qualsiasi algoritmo che estrae features da un’immagine e permette di trovare una corrispondenza tra features. I risultati che verranno presentati potranno, in futuro, essere migliorati utilizzando un diverso modulo per l’estrazione di features.
5.2 Clusterizzazione delle features
5.2.1 Scelta del metodo di clusterizzazioneIl problema della clusterizzazione è già stato esposto nel paragrafo 1.3.3.
Nel nostro caso dobbiamo clusterizzare punti tridimensionali per riconoscere gli ostacoli. Si devono fare due osservazioni:
• Non si conosce a priori il numero di clusters.
• Il baricentro del cluster solitamente non appartiene ai punti del cluster perché i punti del cluster rappresentano superfici che possono essere concave o convesse.
Il metodo utilizzato in [12] presentato nel paragrafo 1.3.3 non può essere impiegato perché si ha un numero basso di punti che il SIFT restituisce dopo la triangolazione (circa 45) e si ha overfitting (numero di osservazioni troppo basso rispetto al numero di parametri del modello) anche nel caso di pochi oggetti (ad. esempio 5). Infatti, con un numero di clusters grande (ad esempio 5) il parametro che quantifica la qualità dei clusters non dà indicazioni attendibili sul numero di oggetti presenti. Inoltre la supposizione fatta nell’ articolo che i clusters abbiano struttura planare , valida quando si utilizzano altre tecniche di visione rispetto alle nostre per costruire una immagine di profondità, non può essere fatta nel nostro caso.
Nell’ articolo [13] presentato nel paragrafo 1.3.3 si ha un problema molto simile al nostro : clusterizzare punti 3D per riconoscere oggetti, senza sapere a priori quanti oggetti abbiamo di fronte. In questo caso come nel nostro, si ha un numero basso di punti perché si utilizzano features per rappresentare le immagini. Il metodo che viene utilizzato è il clustering gerarchico. Tale metodo permette di conoscere il numero di oggetti presenti in funzione della distanza che due punti devono avere per essere considerati come appartenenti allo stesso oggetto.Tale distanza nel nostro caso potrebbe essere data dall’errore di triangolazione.
Non si può utilizzare un metodo a potenziale perché tale metodo fa sì che diventino centri dei clusters solo i punti che hanno un certo potenziale. Un punto lontano da tutti gli altri, nel nostro caso, costituisce un cluster dato che rappresenta un ostacolo lontano da tutti gli altri; utilizzando il metodo dei potenziali tale punto non diventerebbe un cluster perché avrebbe potenziale basso.
Il clustering incrementale è utilizzato per il problema di rappresentare la superficie di un oggetto con un numero di punti minore rispetto a quelli che si hanno ([11]). Il clustering incrementale consiste nei seguenti passi:
1. Si parte da un cluster contenente un solo punto che è uno dei punti da clusterizzare. 2. Si aggiungono al cluster i punti non ancora clusterizzati più vicini a tale cluster
(solitamente in termini di distanza euclidea), incrementando il numero degli elementi del cluster.
3. Ci si ferma secondo criteri che dipendono dall’applicazione: è stato creato un nuovo cluster.
4. Si eseguono le operazioni 1,2 e 3 finché tutti i punti non sono stati clusterizzati. Nel nostro caso abbiamo deciso di utilizzare il clustering incrementale perché tale tecnica non richiede la conoscenza a priori del numero di cluster. Inoltre, il metodo da noi utilizzato ci permette di sfruttare due considerazioni che verranno fatte in seguito per effettuare il clustering.
Esiste la possibilità di effettuare un clustering gerarchico in cui l’albero gerarchico viene “tagliato” ad una certa altezza, in modo da determinare il numero di clusters. La creazione dell’albero gerarchico ha però un grande costo computazionale quindi si è scelto di utilizzare il metodo incrementale.
5.2.2 Il metodo utilizzato
Per chiarire il funzionamento del nostro metodo immaginiamo di associare una sfera a ciascun punto da clusterizzare. Tali sfere avranno un raggio proporzionale alla distanza del punto ad esse associato dal sistema di visione. Ogni sfera avrà il centro proprio nel punto cui è associata. Il metodo di clustering proposto segue la seguente regola: due punti appartengono allo stesso cluster se le sfere a loro associate si incontrano.(fig.5.1)
Fig.5.1 Clusterizzazione utilizzando il metodo incrementale. Cluster diversi hanno colori diversi. Ciascun punto da clusterizzare è rappresentato da una sfera che ha il suo centro proprio
in quel punto e raggio pari all’errore di triangolazione del punto. Il sistema di riferimento utilizzato e quello specificato in fig.2.7 telecamera sinistra (Xcl,Ycl,Zcl).
5.2.3 Implementazione
L’algoritmo utilizzato per realizzare il clustering incrementale descritto nel paragrafo precedente utilizza due strutture dati: una, chiamiamola P, contenente i punti da clusterizzare, l’altra, chiamiamola C, contenente i punti raggruppati in clusters.
La struttura dati P sarà un insieme di punti 3D vale a dire una matrice 3xn dove n è il numero di punti. La struttura dati C sarà un insieme di matrici; ogni matrice appartenente alla struttura dati C rappresenta un cluster. Ogni matrice appartenente alla struttura dati C avrà lunghezza (3xk) dove k è il numero di punti appartenenti al cluster. Il numero di matrici appartenenti alla struttura dati C è variabile perché variabile è il numero dei cluster (par.5.2.1).
L’algoritmo, man mano che clusterizza i punti, elimina gli elementi dalla struttura dati P per metterli nella struttura dati C; quando la struttura dati P è vuota l’algoritmo ha terminato la clusterizzazione.
L’algoritmo può essere esplicato con i seguenti passi:
1. Aggiungere un punto 3D da clusterizzare (struttura dati P) alla struttura dati C. Il punto aggiunto rappresenta un nuovo cluster.
2. Togliere l’elemento aggiunto nel punto 1 dalla struttura dati P.
3. Ogni elemento della struttura dati C viene confrontato con tutti gli elementi della struttura dati P in termini di distanza euclidea; se tale distanza euclidea è inferiore alla somma dei raggi delle due sfere associate con i due punti confrontati, l’elemento della struttura dati P viene aggiunto al cluster cui appartiene il punto con cui è stato confrontato. Se un punto viene aggiunto alla struttura dati C, viene eliminato dalla struttura dati P.
4. Si eseguono i punti 1,2,3 finché la struttura dati P non è vuota.
Il funzionamento dell’algoritmo viene ulteriormente chiarito con il flow-chart di fig.5.2. Gli elementi della struttura dati P vengono riferiti con la notazione P(i,j) perché P è una matrice di dimensioni (3xn). Con la notazione P(:,j) ci si riferisce alla colonna j della matrice P (ogni colonna della matrice P rappresenterà un punto). Ogni cluster all’interno della struttura dati C è una matrice: ci si riferisce a tale matrice con la notazione C{k} dove k è l’indice associato al cluster.
Ci si riferisce ad un elemento della matrice che rappresenta un cluster con la notazione C{k}[i,j].Ogni colonna della matrice C{k} verrà riferita con la notazione C{k}[:,j] e rappresenterà un punto tridimensionale clusterizzato.
Gli indici partono dal valore 0 (zero-based).
La funzione ncol(M) restituisce il numero delle colonne della matrice M .
La funzione elim(M,j) elimina la colonna j dalla matrice x; dopo l’eliminazione il numero delle colonne della matrice x diminuisce di 1.
La funzione dist(x,y) calcola la distanza tra due vettori x e y.
Fig.5.2 Flow-chart che rappresenta l’algoritmo che realizza il clustering 5.2.4 Scelta del raggio delle sfere
Si presenta il problema di scegliere il raggio dalla sfera associata a ciascun punto da clusterizzare.
E’ stato deciso di scegliere un raggio proporzionale alla coordinata z del punto da clusterizzare per due motivi:
1. In generale il SIFT trova più features su un oggetto lontano che su uno vicino. (A meno che l’oggetto non sia di colore uniforme, vedi paragrafo 3.5).
2. L’errore sulla stima della posizione tridimensionale nel sistema di riferimento camera (fig.2.7) di un punto aumenta con la sua coordinata z.[24]
Nell’articolo [24] viene provato che l’errore di triangolazione dipende dalla posizione del punto tridimensionale rispetto al sistema di riferimento telecamera (fig.2.7). In questo articolo l’errore di triangolazione viene rappresentato con degli ellissi. Nella presente tesi l’errore di triangolazione viene rappresentato con delle sfere per motivi computazionali.
Si deve ora scegliere qual’è la forma della funzione che ,data la coordinata z del punto 3D da clusterizzare, ci restituisce il valore del raggio associato.
E’ stata scelta una retta con pendenza 0.10.
z
z
f
r
=
(
)
=
0
.
1
⋅
(5.1)La scelta del valore 0.1 per quanto riguarda la pendenza è stata fatta in base a due cosiderazioni che verranno espresse nei prossimi due paragrafi.
5.2.4.1 Prima considerazione
Sperimentalmente si è scoperto che il numero di features estratte e triangolate che stanno su un oggetto lontano non è uguale al numero di features estratte e triangolate che stanno su un oggetto vicino anche in proporzione alla sua superficie.
Se prendiamo un qualsiasi oggetto, il numero di features estratte che stanno su di esso saranno un numero tanto maggiore quanto l’oggetto è vicino al sistema di visione. Per questo motivo, il raggio delle features è stato scelto in proporzione alla coordinata z (5.1).
Segue un tentativo di scrivere una formula che ci permetta di calcolare la pendenza della retta della (5.1) in base a questa considerazione. Tale tentativo non verrà impostato mediante considerazioni rigorose dal punto di vista teoretico, data l’assoluta varietà degli oggetti presenti nella realtà empirica.
Ammettiamo di avere un piano davanti al cono visivo ad un qualsiasi distanza. Tale piano copre tutto il cono visivo. Ammettiamo che l’algoritmo di visione restituisca un certo numero nFeat di features. Ammettiamo inoltre che l’algoritmo di visione estragga features disposte uniformemente sul piano che stiamo prendendo in considerazione. La cosa migliore sarebbe che i punti appartenenti a tale piano venissero assegnati allo stesso cluster visto che appartengono allo stesso oggetto.
Se dobbiamo scegliere il raggio delle sfere in maniera proporzionale a z per far sì che i punti vengano assegnati allo stesso cluster , il raggio deve essere scelto con la seguente formula:
z
m
r
=
⋅
nFeat
m
fcLength imSize⋅
=
2
(5.2)dove m è la pendenza della retta scelta, imSize è una delle due dimensioni dell’immagine (si può scegliere la dimensione minima, media oppure la massima), fcLength è la lunghezza focale,nFeat è il numero di features restituite dall’algoritmo di visione dopo la triangolazione.
Fig.5.3 Immagine artificiale in cui un piano bianco copre tutto il cono visivo.
In blu:sono rappresentate le features che l’algoritmo di visione estrae idealmente in maniera costante su tutta l’immagine.
In verde:il raggio (Rp) è il raggio delle sfere proiettato sull’immagine.
Scegliendo il raggio con la formula (5.2), le sfere si incontrano e vanno a formare un cluster. Questa considerazione vale qualsiasi sia la distanza del piano visto che ,data la formula (5.2), possiamo assumere che la proiezione del raggio sull’immagine rimanga costante.(fig.5.3).
5.2.4.2 Seconda considerazione: Stima dell’errore di triangolazione
Si può scegliere il raggio delle sfere in base alla stima dell’errore di triangolazione. Per stimare l’errore di triangolazione utilizziamo il database di features. Il funzionamento del software che gestisce il database è stato spiegato nel cap.3.
Per stimare l’errore di triangolazione si adotta la seguente procedura sperimentale:
• Utilizzando la coppia di telecamere a bordo del robot, si cattura un video in cui il robot è fermo.
• Su tale video si fa girare il programma che gestisce il database di features. Le features presenti all’interno dei frames verranno seguite nel tempo.
• Dato che c’è un errore di triangolazione, le features non rimarranno ferme tra un frame e l’altro ma si muoveranno. Visto che il robot è fermo, il movimento delle features è dovuto all’errore di triangolazione.Si memorizza quindi le posizioni che le varie features hanno avuto nel tempo per valutare l’errore di triangolazione.
Fig.5.4 Rappresentazione dei dati presenti all’interno del database di features. I punti rappresentano la posizione vista dall’alto (coordinate X e Z) delle features(fig.2.7). I punti rossi rappresentano le features viste nell’ultimo frame e che sono già state viste in frames
precedenti. I punti verdi rappresentano le features viste solo nell’ultimo frame. I punti blu rappresentano le features viste solo una volta nei cinque frame precedenti. I punti neri rappresentano le features che sono state viste per più frames precedenti ma non nell’ultimo
frame.
La posizione delle features rappresentata sul grafico è quella che avevano l’ultima volta che sono state viste.
Il numero accanto ai punti rossi rappresenta il numero di volte che le features sono state viste meno uno.
I segmenti blu rappresentano la differenza di posizione che c’è tra la posizione attuale delle features e quella che avevano la prima volta che sono state viste.
I segmenti blu di fig.5.4 rappresentano la differenza tra la posizione che le features avevano la prima volta che sono state trovate e la posizione attuale. Questi segmenti ci possono dare un’idea dello spostamento delle features nel tempo.Dato che il robot è fermo, lo spostamento delle features è dovuto all’errore di triangolazione. Notare che la lunghezza dei segmenti aumenta all’aumentare della coordinata z della posizione delle features.
Una volta memorizzate le posizioni che le varie features hanno avuto nei vari frame si procede ad un’analisi dei dati sperimentali:
1. Si calcola la coordinata z (vedi coordinate camera fig.2.7) media della posizione che ogni feature ha assunto nei vari frames.
2. Si calcola quindi la deviazione standard di tale posizione per ogni coordinata (x,y,z) e si sommano le tre deviazioni standard.
3. Si realizza un grafico bidimensionale in cui l’asse delle ascisse rappresenta la coordinata z media della posizione che le varie features hanno assunto, quello delle ordinate la somma delle deviazioni standard calcolate al punto 2.
4. Per ogni feature che è stata seguita per almeno 20 frame, si mette sul grafico un punto che rappresenta la coordinata z della posizione media e la deviazione standard della
posizione media (in realtà è la somma delle deviazioni standard delle tre coordinate x, y e z) che quella feature ha avuto. Si utilizza la somma delle deviazioni standard delle tre coordinate perché si considera il fatto che questo grafico verrà utilizzato per calcolare il raggio delle sfere.
Il risultato delle operazioni appena descritte è il seguente grafico:
Fig.5.5 Stima dell’errore di triangolazione. Ogni punto rappresenta la coordinata z della posizione media e la deviazione standard della posizione di una feature che è stata seguita per
almeno 20 frames.
La retta in rosso è la retta di regressione ai minimi quadrati.
In fig.5.5 vediamo rappresentata in rosso la retta di regressione dei minimi quadrati
([25],paragrafo 9.2 del libro). Tale retta può essere vista come la funzione che lega l’errore di triangolazione con la coordinata z di una feature. La retta ha pendenza pari a 0.099272.
Visto che, non solo la media, ma anche la dispersione della deviazione standard aumenta con l’aumentare della posizione media, una conclusione a cui si è giunti è che i punti da prendere in considerazione sono quelli che hanno una coordinata z rispetto alla camera (fig.2.7) inferiore a 10 metri.
5.2.4.3 Scelta finale in funzione delle due considerazioni
Le telecamere utilizzate hanno una lunghezza focale pari a circa 400 pixels. Si lavora ad una risoluzione 320 x 240 quindi come dimensione dell’immagine possiamo scegliere 320 pixels.Ammettiamo che il numero medio di features restituite dall’algoritmo di triangolazione sia 13;se, per calcolare il raggio, si utilizza l’equazione (5.2), otteniamo:
z 0.1109 2 13 400 320 ⋅ = ⋅ ⋅ = z r (5.3)
La retta di regressione ottenuta dal grafico dell’errore di triangolazione (fig.5.5) ha pendenza pari a 0.099272. Si sceglie quindi come pendenza della retta che rappresenta la funzione che lega il raggio delle sfere con la coordinata z delle features un valore pari a 0.1 che è circa la media delle due pendenze che si hanno in base alle due precedenti considerazioni:
z z z r = + ⋅ =0.1051⋅ ≅0.1⋅ 2 099272 . 0 1109 . 0 (5.4) 5.2.4.4 La conferma sperimentale
Utilizzando la (5.3), che considera un numero di features estratte pari a 13, si ottiene che la pendenza m della retta che lega il raggio delle sfere associate con la coordinata z delle features ha un valore simile alla pendenza della retta di regressione di fig.5.5: una prova sperimentale della validità della (5.2).
5.3 Rappresentazione degli ostacoli
5.3.1 Il problema della rappresentazione bidimensionale
Adesso che i punti sono stati clusterizzati, sappiamo che ogni cluster rappresenta un ostacolo. Si pone ora il problema di rappresentare gli ostacoli sul piano bidimensionale, in modo da poter agevolmente pianificare il percorso che il robot condurrà tra gli ostacoli.
Gli ostacoli saranno rappresentati come se venissero visti dall’alto. Con riferimento alle coordinate relative alla camera sinistra (fig.2.7), verranno considerate solo le coordinate x-z. I cluster composti da punti che stanno al livello del terreno, non sono veri e propri ostacoli ma insiemi di features che l’algoritmo ha trovato sul terreno (tali features possono rappresentare qualcosa che è disegnato sul terreno come le strisce pedonali); così come i cluster troppo alti possono rappresentare oggetti sotto cui il robot può passare. Sarà compito di un algoritmo a valle di quello qui presentato, valutare le coordinate y dei punti appartenenti al cluster per decidere se il cluster rappresenta un ostacolo da evitare o meno.
Utilizzando il metodo di rappresentazione degli ostacoli che verrà esposto di seguito, si fa la supposizione che gli ostacoli siano dei cilindri infiniti messi in verticale di fronte al robot.
5.3.2 Il metodo di rappresentazione proposto
Per spiegare come viene rappresentato un ostacolo immaginiamo di costruire una circonferenza per ogni punto del cluster; tale circonferenza avrà raggio pari all’errore di triangolazione e centro nel punto cui è associato. A questo punto l’ostacolo è rappresentato da un insieme di circonferenze che si intersecano.(fig.5.6)
Fig.5.6 L’ostacolo è rappresentato come un insieme di circonferenze che si intersecano
Dovremo, adesso, trovare il bordo esterno dell’insieme di circonferenze per avere una rappresentazione dell’ostacolo che sia utile per l’algoritmo di pianificazione del percorso.
In seguito, chiameremo centri delle circonferenze i punti tridimensionali che abbiamo clusterizzato nel par.5.2, di cui si considerano solo le coordinate x-z; chiameremo punti 2D i punti appartenenti al bordo esterno dell’ostacolo rappresentato in fig.5.6.
5.3.2.1 L’algoritmo utilizzato
Per trovare il bordo esterno dell’ostacolo si utilizza un algoritmo che, ricevendo in ingresso l’insieme dei punti tridimensionali clusterizzati, è in grado di calcolare un insieme di punti 2D che descrive adeguatamente il bordo dell’ostacolo. Il bordo dell’ostacolo sarà rappresentato da un vettore di punti 2D, vale a dire da una matrice 2xN, chiamiamola M. Tale matrice è il dato di uscita dell’algoritmo. Possiamo vedere la matrice M come un vettore di punti 2D; il punto 2D di indice j non è altro che la colonna j della matrice M.
E’ inoltre richiesto che gli N punti 2D presenti nella matrice M siano ordinati in modo che l’ostacolo possa essere visualizzato tracciando i segmenti che uniscono i punti contigui. In altre parole, deve essere possibile visualizzare l’ostacolo tracciando per ciascun punto 2D di indice j il segmento che va dal punto di indice j a quello di indice j+1; dovrà inoltre essere tracciato un altro segmento che va dal punto di indice N-1 al punto di indice 0 (gli indici sono zero-based) per avere una curva chiusa che rappresenta l’ostacolo.
L’algoritmo che realizza la rappresentazione 2D degli ostacoli dovrà inserire nella matrice M, punti che appartengono agli archi di circonferenza che costituiscono il bordo dell’ostacolo.
L’algoritmo può essere esplicato nel seguente modo:
1. Si inizia da uno dei punti clusterizzati nel par.5.2 che ha un arco della propria circonferenza appartenente al bordo dell’ostacolo
2. Si aggiunge alla matrice M i punti che appartengono all’arco di circonferenza che appartiene al bordo.
3. Se uno dei punti che si sta aggiungendo appartiene ad un cerchio, si passa a disegnare l’arco di circonferenza avente centro nel cerchio cui il punto in oggetto appartiene.
4. Si eseguono i punti 2 e 3 finché i punti che si stanno aggiungendo non sono vicini al punto iniziale. Per verificare ciò si calcola la distanza tra i punti che si stanno aggiungendo e il punto iniziale.
Da qui in poi intenderemo con “cambio di centro” il momento in cui ci si accorge che l’arco di circonferenza che stiamo “disegnando” non appartiene più al bordo, quindi bisogna passare a disegnare un arco di circonferenza avente un altro centro(punto 3).
Fig.5.7 Schema esplicativo del funzionamento dell’algoritmo che calcola il bordo degli ostacoli. In blu: i punti appartenenti al bordo.
Questa tecnica di rappresentazione trova il bordo esterno di un ostacolo ma ha il difetto di non rappresentare il bordo interno di eventuali ostacoli “fatti a ciambella”.Tale problema è particolarmente rilevante nel caso in cui il veicolo sia circondato da un ostacolo. In tal caso, utilizzando questo algoritmo di rappresentazione, il veicolo viene a trovarsi all’interno di un ostacolo.(fig.5.8)
Fig.5.8 Schema esplicativo del funzionamento dell’algoritmo di rappresentazione nel caso in cui il veicolo si venga a trovare all’interno di un ostacolo ”fatto a ciambella”.
I punti in blu rappresentano le features che compongono l’ostacolo. Il triangolo in verde rappresenta il veicolo.
Segmenti in blu: rappresentazione dell’ostacolo utilizzando l’algoritmo esposto in queso paragrafo.
5.3.2.2 Implementazione
Come abbiamo detto, il programma si arresta quando la distanza tra il punto che si sta processando e il punto iniziale sta sotto di una certa soglia. Questa condizione, però, non può essere utilizzata fin dall’inizio perché i punti che vengono processati inizialmente saranno necessariamente vicini al punto iniziale: il programma si arresterebbe subito. C’è bisogno di un ciclo di isteresi “artificiale” che ha come variabile indipendente la variabile “distanza del punto attualmente processato dal punto iniziale”.(fig.5.9).
Fig.5.9 Ciclo di isteresi “artificiale” utilizzato per decidere quando il programma che calcola il bordo va terminato
La soglia andrà scelta in funzione del raggio medio delle circonferenze che compongono l’ostacolo. Dopo alcune prove d’errore la soglia é stata scelta con la seguente formula:
25
medio
raggio
=
Soglia
(5.5)Per far sì che il flow-chart che segue sia più chiaro si ricordano due verità geometriche: 1. I punti appartenenti ad una circonferenza si possono esprimere come:
))
(
),
cos(
(
)
,
(
x
y
=
C
x+
r
⋅
α
C
y+
r
⋅
sen
α
(5.6)dove (x,y) sono le coordinate cartesiane del punto;Cx e Cy rispettivamente le coordinate x e y del centro; r il raggio della circonferenza; α un angolo compreso tra 0 e 2π.
2. Un punto (x,y) sul piano 2D appartiene al cerchio delimitato dalla circonferenza di centro (Cx,Cy) e raggio r se:
r
Cy
Cx
y
x
dist
((
,
),
(
,
))
<
(5.7)dove dist è una funzione che calcola la distanza euclidea tra due punti.
Il flow-char di fig.5.10 spiega in maniera più chiara il funzionamento dell’algoritmo.
La funzione calcIst restituisce 1 se il programma deve essere terminato, 0 altrimenti. La funzione calcIst si basa sul ciclo di isteresi di fig.5.9.
La funzione verifica(x,y) verifica se il punto (x,y) appartiene ad uno dei cerchi;se il punto appartiene ad uno dei cerchi restituisce l’indice nel vettore dei punti tridimensionali (vettore dei punti appartenenti al cluster) del centro del cechio cui il punto appartiene, altrimenti restituisce 0. La funzione calcolaxy(α,r,Cx,Cy) le coordinate cartesiane del punto in base alla formula (5.6).
La funzione trovaNuovoCentro trova il nuovo centro, in base al quale i punti del bordo devono essere disegnati, in base all’indice restituito dalla funzione verifica(x,y).Restituisce tale centro.
La funzione trovaNuovoAngolo trova il nuovo angolo grazie al quale i prossimi punti del bordo verranno calcolati dalla funzione calcolaxy.Restituisce tale angolo.
γ è il valore di cui l’angolo viene incrementato ad ogni ciclo in cui non avviene un “cambio di centro”. E’ stato deciso essere pari a π/360.
φ è il valore di cui l’angolo viene incrementato ad ogni ciclo in cui avviene un “cambio di centro” deve essere maggiore di γ perché il programma non si blocchi in un ciclo infinito.E’ stato scelto pari a π/40.
La funzione agg(M,v) aggiunge il vettore v alla matrice M. La matrice aumenta di dimensioni.
La matrice M è una matrice di dimensioni 2xn (dove n è il numero dei punti bidimensionali che rappresentano il bordo), che rappresenta il bordo.(paragrafo 5.2.3.1).
Fig.5.10 Flow-chart esplicsativo del funzionamento dell’algoritmo che trova il bordo
5.3.3 Semplificazione della rappresentazione
Si presenta la necessità di semplificare la rappresentazione dell’ostacolo che è stata prodotta con l’algoritmo di par.5.3.2. Si vuole far si che servano meno punti per descrivere l’ostacolo.
Per spiegare il funzionamento della tecnica di semplificazione che è stata utilizzata definiamo l’errore cordale Er.
5.3.3.1 L’errore cordale
L’errore cordale ci dà un’idea dell’errore che si commette semplificando il bordo dell’ostacolo con meno punti di quelli trovati con l’algoritmo di par.5.3.2.
Dati n punti p1,…..,pn che rappresentano una parte di bordo, data la retta r che passa dai punti p1 e pn l’errore cordale è definito come:
))
,
(
(
max
, 1n j jdist
r
p
Er
==
(5.8)dove dist è una funzione che calcola la distanza euclidea tra un punto ed una retta.
Dato un insieme ordinato di punti bidimensionali (p1,p2,..pn) è sempre possibile calcolare l’errore cordale calcolando la retta r che passa tra p1 e pn e utilizzando la formula (5.8).
In questo modo l’errore cordale ci dice quale errore commettiamo quando semplifichiamo un insieme di punti che rappresentano una parte del bordo di un ostacolo con un segmento. (fig.5.11).
Fig.5.11: Parte del bordo di un ostacolo. In blu: i segmenti che uniscono i punti appartenenti al bordo. In rosso la retta r che unisce il punto 1 con il punto n. Il segmento in verde è di
lunghezza pari all’errore cordale.
In fig.5.11 i punti che rappresentano il bordo non semplificato sono uniti da segmenti di colore blu. Se semplifichiamo il bordo con una retta che va dal punto p1 al punto pn (retta r di colore rosso) commettiamo un certo errore. Tale errore può essere quantificato con l’errore cordale che è dato dal massimo delle distanze tra la retta r e i punti p2,p3,p4. Tale errore è pari alla lunghezza del segmento disegnato in verde.
5.3.3.2 Algoritmo di semplificazione
L’algoritmo di semplificazione consiste nel sostituire la rappresentazione data dai punti p1,..,pj con i punti p1,pj se l’errore cordale dato dai punti p1,..,pj sta sotto la soglia. L’algoritmo che realizza la semplificazione della rappresentazione degli ostacoli può essere esplicato come segue:
• Si parte dal bordo trovato nel par.5.2
• Si sceglie il valore di una soglia che rappresenta l’errore cordale massimo.
L’algoritmo è esplicato più nel dettaglio dal flow-chart di fig.5.12.
S è una matrice di dimensione 2xn le cui colonne contengono i punti bidimensionali del bordo semplificato. La matrice S è il risultato di questo algoritmo.Inizialmente la matrice S è vuota.Gli elementi della matrice risultato S vengono aggiunti man mano che l’algoritmo cicla dalla funzione agg.
X è una matrice di dimensione 2xn le cui colonne contengono i punti bidimensionali del bordo restituiti dall’algoritmo di par.5.3.2.
La funzione last(X) riceve in ingresso la matrice X e restituisce l’ultima colonna della matrice X.
La funzione cordError(M) riceve in ingresso una matrice di dimensioni 2xn le cui colonne rappresentano punti bidimensionali (p1,…,pn), restituisce l’errore cordale dato da questi punti.(5.8)
La funzione agg(M,v) aggiunge il vettore v alla matrice M. La matrice aumenta di dimensioni.
La notazione X(:,j), dove X è una matrice e j un numero naturale, indica la colonna j della matrice X.
Con la notazione X(:,i:j) si intende la sottomatrice che comprende le colonne di X che vanno da i a j.
CerrTh è la soglia per l’errore cordale che va scelta prima di mandare in esecuzione l’algoritmo.
Fig.5.12 Flow-chart che rappresenta l’algoritmo di semplificazione della rappresentazione di un ostacolo.
5.3.3.3 Risultati
I risultati ottenuti con l’ algoritmo che semplifica il bordo sono presentati con il grafico che segue.
Fig.5.13: rappresentazione di un ostacolo sul piano bidimensionale visto dall’alto (coordinate Zcl,Xcl fig.2.7). In blu: rappresentazione ottenuta utilizzando l’algoritmo di par.5.3.2. In rosso:
semplificazione della rappresentazione ottenuta utilizzando l’algoritmo di par.5.3.3 L’errore cordale utilizzato nell’esperimento è pari a 0.2 metri.
Utilizzando l’algoritmo presentato in questo paragrafo, si riesce a passare da una rappresentazione con 1844 punti (in blu in fig.5.13) ad una rappresentazione che utilizza 33 punti.(in rosso in fig.5.13).
L’errore cordale scelto è pari a 0.2 metri.
5.4 Costruzione della mappa degli ostacoli
5.4.1 Posizione delle features nel sistema di riferimento fisso
Nel paragrafo 2.3 sono state ricostruite le coordinate 3D delle features rispetto al sistema di riferimento solidale alla videocamera sinistra. In questo paragrafo vogliamo stimare la posizione delle features rispetto ad un riferimento fisso.
Per riuscire in questo intento, è necessario conoscere la posizione del robot rispetto ad un riferimento fisso. La posizione del robot può essere ricavata, nel modo più semplice, basandosi sui dati dell’odometria.
Il kart Ulisse [2.2.1] è infatti dotato di due encoder, uno assoluto,che misura l’angolo di sterzo e uno incrementale che misura la velocità angolare della ruota anteriore. Dalla rielaborazione delle misure provenienti ad questi sensori è possibile ricavare la velocità della ruota anteriore e del veicolo e quindi di ricavare, mediante integrazione, la posizione del veicolo.
• Rw raggio di ciascuna ruota
• D lunghezza dell’asse principale • φ angolo di sterzata
• ωA velocità angolare della ruota anteriore
• θ heading angle, ovvero angolo tra l’asse principale del kart e l’asse X • (x,y) posizione del centro dell’asse delle ruote posteriori
Fig.5.14 Schema del modello Cinematico del kart Ulisse
Il modello cinematico per il veicolo che si sfrutta per ricavare le varie quantità in gioco è basato sulle equazioni seguenti:
) sin( ) sin( ) cos( ) cos( ) cos(
ϕ
ω
ϑ
ϑ
ϕ
ω
ϑ
ϕ
ω
D R R y R x w A w A w A = = = & & & (5.9)Mediante integrazione delle equazioni nel sistema (5.9) è possibile ricavare le misure di posizione e dell’angolo di heading, in modo da poter stabilire con precisione la posizione del kart.
In particolare si considera come sistema di riferimento assoluto uno con medesima posizione dell’origine (al centro dell’asse che collega le ruote posteriori) nell’istante iniziale col sistema di riferimento del kart, nella figura 5.14 viene indicato in arancio, ma diversa orientazione.
E’ dunque necessaria qualche piccola trasformazione tra i vari sistemi di riferimento. All’istante iniziale il sistema di riferimento assoluto ha asse X che giace lungo l’asse principale del kart e coincidente con l’asse Y del sistema solidale al kart. L’asse Z dei due riferimenti
invece coincide, quindi la trasformazione tra il sistema di riferimento sul kart e il sistema assoluto è una rotazione di 90-θ° attorno all’asse Z del primo sistema di riferimento:
) 90 , ' (' −θ =rot Z Rkabs (5.10)
La medesima trasformazione si può utilizzare per avere i dati in uscita dal modello Cinematico, implementato in Simulink, per avere i dati dell’odometria espressi rispetto al sistema assoluto.
La trasformazione per passare dal sistema di riferimento sulla videocamera sinistra, in cui risultano espresse le coordinate 3D dopo triangolazione, al sistema di riferimento sul kart è invece la seguente: − − = ° = 0 1 0 0 0 1 1 0 0 ) 90 , ' (' * ) 90 , ' ('X rot Z rot Rwk (5.11)
In questo modo un punto pk in coordinate del sistema di riferimento sul kart è esprimibile
come: w k w k w k R p o p = + (5.12)
dove okw esprime la distanza tra le origini dei due sistemi di riferimento.
Grazie a queste trasformazioni è possibile ricostruire la posizione 3D delle feature rispetto ad un sistema assoluto.
Tuttavia, l’odometria talvolta si rivela inesatta, soprattutto nel lungo periodo, a causa degli errori dovuti all’incremento, per questo motivo in seguito si potrà pensare di migliorare la stima della posizione sfruttando il Sistema di Navigazione già realizzato per il kart, che, fondendo insieme i dati provenienti da GPS e odometria ,produce una stima migliore della posizione.E’ inoltre pensabile l’utilizzo del database di features (capitolo 3) per stimare la posizione del robot, tenendo traccia della posizione assunta nel riferimento mobile da features che sappiamo essere ferme o di cui conosciamo la posizione nel riferimento fisso istante per istante.
Conoscendo la posizione delle features nel sistema di riferimento fisso, è possibile selezionare le features, se supponiamo che esse siano ferme rispetto al terreno. Le features che apparentemente si muovono lo fanno perché c’è un errore di triangolazione, tali features possono essere eliminate dal database.
5.4.2 Selezione delle features mediante clusterizzazione
5.4.2.1 La clusterizzazione nel sistema di riferimento fisso
Nel paragrafo (5.4.1), è stata ricostruita la posizione 3D delle features utilizzando l’odometria. Per avere una mappa vista dall’alto degli ostacoli, sarà necessario clusterizzare le features nel sistema di riferimento fisso col la tecnica di paragrafo 5.3. Per la clusterizzazione sono stati utilizzati i dati contenuti nel database di features (capitolo 3); viene clusterizzato il dato più recente sulla posizione delle varie features nel sistema di riferimento fisso. Non
vengono clusterizzate tutte le features ma possono venir selezionate secondo certi criteri. Uno di questi criteri verrà esplicato nel prossimo paragrafo (5.4.2.2).
5.4.2.2 Criterio di selezione delle features mediante clusterizzazione
Il criterio di selezione delle features si basa sulla seguente affermazione : una feature a
bassa precisione non può stare nello stesso cluster in cui vi sono features ad alta precisione. Questo perché una feature ad alta precisione descrive meglio la posizione e la forma di un ostacolo; una feature a bassa precisione clusterizzata insieme a features ad alta precisione non fa altro che “rovinare” il cluster. Il termine “precisione” si riferisce alla stima dell’errore che si ha sulla posizione delle features. La stima dell’errore è stata fatta nel paragrafo 5.2.3.2 , in base a tale stima è stato scelto il raggio delle sfere utilizzate per la clusterizzazione. Tale raggio verrà ora utilizzato per la stima della precisione: minore è il raggio associato alla feature, maggiore è la precisione della feature.
Per realizzare la selezione delle features si calcola, per ogni cluster, il raggio medio associato alla features: N r m i i
∑
= (5.13)dove ri sono i raggi associati alle features appartenenti al cluster, N il numero di features appartenenti al cluster, m la media dei raggi associati ad ogni feature.
Una features il cui raggio associato è molto maggiore rispetto al raggio medio del cluster (5.13) viene considerata un outlier e viene quindi eliminata dal cluster. La formula utilizzata è la seguente: S m ri > (5.14)
dove S è una soglia scelta im maniera euristica.
La (5.14) può essere calcolata per ogni feature i del cluster. Le features per cui è vera la (5.14) vengono eliminate dal cluster.
Fig.5.15 Schema esplicativo del criterio di selezione delle features mediante clusterizzazione. Il cerchio in nero rappresenta una feature a bassa precisione. I cerchi in blu rappresentano
Prendendo il cluster rappresentato in fig.5.15, la feature rappresentata dal cerchio in nero verrà eliminata dal cluster perché a bassa precisione rispetto alle altre features.
Una volta eliminate le features a bassa precisione, le features vengono nuovamente clusterizzate visto che, a causa della selezione delle features, un cluster può dividersi in più clusters. In fig.5.15, una volta eliminata la features a bassa precisione, il cluster si scinde in due.
5.4.3 Tracking dei clusters nel tempo
5.4.3.1 Realizzazione del tracking mediante database di features
Sfruttando i dati presenti all’interno del database di features, è possibile realizzare un tracking dei clusters nel tempo. Grazie al database è possibile sapere quale percentuale di features che compone un cluster attuale ha composto un cluster al passo precedente.
Si ricorda che ogni passo corrisponde all’elaborazione di una coppia di frames.
Esiste perciò la possibilità di creare un indice che ci dice quanto un cluster al passo attuale corrisponde ad un cluster al passo precedente. Tale indice è stato calcolato con la seguente formula:
n
n
P
=
c (5.15)dove n è il numero delle features che compongono il cluster al passo attuale, nc è il numero di features appartenenti al cluster attuale che corrispondono con quelle del cluster al passo precedente, P è un numero tra 0 e 1 che ci dice quanto un cluster al passo attuale corrisponde ad un cluster al passo precedente.
E’ possibile decidere che, se due clusters presi ad istanti diversi, hanno un P maggiore di una certa soglia, rappresentano lo stesso ostacolo ad istanti differenti.
Il calcolo dell’indice (5.15) è stato implementato e viene visualizzato dal software al centro di ogni cluster (Fig.5.16).
5.4.3.2 Problema dell’angolo visivo
Un ostacolo, ossia un cluster, può stare in parte all’interno del campo visivo, in parte fuori del campo visivo. Per questo motivo, non è possibile utilizzare la formula (5.15) per realizzare un tracking dei clusters, senza tener conto della limitatezza dell’angolo visivo. Infatti, se prendiamo un ostacolo fermo mentre il robot si muove, che sta solo in parte all’interno del campo visivo, possiamo basarci sulla (5.15) per stabilire che, nel tempo, stiamo vedendo lo stesso ostacolo: senza considerare la limitatezza del campo visivo, penseremmo di vedere l’ostacolo che si muove mentre in realtà è il campo visivo che si muove. Questo è un problema simile a quello che si presenta in [2], paragrafo 3.1 dell’articolo.
Sono state quindi create due liste di clusters: una in cui sono presenti i clusters che stanno, almeno in parte, all’interno del campo visivo, una in cui sono presenti i clusters che stanno fuori dal campo visivo. Le features appartenenti ai clusters che stanno, almeno in parte, all’interno del campo visivo vengono clusterizzate ad ogni passo e ad ogni passo viene eseguito il tracking dei clusters. Le features appartenenti ai clusters che stanno fuori del campo visivo sono inattive quindi non vengono clusterizzate e, per la costruzione della mappa, si utilizza la clusterizzazione
che era stata effettuata quando i cluster sono stati messi nella lista dei cluster fuori del campo visivo.
I cluster appartenenti alla lista dei clusters che stanno fuori del campo visivo, possono nuovamente tornare nella lista dei cluster stanno all’interno del campo visivo, se il campo visivo torna ad “inquadrare” tali clusters.
5.4.3.3 Risultati
Fig.5.16 A sinistra: database delle feature (capitolo 3) appartenti ai cluster che stanno all’ interno del cono visivo
A destra: Mappa georeferenziata degli ostacoli. I cluster blu stanno in parte all’interno del campo visivo, i cluster neri stanno fuori dal campo visivo. In rosso: il campo visivo. In verde: il
veicolo. Le misure sugli assi sono in metri.
In fig.5.16 sono mostrati i risultati del tracking dei clusters. Per ogni cluster al passo attuale sono stati calcolati i valori di P (5.15) per ogni corrispondenza tra il cluster al passo attuale e tutti i cluster al passo precedente. Il valore massimo di tutti questi valori di P per ogni cluster è stato visualizzato nel baricentro (fig.5.16, destra). Per quanto riguarda i clusters fuori dal campo visivo, il valore visualizzato si riferisce all’ultimo tracking che è stato eseguito prima che il cluster venisse messo nella lista dei clusters che stanno fuori dal campo visivo.
Siamo quindi riusciti a seguire i cluster nel tempo, senza dover fare stime sulla dinamica dei cluster come, al contrario, è stato fatto negli articoli [1],[2],[3].
5.4.4.1 La Tecnica di selezione proposta
Com’è stato già detto, il software realizzato dovrà funzionare in ambienti dinamici. Può perciò accadere che un oggetto che, in un certo istante, sta in una certa posizione, non stia nella stessa posizione in istanti successivi o precedenti. Per questo motivo, è stato deciso di eseguire una selezione delle features in accordo al seguente criterio: una feature che si trova nel cono
visivo viene eliminata dal database se non è stata individuata almeno una volta negli ultimi N frame. Chiameremo questo criterio di selezione “selezione delle features mediante finestra temporale”.
Se l’algoritmo che estrae le features, che nel nostro caso è il SIFT, fosse perfetto, ossia estraesse sempre le features in maniera uniforme su tutti gli oggetti, non servirebbe la finestra temporale perché, in questo caso, se una feature non viene rilevata vuol dire che non è presente quindi può essere eliminata dal database.
Il funzionamento del SIFT si discosta molto dal suddetto funzionamento ideale, quindi si rende necessario adottare la finestra temporale per far sì che la forma della mappa ricostruita non si modifichi troppo tra un passo dell’algoritmo (che equivale all’elaborazione di una coppia di frames) ed il successivo.
5.4.4.2 Il problema dell’occlusione
La tecnica di selezione delle features a finestra temporale presenta però un problema nel caso in cui un oggetto occluda il campo visivo. In questo caso vengono eliminati dal database i punti lontani memorizzati precedentemente che pur sono presenti nella realtà.
Fig.5.17 Rappresentazione del problema dell’occlusione. I segmenti in nero rappresentano il campo visivo visto dall’alto.
I segmenti in verde rappresentano l’oggetto che occlude
I punti in blu rappresentano i punti che vengono eliminati dal database perché non vengono visti dal sistema di visione a causa dell’oggetto che occlude il campo visivo
In fig.5.17, vediamo che i punti in blu vengono eliminati dal database perché occlusi dall’oggetto in verde pur essendo presenti nella realtà.
5.4.4.3 Implementazione
La finestra temporale viene implementata utilizzando il dato sul numero del frames in cui una features è stata estratta l’ultima volta.Tale dato è presente nel database di features (capitolo
3). Se la differenza tra il numero del frame attuale e quello precedente supera la soglia N, la feature non viene più utilizzata per la clusterizzazione quindi determinazione degli ostacoli. Solo le features appartenenti ai cluster che stanno, almeno in parte, nel cono visivo sono interessate da questo processo di selezione. Come è stato spiegato nel paragrafo 5.4.3, esistono due liste: una che contiene le features appartenenti ai clusters che stanno, almeno in parte, nel cono visivo, l’altra che contiene le features appartenenti ai clusters che non stanno nel cono visivo. Solo la prima lista sarà interessata dal processo di selezione.
Anche nella prima lista, però, vi possono essere features che stanno fuori dal cono visivo, quindi non vanno considerate nel processo di selezione. Per questo motivo, l’attributo riguardante il numero del frame in cui la feature è stata estratta, viene incrementato di uno ad ogni passo, solo per le feature che stanno nella lista dei cluster “attivi” e che stanno fuori dal cono visivo.
Come spiegato nel paragrafo 5.4.3, i cluster che stanno fuori del campo visivo possono venire nuovamente inquadrati dal sistema di visione; in tal caso, le features appartenenti a tali clusters tornano a far parte delle features “attive” quindi su di loro viene eseguita la selezione mediante finestra temporale. Perché l’algoritmo di selezione funzioni bene, c’è bisogno che venga aggiunto all’attributo “numero del frame in cui le features sono state trovate” delle features che erano fuori del cono visivo e che sono state riattivate, un valore pari al numero di frame in cui le features sono state fuori dal cono visivo. Se ciò non viene fatto e le features sono state fuori del campo visivo per molti frames, le features vengono automaticamente eliminate dall’algoritmo di selezione mediante finestra temporale.
5.4.5 Risultati
Utilizzando le tecniche spiegate, si riesce ad ottenere una buona mappa degli ostacoli visti dall’alto.
Fig.5.17 Schemata del software che costruisce la mappa dell’ambiente vista dall’alto. In alto: coppia di frames stereo da cui vengono estratte le features
In basso a sinistra: il database di features (capitolo 3)
In basso a destra: Rappresentazione bidimensionale degli ostacoli. In nero:gli ostacoli che stanno fuori del campo visivo. In blu: gli ostacoli che stanno nel campo visivo.In verde: il
veicolo Ulisse. In rosso: il campo visivo. Le misure sugli assi sono in metri.
In fig.5.17, vediamo una schermata del programma realizzato che costruisce la mappa vista dall’alto dell’ambiente circostante.
Il programma è in grado di girare in tempo reale e costruire la mappa, riesce ad elaborare una coppia di frames in un secondo circa. I frames sono stati acquisiti alla risoluzione di 320x240. Il programma è in grado di eseguire un tracking dei clusters nel tempo, come si vede dai numeri presenti in fig.5.17 in basso a destra. Tali numeri stanno nel baricentro di ogni clusters e rappresentano il valore di P (5.15) calcolato tra quel cluster ed il cluster corrispondente al passo precedente(vedi paragrafo 5.4.3).
5.5 Chiusura dell’anello
5.5.1 La struttura dati di uscitaUna volta costruita la mappa, si è presentata la necessità di fornire un’uscita dalla struttura semplice in modo che il modulo di controllo potesse chiudere l’anello. E’ stato deciso di utilizzare come uscita un vettore statico di dimensione scelta a priori.
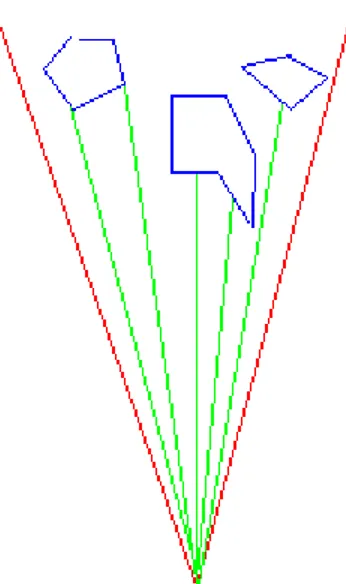
Il campo visivo è stato suddiviso in N parti , dove N è la dimensione del vettore, ed ogni elemento del vettore rappresenta la distanza dell’ostacolo più vicino in una direzione.(fig.5.18)
Fig. 5.18 Schema esplicativo della suddivisione del campo visivo. Il campo visivo è stato suddiviso in 5 parti.(N=5). I segmenti in rosso rappresentano il campo visivo. I segmenti in blu
rappresentano gli ostacoli. I segmenti in verde sono di lunghezza pari ai valori che vengono assegnati al vettore di uscita.
5.5.2 Implementazione
Nel paragrafo 5.4, è stata creata la mappa vista dall’alto degli ostacoli rispetto ad un riferimento fisso. L’uscita che dobbiamo produrre rappresenta la distanza degli ostacoli rispetto ad un riferimento mobile. Per produrre tale uscita c’è quindi bisogno della posizione degli ostacoli rispetto al riferimento mobile. Grazie all’odometria (paragrafo 5.4.1) conosciamo la matrice di rototraslazione del riferimento mobile R. Tale matrice può essere usata nel seguente modo per ottenere un punto riferito al sistema di riferimento fisso dato un punto riferito al sistema di riferimento mobile:
pm
R
pf
=
⋅
(5.16)dove pm è un punto riferito al sistema mobile, pf è lo stesso punto riferito al sistema fisso. Nel paragrafo 5.4, gli ostacoli sono rappresentati da un insieme di punti nel sistema di riferimento fisso, per ottenere gli stessi punti riferiti al sistema mobile basta invertire la (5.16):
pf
R
pm
=
−1⋅
(5.17)Grazie alla (5.17) si può ottenere la posizione degli ostacoli nel riferimento mobile partendo dalla mappa costruita nel paragrafo 5.4.
A questo punto, basta trovare l’intersezione tra ogni segmento in verde in fig.5.18 e il segmento appartenente all’ostacolo più vicino al cono visivo nella direzione del segmento verde, per ottenere il vettore di uscita. Nel caso che, nella direzione del segmento verde, non vi siano ostacoli, si assegna il valore massimo all’elemento che nel vettore rappresenta quella direzione. Tale valore massimo viene scelto a priori.
5.5.3 Risultati
Implementando la tecnica sopra descritta, si ottiene un vettore statico che descrive l’ambiente che si trova davanti al sistema di visione, a partire dalla mappa bidimensionale degli ostacoli (fig.5.19).
Fig.5.19 Descrizione della profondità dell’ambiente che sta davanti al sistema di visione a partire dalla mappa creata nel paragrafo 5.4.
In alto a sinistra: il database di features (cap.4) In alto a destra: la mappa degli ostacoli